基于波动趋势分段的风电功率区间预测
2023-09-25于晓娇喻洪波王晓静
韩 丽,于晓娇,喻洪波,王 冲,王晓静
(中国矿业大学电气工程学院,江苏省 徐州市 221116)
0 引言
当今世界面临环境污染日益严重和不可再生能源日益衰竭这两大问题,各国对可再生能源的开发和应用迫在眉睫。风能作为可再生能源之一,在电力系统中得到了广泛应用,但因为风能本身具有强随机性,风电接入电网会带来不确定性。特别是在风电波动性大、功率突变事件频繁发生的场景下,预测的难度更大,对电力系统的安全稳定运行而言是一个巨大难题。为了降低这种不确定性、保证电力系统的安全稳定运行,在日内时间尺度下需要准确预测风电功率[1]。
风电功率预测包括确定性预测和不确定性预测。确定性预测是最常见的风电功率预测形式,主要有支持向量机法[2]、人工神经网络法[3-5]和组合法[6]。但含风电的电网规划、运行和安全稳定性分析领域都依赖于估计的风电功率波动范围[7]。概率预测是能反映风电功率不确定性的预测形式,主要包括区间预测和密度预测[8]。其中,区间预测主要有利用高斯分布[9]、指数分布[10]、β分布[11]等已知分布的参数型法和利用分位点回归[12]、核密度估计[13-14]等数据驱动方法的非参数型法。
文献[15]在概率分布预测的基础上实现区间预测,但由于风电的随机性和波动性,功率/误差不能完全服从任何已知分布。非参数法事先不假设功率/误差的概率分布,避免了建模误差。具体地,文献[16]提出分别对数据和模型的不确定性进行建模,但未考虑到风电功率在不同时段上的波动差别。文献[17]提出通过数值天气预报中的风速对点预测误差进行层次聚类,但该模型在高风速时段误差较大,从而导致预测精度降低。由于功率变化剧烈的时段相较于功率波动平缓的时段具有更强的非线性,文献[18]提出一种确定性预测与概率预测相结合的分段预测,但未考虑到对特殊时段的识别精度,且区间预测与点预测结果相继输出的情况不利于调度策略的制定。文献[19]基于风电爬坡特征对预测误差区间进行评估,但上爬坡与下爬坡误差分布特征相似且未对爬坡事件做出更进一步的分类。
上述文献对风电功率进行的不确定性预测在一定程度上提升了区间预测性能,但仍具有以下问题:1)没有考虑功率变化剧烈时段与功率波动平缓时段之间波动趋势的差别或未能对特殊时段精准划分,影响预测精度;2)数值上,功率变化剧烈时段下的预测误差相较于功率波动平缓时段来说普遍更大,未对其进行有效分类也是区间预测效果未能进一步提升的原因之一。
为解决上述问题,本文提出一种基于风电功率波动趋势分段的区间预测方法。首先,为提取功率实时变化趋势,对原功率序列进行滤波处理。其次,建立滑动窗口对滤波后的序列进行初步分段准备,得到表征功率序列不同变化趋势的转折点,进而根据改进的双时段划分方法得到两时段:突变时段与非突变时段。再次,分别对历史时段上的非突变时段和突变时段误差应用k-means 算法,通过聚类算法得到非突变时段上的误差区间,通过对突变时段进一步构建分类的误差云模型得到突变时段上的误差区间。最后,叠加长短期记忆(LSTM)网络模型的预测值得到全时段区间预测结果。
1 基于改进分段方法的双时段划分
1.1 功率突变时段识别原理
风电序列上的噪声会造成对趋势变化的误判,干扰时段划分。为获取对风电功率基本变化趋势的描述,完整提取时段划分的转折点,需要对风电序列进行滤波处理。采用滑动平均滤波算法对功率序列进行多层滤波处理以达到减小波动形态失真程度和减小转折点位移的目的。为完整获取时段划分点,根据文献[20]给出的参数平衡原则,确定滤波窗宽和滤波层数。滤波效果如附录A 图A1 所示,滤波后序列与原始序列相比,提取了变化趋势而滤除了局部波动。
