基于遗传算法的矿山装备制造企业排程优化
2023-09-24李涛
李 涛
中信重工机械股份有限公司 河南洛阳 471039
随 着全球制造业市场的竞争越来越激烈,如何提高生产计划排程效率成为矿山装备制造企业提高市场竞争力的重要手段[1]。该类型企业生产的产品属于重型装备,拥有复杂的产品结构和生产流程,具有生产周期长、重复率低、单件小批量等特点,对生产系统的柔性要求较高。同时,不同零部件需要多个工厂协作来完成生产,进一步增加了生产管理的难度。因此,该类型企业需要利用先进的 APS 系统来辅助不同分厂进行生产计划排程,同时实现对几十甚至上百个订单的生产排程,以达到提前预警和按期交货等目标[2]。
生产计划排程是矿山装备制造企业生产管理的核心环节,影响生产效率和客户满意度。通过基于遗传算法的排程优化研究,可以有效解决承制工厂 (生产分厂) 零部件的工序、车间和资源调度等问题,以此提高生产计划排程的效率和精度,降低成本和时间浪费[3]。此外,该研究可以为矿山装备制造企业生产管理提供技术支持和决策依据,提升企业的市场竞争力。
1 研究内容和目标
矿山装备制造企业目前多采用以订单为驱动的生产模式,对生产系统的柔性要求较高,故需要利用先进的 APS 系统来辅助不同承制工厂 (生产分厂) 进行生产计划排程。分厂级的排程算法需要嵌入到 APS系统中[4],根据企业生产管理部门分配的生产任务和给定的关键节点计划,并考虑多个订单的零部件生产工单结构顺序、物料可用性以及上游工序预期完成时间等信息,解决零部件工序的车间和资源调度等问题。根据不同工单的工序、优先级、来料准备等特点,将各个工单的各个工序合理地排布在可行的车间、资源和时间节点,在满足交货期的同时,降低成本,提高运营和生产效率。该算法将公司级主生产计划和年度滚动计划中确定下来的关键时间节点,在组批算法中得到的合成工单作为输入,并与其紧密衔接,从而实现在规定的时间跨度和交货期内,对关键工单排程。
初级 APS 系统的排程算法是将工单工序的排程工作拆分为了车间级别和资源级别,并进行优化。此类算法虽然可以做到减少跳线,并能在满足父子工单关系的条件下,对工序进行合理安排,但也存在一定的不足:将所有工单一起考虑,问题规模太大,难以对影响生产交期较大的关键路径上的工单进行优先满足;2 个层级算法的基本逻辑都是基于简单的规则形式进行实现,因此排程方案具有很大的局限性。
基于遗传算法的优化排程算法针对关键路径工单进行生产排程,再基于此对非关键路径工单进行排程,同时考虑了工单之间的父子关系、工单内部的顺序、车间之间的较少跳线、关键节点等,对“工单—父子关系—工序—车间—设备—时间节点”进行了排程和优化。与此同时,该算法基于企业整体的信息集成,融合企业内部多部门和内外部协同生产节点信息的更新以及物料达成等信息,以实现对企业内外多部门的生产协同进行整体统筹。
2 遗传算法
2.1 基本原理
遗传算法是由 John Holland 于 20 世纪 70 年代提出的一种基于种群的元启发式算法[5-6]。该算法依据自然选择和自然遗传学机制进行随机全局搜索,在搜索过程中自动获取和积累有关搜索空间的知识,采用概率化的寻优方法,不需要确定的规则就能自动获取和指导优化的搜索空间,自适应地控制搜索过程。
遗传算法主要利用遗传操作 (交叉、变异等) 对群体中的个体进行全部或部分替换,不断适应环境,进化到更优的状态。与其他优化算法相比,遗传算法适用范围广,具有全局寻优能力、高可靠性、高并行性等优点,被广泛应用于组合优化、机器学习、人工智能、神经网络等领域[7-8]。
2.2 遗传算法框架
遗传算法的基本思想是模拟生物进化过程搜索最优解,因此,其过程包括个体的选择、交叉、变异等要素,形成了遗传算法的框架。其中,个体表示可行解决方案;种群是个体的集合。遗传算法主要通过不断对种群中的个体进行操作,来逐渐搜索最优解。
遗传算法的框架为[9]:
(1) 初始化,随机生成一组初始个体,即种群;
(2) 适应度评价,对种群中的每个个体的成本、效益和适应度等进行评价;
(3) 选择操作,根据适应度大小,选择一定数量的个体作为父代;
