基于局部方差和后验概率分类的快速模板匹配算法*
2023-10-07林煜桐朱姗姗彭凌西彭绍湖林焕然
林煜桐,朱姗姗,彭凌西,彭绍湖,谢 翔,林焕然
(1.广州大学 电子与通信工程学院,广东 广州 510006;2.广东白云学院 电气与信息工程学院,广东 广州 510450;3.广州大学 机械与电气工程学院,广东 广州 510006)
0 引言
模板匹配是计算机视觉领域的一种经典算法[1-2],在实际工业应用中用于目标定位。它的基本思想是仅凭模板图像的先验知识,在目标图像中找到与模板图像最相似的匹配区域,其匹配思路可以分为基于灰度[3]、基于特征点[4]和基于形状[5]。
基于灰度的方法[6-8]通过计算灰度的差异来估计模板图像和候选窗口的相似度,其中NCC 以及基于NCC的方法[9-10]在线性光照变化的场景有着广泛的应用。基于灰度的匹配方法思路简单,性价比较高,但是考虑目标旋转的情况后匹配时间会大大增长[11]。
基于特征点的方法如SIFT[12]、SURF[13]和BBS[14],该类方法以特征点作为匹配单元,不依赖于滑动窗口遍历,因此可很好地解决目标旋转、比例变化、变形等问题,但是匹配时的计算量和内存占用较大,而且实际工业应用中的目标大小和背景亮度都已经固定,所以这类方法一般不会成为工业目标检测的首要考虑。
基于形状的方法[15-16]通过提取模板的轮廓得到形状信息,在匹配中以形状为单位进行相似度计算来实现匹配[17],这类方法在边缘特征明显的模板匹配任务上有着很好的发挥[18],但是这准确率非常依赖于线段拟合的结果和模板的类型,而且目标旋转也会影响匹配效果。
对工业于生产线上的模板匹配,如缺陷检测[19]和目标定位[20],最大的挑战是检测目标的旋转、匹配速度问题。为克服这些问题,本文提出一种基于局部方差和后验概率分类的快速模板匹配算法,实验结果表明,本方法在目标旋转的情况下能实现快速的目标定位,能够满足实时性和准确性要求。
1 提出的算法