为划分不同时段,立足趋势提取结果建立滑动窗口,通过窗口滑过的极小值位置确定转折点的位置,将其划进转折点集Bi。基于已得到的转折点集Bi,两相邻转折点之间构成一个时段,根据时段识别方法对各时段进行提取划分。
目前,尚缺乏对于功率突变时段的准确定义,但是功率突变事件与爬坡事件发生的条件相似,根据常用的爬坡特性描述方法[21],传统功率突变时段识别原理可表示为:
式中:ζ为突变时段的功率变化速率阈值;P(t)为t时刻的风电功率;Δt为时间间隔。通常,ζ可根据风电机组额定装机容量的15%~20%进行设定。
1.2 基于改进分段方法的双时段划分
在对原始曲线做上述平滑过程后,全时段的波动趋势得以提取,但存在小部分时刻的时段内部与临近时段波动的差别较大,造成波动特征被缩小。而传统功率突变时段识别的定义只能体现相邻两转折点间的功率变化速率,忽略了序列内的功率变化速率,基于转折点集和传统功率突变时段识别原理进行时段的划分,可能会出现时段误判的情况,从而影响时段划分的精度。
通过传统功率突变时段判据得到的时段划分片段如图1(a)所示,为明确示例时段,仅对示例时段的拐点进行标明。可以看出,传统功率突变时段判据立足滤波结果将示例时段1 识别为非突变段,将示例时段2 识别为突变段。然而,时段1 的两个拐点之间存在一个快速(短时)高峰值波动过程,时段2 的两个拐点内部有一个反向趋势的变化过程。总的来说,上述两时段都是滤波后序列的波动趋势与原序列差别较大的时段,本文将其统称为特殊时段。因为风电功率序列在不同时刻的波动变化情况不一,对滤波算法来说总有小部分时刻风电功率的变化让其无法完美应对,但获取风电功率基本变化趋势需要平滑曲线。
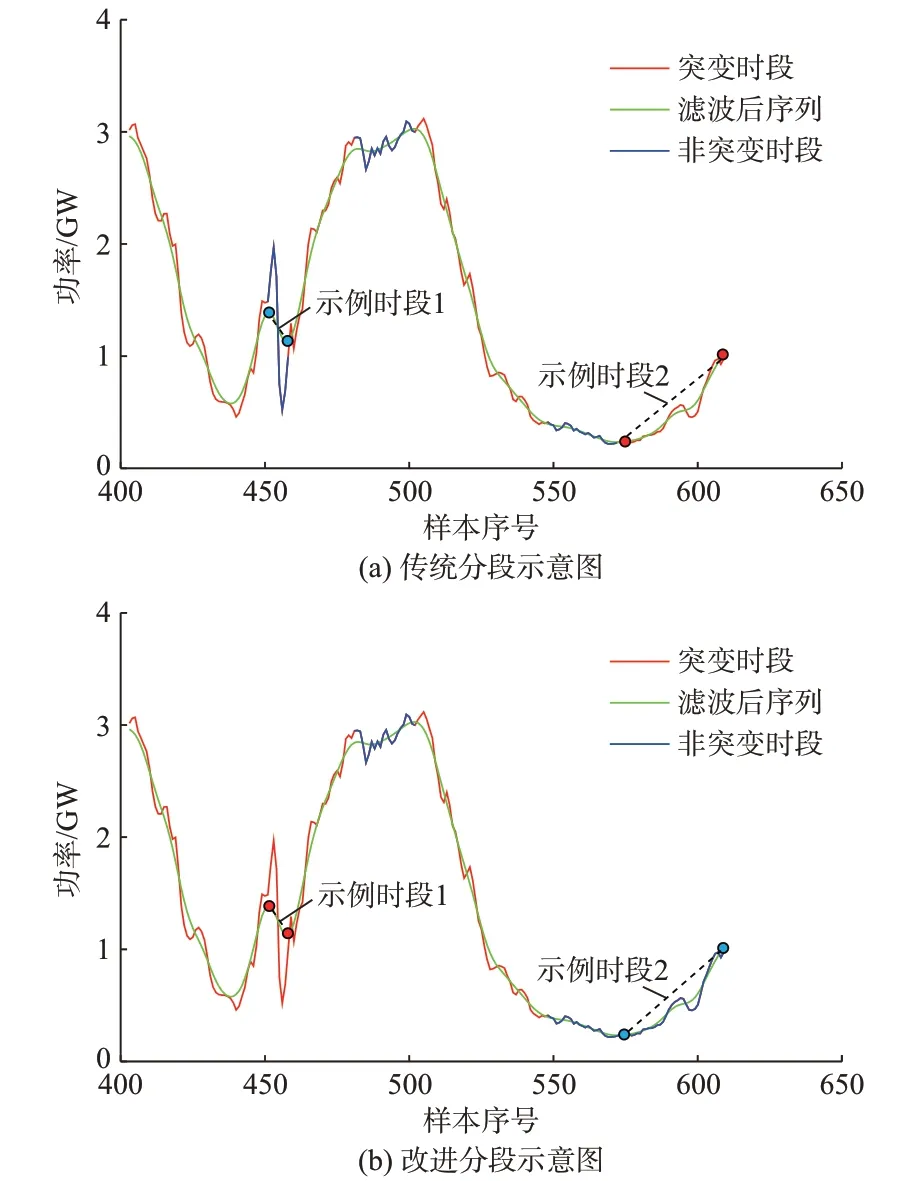
图1 分段示意图Fig.1 Schematic diagram of segmentation
为克服上述问题,对传统功率突变时段判据进行了改进。首先,求取时序变化率Sp,计算方式为:
式中:PL(t) 为滤波处理后t时刻的风电功率。
Sp较大时,在当前时段下保持Sp较大数值的时间越长,功率突变的可能性越大,该时段就越容易成为突变时段;反之,Sp较小时,在当前时段下保持Sp较小数值的时间越长,功率突变的可能性越小,该时段就越容易成为非突变时段。Sp的引入提供了序列内的变化速率,放大了特殊时段的波动特征,为时段划分提供了更多重要依据。
在以传统功率突变时段识别原理为初始依据的基础上,为精准划分特殊时段,对相邻转折点之间的变化率进行了综合考虑,提出改进的双时段划分方法。其中,式(3)为传统功率突变时段判别公式,式(4)和式(5)为改进的双时段划分方法新增公式。
式中:PBi,m为转折点集Bi中第m个点的功率;Sp,Bi,(m,m+1)为区间内的功率变化率;Sph和Spl分别为突变时段、非突变时段功率变化率阈值,与ζ相同,都是根据风电机组额定装机容量设定的;δh和δl分别为突变时段、非突变时段的时间长度系数,均取0.5;Th和Tl分别为满足条件的突变时段、非突变时段的时间长度;tBi,m为转折点集Bi中第m个点对应的时刻。
相比于ζ,Sph和Spl反映的是每一时刻功率变化率的大小,能够提供序列内的功率变化率。传统分段判断各序列变化缓慢或剧烈是针对序列首尾的;而改进分段判断各序列内每一时刻的变化缓慢或剧烈是针对序列整体,放大内部波动的过程。对改进分段来说,可通过计算序列内变化缓慢时刻的占比和序列内变化剧烈时刻的占比来划分双时段。
