基于强化学习DQN算法的智能决策模型研究
2023-09-25韩中华
韩中华
(北方工业大学理学院,北京 100144)
0 引言
众所周知,作为毫无规律可循的时间序列数据,提升股票数据的预测精度一直备受金融领域的关注。然而,随着大数据与人工智能领域的不断发展,利用计算机实现自我学习以及大批量计算,对预测准度的提升不容小觑。其中,强化学习作为一种倍受瞩目的机器学习方法,它利用与环境交互过程中的奖励函数激励计算机学习,模拟人脑在学习过程当中的特点。自Alpha Go以4∶1击败著名围棋选手李世石后,强化学习瞬间掀起了人工智能领域的研究浪潮,这一技术特点被应用在包括金融在内的不同领域,进而凸显其强大的学习能力。因此,强化学习将在未来广泛应用于金融领域。
目前,强化学习在金融股票投资组合这一领域应用十分广泛。例如,为了验证DDPG算法的有效性,齐岳等[1]以我国股市为例,发现利用强化学习方法构建的投资组合,在实验期间的价值增幅远大于对照组,进而得以验证。焦禹铭[2]通过对比A2C、PPO与SAC三个模型,发现SAC模型无论是在获取收益还是在风险控制方面的优势最为显著。考虑到股票价格变化受到多种因素影响,陈诗乐等[3]将遗传算法(GA)与Transformer模型结合,提出GA-Transformer 这一组合模型,该组合模型要优于传统单模型的效果。
本文将DQN(Deep Q Network)算法作为基线,将三个不同优化层面(Double-Q、Prioritized-replay以及Dueling)随机组合成七个优化模型对HDFC银行(HDB)历史交易数据进行预测,主要贡献在于:①找出三种优化方案分别对DQN 算法预测的影响作用;②对比三个优化层面之间的联系以及影响程度;③对短期股票收益预测产生的随机性进行多次实验取平均值,与基线模型进行预期收益平均水平与波动情况的对比分析。
1 模型构建
1.1 DQN算法思想及其优势
相较于传统的Q-learning 算法,DQN 算法解决了其Q-table 无法使用在状态与动作为连续的高维空间中。通过将Q-table 更新替换为一个函数拟合的问题,以此来获得处于相近状态的输出动作。这样,将Deep Learning(DL)与Reinforcement Learning(RL)两者相结合,便可获得DQN。
在DQN 算法中,存在下列问题:首先,由于DL 中存在噪声与延迟性,导致许多状态与奖励的值普遍为0;其次,尽管DL 当中每个样本之间相互独立,但是RL 当前状态的返回值则依赖后续状态的返回值;最后,当使用非线性表达式表示值函数时,可能会出现不稳定的情况。
针对上述问题,DQN 通过以下方面进行优化:首先,Q-learning 中使用奖励来构造标签;其次,采用经验池(Prioritized-replay)来解决相关性以及非静态分布的问题;最后,采用主网络(Main Net)产生当前状态的Q值,使用另一个目标网络(Target Net)产生相应的目标Q值。
1.2 DQN神经网络的构建
