基于重组性高斯自注意力的视觉Transformer
2023-09-27周继开
赵 亮 周继开
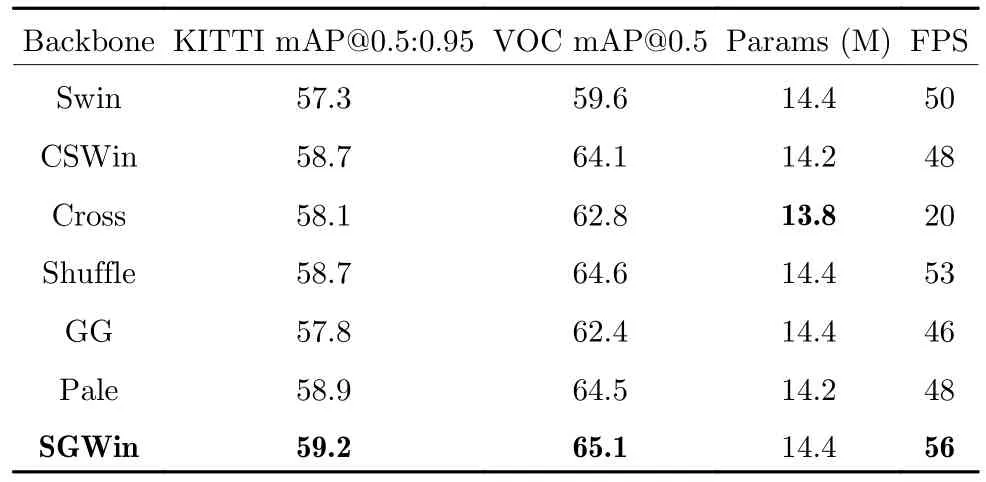
目前计算机视觉领域使用的方法有两大类,分别是卷积神经网络(Convolutional neural networks,CNN)和Transformer.其中CNN 是图像分类[1]、目标检测[2]和语义分割[3]等计算机视觉任务的主流方法,自AlexNet[4]诞生并在ImageNet 图像分类挑战中获得冠军以后,研究者们开始通过各种方法设计卷积神经网络,使得网络变得更深、更密集、更复杂[5-8],在随后的几年内出现了很多经典的卷积神经网络.VGGNet[5]探索了CNN 的深度及性能之间的关系,通过使用很小的卷积叠加增加网络的深度达到提升网络精度的效果;DenseNet[6]通过从特征图的角度入手,为每一个模块加入密集连接达到了更好的性能和更少的参数量;ResNet[7]通过引入残差结构解决了随着网络层数的加深出现梯度消失的问题;GoogLeNet[9]使用密集成分来近似最优的稀疏结构,在提升性能的同时不增加计算量;EfficientNet[10]提出了一种多维度混合的模型缩放方法,可以同时兼顾模型的精度以及速度.在CNN 模型性能越来越强的同时,另一类视觉Transformer的方法横空出世.Transformer 由于其自注意力模块具有捕捉长距离依赖[11]的能力广泛被应用于自然语言处理的任务中,而后被用到了计算机视觉任务中并取得了比CNN 方法更优的效果.在文献[12-15]中将自注意力模块嵌入到CNN 中并应用于图像分类、目标检测和语义分割等计算机视觉任务中.Vision Transformer (ViT)[16]不使用卷积神经网络而是通过将图像序列化的方法首次将Transformer 架构应用到图像领域中,并且在ImageNet 数据集上取得了比ResNet 更好的效果,而后在短时间内被引入改进[17-20]并应用于各种图像领域的各种下游任务[21-24].但是Transformer 的复杂度成为了其性能最大的瓶颈,为了减小因全局自注意力引起的二次复杂度,现有的方法较多使用局部自注意力机制.目前现有的局部自注意力机制主要有7 类(如图1 所示).
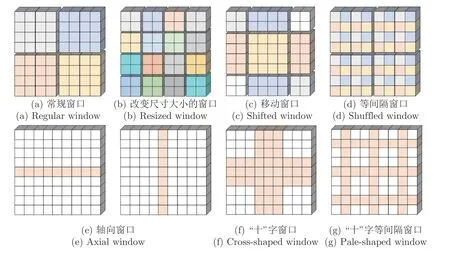
图1 现有局部自注意力方法Fig.1 Existing local self-attention methods
1)目前几乎所有的基于局部自注意力的Transformer 模型都会使用常规窗口自注意力(Windowmulti-head self-attention,W-MSA),通过W-MSA与其他类型的局部自注意力交替使用来建立窗口之间的通信,如图1(a)所示.
2)HaloNet[25]通过对窗口进行缩放的操作来收集窗口之外的信息并建立跨窗口的信息交互,如图1(b)所示.
3)Swin Transformer 通过在连续的局部注意力层之间移动窗口的分区建立跨窗口之间的信息通信缓解感受野受限的问题,如图1(c)所示.
4)CrossFormer[26]提出了跨尺度嵌入层和长短注意力,有效地建立了长远距离的跨窗口的连接.
5)Shuffle Transformer[27]在连续的局部自注意力层之间加入空间shuffle 的操作,以提供长距离窗口之间的连接并增强建模能力.
6)GG Transformer[28]受到了人类在自然场景中识别物体的Glance 和Gaze 行为的启发,能够有效地对远程依赖性和局部上下文进行建模,4)~6)这3 种局部注意力可统一归为图1(d)的形式.
7)Axial-DeepLab[29]将二维自注意力分解为横向和纵向两个一维的自注意力,如图1(e)所示.
8)CSWin Transformer[30]提出了一种在“十”字等宽窗口内计算自注意力的方式(Cross-shaped window self-attention),通过横条和纵条窗口自注意力并行实现,如图1(f)所示.
9)Pale Transformer[31]提出了“十”字等间隔窗口自注意力(Pale-shaped-attention,PS-Attention),如图1(g)所示.
图1 展示了现有的局部自注意力方法.不同的颜色表示不同的窗口,在每个窗口内执行计算自注意力,并通过引入各种策略来建立跨窗口之间的连接.这些工作虽然取得了优异的性能,甚至优于一些最新的CNN 的方法,但是每个自注意力层中的依赖性仍然具有局限性,具体表现在当特征图很大时,通过有间隔的采样点组成的窗口无法建立所有窗口之间的信息流动导致了模型捕获的上下文语义信息的能力不足.针对上述问题,本文提出了一种高斯窗口自注意力机制(Gaussian window-multihead self-attention,GW-MSA),它包括纵向高斯窗口自注意力(Vertical Gaussian window-multihead self-attention,VGW-MSA)和横向高斯窗口自注意力(Horizontal Gaussian window-MSA,HGW-MSA)两种类型的局部自注意力.GW-MSA与图1(d)中的Shuffled W-MSA 联合组成了SGWMSA,有效地捕捉更丰富的上下文依赖,如图2 所示,不同颜色的点代表不同的窗口组成,在GW-MSA中,通过混合高斯权重重组GWR 策略重构特征图,并在重构后的特征图上计算局部自注意力.本文在Swin Transformer 结构的基础上,引入SGW-MSA 设计了SGWin Transformer 模型,在公开数据集CIFAR10、mini-imagenet、KITTI、PASCAL VOC和MS COCO 上进行了实验,实验结果表明SGWin Transformer 在图像分类和目标检测的任务上优于其他同等参数量的基于局部自注意力的Transformer 网络.
