基于深度学习的聊天机器人自动化平台设计
2023-09-25肖俊辉冉国翔朱荣清陈镜宇张天乙
肖俊辉,孙 丽,冉国翔,朱荣清,陈镜宇,张天乙
(东南大学成贤学院电子与计算机工程学院,南京 210000)
0 引言
本项目的灵感来源于QQ群中的群聊机器人小冰,其功能包含入群欢迎、提醒打卡、简单的游戏交互等,那么我们能否创造一个功能更加完善、更加类似人类、更加贴合特定群聊特色的(个性化的)机器人加入群聊之中呢?一个对计算机编程了解甚少的人又如何能够在群聊中拥有自己所需要的机器人呢?于是我们便计划开发一个平台,使得更多的人能够通过低代码甚至无代码的简单方式获取和培养个性化的聊天机器人,旨在将本技术简单化、日常化,带入人们的日常生活。
经过多方渠道考察,从1950 年开始,随着聊天机器人相关研究的不断发展,已有众多聊天机器人产品相继面世,目前的热点便是2022年11 月30 日由美国OpenAI 公司发布的聊天机器人程序ChatGPT,其为人工智能技术驱动的自然语言处理工具,能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动,真正像人类一样来聊天交流。这一里程碑式的技术革命便是深度学习应用越来越广泛,技术越来越成熟的体现,其核心通过机器来模仿人类的对话内容和习惯,对聊天输入的内容做出决策和判断,给予相应的回应。
现如今国内外虽已出现众多的聊天机器人产品,但都在个性化和简便性方面有所不足,导致目前大部分聊天机器人还是需投入到客服环境中使用,因此如果实现了聊天机器人个性化和简便性的突破,便可走进普通人的日常生活,小到供人消遣娱乐、排忧解难,大到协助公司部门进行人事管理、甚至能够做到24 小时不间断提供高质量人性化服务等,以其个性化程度进军各行各业,将拥有巨大的市场潜力。
本项目计划开发一个基于深度学习的聊天机器人自动化搭建平台的软件产品,试图在上述技术方面有所突破,弥补现阶段QQ小冰在群聊趣味性、个性化上的不足,以低代码甚至无代码形式对机器人进行操作。本项目产品与QQ小冰的功能对比见表1。
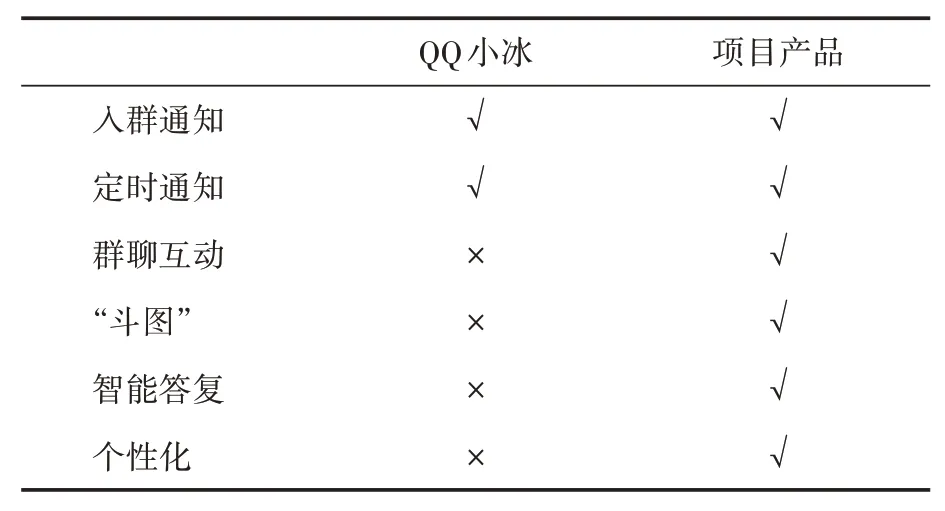
表1 本项目与QQ小冰功能对比
1 总体设计
软件总共分为三个系统,如图1所示,包括聊天数据收集系统、聊天回复系统和自动化训练系统。

