基于对比学习思想的多跳问题生成
2023-09-27王红斌杨何祯旻王灿宇
王红斌, 杨何祯旻, 王灿宇
(1. 昆明理工大学 信息工程与自动化学院, 昆明 650500;2. 昆明理工大学 云南省人工智能重点实验室, 昆明 650500;3. 昆明理工大学 云南省计算机技术应用重点实验室, 昆明 650500;4. 云南农业大学 大数据学院, 昆明 650201)
问题生成(question generation, QG)是与机器阅读理解(machine reading comprehension, MRC)相关的一个自然语言处理任务[1-2]. 问题生成任务定义为: 给定一个文本描述和答案, 通过文本描述和答案生成内容相关、 语序通顺的问题. 问题生成可分为单跳问题生成和多跳问题生成. 单跳问题的答案出现在单一文档中, 且这类问题多数可通过对问题和单一文档使用关键词匹配的方式进行回答, 目前主流的阅读理解数据集SQuAD所提供的问题都是单跳问题. 使用单跳问答数据集的训练模型虽然在单文本阅读理解任务上表现较好, 但其无法评估需要多步推理能力的多文本阅读理解任务. 因此, 文献[3]构建了面向自然语言和多步推理问题的数据集HotpotQA, 该数据集是一个多文档、 多跳推理、 标注支持事实的同构数据集. 面向自然语言和多步推理问题的数据集HotpotQA提供了大量的多跳问答数据, 多跳问题的回答则需要定位多个信息来源并建模信息间的关系, 基于这些信息链进行多步推理和理解, 更接近于人类的思维. 因此, 本文主要考虑多跳问题生成研究.
现有的神经网络模型在单跳和多跳问答数据集上都表现较好[4-24], 但这些方法严重依赖于大规模的人工标注. 尽管当前有监督学习技术表现较好, 但人工标注大规模的多跳问答训练数据集成本过高. Pan等[4]提出的无监督多跳问题生成器MQA-QG作为第一个研究无监督多跳问题生成的模型, 初步实现了采用自动生成的多跳问题取代人工标注的多跳问题, 但其效果仍与人工标注的数据集有一定差距, 使用多跳问题生成器MQA-QG自动生成的数据训练问答QA模型的结果与使用人工标注的数据相比, EM值和F1值分别相差14.5和14.2, 因此还有较大的提升空间. 同时, 多跳问题生成器MQA-QG将两篇关联的文本分别生成单跳问题, 再将单跳问题融合生成多个候选多跳问题, 该方法虽然无需标注支持句, 但其生成的候选多跳问题不灵活且质量参差不齐没有进行有效筛选.
为解决该问题, 本文在生成任务中引入对比学习的思想, 提出基于对比学习思想的多跳问题生成方法, 通过将生成的候选问题与原文本进行对比, 并引入与参考问题的对比损失, 在一定程度上提高了生成问题的质量且无需标注支持句. 同时对生成的多跳问题集进行数据增强, 扩充后的训练集放入QA模型训练能得到更好的训练效果. 将本文方法在多文本同构数据集HotpotQA上进行实验, 实验结果表明, 所提出的基于对比学习思想的多跳问题生成方法不需要对支持句进行标注, 只需要一定的参考问题和对应的文档数据进行训练, 成功生成并有效筛选了质量较高的多跳问题集, 扩充了原始训练集, 极大减少了人工标注数据的需求, 在部分机器阅读理解任务上取得了一定的性能提升.
1 相关工作
1.1 基于规则方法的问题生成
早期的问题生成研究主要采用规则方法, 基于规则的问题生成系统[5]需要人工设计将陈述句转换为疑问句的复杂规则, 如句法树转换模板, 这些方法成功的关键取决于将陈述句转换到疑问句的规则设计是否足够好, 而转化规则通常需要设计者具有深厚的语言知识. 为改进纯基于规则的系统, Heilman等[6]提出可以使系统生成过量的问题, 然后采用基于监督学习的排序算法对问题质量进行排序, 选出排序最好的; 而监督算法又要求人工设计复杂的特征集, 即使设计出来, 系统所生成的问题也与文档有较多重叠, 导致生成的问题容易回答. 早期基于规则的方法初步证明了自然语言处理技术可以帮助生成问题从而减少人工劳动. 但由于语言本身的复杂性, 人工发现和归纳出所有的问题规则几乎是不可能的, 而且规则方法难以扩展, 为某个领域制定的规则通常很难在其他领域快速移植.