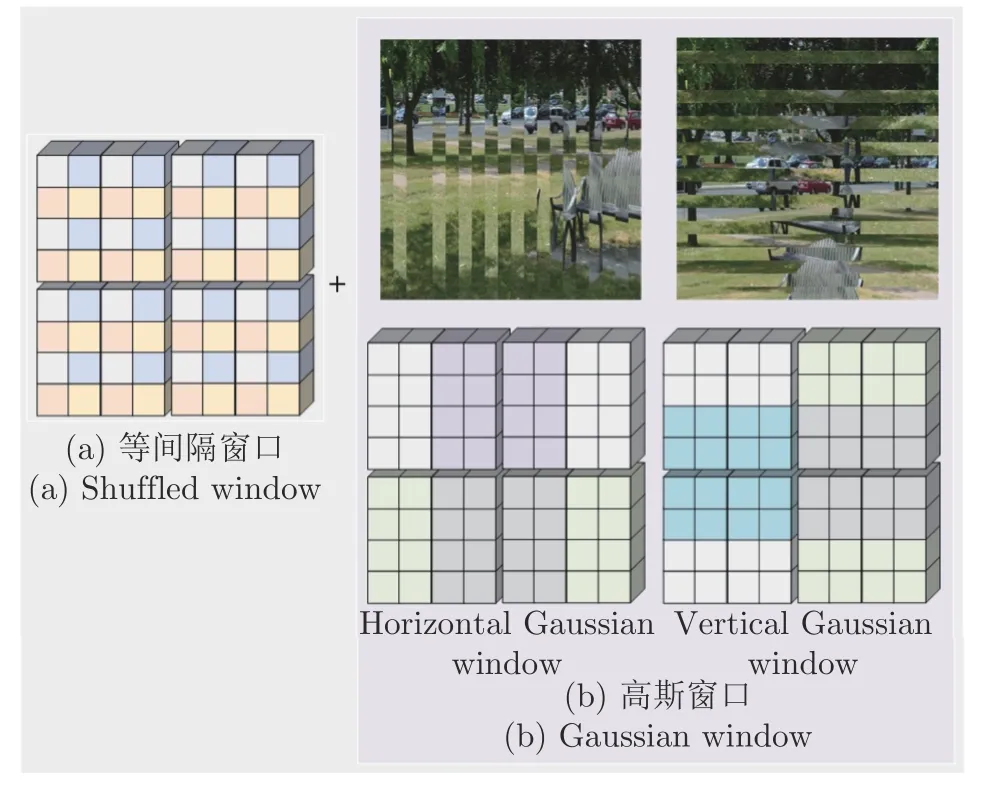
图2 局部自注意力组合Fig.2 Local self-attention combination
1 模型框架
1.1 Swin Transformer 算法
Swin Transformer 提出了一种新的基于Transformer 的视觉主干网络,自注意力的计算在局部非重叠窗口内进行.一方面可以将复杂度从之前的和图像大小成平方的关系变成线性关系,并且采用非重叠局部窗口,大大减小了计算量;另一方面在不同的注意力层之间采用移动窗口的操作,使得不同窗口之间的信息可以交换.并且由于性能超越了参数量相似的CNN 主干,推动了Transformer 成为了视觉主干网络的新主流,在近两年出现了越来越多基于局部自注意力机制的视觉Transformer 方法,然而目前的各种局部自注意力建立远距离跨窗口连接策略具有一定的局限性.当特征图很大时,现有的窗口连接的策略无法建立所有窗口之间的信息流动导致无法捕捉足够的上下文信息.假设特征图的高和宽分别为h和w,局部窗口的高和宽分别为Wh和Ww,对于特征图上划分的某一个局部窗口,该窗口在纵向和横向可以建立最近窗口连接的距离分别为:
在纵向和横向可以建立最远窗口连接的距离分别为:
1.2 SGWin Transformer 的整体结构
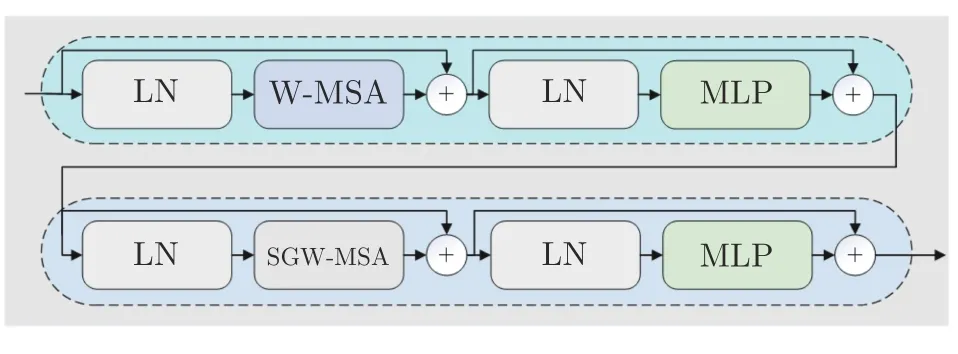
为了解决当特征图过大时现有的局部自注意力机制无法建立所有窗口之间的信息交互的问题,本文提出了一种新的局部自注意力机制SGW-MSA,并在Swin Transformer 的基础上将所有的移动窗口自注意力SW-MSA 替换为SGW-MSA 得到一种新的SGWin Transformer 模型,模型的整体架构如图3(a)所示.主干网络符合标准的视觉分层Transformer 的PVT[32]的结构,该设计包含了4 个阶段的金字塔结构,每个阶段由Patch embed 或Patch merging 和多个SGWin Transformer block 串联组合而成.如图3(b)所示,每个SGWin Transformer block 由两组结构串联组成,第一组结构包括一个W-MSA 模块和一个MLP,第二组结构由一个SGW-MSA 模块和一个MLP 模块组成,MLP 对输入特征图进行非线性化的映射得到新的特征图,SGW-MSA 局部自注意力机制的示意图如图3(c)所示.整个模型的计算过程为: 输入图片通过Patch embed 将输入图像下采样4 倍,并得到指定通道数的特征图,特征图会被送入Stage 1 的SGWin Transformer block 中,通过W-MSA、SGW-MSA 模块提取局部特征和图像中的上下文信息并建立所有窗口之间的信息流通,Stage 1 最后一个SGWin Transformer block 的输出会被送入Stage 2 中,除Stage 1 之外的所有Stage 会通过一个Patch merging 将上一个阶段输出的特征图尺寸降采样两倍(宽和高变为原来的二分之一),通道维度变为原来的两倍.整个网络之后可以接一个Softmax 层和一个全连接层用于图像分类任务,并且每个阶段的特征图可输入到目标检测的FPN[33]部分中进行多尺度目标检测.