根据改进的双时段划分方法,具体时段划分步骤如下:
步骤1:判断式(3)是否成立,若是,识别为突变时段并且转到步骤2;若否,识别为非突变时段并且转到步骤3。
步骤2:判断式(5)是否成立,若是,纠正突变时段为非突变时段;若否,识别为突变时段。
步骤3:判断式(4)是否成立,若是,纠正非突变时段为突变时段;若否,识别为非突变时段。
通过改进的双时段划分方法得到的时段划分片段如图1(b)所示,改进的双时段划分方法将时段1纠正为突变时段,将时段2 纠正为非突变时段。在突变时段的初步提取中,由于传统功率突变时段判据未考虑每一时刻的时序变化率,只根据相邻转折点间的变化率将时段1 划分为非突变时段,在改进时段划分方法后的进一步判断中,识别到时序变化率高于突变时段功率变化率阈值的时长超过正常时长,最终又将时段1 划分到突变时段;同样地,在突变时段的初步提取中时段2 被识别为突变时段,在改进时段划分方法后的判断中,识别到时序变化率低于非突变时段阈值的时长超过正常时长,最终纠正时段2 为非突变时段。由此可见,改进的双时段划分方法能够对特殊时段的情况进行充分考虑并且给予纠正处理。
2 基于双时段划分的区间预测
风电功率区间预测不仅需要保证可靠性,还要保证合理性,即兼顾预测区间覆盖率与预测区间平均带宽。对本文来说,要满足提高风电功率区间预测性能的要求,关键在于能充分学习风电功率间非线性映射关系的点预测模型和能精确获取双时段误差区间的预测策略,其中,预测策略的制定主要包括基于双时段的误差分类和基于误差分类的云模型的建立。
基于上述双时段划分方法,获取双时段误差区间的分段预测策略显得尤为重要,当突变时段误差的不确定性不能被充分估计时,会造成突变时段的预测区间覆盖率降低;或者非突变时段误差的不确定性被放大估计,会造成非突变时段的预测区间平均带宽增大,总的来说会对电网运行的经济性和安全性带来挑战。
2.1 基于LSTM 网络的点预测模型
LSTM 网络是一种经过改进的循环神经网络,克服了循环神经网络无法保留长期信息的问题[22]。LSTM 网络是由重复结构组成的模型,包含输入层、隐藏层和输出层3 个层,基本单元结构中包括了3 个控制门:输入门、遗忘门和输出门[23]。具体表达式如下[24]:
式中:it、ft、ot分别为输入门、遗忘门和输出门的激活函数,激活函数一般为sigmoid 函数或tanh 函数;ht为中间输出状态;ct为细胞状态;xt为输入向量;Wxf、Whf、Wcf和bf分别为遗忘门的权重矩阵和偏置;Wxi、Whi、Wci和bi分别为输入门的权重矩阵和偏置;Wxo、Who、Wco和bo分别为输出门的权重矩阵和偏置;Whc为连接中间输出状态信号的权重矩阵;Wxc为连接输入状态信号的权重矩阵;bc为细胞状态的偏置。
传统神经网络在模型输入中只能学习模式本身,更类似于模式识别,而LSTM 网络可以学习到输入样本与时序之间的联系,记住之前发生的事情并将其应用到网络中,观察它们之间的联系及神经网络接下来的变化。
历史风电功率数据作为模型输入,未来4 h 内的预测功率数据作为模型输出。具体描述为在当前时刻t下,将t时刻之前的几个数据样本作为输入向量xt,同时上一时刻的模型状态ct-1和模型输出ht-1输入预测模型中,确定t时刻的输出向量ht,即t+1到t+L时刻的预测功率结果,1 ≤L≤16。LSTM网络在每次预测时都是通过先前记忆ct-1和ht-1相互关联的,并且这种记忆机制贯穿了整个预测过程。因此,LSTM 网络的学习能力既能保证在非突变段上的预测有更好的效果,也能保证在全时段上的预测具有整体良好的效果。
