Transformer驱动的图像分类研究进展
2023-09-26石争浩李成建周亮张治军仵晨伟尤珍臻任文琦
石争浩,李成建*,周亮,张治军,仵晨伟,尤珍臻,任文琦
1.西安理工大学计算机科学与工程学院,西安 710048;2.中山大学网络空间安全学院,深圳 518107
0 引言
图像分类旨在识别图像中存在目标对象所属具体类别,是图像处理和计算机视觉领域的重要研究方向,具有重要实际应用价值。然而由于实际应用中,图像目标的形态、类型多样,且成像环境复杂,现有方法的分类效果却总是差强人意,存在分类准确性低、假阳性高等问题,严重影响其在后续图像及计算机视觉相关任务中的应用。因此,如何通过后期算法提高图像分类的精度和准确性,具有重要研究意义,受到越来越多的关注。
在近十几年间,由于优异的特征提取能力,以卷积神经网络(convolutional neural network,CNN)及其变体,如VGGNet(Visual Geometry Group network)(Simonyan 和Zisserman,2015)、Inceptions(Szegedy等,2015)、ResNet(X)(residual network)(He 等,2016;Xie 等,2017)、DenseNet(densely connected convolutional network)(Huang 等,2017)、MobileNet(Howard 等,2017)、EfficientNet(Tan 和Le,2019)、RegNet(Parmar 等,2019)和ConvNeXts(Liu 等,2022a)等为代表的深度学习技术广泛应用于各种图像处理任务,取得了较好的处理效果。作为后起之秀,在自然语言处理领域大放异彩的Transformer(Vaswani 等,2017)模型,由于较强的远距离建模和并行化序列处理能力,逐渐引起图像处理和计算机视觉领域研究者的兴趣,并在目标检测(Carion 等,2020)、语义分割(Wang 等,2021a)、目标跟踪(Chen等,2021a)、图像生成(Jiang 等,2021)和图像增强(Chen 等,2021b)等应用中表现出良好的性能。ViT(vision Transformer)(Dosovitskiy 等,2021)是Google团队提出的第一个利用堆叠的 Transformer 编码器代替传统CNN 的网络模型。相较于传统CNN,ViT通过将输入图像划分为一个个的图像块(Patch),实现对待处理图像的全局建模和并行化处理,极大提升了模型的图像分类能力。然而,尽管ViT 模型在图像处理和计算机视觉应用中已取得了很好成效,但研究(Guo等,2022)发现,与目前最先进的CNN 模型相比,现有ViT 模型在视觉任务中的表现仍存在差距。分析其原因,主要有:1)绝对位置编码导致现有模型可扩展性能差;2)自注意力机制与分辨率计算上呈二次方关系带来高昂的计算开销;3)缺乏归纳偏置导致数据饥饿和收敛速度慢问题;4)深层Transformer存在注意力崩溃问题。
针对上述问题,研究者开展了更为深入的研究,并先后推出数篇关于Transformer 的技术综述。Tay等人(2023)回顾了Transformer 的效率;Khan 等人(2022)和Han 等人(2023)总结了一些早期的视觉Transformer 和一些注意力模型;Lin 等人(2022)提供了对Transformer 的各种变体的系统评论,并粗略地给出了Transformer在不同视觉任务中的应用;Liu等人(2022b)提出根据动机、结构和使用场景组织这些方法;Xu 等人(2022)根据任务场景对它们进行分类。
与以上综述不同,为了使读者对最新研究进展有一个更为全面、更为系统、更为深入的了解,紧跟最新研究进展,本文对2021年和2022年发表的各种Transformer驱动的深度学习图像分类方法和模型进行了系统梳理,重点对ViT 变体驱动的图像分类方法进行了归纳和总结,包括可扩展的位置编码、低复杂度和低计算代价、局部信息与全局信息融合以及深层ViT模型等。本文主要贡献如下:
1)分类总结近年来Transformer驱动的深度学习图像分类方法和模型,介绍各类方法的核心思想,分析存在的问题及可能的解决方案;
2)系统梳理Transformer驱动的深度学习图像分类任务需要解决的关键性科学问题,并对未来的研究方向及发展趋势进行展望。
1 传统Transformer
Transformer(Vaswani 等,2017)最早应用在序列到序列的自然语言处理自回归任务中,其整体架构为 encoder-decoder 结构,其中编码部分采用多头自注意力机制(multi-head self-attention,MHSA)实现全局信息的提取,随后采用前馈神经网络(feedforward network,FFN)来完成维度的变换和提取更丰富的语义信息。本节先介绍注意力机制和多头注意力机制,然后介绍前馈神经网络和位置编码,最后给出传统Transformer的模型结构。
1.1 注意力机制和多头注意力机制
注意力机制是Transformer 的重要组成部分,其整体结构可以分为线性映射模块和注意力模块两部分。
线性映射模块的作用是将输入序列X和Y映射成其投影Q、K和V。给定输入序列X和Y,其中X∈Rn×d,Y∈Rn×d,n表示输入序列长度,d代表输入数据的维度。令Q表示X投影,K和V表示Y的投影。其数学表述为
式中,WQ∈,WK∈和WV∈分别表示不同的线性矩阵;dq,dk,dv分别代表经过特征映射后的Q,K,V的序列维度。当Y=X时,dq=dk=dv,注意力机制也变为自注意力机制。这种机制由于减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。
注意力模块的作用是显式地将查询Q与对应的键K进行相似度计算获得注意力权重,根据权重矩阵为V分配关注度权值,并更新输出向量,其数学表述为
由于特征子空间的限制,单头注意力机制的建模能力通常较差。为此,Vaswani等人(2017)提出多头注意力机制,即将输入矩阵线性映射到由多个独立注意力头组成的特征子空间中进行点乘运算,随后拼接特征向量和线性映射得到最终输出,具体为
式中,i代表头的序号,head代表头的个数,fConcat代表拼接,WO代表输出映射矩阵。多头注意力将输入序列维度d拆分成head个维度为d/head的独立注意头,每个头完成自注意计算后进行拼接(结果定义为MH)。在不增加额外计算成本的情况下,多头注意力机制丰富了特征子空间的多样性。
1.2 前馈神经网络
在编码器和解码器结构中,前馈神经网络在Self-attention 层之后,主要由两个线性层和一个非线性激活层组成,即
式中,W1和W2是两个线性映射矩阵,b1和b2为偏移量。δ为非线性激活函数,如GELU(Gaussian error linear unit)(Hendrycks和Gimpel,2020)。
1.3 位置编码
在提取序列数据特征过程中,有效利用数据的先后顺序对于获得更好的特征表示至关重要。但Transformer 模型中的Self-attention 模块缺乏捕获数据先后顺序的能力,限制了其在序列数据处理中的应用。针对该问题,Vaswani等人(2017)将绝对位置编码引入Transformer 模型结构中,通过正弦余弦的相对位置学习,提高了Transformer 模型获取序列位置信息的能力。绝对位置编码的定义为
式中,m和j代表向量索引,pos表示序列中每个元素的位置。
为了进一步提高Transformer模型获取序列位置信息的能力,Devlin 等人(2019)、Dosovitskiy 等人(2021)和Li 等人(2022a)还提出了可学习位置编码(Gehring等,2017)、相对位置编码(Shaw等,2018)和动态位置编码。本文主要介绍可扩展的位置编码。
1.4 Transformer模型架构
Transformer 模型首先通过线性映射层对输入数据进行编码,并将输入数据与绝对位置编码相加,为输入Transformer encoder 的数据添加位置信息(此时的数据称之为Token)。然后,Tokens 集合通过编码器完成特征编码,将编码特征输入到解码器实现解码操作。最后,通过Linear 层和softmax 将数据转化为概率,完成对数据的分类。上述结构中,编码层由MHSA(multi-head self-attention)聚合编码信息,FFN(feed-forward network)层完成维度的变换和提取更丰富的语义信息。解码器通过掩码多头自注意力机制(mask multi-head self-attention,Mask-MHSA)完成对输入数据Y的有序解码,其中,交叉注意力层(cross-attention)则是编码信息和解码信息融合的关键。
除上述主干网络外,Vaswani等人(2017)还将残差网络连接(He 等,2016)和层归一化(layer normalization)(Hu等,2019)引入Transformer模型。
2 Vision Transformer
图1 按时间顺序给出了近年来Transformer 模型及其在图像处理应用中的研究发展演化过程。由图1 可见,基于Transformer 模型的图像处理方法已经成为近年图像处理的主流研究方法。

图1 Transformer研究演化进程Fig.1 The evolution of research on Transformer and its application in image classification
本节首先介绍传统的ViT模型,然后根据ViT面临的问题及其所采用解决策略的不同,对近年来的ViT 变体模型进行梳理总结,主要包括可扩展的位置编码、低复杂度和低计算代价、局部信息与全局信息融合以及深层ViT模型,如图2所示。

图2 基于视觉Transformer的变体分类Fig.2 Visual Transformer-based variant classification
2.1 ViT
ViT模型的整体结构如图3所示,首先将输入图像I∈RH×W×3划分为一个个不重叠的图像块,其维度为x∈,这里H和W分别代表图像的高与宽,3代表输入图像的通道数,P代表了Patch 块的高和宽,N代表了根据高和宽为P的尺寸划分图像块的个数。然后,将图像块线性映射为Tokens 集合,此时的维度为x∈RN×C,C为映射的Hidden Embedding。再后,为Tokens 集合添加绝对位置编码以保证输入Tokens 之间的空间位置信息和添加CLS(Class Token)用于后续分类任务。最后,将Tokens经过堆叠6 层的Transformer 编码器提取特征,并取出最后一层输出的CLS进行图像分类。
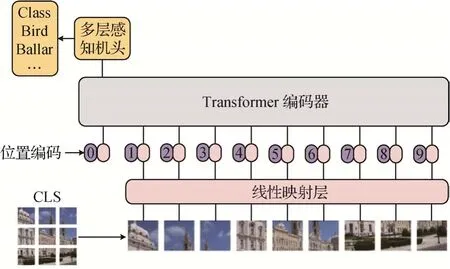
图3 ViT模型(Dosovitskiy等,2021)Fig.3 ViT model(Dosovitskiy et al.,2021)
2.2 可扩展位置编码
在传统的标准ViT 中,为确定图像块之间的先后顺序,绝对位置编码为每个图像块线性映射后的Tokens 集合添加一个唯一的位置编码,但破坏了模型提取特征的平移不变性(Kayhan 和van Gemert,2020)。针对该问题,可学习位置编码通过定义输入序列长度相同的向量与网络权重联合更新,但导致模型在测试阶段遇到更长序列时性能下降。而相对位置编码不仅带来额外的开销,而且需要修改ViT的实现方式。
由此可见,具有良好可扩展性及较小计算成本的编码方式变得非常必要。为此,先后提出了一种可扩展的位置编码和其变体CPVT(conditional position encoding vision Transformer)(Chu 等,2023)、ResT(efficient multi-scale vision Transformer)(Zhang和 Yang,2021)、Uniformer(unified Transformer)(Li等,2022a)和 CMT(convolutional neural networks neet vision Transformers)(Guo等,2022)。
CPVT(Chu 等,2023)中的位置编码方式与绝对位置编码不同,提出了一种条件位置编码,如图 4(a)所示,通过对Tokens序列进行维度变换转为一幅图像,对图像进行F操作后再转为Tokens序列,以此实现可扩展位置编码。F可以是深度卷积(depth wise convolution,DWconv)、可分离卷积(separable convolution,Sconv)或其他复杂的运算(Chu等,2023)。
ResT(Zhang 和Yang,2021)是一种多尺度的ViT,主要通过高效的多头注意力机制和基于空间注意力机制的位置编码结合,让整个模型相较于绝对位置编码方式具有更大的灵活性,可以处理任意大小的输入图像,无需插值和微调就能获得很好的实验效果。空间注意力机制(如图4(b)所示)的位置编码为