图3 SGWin Transformer 整体架构Fig.3 Overall architecture of SGWin Transformer
1.3 SGW-MSA 局部自注意力机制
当出现式(5)或式(6)中的情况时,两个窗口之间的纵(横)向距离大于一定值时就无法建立连接.当出现式(7)中的情况时,两个窗口之间的纵(横)向距离大于或小于一定值时都无法建立连接.因此式(7)中的问题包含式(5)和式(6)存在的问题.仅考虑式(7)中的情况,将纵向无法建立窗口连接的两个距离分别记为,将横向无法建立窗口连接的两个距离分别记为.如图4所示,为了能够建立所有窗口之间的信息交互,SGWMSA 将输入特征图在通道上均匀拆分成3 组,对第一组特征图使用现有的Shuffled W-MSA 等间隔采样点组成窗口用于纵(横)向距离大于且小于窗口之间的联系;后两份特征图分别使用横向高斯窗口自注意力HGW-MSA 和纵向高斯窗口自注意力VGW-MSA 计算局部自注意力,建立Shuffled W-MSA 未能建立的窗口的联系.最后将3 个部分的局部自注意力计算结果在通道上进行合并得到最终的输出结果.
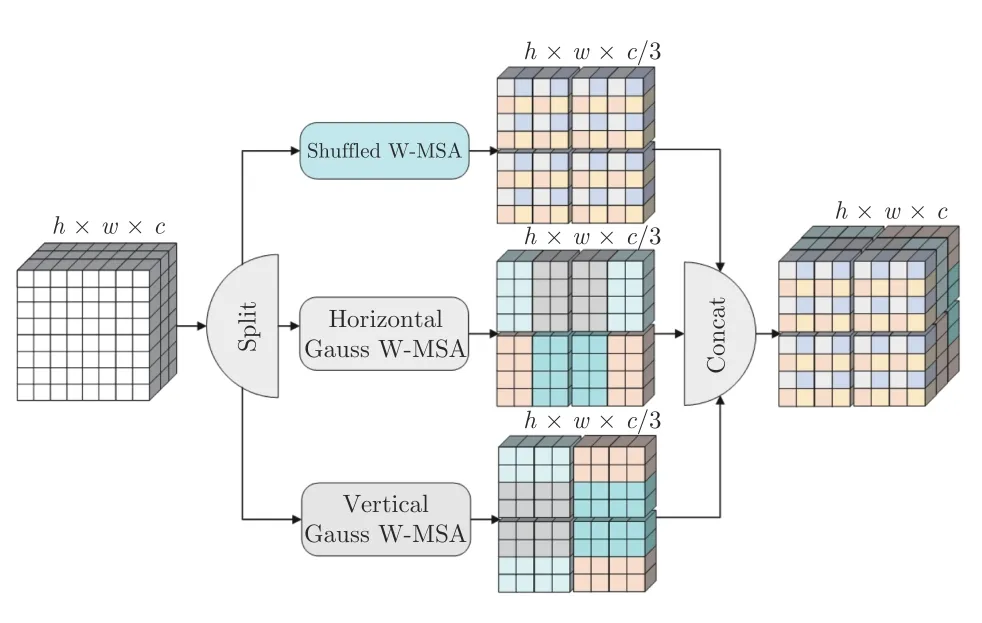
图4 SGW-MSA 局部自注意力示意图Fig.4 SGW-MSA local self-attention diagram
1.3.1 GW-MSA 局部自注意力机制
GW-MSA 可用于建立Shuffled W-MSA 未能建立的窗口连接,分为VGW-MSA 和HGW-MSA两种不同的形式.如图5 所示,每个形式的GW-MSA由混合高斯权重重组GWR 模块、常规局部自注意力W-MSA 和逆混合高斯权重重组(re Gaussian weight recombination,reGWR)模块3 个部分组成,其中GWR 是本文为了建立纵(横)向距离小于窗口之间的信息交互提出的一种特征图重组的策略.
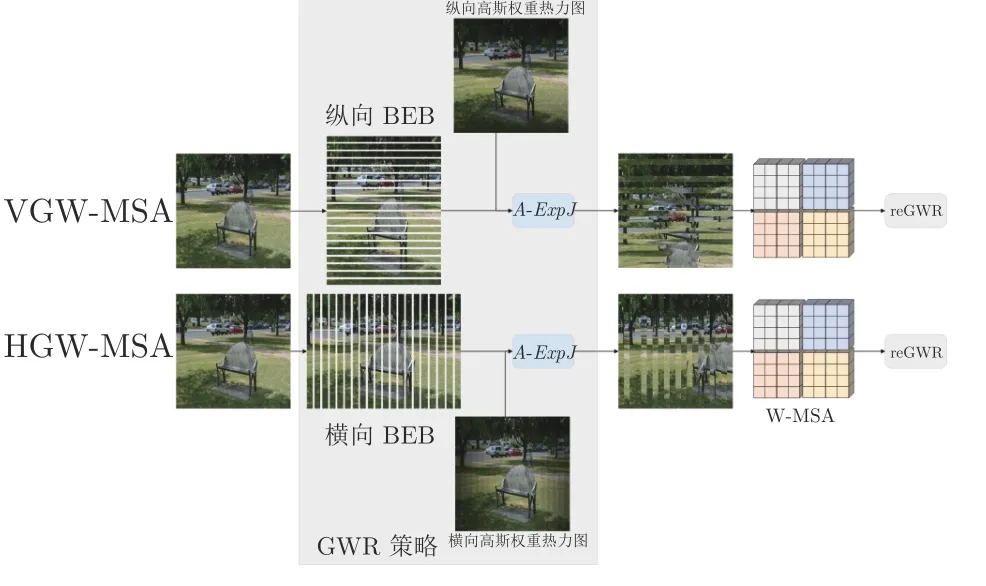
图5 GW-MSA 局部自注意力示意图Fig.5 GW-MSA local self-attention diagram
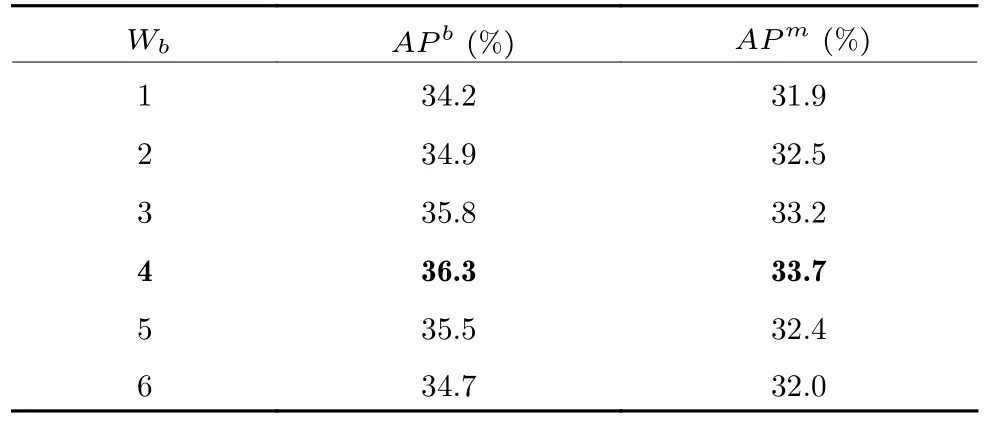
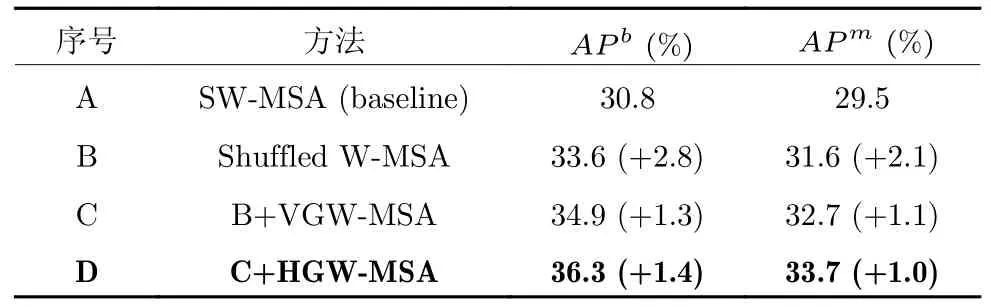
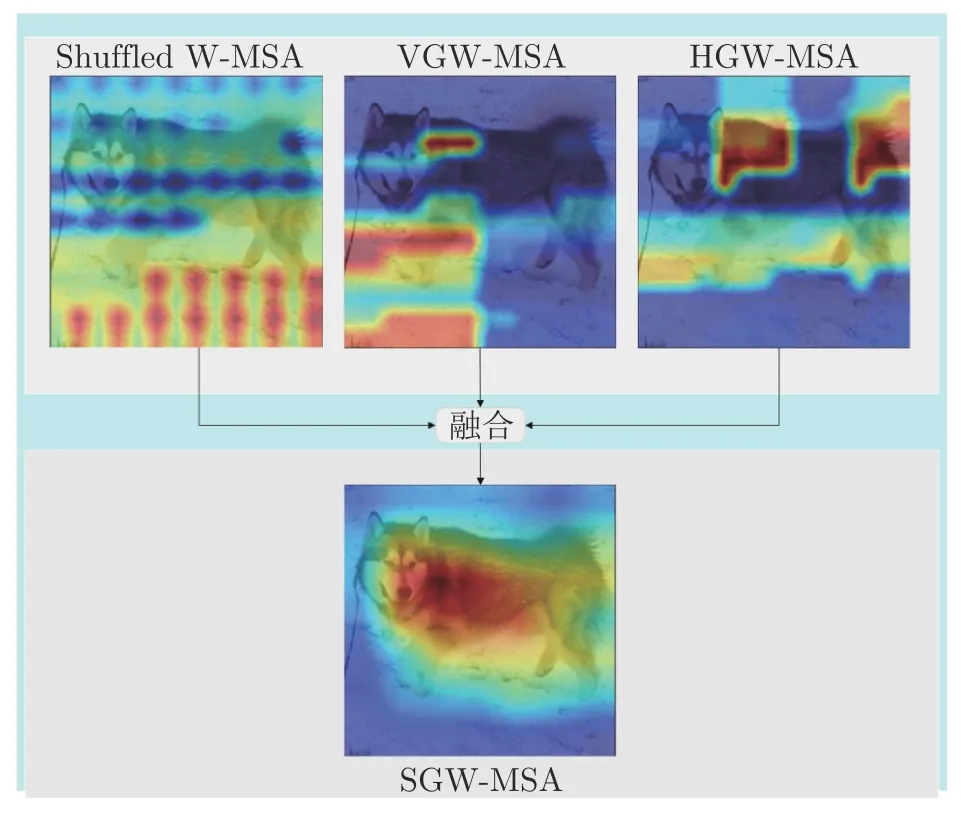
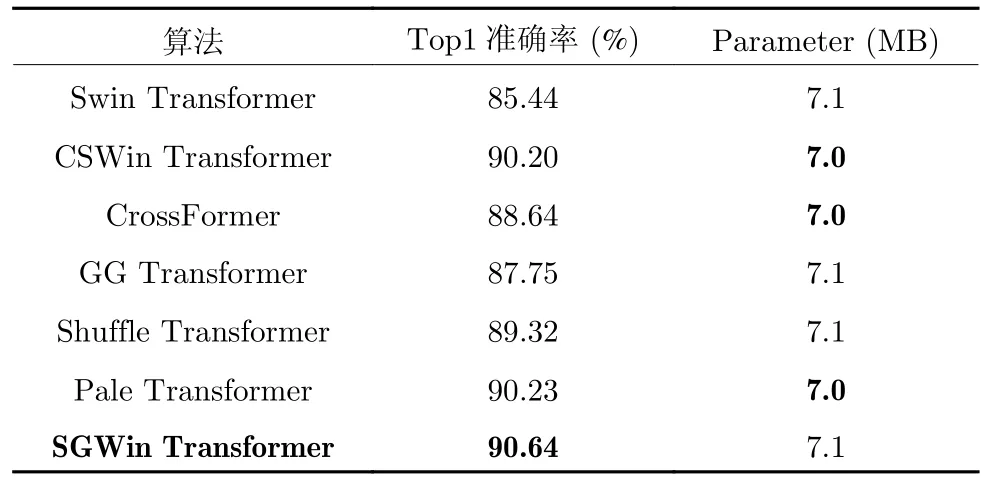
假设特征图的高和宽分别为h和w,局部窗口的高和宽分别为Wh和Ww.GWR 会将输入特征图划分成多个长条形状的基础元素块(Basic element block,BEB),计算纵向的VGW-MSA 时将特征图按高切分成若干份高宽分别为Wb(Wb 图6 纵横向基础元素块示意图Fig.6 Schematic diagram of vertical and horizontal basic element block 为所有的基础元素块建立高斯权重分布表,结合高斯权重分布表尽可能使距离小于或者大于的基础元素块放在一起用于重组特征图.然后在重组后的特征图上使用W-MSA 计算局部自注意力.高斯权重分布表由一维高斯分布公式得到: 式中A代表权重的幅值,µ表示均值,σ2为方差.GWR 策略的思想就是根据高斯分布的特性.如图6(c)和图6(d)所示,纵向基础元素块越靠近图像上边缘或下边缘,权重越小;横向基础元素块越靠近左边缘和右边缘,权重越小.权重越高的基础元素块对应图像中的位置颜色越亮,代表对应位置的权重越高;权重越低的基础元素块对应图像中的位置颜色越暗,代表对应位置的权重越低.将特征图上的每一个基础元素块看作一个点,以特征图中心的基础元素块为原点建立坐标系,依据每个基础元素块在坐标系中的位置可以被赋予一个对应的高斯分布权重,纵(向和横向的中心基)础元素块的位置坐标记为,对于任意x位置下的基础元素块对应的高斯权重分布遵循下式: 式中的σ取值为1.5,分子部分除以cx是为了控制权重不会过小而约等于0.