拉曼光谱学结合人工智能算法的分析技术研究
2023-09-25赵景维朱虹霓黄晋卿
赵景维,朱虹霓,曹 艺,黄晋卿
(1.香港科技大学深圳研究院,广东 深圳 518057;2.湖北师范大学 先进材料研究院,湖北 黄石 435002)
0 引言
长期的压力会导致身体内与压力相关的生物标志物一直保持在很高的水平,可能会增加长期焦虑和抑郁的风险[1, 2]。在血液中,与压力相关的生物标志物包括皮质醇、肾上腺素、睾酮等应激激素[3]。其中,肾上腺素还与睾酮的分泌相关,这使得血液中肾上腺素浓度的监测能带来更多的压力相关信息[3]。此外,血红蛋白是一种将氧气从肺部输送到其他器官和组织以支持身体活动的蛋白质,是血液中与应激激素共存的主要成分,分析这些与压力相关的生物标志物的浓度水平对于健康监测和风险评估具有重要的意义。
拉曼光谱法作为一种光学诊断技术,可直接探测分子的化学键振动,具有快速的分析速度、可靠的结果以及无破坏性的特点[4]。近年来,人工智能算法被应用到光谱分析领域中,显著提高了数据处理效率和准确度。但是,目前还没有从水相混合物中定量分析多种生理指标分子的工作。这是因为很多生物分子通常具有一些相似的振动基团,导致他们的光谱峰变宽和相互重叠[3]。例如,Kirsten Gracie等人利用位于1 611 cm-1的拉曼峰对血清中皮质醇进行定量分析[5],但这是一个经常出现光谱峰重叠的区域[6]。因此,我们需要继续研究更好的方法来识别和量化在接近生理条件下复杂混合物中的多种生理指标分子。
1 实验材料与方法
1.1 样品准备
皮质醇 (≥99%)、L-肾上腺素 (≥99%)、血红蛋白(冻干粉)和二甲基亚砜 (DMSO)(≥99.0%)购自 Sigma-Aldrich.皮质醇、肾上腺素和血红蛋白分别溶解在 5% 二甲基亚砜 (DMSO) 水溶液中,将这些储备溶液以不同的体积比混合,制备得到566 组含有不同量皮质醇、肾上腺素和血红蛋白的样品溶液。
1.2 光谱采集
使用共聚焦拉曼显微镜(in-Via,Renishaw,Gloucestershire,英国)采集光谱数据。样品溶液放在 20 倍显微镜物镜下,使用 514.5 nm,功率为 25 mW的激光进行拉曼光谱测量。每次测量的采集时间为 20 秒,光谱重复10次测量进行累积叠加。拉曼光谱扫描范围为500 cm-1至2 000 cm-1,光谱分辨率为 1 cm-1.
1.3 数据分析
原始拉曼光谱先进行基线校正、去除宇宙射线和扣除溶剂背景的预处理,然后将全部光谱数据随机分为两组:将75%的数据作为训练集,将25%的数据作为测试集。训练集的光谱数据用来构建多目标人工智能算法模型,其中包含3个独立的模型分别用来分析皮质醇、肾上腺素和血红蛋白的含量。调整每个独立模型的超参数,优化生成评估指标。
1.4 人工智能算法
使用支持向量回归(SVR)、决策树(DT)、随机森林(RF)和eXtreme Boost(XGBoost)建立多目标回归模型,对每一种生理指标分子进行含量分析,计算预测结果的判定系数(R2)和均方根误差(RMSE)来评价性能。一般来说,R2的数值越高并且RMSE的数值越低代表模型的结果预测性能越好。由于多目标回归模型是由三个单目标回归变量构建的,分别用于皮质醇、肾上腺素和血红蛋白的定量分析,因此本研究采用平均(R2)和平均RMSE来检验不同模型的整体准确性。操作指南和源代码分享于网络数据库:https://doi.org/10.14711/dataset/BP30DS.
