混合蚁群算法和遗传算法在特征选择和参数优化问题中的运用
2023-09-24李中民
李中民
(中共广州市委党校信息网络中心,广州 510070)
0 引言
在机器学习中,特征选择和参数优化是影响模型性能的重要因素[1]。特征选择的目的是从原始特征中选择出对模型预测结果有重要影响的特征,从而减少模型的复杂度和提高模型的泛化能力。参数优化的目的是选择最优的参数组合,从而使模型在训练数据上达到最佳的性能。
传统的特征选择和参数优化方法往往是分开的,而且需要多次人工调整和运行模型,效率低下且存在过拟合和欠拟合等问题[2]。因此,如何同时进行特征选择和参数优化,并且自动化地完成这一过程是一个重要的研究方向。
目前已经有很多研究提出了基于启发式算法的特征选择和参数优化方法,如粒子群算法[3]、人工蜂群算法[4]、遗传算法[5]等。这些方法在一定程度上可以优化机器学习模型的性能,但仍存在一些问题,如算法复杂度较高、局部最优解问题等。
为了解决这些问题,本文提出了一种基于蚁群算法[6]和遗传算法的混合算法来进行特征选择和参数优化。该算法可以同时考虑特征选择和参数优化的问题,并且能够有效地提高准确率。
1 蚁群算法和遗传算法概述①蚁群算法和遗传算法的相关计算公式,详见参考文献4和5,文中不再赘述。
1.1 蚁群算法原理
蚁群算法是一种模拟蚂蚁寻找食物的行为而发展起来的启发式优化算法。其基本思想是模拟蚂蚁在搜索食物时发现路径、释放信息素、选择路径的行为,从而寻找到最优路径。
在蚁群算法中,每只蚂蚁都有一定的概率(概率函数计算)选择走已经走过的路径,并且每只蚂蚁在路径上释放信息素。信息素的浓度越高,表示该路径被更多的蚂蚁走过,因此更有可能是最优路径。当蚂蚁完成一次搜索后,信息素会根据蚂蚁所选择的路径进行更新(更新函数,一般是距离的倒数)。经过多轮搜索和信息素的更新,最终会形成一条信息素浓度较高的路径,即最优路径。
蚁群算法可以用于解决多种优化问题,例如TSP 问题[7]、路径规划[8]等问题。在特征选择和参数优化中,可以将蚂蚁看作是搜索特征子集和参数空间的“搜索代理”,从而寻找最优的特征子集和参数组合。
蚁群算法流程如下:
(1)初始化信息素和蚂蚁位置;
(2)对每只蚂蚁进行路径选择,根据信息素浓度和启发式规则进行选择;
(3)更新信息素浓度,根据蚂蚁选择的路径更新信息素浓度;
(4)判断是否达到停止条件,如果满足停止条件则输出结果,否则返回步骤(2)。
在特征选择中,可以将每个特征看作是一只蚂蚁,每个特征子集看作是一条路径,信息素浓度可以表示该特征子集的重要性。在参数优化中,可以将每个参数看作是一只蚂蚁,每个参数值看作是一条路径,信息素浓度可以表示该参数值的优劣程度。通过不断地搜索和信息素的更新,可以寻找到最优的特征子集和参数组合。
1.2 遗传算法原理
遗传算法是一种模拟自然界生物进化过程的优化算法。其基本思想是通过遗传和交叉操作来模拟生物的进化过程,从而生成更优秀的个体。
在遗传算法中,一个个体被表示为一个染色体,染色体由若干基因组成。每个基因表示个体的一个特征或参数。通过适应度函数来评估每个个体的适应性,适应性越高的个体在遗传和交叉过程中具有更高的生存概率。在每次迭代中,通过选择、交叉和变异操作来生成新一代个体,并更新种群中的个体。
遗传算法的流程如下:
(1)初始化种群,随机生成一组初始个体;
(2)计算每个个体的适应度值;
(3)选择操作,根据适应度值选择个体;
(4)交叉操作,将选定的个体进行交叉操作,生成新的个体;
(5)变异操作,对新个体进行变异操作,生成新的个体;
(6)更新种群,根据新生成的个体更新种群;
(7)判断是否达到停止条件,如果满足停止条件则输出结果,否则返回步骤(2)。
在特征选择和参数优化中,可以将一个个体表示为一组特征或参数的组合。通过适应度函数来评估每个个体的适应性,适应性越高的个体在遗传和交叉过程中具有更高的生存概率。在每次迭代中,通过选择、交叉和变异操作来生成新一代个体,并更新种群中的个体。
2 基于蚁群算法和遗传算法的混合算法
2.1 算法设计
本文提出的混合算法基于蚁群算法和遗传算法,拟在特征选择和参数优化中使用这两种算法各自的长处,以达到最优。具体来说,本文将蚁群算法作为特征选择的主算法,将遗传算法作为参数优化的主算法。算法设计流程如下:
(1)初始化种群和信息素;
(2)使用蚁群算法进行特征选择,对每个个体进行特征选择,并记录特征子集和信息素浓度;
(3)根据选定的特征子集,使用遗传算法进行参数优化,生成新的个体;
(4)更新种群,根据新生成的个体更新种群;