为了尽可能将权重近似的基础元素块放在一起,本文采用了带权重的随机抽样A-ExpJ[34]依据每一个基础元素块的索引以及对应的权重进行随机抽样,最后将所有基础元素块的索引按照抽样的顺序进行排列得到新的重组后的特征图.假设将特征图划分成基础元素块的序列索引为idx=[1,2,···,n],其中n=h/Wb或w/Wb;基础元素块的高斯权重分布表为W=[W1,W2,···,Wn],其中n=h/Wb或w/Wb;重组的索引idxnew可以由式(10)得到,其中n表示通过权重抽样的个数.A-ExpJ 表示带权重的随机抽样函数.最后按照新的基础元素块的索引对特征图进行重组得到GWR策略的输出结果. 1.3.2 SGW-MSA 的计算过程 假设输入特征图为X∈Rh×w×c,SGW-MSA首先将输入特征图X在通道上切分成3 个部分,第一个部分的特征图记为,第二个部分的特征图记为,第三个部分的特征图记为.对XS使用Shuffled W-MSA在特征图上使用等间隔采样点组成窗口,并在所有的窗口内部计算自注意力.对XV和XH分别使用纵向和横向的GWR 策略对特征图进行重组,并在重组的特征图上使用W-MSA 计算局部自注意力.具体计算过程如下. 首先在XS上通过等间隔采样特征点形成多个具有相同尺寸 (Wh,Ww)的窗口: 每一个窗口内部单独计算局部自注意力.在计算局部自注意力时,使用3 个全连接层ℓQ,ℓK,ℓV计算得到Q (Qurey),K (Key),V (Value),计算式如下: 其中i∈[1,2,···,N],MSA表示Multi-head selfattention[33].最后将所有的局部自注意力的计算结果在空间上进行合并得到新的特征图: 因为GWR 策略将原有的特征图根据新的基础元素块的顺序进行了重组,所以需要将YV和YH依据原先的基础元素块的顺序进行还原.将两个部分的局部自注意力计算结果在通道上进行合并,得到最终的输出结果,如式(20)所示,其中Concat表示在通道上进行合并. 1.3.3 计算复杂度分析 对于给定的尺寸为Rh×w×c的特征图,局部窗口的尺寸为 (Wh×Ww),用O表示复杂度.标准的全局自注意力(Global self-attention)的计算复杂度如式(21)所示: SGW-MSA 的计算复杂度如式(22)所示 其中Ww,Wh分别为局部窗口的宽和高.对比式(9)和式(10),因为SwSh ≪hw,所以OSGW≪OGlobal,即SGW-MSA 的计算复杂度远小于全局自注意力的计算复杂度. SGWin Transformer block 由两组结构串联组成.如图7 所示,第一组结构包括一个W-MSA 模块和一个多层感知机模块MLP,第二组结构由一个SGW-MSA 模块和一个MLP 模块组成,MLP对输入特征图进行非线性化的映射得到新的特征图,W-MSA 用于捕捉特征图的局部自注意力,SGW-MSA 用于捕捉局部自注意力并建立所有窗口之间的信息流通.整个SGWin Transformer block的向前传播式如下: 图7 SGWin Transformer block 结构示意图Fig.7 Structure diagram of SGWin Transformer block 其中xl-1为前一个Patch embed 或者Patch merging 或者SGWin Transformer block 的输出,和xl分别代表(SG)W-MSA 模块和MLP 模块的输出,LN 代表LayerNorm. SGWin Transformer 的超参数配置与Swin Transformer 相同,如表1 所示.其中Stage=i表示SGWin Transformer 模型的第i个阶段.Stride表示SGWin Transformer 模型在每个阶段下采样的倍数.Layer 表示当前阶段的模块名字,一个阶段包含两个模块,Patch embed 和Patch merging 负责对特征图进行下采样,下采样的倍数分别为4 和2,Patch embed 和Patch merging 的输出会被送入后续的Transformer block 中提取局部自注意力并进行特征的映射,在最后一个Transformer block后接一个平均池化层和全连接层可用于图像分类任务,或者将每一层的特征图输出可用于目标检测任务.