图1 总体架构
2 详细设计
2.1 软件设计
2.1.1 聊天数据收集系统
通过Mirai框架,运用Http技术[1],使得QQ能与软件连接,可以自动将聊天记录生成一个“问—答”的词库,其中对数据集过滤方式包括:用户自定义策略、常用的无用语句、敏感隐晦字眼分析。最后根据词库链生成训练用语料集。
2.1.2 聊天回复系统
同样通过Mirai 框架,让QQ 群或者私聊作为一个聊天室的载体,可以收集数据的同时,使用训练的模型给出特定的回答,并回复在群聊中,系统功能架构如图2所示。
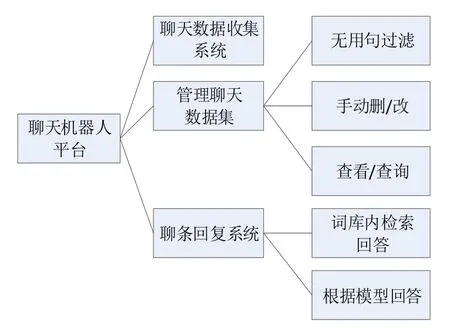
图2 收集/回复系统功能架构
2.2 模型训练设计
2.2.1 数据预处理
因为群聊内的聊天有时候会出现上文不接下文的情况,此时如果直接将聊天内容原封不动地生成对话场景模型,将会使得模型上下文逻辑混乱。我们设计词库链的初衷就是为了能更好地生成对话场景。
每个回答均是上一个“问题”的“答案”和下一个回答的“问题”,“问题”和“答案”均有一个“出现频率”的属性,据此可以较好地模拟聊天的对话场景,生成对话模型。
2.2.2 进行tokenize(标记化)
在文本分割的步骤上,我们从传统的词向量[2]转而使用了同为Transformer的BERT框架[3-4]的tokenize,能很好地应对一词多义的问题,从而提高模型对语言的理解能力,如图3所示。

