改进的YOLOv3浅海水下生物目标检测
2023-09-25陈宇梁董绍江朱孙科孙世政胡小林
陈宇梁,董绍江,朱孙科,孙世政,胡小林
1.重庆交通大学机电与车辆工程学院,重庆400074
2.重庆工业大数据创新中心有限公司,重庆404100
我国渔业资源丰富,通过水下图像进行水下生物检测对于渔业资源勘测具有重要意义。目前普遍采用将摄像头放入水中的方式进行水下图像获取,该方式效率低且难以检测深水区域,而通过水下机器人搭载摄像头对海洋渔业资源进行探索能够在提高效率,并且能够对深水环境进行广泛探测[1]。传统目标检测方法通过人工进行特征提取后再分类,效率极低。自卷积神经网络被提出以来,基于深度学习的目标检测方法能够在同一个网络中进行不同尺度的特征提取,使目标检测的效率得到大幅提升,进而获得广泛应用[2]。
目前主流的目标检测方法根据网络检测顺序分为“双阶段(Two-stage)”和“单阶段(One-stage)”两类[3]。“Two-stage”目标检测算法中具有代表性的是Girshick等[4]提出的超快区域卷积神经网络(Faster R-CNN),该类算法基于候选区域进行目标分类,资源消耗较大,检测速度也有待提高。为了提高模型的检测速度,减少资源的消耗,Redmon 等[5]提出了基于深度学习的YOLO(You Only Look Once)算法,该算法为“One-stage”目标检测算法,将区域预测和分类两个步骤整合至稠密卷积神经网络(DCNN)中完成,检测速度得到大大提升,但检测精确度不如Faster R-CNN。针对精确度,Liu等[6]提出了单阶段多尺度目标检测(single shot multibox detector,SSD),通过使用不同的特征图对不同尺寸的物体进行检测的多层预测完成目标检测,但检测速度方面未得到提升,仍难以达到实时性要求。针对检测速率和精确度较低的问题,Redmon 等[7]提出的YOLOv3(YOLO version 3)采用将深层特征和浅层特征相融合的残差单元模块(Res Unit)融入到网络中,对检测速度和精确度都有大幅提升,达到实时检测的条件。因此许多研究人员基于单阶段目标检测算法对水下目标检测进行研究。袁利毫等[8]通过将YOLOv3用于水下目标检测以辅助水下机器人进行水下工作。高英杰[9]基于SSD 算法结合深度分离可变形卷积模块提高了水下目标检测的精度,但大幅增加模型的参数量后降低了检测速度,实时性较差。赵德安等[10]提出图像预处理与YOLOv3 算法相结合的方式提高了对河蟹的检测精度,但对特征模糊的水下小目标的识别精度较低。刘萍等[11]基于YOLOv3算法利用GAN(generative adversarial networks)模型提高对海洋生物的识别能力,但该方法提高了训练难度以及对数据集的要求。
但该类算法并未充分利用水下目标的特征,并且水下图像存在色彩失真和纹理不清晰,且存在目标尺寸较小或曝光问题时检测精度影响较大,存在漏检和误检的问题。