图4 可扩展位置编码Fig.4 Scalable position encoding((a)CPVT(Chu et al.,2023);(b)ResT(Zhang and Yang,2021))
式中,PA为线性映射函数,fDW为深度卷积,σ为sigmoid激活函数,x为输入Patch块的序列。
CMT(Guo 等,2022)主要致力于融合CNN 的局部信息提取和Transformer 的长距离建模能力,以此获得更高的性能。如图5 所示,在模型设计过程中,首先通过在Stem层堆叠3层卷积使得减少图像尺寸的同时增加局部信息的提取能力。随后,通过设计局部感知单元(local perception unit,LPU)来解决绝对位置编码破坏Transformer 的平移不变性问题,整个局部感知单元通过将深度卷积提取特征与原输入特征求和来实现可扩展位置编码,具体为

图5 CMT模型的核心架构(Guo等,2022)Fig.5 Core architecture of the CMT model(Guo et al.,2022)
式中,fDW表示深度卷积,x为输入Patch序列。
再后,为缓解Transformer高昂计算代价问题,设计了轻量级多头注意力(lightweight multi-head selfattention,LMHSA),将大卷积核的深度可分离卷积应用到K,V上,减少尺寸降低计算量。最后,在原始逆残差结构基础上,逆残差前馈神经网络(inverted residual feed-forward network,IRFFN)通过改进残差路线提升梯度在本层的传播能力。
Uniformer(Li 等,2022a)与CMT(Guo 等,2022)类似,都通过堆叠多层卷积实现局部特征的提取和降低分辨率。此外,在位置编码上将经过深度卷积后的数据与线性变化后的数据进行相加,来完成可扩展的位置编码,如式(11)所示。
基于可扩展位置编码的ViT 模型及其特点如表1所示。

表1 基于可扩展位置编码的ViT模型Table 1 ViT model based on scalable positional coding
2.3 低复杂度和低计算代价
由于采用softmax 作为注意力分数概率化的Self-attention与编码后的Tokens数量呈二次方关系,ViT 的计算复杂度为Ω(2(hw)2C+4hwC2)。其中,Ω 为计算复杂度,h与w为Patch 的高和宽,C为每个块的维度。在自然语言处理(natural language processing,NLP)任务中,虽然Wang 等人(2020)和Wu等人2021)引入了线性注意力来缓解此类问题,但将NLP 领域设计的线性注意力直接应用于ViT 中,效果并不理想。因此,一种基于计算机视觉领域降低Self-attention 或整个Transformer encoder 计算复杂度的模型是必要的。为了从图像处理的基本属性出发降低ViT 的计算复杂度,以Swin Transformer(hierarchical vision Transformer using shifted windows)(Liu等,2021)为代表的许多工作,对于低复杂度模型进行研究。代表性工作有VOLO(vision outlooker)(Yuan 等,2021a)、CSwin Transformer(cross-shaped window Transformer)(Dong 等,2022)和VVT(vicinity vision Transformer)(Sun等,2022)。
Swin Transformer(Liu 等,2021a)将图像划分为一个个Patch 后,先在Patch 内部进行自注意力机制运算,通过Patch 的划分与合并,实现空间缩减和通道扩充任务,这种方法称为Window attention。然后,沿着空间维度移动窗口来对全局信息和边界信息进行建模,此方法称为Shift attention。两者在模型搭建过程中顺次交替进行局部和全局信息的提取。Swin Transformer 中引入Window attention 后复杂度缩减为Ω(2M2hwC+4hwC2)。其中,M为Patch 中再次划分子Patch 的高和宽。Swin Transformer 核心架构如图6所示,其中,l层为Window attention,l+1层为Shift attention,l为层数。
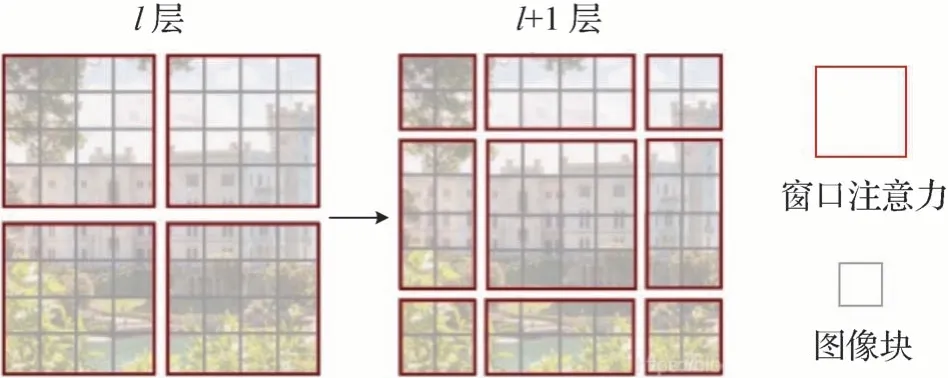
图6 Swin Transformer的核心架构(Liu等,2021)Fig.6 Core architecture of Swin Transformer(Liu et al.,2021)
VOLO(Yuan 等,2021a)采用了两阶段的架构设计。首先,通过Outlooker 生成精细级的Token 表示。然后,堆叠多层Transformer 模块聚合全局信息。其核心模块Outlooker 由实现空间信息编码的Outlook attention 和通道信息交互的多层感知机(multi-layer perceptron,MLP)组成。如图7 所示,对于图像上的每个空间位置(wi,hj),其中wi代表横坐标,hj代表纵坐标,Outlook attention 首先将输入特征图通过线性映射后划分为若干个以(wi,hj)为中心、Ws×Ws大小的局部窗口,计算每个中心点与局部窗口内的所有邻居的相似度。随后通过Reshape 操作和softmax 激活函数获得注意力权重矩阵(如图7中绿色虚框和黑色虚框所示),并将其作为以(wi,hj)为中心的局部窗口内所有值组成的V的权重(如图7 中的Linear+Unfold)。最后,将来自V的不同局部窗口同一位置的不同加权值求和得到最终输出(如图7 中的Fold 操作)。Outlook attention 相较于多头自注意力计算量与Tokens 数量呈现二次方关系而言,通过Reshape 操作简化了求解注意力的流程,并在一定程度上保留了视觉任务的关键位置信息(Hou 等,2021;Hu 等,2019)。计算复杂度缩减为Ω(hwC(2C+head(Ws)4)+hwC(Ws)2)。其中,Ws为滑动窗口大小。
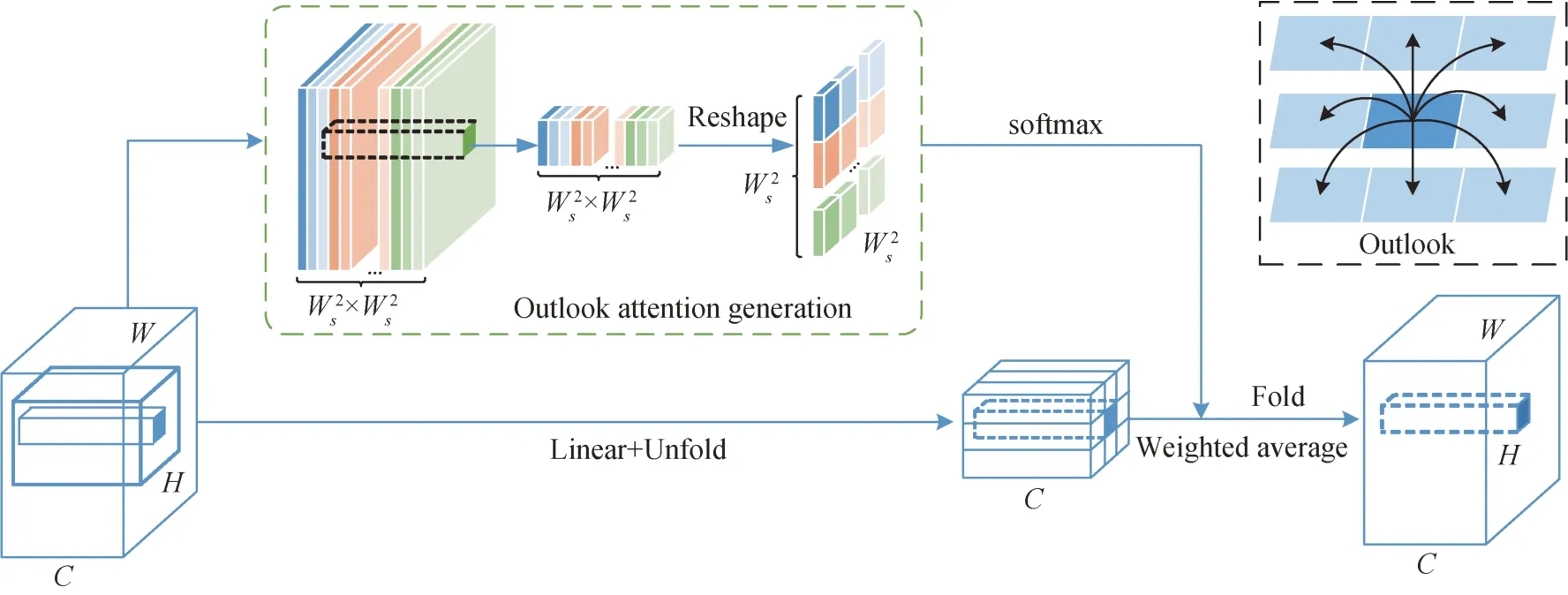
图7 Outlook attention的整体架构(Yuan等,2021a)Fig.7 The overall architecture of Outlook attention(Yuan et al.,2021a)
CSwin Transformer(Dong 等,2022)为了在减小计算量的同时解决Swin Transformer 中窗口注意力的Token 之间信息交互受限问题,提出一种十字形窗口自注意力机制。该注意力机制通过平行水平和垂直条纹来实现自我注意,形成十字形窗口,扩大感受野提升Token 之间的信息交互能力。计算复杂度缩减为Ω(HWC×(4C+Sw×H+Sw×W)),Sw是超参数,每层Sw为[1,2,7],前期小后期大是为了增加CSwin 的感受野,并使计算复杂度控制在可接受范围内。
VVT(Sun 等,2022)提出了Vicinity attention,在具有线性复杂度的ViT 中引入局部偏差。具体来说,对于每个划分的图像块,根据其相邻块测量的2D 曼哈顿距离调整其注意力权重。在这种情况下,邻近的Patch将比远处的Patch受到更多的关注。此外,由于Vicinity attention 需要的Token 数量远大于特征维度,VVT模型在不降低分类准确率的情况下,模型计算复杂度从Ω(2(hw)2C+4hwC2) 缩减为Ω(hw(2C)2+2C2),(2C)2≪(hw)2。
基于低复杂度和低计算代价的ViT 模型及其特点如表2所示。

