基于多维数据挖掘的学生学习画像构建
2023-09-25许惠惠
许惠惠
(山西药科职业学院器械工程系,太原 030031)
0 引言
随着信息技术和大数据时代的到来,数据驱动的决策在教育领域中受到极大的关注。学生学习画像可以提供有关学生学习习惯、人际关系、家庭背景等方面的信息,有助于教育工作者深入了解学生的需求,从而提供更为个性化的教育方案[1-3]。本研究旨在探讨多维数据在学生学习画像中的应用,利用多种数据挖掘技术,综合分析影响学生学习能力的因素,并尝试通过学生的多种学习属性构建学生的全方位学生学习画像。
数据挖掘是一种从大规模、复杂的数据集中提取有用信息、知识和规律的过程。这种技术结合统计学、机器学习、人工智能等多种方法,对原始数据进行处理、归纳和挖掘,为决策者提供有价值的参考依据[4]。利用这种技术,教育工作者可以更精确地评估学生的学习需求,建立相应的学生画像,从而为他们提供个性化的教育支持。
学生学习画像的构建具有重要的实际意义,它可以帮助教师发现学生的潜在问题,及时调整教学策略,提高教学质量。同时,学生学习画像还可以为学生提供有针对性的学习资源和建议,促进他们的自主学习[5]。然而,构建一个有效的学生学习画像并非易事,需要考虑诸多因素,如个性特征、家庭背景、社会经历等[6-7]。因此,本研究通过收集大量学生数据,分析这些因素与学生习惯的关系,为构建学生学习画像提供参考。
本研究共收集了273 名学生的调查问卷数据,包括五个方面的属性信息:人际关系、个性特征、家庭背景、社会经历和健康状况,以及五个维度的学习习惯主题问题。通过对这些数据的分析,我们将提取与学生学习习惯相关的背景特征,并尝试利用数据挖掘方法探索学生各维度信息对学习习惯的影响,从而构建学生学习画像。
1 方法
本研究旨在基于多维特征提取构建学生学习画像并预测学生学习习惯类型,最终构建不同类型的学习习惯类型学生画像。在此部分中,将详细阐述研究方法,包括数据收集、问题定义以及模型构建。
1.1 数据收集
首先,为了获取学生的多维背景信息数据,本研究设计了一份涉及学生五个背景领域的调查问卷,共计收集了273 名学生的相关信息。调查问卷包含人际关系、个性特征、家庭背景、社会经历和健康状况五个方面的属性特征,这五个属性特征与学习习惯和学生学习画像之间的关系如图1所示。

图1 学生学习画像属性图
其中每个属性含有三个具体的衡量指标,见表1。我们选择这五个属性是因为它们通常被认为是影响学生学习习惯的重要因素。例如,学生的人际关系和社会经历可能会影响他们的团队合作能力和社会适应性;个性特征可能会影响他们的学习方式和动机;家庭背景可能会影响他们的学习环境和资源;而健康状况则可能影响他们的学习效率和持久力。因此,这五个方面的信息为我们提供了学生学习画像的全面视角。

表1 调查问卷样例格式
同时为了对学生学习习惯做一个综合全面的描述和评分,我们还设计了一份用于统计学生学习习惯的调查问卷,见表2,该调查问卷主要从五个方面对学生的学习习惯进行刻画,以多个维度来评估学生的学习情况。