1.2 基于深度神经网络的问题生成
随着深度学习技术的发展, 基于深度学习的问题生成研究取得了许多成果. 第一种方法是采用序列到序列模型实现问题生成. Bahdanau等[7]提出了一个采用双向循环神经网络BiRNN的序列到序列模型, 首次将注意力机制引入到自然语言处理(NLP)领域. Gulcehre等[8]和Gu等[9]引入了复制机制, 将文本中的内容复制到输出问题中, 强化了输入与输出之间的关联. 融入了复制机制的序列到序列模型, 采用双向长短时记忆网络(BiLSTM)编码器编码段落, 采用融入复制机制的注意力双向长短期记忆(LSTM)解码器生成问题. Du等[10]改进了序列到序列的模型, 编码端采用了句子级和篇章级的基于注意力机制的双向LSTM编码器, 解码端采用了LSTM. Song等[11]通过在编码端加入多视角匹配机制, 考虑了答案位置信息与所有文本词的匹配信息, 丰富的匹配信息可以引导解码器生成更准确的问题. 第二种方法是基于Transformer模型的问题生成研究, Transformer结构的提出使神经网络机器翻译任务取得了重大突破, 性能获得很大提升. Scialom等[12]提出了使用Transformer模型进行答案无关的文本问题生成任务, 研究人员将Transformer结构同样应用到了问题生成任务中, 仍可以与复制机制结合, 从而提高文本问题生成任务的性能. 第三种方法是基于预训练技术的问题生成研究. 该技术从大量的语料中学习自然语言知识, 从而提高下游任务的表现. 其中较常用的是预训练模型BERT[13], 该模型提出了掩码训练的方式训练语言模型. 在下游任务中, 通过对语言模型的微调即可获得较好的表现. 后续的研究工作探索了多种不同的预训练模型, 并将其用于问题生成任务中, 使该任务的性能得到进一步提升. 这类方法的模式为“预训练-微调”, 且一次预训练就能利用大量的语料, 微调过程时间更短, 其在文本问题生成领域具有广阔的应用前景.
1.3 多跳问题生成
近年来, 多跳问题生成研究成为问题生成领域的一个研究热点. Pan等[4]提出了一个无监督的多跳问答框架MQA-QG, 是一个多跳问题生成器, 使用多跳问题生成器MQA-QG可以从同构或异构的数据集中生成接近人类思维的多跳问答训练集, 再用生成的训练集去训练多跳QA模型可得到更好的结果, 并且极大减少了人工标注数据的需求. 同样作为问答的数据源, 知识图谱与无结构的纯文本数据源相比, 其优势主要体现在数据的结构化、 精度、 关联度等方面, 结构化的知识图谱以一种更清晰、 更准确的方式表示人类知识, 对于生成更契合实际应用中复杂场景的复杂多跳问题效果更佳. Yu等[14]将知识图谱和知识推理融入多跳问题生成研究中, 生成的多跳问题需要多个句子或段落的证据进行推理才能回答, 缓解了多跳数据短缺的问题, 并提升了多跳机器阅读理解的性能. Fei等[15]提出了一个简单有效的可控生成框架CQG, 保证了问题的复杂性和质量, 同时引入了一种新的基于Transformer的可控解码器, 以保证关键实体出现在问题中. Su等[16]提出的QA4QG使用Transformer结构替代了图结构, 同时考虑了问答任务对问题生成任务的帮助. Yu等[17]提出了相似的输入文本表达结构, 其问题形式也相似, 即两个样本在文本上共享一个近似表达结构的观点, 采用元学习提出了一个自适应的多跳问题生成框架. Su等[18]提出了一个问题生成的多跳编码融合网络MulQG, 其通过图卷积网络(GCN)在多跳中进行上下文编码, 并通过编码器推理门进行编码融合. Gupta等[19]根据上下文中的支持事实生成相关问题, 采用了多任务学习的方式, 并辅以answer-aware支持性事实预测任务指导问题生成. Sachan等[20]使用强Transformer进行多跳问题生成, 同时采用基于图网络增强的方法与Transformer模型融合, 使问题生成效果进一步提升.
本文主要考虑多跳问题生成, 提出一个基于对比学习的多跳问题生成模型, 该模型是一个分为生成阶段和对比学习打分阶段的生成-评估两阶段模型, 生成阶段通过执行推理图生成候选多跳问题, 对比学习打分阶段通过一个基于对比学习的无参考问题的候选问题打分模型对候选问题进行打分排序, 并选择最优的候选问题.