表2 基于低复杂度和低计算代价的ViT模型Table 2 ViT model based on low complexity and low computational cost
2.4 局部与全局信息融合
本节从问题和架构设计两个角度组织叙述逻辑,分“数据饥饿”问题、CNN 与Transformer 结合和纯Transformer架构3个部分展开。
2.4.1 “数据饥饿”问题
“数据饥饿”问题(Hassani等,2022b)是指ViT模型从头开始训练到模型收敛性能达到与CNN 一样好或更好的效果所需的数据量规模更大。Selfattention 是ViT 模型提取全局信息获得远距离建模能力的关键,但这种模型设计缺乏CNN 中所固有的归纳偏置,如平移不变性和局部性。导致模型训练过程中所需数据量更大,收敛速度在相同数据量的情况下相对于CNN 模型速度更慢。虽然随着数据量的增大可以使得模型收敛并取得更好的效果,但针对一些研究领域,由于数据集标记比较困难,导致数据量较小。在这种情况下,模型的处理性能和收敛速度都不能达到令人满意的效果。因此,DeiT(data-efficient image Transformers)(Touvron 等,2021a)、SLViT(vision Transformer for small-size datas-ets)(Lee等,2021)和CCT(compact convolutional Transformer)(Hassani 等,2022b)从解决数据饥饿问题出发设计模型。
DeiT(Touvron等,2021a)为了缓解ViT模型对于大数据集的依赖,通过引入数据增强和正则化策略,在ImageNet 上获得了81.8%的准确率。此外,在训练中,DeiT 使用知识蒸馏策略,将训练好的CNN 模型作为老师,Transformer 模型作为学生,在CNN 模型的指导下为Transformer模型带来了归纳偏置。基于这种蒸馏策略在不借助外部数据的情况下获得了83.4%的准确率,既说明了蒸馏策略的有效性,也说明归纳偏置的添加对于提升ViT 模型性能和解决数据饥饿问题是有效的,如图8 所示,其中Class Token负责模型分类,Distillation负责知识蒸馏引入归纳偏置,LCE代表学生模型分类交叉熵损失,Lteacher代表老师模型损失。

图8 DeiT模型(Touvron等,2021a)Fig.8 DeiT model(Touvron et al.,2021a)
SLViT(Lee 等,2021)从ViT 在小数据集训练慢、效果差现象的本质出发,提出了一种新的基于空间特征平移的标记化方法(shifted patch tokenization,SPT)。此外,为了解决注意力分数分布平滑问题,Lee 等人(2021)还提出了局部自注意力机制(locality self-attention,LSA),在仅增加少量参数和简单操作的情况下显著提升了ViT的性能。
CCT(Hassani 等,2022b)为了解决数据饥饿问题提出了一种新型的序列池化操作,使得模型消除了对于Class Token和位置编码的依赖。整个模型小而灵活,在参数量0.28 M 的情况下即可取得很好的效果。序列池化操作为
式中,g为线性映射层,Xl∈Rn×d为Transformer 第l层的输出,∈R1×n为通过通道注意力后的特征,z为分配权重后的输出特征。整个流程如下:首先,将Xl输入到线性映射层g(Xl)∈Rd×1,并使用softmax 激活函数进行归一化和概率化。随后,将计算的概率与Xl相乘获得z,并通过池化层移除z中的第2个维度,此时z∈Rd。最后,将z输入到线性层进行分类或其他工作。
基于解决“数据饥饿”问题的ViT 模型及其特点如表3所示。

表3 基于解决“数据饥饿”问题的ViT模型Table 3 Based on the ViT model to solve the “data hunger” problem
2.4.2 CNN与Transformer结合
由于Transformer 强大的全局信息提取能力,在不同的领域取得了很大的成就,有力地推动了NLP和计算机视觉工作的发展。但由于缺乏归纳偏置,收敛速度慢,信息利用不充分。CNN 因其具有的局部性和平移不变性,能够很好地提取局部信息,但其感受野受限(刘启超 等,2021),在一定程度上限制了卷积神经网络在大数据集上的吞吐量和提取能力。SLaK(sparse large kernel network)(Liu 等,2023)、RepLKNet(revisiting large kernel design in CNNs)(Ding 等,2022)和ConvNeXt(a convnet for the 2020s)(Liu 等,2022a)提出采用大卷积核策略扩大模型感受野,但带来了更高的计算代价,且视野范围小于自注意力机制。为了更充分地利用有效信息,弥补两种模型的缺陷,Xiao 等人(2021)提出了将卷积与ViT 结合的模型(Early Conv)。该模型的实验结果证明了两种模型的联合对增强特征提取能力具有重要意义(孙旭辉 等,2023)。
目前,CNN 与Transformer 的结合,主要有3 种模式,即CNN+Self-attention、串行机制和并行机制。其中,CoTNet(contextual Transformer networks)(Li 等,2023)、LG-Transformer(local-to-global Self-attention in vision Transformers)(Li 等,2021a)和BoTNet(bottleneck Transformers for visual recognition)(Srinivas等,2021)等都采用CNN+Self-attention 模式。该模式通过堆叠多层卷积提取局部信息,在分类前一层添加Self-attention 及其变体以增强模型的全局信息提取能力。最终实现局部信息与全局信息的融合。
基于CNN+Self-attention 的模型架构图如图9所示。本文以BoTNet 模型作为CNN+Self-attention模式的代表进行阐述。

图9 CNN+Self-attention模型架构Fig.9 CNN+Self-attention model architecture
BoTNet(Srinivas 等,2021)提出了一种all2all attention 机制,相较于原始的Self-attention 通过Token 的序列化表示,所提出的注意力直接作用于2D 特征图,并在Self-attention 的基础上添加了内容—编码和内容—内容的交互。其中,内容—编码的信息交互主要通过定义高和宽的相对位置编码来表达特征之间的相对距离,并通过与Q计算注意力得分获得Q中所查询对象在图像中的位置信息;内容—内容的交互与原始的自注意力一致,将线性映射的Q和K进行内积获得内容之间的相关关系。随后,将内容—编码和内容—内容得分进行求和并通过与V的运算获得交互后的位置和内容信息,以提高模型全局定位和分类能力,模型如图10 所示。当应用于图像分类任务中时,先将所设计的all2all attention 模块替换残差结构中的3 × 3 卷积,以获得具有全局建模能力的残差结构。然后,将该残差结构堆叠多层替换ResNet 架构的最后一个stage,以实现局部信息与全局信息交互,增强模型分类性能。
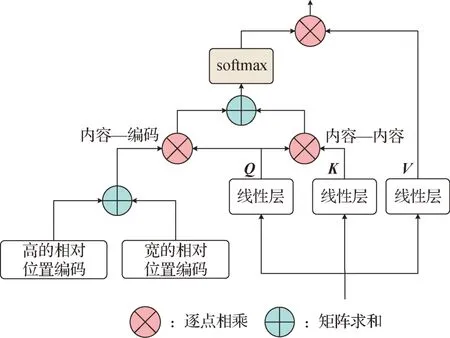
图10 BoTNet中all2all attention整体架构(Srinivas等,2021)Fig.10 Overall architecture of all2all attention in BoTNet(Srinivas et al.,2021)

图11 GPSA模型块(Dai等,2021)Fig.11 GPSA model block(Dai et al.,2021)
基于CNN+Self-attention 的模型及其特点如表4所示。

