基于既有医疗数据构建研究型数据库的方法学探讨及实例解读(二):数据治理的方法
2023-09-25赵国桢闫世艳郭玉红宋爽胡雅慧郭诗琪徐霄龙叶浩然朱泠霏杜元任志颖卢海天胡晶李博刘清泉
赵国桢,闫世艳 ,郭玉红 宋爽 ,胡雅慧 ,郭诗琪 ,徐霄龙 叶浩然 朱泠霏 杜元 任志颖 ,卢海天 胡晶李博刘清泉
1.首都医科大学附属北京中医医院,北京市中医药研究所,北京 100010;2.北京中医药循证医学中心,北京 100010; 3.北京中医药大学,北京 100029; 4.天津中医药大学,天津 301617
随机对照试验(randomized controlled trial,RCT)一般被认为是干预措施疗效和安全性评价的金标准[1]。但因其外推性较差、对于某些疾病领域难以实施、人力物力成本较高等因素,存在一定的局限性。如开展中医药RCT时,由于存在辨证论治的特点,若对患者证型加以限制,会增加患者招募难度,延长试验周期;而不对证型进行限制,又可能低估中医药干预措施的实际疗效。考虑到中医药在临床实践中被大量使用,具有较丰富的医疗数据,研究者可通过真实世界研究(real-world study,RWS),利用临床实际产生的数据,系统性地收集、治理并分析,形成真实世界证据(realworld evidence,RWE),与RCT互补,为医疗卫生决策提供证据支持[2]。相较RCT,RWS可有较为宽泛的纳排标准,但仍需科学合理的研究设计,以及完整、可靠的数据来源[3]。因此,基于真实世界数据(realworld data,RWD)开展严谨的数据治理工作,构建高质量的研究型数据库,是进行RWS的关键基础[4]。目前,国内已有多篇相关技术规范,指导研究型数据库的建设[4-5]。但因中医药RWD的复杂等特点,数据治理过程仍面临困难。
本文以“中西医结合治疗新型冠状病毒感染研究型数据库”为例,对基于既有医疗数据构建研究型数据库中数据治理的方法进行探讨。本研究经首都医科大学附属北京中医医院医学伦理委员会审查批准(2022-BL02-033-01),并在中国临床研究注册中心注册(ChiCTR2200062917)[6]。
1 相关概念和总体设计
和既有医疗数据比较,研究型数据库具有基本明确研究目的和研究对象、确定研究变量、数据格式统一、完成数据脱敏及异常数据清理等特点。为实现这些特点,严谨的数据治理工作是必要的。数据治理指针对特定临床研究问题,为达到适用于统计分析而对原始数据所进行的治理[7]。数据治理主要包括4个步骤:数据链接、数据提取、数据核查及数据清理,具体工作内容见表1[4]。各步骤间存在区别,但实施时易相互混淆,导致步骤遗漏,如人工数据提取后未进行数据核查及清洗。高质量研究型数据库的每一个变量均需按照上述步骤逐一完成。

表1 数据治理各步骤的主要工作内容
2 数据链接
构建研究型数据库的原始数据常多源,如电子医疗记录、患者自行报告的中医症状及舌象记录等,且研究型数据库通常包含多个变量集和数据模块,因此需要通过链接变量实现数据链接。原始数据中可能存在多组链接变量,如以病案号链接病程记录数据、以标本号链接实验室检查数据等。但在研究型数据库中,通常以一个准确的、无重复的、唯一的患者识别码(identification number,ID)为链接变量,实现各变量集和数据模块的链接。