本算法目标是实现具有旋转鲁棒性的快速模板匹配,可在检测目标发生任意旋转的情况下快速地计算出目标坐标和旋转角度。该方法主要思想是在预处理环节实现算法的旋转不变性,基于后验概率分类的窗口相关度计算方式使得滑动窗口不逐个像素遍历也能完成匹配。提出的模板匹配算法流程图如图1 所示,检测任务为实际工业生产线上的目标,选择的实例图像集具有较好的代表性,如图2 所示。

图1 算法流程图

图2 模板匹配任务
1.1 滑动窗口生成和划分
该部分包括滑动窗口的大小计算、不同移动步长的滑动窗口的生成以及正负样本的划分。滑动窗口的大小由式(1)得出:
其中,w、h分别表示初始模板图T(x,y)的宽和高,先计算平方和后再开方可以得出模板图像的对角线R。以R作为滑动窗口的宽W和高H能保证检测目标在发生旋转后依旧能被包含在窗口中。在原始图像以模板T(x,y)为中心建立宽为W、高为H的新模板图像Tex(x,y),后续的预处理以Tex(x,y)为模板,如图3 所示。
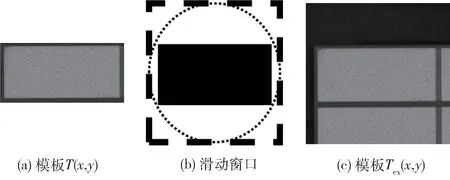
图3 滑动窗口和模板图像的扩大
在原始图像上分别构建以单个像素为移动步长和S个像素为移动步长的滑动窗口,前者在预处理中使用,后者作为匹配过程中的候选窗口。S的取值决定匹配过程的计算量,综合考虑匹配准确度和速度,检测用的滑动窗口移动步长S设置为4~6 为佳。
在模板所在图像上,分别计算以单个像素为移动步长的滑动窗口和Tex(x,y)的重叠度。重叠度大于阈值θ的滑动窗口作为正样本窗口,其余为负样本窗口。重叠度阈值θ的取值和检测时使用的滑动窗口移动步长S相关,如式(2)所示。
其中滑动窗口的移动步长S越大则检测过程中的候选窗口间距就越大,重叠度阈值θ就越小。θ的取值保证了Tex(x,y)周围一定范围内的滑动窗口都划分为正样本加入训练。
1.2 局部方差分类的准备
图像的方差反映了图像的对比度,对比度越高,方差越大。在这一部分中,局部方差的计算范围是滑动窗口内图像的中心区域,这是为了避免在滑动窗口中出现过多的背景从而影响方差值大小。