由图1 可得,在使用Tensorflow 来实现DQN的过程中,一般选用两个神经网络进行搭建。其中target_net 用于预测Q_target 的值,但它并不会及时更新其中的参数;eval_net 用于预测Q_eval,该神经网络拥有最新的神经网络参数。这两个神经网络的结构是完全一致,只是其中的参数并不一样。
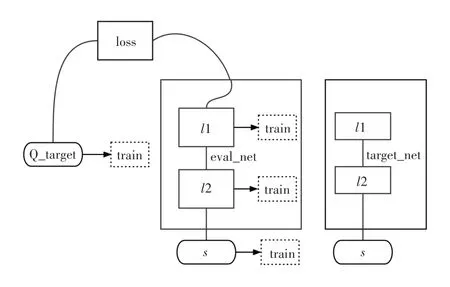
图1 DQN网络
除了传统的DQN 方法之外,可以通过对其进行优化,得到下列三个DQN 的优化算法:①Double DQN:解决了原本DQN 算法中Qmax导致Qreality当中的过估计问题;②Prioritized-replay DQN:在训练过程中对奖励较高或者较低的值加以重视;③Dueling DQN:将每个状态的Q值分解成每个状态的Value加上每个动作的advantage。
本文将DQN 算法作为基准,与七个组合模型的交易策略进行比较。表1 为DQN 算法与三个优化因子之间的组合情况。
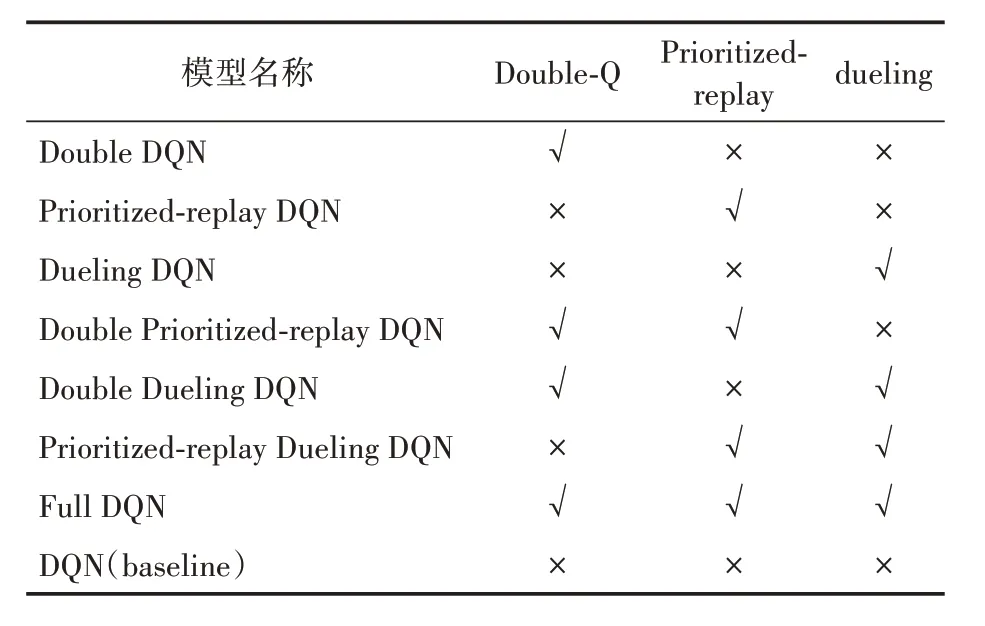
表1 三个优化因子与DQN算法的任意组合
2 数据来源及样本选择
本文选取的股票数据取自雅虎金融(yahoo finance)网站,选取的对象为HDFC Bank(HDB)。本文设定的时间区间为2020 年9 月2 日至2022年9 月2 日这两年期间所有交易日的历史价格与成交量数据,包含最高价(high)、最低价(low)、开盘价(open)、收盘价(close)、成交量(volume)以及调整后的收盘价(adj close)共计505条。图2是历史数据集的总体趋势图。

图2 HDB股票2020年9月2日到2022年9月2日历史收盘价轨迹
从图2 中,大致可以看出HDB 股票收盘价的历史变化趋势。从2020 年10 月到2021 年4 月保持上升趋势,但2021 年4 月到2022 年7 月之后整体呈下降趋势,2022 年7 月到2022 年9 月有所回暖。
3 实证研究
将原始数据分为以下两个部分。其中,训练集选取数据集中的前15~450 条数据,从第450~505条数据则作为测试集来评估模型。
为了控制其他变量的影响,将固定移动预测步长(window_size)为15 天,即预测下一天股票短期收益情况取决于前15 天的历史数据;将总时间步数(total_timesteps= 150000),即循环训练的总时间步长为150000次。
本文展开分析的角度共有两个。首先,通过七种组合方法与单模型DQN 这一基线方法的对比,寻找出哪一个组合模型对短期股票预测效果较为贴切实际;其次,通过最终预测的短期股票收益情况,以此来确定这三种优化方面之间的相互促进或抑制作用。
3.1 七个组合模型以及基线模型的预测情况