2.2 基于k-means 算法的双时段误差分类
风电功率点预测一定会存在预测误差,不同时段产生的误差也会具有不同的分布。为掌握两个时段误差数据的特点,对误差进行有效分类十分必要。
k-means 算法在聚类算法中优势明显,主要在于其聚类效果好、实现简单,因此在各个领域中得到了广泛应用。作为一种无监督的学习算法[25],其通过不断迭代计算得到聚类结果。算法需要在开始时设定k个初始聚类类别和k个初始聚类中心,通过计算数据样本与聚类中心的相似度,将数据聚类到相似度最大的聚类中心所在的类中。然后,通过计算各类数据样本的平均值,不断更新k个聚类中心的位置,降低簇内的误差平方和(SSE),直到SSE 不再变化或目标函数收敛,得到最终的聚类结果,借鉴文献[26]的聚类依据,取k=3。
相似度的计算是以距离函数为依据,且与距离大小成反比,即距离越大,相似度越小,距离越小,相似度越大[27]。以欧氏距离函数作为距离大小的计算,计算公式如下:
式中:a和b为实数域上的点;H为实数域上点的维数;ah和bh分别为a和b在第h维度上的值。
为精确获取功率误差区间,提高全时段下风电功率预测性能,选择分别在突变段和非突变段引入k-means 聚类算法,基于计算数据集密度设定初始聚类中心[-100;0;100],对误差类型进行更细致的划分,如附录A 图A2 所示。每隔15 min 为1 个数据点,非突变段误差和突变段误差各分为3 类:Ⅰ类、Ⅱ类和Ⅲ类,各聚类中心标记为竖线。非突变段的预测结果呈现出误差小、误差分布范围较集中的现象,突变段的预测结果呈现出误差大、误差分布范围更分散的现象,即非突变段误差的不确定性较弱,突变段误差的不确定性较强。
2.3 基于误差分类的云模型建立
在突变型天气的影响下,突变时段功率变化剧烈,其预测结果有着较大的不确定性。但当聚类对象的不确定性较大时,聚类中心只能反映类别之间的差异,不能反映类别内部误差点分布的具体情况。为了得到更精确的预测区间,需要对突变时段预测误差的不确定性进行描述,获取更多类内误差分布的信息。
2.3.1 云模型原理
数据的不确定性主要由随机性和模糊性引起,研究随机性和模糊性两种现象的主要工具是概率论理论和模糊集合理论,而云模型将这两种理论交叉渗透,可以描述定性概念和定量关系之间的不确定性转换,实现了定性和定量相互之间的映射关系。根据文献[28]可知,云模型在不确定拟合中具有不可比拟的优势,并且云模型不再强调确定的函数表示,具有普适性[29]。
假设W是定值x的集合,满足x∈W,C是定量论域W上的定性概念。论域W中任意定值元素x与定性概念C之间的关系可以描述为:x在C上的确定度Q(x)是一个有确定倾向的随机数u,称为x对C的隶属度,u∈[0,1]。定量论域W的整个分布称为云,W上的所有定值元素x称为云滴,在本文区间预测模型中,云滴为经计算变换的预测误差。关于云模型的确定性描述包括期望Ex、熵值En、超熵值He,计算公式如下:
式中:n为样本序号;xn为风电功率预测误差值;S2为样本方差;N为样本个数。
期望Ex表征云滴在定量论域上的期望,是最能体现定性概念的参数,在统计上反映的是云滴样本的平均值,在风电功率区间预测中,反映的是预测误差的平均值。