模型的第i个Stage 的模型的超参数定义如下: 表1 SGWin Transformer 的超参数配置表Table 1 Super parameter configuration table of SGWin Transformer 1)Pi.第i个Stage 的输入特征图下采样的倍数,第一个Stage 下采样的倍数是4,其余3 个Stage 的下采样倍数为2; 2)Ci.第i个Stage 的输入特征图下采样后新特征图的通道数; 3)Si.第i个Stage 的Transformer block 中计算局部自注意力的窗口大小; 4)Hi.第i个Stage 的Transformer block 中多头自注意力机制的Head 数量; 5)Ri.第i个Stage 的Transformer block 中MLP 模块的通道扩展比. 本文分别在图像分类数据集CIFAR10[35]以及目标检测数据集KITTI[36]、PASCAL VOC[37]、MS COCO[38]上进行了实验,与其他参数量相似且具有代表性的基于局部自注意力的Transformer 的模型进行了对比,并通过消融实验分析验证了本文提出的局部自注意力机制SGW-MSA 模块的有效性. 热力图通常是对类别进行可视化的图像,表示着模型特征提取的能力.图8 展示了本文算法与基线算法Swin Transformer 的热力图对比,第一行是原图,第二行是Swin Transformer 的热力图,第三行是SGWin Transformer 的热力图.(a)、(b)、(c)列的对比可以看出SGWin Transformer 比Swin Transformer 热力图覆盖的目标范围更全面;(d)列的对比可以看出SGWin Transformer 比Swin Transformer 的定位更准确且小目标检测能力更强.所以SGWin Transformer 算法比Swin Transformer 算法的目标定位更加准确,也验证了本文提出的SGW-MSA 局部自注意力机制的有效性.此外SGWin Transformer 对小目标检测的性能也有一定提升. 图8 本文算法与Swin Transformer 的热力图对比Fig.8 Comparison between the algorithm in this paper and the thermal diagram of Swin Transformer 为了验证SGW-MSA 模块的有效性,首先在MS COCO 数据集上进行了消融实验分析.实验使用mmdetection[39]目标检测库以及Mask R-CNN[40]目标检测框架,将主干网络替换为Swin Transformer,然后依次将本文改进的策略加入到Swin Transformer 中进行实验,优化器采用对超参数不敏感的AdamW[41]优化算法更新参数,训练Epoch为12,初始学习率为1×10-4,在第8 Epoch 和第11 Epoch 结束时分别衰减10 倍,评价指标采用目标检测平均精度APb以及实例分割平均精度APm. 2.2.1 GWR 策略超参数消融实验分析 GWR 策略通过横条和竖条状的基础元素块重组特征图来建立距离小于的窗口的连接,对于基础元素块的宽度Wb的设置会直接影响重组后的特征图的结果,也会对网络的性能造成影响.为了验证Wb(Wb小于局部窗口的宽和高)的最佳取值,本文在默认窗口大小为7×7的情况下,Wb的值从1 到6 取值进行对比实验,在不使用预训练模型的情况下,实验结果如表2 所示. 表2 基础元素块宽度消融实验对比Table 2 Comparison of ablation experiments of basic element block width 从表2 中可以看出当基础元素块的宽度Wb从1 到6 改变的过程中,在1 到4 的区间内精度呈现上升趋势,在4 到6 区间内精度呈现下降趋势,在取值为4 时模型的精度达到了最高,达到了最好的效果,所以本文的GWR 策略中基础元素块的宽度确定为4. 