基于改进DEC的评论文本聚类算法
2023-09-27陈可嘉夏瑞东林鸿熙
陈可嘉, 夏瑞东, 林鸿熙
(1. 福州大学 经济与管理学院, 福州 350108; 2. 莆田学院 商学院, 福建 莆田 351100)
随着互联网上电商评论数量的激增, 已引起商家和企业的广泛关注. 获取在线电商评论有助于商家和企业更好地了解消费者真正的需求. 而这些存在于电商平台的评论文本通常是无标注的数据, 由人工从无标注的大量文本数据中获取信息非常困难且耗时[1]. 随着应用场景的多样化发展, 越来越多的文本数据需要更适用于特定场景的聚类划分[2]. 电商产品的评论也属于文本数据, 因此对于产品评论, 可进行无监督聚类分析以了解用户对产品具体信息的关注分布情况.
目前在关于文本聚类的研究中, 基于K-means的聚类是一种经典的无监督聚类算法, 通常可用于文本聚类任务中[3], 其对大部分数据都有较强的适用性, 并且计算简单高效. 张蕾等[4]利用改进的词频-逆文档频率算法并结合K-means++算法对科研机构发表论文数据进行了聚类应用分析; 朱枫怡等[5]利用K-means算法对故事等类型的文本进行了聚类应用分析. 但K-means算法也存在明显的局限性, 如需要预先给定最优聚类数目K值以及无法有效处理高维数据等. 对于如何解决局限性, Bejos等[6]提出了一种改进的快速分区聚类算法缓解无法有效处理高维数据问题, 以提高文本聚类效果; 张朝等[7]提出了一种K-means聚类最优匹配算法解决传统K-means算法对聚类初始点的选取和距离度量的计算异常敏感问题.
随着文本聚类技术的发展, 深度聚类的应用可提升聚类算法的性能. Hosseini等[1]提出了一种基于叠架构的Autoencoder, 可减少数据的维度以提供强大的聚类特征. 同时, 深度嵌入聚类已成为无监督聚类的主要方法[8], Xie等[9]提出的深度嵌入聚类(deep embedding clustering, DEC)算法, 将训练数据从高维空间到低维特征空间映射, 并在其中迭代优化聚类目标; Ren等[10]使用了一种新的半监督深度嵌入聚类方法, 其在特征学习过程中加入了成对约束, 使得在学习到的特征空间中属于同一簇的数据样本彼此靠近, 而属于不同簇的数据样本彼此远离; Boubekki等[8]提出了在深度嵌入聚类算法上进行自动编码器与聚类的联合学习和嵌入, 保证前者可从后者获得的有价值信息中受益; 黄宇翔等[11]提出了基于集成学习的改进深度嵌入聚类算法以及其对超参数λ的敏感性.
在文本聚类研究中, 使用预训练词向量模型获取词向量是必不可少的部分, 对于预训练词向量模型, BERT(bidirectional encoder representation from transformer)模型相比于Word2vec和Glove等模型可以得到考虑词上下文信息且适用性广泛的词向量, 同时还能在具体任务中动态优化词向量[12]. 在针对主题分布与词嵌入信息相融合的问题上, Liang等[13]提出了结合BERT和LDA(latent dirichlet allocation)主题模型以确定主题最佳分类数; 文献[14]提出了利用LDA模型、 词嵌入模型Word2vec和Glove综合获得文本向量表示. 针对BERT预训练模型在聚类任务中的应用, Hosseini等[1]提出了先使用改进的预训练BERT模型进行文本的向量表示, 然后进行聚类分析; Mehta等[15]提出了基于BERT模型派生词嵌入的聚类方法对大型文本数据集进行聚类研究; Subakti等[16]使用了多种聚类算法, 包括K-means聚类、 深度嵌入聚类和改进的深度嵌入聚类等融合BERT得出的文本数据表示进行聚类研究.
但在评论的无监督聚类工作中, DEC算法的K-means聚类层可能仍存在聚类数目K需要预先给定的情况, 以及聚类中心的初始化有很强的随机性会影响整个DEC算法效果; 同时在预训练词向量工作中, 较少考虑到评论中词上下文信息与评论中主题特征的融合.
针对上述问题, 本文提出一种基于改进DEC的评论文本聚类算法, 该算法结合了BERT和LDA模型作为预训练词向量嵌入, 有效融合了句子嵌入向量和评论主题分布向量; 在K-means聚类层中, 通过主题连贯性的变化选择合适的主题数作为聚类数目K, 同时将LDA模型得出的主题特征向量作为自定义聚类中心, 然后进行联合训练以增强聚类的准确性.
1 聚类算法设计
本文基于改进DEC的评论文本聚类算法流程如图1所示, 其中包括: 数据集获取与预处理; 基于BERT-LDA的数据集向量化表示; 改进DEC算法; 评论文本聚类可视化分析.