熵值En表征云滴在数值分布上的不确定性程度,是体现定性概念的云滴与期望之间离散程度的参数,在分类的云模型中,反映的是各类误差的波动范围。
超熵值He表征云滴分布的离散程度,即云的厚度,其值与云滴分布的离散程度成正比,在分类的云模型中,反映的是误差波动范围的集中程度。
2.3.2 基于误差分类的云模型建立
近年来,云模型开始在风电功率预测方面得到应用[28,30]。文献[30]首次将云模型用于风电功率不确定性预测范畴,但未分析根据其分类依据各情况下的误差特性,没有基于不确定性研究模型与误差之间的具体适配性。
2.2 节中对突变段功率误差进行k-means 聚类后分为3 类,对3 类误差分别建立云模型,生成的云滴图如图2(a)所示,确定度为1.0 处所对应的云滴为云模型的中心,同时将附录A 图A2 中对应的聚类中心标记在图2(a)中。对突变段Ⅰ类误差云模型来说,k-means 聚类中心向左有明显偏移,更偏向散落在边缘的点,即反映着强随机性的点,而云模型中心位于类内误差点分布的密集处;同理,对突变段Ⅲ类误差云模型来说,k-means 聚类中心向右有明显偏移,而云模型中心位于类内误差点分布的密集处。所以在获取突变时段误差区间时,若基于kmeans 聚类中心,则更容易因为具有强随机性的点争取更多备用裕量而不能获取可靠的误差区间。因此,本文在聚类的基础之上对突变时段做了进一步不确定拟合处理,在考虑电网经济性的同时得到更合理的误差区间。
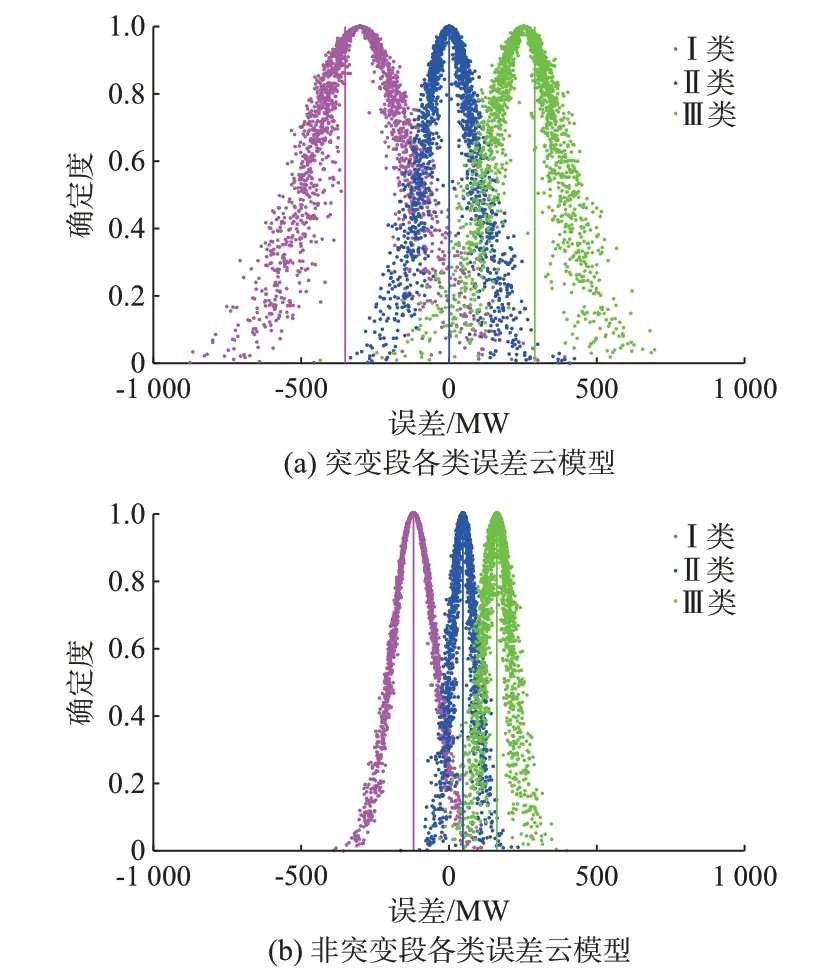
图2 各类误差云模型Fig.2 Cloud models of various types of errors
对聚类后的非突变段误差建立云模型生成云滴图,如图2(b)所示,并将附录A 图A2 中对应的聚类中心标记其中。根据图2(b)可知,非突变段3 类误差聚类中心与云模型中心之间没有明显偏移,因此,基于聚类结果即可获得精确的误差区间,无须再采用云模型对其进行拟合。
3 整体思路
本文提出了一种基于风电功率波动趋势分段的区间预测方法,整体思路过程见附录A 图A3。首先,基于预测模型输入当前待预测点前(t时刻及之前)的历史风电功率数据,获取其误差和预测值,同时根据双时段划分判据将功率序列分为两个时段:非突变时段和突变时段。其次,为得到精确的误差区间,引入k-means 聚类算法分别对两时段的历史误差进行聚类。由于非突变时段误差普遍较小,通过聚类结果获取误差区间即可,对聚类后的突变时段进一步建立分类的误差云模型以减小突变时段误差区间的宽度。最后,根据双时段划分判据确定预测点(t+1 时刻及之后)的时段分类,预测值叠加各时段对应的误差区间,最终得到区间预测结果。
区间预测模型整体思路如上文所述,改进的双时段划分方法能够充分考虑两时段之间的差异,纠正对特殊时段的误判,不同时段的预测策略能够获取精确的误差区间,从而提高模型的预测效果。
本文方法在实际使用中,面对不同的预测系统时,首先要对该预测系统进行前期学习,基于该预测系统的误差数据生成误差分布,调整误差分布参数。然后,根据实际预测系统的历史预测误差得到误差分布后,叠加在该系统的预测结果上,即可得到该系统的预测误差评估结果。
4 算例分析
本文研究的样本数据选自Elia 网站某比利时风电场提供的风电功率,样本数据的采样时间间隔为15 min,风电场装机容量为4 670 MW。具体选取2021 年全年的数据为研究样本数据,并以四季形式划分,每个季度选取其中一个月的数据构建训练集和测试集进行算例分析。本文研究的编译环境均在MATLAB2021b 和以 Python 为编程语言的PyCharm Community Edition 2021.3.2 软件中实现。