表4 基于CNN+Self-attention的模型Table 4 CNN+Self-attention-based model
串行机制主要是将CNN 模型添加到Transformer 的不同位置,为模型增加局部信息提取能力。如CNN 进行位置编码、CNN 将Patch 编码为Token,亦或是将ViT 中的线性层变为卷积层或添加一些其他的注意力机制。
DeiT 通过使用知识蒸馏策略为Transformer 引入归纳偏置。CCT 通过将卷积与Transformer结合完成局部和全局信息融合的同时利用蒸馏的方式增强CCT性能。上述两个模型既是数据饥饿问题的解决方法,也是串行机制的经典模型。除了通过上述方法为模型添加软归纳偏置外,串行机制还包括如下3类:
1)位置编码或Patch 编码中添加CNN 引入归纳偏置。如CPVT、ResT、CMT、MobileViT(light-weight,general-puprose and mobile-friendly vision Transformer)(Mehta 和Rastegari,2022)和GC ViT(global context vision Transformers)(Hatamizadeh 等,2023)、MFT(multimodal fusion Transformer)(Roy 等,2022)、MCT(multiscale convolutional Transformer)(Jia 等,2022)、CTN(convolutional Transformer network)(Zhao等,2022)、DHViT(deep hierarchical vision Transformer)(Xue 等,2022)、DSS-TRM(deep spatialspectral Transformer)(Liu等,2022c)等。
2)自注意力模块添加CNN。如CoAtNet(convolution and Self-attention)(Dai 等,2021)、ConViT(improving vision Transformers with soft convolutional inductive biases)(D’Ascoli 等,2021)、CvT(convolutional vision Transformer)(Wu 等,2021b)、CMT(Guo等,2022)、PVTv1(pyramid vision Transformer)(Wang等,2021b)、PVTv2(improved baselines with pyramid vision Transformer)(Wang 等,2022)、MViTv1(multiscale vision Transformers)(Fan 等,2021)、MViTv2(improved multiscale vision Transformers for classification and detection)(Li 等,2022b)、EdgeViTs(light-weight Transformers)(Pan 等,2022)、EdgeNeXt(efficiently amalgamated CNN-Transformer architecture for mobile vision applications)(Maaz 等,2022)、ScalableViT(scalable vision Transformer)(Yang 等,2022)等。
3)MLP 或FFN 中添加深度可分离卷积为ViT 引入归纳偏置。如LeViT(a vision Transformer in convnet’s clothing for faster inference)(Graham 等,2021)、CMT、GLiT(global local image Transfomer)(Chen 等,2021c)、LocalViT(bringing locality to vision Transformers)(Li 等,2021b)、CeiT(convolutionenhanced image Transformer)(Yuan 等,2021b)、PiT(pooling-based vision Transformer)(Heo等,2021)等。
在类型1)中,CPVT 和ResT 通过使用深度卷积神经网络实现可扩展位置编码的设计,将CNN 的归纳偏置引入到ViT 中。CMT 的设计不仅在编码阶段使用深度卷积作为可扩展位置编码的一部分,在自注意力机制和FFN中都使用CNN来帮助ViT模型引入归纳偏置提高模型的收敛速度。
MobileViT(Mehta 和Rastegari,2022)主要致力于将轻量级卷积与Transrformer 结合应用于移动端,网络模型采用类似于UNet的网络架构。首先,通过n×n的卷积提取局部信息,将特征序列化后输入ViT 完成全局信息的提取。其中,ks为卷积核大小。然后,通过卷积操作升维和残差连接完成局部信息和全局信息融合。
GC ViT(Hatamizadeh 等,2023)提出一种全局Token 生成模块,利用卷积的方式产生全局Token,将生成的Token 作为全局自注意力机制的Q完成全局信息提取。局部注意力与全局注意力交替提取局部和全局信息。
MFT(Roy 等,2022)提出多模态信息融合方案。首先,将高光谱图像(hyperspectral image,HSI)信息作为输入Transformer 的Patch token,激光雷达(light detection and ranging,LiDAR)合成图像与高光谱图像对应位置的图像信息作为CLS。随后,对高光谱图像的Patch token 和CLS 通过CNN 进行标记化,将标记化后的Token 输入到Transformer 模型提取全局信息。最后,通过跨Patch的注意力实现两种模态信息的交互,完成局部和全局信息融合。
MCT(Jia 等,2022)提出一种多尺度卷积Transformer,可以有效捕获局部与全局空间光谱信息。此外,还定义了一个自监督预置任务,使得骨干网络在自监督学习过程中有效地建模中心像素点与邻域像素的关系。
CTN(Zhao等,2022)通过设计中心位置编码,将位置和光谱特征相结合生成空间位置特征,并使用卷积Transformer 将局部信息与全局信息融合,提高模型的分类性能。
DHViT(Xue等,2022)利用光谱序列Transformer沿光谱维度从高光谱图像中提取特征,捕获光谱长期依赖。并通过CNN 和Transformer 结合的空间层次Transfromer 提取HSI 和LiDAR 图像中的空间特征。最后,堆叠多层交叉注意力机制自适应融合多模态信息实现高光谱图像的分类。
DSS-TRM(Liu 等,2022c)提出了一种局部—全局信息融合和空间光谱交互的Transformer模型。该模型中,两个注意力机制通过二维卷积实现Patch的编码。其中,空间注意力提取高光谱图像的空间特征,光谱自注意力负责光谱维度的信息交互。最后,通过将两种注意力提取的特征进行拼接输入到分类器完成图像分类。
在类型2)中,CoAtNet(Dai等,2021)提出了一种将深度卷积与自注意力机制有效结合的垂直堆叠方式,在提高泛化性、容量和效率方面取得了惊人的成果。ConViT(D’Ascoli 等,2021)提出一种门控位置自注意力(gated positional self-attention,GPSA)模块。模块分为两个分支:Wq和Wk用于全局建模,Trpos提取局部信息。为了进行局部信息和全局信息的平衡,引入一个可学习参数λ,对CNN 和Self-attention占比进行动态调节,如图 11所示,r代表相对位置编码,Awi,hj为注意力矩阵。CvT(Wu 等,2021b)模型采用CNN 代替线性映射层和Self-attention 中的Linear以构建卷积ViT。
PVTv1(Wang 等,2021b)主要是对自注意模块进行改进,即将Linear 层设计为空间收缩注意力(spatial reduction attention,SRA),在降低空间分辨率的同时加深模型深度类似于MaxPooling,实现金字塔结构以利用空间信息。PVTv2(Wang 等,2022)针对PVTv1 中存在的问题做出3 点改进:1)采用卷积提取连续特征;2)带Zero-padding的重叠块嵌入提取位置信息的编码;3)均值池化的注意力层。相对于PVTv1,PVTv2 更能充分利用局部和全局信息,以提升模型的性能。
MViTv1(Fan 等,2022)提出了一种Pool attention,在整个注意力中对Q、K、V进行池化操作,降低输入图像分辨率,从而减少序列长度,降低计算量,使得模型能够应对不同时空分辨率的输入。
MViTv2(Li 等,2022b)采用池化操作来增强模型的空间建模能力,同时又利用多尺度信息提高模型性能。MViTv2 提出了Improved pooling attention,如图12 所示。该注意力模型采用与MViTv1 中相同的池化操作来进行特征降维,降低参数量。此外,为了解决MViTv1 使用绝对位置编码忽略平移不变性的问题和增强池化模块的训练,MViTv2 在MHPA 中添加相对位置编码指导K获知所处位置,Q处添加残差池化连接与Self-attention后的信息融合,增强了信息流,便于池化模块的训练。最后,通过线性层和池化层完成全局信息建模,同时在模型Patch 转Token中使用CNN提取局部信息。
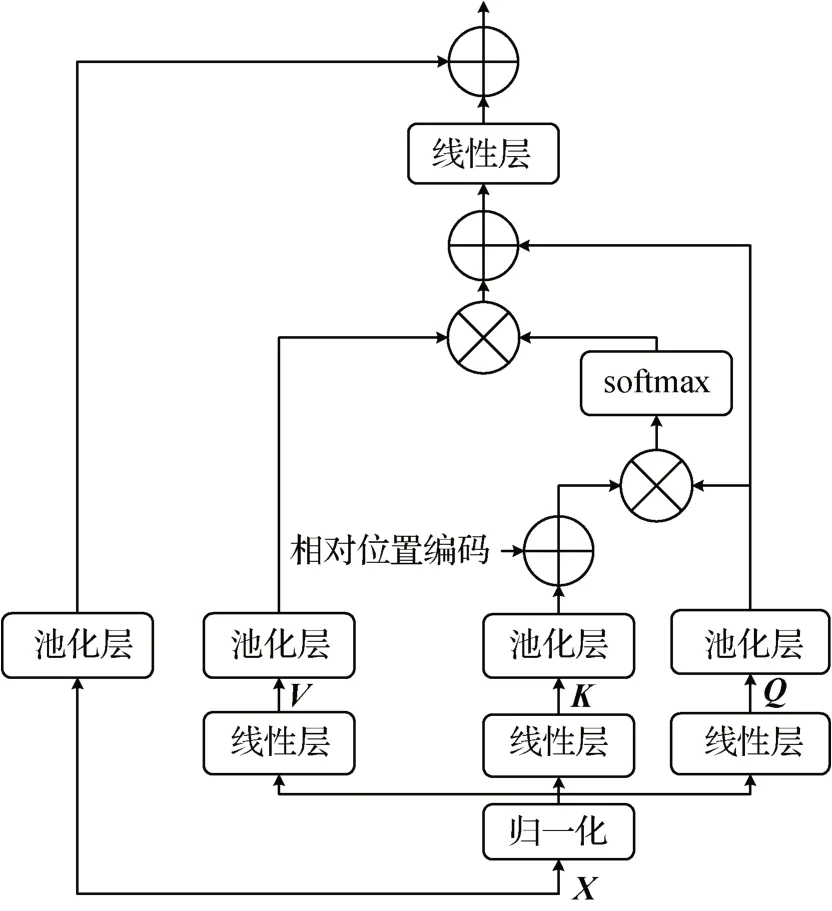
图12 Improved pooling attention 架构图(Li等,2022b)Fig.12 Diagram of the improved pooling attention architecture(Li et al.,2022b)
EdgeNeXt(Maaz 等,2022)提出一种卷积编码器和分割深度转置注意编码器(split depth-wise transpose attention,SDTA)。卷积编码器由深度卷积和线性层组成负责提取局部信息。SDTA 编码器主要由特征编码模块和自注意计算模块组成。特征编码模块将输入数据按通道维度进行拆分,每个部分经深度卷积提取局部信息后进行拼接。而自注意计算模块则负责对经过特征编码模块提取局部信息后的特征进行全局建模。最终实现局部信息和全局信息的融合。
EdgeViTs(Pan等,2022)提出一种局部—全局—局部的结构。该结构通过深度可分离卷积聚合局部信息,全局稀疏的Self-attention 提取全局信息,最后通过转置卷积将代表Token 中的全局上下文信息传播到它们相邻的Token。从而实现局部—全局融合。
ScalableViT(Yang 等,2022)提出了可扩展的自注意力机制(scalable self-attention,SSA)和基于窗口交互的注意力机制(interactive window-based selfattention,IWSA)。SSA 通过引入用于控制空间和通道维度数量的两个参数,解除ViT 结构中固定维度带来的约束,以增强上下文信息的学习能力和提升网络效率。而IWSA 则通过对V矩阵重新组合并从相邻窗口中提取空间信息实现窗口之间的信息交互。
在类型3)中,LeViT(Graham 等,2021)采用4 层3 × 3卷积降低图像分辨率和图像化编码,随后通过attention 与MLP 交替堆叠搭建模型。其中,MLP 与Self-attention数量关系上由一对一变为多对多。
GLiT(Chen 等,2021c)模型提出将ViT 中的FFN替换为由深度卷积神经网络、Swish 和GELU 激活函数组成的卷积MLP。整个模块负责局部信息提取和优化。
LocalViT(Li等,2021b)主要通过将Self-attention处理后的全局信息重构为图像。随后,通过Conv(1 × 1) →Conv(3 × 3) →Conv(1 × 1) 等卷积操作来实现全局信息的整合与局部信息的提取。最后,将特征图转为序列Token 作为下层Transformer的输入。
CeiT(Yuan 等,2021b)与LocalViT、GLiT 类似,通过卷积降低分辨率,设置类似于LocalViT 的卷积MLP 结构增强模型局部信息提取和全局融合能力。最后,将每个阶段的Class Token 进行拼接,并通过ViT模型完成图像分类。MLP改进图如图13所示。

图13 MLP改进图(Li等,2021b)Fig.13 MLP improvement diagram(Li et al.,2021b)
PiT(Heo 等,2021)从CNN 模型进行图像分类任务时维度升高和空间维度下绛的角度考虑ViT模型是否存在同样的空间维度变化出发,设计了由深度卷积实现池化操作的池化层,在降低模型空间维度的同时提升模型通道数量。在与ResNet 相同的超参数配置时明显优于ResNet,说明了PiT 的有效性。PiT 与ViT 的对比说明,空间降维对ViT 架构有利。
基于串行机制的局部与全局信息融合ViT 模型及其特点如表5所示。

表5 基于串行机制的局部与全局信息融合ViT模型Table 5 Local and global information fusion ViT model based on serial mechanism
并行机制实现局部信息和全局信息的融合方式可以分为以下两种:
1)CNN 分支和ViT 分支通过桥接来进行数据交互。如ConFormer(local features coupling global representations for visual recognition)(Peng 等,2021)、MobileFormer(bridging mobileNet and Transformer)(Chen 等,2022a)和 MixFormer(mixing features across windows and dimensions)(Chen等,2022b)。
2)将输入特征按通道维度进行划分,随后对不同通道的特征进行计算,将计算的结果进行拼接以完成新的自注意力变体设计。如IFormer(inception Transformer)(Si 等,2022)、LITv2(fast vision Transformers with HiLo attention)(Pan 等,2023)和ASFFormer(adaptive split-fusion Transformer)(Su 等,2022)。
在方式1)中,ConFormer(Peng 等,2021)模型通过CNN 分支进行局部信息的提取,ViT 分支提取全局信息,中间通过特征耦合单元(feature coupling unit,FCU)解构器来并行传输数据,实现局部信息和全局信息的融合,如图14所示。