在预处理中,使用上一个环节中划分的正样本窗口计算出局部方差分类阈值。首先对所有正样本窗口内图像做一个0~90°范围的旋转,之后分别统计图像中心区域的方差值。其中所有正样本内图像计算得到的最大和最小的方差值将作为局部方差分类的阈值区间。方差的计算如式(3)所示。
在检测过程中,先计算检测图像的积分图和平方积分图。之后使用积分图和平方积分图计算候选窗口内图像的局部方差,再判断方差是否在方差阈值区间内。方差值不在区间范围内的候选窗口则不存在目标。
1.3 基于梯度的稳定特征点对的提取
这部分主要包括模板区域的划分、低梯度区域稳定特征点PL的筛选以及高梯度区域稳定特征点PH的筛选,流程图如图4 所示。

图4 稳定特征点对筛选的流程图
首先在模板图像Tex(x,y)上划分多个区域,以Tex(x,y)在每个区域的梯度的平均值作为划分的依据,区域被分为高梯度区域和低梯度区域,如图5(a)所示。之后在低梯度区域和高梯度区域分别筛选特征点对PL、PH,特征点的数量是根据后验概率分类模块的特征位数和特征数量决定的。

图5 稳定特征点对的筛选过程
特征点PL的筛选是在每个低梯度区域中筛选均匀分布的坐标点,每个区域筛选的坐标点数量是所需的特征点数量除以低梯度区域数量,以区域为单位来筛选特征点是为了让特征点能均匀分布在模板图像上。低梯度区域内的坐标灰度变化小,所以特征点PL的筛选可以在区域内随机取点,如图5(b)所示。
特征点PH的筛选是在每个高梯度区域中筛选固定数量的特征点,筛选的特征点数量和特征点PL数量一样。在高梯度区域中筛选的特征点按照以下标准:坐标点周围的梯度较小且和特征点PL灰度差较大,如图5(c)所示。特征点PH的筛选优先考虑周围梯度小的特征点是因为这些点周围灰度稳定,即使这些特征点的坐标偏移几个像素,它们的灰度变化的概率也会很小。考虑灰度差大的坐标点,是因为窗口特征是通过PL和PH的特征点的灰度对比来生成数字编码特征。
最后将基于模板图像T(x,y)的特征点PL和PH的坐标转化为基于滑动窗口大小的模板图像Tex(x,y)的相对坐标,如图5(d)所示。
1.4 基于稳定特征点的窗口特征提取