4.1 评价指标
采用预测区间覆盖率(PICP)、预测区间平均带宽(PINAW)和可靠性指标Xc作为模型的评价指标,验证模型的可靠性。
1)预测区间覆盖率XPICP
式中:M为预测点的个数;Jα为布尔数;当第α个预测点的实际风电功率值位于预测区间内,Jα=1;当第α个预测点的实际风电功率值位于预测区间外,Jα=0。
2)预测区间平均带宽XPINAW
式中:ft为待预测点;H(ft)和L(ft)分别为区间预测的上、下界;ω(ft)为区间预测的宽度;T为预测的时间区间。
3)可靠性Xc
式中:c为置信度。
XPICP和Xc反映了预测结果的可靠性,XPINAW反映了预测结果的适用性。相同的XPICP和Xc下,较小的XPINAW保证了更好的预测效果;相同的XPINAW下,较高的XPICP和Xc保证了更好的预测效果。
4.2 分段效果云模型验证分析
以Elia 网站某比利时风电场提供的2021 年1 月的风电数据为例,基于历史风电功率实际值,利用LSTM 网络点预测模型进行提前4 h 预测,得到风电功率预测值,与风电功率实际值作差得到风电功率预测误差数据。分别由未改进分段方法(传统功率突变时段识别方法)、改进双时段划分方法识别突变类型后得到了两组全时段划分结果。为了说明不同分段方法产生的误差云滴具有不同的分布,对两种分段方法对应的突变段和非突变段分别建立云模型,得到的云模型特征参数如附录A 表A1 所示。基于两种分段结果建立云模型,得到的误差云滴图如图3 和图4 所示。
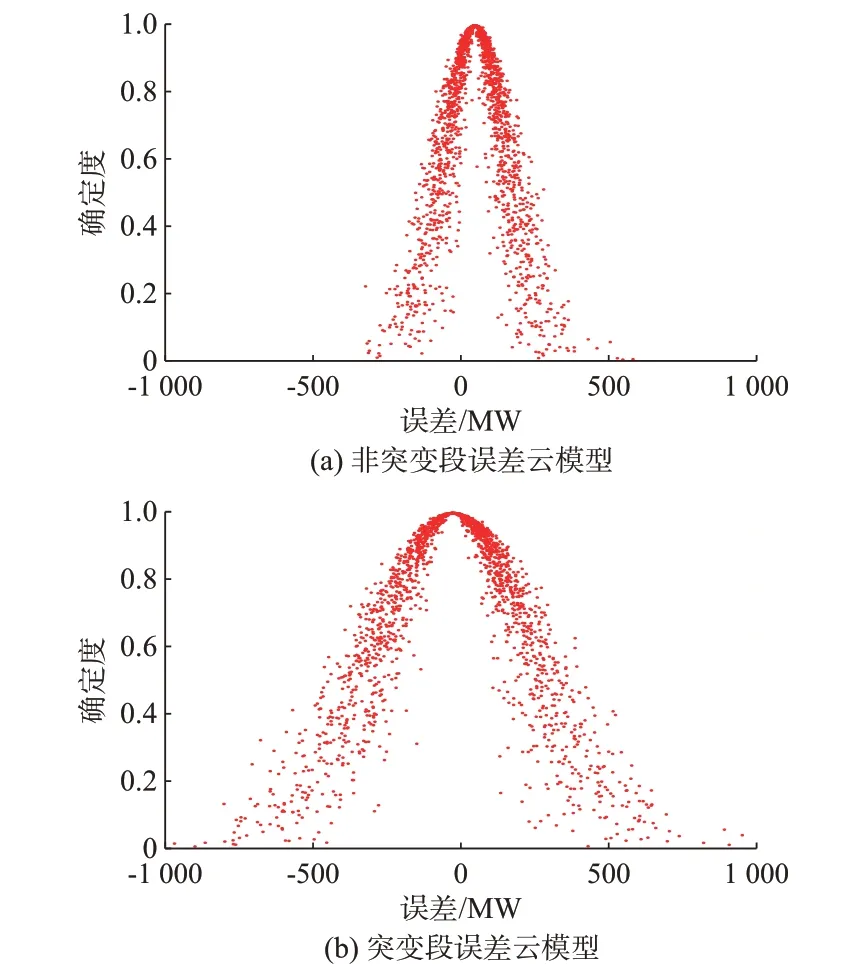
图4 基于改进分段方法得到的分类云模型Fig.4 Cloud models for classification based on improved segmentation method
根据附录A 表A1 可知,在不同分段方法的识别下,横向对比可知突变段的熵值总是大于非突变段的熵值,这说明两分段方法下突变段的不确定性更强,也就是突变段数值误差波动的范围比非突变段数值误差波动的范围更大,符合风电功率突变的分段理论依据,初步肯定了两分段方法在时段划分方面的合理性。但是未改进分段方法下两时段的超熵值都较大,说明在时段的划分中划分依据不够鲜明,不符合风电出力平缓情况下预测误差分布更集中、风电出力突变情况下误差分布随机性更强的特点。
结合附录A 表A1、图3 和图4,对不同分段方法下的云模型参数进行纵向对比,发现改进分段方法具有关键优势:1)改进分段方法下,非突变段误差云滴与其期望之间的离散程度较小,突变段误差云滴与其期望之间的离散程度较大,即两时段下误差云滴与期望之间的离散程度差别较大;未改进分段方法下,两时段下误差云滴与期望之间的离散程度差别较小。在表A1 中表现为改进分段方法下两时段的熵值相差明显;未改进分段方法下两时段的熵值相差较小。在图3 和图4 中表现为改进分段方法下,非突变段与突变段相比误差云滴分布范围明显减小;未改进分段方法下,非突变段与突变段相比误差云滴分布范围大小相近。2)改进分段方法下各时段误差波动更为集中。在表A1 中表现为改进分段方法下各时段的超熵分别小于未改进分段方法下各时段的超熵。在图3 和图4 中表现为改进分段方法下各时段误差云滴的厚度均小于未改进分段方法下各时段误差云滴的厚度。
以上优势总结为改进分段方法下各时段之间的区分更明显,相同时段中误差分布情况更相近。