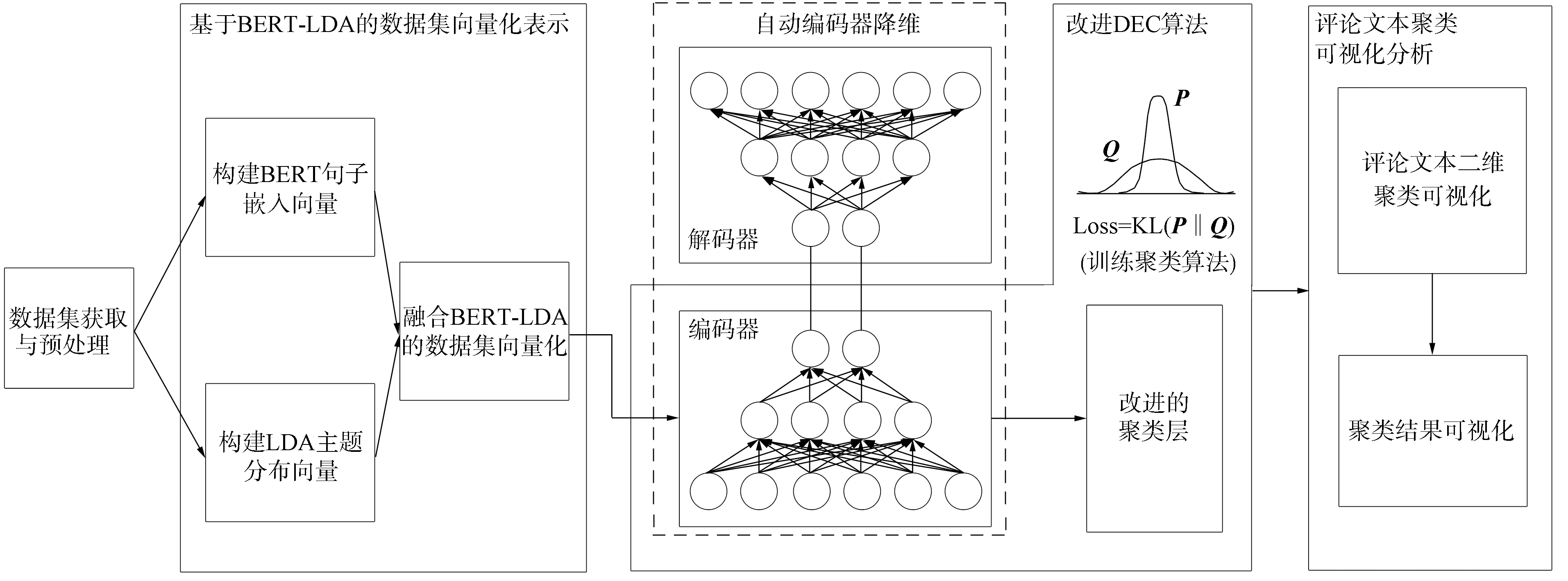
图1 基于改进DEC的评论文本聚类算法Fig.1 Review text clustering algorithm based on improved DEC
1.1 数据集获取与预处理
本文使用Python从天猫商城(www.tmall.com)和京东商城(www.jd.com)中进行评论数据集爬取, 以此进行后续的产品评论聚类分析. 对于获取的产品评论文本数据需要做如下预处理.
1) 重复数据剔除: 将重复的无效数据进行剔除.
2) 去停用词: 停用词通常在评论中大量重复出现, 却没有实际意义, 例如: “嗯、 了、 即、 不但、 终于”等, 将停用词进行剔除以获得更有效的评论句.
1.2 基于BERT-LDA的数据集向量化表示
本文利用获取的无标注评论数据集进行基于BERT-LDA的数据集向量化表示, 主要流程如下: 1) 构建BERT句子嵌入向量; 2) 构建LDA主题分布向量; 3) 融合生成BERT-LDA数据集向量化表示.
1.2.1 构建BERT句子嵌入向量
本文通过谷歌开源工具包BERT 模型训练产品评论数据集上的句子嵌入向量表示. BERT 模型具有很强的文本特征表示能力[16-17], 如图2所示.
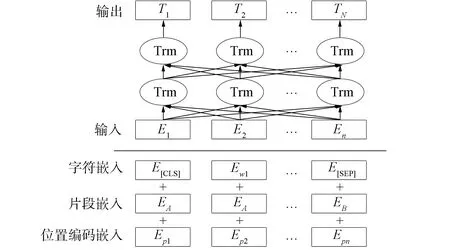
图2 BERT模型Fig.2 BERT model
输入包括3部分, 分别为位置编码嵌入、 片段嵌入和字符嵌入. BERT的核心模块是Transformer块[18], 每个Transformer 共有12个注意力头, 其隐含层大小为768.
本文使用开源的BERT-as-service工具加载预训练模型, 将预处理后数据集中的句子进行编码后, 取输出层字向量的平均值作为句子的句向量. 将BERT句子嵌入向量Di定义为
Di=MEAN(T1,T2,…,Tn),
(1)
其中T1,T2,…,Tn表示输出层的字向量.
1.2.2 构建LDA主题分布向量
LDA主题模型用于推测文档的主题分布, 它可以将文档集中每篇文档的主题以概率分布的形式给出. LDA主题模型认为一个文档由若干主题组成, 主题由数据集下相应的特征词构成, 则可以描述对应为m个文档中, 具有n个特征词,z表示为n个特征词所对应的主题. LDA主题模型如图3所示.
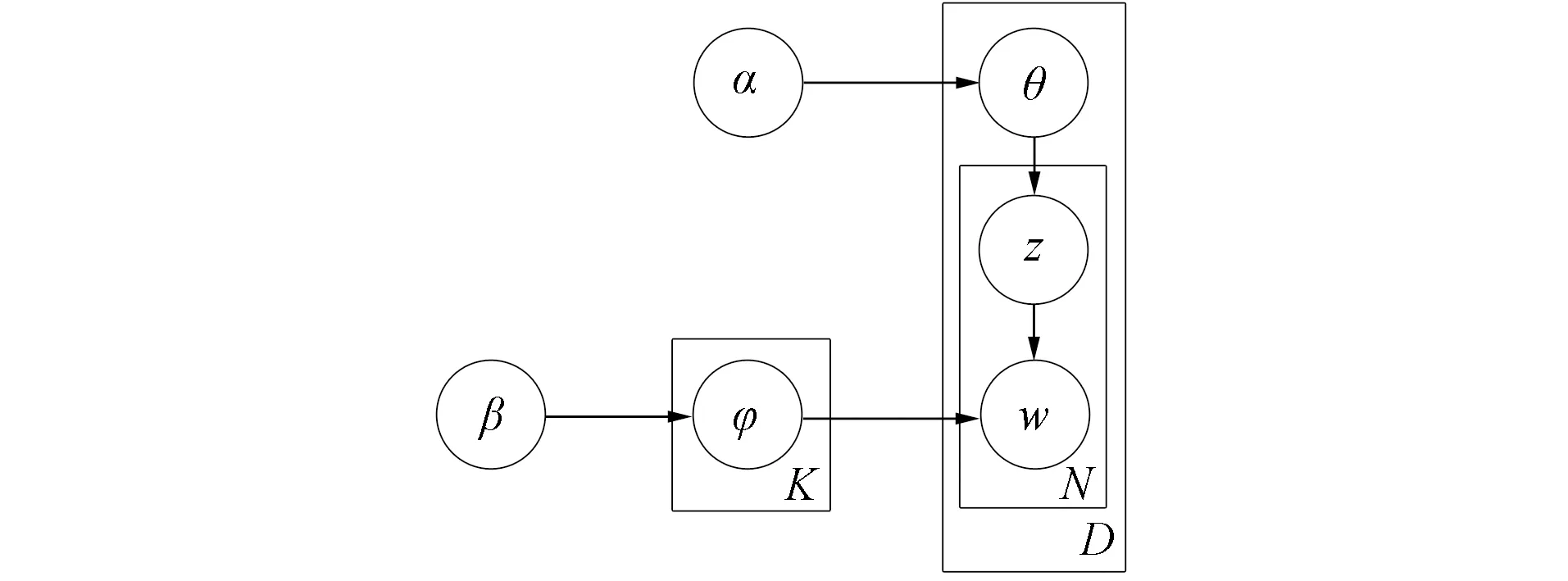
图3 LDA主题模型Fig.3 LDA topic model
LDA主题模型中各参数的含义如下:α表示评论-主题分布中的Dirichlet分布超参数;β表示主题-词分布中的Dirichlet分布超参数;D表示评论总数;N表示评论中总的词语数量;K表示主题数;θ表示评论-主题分布;φ表示主题-词分布;z表示评论中词语对应的主题;w表示评论中的词语.