2.2.2 纵向VGW-MSA 与横向HGW-MSA 的消融实验分析 在验证GW-MSA 局部自注意力中包含的纵向VGW-MSA 和横向HGW-MSA 的有效性时,本文依次将基线算法Swin Transformer 的SW-MSA替换为Shuffled W-MSA、Shuffled W-MSA+VGWMSA、Shuffled W-MSA+VGW-MSA+HGWMSA,逐步验证每个模块的有效性,在不使用预训练模型的情况下,实验结果如表3 所示. 表3 SGW-MSA 消融实验结果Table 3 SGW-MSA ablation experimental results 从表3 中可以看出本文算法的基线模型Swin Transformer 使用SW-MSA 局部自注意力的目标检测和实例分割的平均精度分别为30.8%和29.5%;将SW-MSA 替换为Shuffled W-MSA 后精度分别提升了2.8%和2.1%;将SW-MSA 替换为Shuffled W-MSA 与纵向高斯窗口自注意力VGW-MSA 的结合后精度分别提升了1.3%和1.1%;将SW-MSA替换为SGW-MSA (Shuffled W-MSA+VGWMSA+HGW-MSA)后精度分别提升了1.4% 和1.0%.这些消融实验的数据进一步验证了本文提出的SGW-MSA 局部自注意力机制的有效性. 2.2.3 三种局部自注意力特征图融合的消融实验与分析 为了更直观地感受到SGW-MSA 联合3 种自注意力机制的优势,选用ImageNet 中的图像分别可视化3 种局部自注意力机制的注意力热力图.输入图像采用 224×224 像素的尺寸,每一个stage 中特征图的尺寸分别为 56×56,28×28,14×14,7×7,越靠后的stage 可视化出的热力图覆盖的物体范围越大、效果越好,但是考虑到最后一个stage 特征图的尺寸为7×7 等于局部自注意力机制的窗口大小,此时的三个局部自注意力全部退化为全局自注意力.因此选取第3 个stage 中最后一个SGWin Transformer block 中SGW-MSA 的3 个自注意力的热力图进行可视化对比.融合效果示意图如图9 所示. 图9 融合效果示意图Fig.9 Schematic diagram of fusion effect 图9 展示了各部分注意力机制的输出结果.可以看到每一种注意力的关注部分都有所不同.Shuffled W-MSA 建立固定距离的窗口连接,对跳跃的关注目标和周围信息的联系比较敏感.VGWMSA 建立纵轴上任意距离的窗口连接,对目标和纵向背景之间的联系比较敏感.HGW-MSA 建立横轴上任意距离的窗口连接,更关注目标和横向背景之间的联系.因此,相比于单一的局部自注意力机制,SGW-MSA 通过融合3 种自注意力机制的方式,具有更优秀的上下文信息提取能力. 2.3.1 CIFAR10 图像分类实验 CIFAR10 数据集包含60000 张尺寸为 32 的彩色图片,分为10 个类别,每一个类别有6000 张图像.分为训练集50000 张,测试集10000 张.本文在训练集上训练模型,并用测试集测试输出的Top1 准确率(排名第一的类别与实际结果相符的准确率).在训练模型时,采用PyTorch 深度学习框架和Timm 图像分类库,优化器采用了对超参数不敏感的AdamW[42],学习率采用余弦退火[43]的方式,初始的学习率设置为 1 ×10-3,最小学习率为1×10-6,warmup 学习率为 1 ×10-4,warmup Epoch设置为3,权重衰减率为 2 ×10-5,动量为0.9,数据增强采用随机裁剪和水平随机翻转.训练总轮数为130 Epoch,在120 个Epoch 之后保持最低学习率继续训练10 Epoch.损失函数采用标准的交叉熵分类损失函数.在不使用预训练模型的情况下,所有的模型均在一张RTX2070 的GPU 上训练,基础配置采用表1 中的配置.