窗口特征的提取在预处理中使用滑动窗口和特征点实现,其中滑动窗口是第一个部分划分的正样本窗口和负样本窗口,特征点是第三个部分筛选的基于滑动窗口的特征坐标点PL和PH。此处的特征是对比滑动窗口内图像的特征点对坐标的灰度值来得到的,如式(4)所示。
其中,Featurei,j表示的是第i个特征的第j位编码,G(PL)和G(PH)分别表示的是窗口内图像上特征点PL和PH的灰度值大小。
筛选的特征点对的数量是由后验概率分类模块中的特征位数和特征数量决定的。本实验案例将特征位数设置为13、特征数量设置为10,即两组特征点PL和PH各有130 个特征点。通过对比窗口内图像PL和PH特征点的灰度大小可以组合得到10 个13 位的二进制编码,考虑到内存占用将二进制编码转为十进制编码进行存储,即每个窗口可以得到10 个十进制编码作为特征。
预处理中提取的窗口特征包括了初始角度的正样本特征、多角度的正样本特征和负样本特征:初始角度正样本特征的提取是直接在初始图像上使用划分后的正样本滑动窗口,把滑动窗口内的图像一一裁剪出来,之后对比裁剪图像上PL和PH两组特征点的灰度大小生成滑动窗口的特征,如图6 所示。
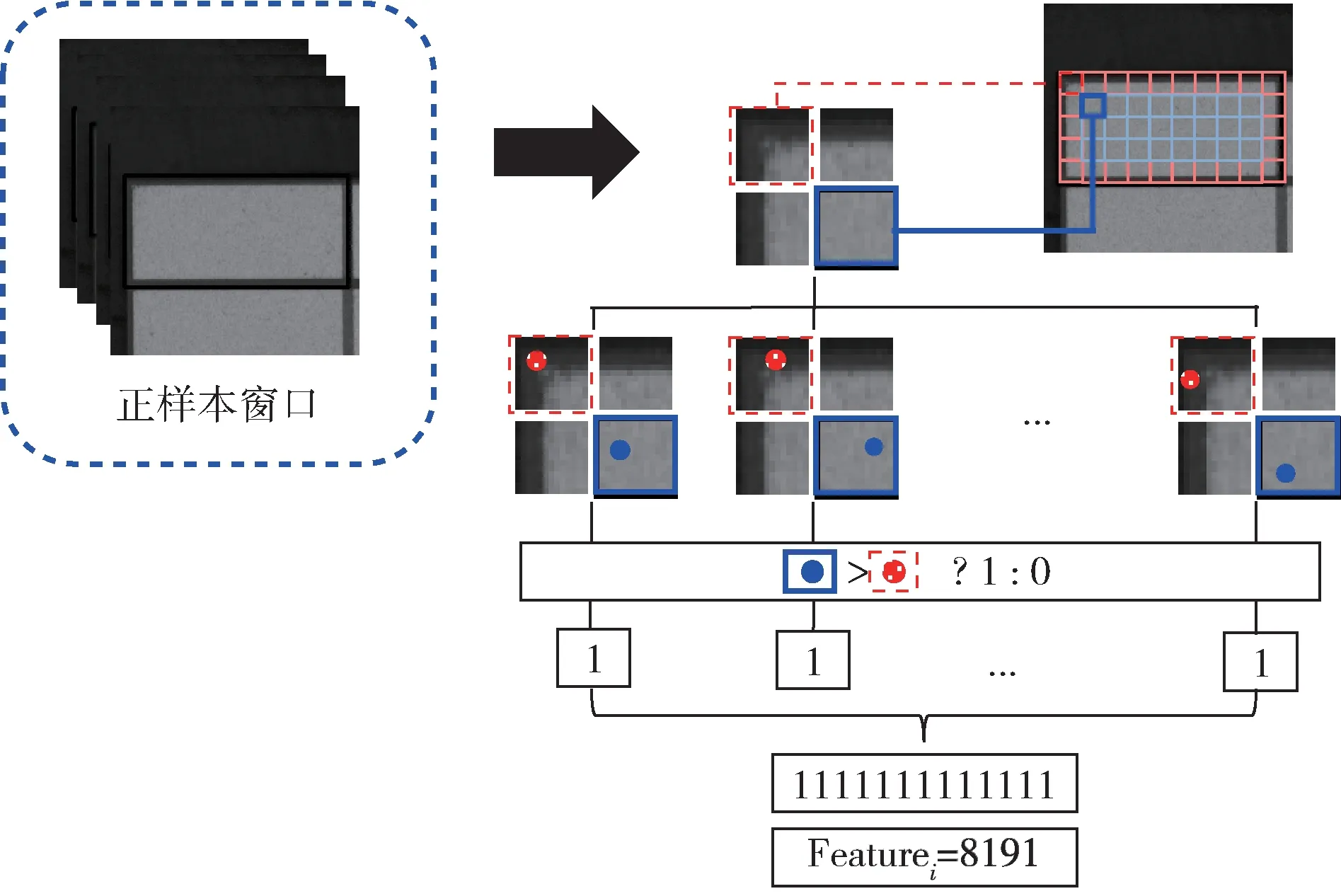
图6 正样本特征提取过程
多角度的正样本特征的提取会先旋转初始图像再裁剪出滑动窗口内图像,旋转的中心是正样本滑动窗口的中心点。其中旋转图像后裁剪正样本滑动窗口等同于对模板以及模板周边进行旋转,此时提取的特征是模板旋转后的特征,如图7(a)所示。负样本特征的提取是根据负样本滑动窗口内图像的局部方差来决定是否提取特征。因为局部方差不在阈值范围内的负样本在检测过程中会先被局部方差模块给过滤掉,避免了后验概率分类模块训练无用的特征。负样本特征的提取过程如图7(b)所示。
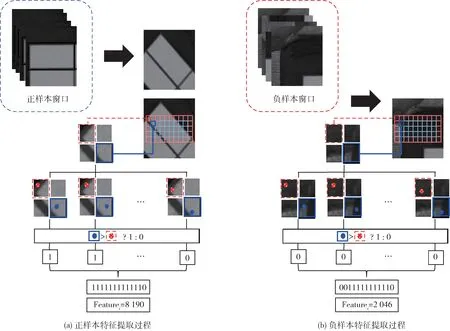
图7 多角度正样本特征和负样本特征提取
1.5 后验概率分类模块的训练和修正
后验概率指已知“结果”信息后再对信息的概率修正,已知的“结果”信息是在预处理过程中提取的正负样本窗口特征,信息的概率即特征所属的窗口存在目标的概率。每个特征对应的后验概率计算如式(5)所示:
其中,P(Positive|Featurei)表示的是提取出Featurei的窗口属于正样本的概率,num(Featurei,Positive)和num(Featurei,Negative)分别表示已经提取出Featurei的正样本和负样本数量。
后验概率分类模块的训练会打乱正负样本特征,之后根据特征的归属统计特征值对应正负样本数量。窗口相关度计算的实质是累加代表窗口的每个数字编码特征所对应的属于正样本的概率,所以后验概率的训练就是统计每个特征值属于正样本的概率,如图8 所示。
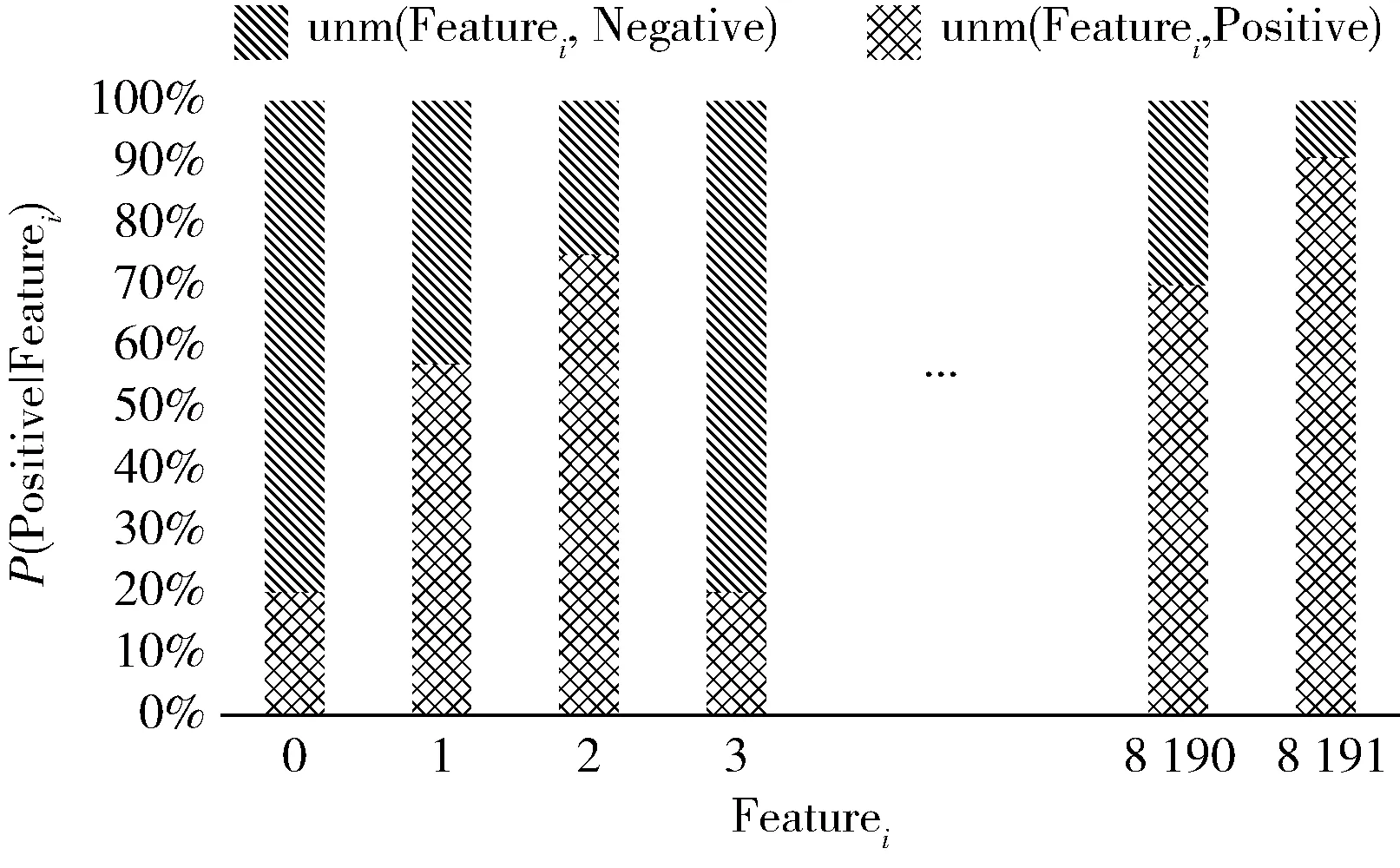
图8 后验概率分类模块的训练
后验概率分类模块的修正是对模块的完善,在正负样本特征中随机各抽取一半作为测试集。以负样本特征测试集中最大的后验概率作为模块的概率阈值,之后判断正样本特征测试集的后验概率是否大于概率阈值,如果小于阈值则训练该正样本特征,直到特征对应的概率超过概率阈值。其中负样本测试集是为了得到能排除大部分负样本特征的阈值,正样本测试集是为了保证正样本特征对应的概率能大于阈值然后通过模块检测。
1.6 旋转角度的判断
局部稳定特征点对PL和PH在模板图像上它们周围的梯度变化是所处的区域中最小,因此以窗口内局部稳定特征点对PL和PH的灰度为标准判断目标的旋转角度。预处理时将特征点对PL和PH的坐标点围绕窗口中心作多次旋转,存储每次旋转后的特征点坐标,如图9所示。检测过程中使用每个角度旋转的特征点灰度匹配得到检测目标的旋转角度,最后根据角度将候选窗口缩放到原始模板大小和对应角度。

图9 稳定特征点对的旋转结果
2 匹配过程
在匹配过程中,使用预处理环节构建的移动步长为S的滑动窗口作为候选窗口,首先在检测图像上构建积分图和平方积分图,计算候选窗口内图像的局部方差,过滤掉局部方差不在阈值区间范围内的候选窗口。使用预处理得到的特征点对PL和PH提取窗口特征并计算后验概率,后验概率大于阈值的候选窗口进行角度判断。最后根据角度大小将候选窗口缩放为模板大小。匹配结果如图10 所示。