图3 tokenize示意图
2.3 模型训练
2.3.1 切分训练集和测试集
读取上一个步骤生成的预处理数据,将它们按照一定比例划分为训练集和测试集。
2.3.2 读取预训练模型
群聊语料集对于训练一个模型来说还不够庞大,所以本文使用GPT-2 预训练模型[5-6]来训练我们的模型。
2.3.3 自回归训练
在强大的GPT-2 模型基础上,我们采用自回归训练方式,让模型输出能更加符合语料集的聊天场景,加强连续聊天能力,如图4所示。
图4 自回归概念图
2.4 训练结束指标
2.4.1 模型训练指标(loss)计算
在每一批次的训练中,通过前向传播计算出模型的预测输出和实际输出,使用反向传播算法计算出损失函数值(loss)以及对应训练模型参数的梯度,同时进行梯度裁剪[7],防止发生梯度爆炸,进行一定次数的梯度积累后,根据梯度下降算法,更新模型的参数,完成一轮训练。
2.4.2 生成困惑度最低模型(Perplexity)
困惑度可以被看作是一个语言模型中预测的不确定性大小的加权平均。在相同的测试数据集上,一般来说,困惑度越低,模型的性能就越好。
在一次训练中,通过对每个批次的loss值进行加权平均就可以得到一次训练的loss值,在测试集上使用同样的算法得出测试loss值后,与最佳测试loss 值进行比较,低于最佳测试loss 值的将保存,在每轮训练中不断更新与迭代困惑度最低模型,如图5所示。
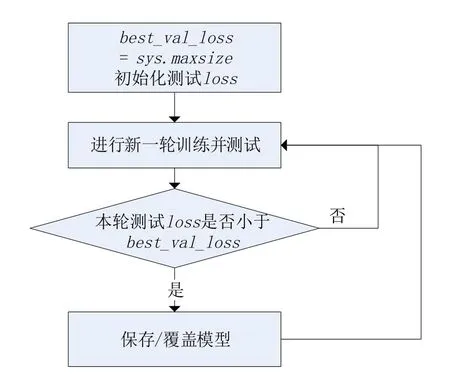
图5 生成困惑度最低模型逻辑
在本文的多次测试中,有时候困惑度低,模型的生成效果不一定会越好,所以最后采用loss 收敛来判断训练结束,loss 值稳定且不再下降则训练完成,如图6和图7所示。
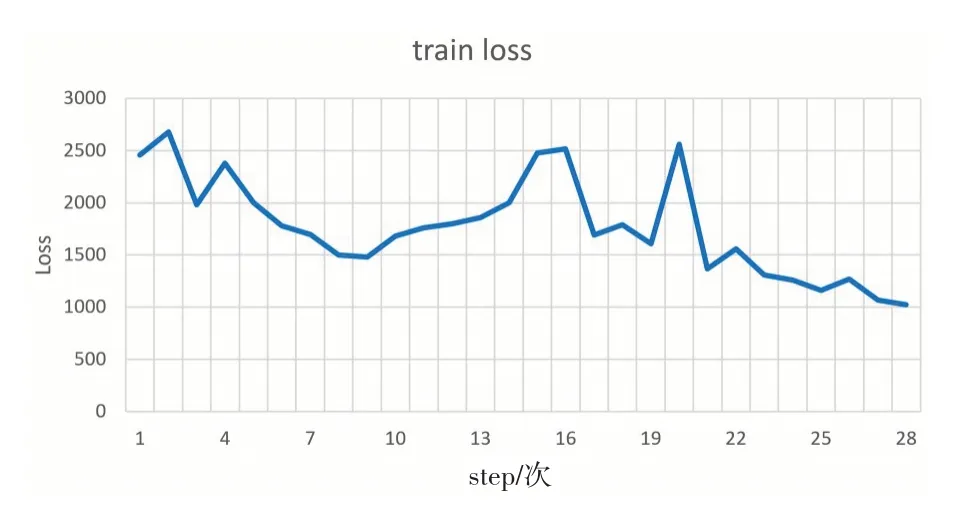
图6 训练初期loss值变化
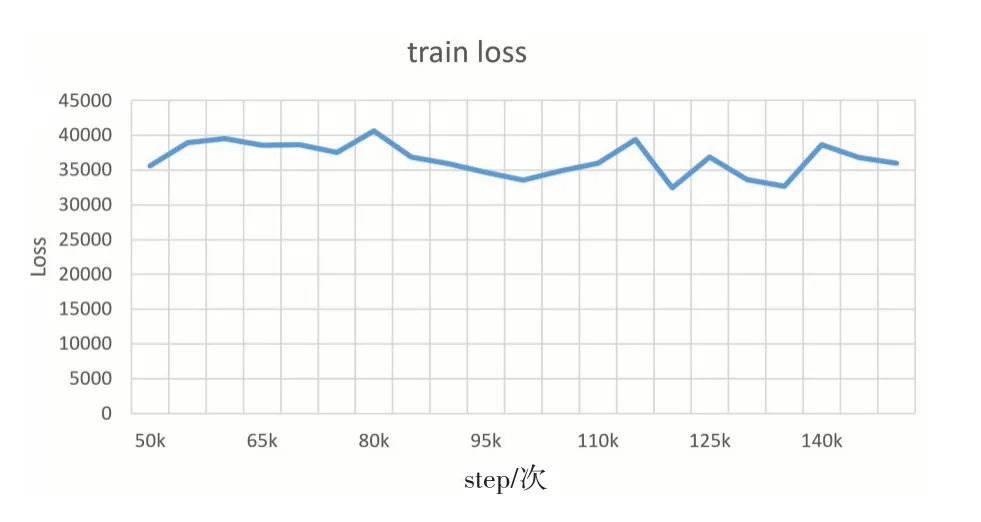
图7 训练后期loss值变化
3 软件测试
3.1 软件操作说明
软件操作流程如图8所示。

图8 软件操作流程

图9 功能列表
3.2 软件流程测试
首先进行收集系统测试,添加群聊“add learning”,开始记录“learning”,如图10 所示,收集一段时间后得足量数据,进行数据预处理,如图11所示。