2 方法设计
本文设计的模型是一个生成-评估两阶段模型. 生成阶段提取和整合多个输入源文本的信息生成多个候选多跳问题, 通过执行桥式推理图和比较式推理图生成桥式候选多跳问题和比较式候选多跳问题. 对比学习打分阶段通过一个基于对比学习思想的无参考问题的候选问题打分模型对候选问题进行打分排序, 并选择最优的候选问题. 模型如图1所示.
多跳问题生成的定义为给定多个自然语言文本D={D1,D2,…,Dn}, 其中Di表示输入的第i个自然语言文本, 目标是生成多跳自然语言问题Q.本文模型定义为给定两篇原文本〈texti,textj〉和对应的参考问题答案对〈refQ,refA〉, 问题生成模型f的目标是生成候选多跳问题Q=f(texti,textj), 使得对比学习打分模型h给出的分数r=h(Q,refQ)尽可能高.在该过程中, 模型被分解成两个阶段: 生成模型g和对比学习打分模型h, 前者负责生成候选多跳问题集合, 后者负责打分并选择最优候选多跳问题.
2.1 生成阶段
生成阶段模型分为两个类型: 桥式多跳问题生成和比较式多跳问题生成.这两种类型的问题生成方法基本上涵盖了数据集HotpotQA的所有问题类型. 生成阶段从输入的两个相关文本T={ti,tj}中提取、 生成、 融合相关信息得到候选的多跳问题集.
2.1.1 桥式多跳问题生成
桥式多跳问题生成阶段模型g1的输入为两个具有共同实体的文本对T={ti,tj}, 生成的多个候选问题{Q1,Q2,…,Qn}=g1(T), 生成模型方案如图2所示.多数多跳问题会通过桥实体整合信息[25].图2中: FindBridge模块表示提取两个文本的共同桥实体e=f(ti)∩f(tj), 其中f(·)表示实体抽取过程, 使用stanza_nlp工具包识别并提取出两篇文本共同的桥实体; QGwithAns模块表示通过第一个文本的内容ti和答案a生成一个简单的单跳问题q1=QG(ti,a); QGwithEnt模块表示通过第二个文本tj和提取的桥实体e生成一个简单的单跳问题q2=QG(tj,e), 其中QG(·)表示单跳问题生成的过程, 该过程使用谷歌的T5预训练模型进行单跳问题生成[26]; QuesToSent模块表示将其中一个单跳问题q1转换为陈述句式s[27]; BridgeBlend模块表示将转化为陈述句式的句子s与另一个单跳问题q2融合生成一个复杂的多跳问题Q=BERT-Large(s,q2), 其中BERT-Large[28]表示融合两个单跳问题的预训练模型.
2.1.2 比较式多跳问题生成
比较式多跳问题生成阶段模型g2的输入为两个具有比较属性的文本对T={ti,tj}, 生成的多个候选问题{Q1,Q2,…,Qn}=g2(T), 生成模型方案如图3所示.图3中: FindComEnt模块表示提取两篇文本中可以作比较的属性作为桥实体e1=f(ti)和e2=f(tj), 其中f(·)表示使用stanza_nlp工具包提取可能作为比较属性的实体, 例如时间、 地点、 数字等; QGwithAns模块表示通过第一个文本生成一个简单的单跳问题q1=T5(ti), QGwithEnt模块表示通过第二个文本生成一个简单的单跳问题q2=T5(tj), QGwithAns和QGwithEnt模块使用谷歌的T5预训练模型进行单跳问题生成; CompareBlend模块表示将两个单跳问题q1和q2融合生成一个比较式多跳问题Q, 此处的两个单跳问题是关于不同的实体e1和e2的问题.