目前YOLO系列已优化到YOLOv5,该网络在对于正常场景下的数据集的检测精确度和速度上均获得更好的效果,但对目标尺寸较为敏感,在小目标的检测检测任务中效果表现较差,而水下图像中由于拍摄位置等问题极易出现小目标[12]。但YOLOv5极为精简,难以针对水下图像融入特征提取模块,因此本文将基于YOLOv3进行模型改进。
首先,针对使用人造光源改善浅海中光线较暗时易导致图像中距离光源较近物体出现局部过曝以及小目标难以检测的问题,本文在YOLOv3网络中加入残差卷积块注意力模块(residual convolutional block attention module,Res CBAM),增强对目标的特征提取能力;然后,针对浅海中水下光线衰弱严重带来的图像色彩失真和图像毛糙等影响生物目标检测识别效果的问题[13],本文采用跨阶段局部模块(cross stage partial block,CSP Block)增强特征提取,提高检测精确度;最后,针对水下生物目标尺寸差异大且数据集有限的情况,为提高小目标和过大目标的检测精确度,引入了完全交并比(complete intersection over union,CIoU)[14]的预测框损失函数进行训练,以增强预测框的适应能力,提高目标检测精确度。
1 YOLOv3模型框架
YOLOv3模型主要由主干(backbone)、连接颈(neck)和预测头(head)三个部分组成,结构如图1所示。
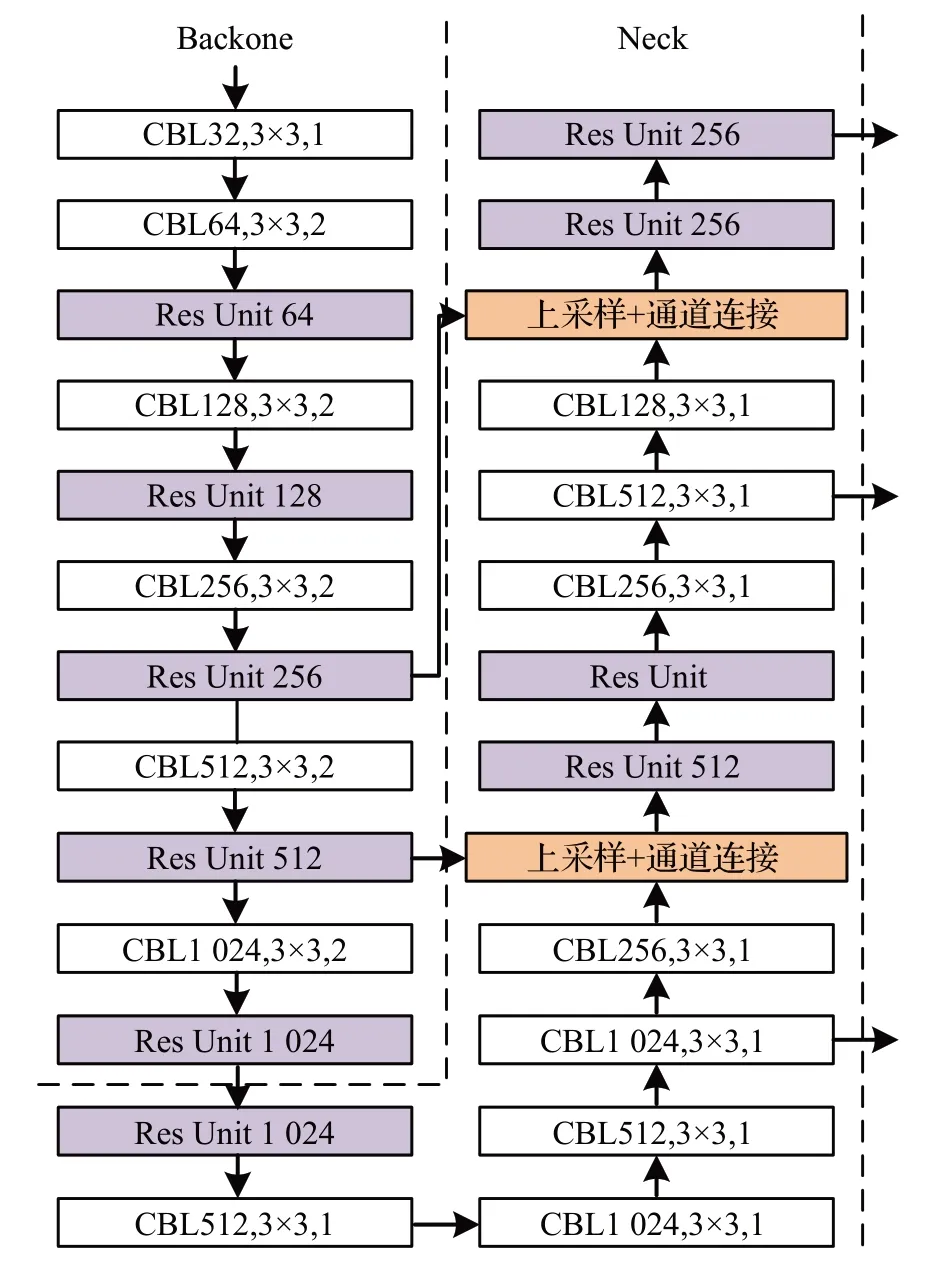
图1 YOLOv3模型结构图Fig.1 YOLOv3 module structure diagram
YOLOv3 的主要由卷积模块(CBL)和残差单元模块(Res Unit)组成。darknet-53 网络是YOLOv3 模型的主干部分,负责图像的特征提取。其中,卷积模块由卷积(Conv)层、标准归一化(BN)层和Leaky ReLU 激活函数组成;残差单元模块如图2所示,基于经典残差结构,由卷积模块和相加融合(Add)模块组成,计算如式(1):

图2 残差单元模块结构图Fig.2 Res Unit structure diagram
y=CBL3×3(CBL1×1(x))+x(1)其中,x表输入的图像特征,y代表经提取后输出的图像特征,CBL(x)计算如式(2):
其中,CBL模块结构如图3所示。

图3 卷积模块结构图Fig.3 CBL structure diagram
连接颈部分在YOLOv3 中将主干部分输出特征进行特征融合。
预测头部分起目标检测识别的作用,通过连接颈部分输出的多尺度特征生成预测框和识别类型作为目标检测识别结果输出。
2 用于水下生物目标检测的改进型YOLOv3模型
本文将YOLOv3 与所构造的跨阶段局部模块和残差卷积块注意力模块相结合,提出了YOLO-fish 结构,如图4所示,并使用CIoU进行损失计算。
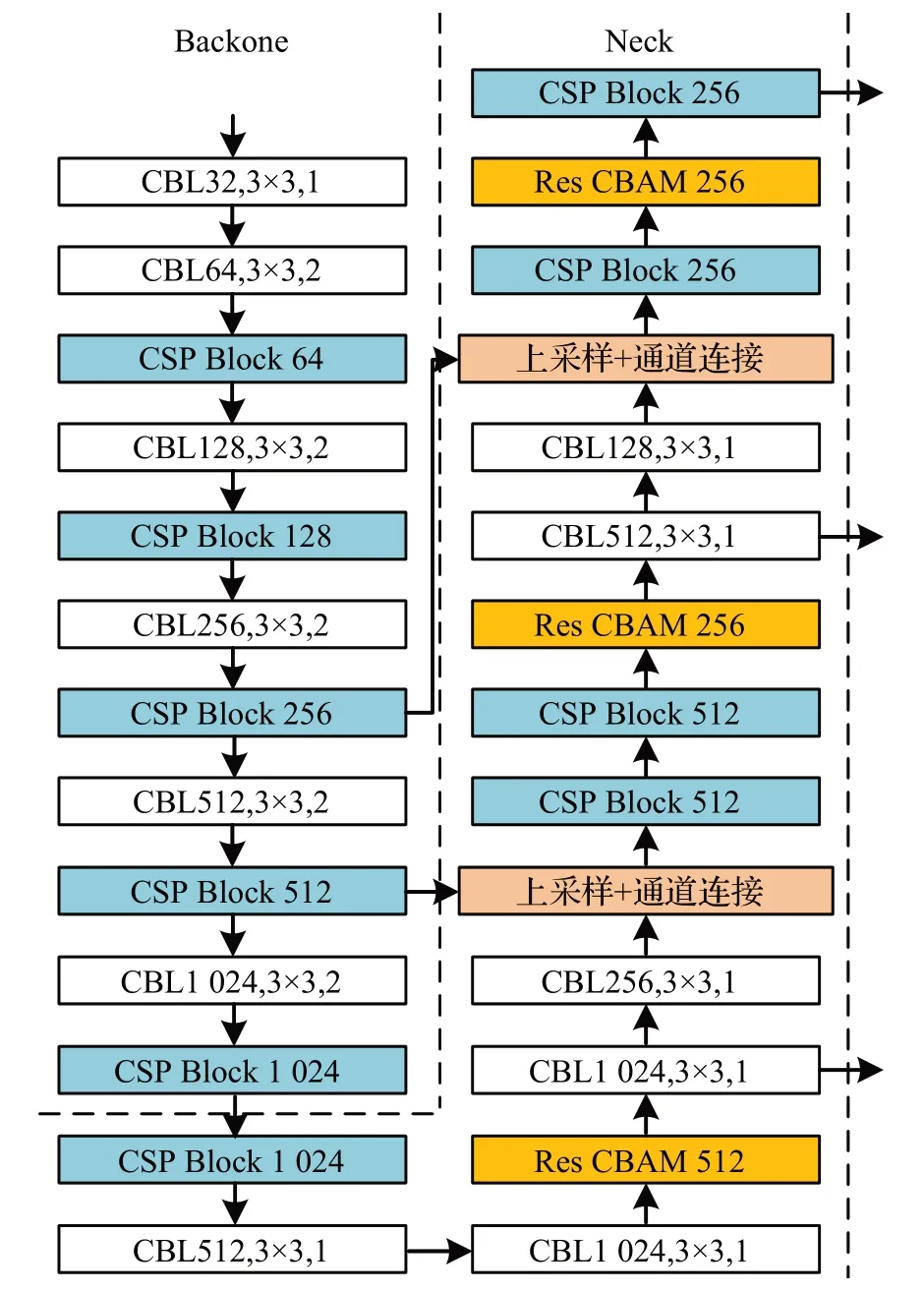
图4 YOLO-fish网络结构图Fig.4 YOLO-fish network structure diagram
其中,将YOLOv3中的残差单元均修改为跨阶段局部模块;并在网络的第15、21和26层加入了残差卷积块注意力模块。