图14 ConFormer架构(Peng等,2021)Fig.14 ConFormer architecture(Peng et al.,2021)
MobileFormer(Chen 等,2022a)是Google 团队设计的一个并行ViT,整个模型可以分为两个阶段:1) Mobile →Former;2) Former →Mobile;其中Mobile表示轻量级的卷积提取网络,Former 表示Crossattention。整个模型并行传递信息流,完成局部信息和全局信息的交互。
MixFormer(Chen 等,2022b)提出了一种并行交互模块。该模块通过局部窗口自注意力提取局部信息,深度卷积提取全局信息中间则利用通道和空间交互模块进行信息并行传输,从而提高窗口之间的信息交互能力,实现局部和全局信息的融合。
在方式2)中,主要是在完成通道划分的同时对划分后的通道信息进行计算和融合。其中,IFormer(Si 等,2022)从图像数据的高低频角度出发看待模型的全局信息和局部信息融合问题。由于模型提取的全局信息对应了图像中的低频成分,从ViT 模型特征提取能力角度可以得到结论:Transformer 模型提取低频信息能力强、提取高频信息能力弱。因此,为增强高低频信息的提取,模型将输入的特征图在通道维度上划分为3 块,一块采用Self-attention 完成低频信息的提取,另外两块分别采用Maxpool 和DWconv完成高频信息的提取。最后,使用Fusion模块完成高低频信息融合,如图15所示。

图15 IFormer核心架构(Si等,2022)Fig.15 IFormer core architecture(Si et al.,2022)
LITv2(Pan 等,2023)的核心是一种新颖的自注意力机制,灵感来源于图像中的高频捕捉局部精细细节、低频聚焦于全局结构,而多头自注意力层忽略了不同频率的特征。因此,模型通过将头部分成两组来解开注意力层中的高/低频模式。其中,一组通过每个局部窗口内的自注意力对高频进行编码;另一组对每个窗口使用平均池化获得输入图像的低频特征,随后将低频特征进行线性映射为K和V,并将其与来自原始图像的Q进行注意力计算提取低频信息。最后通过拼接和ConvFFN完成高频信息和低频信息的融合。
ASF-Former(Su 等,2022)提出了HMCB(halfresidual mobile convolutional branch),根据模型所处层数和分类重要程度的不同,将数据通道划分为两半,并行提取局部信息和全局信息,并采用Adaptive Fusion 方法,动态地生成通道信息融合标量,以更加合理的方式融合局部和全局信息。
基于并行机制的局部与全局信息融合ViT 模型及其特点如表6所示。

表6 基于并行机制的局部与全局信息融合ViT模型Table 6 ViT model of local and global information fusion based on parallel mechanism
2.4.3 纯Transformer架构
相较于在Transformer架构中引入CNN 为ViT模型添加归纳偏置,实现局部信息与全局信息的融合,纯Transformer 架构更偏向于修改ViT 架构,使得模型兼具局部信息与全局信息提取能力。典型的模型代表有Swin Transformer、PoolFormer(Yu 等,2022b)、CAT(cross attention Transformer)(Lin 等,2021)、CrossFormer(Wang 等,2021c)、TNT(Transformer in Transformer)(Han 等,2021)、Twins-SVT(twins spatial attention in vision Transformers)(Chu等,2021)、LightViT(light-weight vision Transformers)(Huang 等,2022)、SpectralFormer(spectral Transformer)(Hong 等,2022)、PyramidTNT(improved Transformer-in-Transformer baselines with pyramid architecture)(Han 等,2022)、NAT(neighborhood attention Transformer)(Hassani 等,2022a)、BOAT(bilateral local attention vision Transformer)(Yu 等,2022a)、Sequencer(Tatsunami 和 Taki,2023)和Sep-ViT(separable vision Transformer)(Li等,2022c)。
PoolFormer(Yu 等,2022b)通过实验分析证明Self-attention 层主要提取空间信息,而FFN 负责提取通道信息。最后通过实验将由AvgPool 组成的模型与Self-attention 组成的模型顺次结合获得最优实验结果,既体现了局部信息与全局信息的融合对于提升模型性能的有效性,又为随后的研究者设计更加有效的ViT变体提供了思路。
CAT(Lin 等,2021)提出一种新的注意力机制,即交叉注意力机制。该注意力通过在图像块内部进行自注意力获取局部信息,并从单通道特征图划分的图像块之间应用注意力捕获全局信息。随后,交替应用Patch内和Patch间注意力,实现交叉注意,以较低的计算成本保持性能,并为其他视觉任务构建一个分层网络。
CrossFormer(Wang 等,2021c)提出了跨尺度嵌入层(cross-scale embedding layer,CEL)和长短距离注意力(long short distance attention,LSDA)来解决跨尺度、计算开销大以及局部—全局信息融合能力弱等问题。一方面,CEL 将每个嵌入与多个不同尺度的Patch混合在一起,为自注意力模块本身提供跨尺度特征;另一方面,LSDA 将 Self-attention 模块分为短距离和长距离对应模块,不仅减少了计算负担,而且在嵌入中同时保留了小规模和大规模的特征。通过以上两种设计,实现了跨尺度注意力。
TNT(Han 等,2021)和PyramidTNT(Han 等,2022)都通过两层嵌套的方式完成Patch和像素级编码,即外部Transformer将图像划分为一个个Patch提取全部特征,而内部Transformer 块则从像素编码中提取局部特征。通过线性变换层将像素级特征投影到Patch 编码的空间,然后将其添加到Patch 中。区别之处在于PyramidTNT 引入了金字塔结构,可以更好地利用空间信息。
Twins-SVT(Chu 等,2021)由局部分组自注意力(locally-grouped self-attention,LSA)和全局子采样自注意力(global sub-sampled attention,GSA)组成。LSA 将输入的特征图划分为子窗口,在窗口内进行自注意力计算,实现降低参数量的同时提取局部信息。但划分窗口的方式无法有效实现窗口之间的信息交互,进而影响了模型的性能。因此,通过设计GSA 模块选择窗口代表信息,并通过代表信息之间的交互完成全局信息的提取。最后,通过LSA 和GSA的交替堆叠,完成局部和全局信息的融合,提升模型分类性能。
LightViT(Huang 等,2022)为降低模型的计算量,实现局部信息和全局信息的融合,对ViT 模型中的自注意力和FFN 模块进行改进。首先,提出一种局部全局广播注意力,通过窗口注意力降低参数量。同时,引入可学习全局Token,动态地聚合局部信息和全局信息,解决经过局部窗口注意力后窗口之间交互能力差的问题。最后,通过空间注意力和通道注意力结合的方式,增强FFN的特征表达能力。
SpectralFormer(Hong 等,2022)提出一种纯Transformer 的高光谱图像分类模型,可以接受像素级或Patch级的输入,旨在从附近的高光谱波段捕获光谱局部序列信息。整个模型由分组光谱嵌入(group-wise spectral embedding,GSE)和跨层自适应融合(cross-layer adaptive fusion,CAF)模块组成。其中,GSE主要学习局部光谱表示,以提高模型捕获细微光谱差异的能力。CAF模块通过设计跨层跳跃连接将信息从浅层传递到深层,增强层间的信息交互能力。两个模块的设计与Transformer 架构结合,能够有效将局部信息与全局信息融合,提升模型的分类能力。
NAT(Hassani 等,2022a)提出了邻域注意力(neighborhood attention,NA),其实质是点积自注意力的局部化,主要将每个查询Token 的感受野限制在键值对对应Token 周围的固定大小邻域。这种结构能够使较小的区域引起更多的局部关注,而较大的区域会产生更多的全局关注,从而在平移不变性和等变性之间取得平衡,实现对感受野的控制,进而通过这种邻居形式,获得局部信息与全局信息的融合,提升了模型性能,降低了计算开销。
BOAT(Yu 等,2022a)提出一种双向局部注意力模块,由特征空间局部注意力模块和图像空间局部注意力模块组成。图像空间局部注意力模块将图像划分为多个局部窗口,通过注意力运算提取局部信息。而特征空间局部注意力模块则根据Patch 的特性,采用平衡分层聚类法(如图16 所示),将其分组到多个集群中,在每个集群中进行自注意力机制计算。这种特征空间局部注意力方法能够有效地捕获跨不同局部窗口的Patch之间的连接,但仍然具有相关性。

图16 平衡分层聚类法示例(Yu等,2022a)Fig.16 Example of balanced hierarchical clustering(Yu et al.,2022a)
Sequencer(Tatsunami和Taki,2023)提出一种基于双向LSTM(long short-term memory)提取局部与全局信息的网络模型。首先将图像按照行与列进行划分并采用双向LSTM提取特征,随后将提取的特征进行拼接和通道混合。实现局部信息和全局信息的融合。
SepViT(Li等,2022c)提出一种深度可分离的注意力机制,结构如图17 所示。首先将图像分割为不同的Patch,然后为不同的Patch 添加Window Token,计算窗口注意力。随后将Window Token 通过卷积转变为Q、K,Patch 作为新的Self-attention 的V进行点积注意力,实现局部信息和全局信息融合。
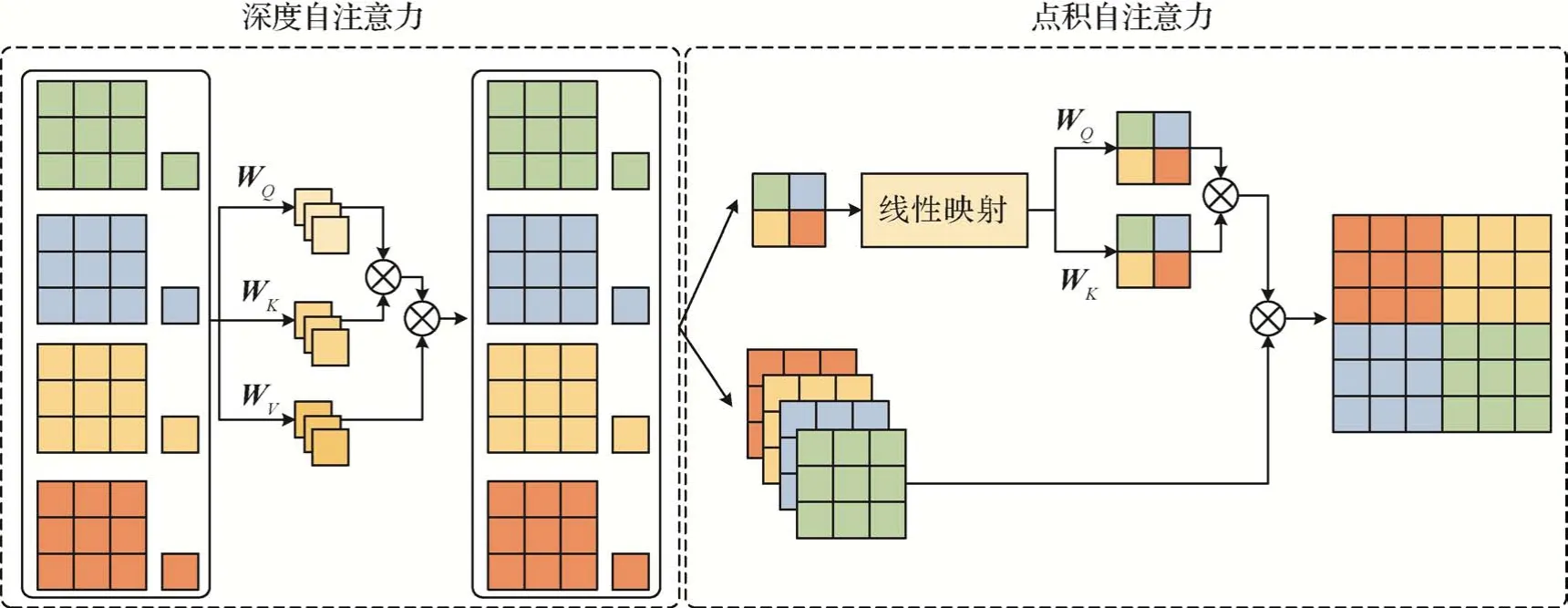
图17 SepViT模型(Li等,2022c)Fig.17 SepViT model(Li et al.,2022c)
基于纯Transformer 的局部与全局信息融合ViT模型及其特点如表7所示。