图10 收集系统测试

图11 数据预处理测试
将生成的语料集置于训练环境进行模型训练,如图12 所示,注意关注loss 值浮动幅度,等待训练结束,如图13 所示。训练完成后将模型重新加载至机器人内部,如图14所示。
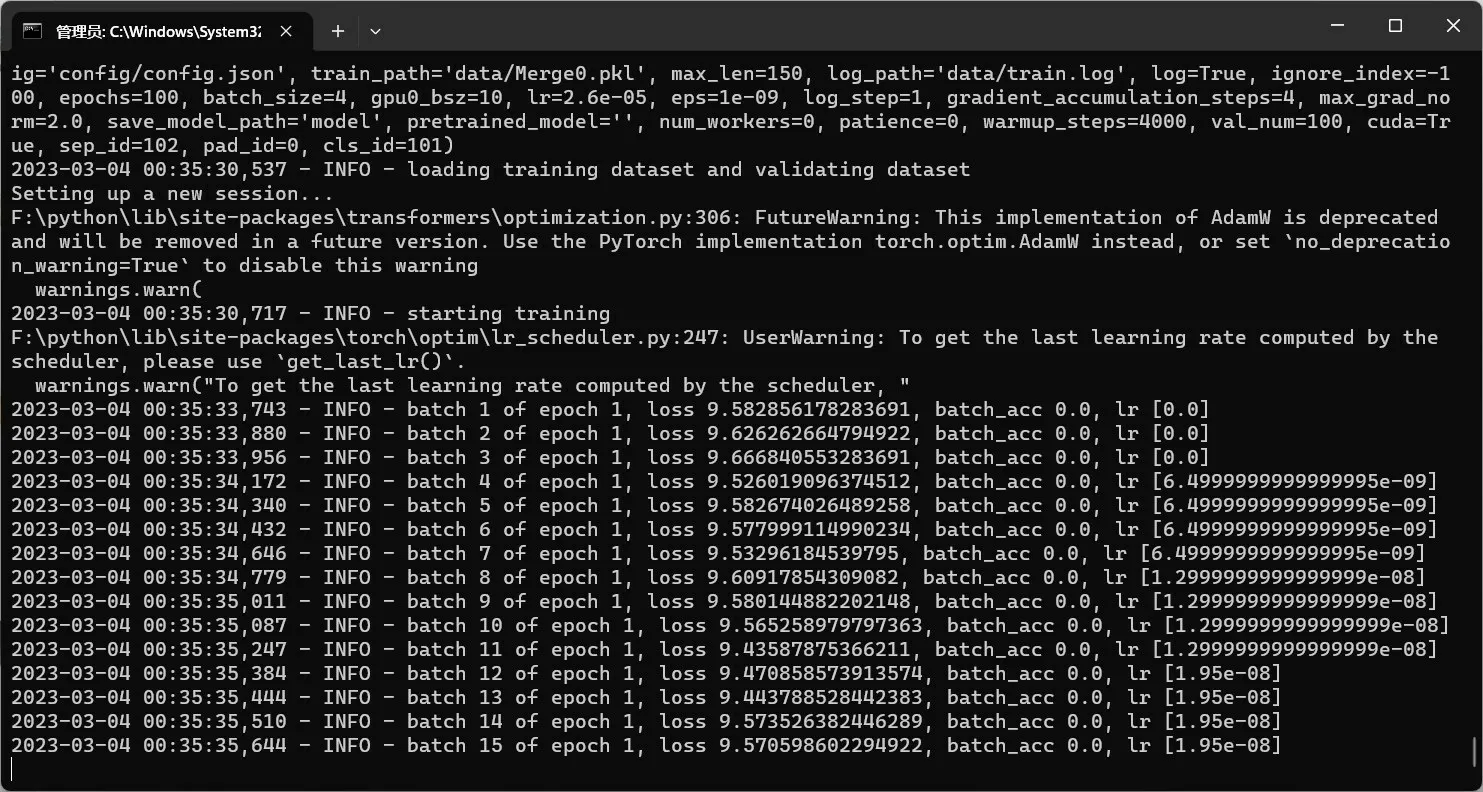
图12 模型训练测试

图13 训练Loss可视化测试

图14 训练模型加载测试
4 结语
本文详细介绍了一个基于深度学习的聊天机器人自动化平台,该平台旨在为普通用户提供一个亲民简单的方式来构建个性化的聊天机器人,从而将这项技术更广泛地应用于日常生活。所设计的平台分为“收集系统”“回复系统”“训练系统”三个模块,三个模块相互分离,方便用户根据需求灵活地选择和使用。
“收集系统”负责连接群聊,自动收集聊天记录并生成相应的问答词库。经过过滤无用信息和敏感内容后,将收集到的聊天数据用于训练语料集。而“回复系统”则负责在群聊中使用训练好的模型或收集的词库进行智能回复。“训练系统”模块则包括数据预处理、模型训练和模型优化等环节。
通过这一设计,本文为普通用户提供了一个易于操作、个性化的聊天机器人搭建平台。这不仅有利于推动人工智能技术在日常生活中的应用,还能满足各种不同场景的需求。在未来的研究中,我们将不断改进和优化本平台的功能和性能,以满足用户不断增长的需求,推动聊天机器人领域的发展。