4.3 全时段区间预测效果分析
为进一步验证本文分段方法的意义,以2021 年冬季为例进行区间预测。通过点预测模型进行若干组提前4 h 预测未来4 h 的滚动预测,再分别通过未考虑分段方法、未改进分段的传统分段方法和本文改进分段方法3 种不同分段方法进行置信度为90%的区间预测,预测效果见图5。基于每种分段方法得到的预测区间对应于相应的颜色区域,预测结果见表1。结合图5 和表1 可以看出,改进分段后的方法在区间预测结果中有更高的区间覆盖率、更高的可靠性和更小的区间平均带宽。具体表现为改进分段后的方法较改进分段前和未考虑分段的方法在区间覆盖率上分别提高了0.64%、1.48%,在区间平均带宽上分别减小了5.8%、8.24%,这是因为不考虑分段将导致全时段共享一个区间宽度,功率平缓时段预测区间过大。而未改进传统分段的分段方法会造成各时段误差之间区分度不高,即对非突变时段和突变时段划分不准确,将突变时段误划分到非突变时段,导致非突变时段历史误差聚类后得到的各类区间宽度都增大。同时,突变时段中误分入了部分非突变时段,造成分类的云模型中除Ⅱ类(小误差类)云模型外,其他云模型得到的区间宽度都变得更加宽泛。而采用本文改进分段后,各时段的提取更加准确,非突变时段中不包含具有大预测误差的突变时段,从而得到的区间宽度较小,同样突变时段中不包含会使聚类后Ⅰ、Ⅲ类云模型的预测区间增大的非突变时段。

表1 不同分段方法预测结果对比Table 1 Comparison of prediction results with different segmentation methods
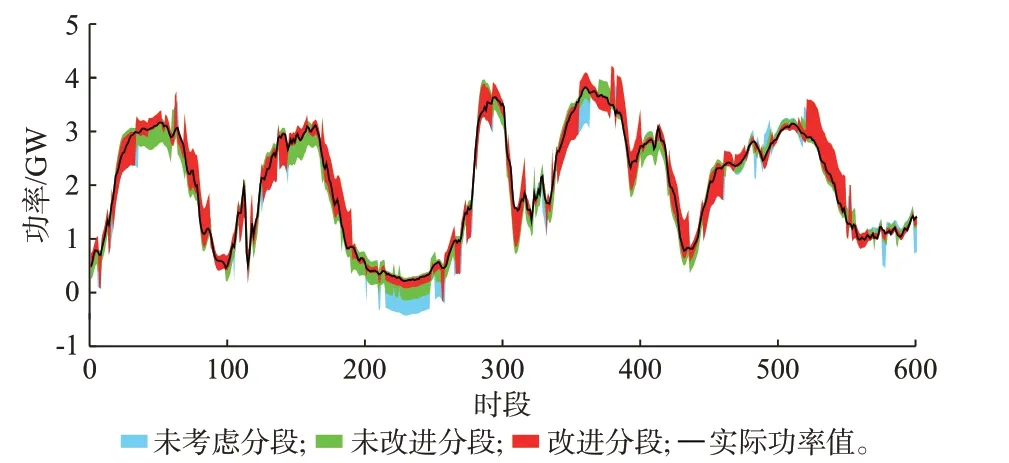
图5 不同分段方法预测效果对比图Fig.5 Comparison diagram of prediction effect of different segmentation methods
4.4 模型性能结果分析
为分析本文所提模型的性能,本节用不同模型对改进分段后的结果进行误差区间的获取,4 个季节的预测结果量化对比依次见附录A 表A2 至表A5。由于4.2 节和4.3 节已对本文改进的双时段划分方法的优势进行了验证说明,下述各预测模型中的时段划分均采用改进的分段方法。以冬季为例,提前4 h 区间预测结果如附录A 图A4 所示,背景颜色按照分段结果和聚类结果分割为6 类。其中,突变时段为冷色、非突变时段为暖色,可以看出本文方法在突变时段和非突变时段都有较好的区间预测结果,具体表现为:相比于正态分布、t分布拟合误差的方法和传统的云模型方法,本文方法在同样90%的置信水平下,在保证更高的区间覆盖率的基础上,在区间平均带宽方面有更大的优势,分别较正态分布、t分布拟合误差的方法和传统的云模型方法的区间平均带宽减小了22.39%、21.82%和21.22%。基于功率时段划分的时序模式方法与正态分布、t分布拟合误差的方法和传统的云模型方法相比,有更高的区间覆盖率和更小的区间平均带宽,特别是在预测难度较大的突变时段,优势更为明显。这是因为在分时段的基础上,又对各时段进行了按照功率时段变化的划分。为方便将时序模式方法与本文方法进行比较,在此将各时段划分为显著上升、显著下降和较平缓3 种模式。本文方法与时序模式相比较,不管是区间覆盖率还是区间平均带宽都有更明显的优势,在保证更高区间覆盖率的基础上,区间平均带宽减小了17.13%。为验证突变时段采用云模型拟合误差的必要性,对突变时段不采用云模型的预测效果如附录A 图A5 所示。根据图A4、图A5 和表A5可知,本文方法在突变时段(暖色背景)下预测区间的覆盖率更高并且带宽减少了5.78%,进一步验证了突变时段具有强不确定性,需要能很好描述其不确定性的云模型来提升预测效果。