LDA主题模型的联合分布定义为
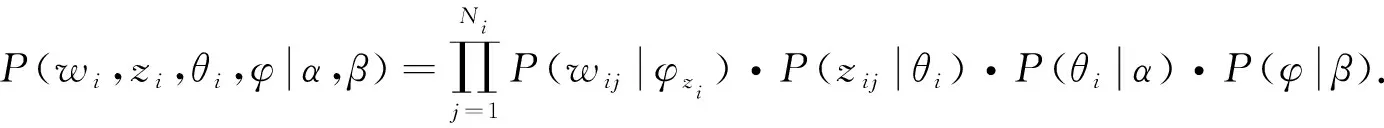
(2)
利用Gibbs Sampling算法进行参数估计, 迭代抽样直到收敛, 用公式表示为
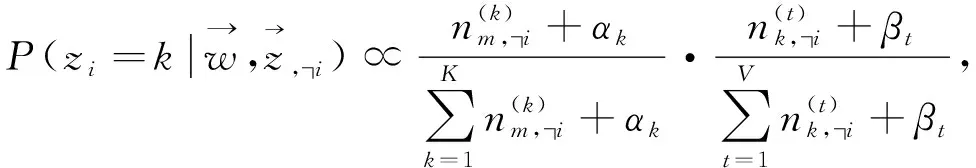
(3)
1.2.3 融合BERT-LDA的数据集向量化
根据构建的BERT句子嵌入向量和LDA主题分布向量, 采用向量拼接融合的方式, 将得到新表达的向量输入[14]. 这种新的输入向量, 既包含了评论的句子整体语义特征, 又包含了评论所具有的主题特征. 定义融合BERT句子嵌入向量和LDA主题分布向量的文本向量化表示Di,μ为
Di,μ={Di∘μ},
(4)
其中∘为向量拼接符号.
1.3 改进DEC算法
根据得到的基于BERT-LDA的数据集向量化表示进行评论数据集的聚类任务. 考虑到拼接后的向量存在高维稀疏的问题, 同时原始DEC算法的K-means聚类层存在需要预先给定初始聚类数目K值以及初始聚类中心具有随机性等问题. 本文使用改进的DEC算法, 主要包括: 1) 自动编码器降维, 以学习无标签数据集高维向量降维后的特征表示; 2) 改进聚类层, 在编码器后堆积K-means聚类层, 以分配编码器输出到一个聚类组, 基于主题连贯性选择初始聚类数目K, 同时使用LDA主题特征向量ω作为初始聚类中心; 3) 训练聚类算法, 以同时改善聚类层和编码器.
1.3.1 自动编码器降维
自动编码器是一种无监督式的特征降维方法, 其由两部分组成, 分别为编码器(Encoder)和解码器(Decoder), 编码器和解码器均包括输入层、 输出层和隐藏层3层神经网络结构.
自动编码器通过编码器提取高维特征并降维处理输出文本特征, 解码器通过对称的网络结构, 对编码器的输入进行重构. 针对需要不断进行迭代训练调整自编码器网络结构参数的过程, 训练过程将均方误差(mean square error, MSE)[19]作为相应的损失函数, 以此获取精确的低维度特征信息. 自编码器中编码器和解码器过程可用公式表示为
Zi=f1(WeDi,μ+be),
(5)
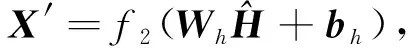
(6)
其中Zi为编码器提取的高维特征并降维处理输出后的文本特征,X′为解码器通过对称的网络结构对编码器的输入进行重构的结果,We和Wh是权重矩阵,be和bh是偏置向量,f1和f2是映射函数.
1.3.2 改进的聚类层
原始DEC算法中, 聚类层存在需要人工给定聚类数目K值和初始聚类中心具有随机性从而影响聚类效果的问题.
首先, 聚类数目K等价于一个确定主题建模中主题数量的参数, 因此从LDA主题模型到K-means有一个自然的联系. 基于此, 本文使用主题连贯性的变化确定最合适的主题数, 以此作为K-means聚类层的聚类数目K. 主题连贯性主要用于衡量一个主题内的词是否是连贯的. 随着主题数量的变化, 主题连贯性得分也逐渐变化, 因此利用主题连贯性的变化进行主题数选择时, 最合适的主题数目是当主题连贯性最大时所对应的主题数.