2.1 跨阶段局部模块
YOLOv3 使用的残差单元模块在对特征进行提取时易将水下图像中的噪声带到下一层网络使特征信息冗杂,掩盖有用特征。为提高网络的特征提取能力,本文借鉴跨阶段局部网络(cross stage partial network,CSPNet)[15]的结构,提出跨阶段局部模块(CSP Block),结构如图5所示。
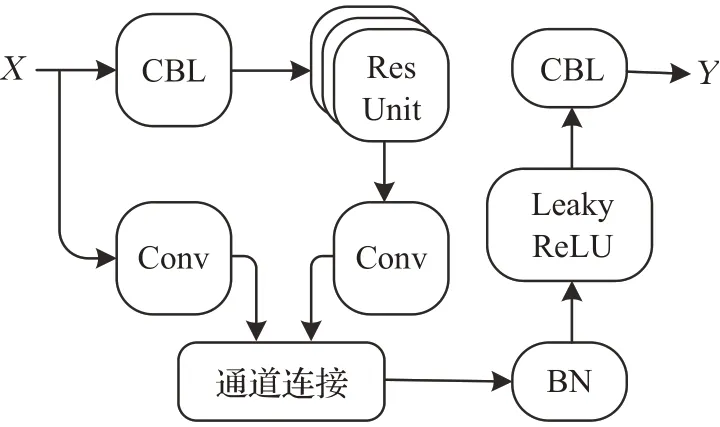
图5 跨阶段局部模块结构图Fig.5 CSP Block structure diagram
跨阶段局部模块在通过融合多通道特征对浅海水下图像进行深层特征提取的同时,避免了残差网络带来的信息冗余问题,提高了特征提取能力;并使梯度路径长度最小化,提高了误差反向传播的传播效率。
将YOLOv3 网络中的残差单元模块替换为跨阶段局部模块,缓解了其中多层残差单元模块堆叠提取的深层特征被浅层特征覆盖的问题,提高了浅层特征与深层特征的融合。残差单元模块的计算如式(3)所示:
y(x)=M([x′;x′])(3)式中,[;]表示通道连接,M表示通道连接后相连的3个模块的操作,x′、x′分别表示图4中两条支路的输出特征。
2.2 残差卷积块注意力模块
对于浅海水下图像中,通过人造光源进行亮度补充易造成的因物体距离人造光源较近出现目标图像过曝和光照较弱或物体距离较远出现光线不足等情况,在卷积时,该部分图像中存在的信息易被冗余信息所掩盖,从而影响水下生物目标检测识别的精确度[16]。因此,本文提出残差卷积块注意力模块以增强对水下生物目标特征的提取,达到增强对目标信息识别的目的。
残差卷积块注意力模块是一个将卷积块注意力模块(convolutional block attention module,CBAM)[17]与残差网络(residual network,ResNet)相结合的注意力模块。其中,卷积块注意力模块是由通道注意力模块(channel attention module,CAM)和空间注意力模块(spatial attention module,SAM)组成的轻量化注意力模块。卷积块注意力模块首先将输入特征F与其被通道注意力模块处理后所得到的特征F′CA相乘,得到通道细化注意力特征FCA;然后与空间注意力模块处理所得到的特征F′SA相乘得到空间细化注意力特征FSA;最后与输入特征F进行相加融合得到残差卷积块注意力模块的输出FOUT,如图6所示。

图6 残差卷积块注意力模块结构图Fig.6 Res CBAM structure diagram
通道注意力模块由最大池化层(MaxPool)、平均池化层(AvgPool)、多层感知机(multilayer perception,MLP)、相加融合模块和Sigmoid激活函数构成,如图7所示。
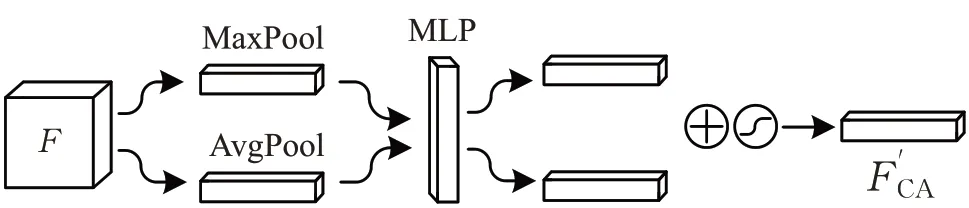
图7 空间注意力模块结构图Fig.7 CAM structure diagram
通道方向注意力F′CA计算如式(4)所示:
式中,σ代表Sigmoid激活函数,F代表输入特征图。