(4) 交叉操作,随机选择一对父代,利用交叉算子实现基因交换,产生新的个体;
(5) 变异操作,对新的个体进行一定的概率变异操作,产生新的解决方案;
(6) 替换操作,根据适应度,选择新个体和旧个体进行替换,形成新的种群;
(7) 结束判断,达到指定迭代次数或满足精度要求时终止,返回最优解。
2.3 基本操作
2.3.1 编码和解码
在遗传算法中,个体需要进行编码和解码。编码是将决策变量转换成目标函数值,计算机可处理的二进制表达式的过程。不同的编码方式适用于不同类型的函数问题,例如,二进制编码适用于多目标函数优化;浮点编码适用于连续性变量的优化;排列编码适用于旅行商问题等。解码是指将二进制编码重构为原始问题的过程。
2.3.2 选择操作
选择操作是根据适应度大小,选择一部分个体作为父代,这里的适应度通常定义为目标函数值或评价函数值。优秀的个体被选中,不良的个体被淘汰。常见的适应度选择方法有轮盘选择、锦标赛选择、最小竞标赛等。
2.3.3 交叉操作
交叉操作是指将选出的父代进行重组操作,产生新的个体。重组的方式常见有单点交叉、多点交叉、均匀交叉、基因重组等,交叉方式也根据问题的性质进行调整。对于连续性变量问题,可以采用基于结果随机化的交叉方式,比如 BLX-α 交叉;对于多目标问题,则可以采用向量交叉,实现多目标优化。
2.3.4 变异操作
变异操作是指在交叉操作后对个体进行一定概率的操作,产生新的解决方案。变异操作通常是单点变异,即随机选择一个基因位置,并改变其值。在实际应用中,变异率设置过大会导致算法陷入局部最优解,因此应该根据具体问题进行设置。
2.3.5 替换操作
替换操作是在交叉和变异操作后,根据适应度,选择新个体和旧个体进行替换,形成新的种群。常见的替换方式有全替换、部分替换等。
2.4 遗传算法的优缺点
遗传算法作为一种常用的优化算法,其优缺点如下[10]。
2.4.1 遗传算法的优点
(1) 可以寻找全局最优解,具有较强的全局寻优能力;
(2) 算法具有较高的可靠性,能够避免局部最优解;
(3) 算法具有高度的并行性,可以利用并行处理技术进行优化;
(4) 算法适用范围广,可以用于多种类型的问题。
2.4.2 遗传算法的缺点
(1) 遗传算法的收敛速度相对较慢,需要较多的迭代次数;
(2) 在编码、交叉、变异等操作中需要设置一系列参数,参数对算法效果影响较大;
(3) 操作不当时,遗传算法也有可能造成早熟现象,即过早收敛到局部最优解。
3 排程优化
3.1 输入信息
遗传算法的输入信息包括:
(1) 产品对应的物料信息;
(2) 资源及日历信息;
(3) 需要生产的工单、工序和工艺信息,包括父子工单关系、工序顺序以及工单的最早开始时间和最晚结束时间 (节点交期);
(4) 生产时间期量工序生产时间和提前期,换线时间,制造效率 (用于修正实际的制造时长);
(5) 物料供应链信息物料库存、采购、到货等信息;
(6) 生产计划,包括公司级主生产计划、年度滚动计划中确定的关键时间节点;
(7) 工单、工序的预排车间信息,如有此信息,则基于此进行车间线体排程;
(8) 外协线体及其能力约束,可以为无限,对应外协无限产能概念。
3.2 排程算法框架
产品的生产时长主要取决于该订单关键路径上的工单生产时长。该部分工单的生产时间较长或其所占用关键的设备资源有限,如何对关键路径上的工单进行生产排程是个重要问题。另外,除了关键路径上的生产工单外,由于产品结构复杂且零部件繁多,故而也需要对所有的非关键路径的工单进行排程。首先利用遗传算法对关键路径工单进行排程优化,然后考虑父子工单关系等约束,利用一定的规则对非关键路径工单进行排程,分厂级 APS 排程算法框架图如图1所示。

图1 分厂级 APS 排程算法框架Fig.1 Branch level APS scheduling algorithm framework
3.3 关键路径工单排程
首先对不同订单的关键路径使用遗传算法进行排程。
(1) 针对离散型装备制造企业的排程,考虑父子工单关系以及工单内部的工序,设计合理的编码规则;
(2) 考虑车间减少跳线以及资源设备在成本、时间、优先级等方面的权重考量,设计合理的解码规则;