采用的主题连贯性计算方法为: 先基于滑动窗口, 对主题词进行One-Set分割(一个Set内的任意两个词组成词对进行对比), 再使用归一化点态互信息(normalized pointwise mutual information, NPMI)[20]和余弦相似度[21]间接获得连贯度. 其取值范围为[0,1], 用于衡量同一主题内的特征词语义是否连贯, 其数值越高模型效果越好[22]. 归一化点态互信息的计算公式为
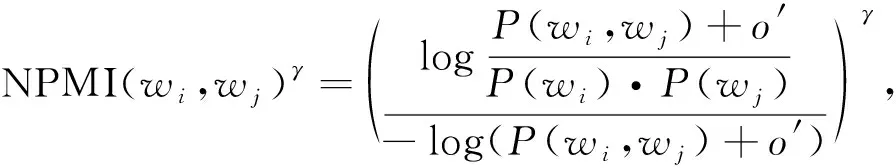
(7)
其中:γ为设置的权重;P(wi,wj)表示包含wi,wj的文本与全部文本的比值;o′表示平滑因子, 是为了在计算中保持数值稳定性并避免零概率问题.
其次, 考虑初始聚类中心存在随机性的问题, 使用LDA模型得出的主题特征向量ω作为初始聚类中心可有效反映其文本主题的划分信息, 同时可避免K-means聚类层随机选择聚类中心而影响聚类效果. 其步骤如下:
1) 使用主题特征向量ω作为初始聚类中心ω=(ω1,ω2,…,ωK), 其中K为聚类数目;
2) 计算每个样本数据Zi与K个聚类中心的距离, 将其划分到距离最近中心点所在的簇中;
3) 重新计算每个簇中所有数据对象的平均值, 将其作为新的簇中心ω′, 用公式表示为
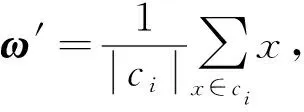
(8)
其中ci为每个簇中的数据对象;
4) 重复步骤2)和步骤3), 直到簇心不发生改变或达到最大迭代次数.
使用基于主题连贯性选择的聚类数目K, 并使用主题特征向量ω作为初始聚类中心的聚类层流程如图4所示.
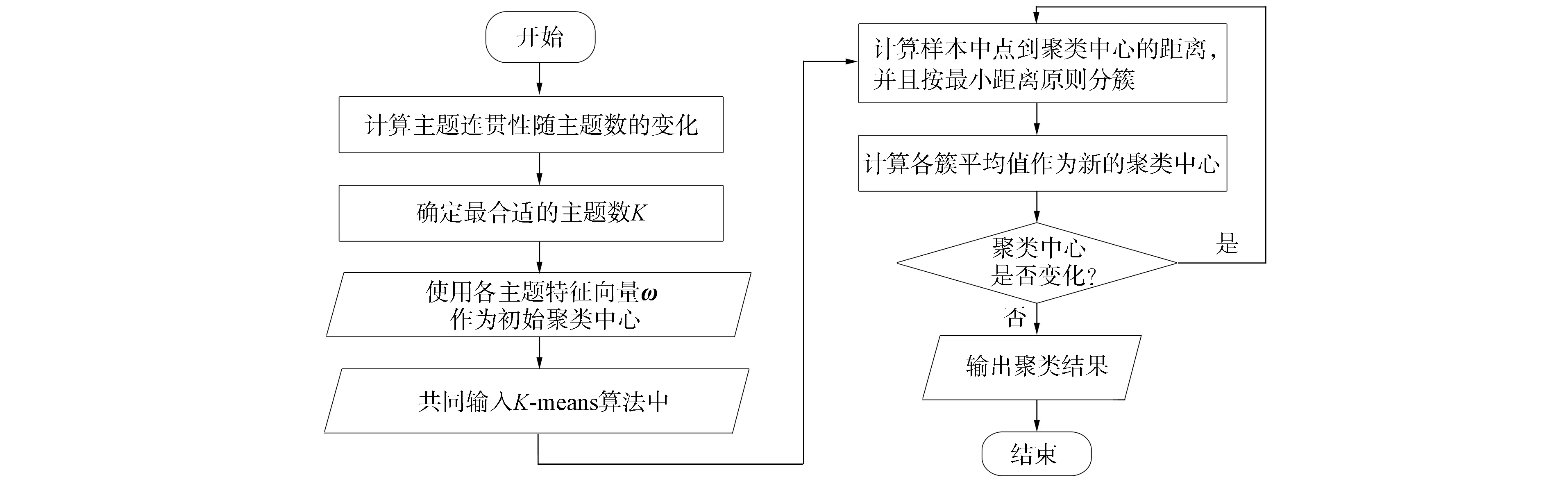
图4 聚类层的聚类流程Fig.4 Clustering process of clustering layer
1.3.3 训练聚类算法
经过自动编码器进行参数初始化得到降维后的潜在特征空间的文本特征Zi后, 预训练编码器后堆叠聚类层, 从而形成聚类算法.为同时提升聚类和特征表示的效果, 利用聚类结果优化编码器和聚类算法的参数, 进行聚类算法的训练.因此本文将计算辅助目标分布, 并根据算法聚类结果最小化KL(Kullback-Leibler)散度[9], 其流程为: 1) 每个样本点属于簇的概率得到样本点的概率分布Q; 2) 使用辅助目标分布从当前高置信度分配中学习优化聚类质心.重复该过程直到满足收敛条件.训练聚类算法的步骤如下.
1) 计算每个样本点i属于簇j的概率qij, 用公式表示为
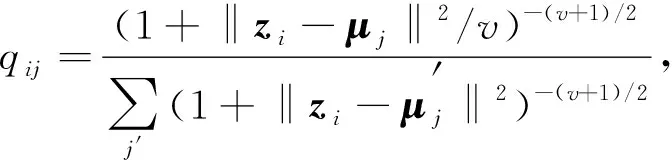
(9)
得到样本点的概率分布Q, 其中:zi表示样本点的特征向量;μj表示簇心向量;v是t分布的自由度, 由于无法在无监督环境中对验证集上的v进行交叉验证, 并且学习它是多余的[23], 因此本文将其取值为1.