因为CIFAR10 数据集中的图像较小,所以配置中的窗口大小Si设置为3;4 个阶段的通道数Ci分别对应 [32,64,128,256];4 个阶段Transformer block 的Head 数量Hi分别设置为[2,4,8,16];SGWin Transformer 的基础元素块的宽度Wb设置为1.表4 展示了参与对比的模型在CIFAR10 数据集上的实验结果.可以看出本文所设计的SGWin Transformer 在参数量相当的情况下的性能明显优于现有具有代表性的其他基于局部自注意力的Transformer 模型.Top1 准确率比目前最先进的Pale Transformer 提升0.41%,相比于基线算法Swin Transformer,SGWin Transformer 在参数量相同的情况下,仅仅通过替换SWMSA 为SGW-MSA 就达到了5.2%的提升,验证了本文设计的SGW-MSA 的有效性. 表4 CIFAR10 数据集上的Top1 精度对比Table 4 Top1 accuracy comparison on CIFAR10 dataset 2.3.2 mini-imagenet 数据集上的实验 本文还在mini-imagenet 数据集上进行了实验.mini-imagenet 数据集包含60000 张图像,分为100 个类别,每张图像的宽高中的长边均为500 个像素,每个类别的图像大约有6000 张.将50000张图像作为训练集,10000 张图像作为验证集,训练模型的设置基本与第2.3.1 节中的CIFAR10 数据集相同,不同的是模型的超参数配置采用表1 中的配置,训练的Epoch 数为100.SGWin Transformer的基础元素块的宽度Wb设置为4.表5 展示了参与对比的模型在mini-imagenet 数据集上的实验结果.从表5 中的结果可以看出本文算法相比于基线Swin Transformer 提升了5.1%,同时比最先进的Pale Transformer 提升了0.67%.证明了SGW-MSA的有效性. 表5 mini-imagenet 数据集上的Top1 精度对比Table 5 Top1 accuracy comparison on mini-imagenet dataset 2.4.1 MS COCO 数据集上的实验结果 本文使用mmdetection 库以及Mask R-CNN目标检测框架,将主干网络替换为所有具有代表性的基于局部窗口自注意力的Transformer 模型,并与本文的方法进行了对比,采用AdamW 优化器更新网络参数,训练周期为36 Epoch,设置初始学习率为 1 ×10-4,在第27 Epoch 和33 Epoch 结束之后分别衰减10 倍.所有的模型均不使用预训练模型.实验结果如表6 所示.其中Params (M)代表模型的参数量,FLOPs (G)代表模型的计算复杂度.可以看出本文提出的SGWin Transforemr 算法达到了45.1%的mAP,相比于目前最先进的Pale Transformer 模型提升1.8%,并且在参数量不变的情况下比基线算法Swin Transformer 提升了5.5%.此外,SGWin Transformer 在实例分割上也具有一定的提升,比最先进的Pale Transformer 提升了1.3%,比基线算法Swin Transformer 提升了4.2%,也验证了本文提出的SGW-MSA的有效性.此外使用mmdetection 库以及Cascade R-CNN[44]目标检测框架,除训练周期外实验配置如同上述的Mask RCNN,训练周期设置为11 Epoch,初始学习率为1×10-4,在第8 Epoch和11 Epoch 结束后分别衰减10 倍.实验结果如表7所示.本文提出的SGWin Transformer 算法达到42.9% (APb)和37.8% (APm),相比于Pale Transformer 模型分别提升了1.4%和1.7%,并且在参数量不变的情况下比基线算法Swin Transformer 分别提升了5.1%和4.4%.证明了SGWMSA 的有效性. 