(3) 初始化种群;
(4) 设计合理的适应度函数,并对其进行计算,筛选出更优解;
(5) 对种群进行选择、交叉、变异操作,产生下一代遗传编码;
(6) 重复以上过程,对排程结果不断迭代优化,直到满足条件,得到最终的排程优化结果。
3.4 非关键路径工单排程
在关键路径工单排程计划的基础上,基于优先级规则对非关键路径工单进行启发式的排程。同样,也需要考虑工单的父子关系、工单内部的工序顺序、工单工序的车间线体选择、工单工序的资源设备选择以及开始生产时间节点等内容。
根据离散型装备制造企业生产组织方式,整个协同制造体系包括很多外部协同制造过程,包括工艺性和能力性外协,因此在以上排程算法和规则中,将外部协同制造作为一个车间线体 (该车间实际为一个虚拟车间,仅用于表示工单的外部协同制造),根据企业“无限产能”的理念,可以将该车间的产能设置为无限大,也可以设置一定的约束。
3.5 多订单关键路径工单生产排程算法
3.5.1 编码规则
算法的关键点之一便是编码规则。遗传算法通过染色体的基因信息对索要决策的内容进行编码。针对离散型装备制造企业的生产排程,笔者提出了一个同时考虑父子工单以及工序的编码方式。
首先,染色体中每个数字代表对应工单编号,如:工单 1、2、3 等,同一数字出现的次数代表该工单拥有的工序数量,而同一数字出现的先后顺序则代表工单内部的工序顺序。如图2 所示,Oi,k表示第i个工单的第k道工序。从左至右,O3,1代表工单 3 的第1 道工序;O1,1代表工单 1 的第 1 道工序;O2,1代表工单 2 的第 1 道工序;O2,2代表工单 2 的第 2 道工序,以此类推。通过这种编码方式即可实现工单内不同工序顺序的排序。

图2 染色体示例Fig.2 Chromosome example
其次,在实际的生产过程中,必须满足父子工单的顺序关系。因此,本部分的染色体编码规则可根据BOM 结构/工单树中的父子工单关系,对订单中多工单的加工顺序进行调整。具体的,找到父子工单关系中最高层级的父工单,并以此作为染色体调整起点,依次向下一层级进行修复。修复的过程如下:对每一个父工单对应的工序节点进行检查,若该父工单工序的右侧存在子工单工序,则两者交换,直到父工单的全部工序检查完毕,顺延至下一层级重复修复过程。以“1→4”为例,假设工单 1 是工单 4 的子工单,那么染色体的修复过程如图3 所示。
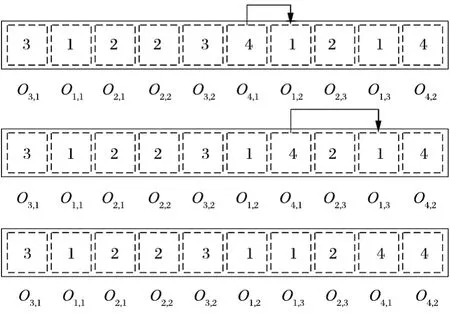
图3 染色体修复过程Fig.3 Chromosome repair procedure
通过以上的编码规则和调整修复过程,即可实现染色体工单内部工序顺序以及父子工单关系的要求。
3.5.2 解码规则
在种群解码过程中,采用基于空闲时间段的主动调度工序解码方法以获得可行序列解,即新的待排序工序需要同时满足车间分配、资源分配、以及考虑物料问题,在对已排序工序开工时间不产生影响的基础上,根据当前机器空闲时间,安排至最早可开工的时间点。
3.5.3 车间分配
对工单中不同工序进行车间分配,总体目标是减少同一工单在不同车间之间的转换,从而减少跳线时间和降低跳线成本。通过构建整数规划模型的方法,以工单工序之间的跳线最小化为目标,对工单内部各道工序进行车间分配决策。模型参数包括各工单的工序以及对应的车间信息。对每一个工单运行一次分配决策,可完成对所有工单的车间预分配工作。
模型的目标函数为
式中:wi,i+1,m,n为工序i到工序i+1 之间,从车间m跳线到车间n的成本 (权重);yi,i+1,m,n为 0~1 决策变量,若为 1,则代表工序i到工序i+1 之间,从车间m跳线到车间n;xi,m为 0~1 决策变量,若为 1,则代表工序i分配到车间m内;xi+1,n为 0~1 决策变量,若为 1,则代表工序i+1 分配到车间n内。
第1 个约束用于保证每道工序只可能被分配到一个车间;第 2、3、4 个约束用于保证,只有当跳线真实发生的情况下,0~1 决策变量的值才为 1;第 5、6、7 个约束规定变量类型。
另外,也可在此模型中增加负荷平衡等因素和目标,即在对工单工序分配车间的过程中,考虑不同车间资源的负荷平衡,最小化跳线。