2) 目标分布应该具有以下属性: 加强预测, 提升聚类精度; 更关注于高置信度的数据样本; 避免大聚类组干扰隐藏特征空间.因此本文使用文献[9]提出的辅助目标分布P=(pij), 计算公式为
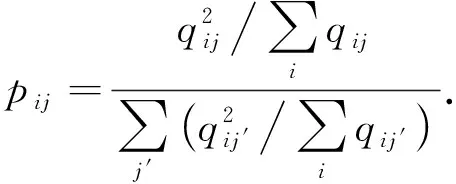
(10)
3) 联合训练编码器和聚类层.本文采用KL散度作为损失函数训练模型度量两个分布Q和P之间的差异, 计算公式为
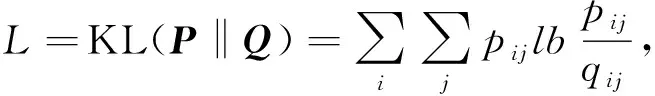
(11)
其中qij是样本点i属于簇j的估计概率值,pij是样本点i属于簇j的近似概率值.
1.4 评论文本聚类可视化分析
1.4.1 评论文本二维聚类可视化
UMAP(uniform manifold approximation and projection)是一种数据降维可视化工具, 具有优越的运行性能和可扩展性, 同时在可视化质量方面保留了更多的全局结构[24]. 因此, 本文使用UMAP工具对聚类后的数据集主题进行可视化展示.
1.4.2 聚类结果可视化
UMAP获取可视化聚类结果后, 使用词云图可以对文本数据中出现频率较高的关键词予以视觉上的突出, 形成“关键词的渲染”, 从而过滤掉大量的文本信息. 因此, 本文同时选取每个主题下高频的主题词进行词云图可视化分析, 以达到更直观的聚类结果展示.
1.5 本文算法设计
本文基于改进DEC的评论文本聚类算法的整体步骤如下.
算法1基于改进DEC的评论文本聚类算法.
输入: 经过预处理后的数据集En;
输出: 聚类可视化结果;
步骤1) 将En输入BERT模型, 根据式(1)得到BERT句子嵌入向量Di;
步骤2) 将En输入LDA模型, 根据式(2)和式(3)得到主题分布向量μ和主题特征向量ω;
步骤3) 根据式(4)获得融合BERT-LDA的数据集向量Di,μ;
步骤4) 配置自动编码器的优化器参数及迭代参数;
步骤5) 根据式(5)进行自动编码器训练, 得出降维后的向量特征表示;
步骤6) 配置聚类算法的优化器参数并定义损失函数;
步骤7) 根据式(7)进行主题连贯性选择初始聚类数目K;
步骤8) 用主题特征向量ω作为初始聚类中心, 根据式(8)进行K-means初始聚类;
步骤9) 根据式(9)计算每个样本点i属于簇j的概率分布Q;
步骤10) 根据式(10)计算辅助目标分布P;
步骤11) 定义算法训练的初始损失值、 迭代参数及终止条件;
步骤12) 采用KL散度根据式(11)进行辅助目标分布P的更新, 度量两个分布Q和P之间的差异;
步骤13) 检验终止条件;
步骤14) 使用UMAP和词云图输出聚类可视化结果.
2 实验及分析
2.1 实验数据集
聚类分析是指应用数学方法按照数据间的相似性进行划分的过程[25]. 针对目前电商产品中的在线评论文本多是无标注的数据, 而要从相应的评论数据集中获取有用信息, 就需要进行相应的评论聚类以获取用户对产品进行评论的情况. 使用本文基于改进DEC的评论文本聚类算法对电商产品手机的评论数据集进行聚类, 并进行聚类结果可视化分析. 本文选取天猫商城(www.tmall.com)和京东商城(www.jd.com)中的华为手机评论数据作为实验研究数据, 利用Python软件爬取购买华为手机用户对相关手机发表的在线产品评论. 爬取的手机型号是目前该品牌热销的旗舰款手机, 如mate40,mate40pro,p40,p40pro等. 其中包含19 869条初始数据.
通过对获取的产品评论数据集进行重复剔除, 如出现的多条“此用户没有填写评论!”等, 同时去除出现较多但与评论聚类无关的停用词, 得到12 289条进行实验的评论数据. 数据集示例列于表1.

表1 数据集示例Table 1 Examples of datasets
2.2 实验环境及参数设置
2.2.1 实验环境
实验的运行环境: 基于Windows10操作系统, 处理器为i5-10500H, 16 GB内存; 算法使用Python3.7编程语言实现, 编码工作通过Pycharm开发工具完成, 主要使用的库有Gensim3.8.1,keras2.3.1等.
2.2.2 实验参数设置
在进行自动编码器训练以及改进DEC算法训练时, 将epochs分别设为50,100,150,200,250个进行对照, 以评估其参数对算法结果以及训练时间的影响, 结果列于表2.

表2 设置不同epochs的运行情况Table 2 Operation status of setting different epochs
由表2可见, 当设置epochs为200和250时, 输出结果接近, 而运行250个epochs的时间远大于设置200个epochs. 因此自动编码器训练时, 设置批量处理大小batch_size=128, 学习率为0.001, 训练迭代epochs为200, 优化算法为Adam算法[26]. 同时, 在进行改进DEC算法训练时, 设置每200个epochs训练迭代更新目标分布, 优化算法为Adam算法, 损失函数为KL散度.
2.3 评价指标
根据是否需要外部信息, 聚类评价指标可分为外部聚类评价指标[27]和内部聚类评价指标[28], 外部评价指标旨在将聚类结果与预先确定的聚类结果进行比较. 而在无监督的聚类任务中, 通常并无预先确定的聚类结果, 因此内部评价指标更适用于无监督聚类评价. 聚类的轮廓系数和CH(Calinski-Harabaz)指标是推荐的聚类评价方法[29].
1) 轮廓系数是测量聚类簇内一致性的指标, 用于评价算法聚类效果的好坏, 其取值范围为[-1,1], 数值越高算法效果越好, 计算公式为
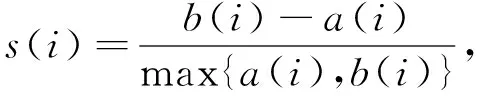
(12)
其中:a(i)表示样本点与同一簇中所有其他点的平均距离, 即样本点与同一簇中其他点的相似度;b(i)表示样本点与下一个最近簇中所有点的平均距离, 即样本点与下一个最近簇中其他点的相似度.