表6 以Mask R-CNN 为目标检测框架在MS COCO 数据集上的实验结果Table 6 Experimental results on MS COCO dataset based on Mask R-CNN 表7 以Cascade R-CNN 为目标检测框架在MS COCO 数据集上的实验结果Table 7 Experimental results on MS COCO dataset based on Cascade R-CNN 为了更直观地展示SGWin Transformer 的有效性,本文选取MS COCO 测试集的图像进行检测并将结果进行可视化,如图10 所示.以Cascade RCNN 为目标检测框架,分别将Swin Transformer以及SGWin Transformer 作为主干网络进行检测.从图中可以看出,SGWin Transformer 相比于基线算法检测到了更多的小目标(如图10(a)中心的人和车,如图10(b)中心处的绵羊)和遮挡目标(图10(c)最下边的游艇,图10(d)泳池中的人).证明了SGWMSA 能够通过提取更多的上下信息来提高遮挡目标和小目标的检测效果. 图10 MS COCO 检测结果或可视化Fig.10 MS COCO test results or visualization 2.4.2 在其他目标检测数据集上的实验结果 本文还在KITTI 数据集和PASCAL VOC 数据集上进行了对比实验,使用PyTorch 深度学习框架以及YOLOv5[45]目标检测架构,采用SGD[46]优化器,学习率采用余弦退火的方式,初始学习率设置为0.01,最小学习率为 1 ×10-6,warmup 学习率为0.1,warmup 学习率为0.1,warmup Epoch 为3,权重衰减为 5 ×10-4,动量为0.937,数据增强采用Mosaic[47]、水平翻转和色调变换.在3 张RTX3090的GPU 上训练模型,超参数采用表1 中的配置.采用上述的训练策略,所有的算法均不使用预训练模型,在PASCAL VOC 数据集上训练100 Epoch,在KITTI 数据集上训练300 Epoch,训练Batch size 数为64,实验结果如表8 所示.可以看出在模型参数量相当的情况下,本文提出的SGWin Transformer 模型在KITTI 数据集和PASCAL VOC 数据集的精度比最先进的Pale Transformer 分别提升了0.3 和0.6,比基线算法Swin Transformer 分别提升了1.9 和4.5.在检测速度方面,SGWin Transformer 的FPS 达到了56,超出最先进的Pale Transformer 算法16%,相比于基线算法Swin Transformer 提升了12%.所以本文设计的SGWin Transformer 在速度和精度上都优于其他Transformer,整体性能最好. 本文针对现有的基于局部自注意力机制的Transformer 模型不能建立所有窗口之间信息流通的问题,提出了一种SGW-MSA 局部自注意力以及SGWin Transformer 模型,在SGW-MSA 中结合3 种不同的局部自注意力机制的特点,有效地建立所有窗口之间的信息交互.实验结果表明在参数量和计算量相当的情况下,本文提出的算法比现有的基于局部自注意力的Transformer 模型更具有优势,证明了本文提出的SGW-MSA 通过高斯随机窗口策略建立所有窗口之间的信息流动能够捕捉更多的特征图语义信息并且具有更强大的上下文建模能力. 表 8 KITTI 和PASCAL VOC 数据集上的实验结果Table 8 Experimental results on KITTI and PASCAL VOC dataset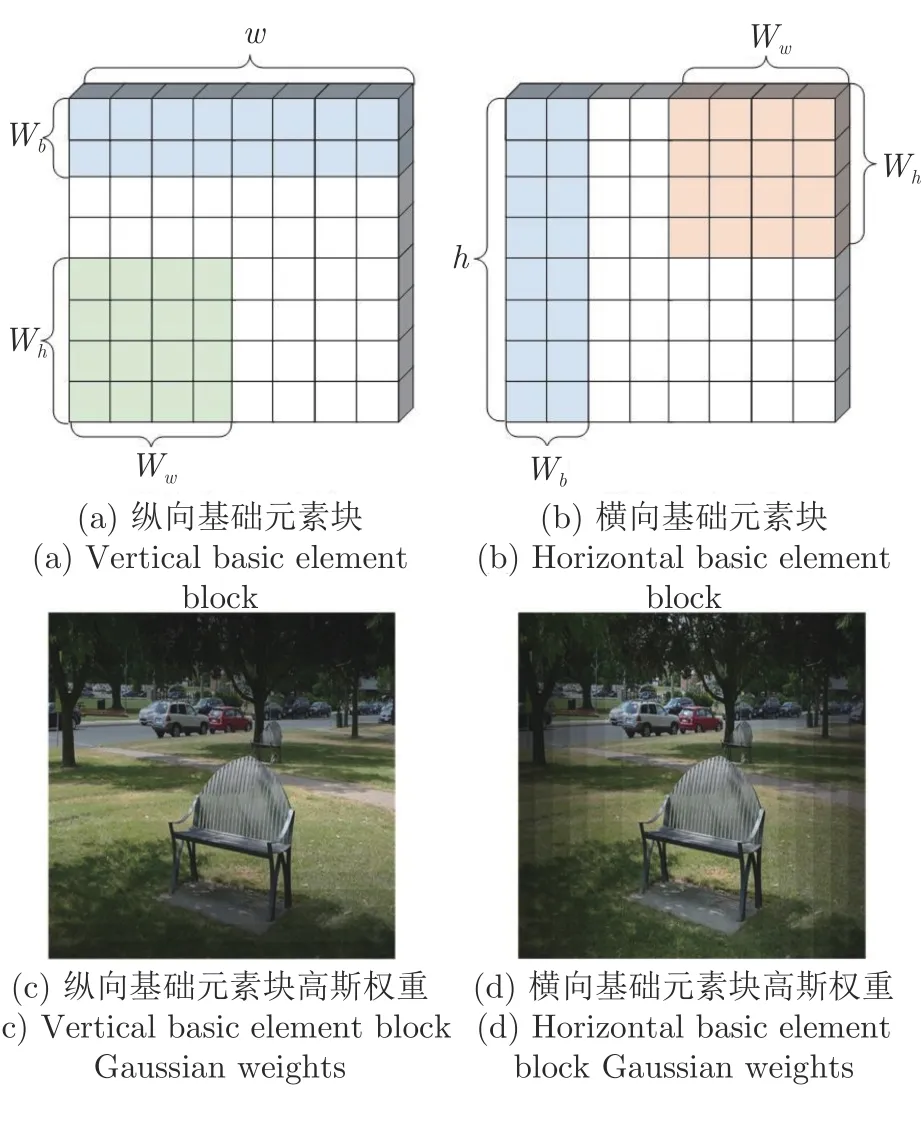
1.4 SGWin Transformer block
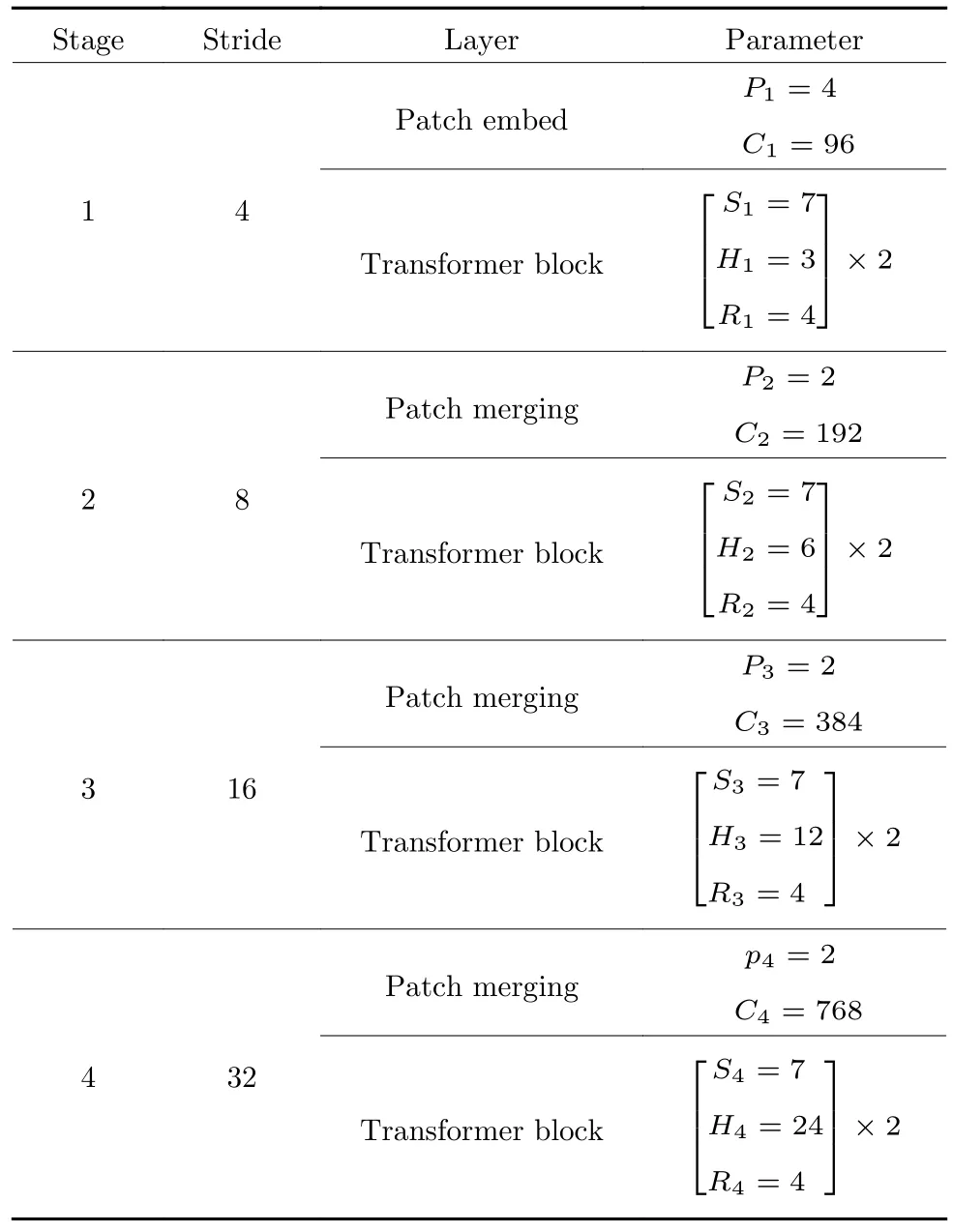
1.5 SGWin Transformer 的超参数配置
2 实验结果
2.1 热力图对比实验分析

2.2 消融实验分析
2.3 图像分类实验

2.4 目标检测实验



3 结论