在本文方法和其他预测方法中,均呈现出突变时段的区间平均宽度更大、非突变时段的区间平均宽度较小的现象。这是因为本文采用的预测模型在进行点预测阶段时就对功率较平缓的非突变时段表现出较高的预测水平,也印证了本文分段方法的合理性。因此,在各类误差中,基于k-means 算法和云模型得到的误差区间,非突变时段的区间宽度小于突变时段的区间宽度。上述现象在提前4 h 预测中更为明显,这是因为提前1.5 h 预测本就有较好的点预测结果,所以不管是非突变时段还是突变时段,区间宽度都较小,但仍保有上述特点。尽管点预测模型对功率较平缓的非突变时段表现出较高的预测水平,但若因此不去进一步得到非突变时段的区间预测,而直接输出点预测结果,将会使全时段上的不同时段输出不同类型的预测结果,即点预测与区间预测结果相继输出,这将不利于电网调度。
为了体现本文方法的适用性,4 个季节下采用不同方法提前1.5 h 区间预测的结果量化对比依次见附录A 表A6 至表A9。同样可知,本文方法在全时段下依旧保持较其他方法更好的预测效果,以冬季的表A9 为例,相比于正态分布、t分布拟合误差的方法、传统的云模型方法和基于功率时段划分的时序模式方法,在置信度为90%的情况下,本文方法仍能保证更高的区间覆盖率,并且在区间平均带宽方面较其他方法依次减小了5.88%、5.54%、5.96%和6.38%。突变时段下,本文方法也较不含云模型方法在具有更高可靠性的同时,平均带宽也减少了0.62%,进一步说明了云模型在不确定性较强时段下对拟合误差的必要性。提前1.5 h 预测结果中,基于功率时段划分的时序模式方法与正态分布、t分布拟合误差的方法和传统的云模型方法相比不再具有优势。这是因为在提前较短时间预测缓解了点预测模型的压力,已经得到较好的点预测结果,正如上述对提前4 h 区间预测结果的分析中提到,该方法在预测难度较大的突变时段优势明显。提前1.5 h 的预测结果进一步说明了这一点,该方法在突变时段相较于除本文方法外的其他3 种方法能保持近似的预测效果,但在非突变时段的预测结果中劣势突出,这也说明了时序模式方法不适用于风电功率预测的所有情况,从而不再具有优势。而本文方法不论是在提前4 h 的预测中,还是在提前1.5 h 的预测中,都保证了较高的区间覆盖率和更窄的区间平均宽度。总体而言,本文所提出的分段区间预测模型的预测精度高于传统模型,能满足行业要求。
5 结语
本文对风能的随机性造成的风电功率波动趋势进行研究,提出一种基于风电功率波动情况的分时段区间预测方法。与其他方法相比,本文提出的改进双时段划分方法对时段划分的精度进行了提升,克服了特殊时段误判影响预测效果的问题;提出贴合时段特点的分段预测策略,进一步精确了误差区间。以本文所提模型评价指标为依据,采用Elia 网站的风电数据为样本进行实例分析,证明本文方法在保证区间覆盖率较高的基础上有更小的区间平均带宽。
本文所提方法没有考虑气象数据,后续可以考虑多因素构成研究数据,综合考虑各方面因素对分段效果和预测效果的影响。
本文研究得到徐州市科技项目(KC22343)资助,特此感谢!
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