2) CH指标通过计算簇内各点与簇中心的距离平方和度量簇内的紧密度, 同时也通过计算簇间中心点与数据集中心点距离平方和度量数据集的分离度. CH越大表示簇自身越紧密, 簇与簇之间越分散, 即更优的聚类结果. 计算公式为
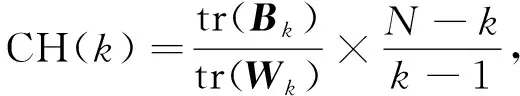
(13)
其中: tr(X)表示求矩阵X的迹;N为样本数;k为簇的数量;Bk和Wk分别计算组间协方差和组内协方差, 其计算式为
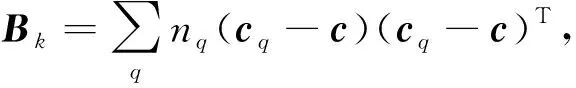
(14)
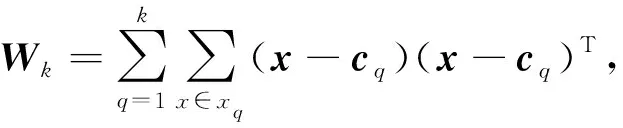
(15)
其中xq为簇q中所有数据的集合,cq为簇q的中心点,c为样本集合中心点,nq为簇q包含点的个数.
2.4 对比算法实验
将如下7种算法与本文算法在相应的数据集上进行对比实验, 分别进行5次实验, 其轮廓系数指标和CH指标结果列于表3.
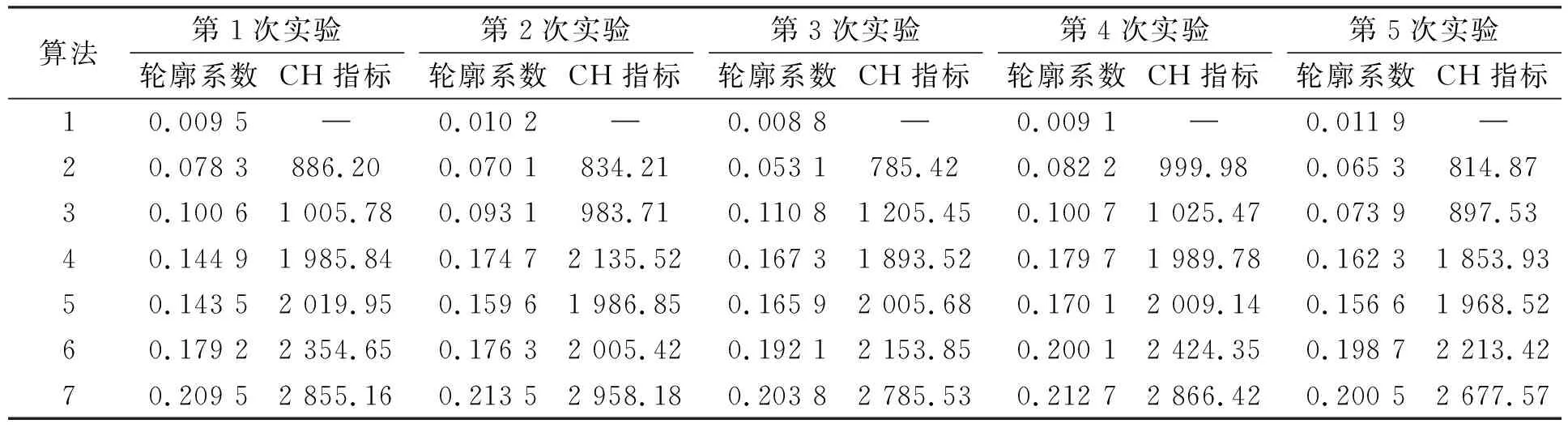
表3 不同算法的5次实验指标对比结果Table 3 Comparison results of 5 experimental indicators of different algorithms
1. TF-IDF+K-means: 是一种基线算法, TF-IDF获取词向量, 直接利用K-means聚类算法进行聚类.
2. Word2Vec+K-means: 是一种基线算法, Word2Vec获取词向量, 直接利用K-means聚类算法进行聚类.
3. BERT+K-means[15]: 该算法使用BERT模型得到相应的文本特征表示, 再利用K-means聚类算法进行聚类.
4. BERT+DEC[16]: 该算法使用BERT模型得到相应的文本特征表示, 再利用DEC聚类算法进行聚类.
5. BERTopic+AE+K-means[1]: 该算法基于BERT得到文本向量表示, 同时根据文档概率分布获得潜在主题, 再结合自动编码器与K-means进行数据的聚类.
6. BERT-LDA+原始DEC: 在本文基于BERT-LDA得到文本向量表示后, 结合未改进DEC聚类算法进行聚类实验.
7. BERT-LDA+改进DEC: 本文提出的聚类算法, 基于BERT-LDA得到文本向量表示, 再结合改进DEC算法对数据进行聚类.
由表3可见: 在算法1~算法3中, BERT+K-means的效果最好, 说明在评论的聚类中, 直接利用基于词频进行表示的聚类效果较差, 而通过大量语料进行预训练的BERT模型进行向量表示可有效提高后续聚类的能力; 由算法3分别与算法4和算法5之间的对比可见, 结合深度嵌入聚类进行训练比直接进行K-means聚类可以得到更优的效果; 同时可见, 在BERT模型的基础上加上Topic主题的融合训练进行聚类的效果更优; 算法6与算法7相比, BERT-LDA+改进DEC算法相对于BERT-LDA+原始DEC算法, 其轮廓系统与CH指标波动变化最大约为6%和10%, 而BERT-LDA+原始DEC算法中第2次实验和第4次实验的轮廓系统与CH指标分别有约14%和19%的变化, 因此BERT-LDA+原始DEC算法的聚类结果差别波动较大, 且可能存在聚类结果较差的问题, 而本文基于BERT-LDA+改进DEC算法, 轮廓系数在5次实验中结果均大于0.2, 且均优于未改进的原算法, 因此, 本文算法在指标更优的基础上也很好地改善了聚类结果差别波动较大的问题.