2.2 对比学习阶段
对比学习阶段设计为一个基于对比损失的无参考问题的候选问题打分模型h, 模型方案如图4所示.输入为两篇相关的原文本对T={ti,tj}和参考问题refQ以及上一阶段生成的候选多跳问题集Qi, 输出为最优的候选问题Q.针对原文本T={ti,tj}, 一个更好的候选多跳问题Q应该获得更高的打分, 建立一个评价打分模型h, 其目标是为生成模型g生成的候选问题Qi打分ri, 可表示为
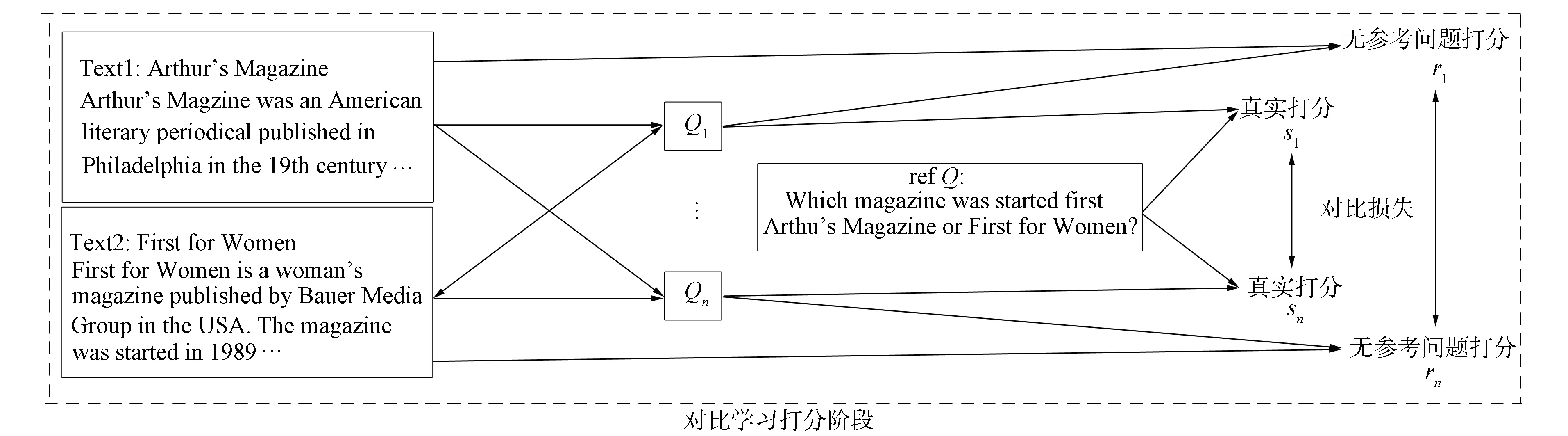
图4 基于对比学习的无参考问题打分模型Fig.4 Scoring model without reference question based on contrastive learning
ri=h(Qi,T),
(1)
其中h表示打分模型.模型h初始化为预训练模型RoBERTa[29], 该模型首先分别对候选问题集Qi和原文本T={ti,tj}编码; 然后计算候选问题与文本内容的余弦相似度, 并将其作为候选问题Qi的无参考问题的打分ri; 最后模型输出的多跳问题Q为获得最高分的候选多跳问题, 即
Q=argmaxri,
(2)
其中ri表示第i个候选问题的无参考问题打分.选择打分最高的问题Q作为最终候选多跳问题, 同时计算参考问题refQ与候选问题Qi的余弦相似度作为候选问题Qi的真实打分si, 期望候选问题Qi的无参考问题打分ri能更接近真实打分si.
不同于其他对比学习工作采用的明确构建正例和负例, 本文模型对比学习阶段的对比性体现在参数化模型h(·)评估生成问题的不同质量.在对比学习阶段的模型h中引入一个对比损失:
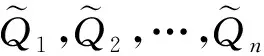
3 实 验
3.1 生成阶段
本文实验采用数据集HotpotQA[3], 其是一个多文档、 多跳推理、 标注支持事实的同构数据集. 要回答多跳问题, 需要定位多个信息来源并从中找到最相关的部分, 同时基于这些信息进行多步推理和理解. 数据集HotpotQA包含78 909个桥式多跳问题和18 943个比较式多跳问题, 共97 852个多跳问题. 其中桥式问题分出72 991个问题作为训练集和5 918个问题作为验证集, 比较式问题分出17 456个问题作为训练集和1 487个问题作为验证集. 每个多跳问题都需要在两篇标注了支持事实的维基文档进行推理才能回答. 数据集HotpotQA标注了支持事实, 本文实验使用无监督的生成方法, 所以只需提取出数据集中的文本内容及对应的问答集作为训练数据, 无需标注支持句.
实验采用精确匹配EM和F1值两个评价指标. EM测量预测结果与基本事实之间精确字符串匹配的百分数,F1是精度和召回率的协调平均值, 即
3.2 实验设置
实验中模型分为两个阶段: 生成阶段和对比学习打分阶段. 在生成阶段, 执行多跳问题生成器g(·)生成两种类型的问题集Qbridge和Qcomparison,Qbridge只包含生成的候选桥式问题,Qcomparison只包含生成的候选比较式问题, 将Qbridge和Qcomparison合并起来作为数据集HotpotQA生成的候选问题集Qhotpot. 在对比学习打分阶段, 对于3个候选问题集Qbridge,Qcomparison,Qhotpot, 通过对比学习打分模型h(·)分别挑选出得分最高的问题集并通过数据增强得到Qbge-select,Qcom-select,Qhotpot-select作为最终的训练集, 实验数据的信息如下:Qbridge有37 647个问题,Qcomparison有17 455个问题,Qhotpot有55 102个问题,Qbge-select有44 316个问题,Qcom-select有32 126个问题,Qhotpot-select有76 442个问题.