2 结果与分析
2.1 拉曼光谱解析
图1a)展示了含有不同浓度的皮质醇、肾上腺素和血红蛋白样品溶液的三角形关系示意图。图中,位于三个角落处的圆形点代表只含有皮质醇、肾上腺素或血红蛋白的单一样品溶液,位于三条边缘的三角形点代表它们的二元混合样品溶液,位于三角形内的星形点代表它们的三元混合样品溶液。图1b)分别展示了通过这些数据处理后得到的皮质醇(b1)、肾上腺素(b2)和血红蛋白(b3)的拉曼光谱。在皮质醇的拉曼光谱中,在1 609 cm-1处有一个明显的峰,归属于C=C伸缩振动模式[7]。肾上腺素的光谱特征包含777 cm-1(NH弯曲)、1 290 cm-1(面内环变形、脂肪族H-O-C-H弯曲和链扭曲的耦合)、1 468 cm-1(面内环变形和CH弯曲的耦合)和1 609 cm-1(面内环变形、环内C-O-H弯曲和C=C拉伸的耦合)[6,8]。血红蛋白光谱中的峰主要归属于其氧合状态下的血红素基团,显示特征峰位于1 373 cm-1的对称pyr半环拉伸,1 561 cm-1的CβCβ拉伸,1 582 cm-1的不对称CαCm拉伸,1 609 cm-1的乙烯基C=C拉伸,1 637cm-1的不对称CαCm拉伸[9]。如图1b)中虚线标记所示,皮质醇、肾上腺素和血红蛋白的拉曼特征峰在1 609 cm-1处重叠,这主要是来源于它们化学结构中的C=C拉伸振动[6]。除此之外,皮质醇、肾上腺素和血红蛋白的其他光谱特征峰的强度较弱,增加了区分和量化各成分含量的难度。图1c)展示了这些生理指标分子在二元混合物和三元混合物溶液中的拉曼光谱。皮质醇和肾上腺素(C1)、肾上腺素和血红蛋白(C2)、皮质醇和血红蛋白(C3)、二元混合物(体积比为 1∶1)以及皮质醇、肾上腺素和血红蛋白(C4)三元混合物(体积比为 1∶1∶1)的光谱明显变得更加复杂。值得注意的是,位于1 609 cm-1处的重叠峰出现了变宽和扭曲[6]。尽管拉曼光谱中包含了丰富的分子特征信息,但对于从多元混合物的水溶液中分别对皮质醇、肾上腺素和血红蛋白的进行定量分析仍然具有挑战性。

图1 a)皮质醇、肾上腺素和血红蛋白的样品三元图;b)皮质醇(b1)、肾上腺素(b2)和血红蛋白(b3)的拉曼光谱图;c)皮质醇和肾上腺素(c1)、肾上腺素和血红蛋白(c2)、皮质醇和血红蛋白(c3)的二元混合物以及皮质醇、肾上腺素和血红蛋白(c4)的三元混合物的拉曼光谱图
2.2 模型比较
分别使用支持向量回归 (SVR)、决策树 (DT)、随机森林 (RF) 和 eXtreme Boost (XGBoost),可搭建出基于光谱信息的多目标回归模型,基于不同人工智能算法的模型进行全面超参数优化后,用于从混合物的拉曼光谱中分别分析皮质醇、肾上腺素和血红蛋白的含量。例如,通过支持向量回归 (SVR) 来学习随三种组分在不同体积比的光谱特征,可将如图1c中所展示的混合拉曼光谱进行多组分定量分析,结果如下:皮质醇和肾上腺素的二元混合物拉曼光谱(C1)分析值为0.52∶0.49∶-0.01,真实值为0.50∶0.50∶0.00(皮质醇:肾上腺素:血红蛋白溶液体积比)、肾上腺素和血红蛋白二元混合物拉曼光谱(C2)分析值为0.00∶0.53∶0.43,真实值为0.00∶0.50∶0.50(皮质醇:肾上腺素:血红蛋白溶液体积比)、皮质醇和血红蛋白的二元混合物拉曼光谱(C3)分析值为0.50∶0.06∶0.51,真实值为0.50∶0.00∶0.50(皮质醇:肾上腺素:血红蛋白溶液体积比)、皮质醇、肾上腺素和血红蛋白的三元混合物的拉曼光谱图(C4)分析值为0.23∶0.43∶0.30,真实值为0.33∶0.33∶0.33(皮质醇:肾上腺素:血红蛋白溶液体积比)。