本文算法在指标结果上均优于其他对比算法, 说明本文提出的结合BERT-LDA进行向量表示以及结合改进DEC算法的有效性. 在无监督聚类中, 该算法的聚类簇内一致性更好, 同时该算法有更明显的簇内自身更紧密以及簇与簇之间更分散的效果.
2.5 实验结果与分析
首先采取向量融合的方式, 将得到的BERT句子嵌入向量与LDA主题分布向量进行拼接融合, 得到基于BERT-LDA的融合向量输入. 其中LDA模型得到的主题分布向量部分示例列于表4.

表4 主题分布向量部分示例Table 4 Some examples of topic distribution vector
其次进行改进DEC算法的构建, 利用自动编码器对上述的文本向量做向量降维, 再将编码器后堆叠聚类层, 其中使用LDA模型得出的主题特征向量ω作为初始聚类中心, 并且通过主题连贯性的变化选择最合适的主题数目K, 以此作为K-means算法的聚类数目K, 其主题连贯性随主题数的变化曲线如图5所示. 由图5可见, 当主题数为8时, 模型的主题连贯性最大, 因此可设置聚类的初始聚类数为8. 再输入主题特征向量ω作为初始聚类中心, 进行聚类算法的优化训练.
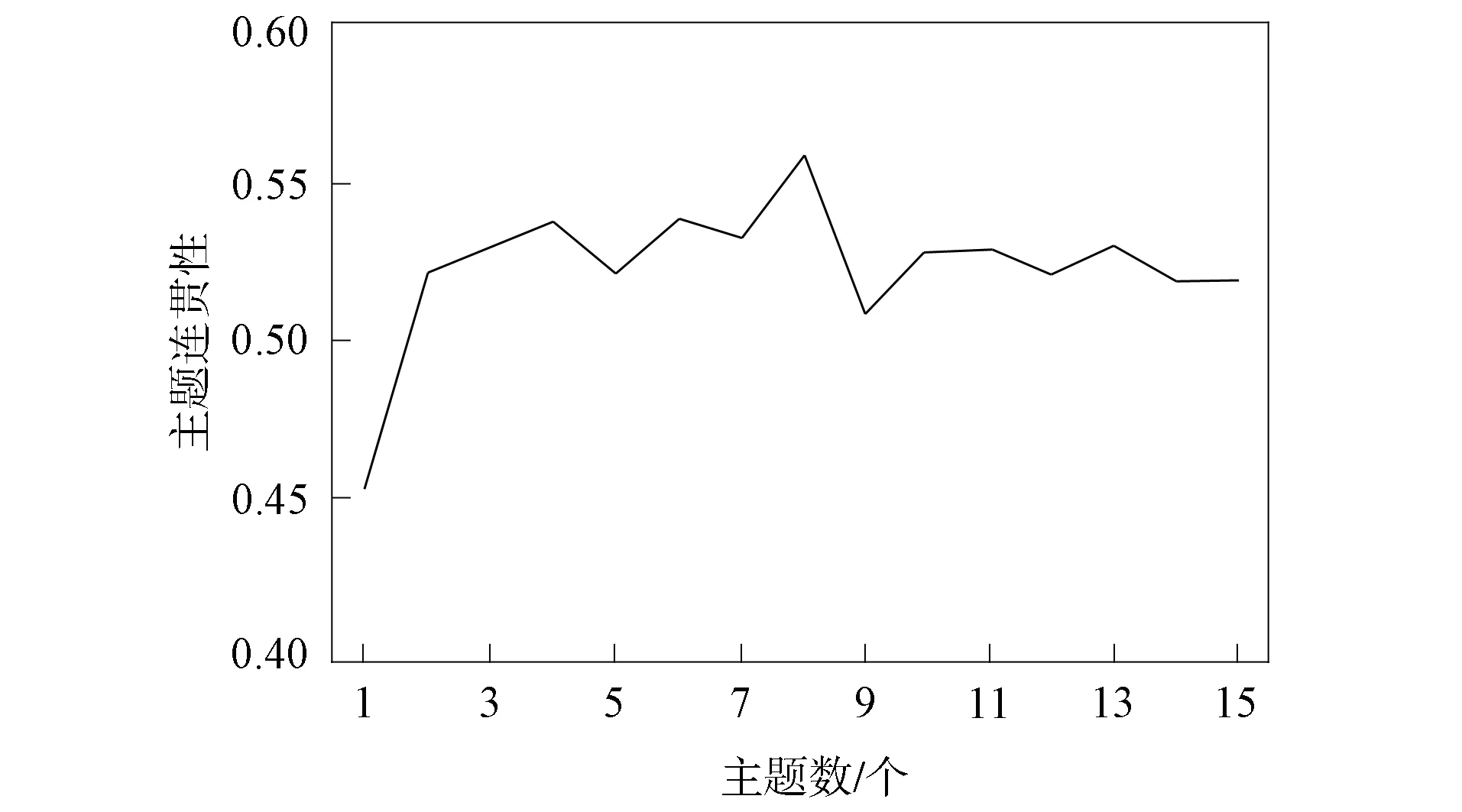
图5 主题数-主题连贯性变化曲线Fig.5 Change curves of topic coherence with number of topics
最后得到相应的聚类结果, 并利用UMAP工具进行聚类可视化效果展示. 产品评论文本聚类后的二维聚类可视化结果如图6所示.