图10 匹配结果
3 实验
为评价本方法在各种旋转条件下的匹配精度和匹配速度,将分别在多目标的检测任务和单目标的检测任务中进行测试。使用多种数据集和它们的旋转图像共计1 300 张测试图像,如图11 所示。

图11 部分测试图像
该算法的性能在匹配精度和速度上进行评估。若检测得到窗口和真实的窗口的重叠度大于0.9 则判断为匹配成功,匹配精度由匹配成功的图像数量除以总图片数量。匹配时间是所有图像的匹配时间的平均值。
多目标的检测任务中的测试图像使用的是实际工业生产线上的数据集,图像分辨率为1 024×750。本文提出的方法将与Improved-FDCM[18]、NCC&HU[10]方法比较,结果如表1 所示,对于原始图和旋转图,本方法匹配准确率达到了工业要求,且相较其他方法速度更快。
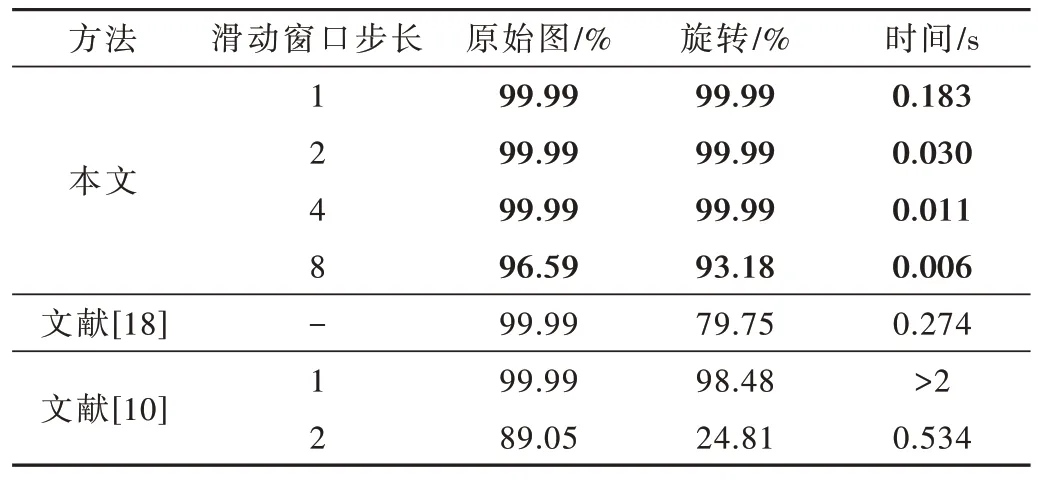
表1 算法在多目标匹配任务的对比结果
单目标的检测任务中使用的搜索图像分辨率为640×480,包括Halcon 的公开测试图像和在COCO 数据集上随机筛选的图像。将本方法与Sub-NCC[11]、Improved-SSDA[9]在这些图像上比较,在单目标的定位上不做角度判断直接进行定位。结果如表2 所示,本方法在应对目标旋转的匹配任务时速度较快,准确度较高。

表2 算法在单目标匹配任务的对比结果
由实验结果可知,在多目标检测任务中目标和目标间是紧贴的,基于形状的方法匹配精度会受到旋转的影响。NCC 及改进方法不管在多目标和单目标检测任务都有匹配时间过长的问题,增加金字塔层数或增加滑动窗口的移动步长又会使精度受到影响。
4 结论
为实现生产线上的实时目标定位,本文提出了一种基于局部方差和后验概率分类的模板匹配方法,以解决生产线上目标旋转后匹配受影响的问题。基于后验概率分类的相关度计算方式使得能用尽可能少的候选窗口来完成匹配任务。后续研究可考虑设置自适应的滑动窗口移动步长和考虑目标尺度变化等,匹配的速度还可进一步提升。