表2 学生学习习惯调查问卷
1.2 问题定义
本研究中,我们将学生画像中的学生学习习惯类型作为衡量学生学习画像的一项主要指标,将上述统计中学生五个方面的背景信息(人际关系、个性特征、家庭背景、社会经历和健康状况)作为影响学生学习习惯的因素。将学习习惯类型预测作为一项分类任务,目的是确定学生的哪些因素指标对学生学习能力的影响较高。在实验设计中,每个学生会有以上五维的表征向量,每个向量中包含三个衡量指标分数,标签即为学生的学习习惯类型,学习习惯类型预测任务定义如下:
问题定义:给定学生S的五维表征向量,见公式(1):
其中:si表示五个主要因素的指标得分,xi代表每个因素下的具体指标,如人际关系中的朋友圈子数量、社交活动频率和团队合作能力评分等。
学生的学习习惯类型为y∈{1,2,3,4,5} ,分别对应{A,B,C,D,E}不同的学生学习类型,这五种类型由表2 中的学习习惯调查问卷得出,主题包括学习时间管理、学习方法、学习动机、学习环境、学习压力和应对策略等。
学生的学习习惯类型预测任务可以被描述为学习一个映射函数:
其中:A是映射矩阵,y是学生的学习习惯类型。预测问题为一项分类任务,目标是预测特定学生画像下的学习习惯类型。
本文目标是从各项背景指标中挖掘出与学生学习习惯具有较强关联的指标,这些指标将作为后续针对学生课程设计和学习习惯加强的关键依据。
1.3 模型构建
为了从多维数据中提取与学生学习习惯相关的特征,本研究采用了支持向量机(support vector machine,SVM)和K 近邻(K-nearest neighbors,KNN)算法并行地提取处理调查问卷中的五个主要因素:人际关系、个性特征、家庭背景、社会经历、健康状况,将相关指标作为输入,提取出与学生学习习惯类型高度相关的特征表征。
例如,对于人际关系因素,本方法将朋友圈子数量、社交活动频率和团队合作能力评分这三个属性输入到SVM 和KNN 模型中,生成特征表征。同样的方法也被应用到其它四个因素的处理上。
这些特征表征被融合起来,作为学生的综合特征表示,这个向量代表了学生在各因素上的表现和属性的组合。随后将其输入到多层感知机(multilayer perceptron,MLP)模型中,MLP模型会根据这个综合特征向量预测学生的学习习惯类型。
这一研究设计旨在通过SVM 和KNN 对各因素的详细处理,以及MLP 对各因素关系的深度理解,实现对学生学习习惯的准确预测和理解。以期通过这种方法提供一个准确和有深度的理解学生学习习惯类型的方式。本研究的模型如图2所示。
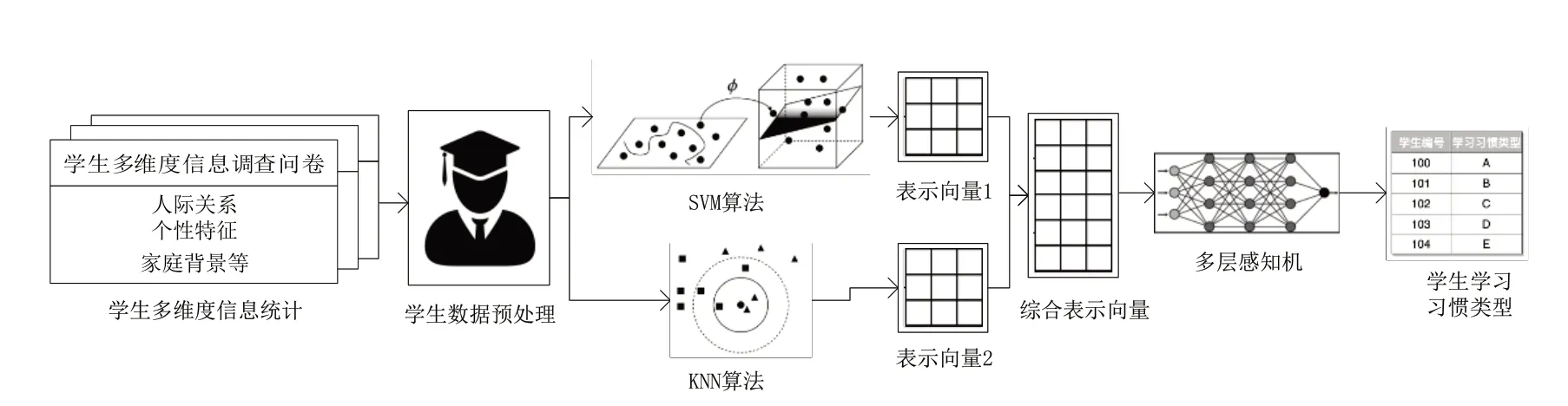
图2 模型结构
1.3.1 基于支持向量机的特征提取
支持向量机(SVM)是一种监督学习方法,主要用于分类和回归任务[8]。SVM 算法的基本思想是找到一个最优超平面,将不同类别的样本尽可能地分开[9]。在本研究中,由于学生不同特征属性之间关系很难直观被发现,所以在我们的应用中,SVM 主要用于处理调查问卷中关于学生个性特征和家庭背景的问题,比如学习动机评分、时间管理能力评分、家庭经济状况、父母教育水平等,这些特征在高维空间中的分布可能会影响学生的学习习惯类型。我们使用SVM 对学生的原始数据进行特征丰富,进一步提升学生的特征维度,有益于后续模型从中学习到关于不同表征之间的关系。SVM 通过构建最大间隔超平面,提取出对预测任务具有较高贡献的特征[10]。
SVM 模型的输出特征向量是从特征提取后的数据中得出的,使用多项式核函数的计算如公式(3)所示:
其中:xi为训练样本的特征向量,yi为样本的标签,αi为对应样本的拉格朗日乘子,b为偏置项,c和d是多项式核函数的参数,最终得到样本同学的基于支持向量机的特征表征向量。
1.3.2 基于KNN的特征提取
K 近邻(KNN)算法是一种基于实例的学习方法,同样可用于分类和回归任务[11]。KNN 算法的核心思想是根据一个样本在特征空间中距离最近的K个邻居的类别来确定该样本的类别[12]。KNN 能够处理调查问卷中关于学生人际关系的问题,比如朋友圈子数量、社交活动频率等,还可以处理调查问卷中关于学生社会经历的问题,比如志愿者活动次数、兼职经历次数等。这些特征在局部空间的相似性可能会影响学生的学习习惯类型。KNN通过计算样本间的距离并分析邻近样本的类别,找出具有较强预测能力的特征[13]。本研究中,我们使用欧几里得距离度量方法,对应的计算如公式(4)所示:
其中:xi为学生i输入的样本特征,yi为学生i对应的习惯类型。
1.3.3 多层感知机
多层感知机(MLP)是一种前馈神经网络,我们使用四层(输入层、两个隐藏层和输出层)网络的结构。MLP 可以用于解决复杂的非线性问题,并广泛应用于分类和回归任务[14-16]。在预测阶段,我们将SVM 和KNN 提取的特征拼接,并输入到MLP模型中。MLP通过激活函数、权重更新和反向传播算法,在训练过程中学习到最优的权重参数,从而实现对学生学习习惯类型的预测。
我们首先初始化参数,包括隐藏层和输出层的权重和偏差,然后对于每个学生,将其输入向量馈送到网络中,计算输出,随后计算输出和真实标签之间的误差,使用误差来调整模型参数。其中每个隐藏层和输出层,计算加权和激活函数如公式(5)所示:
其中:W为权重矩阵,B表示偏置,f是ReLU激活函数。
进而计算输出层的误差,使用交叉熵损失函数,如公式(6)所示:
其中:N是样本数;y是真实标签;y′i是预测值。
本研究通过对多维特征进行分析,构建了一个有效的学生学习习惯类型预测模型。该模型能够较好地预测学生的学习习惯类型,并为教育工作者提供有益的信息,以便更好地理解学生的学习状况和需求。
2 实验
2.1 实验参数和环境设置
在实验参数设置方面,我们为支持向量机(SVM)选择了多项式核函数,参数C 设为1,参数γ设为0.1。对于K 近邻(KNN)算法,我们设定邻居数量(K)为5,并采用欧氏距离作为距离度量。对于多层感知机(MLP),我们将输入层节点数设置为与拼接后的特征数量相等,隐藏层节点数为128,输出层节点数与学习习惯类型类别数量相等。
本文使用Python 3.7.9作为主要的编程语言,并在Ubuntu 20.04 LTS 系统上运行实验。使用的主要Python 库包括NumPy 1.18.5、Pandas 1.0.5、Matplotlib 3.2.2、 scikit-learn 0.23.1 和PyTorch 1.13.0。实验运行在一台Intel(R)Core(TM)i7-9700K CPU的计算机上,配备了16 GB的内存和四块NVIDIA GeForce RTX 2070显卡。
2.2 性能评估指标
为了评估提出的方法在预测学生学习习惯类型方面的性能,我们使用准确率、精确率、召回率和F1 分数等指标对分类结果进行评估,指标的数学描述如下。
准确度如公式(7)所示:
精确度如公式(8)所示:
召回率如公式(9)所示:
F1分数如公式(10)所示:
其中:TP表示真正例(true positive),TN表示真负例(true negative),FP表示假正例(false positive),FN表示假负例(false negative)。
3 实验结果分析
3.1 模型结果分析
根据本研究的实验结果,我们得到了模型的准确率、精确率、召回率和F1 分数。此外,本文还引入了三种经典的对比方法,分别为决策树(decision tree,DT)、随机森林(random forest,RF)和逻辑回归(logistic regression,LR)。表3是各模型的结果对比。
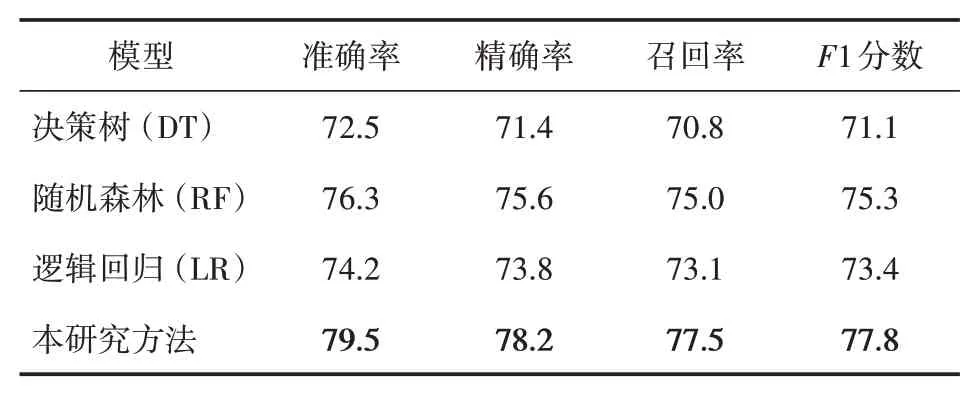
表3 模型结果对比/%
从表3 可以看出,本研究所提出的模型在准确率、精确率、召回率和F1 分数等指标上均优于其他三种对比方法。这说明我们的模型在预测学生学习画像中的学习习惯类型方面具有较高的性能,表现出较好的稳定性和泛化能力。同时,这也证实了将SVM、KNN 和MLP 结合使用的方法在学生学习习惯预测任务上具有一定的优势。
为了深入了解五个指标(人际关系、个性特征、家庭背景、社会经历、健康状况)对学生学习习惯的影响,我们对每个不同学习习惯进行了分析,其混淆矩阵如图3 所示,可以发现本文模型对学习习惯最佳(标签为1)的学生群体预测准确率最高,对学生学习习惯中等(标签为2)的学生预测准确率最低。