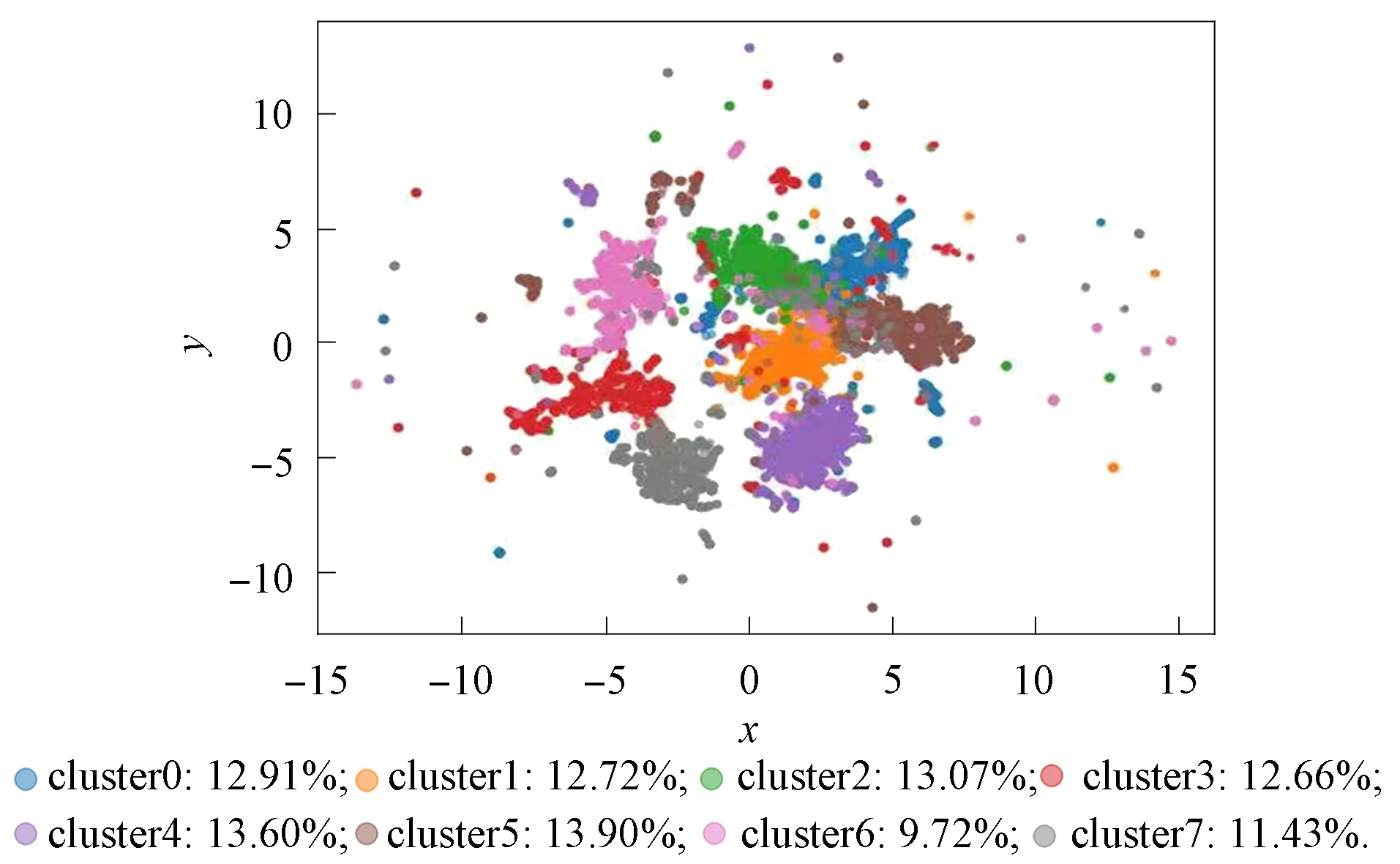
图6 二维聚类可视化Fig.6 Two-dimensional clustering visualization
由图6可见, 8个聚类的聚类效果可较明显地从可视化图中看出其划分情况. 其中cluster1,cluster3,cluster4,cluster5,cluster6和cluster7聚类簇之间被较明显的进行了划分; 而cluster0与cluster2之间存在一部分重合. 具体评论数据的聚类结果及其重合的情况可对聚类簇内的内容分析可得. 因此, 在8个聚类数目的基础上, 选择每个簇中评论高频词进行词云图可视化分析, 从而达到更直观的聚类结果展示. 得出的8个聚类结果的词云图展示如图7所示. 筛选出每个聚类簇中的关键词列于表5, 由此可得进行聚类后的各簇中所包含的评论具体信息.

图7 聚类结果的词云图展示Fig.7 Word cloud graph display of clustering results
由表5可见, 对手机评论进行聚类后, 得到的8个聚类簇的关键词结果可以有效体现用户对产品评论的聚类结果. cluster0中主要的关键词为拍照、 电池、 效果、 速度等, 而cluster2中的主要关键词也有拍照、 效果、 续航、 电池等. 其拍照和电池同时出现在一个簇内, 体现了用户在评论手机时, 通常将对拍照和电池的体验同时发表评论, 也在一定程度上体现了用户对拍照和电池方面的较高关注度. 这种情况也体现在二维聚类可视化图6中cluster0和cluster2之间存在一部分重合的情况. 在cluster1中出现较多的关键词为外观、 手感、 颜值等, 体现了该簇中包含的评论主要涉及用户在购买手机时对外观的关注情况; cluster3中出现较多的关键词为老爸、 家人等, 体现了该簇包含的评论主要涉及手机的使用者或购买对象的情况; cluster4中出现较多的关键词为京东、 物流等, 体现了该簇中包含的评论主要涉及购买手机的物流运输情况; cluster5中出现较多的关键词为屏幕、 使用等, 体现了该簇中包含的评论主要涉及用户在购买手机时对屏幕的关注情况; cluster6中出现较多的关键词为华为、 国货等, 体现了该簇中包含的评论主要涉及用户在购买手机时对品牌的考虑情况; cluster7中出现较多的关键词为系统、 鸿蒙等, 体现了该簇中包含的评论主要涉及用户在购买手机时对系统的关注情况.
综上所述, 本文提出了一种基于改进DEC的评论文本聚类算法对评论数据进行无监督聚类, 可以应用于在无标注的产品评论数据集中更好地获得用户对于手机进行评论的具体内容分布情况. 通过利用BERT获取句子向量表示以及LDA获得主题分布向量表示进而得到融合的数据向量表示; 进一步将其输入改进DEC算法中, 根据LDA模型可以得到主题连贯性的效果评价确定聚类的初始数目, 并使用主题特征向量作为自定义聚类中心; 同时在模型中计算样本点的概率分布Q, 再结合辅助目标分布P, 利用KL散度作为损失函数联合训练自动编码器的编码层和聚类层. 通过与对比算法在产品评论数据集上进行无监督聚类的比较, 结果表明, 本文算法在轮廓系数和CH指标上均高于对比算法, 同时其聚类结果稳定性也更好.