空间注意力模块由最大池化层、平均池化层、通道连接模块、卷积层和Sigmoid激活函数构成,如图8所示。
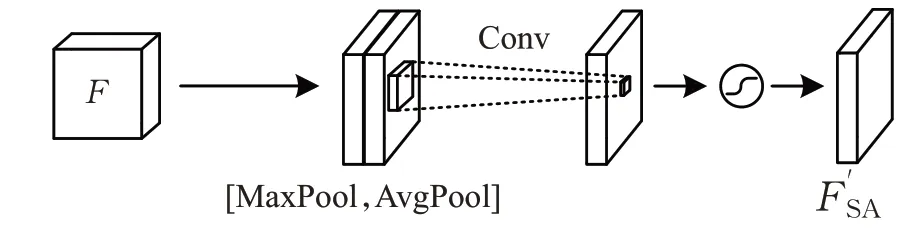
图8 SAM结构图Fig.8 SAM structure diagram
空间方向注意力F′SA计算如式(5)所示:
式中,f3×3代表卷积核为3×3的卷积操作,[;]表示通道连接。
2.3 损失函数
YOLOv3 中使用Rezatofighi 等提出的广义交并比(generalized intersection over union,GIoU)计算预测框损失。该损失计算在IoU[18]的基础上,引入了标注框A和预测框AP的最小包围框C,如图9所示。但浅海中生物个体体积悬殊较大,其中多为小目标,并且由于物体在图像中会呈现远小近大的实际情况,即使同一体积物种在浅海中自由运动时同样会因空间位置而造成尺寸差距较大,易导致预测框与标注框存在包含关系,使GIoU损失计算失效,影响目标标定的精确度。因此,在训练时为增强对标注框信息的挖掘,本文将参考中心交并比(center intersection over union,CIoU)的方法,充分考虑两框的相对位置,对重叠面积、中心点距离和长宽比对输出结果进行评估。

图9 预测框与标注框参数解释图Fig.9 Explanatory diagram of parameters of prediction frame and anchor frame
GIoU计算如式(6)所示:
式中,C(A⋃AP)表示C中标注框A和预测框AP未包含的区域,IoU的计算如式(7)所示:
当两框出现包含关系时,GIoU将与IoU效果相同。而对两框相对位置进行充分考虑的CIoU 计算如式(8)所示:
式中,ρ(A,AP)表示A框和AP框中心点坐标的欧式距离d,l表示C的对角线长度,α是权重参数,计算如式(9):
式中,v是长宽比相似度的衡量值:
式中,WP为预测框的宽,HP为预测框的高,WA为标注框的宽,HA为标注框的高。由CIoU 损失函数LCIoU表示为:
3 YOLOv3模型框架
3.1 实验环境及数据集
本文进行的实验环境为Windows 操作系统,AMD Ryzen 7 5800H(CPU),16 GB 随机存取内存(RAM),RTX 3060 Laptop(GPU),6 GB 显示内存,深度学习框架为pytorch。
本文所使用的浅海水下生物目标数据集,由奥尔堡大学(Aalborg University,AAU)在丹麦北部的利姆水道底部所采集[19],共14 674幅图像,包含海星(starfish)、小鱼(small fish)、虾(shrimp)、水母(jellyfish)、大鱼(fish)和螃蟹(crab)六种海洋动物。取其中1 467幅(约10%)作为验证集,取其中1 468幅(约10%)作为测试集,剩余11 739 幅(约80%)作为训练集进行训练。其中部分图像及其Scharr算子处理后的图像如图10所示。