3.5.4 资源分配
在车间分配的基础上,对车间的资源进行工序分配。采取启发式基于资源权重规则的资源分配方法,将各项需要考虑的资源约束限制赋予不同的权重,并累加在一起,选取最合适该道工序的资源。各项资源约束限制有:加工成本最小、间隔时间最小、工作完工时间最小、该工作与前一道工序的工作的时间间隔最小、制造时间最少和占用负荷量最小的资源。
3.5.5 排程结果
基于染色体编码,从左到右依次对工序进行排程。考虑前序工单完成时间+物料提前期 (若物料充足,则提前期为 0),逐一安排工序—车间—机器—时间点。甘特图排程结果如图4 所示。灰色部分代表物料没有及时到达造成的提前期,通过以上解码方法生成完整的排程结果。
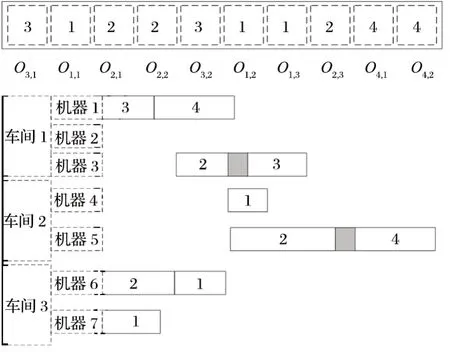
图4 甘特图排程Fig.4 Gantt chart scheduling
利用企业集成的信息平台,将不同订单生产中与其他部门或外部协同工厂生产节点信息以及物料可用性等信息更新到模型中,从而得到与实际生产过程更为匹配的生产计划排程方案。
3.5.6 适应度函数
遗传算法中判别解 (染色体) 的好坏,是通过适应度函数的计算来实现。采用的函数计算规则如下:权重 (1)×生产成本+权重 (2)×最大完工时间+权重(3)×关键时间节点逾期惩罚项。
3.5.7 交叉、变异算子
交叉算子包括:①单点交叉,通过选取两条染色体,在随机选择的位置点上进行分割并交换右侧的部分,从而得到两个不同的子染色体;②两点交叉,是指在个体染色体中随机设置了两个交叉点,然后再进行部分基因交换;③多点交叉,是指在个体染色体中随机设置多个交叉点,然后进行基因交换;④ 部分匹配交叉,保证每个染色体中的基因仅出现一次,通过该交叉策略在一个染色体中不会出现重复的基因。在交叉操作结束后,对染色体的可行性进行判断,如果不可行,则进行修复。
变异算子包括:①将位翻转突变应用于二进制染色体时,随机选择一个基因,其值被翻转 (求补);②将交换突变应用于二进制或整数的染色体时,将随机选择 2 个基因并交换其值;③倒换突变应用后,将选择一个随机基因序列,并将该序列中的基因顺序打乱 (或倒换)。在变异操作结束后,对染色体的可行性进行判断,如果不可行,则进行修复。
3.6 基于规则的非关键路径工单生产排程算法
在关键路径工单已经排程完毕的基础上,采用基于优先级规则的启发式分配方法,再对非关键路径工单进行相应的排程。
(1) 考虑父子工单将工单进行层级分解,从最高层级父工单开始进行工单分层,排程规则均从最高层级父工单开始,依次运行算法排程。
(2) 考虑同层级工单、工序顺序选中当前层级的工单 (由于同层级,因此互不影响),根据优先级进行排序,并由高到低依次输入算法。优先级的规定除人为指定外,可以将以下几点进行自由组合并排出优先级:交货期 (升序/降序)、工单最早开始时刻 (升序/降序)、工单人为优先级 (升序/降序)、工单制造数量(升序/降序)、工单最晚结束时间 (升序/降序)、工单余裕度 (升序/降序)、先到先做 (升序/降序)。
(3) 开始时间节点的排程方法对工序进行排程需要同时满足车间分配、资源分配以及考虑物料问题,且对已排序工序开工时间不产生影响的基础上,根据当前机器空闲时间,安排至最早可开工的时间点,即不存在可以加工任意可加工工序的空闲时间段。
4 结语
通过对遗传算法进行介绍,重点阐述了遗传算法在矿山装备离散制造企业排程优化模型设计应用的研究过程。在研究过程中,进一步验证了遗传算法具有较高的求解效率和广泛的适应性。
遗传算法能够寻找全局最优解,保证算法的全局寻优能力,但是在编码、交叉、变异等操作过程中,需要设置一系列参数。其对参数的选取十分敏感,选取不合理,可能会影响算法的效果。此外,遗传算法的收敛速度相对较慢,需要较多的迭代次数,因此算法在处理大规模或者高维度优化问题时比较困难。
在未来的理论研究和算法模型应用中,可以利用遗传算法结合其他方法,如人工神经网络、模拟退火等来进行研究,以进一步提升算法的效率与精度。另外,如何解决算法早熟现象和局部最优解等问题,值得进一步深入研究。