为验证多跳问题生成能有效提高机器阅读理解的能力, 对于数据集HotpotQA, 本文采用SpanBERT[30]作为QA模型验证生成的问题集Qbge-select,Qcom-select,Qhotpot-select对机器阅读理解任务的效果, 并采用精确匹配EM值和F1值评价效果.
将本文实验模型分别与1个有监督基线和4个无监督基线模型进行对比. 1个有监督基线模型是将完整的原始数据集HotpotQA放入SpanBERT模型中训练得到的结果[30]. 4个无监督基线模型分别是: 1) SQuAD-Transfer, 是用数据集SQuAD训练SpanBERT模型, 然后将其转换为多跳QA; 2) Bridge-Only, 是只用原始数据集HotpotQA中的桥式数据训练SpanBERT模型; 3) Comparison-Only, 是只用原始数据集HotpotQA中的比较式数据训练SpanBERT模型; 4) MQA-QG[4], 是使用多跳问题生成器MQA-QG在数据集HotpotQA上进行多跳问题生成, 然后将生成的数据训练SpanBERT模型. 将原始数据集HotpotQA中的桥式数据、 比较式数据以及全体数据分别与本文模型生成并筛选的数据Qbge-select,Qcom-select,Qhotpot-select相结合, 进行数据增强, 增强后的数据训练SpanBERT模型与有监督基线模型进行对比. 将本文模型生成并筛选的数据Qbge-select,Qcom-select,Qhotpot-select分别进行数据增强后训练SpanBERT模型, 并与无监督基线模型进行对比. 实验的参数设置列于表1.

表1 参数设置Table 1 Parameter settings
实验设置4个epoch, 每个epoch设为10个step, 图5为数据集Bridge,Comparison,Total实验过程的EM和F1值收敛曲线, 横坐标的0~9表示为第一个epoch, 10~19表示为第二个epoch, 20~29表示为第三个epoch, 30~39表示为第四个epoch, 4个epoch后EM值和F1值趋于平缓.

图5 实验过程中EM和F1值的收敛过程Fig.5 Convergence process of EM and F1 values during experimental process
3.3 实验结果分析
不同模型的实验结果列于表2. 由表2可见, 对于有监督基线SpanBERT, 本文模型的生成数据和原始数据的组合数据集对于部分机器阅读理解任务的效果有一定提升, 侧面反映了模型扩充的数据集质量较好. 基于有监督的数据集Bridge和Comparison的实验结果表明, 由于Bridge桥式数据的推理链是顺序链, 需要找到共同的桥实体才能有效关联两个文本, 而Comparison对比式数据的推理链需要比较两个实体的同一属性, 因此二者对于训练集的数据量有一定要求, 特别是Comparison对比式数据对训练集的数据量更敏感.

表2 各模型的实验结果Table 2 Experimental results of each model
对于无监督基线, 本文模型的生成数据Qhotpot-select在机器阅读理解任务中F1值达到了69.0, 优于4个基线模型(SQuAD-Transfer,Bridge-Only,Comparison-Only,MQA-QG). 在没有人工标注支持句的弱监督情况下,F1值与有监督基线的差距由14.2缩短到13.8, 证明了本文模型对于生成高质量多跳问题的有效性. Comparison和Total数据的F1值分别超出MQA-QG模型0.9和0.4, 而数据集Bridge的指标没有超过MQA-QG模型, 说明将候选问题与文本进行对比学习的方式对于捕捉比较式数据集文档的重要实体属性语义信息更有效, 进而筛选出质量高的多跳问题.
综上, 针对获取大规模的多跳问答训练数据集耗时耗力的问题, 本文提出了一个分为生成阶段和对比学习打分阶段的生成-评估两阶段模型, 生成最优候选问题的同时通过数据增强策略, 有效地通过扩充训练集取得了机器阅读理解任务上的性能提升. 在多文本同构数据集HotpotQA上的实验结果表明, 基于对比学习思想的无监督多跳问题生成方法对比了候选问题和源文本, 生成了质量较高的无需人工标注的多跳问题集, 有效扩充并筛选了原始的训练集, 极大减少了人工标注数据的需求, 同时在机器阅读理解任务上性能提升较好.