数据链接的工作核心是对患者ID进行治理。患者ID是既有数据的一部分,也会出现重复、矛盾、缺失等问题。错误的患者ID会导致数据链接错误,给其他数据的治理过程带来困难,因此需先对患者ID进行核查及清理。课题组提出“纵向锁定”方法,即在数据治理前需先明确既有数据中所包含的与本研究相关的全部患者及其ID,即使该患者只在一个数据集中被提及。在待建的横截面数据集中,这些患者ID会形成一个无缺失的、无重复的纵向序列,并在全部横截面数据集中该序列完全相同。这一纵向序列在后期数据治理过程中,无论如何调整数据库变量都不应发生改变,成为“锁定状态”,故称为“纵向锁定”。
以本课题涉及的一家医疗中心数据为例,构建数据库所使用的既有数据包括入院记录数据、出院记录数据、死亡记录数据、病案首页数据、病程记录数据、医嘱单数据、实验室检查数据、影像学检查数据共8个来源。首先对各来源数据集中的患者ID进行核查及清理,使其格式相同且与患者准确对应;接着在既有数据集内对ID进行去重,再将不同数据集的ID合并、数据集间去重、排序;最终形成该中心全部患者ID的纵向序列。具体流程见图1。
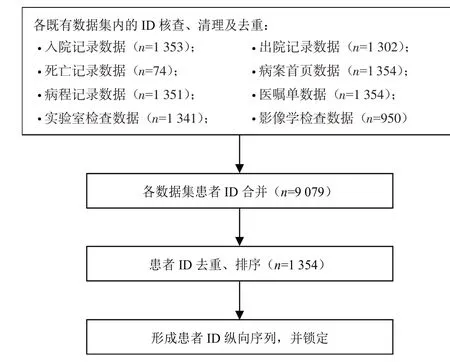
图1 患者ID纵向序列确定流程
3 数据提取
3.1 数据提取方式
原始数据通常从临床中采集,但并非所有原始数据都被用于数据库建设,因此需按照预设的数据提取表进行数据提取。数据提取可分为以下3种方式:计算机提取、人工提取和两者的结合。3种数据提取方式的优缺点及举例见表2。数据提取时,应根据待建数据库的变量格式和既有数据库的变量格式共同确定提取方式。对于结构化程度高的数据,如医嘱、实验室检查数据,可直接使用计算机提取;对于非结构化数据,或需要复杂逻辑判断数据,如从病程中提取症状、生命体征数据,通常使用计算机和人工结合的提取方式,即先通过计算机技术对其预处理,如关键词抽取、文本切割等,再通过人工方式进行数据提取;本课题多采用两者结合方式提取数据。

表2 不同数据提取方式对比
数据提取期间需重点关注的是,凡涉及到人工操作,就会因知识基础和对具体操作方法的理解不同,造成不同研究人员的提取结果存在差异的情况。减少差异的最佳方式是采用双人背靠背独立完成数据提取,再相互比对,但该方法较为耗时耗力,在数据量较大时难以实施。本课题根据实际情况,采取培训、预提取、格式限定、定期讨论、不定期抽查等方法,尽可能降低由于不同人员操作引起的差异。
以生命体征数据集中的血氧饱和度变量提取为例。对比多源数据可靠性后,选择从病程记录数据提取生命体征数据。考虑病程记录数据为非结构化文本数据,因此选择计算机和人工结合的提取方式。首先通过计算机对病程记录数据预处理。通过数据对比,病程中与血氧饱和度相关的关键词包括“SPO”“SPO2%”“血氧”“指氧”“脉氧”等42种。使用计算机截取各关键词后的10个字符,从字符中提取数字,得到初步结果,再进行人工提取。提取前对全部参加数据提取工作的人员开展培训,详细讲解数据提取方案和规则,并对5%的数据进行预提取。预提取后由数据核查团队逐一核查预提取结果,总结错误及错误原因,并通过小组会议进行讲解和讨论。同时,课题组对数据提取格式进行限定,在电子数据提取表中仅可以填写0~100的整数,否则系统会提示并自动清空已填写数据。
3.2 数据提取顺序
构建研究型数据库时,各数据集的数据提取顺序没有严格要求。但部分数据集中的某些变量会用于其他数据集变量的衍生计算,因此需先行提取。如本课题纵向数据集中的时间变量及横截面数据集中的“住院天数”“生存天数”“首次服用中药时的住院天数”等变量,其衍生运算需要基于患者基本信息数据集中的“入院日期”变量,因此优先对患者基本信息数据集、医嘱单数据集和病程记录数据集开展数据提取工作。
3.3 数据脱敏处理