图2展示了四个模型的奇偶校验图,包括每个模型分别用于从混合物的拉曼光谱中分析皮质醇、肾上腺素和血红蛋白的含量时的预测值与真实值的所有数据点。在针对每个组分的分析散点图中,横坐标代表从样品溶液制备中获知的各组分之间体积比的真实值,纵坐标代表模型分析预测结果,圆形点代表从训练集的光谱数据分析中获得的结果,三角形点代表从测试集的光谱数据分析中获得的结果。在针对不同体积比的皮质醇、肾上腺素和血红蛋白的定量分析中,模型整体性能的良好程度由标绘点沿对角线(方程y=x)的接近度定义,表明在每个数据点下模型的预测精度都非常高。红色和绿色绘图点之间的偏差越小,表明该模型对于训练集和测试集数据分析的通用性越高。显然,在使用支持向量回归(SVR)、随机森林(RF)和eXtreme Boost (XGBoost)分析皮质醇、肾上腺素和血红蛋白的奇偶校验图中,大多数标绘点位于奇偶校验图的对角线附近。但是,使用决策树(DT)分析生成的标绘点分散在整个奇偶校验图中,存在欠拟合的情况。
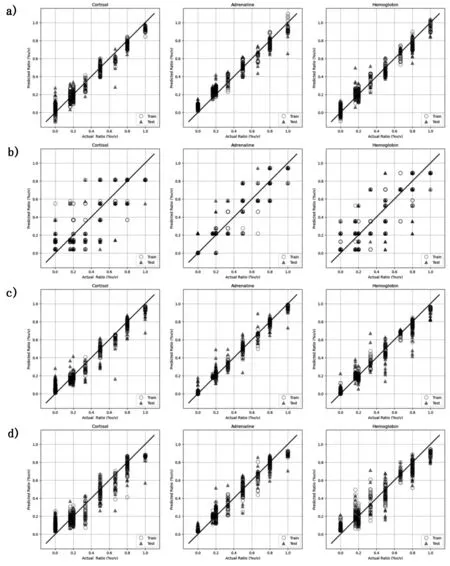
图2 使用a)支持向量回归 (SVR)、b)决策树 (DT)、c)随机森林 (RF)、d)eXtreme Boost (XGBoost) 在每个数据点下分别针对皮质醇、肾上腺素和血红蛋白的分析预测性能的奇偶校验图
通过计算确定系数R2和单种成分含量评估的均方根误差RMSE的平均值,获得每个模型的平均R2和平均RMSE作为评估指标。因此,平均R2和平均RMSE的数值可以用来量化不同模型针对混合样本溶液中三种成分含量分析的整体预测准确性。其中,平均R2可以代表整体精度,而平均RMSE被视为多目标回归模型中的损失函数,也可以用于最佳超参数组合选择。从对于训练集和测试集的光谱数据分析结果来看,性能良好的模型应该能获得较高的平均R2值和较低的平均RMSE值。更重要的是,模型对于训练集和测试集的光谱数据分析而获得的平均R2和平均RMSE之间的相似值可能暗示着模型的通用性。反之,若模型对于训练集和测试集的光谱数据分析而获得的评估指标之间存在巨大差异,则可能表明过度拟合或欠拟合。
表1和表2分别展示了使用支持向量回归 (SVR)、决策树 (DT)、随机森林 (RF) 和 eXtreme Boost (XGBoost) 对于训练集和测试集的光谱数据针对混合物中皮质醇、肾上腺素和血红蛋白进行定量分析而获得的平均R2和平均RMSE.

表1 不同模型使用训练集进行分析的评估指标比较
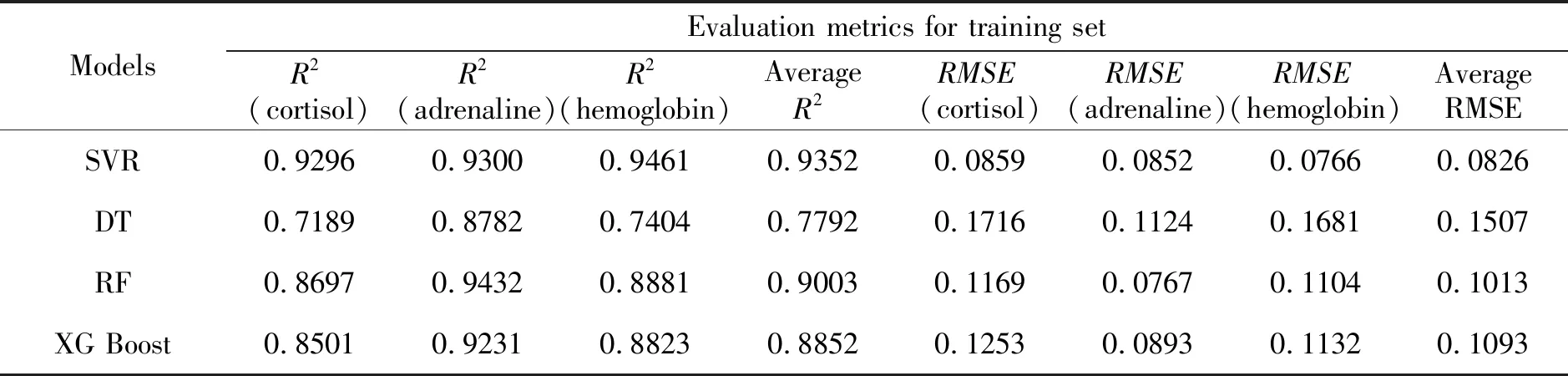
表2 不同模型使用测试集进行分析的评估指标比较