表7 基于纯Transformer的局部与全局信息融合ViT模型Table 7 Local and global information fusion ViT model based on pure Transformer
2.5 深层ViT模型
He 等人(2016)和张珂等人(2021)研究发现,随着模型层数加深,模型性能得到显著提升。因此,有很多研究尝试将ViT 模型层数加深,以提升分类性能。但研究表明,随着ViT 层数增加,会产生注意力崩溃问题。为解决这个问题,DeepViT(towardsdeeper vision Transformer)(Zhou 等,2021)、CaiT(class-attention in image Transformers)(Touvron 等,2021b)和 T2T-ViT(tokens-to-token vision Transformer)(Yuan 等,2021c)等通过巧妙的模型结构设计提升ViT性能。
DeepViT(Zhou 等,2021)发现随着模型层数的不断加深,ViT 每层的相似度差异会逐渐减小。针对该问题,提出了两种解决方法:1)扩大输入Token的维度,增加参数量扩大相似度;2)通过引入Reattention 解决注意力崩溃问题,即在Self-attention 计算过程中添加归一化因子,打破相似度一致化。
CaiT(Touvron 等,2021b)从两个角度加深模型和提升性能,如图18 所示。1)引入LayerScale 层,在每个残差块的输出上添加一个可学习的对角矩阵,以提高训练的动态性和获得更深层次的模型;2)构建了一个CA(class-attention)模块,即通过前期的多层Transformer 完成特征提取,在后期添加Class Token 聚合分类信息,将Class Token 的任务从概括全局信息进行分类与实时更新特征图分离,通过堆叠多层Transformer提升模型性能。

图18 CaiT 归一化因子(Touvron等,2021b)Fig.18 CaiT normalization factor(Touvron et al.,2021b)
T2T-ViT(Yuan 等,2021c)提出Tokens-to-Token(T2T)模块,将相邻的Tokens 聚合为一个Token,以模拟周围Tokens 的局部结构信息,迭代地减少Tokens的长度。具体来说,在每个Token-to-Token步骤中,由Transformer 输出的Tokens 被重建为一个图像,然后通过软分割将周围的Token 分割平铺聚集在一起生成新的Token。因此,周围的局部结构被嵌入到生成的Token 中,并输入到下一个Transformer层。随后,在T2T引入局部先验性的基础上堆叠多层提升模型性能。
深层ViT模型及其特点如表8所示。

表8 深层ViT模型Table 8 Deep ViT model
3 实 验
本节主要通过ViT 变体在ImageNet、CIFAR-10(Canadian Institute for Advanced Research)和CIFAR-100 这3 个数据集上的分类准确率来衡量模型对于ViT 设计之初所面临问题的解决程度。考虑到近年来Transformer 在遥感图像分类中也得到广泛应用,本文对基于Transformer的遥感图像分类方法也通过实验进行了对比分析。
3.1 数据集
CIFAR-10 数据集由10 个类别共60 000 幅32 ×32像素的彩色图像组成,每个类6 000幅图像。训练集50 000幅图像,测试集10 000 幅图像。测试集图像包含10个类别,每个类别1 000幅图像。CIFAR-100数据集有100个类,每个类包含600幅图像。每类分为500幅训练图像和100幅测试图像。
ImageNet(Deng 等,2009)是美国斯坦福大学和普林斯顿大学根据WordNet 层次结构合作组织建立的用于视觉对象识别软件研究的大型可视化数据库,涵盖1 000 个对象类别,包含 1 281 167 幅训练图像,50 000幅验证图像和100 000幅测试图像。本文中的ImageNet数据集特指ImageNet-1K。
Indian Pines 是第一个高光谱(hyperspectral,HS)图像数据集。1992年在美国印第安纳州西北部使用机载可见光/红外成像光谱仪(airborne visible/infrared imaging spectrometer,AVIRIS)传感器收集所得。HS 图像由145 × 145 像素组成,地面采样距离(ground sample distance,GSD)为20 m,220 个光谱波段覆盖400 nm 至2 500 nm 波长范围,光谱分辨率为10 m。去除20 个噪声和水吸收波段后,保留200 个光谱波段。该研究场景中有16个主要研究类别。
Trento 数据集收集了意大利南部特伦托一个农村地区的高光谱图像和LiDAR 数据。该数据集的覆盖范围内包含6个不同的类别。
Salinas 由机载可见光/红外成像光谱仪(AVIRIS)在美国加利福尼亚州萨利纳斯谷地区收集。数据集的空间大小为512 × 217像素,空间分辨率为3.7 m/像素,光谱范围为400~2 500 nm,去除20个噪声波段后有204个波段。除了未标记的像素外,数据集还包含16个手动标记的类。
3.2 评价指标
实验结果的评价主要采用准确率和参数量两个指标。此外,为了更全面地分析模型的性能,采用浮点运算数(floating point operations,FLOPs)作为模型性能评价指标。
对遥感图像分类结果采用与Hong 等人(2022)相同的评价指标。如总体分类精度(overall accuracy,OA)、平均分类精度(average accuracy,AA)和Kappa(κ)系数。
3.3 实验结果
表9 给出了16 个模型在ImageNet、CIFAR-10 和CIFAR-100 数据集上的实验结果。可以看出,对应ResNet 系列模型,随着模型堆叠残差连接网络数量增加,模型深度加深,准确率上升,但参数量和计算复杂度也随之增加。上述结果表明,残差网络在解决深层卷积神经网络的梯度消失和梯度爆炸问题中比较有效,但其参数规模巨大,计算复杂度大,不利于移动端部署。相比于ResNet系列模型,由于采用了深度可分离卷积,EfficientNet 系列模型的参数量显著降低,采用较少计算量,就能完成较高分类性能。该结果表明,深度可分离卷积对于降低参数量十分有效且不会降低分类性能。

表9 可扩展位置编码类别ViT变体与CNN和ViT在不同数据集上的Top-1准确率、参数量和FLOPs对比Table 9 Comparison of Top-1 accuracy,number of parameters and FLOPs of the scalable location coding class ViT variant with CNN and ViT on different datasets
为了获得更高的图像分类准确率,提出了基于可扩展位置编码的ViT 模型。由表9 可见,CMT 模型取得了84.5%的准确率,相比于CNN 系列最高准确率高出3.4%,同时具有较低的计算复杂度。该结果表明,可扩展位置编码能够有效解决ViT 模型中绝对位置编码带来的可扩展性差问题,提升了ViT模型性能,为模型应用于高分辨率图像提供了可能。
表10 给出了14 个模型在ImageNet 图像分类数据集上的实验结果。可以看出,根据模型所采用方式的不同,可以划分为窗口注意力型(Swin Transformer,CSWin Transformer)和自注意力改进型(VOLO,VVT)两种方式。其中,窗口注意力型核心思想是二次划分Patch 进行Self-attention 运算,从而减少计算复杂度。而改进自注意力型主要 将 Self-attention中的运算顺序进行[φ(Q)φ(K)T]V→φ(Q)[φ(K)TV]的交换以及将softmax 替换为线性复杂度的函数来降低计算复杂度。通过表10 中的FLOPs 对比可以发现,两种方式的复杂度都低于ViT 的同时分类准确率更高。此外,窗口注意力型模型性能在相同计算复杂度下不如自注意力改进型。由此可得出结论,两种降低复杂度的方式对于降低复杂度都有效,其中从模型架构上对于Self-attention的改进更直接也更有效,未来改进模型降低复杂度时,为保证复杂度与准确率平衡,可以寻找线性复杂度的函数代替softmax函数。