图10 数据集图片(左)和Scharr算子处理后的图像(右)Fig.10 Dataset images(left)and images processed by Scharr operator(right)
从图10 中右侧图片可以看出,由于光线衰弱导致了水下图像中轮廓和纹理特征的损失,极大影响了清晰度。图10 中(a)和(b)左侧两幅原图分别如图11 中的(a)和(b)两幅三通道直方图。

图11 三通道直方图Fig.11 Histogram of three channels
从图11 可以看出两幅图像的像素值整体偏小,且从图11(a)中可以看到像素值为227 到237 之间像素点数量有明显爆发,表示图像中发生了大面积的曝光,而且数据集中一定数量的图像存在该类情况。数字图像中,图像的标准差反映了图像像素值与均值的离散程度,标准差越大说明图像的质量越好。而图10 中左侧两张原图的标准差分别为49.593和50.682,本数据集的平均标准差为51.849,低于正常场景下的图像的标准差,可知本数据集的水下图像质量较差,图像中信息丰富度较低。
3.2 评价指标
本文的目标检测任务采用精确度P(Precision)、召回率R(Recall)、平均精确度(mean average precision,mAP)和帧数(frame per second,FPS)四种评价指标对模型进行评价。
通过混淆矩阵对精确度P、召回率R 和平均精确度mAP 进行计算,混淆矩阵包含四个指标,即真阳性(true positive,TP)、真阴性(true negative,TN)、假阳性(false positive,FP)和假阴性(false negative,FN),如表1所示。

表1 二元分类的混淆矩阵Table 1 Confusion matrix for binary classification
表1中,预测框与标注框之间的IoU值≥所设阈值的预测框数量为TP,相反,IoU<阈值的数目则为FP,未检测到的目标数量为FN。
精确度AP的定义是预测值为Positive 的总数量中,TP所占的比例,该指标是直观反映模型错检程度的衡量值,其式如式(12)所示:
召回率R的定义是实际值为Positive 的总数量中,TP所占的比例,该指标是直观反映模型漏检程度的衡量值,其式如式(13)所示:
平均精确度(mAP)代表所有物种精确度的平均值,如式(14):
式中,n代表物种数量。
mAP 包含了mAP@0.5 和mAP@0.5:0.95 两种,其中mAP@0.5 是当IoU阈值取值为0.5时,对于其中一个类别,有n个正例样本,对这n个样本的精确度APi求取平均值即得该类的mAP@0.5。将mAP 的IoU 阈值从0.5以0.05为步长增至0.95并取mAP 的平均值,其计算分别为式(15)、(16):
式中,C代表类别数。
mAP@0.5 能够表现精确度P 和召回率R 的变化趋势,mAP@0.5 越高越容易使二者保持较高水平。
mAP@0.5:0.95 是在不同IoU阈值取值情况下的综合表现,相较于mAP@0.5更加考虑整体情况,mAP@0.5:0.95越高代表模型高精度边界回归能力越强,即预测框与标注框的拟合越精确。