数据脱敏是保障医疗数据安全的重要途径之一[8]。需进行脱敏的数据包括且不限于患者及联系人姓名、患者家庭及工作地址、患者及联系人联系方式、患者身份证及社保卡号、患者出生死亡及出入院日期、医护人员姓名及工号、住院科室等相关信息。
数据脱敏处理应在保证数据有效性的前提下进行。数据脱敏的具体方法主要分为5种。①抑制:全部或部分删除敏感信息;②去标识化:用“*”替换敏感信息;③替代:使用伪装数据、假名替换原数据中的敏感信息;④数值变换:对日期类型的敏感数据,可通过加减同一个随机天数,实现脱敏;⑤泛化:对数据进行抽象或概括性描述处理,如详细住址可泛化为“北京市东城区”。
4 数据核查
不同提取方式得到的数据均存在数据错误的可能性,且与前瞻性研究收集的数据相比,既有医疗数据出现错误的可能性更高,因此有必要开展数据核查。数据核查的难点在于确定核查范围,范围过小会遗漏错误数据,范围过大会消耗不必要的人力和时间。
本课题根据数据情况,采用抽样核查和全面核查相结合方式。抽样核查指以系统抽样方式随机抽取一定比例数据进行核查,多用于逻辑复杂的数据,如核查人工提取数据的准确性,通常为人工核查;全面核查是对该变量的全部数据进行核查,多用于逻辑简单的数据,如医嘱单中各医嘱执行时间是否在入院日期及出院日期之间,通常用计算机核查。但对于非常关键的变量,如主要结局指标等,通常也会进行人工全面核查。在抽样核查时可先确定一个较低的抽样比例,以尽可能减少工作量,但核查期间若发现某个条件下多次出现问题数据,可针对这一条件的数据提高抽样比例,甚至对该条件下的全部数据进行核查。
抽样核查以中医治疗数据集的“连花清瘟胶囊使用情况”变量为例。该变量由计算机结合人工的方式,从医嘱单、病程记录等多源数据中提取。核查组首先以5%比例进行抽样核查,发现少量自备药患者,由于医嘱单中缺少自备药的备注数据,且病程记录中误写为“莲花清瘟胶囊”,故先前未识别出患者服用该药物,被错判为“未使用”。因此,对病程记录中“莲花”等关键词补充检索并重新提取相关数据。数据提取完成后对该变量再次核查。
全面核查以生命体征数据集为例。该数据集为纵向数据,关键变量包括体温、呼吸频率、心率、收缩压、舒张压和血氧饱和度,采用计算机与人工结合的方式从病程记录数据集中提取。除抽样核查数据提取准确性外,该数据集还采用计算机对极端值、缺失值、矛盾数据进行全面逐一核查。
5 数据清理
数据清理的重点在于对核查出的各种问题数据制定恰当的清理规则。问题数据主要包括:非标准化数据、重复数据、矛盾数据、极端值和缺失值。数据清理应保证数据的真实性和可溯源性,即在清理期间,保存原始数据,并记录数据清理流程,以供后期使用。
5.1 非标准化数据
数据标准化也称为数据的一致性处理,如记录格式统一、编码统一等[5]。如本课题中的日期类型变量,该变量在SAS9.4软件中可有多种格式,不同格式包含的信息及表达方式存在差异。本研究统一采用“YYMMDD10.”作为日期类型数据格式。
5.2 重复数据
重复数据指多个不同来源的数据引起的变量和数据重复[5]。若变量的多源数据一致,一般不做特殊处理;但若变量的多源数据不一致,则需对比不同来源数据的质量,建立矛盾重复数据优先级,删除重复变量。部分重复数据还会因患者ID错误引起,本课题已对患者ID进行“纵向锁定”,因此不会出现该问题。
以基本信息数据集的“入院日期”变量为例。该变量共有6个数据来源:入院记录、出院记录、死亡记录、病案首页中的入院日期变量,以及首次病程记录日期、首次医嘱单日期。经数据质量评价,以上6个变量均有较好的可靠性。课题组将同一患者的6个数据进行比对,发现以下2个问题:
首次医嘱日期与入院日期不符。根据临床实际情况,首次医嘱日期应该是入院当天,但部分患者的首次医嘱日期是在入院日期的后1天。通过进一步查看这些患者的既有数据,发现其入院时间均在22点30分以后,首次医嘱时间均为次日凌晨,符合逻辑关系,因此仍以原有入院日期为准。
病案首页入院日期与其他来源不符。通过多源数据对比,发现极少数患者病案首页的入院日期比入院记录/出院记录的入院日期晚1天。通过查看既有数据,这些患者的首次医嘱日期与病案首页的入院日期相同,且首次病程、主治医师查房记录的日期符合病案首页入院日期的逻辑关系,最终确定以病案首页来源的入院日期为准。
5.3 矛盾数据
矛盾数据也称为逻辑错误数据,主要指变量之间不符合逻辑关系。通常需要对矛盾的各数据分别核实,找到矛盾的原因,并对数据进行修正。
如在基本信息数据集中,有个别患者既存在出院事件又存在死亡事件,2个变量矛盾。对2个变量的数据来源进行核实,发现这些患者既有出院记录,又有死亡记录,仍存在矛盾。进一步核实病程记录数据集,根据末次病程记录获得患者真实转归情况,对出院事件、死亡事件的变量数据进行校正。
5.4 极端值
极端值也称为离群值或奇异值,指某一变量中远大于或远小于其他数据的数据。极端值可分为人为极端值和自然极端值。自然极端值建议采用稳健的统计方法进行分析;人为极端值需经核实后进行校正[5]。
如生命体征数据集中的体温变量(℃),观测值出现“63.4”“364”等极端值,经课题组比对邻日体温、讨论后认为该观测值为人为极端值,均应为“36.4”。需注意的是,极端值不代表数据一定错误,但出错的可能性较高,应对其逐一清理。
5.5 缺失值
缺失值在临床研究中是一个不可避免的问题[9]。处理缺失值的最好方式是避免缺失值产生,如在回顾性研究中应尽可能对缺失值进行溯源,但通常情况下难以实现,因此需在统计分析阶段对其进行处理。
如本课题对于非结局指标类变量,根据变量类型采用均值、中位数、众数等简单且保守的填补策略;对于结局指标类变量采用多重填补法,并对不同填补结果开展敏感性分析。
6 小结
在确定变量清单和数据库架构后,应开展数据治理工作[10]。良好的数据治理,可为后续研究提供准确的、可靠的数据,是开展高质量RWS的重要基础。数据治理的难点可概括如下:①以唯一、无重复的患者ID序列进行数据链接,并“纵向锁定”;②尽可能减少不同操作人员在数据提取时的差异;③根据研究需要选择恰当的数据核查范围;④对不同类型的问题数据制定恰当的清理规则。
本文在数据提取部分,介绍了不同研究人员进行人工操作时存在差异的问题,以及减少这些差异的方法。在数据核查和数据清理阶段,同样会涉及人工操作的差异化问题。此时,仍可采用双人背对背完成、培训、数据预提取或预清理、定期讨论、不定期抽查等方法,以尽可能提高操作的同质性,减少人为误差。
中医药RWS在数据治理及数据衍生阶段仍面临一些困难。如中医四诊数据多从病程记录中提取,但由于不同医生对四诊信息的记录存在差异,且原始数据的准确性和完整性普遍不高,通常难以获得可靠的四诊信息。此外,中医治疗数据可能涉及患者服用的真实草药处方,这些处方基本不同,难以开展下一步研究。本课题组尝试使用其他来源数据对四诊信息进行补充;采用相似度匹配算法对草药处方进行分类[11],以“类方”的形式开展研究等方法解决上述问题。但如何建立高质量的中医药研究型数据库,并在此基础上开展高质量中医药RWS,仍需要临床、方法学、信息学、统计学等多学科专家共同探索。
本文以“中西医结合治疗新型冠状病毒感染研究型数据库”为例,对基于既有医疗数据建立研究型数据库中数据治理的方法及难点进行介绍。本文介绍的数据治理方法及案例可供开展RWS的研究人员参考。