表10 低复杂度和低计算代价类别ViT变体在ImageNet数据集上的Top-1准确率和计算复杂度对比Table 10 Comparison of Top-1 accuracy and computational complexity of low-complexity and low-computational-cost class ViT variants on ImageNet dataset
表11给出了8个模型(*表示蒸馏)在ImageNet、CIFAR-10 和CIFAR-100 图像分类数据集上的实验结果。可以看出,DeiT、CCT 模型添加知识蒸馏策略时,模型在ImageNet、CIFAR-10 和CIFAR-100 数据集上分类准确率都有所提升,表明了知识蒸馏策略在少量增加甚至不增加参数量的情况下为模型引入归纳偏置提升分类性能具有重要作用,从中可得出结论:归纳偏置的缺乏影响ViT 模型在小数据集上的准确率,进而需要大量数据来缓解这个问题。
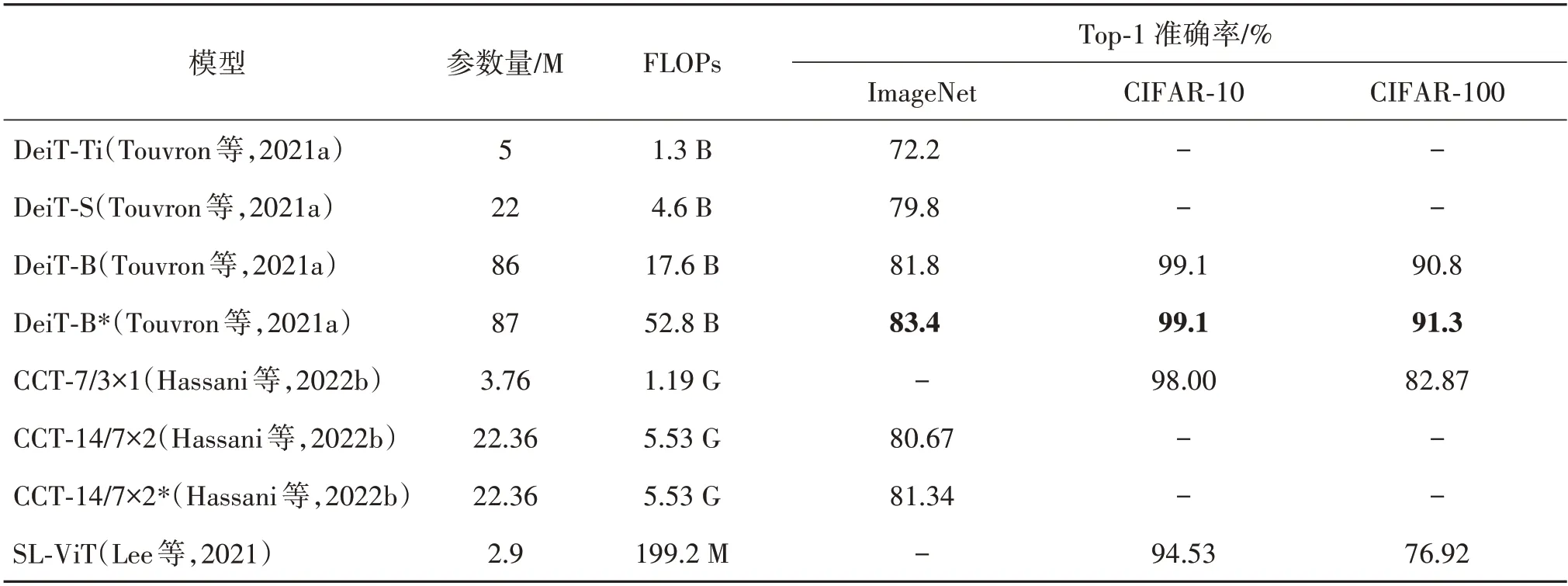
表11 “数据饥饿”问题解决方法在CIFAR-10、CIFAR-100和ImageNet数据集上的准确率对比Table 11 Comparison of accuracy rates for “data hungry” problem on CIFAR-10,CIFAR-100 and ImageNet datasets
表12 给出了9 个模型在ImageNet、CIFAR-10 和CIFAR-100 图像分类数据集上的实验结果。可以看出,3 种模型在ResNet 为基础的Backbone 上合理添加Self-attention 及其变体实现局部信息与全局信息的融合,相较于ResNet 系列、ViT-B 和ViT-L 具有较高的分类准确率,从中可得出结论:两者的结合既降低了参数量(CNN 参数量≪多层Self-attention 堆叠)又降低了计算复杂度。
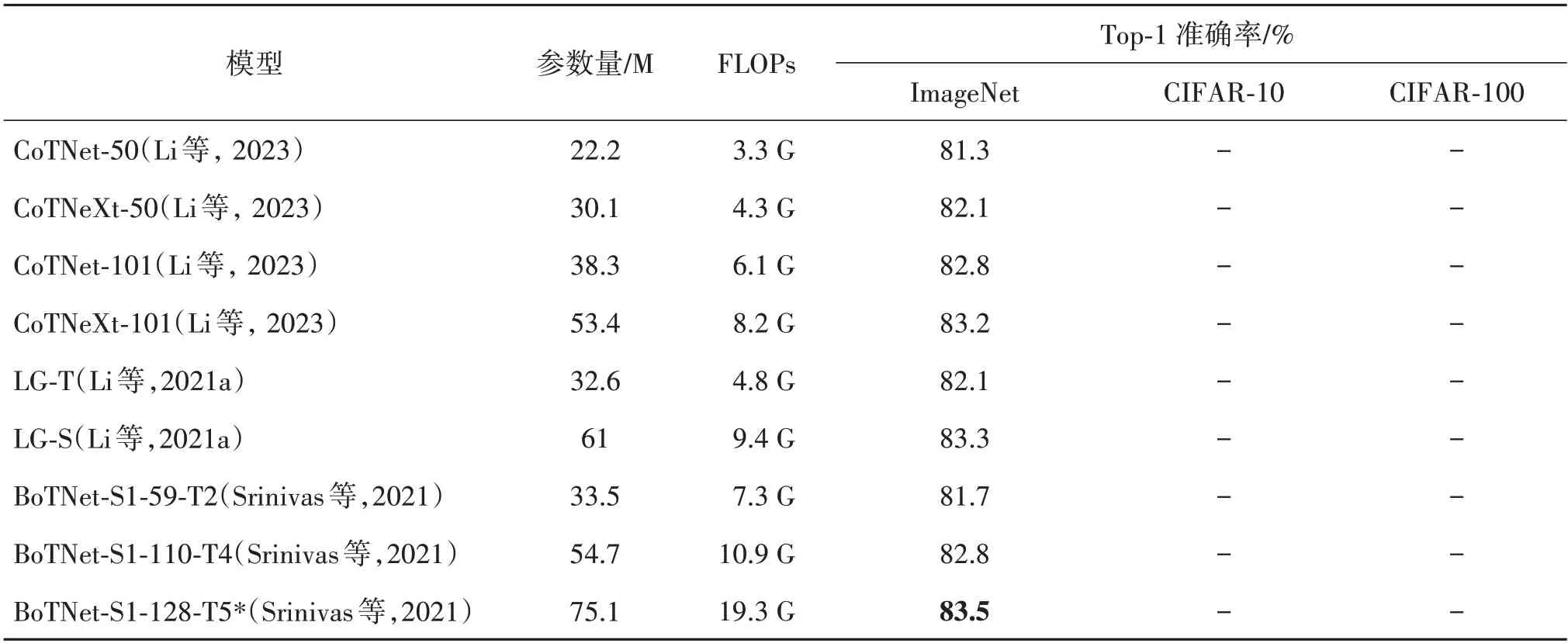
表12 CNN+Self-attention模型及其变体在CIFAR-10、CIFAR-100和ImageNet数据集上的准确率对比Table 12 Accuracy comparison of CNN+Self-attention model and its variants on CIFAR-10,CIFAR-100 and ImageNet datasets
表13 给出了26 个模型在ImageNet、CIFAR-10和CIFAR-100图像分类数据集上的实验结果。可以看出,相较于CNN+Self-attention 的模式而言,CNN和Transformer的串行机制重点是对Transformer的改进。表中CvT、CCT 模型代表了使用CNN 代替线性映射层将Patch 映射到Token 的方法提取特征的局部信息;CeiT 和LocalViT 则是利用CNN 降低分辨率,以及FFN 模块中添加深度卷积来聚合空间局部信息。通过将CvT、CeiT与ViT相比证明两种模型的有效性,从中可得出结论:前期引入CNN 对于提升性能相较于后期FFN 处添加更加有效,深度卷积能够降低模型参数量并提升性能。此外,由表13 可以看出,PVT v1 和PVT v2 通过引入金字塔结构为模型带来了丰富的多尺度空间信息和相较于原始ViT 更低的参数量和更好的性能。PiT、MViTv1 和MViTv2为模型引入Pool 操作增加了模型的空间信息。PVT v2和MViTv2除了引入主要架构外,还在模型中添加CNN 带来归纳偏置,相较于单独添加CNN 模型引入金字塔结构和空间信息的模型,参数量降低且准确率上升。从而得出结论:CNN 带来的归纳偏置和金字塔结构以及Pool操作带来的空间信息结合是使得全局信息与局部信息融合,降低参数量、复杂度和性能提升的重要手段。其中ScalableViT 与GC ViT 主要对窗口注意力进行改进,将它们与Swin Transformer 对比可知,增加窗口之间信息交互,对提升模型性能至关重要。

表13 串行机制中引用量300以上的模型在不同数据集上的准确率对比Table 13 Comparison of accuracy on different datasets for models with 300+citations in the serial mechanism
表14 给出了13 个模型在ImageNet、CIFAR-10和CIFAR-100图像分类数据集上的实验结果。可以看出,并行机制分为两种方式:1)CNN 分支和ViT 分支通过桥接来进行数据交互,如Conformer与Mobile-Former;2)将输入特征按通道维度进行划分,随后对不同通道的特征进行计算,将计算的结果进行拼接以完成新的自注意力变体设计,如IFormer 与ASFFormer。从实验结果来看,桥接的并行方式相较于使用划分通道的方法在相同参数量和计算复杂度情况下,IFormer 取得的准确率更高。从中可得出结论:相较于通过桥接模型完成局部信息和全局信息融合的并行方式,利用交叉Self-attention具有的交互能力直接进行信息传递,省去复杂的传输网络大幅降低了模型复杂度和模型参数量。但交叉注意力方式交互相较于并行模型较低的准确率说明此类方法有待进一步完善。此外,表14 中的划分通道类型的模型,解决了并行桥接和交叉注意力在交互过程中存在的数据冗余,影响模型性能的问题,不同通道各司其职,这种合理的通道融合机制为局部信息和全局信息融合做出重要贡献。

表14 并行机制模型及其变体在CIFAR-10、CIFAR-100和ImageNet数据集上的准确率对比Table 14 Comparison of accuracy of parallel mechanism models and their variants on CIFAR-10,CIFAR-100 and ImageNet datasets
表15 给出了14 个模型在ImageNet、CIFAR-10和CIFAR-100图像分类数据集上的实验结果。可以看出,纯Transformer 架构融合全局与局部信息的方法,从窗口注意力存在的Patch块之间信息交互能力差出发,设计了增强窗口之间信息交互能力的模型。由表15 可以看出,对距离权重分配法(BOAT,NAT)、窗口级嵌套法(TNT,Twins-SVT,PyranidTNT)以及Windows Token 窗口信息交互法(SepVit)等3种方法进行了对比,BOAT 模型获得的准确率最高。此外,NAT 模型取得了第2 的成绩。实验结果表明,距离权重分配法进行局部和全局信息融合相对于另外两种方式获得了更优异的性能,证明了引入归纳偏置对于ViT网络提升性能至关重要。

表15 基于纯Transformer中引用量200以上的模型在不同数据集上的准确率对比Table 15 Comparison of accuracy on different datasets based on models with 200+citations in the pure Transformer architecture
表16 给出了9 个模型在ImageNet、CIFAR-10 和CIFAR-100 图像分类数据集上的实验结果。可以看出,DeepViT、CaiT 和T2T-ViT 这3 个模型主要通过合理的架构设计来解决深层ViT 带来的注意力崩溃问题。从表16 中实验结果对比发现,CaiT 获得了最高的分类准确率。从中可以得出结论,通过层归一化因子可以减缓层与层之间的相似度增加,缓解注意力崩溃问题,进而加深模型层数提升模型性能。