图3 结果混淆矩阵

图4 时间管理型学生画像

图5 探索式学习型学生画像

图6 热情驱动型学生画像

图7 环境适应型学生画像

图8 压力应对型学生画像
我们进一步对模型中的权重进行了分析。权重分析能够帮助我们量化各个背景属性对学生学习习惯的影响程度。通过对本研究中学习习惯和背景属性的综合分析,我们发现以下规律:
(1)个性特征:在五个指标中,个性特征对学生学习习惯的影响最大。这可能是因为学习动机、时间管理能力等因素直接影响学生的学习效率和学习习惯。具有较高学习动机和良好时间管理能力的学生在学习过程中更有目标性,从而形成更好的学习习惯。
(2)家庭背景:家庭背景在五个指标中对学生学习习惯的影响排在第二位。家庭经济状况、父母的教育水平,以及家庭对学习的支持程度等因素可能间接影响学生的学习资源、学习环境和心理压力。在一个有利于学习的家庭环境中成长的学生往往能更好地专注于学业,从而形成较好的学习习惯。
3.2 学生画像分类
除了研究学生的背景信息对学生学习习惯的影响外,我们进一步根据不同的学生学习主题进行了学生画像的分类,以下是五种不同类型的学生画像及其所对应的不同的学习习惯类型和特点。
(1)时间管理型学生画像:这类学生的学习时间管理能力强,他们能有效地规划和利用自己的时间,对于完成学习任务和准备考试有着出色的策略。他们通常对自己的时间表有严格的掌控,且往往在时间管理上展现出显著的自律性。
(2)探索式学习型学生画像:这类学生的学习方法倾向于探索和实验,他们善于寻找和试验新的学习方法,以提高学习效率和理解能力。他们乐于接受新的观念和思维方式,以及积极探索未知的领域。
(3)热情驱动型学生画像:这类学生具有强烈的学习动机,他们对学习充满热情和兴趣,能够主动并积极地进行学习。他们对学习的热情驱使他们在面对困难时坚持下去,激发他们不断进步的动力。
(4)环境适应型学生画像:这类学生对学习环境有较高的适应能力,无论是在安静的图书馆还是在嘈杂的咖啡厅,他们都能保持良好的学习状态。他们能够利用各种环境资源,灵活调整自己的学习方式和习惯。
(5)压力应对型学生画像:这类学生对学习压力有出色的应对策略,他们能有效地管理和减轻学习压力,保持良好的学习心态。他们明白压力是学习过程的一部分,并已学会如何将其转化为推动自己前进的动力。
4 结语
本研究致力于揭示学生的五个核心维度——人际关系、个性特征、家庭背景、社会经历以及健康状况对学生学习习惯的影响,并通过多维度特征分析来预测学生的学习习惯类型。实验结果证明,本文模型在预测准确率、精确率、召回率以及F1 分数等关键指标上,相较于决策树、随机森林和逻辑回归等常见方法,展现出更高的预测性能。此外,根据学生的学习习惯类型,我们成功绘制了五种不同的学生学习画像:时间管理型、探索式学习型、热情驱动型、环境适应型和压力应对型。
未来的研究应重点关注如何更有效地利用这些画像来实施个性化教育,特别是如何通过改变环境和教学方式来改善学生的学习习惯。此外,我们还需进一步探讨不同学生画像之间的动态变化,以及学生画像与其学术成绩的关联。
总体而言,本研究不仅提供了一种有效的方法来预测学生学习习惯,还为理解和改善学生学习过程提供了有益的理论支撑,开启了学生画像研究的新篇章。然而,我们仍需要在更大规模和更多元化的样本上进一步验证和改进模型的有效性和稳定性,以便更深入地理解学生的学习习惯,并更好地指导教育实践。