FPS表示的是每秒完成检测的图像的数量,其计算如式(17)所示:
式中,t代表单幅图像的处理时间,单位是秒(s)。
3.3 实验结果与分析
本文所使用的数据集中存在大量小目标,训练集图片的分辨率与输入图片所设置的分辨率的比例对所训练网络的检测效果影响较大,因此本文中将输入图片尺寸设置为640×640,与数据集图片本身分辨率相同。
将以GIoU作为预测框损失计算的YOLOv3为原生模型,与使用CIoU 改进了损失函数的YOLOv3-CIoU、模型仅加入了残差卷积块注意力模块的YOLOv3-ResCBAM、模型结构修改为跨阶段局部模块的YOLOv3-CSP、模型结构修改为本文所提出的网络框架而训练时未使用CIoU改进损失函数的YOLOv3-a和本文提出的改进了框架和损失函数的YOLO-fish 通过测试集数据进行对比实验。
通过表2 可以看出,本文改进后的YOLO-fish 算法相较于原YOLOv3算法在水下生物目标检测方面,对于各种物种的检测均有所提高。其中,YOLOv3-CIoU 平均准确率提升了9.5 个百分点,召回率提高了42.9 个百分点由于对预测框的损失函数上做出优化,提高了预测框的精确度,因此对各物种目标的精确度都有所提升。YOLOv3-ResCBAM 平均精确度提高了1.1 个百分点,召回率提高了5.1 个百分点,由于添加了ResCBAM 模块,增强了模型对部分水下生物目标特征的提取能力。YOLOv3-CSP 平均精度提高了7.2 个百分点,召回率提高了32.3 个百分点,由于改变了网络结构,增加了网络的深度和广度。YOLOv3-a 平均精确度提高了10.7 个百分点,召回率提高了42.3 个百分点,融合了以上两种改进方法的特点,其各物种目标的精确度和召回率都得到了提升。结合了以上三种改进方式的YOLO-fish,其精确度提高了11.3个百分点,召回率提高了43.0个百分点。

表2 改进的YOLOv3和YOLOv3实验结果详情Table 2 Details of improved YOLOv3 and YOLOv3 experiment results 单位:%
通过表3可以看出,三种优化方式在不影响检测速度的情况下,其mAP@0.5 和mAP@0.5:0.95 两种指标相较于YOLOv3均有提高,说明综合提高了算法对于水下图像的检测能力。表明结合了三种优化方式YOLO-fish在对于水下图像进行水下生物目标检测识别时有更好的检测效果。

表3 改进的YOLOv3和YOLOv3实验结果参数Table 3 Improved YOLOv3 and YOLOv3 experimental result parameters
综合以上分析结果表明,通过将预测框标定的损失函数进行优化,增加了更多的预测框评定指标对误差进行分析,使得更多的标定误差情况得以考虑,增强了目标检测的鲁棒性,从而提高了精确度和召回率。另外,添加了CSP 模块和Res CBAM 模块增加了网络的深度和广度,增强网络对于水下图像中目标物种的特征获取能力,因此进一步地提高了算法的检测能力。