其中,支持向量回归(SVR)和随机森林(RF)在对于训练集和测试集的光谱数据分析中都能获得平均R2大于0.9的高数值,表明这两种模型对成分含量分析的预测精度高于90%。此外,考虑到模型的通用性,本研究还比较了这两种模型对于训练集和测试集的光谱数据分析而获得的两项评价指标之间的绝对差异。使用支持向量回归(SVR)对于训练集和测试集数据分析之间的平均R2的绝对差异(0.0207)小于使用随机森林(RF)对于训练集和测试集数据分析之间的平均R2的绝对差异(0.0837),表明支持向量回归(SVR)在平均R2方面的评估下可认为是更通用的模型,可以很好地测量因变量与自变量的方差比例[10]。并且,使用支持向量回归(SVR)对于训练集和测试集数据分析之间的平均RMSE的绝对差异(0.0147)小于使用随机森林(RF)对于训练集和测试集数据分析之间的平均RMSE的绝对差异(0.0611)。就平均RMSE而言,支持向量回归(SVR)是一种更通用的模型,它可以更好地做出与真实值误差更小的准确预测。根据总体评估数值,在本研究中,支持向量回归(SVR)和随机森林(RF)都可以被认为是用于拉曼光谱分析的四种模型中最好的模型。
2.3 模型改进
基于机器学习算法在分析混合物中皮质醇、肾上腺素和血红蛋白含量的性能表现,光谱数据的多目标回归分析模型还可以继续改进。由于多目标回归模型是由三个独立模型构建的,同一种算法不一定对每种成分分析都能获得最优秀的预测性能,因此可以通过搭配不同种算法来分别针对不同目标成分进行分析,例如用支持向量回归(SVR)来量化皮质醇和血红蛋白,搭配随机森林(RF)来进行肾上腺素的定量分析,最终提高针对所有目标成分含量分析的预测准确性。此外,因为深度学习算法通常优于经典机器使用更多数据学习算法,无需人工干预数据预处理[11]。搭建分析模型时还可以通过使用卷积神经网络 (CNN) 来获得比支持向量回归 (SVR) 更高的预测精度值,实现由于94%的多目标组分含量分析准确率。总体而言,由于三种与压力相关的生理指标分子的拉曼光谱数据具有高维复杂性以及微弱和重叠的光谱特征,需要搭建和优化基于机器学习算法的多目标回归模型来针对每种组分进行定量分析,将来可以结合更先进的算法来进一步改进模型,实现更高的分析预测准确率。
3 结论
通过将拉曼光谱与机器学习相结合,建立多目标回归分析模型,可以实现在二元和三元水相混合物中针对每种与压力相关的生理指标分子进行定量分析。在针对皮质醇、与睾酮相关的肾上腺素、以及血红蛋白的模型优化和比较中,支持向量回归 (SVR) 在对于训练集的光谱数据分析中获得平均R2的最高值0.9352和平均RMSE的最低值0.0826,特别适合针对皮质醇和血红蛋白的含量分析。使用随机森林 (RF) 可以获得0.9003的平均R2和0.1013的平均RMSE,也具有优秀的分析预测性能,尤其适合针对肾上腺素的含量分析。构建的分析模型还可以通过结合不同的机器学习算法并添加额外的组件来得到进一步的改进,比如通过使用卷积神经网络 (CNN) 来获得比支持向量回归 (SVR) 更高的预测精度值,实现由于94%的多目标组分含量分析准确率。结果表明,尽管与压力相关的生理指标分子具有重叠的光谱特征,通过拉曼光谱和多目标回归机器学习算法的结合,可以实现在二元和三元混合水溶液中针对每种生物标志物的准确量化,有望解决多目标成分光谱定量分析的难题,将来在健康监测的应用中发挥关键性作用。