表16 深层ViT模型在CIFAR-10、CIFAR-100和ImageNet数据集上的准确率对比Table 16 Comparison of accuracy of deep ViT models on CIFAR-10,CIFAR-100 and ImageNet datasets
表17 给出了29 个模型在ImageNet、CIFAR-10和CIFAR-100图像分类数据集上的实验结果。表17还给出了本文按照4 个大类别8 个子类别展开叙述的8个最优模型。图19是根据本文所划分的4个类别,在图像尺寸为224 × 224像素情况下获得的每个类别的最高准确率与参数量的关系。
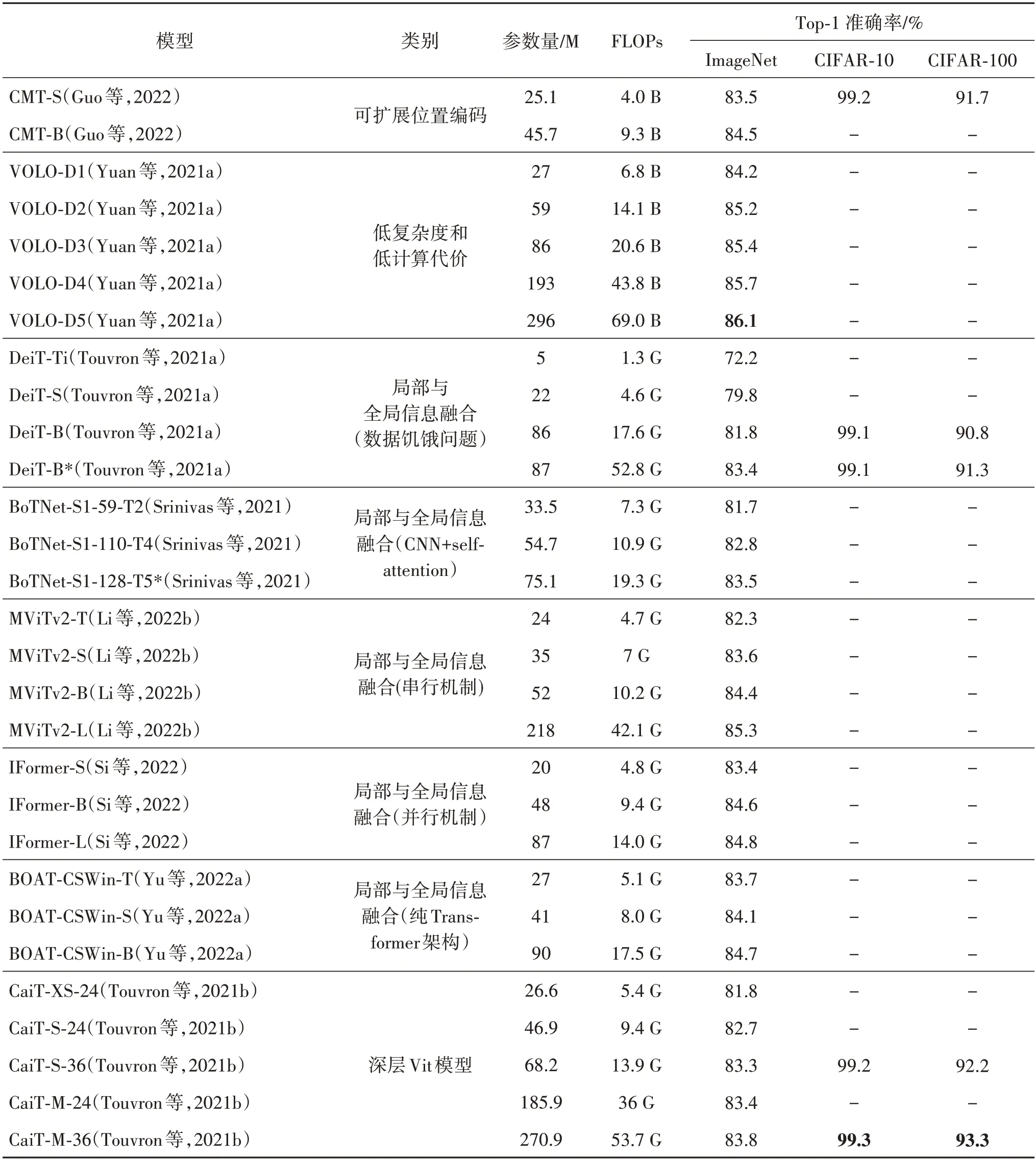
表17 4个大类别8个子类的最优模型在CIFAR-10、CIFAR-100和ImageNet数据集上的准确率对比Table 17 Comparison of accuracy of the best models in four broad categories and eight subcategories on CIFAR-10,CIFAR-100 and ImageNet datasets

图19 4分类中ImageNet上准确率最高模型的参数量和准确率图Fig.19 Plot of number of parameters and accuracy of the most accurate models on ImageNet in the four classifications
由表 17 和图19 可见:1)通过最优模型的参数量逐渐增大,模型的整体性能不断提升,从中可以得出结论,当基础设计有效时,随着模型参数的增加,性能也会不断提升;2)DeiT 蒸馏模型和DeiT-B 的实验效果对比可以得出结论,蒸馏的方式使得模型在参数量少量增加甚至不变的情况下提升了性能;3)随着模型深度加深模型性能提升,证明了CaiT 缓解注意力崩溃的方法有效;4)通过上述模型的内部结构发现,将CNN 与Transformer 有效结合,对于图像分类效果具有明显增益。
表18给出了ViT、SpectralFormer(Hong等,2022)、MFT(Roy等,2022)、MCT(Jia等,2022)、CTN(Zhao等,2022)、DHViT(Xue 等,2022)和DSS-TRM(Liu 等,2022c)等7个模型在Indian Pines、Salinas和Trento遥感高光谱图像分类数据集上的实验结果。
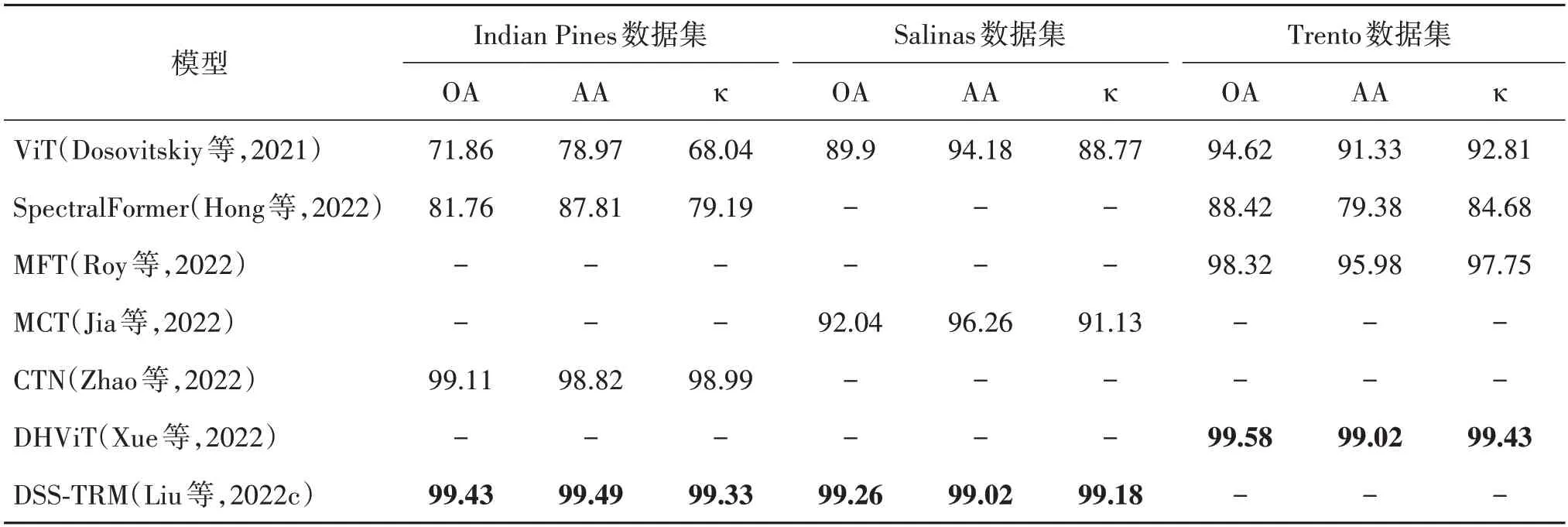
表18 基于Transformer的遥感高光谱图像分类模型在不同数据集上的OA、AA、κ对比Table 18 Comparison of OA,AA and κ of Transformer-based remote sensing hyperspectral image classification model on different datasets/%
由表18 可见,相比于使用原始ViT 模型进行高光谱图分类而言,使用局部信息与全局信息结合的方法有效提高了分类准确率,证明了局部与全局信息融合的有效性。此外,通过使用数据的不同可将模型划分为单模态和多模态。其中,SpectralFormer、MCT、CTN、DSS-TRM 仅使用高光谱图的单模态数据,MFT 和DHViT 则是使用高光谱图像和LiDAR 图像作为输入数据的多模态模型。通过将Spectral-Former 在Trento 数据集上的实验结果与MFT 和DHViT 对比发现,针对多模态数据设计的模型相较于设计之初仅使用一个模态数据的SpectralFormer的OA、AA 和κ分别提高了11.16%、19.64% 和14.75%。实验结果表明,合理利用多模态信息能够提升模型的整体性能。Indian Pines 数据集上的实验结果对比可以发现,DSS-TRM 相较于Spectral-Former、CTN 取得了更好的实验效果,表明有效捕捉和利用空间—光谱信息能够提升高光谱图像分类的准确率。
4 结语
目前基于ViT 的图像分类研究尽管已经取得了一定进展,然而在实际应用中,由于图像分类问题的复杂性,仍面临很多挑战性问题,亟需解决。具体体现如下:1)由于ViT 设计之初将图像划分为固定的图像块,破坏了固有的对象结构,减少了输入Patches 提供的信息量,使得模型聚焦于背景,对图像分类造成信息干扰,影响分类结果。2)Transformer模型中通过添加CNN 的方式引入归纳偏置只是缓解了数据饥饿问题,并未解决发生此类问题的根源。3)目前使用Transformer 和CNN 模型进行图像分类,在相同性能情况下,Transformer 仍比CNN模型参数量和计算复杂度大,且不利于移动端部署。
针对上述问题,本文认为在后续工作中,可以从如下方面展开研究:1)设计一种不从固定位置采样,以迭代方式更新采样位置,通过上下文信息交融聚焦分类关键区域的方案。2)分析产生数据饥饿问题的根本原因,在CNN 与Transformer 结合的基础上进行改进,设计更加合理的模型。3)设计低复杂度、低计算量和轻量级便于部署的模型。4)增加解决问题的数量或设计统一的框架对于推动计算机视觉领域的发展具有里程碑的意义,也是未来主要研究的方向之一。5)将Transformer应用到小众科研领域和工业实景下解决具体的工业问题,对于推动国家工业智能化发展,具有重要意义。