为了进一步验证本文提出的YOLO-fish 算法在浅海水下生物目标检测识别上要优于其他目标检测算法,将使用同样的浅海水下生物目标数据集对目前几种效果较好的目标检测算法进行对比。
从表4可以看出,不论是“Two-stage”的Faster RCNN还是“One-stage”的SSD、RetinaNet和CenterNet,其对于水下生物目标检测的精确度和召回率均低于改进模型,且YOLO-fish 在检测速度方面是前三种方法的3 倍,稍低于CenterNet,但完全能够达到实时性要求。证明了YOLO-fish 在浅海水下生物目标检测上有更好的实时检测效果。

表4 改进的YOLOv3和其他目标检测算法实验结果参数Table 4 Improved YOLOv3 and YOLOv3 experimental result parameters
3.4 检测效果
随机抽取测试集中的3 张图片进行检测,结果如图12所示。

图12 YOLOv3(左)和YOLO-fish(右)的检测结果Fig.12 Detect result of YOLOv3(left)and YOLO-fish(right)
图12中左侧和右侧分别为YOLOv3 和YOLO-fish的检测结果。图12(a)中,YOLOv3 对因人造光源发生曝光的目标进行检测时无法检测出该目标,并错检出一个海星,而YOLO-fish 对于该类目标能够完成检测,且无错检;图12(b)中,YOLOv3 未检测出图中的小鱼,而YOLO-fish 完成了检测;图12(c)中,YOLOv3 将图中约螃蟹1/3 的物体错检为小鱼,并在错检了图中的无目标部分,而YOLO-fish完成了该图片的检测任务。
4 结束语
针对目前通用的目标检测算法对水下生物目标检测中精度低、易漏检和错检的问题,本文提出改进的YOLOv3水下生物目标检测识别算法,以完成对水下生物图像的检测任务。针对水下光线衰弱严重、图像色彩失真、物体曝光和尺寸差异大等问题,本文在YOLOv3中加入残差卷积块注意力模块和跨阶段局部模块,提出了适合水下生物目标的实时检测算法(YOLO-fish)。针对水下图像中物种目标尺寸差异大,且数据集有限的问题,为提高对小目标和过大目标的预测精确度,引入了CIoU 的预测框损失函数进行训练,有效提高预测框的适应能力并提高预测精确度。实验结果表明,改进后的YOLOv3在水下鱼类目标检测识别任务中,在不影响检测实时性的情况下平均精确度比原YOLOv3 网络提高了11.3个百分点,同时漏检率和错检率降低了37.3个百分点。下一步工作将研究改进型YOLOv3 算法搭载到本实验室的智能水下机器人进行渔业资源检测的实际应用,以机器人代替人工进行海洋渔业资源探索作业。
参考文献:[1] 郭威,张有波,周悦,等.应用于水下机器人的快速深海图像复原算法[J].光学学报,2022,42(4):53-67.GUO W,ZHANG Y B,ZHOU Y,et al.Rapid deep-sea image restoration algorithm applied to unmanned underwater vehicles[J].Acta Optica Sinica,2022,42(4):53-67.