在原始DQN 算法的基础之上,可以优化的方面为以下三个,分别是:Double-Q,Prioritizedreplay 以及Dueling。通过这三个优化因子的任意随机组合,将产生七个组合模型以及一个基线模型。将Double DQN、Prioritized-replay DQN、Dueling DQN、Prioritized-replayDoubleDQN、Dueling Double DQN、Prioritized-replay Dueling DQN、Full DQN 以及DQN(baseline)模型分别标记为1~8。考虑到每一次评估模型的预期涨跌情况为一随机数,选取20 次实验的结果以避免偶然性发生。表2 为这七个组合模型(序号1~7)以及基线模型(序号8)在测试集上最终持有资产相较于原始投入资产所占比重。

表2 七个组合模型以及基线模型在测试集上最终持有资产占原始投入资产比重
对表2 中的七个组合模型与基线模型DQN算法的20 次结果计算对应的平均资产变动情况(即平均值)与波动幅度(即标准差)。表3为这七个组合模型与DQN 这一单模型的股票预期平均资产变动与波动情况。
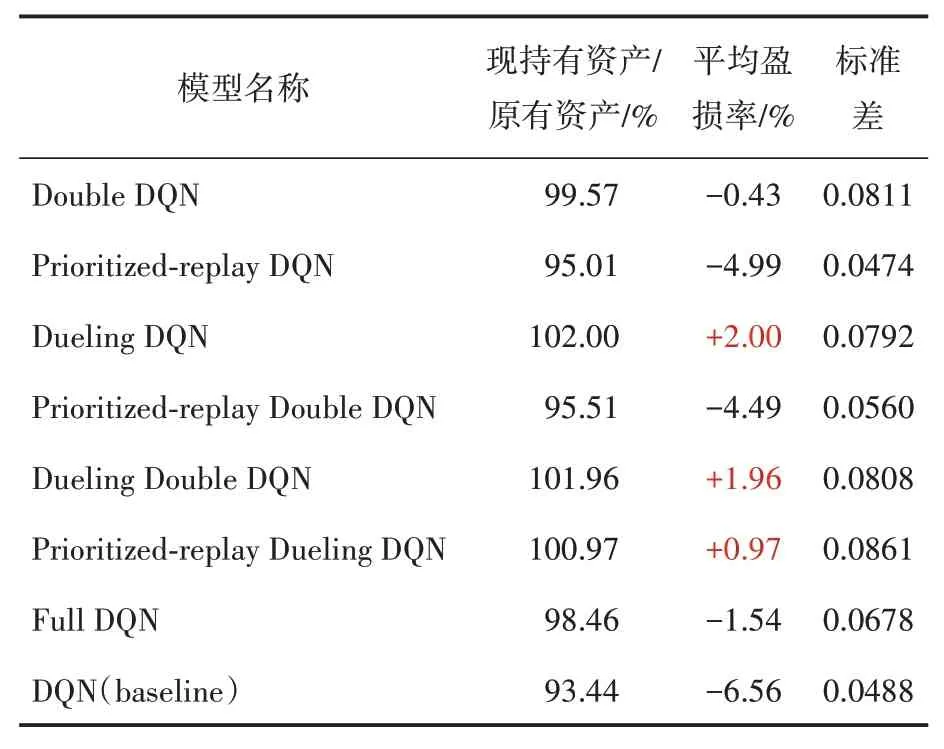
表3 DQN算法及其组合模型的股票测试集上预期资产变动与波动情况
通过表3,可以发现在前三种加入单一优化方面组合算法当中,只有Dueling DQN 这一组合算法的现有资产较原始投入资产上涨幅度最大,为2.00%。因此,说明Dueling DQN 这一方法在预测股票短期收益方面较为贴合实际情况,其精度较高。其次则为Dueling Double DQN 模型,其现持有资产相较于原始投入资产上涨1.96%,说明在原本的Dueling DQN 模型中加入Double-Q后未对原始模型起到显著性的抑制作用,基本保持了原有的收益水平。最后则为Prioritizedreplay Dueling DQN 这一组合算法,相较于原始投入资产,其现有资产上涨了0.97%,说明在原本的Dueling DQN 模型中加入Prioritized-replay后,未对原本的Dueling DQN 算法起到任何促进作用,仅仅保持了微弱的收益幅度。由此说明,在这三个优化因子中,Dueling 这一优化因子的促进作用最强,其次是Double-Q,最后则为Prioritized-replay。
从最后一列的标准差,可以看出,相较于原本的DQN 模型,只有加入Prioritized-replay 这一优化因子后,标准差由原本的0.0488 降低至0.0474,由此可见波动幅度有小幅度的降低。说明Prioritized-replay 这一优化因子对DQN 模型的稳定性具有促进作用。而Dueling DQN 模型相较于原本的DQN 模型,其标准差上涨了0.0304。而该上涨幅度小于Double DQN 模型相较于原本的DQN 模型的0.0323。由此可见,在这三个优化因子中,对DQN 模型稳定性起到促进作用的为Prioritized-replay,对模型稳定性起到抑制作用的为Dueling以及Double-Q。
3.2 三个优化因子之间的关系
表4汇总了本文七个组合模型在测试集上的各项性能的表现,包括年华化收益率与夏普比率。
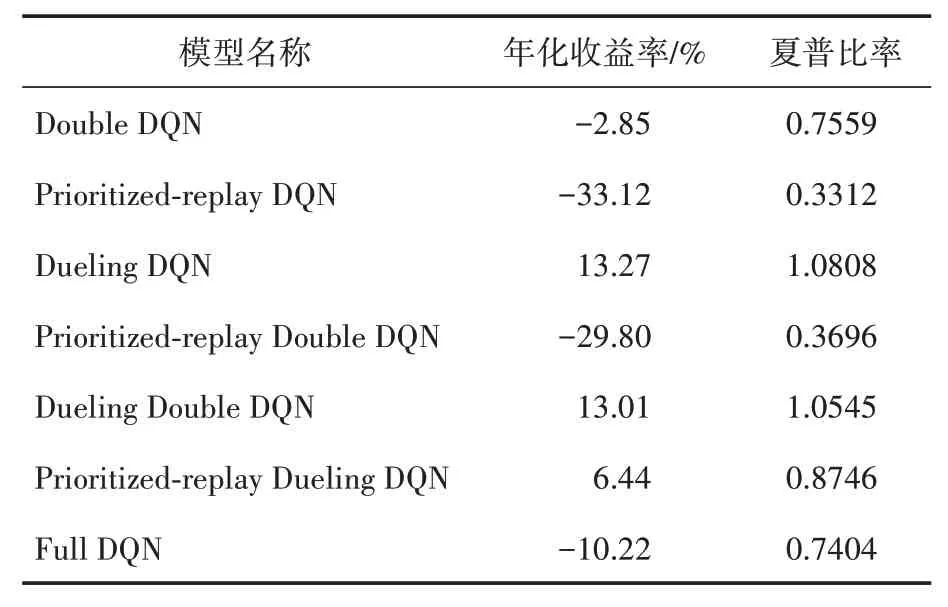
表4 七个组合算法的回测结果(测试集)
本文计算年化收益率的计算公式为:
其中:“现持有资产/原有资产”选取表3 中七个组合模型的结果,测试集天数为55(即505-450=55)。最终结果如表4所示。
对于夏普比率的计算,本文基于原本的公式进行了调整与改动。由于原始公式中包含无风险利率,本文将无风险利率替换为表3 中DQN 模型的现持有资产占原有资产的平均比重,为93.44%;而原始公式中的投资组合预期报酬率与其标准差也相应地替换为表3中七个组合模型的现持有资产占原有资产的平均比重以及标准差。本文计算夏普比率的公式为:
在年化收益率方面,基于Dueling DQN 模型在测试集上达到了13.27%,基于Dueling Double DQN 模型在测试集上达到了13.01%,基于Prioritized-replay Dueling DQN 算法在测试集上达到了6.44%。这三个模型均为在回测中有所盈利的,剩下的模型则均有所亏损。从整体上看,在原本的Double DQN 与Prioritized-replay DQN 模型中分别加入Dueling 这一优化因子后,其年化收益率均有显著性提升;在原本的Double DQN模型与Dueling DQN 模型中加入Prioritized-replay这一优化因子后,年化收益率有明显的负增长;在原本的Prioritized-replay DQN 模型与Dueling DQN 模型中加入Double-Q 这一优化因子后,年化收益率未起到了显著性改变。
在夏普比率方面,基于Dueling DQN 算法在测试集上达到了1.0808,基于Dueling Double DQN 算法达到了1.0545,剩下的组合模型均小于1。由此可见,Dueling 与Double-Q 这两个优化因子对DQN 模型均起到了促进作用,并且将二者同时加入模型中不会对模型起到显著性的抑制作用。
4 结论及建议
本文通过将DQN 算法结合三个不同优化方面的七个相互组合模型,与单一模型DQN 算法进行对比,得出以下结论:①这七个组合模型中,只有Dueling DQN 算法的盈利率达到了最高,为2.00%,说明该模型对股票短期收益预测结果最为贴合实际;②这三个优化方面之间,Dueling 对Double-Q 与Prioritized-replay 均起到了显著性促进作用,而Prioritized-replay对Double-Q与Dueling 均起到了显著性抑制作用,Double-Q则对Prioritized-replay 与Dueling 未起到显著性改变;③将三个优化方面对DQN 算法共同优化,相较于单一模型DQN 算法而言,盈亏率有所上升,由此可以得出三个优化方面之间存在相互独立的作用。
本文在股票短期收益预测方面利用深度学习当中的DQN 算法进行探索,针对不同三个优化方面进行对比验证,为后续将深度学习应用于金融领域奠定了基础。鉴于短期预测的不稳定性,在未来后续研究中仍有可以优化提升的方面。个人认为后续研究还可以在两大主题上进行展开:①引入较为稳定的预测方案及优化技巧的前沿方案,以此来抑制随机性带来的影响;②可将该DQN 算法应用在金融其他领域,例如投资领域,以此来促进我国金融领域智能化大力发展。