[2] 张立艺,武文红,牛恒茂,等.深度学习中的安全帽检测算法应用研究综述[J].计算机工程与应用,2022,58(16):1-17.ZHANG L Y,WU W H,NIU H M,et al.Summary of application research on helmet detection algorithm based on deep learning[J].Computer Engineering and Applications,2022,58(16):1-17.
[3] 周清松,董绍江,罗家元,等.改进YOLOv3 的桥梁表观病害检测识别[J].重庆大学学报,2022,45(6):121-130.ZHOU Q S,DONG S J,LUO J Y,et al.Bridge apparent disease based on improved YOLOv3[J].Journal of Chongqing University,2022,45(6):121-130.
[4] REN S,HE K,GIRSHICK R,et al.Faster R-CNN:towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2017,39(6):1137-1149.
[5] REDMON J,DIVVALA S,GIRSHICK R,et al.You only look once:unified,real-time object detection[C]//IEEE Conference on Computer Vision & Pattern Recognition,2016.
[6] LIU W,ANFUELOY D,ERLAN D,et al.SSD:single shot multibox detector[C]//European Conference on Computer Vision.Cham:Springer,2016:21-37.
[7] REDMON J,FARHADI A.Yolov3:an incremental improvement[J].arXiv:1804.02767,2018.
[8] 袁利毫,昝英飞,钟声华,等.基于YOLOv3 的水下小目标自主识别[J].海洋工程装备与技术,2018,5(S1):118-123.YUAN L H,ZAN Y F,ZHONG S H,et al.Small under-water target recognition based on YOLOv3[J].Ocean Engineering Equipment and Technology,2018,5(S1):118-123.
[9] 高英杰.基于“SSD”模型的水下目标检测网络设计与实现[J].电子世界,2019(8):110-111.GAO Y J.Design and implementation of underwater tar get detection network based on SSD model[J].Electronics World,2019(8):110-111.
[10] 赵德安,刘晓洋,孙月平,等.基于机器视觉的水下河蟹识别方法[J].农业机械学报,2019,50(3):151-158.ZHAO D A,LIU X Y,SUN Y P,et al.Detection of underwater crabs based on machine vision[J].Transactions of the Chinese Society for Agricultural Machinery,2019,50(3):151-158.
[11] 刘萍,杨鸿波,宋阳.改进YOLOv3 网络的海洋生物识别算法[J].计算机应用研究,2020,37(S1):394-397.LIU P,YANG H B,SONG Y.Improved marine biometrics identification algorithm for YOLOv3 network[J].Application Research of Computers,2020,37(S1):394-397.
[12] 邢晋超,潘广贞.改进YOLOv5s的手语识别算法研究[J].计算机工程与应用,2022,58(16):194-203.XING J C,PAN G Z.Research on improved YOLOv5s sign language recognition algorithm[J].Computer Engineering and Applications,2022,58(16):194-203.
[13] 董绍江,刘伟,蔡巍巍,等.基于分层精简双线性注意力网络的鱼类识别[J].计算机工程与应用,2022,58(5):186-192.DONG S J,LIU W,CAI W W,et al.Fish recognition based on hierarchical compact bilinear attention network[J].Computer Engineering and Applications,2022,58(5):186-192.
[14] REZATOFIGHI H,TSOI N,GWAK J Y,et al.Generalized intersection over union:a metric and a loss for bounding box regression[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,2019:658-666.
[15] WANG C Y,LIAO H Y M,WU Y H,et al.CSPNet:a new backbone that can enhance learning capability of CNN[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops,2020:390-391.
[16] 农元君,王俊杰.基于嵌入式的遥感目标实时检测方法[J].光学学报,2021,41(10):179-186.NONG Y J,WANG J J.Real-time object detection in remote sensing images based on embedded system[J].Acta Optica Sinica,2021,41(10):179-186.
[17] WOO S,PARK J,LEE J Y,et al.Cbam:convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision(ECCV),2018:3-19.
[18] YU J,JIANG Y,WANG Z,et al.Unitbox:an advanced object detection network[C]//Proceedings of the 24th ACM International Conference on Multimedia,2016:516-520.
[19] PEDERSEN M,BRUSLUND HAURUM J,GADE R,et al.Detection of marine animals in a new underwater dataset with varying visibility[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops,2019:18-26.
[20] ZHOU X,WANG D,KRAHENBUHL P.Objects as points[J].arXiv:1904.07850,2019.