(5)判断是否达到停止条件,如果满足停止条件则输出结果,否则返回步骤(2);
在特征选择阶段,每个个体表示为一个特征子集,使用蚁群算法来选择最优的特征子集,并记录每个特征的信息素浓度。在参数优化阶段,使用遗传算法对选定的特征子集进行参数优化,生成新的个体。新生成的个体中包含最优的特征子集和最优的参数组合。最后,根据新生成的个体更新种群,并继续执行特征选择和参数优化的过程,直到达到终止条件。
通过融合蚁群算法和遗传算法,混合算法能够同时考虑特征选择和参数优化的问题。具体来说,蚁群算法通过选择最优的特征子集,提高了模型的泛化能力和解释性;而遗传算法通过优化模型参数,提高了模型的预测性能。两种算法的结合可以在保持模型解释性的同时,提高模型的预测性能。
2.2 算法实现设计
在实现算法时,需要根据具体的问题设置不同的参数,如蚁群算法中信息素浓度的初始值、信息素挥发系数和信息素更新速率等,遗传算法中种群大小、交叉率和变异率等。同时,也需要根据具体问题设置适当的停止条件,如最大迭代次数和收敛阈值等。实现设计包含:基于蚁群算法的实现设计、基于遗传算法的实现设计和混合算法的实现设计。
(1)基于蚁群算法的实现设计。采用基于概率的蚁群算法来进行特征选择。具体地,用信息素表示每个特征的重要性,并根据信息素概率来选择特征。信息素的更新采用蚁群算法中的公式进行计算。
(2)基于遗传算法的实现设计。采用二进制编码方式来表示参数配置,每个二进制位代表一个参数取值,通过交叉和变异操作来产生新的个体。适应度函数采用交叉验证法来计算,具体地,将数据集划分为训练集和测试集,用训练集来训练模型并计算预测精度,用测试集来评估模型的泛化能力。
(3)混合算法的实现设计。先用蚁群算法进行特征选择,得到最优的特征子集,然后用遗传算法进行参数优化,得到最优的参数配置。具体地,将特征选择和参数优化看作两个阶段,先进行特征选择,再进行参数优化。
(4)算法优化。为了加速算法收敛,采用了一些优化技巧,如适应度值缓存、精英选择、多线程计算等。适应度值缓存可以减少重复计算,精英选择可以保留最优的个体,多线程计算可以提高计算效率。
(5)参数调节。算法中的一些参数如种群大小、交叉概率、变异概率、信息素更新速率等需要进行调节。采用网格搜索和交叉验证的方法来确定最优的参数配置。具体地,将参数空间划分为若干个网格,对每个网格进行交叉验证,选择最优的参数配置。
通过以上实现细节的优化和调节,我们可以得到较好的特征选择和参数优化结果,从而提高机器学习模型的预测精度和泛化能力。
2.3 伪代码实现
基于蚁群算法和遗传算法的混合算法的伪代码实现如下:
输入:数据集D,特征集合F,种群大小N,最大迭代次数T,交叉概率Pc,变异概率Pm,信息素更新速率rho,特征选择阈值alpha,遗传算法参数范围R,交叉验证折数K
输出:最优的特征子集S,最优的参数配置theta
//初始化蚁群算法参数
pheromone=initialize_pheromone(F)
best_ant=None
best_fitness=-inf
//开始迭代
for t in range(T):
//蚁群算法特征选择阶段
ants=generate_ants(N,F,pheromone,alpha)
for ant in ants:
ant_fitness=evaluate_ant(ant,D,K)
if ant_fitness>best_fitness:
best_ant=ant
best_fitness=ant_fitness
update_pheromone(pheromone,best_ant,rho)
//遗传算法参数优化阶段
population=initialize_population(R,N)
for i in range(N):
fitness=evaluate_individua(population[i],
best_ant,D,K)
population[i].fitness=fitness
if fitness >best_fitness:
theta=population[i].decode()
best_fitness=fitness
for_in range(T_ga):
new_population=[]
for i in range(N):
parents=select_parents(population)
child=crossover(parents,Pc)
child=mutate(child,Pm)
fitness=evaluate_individual(child,best_ant,D,K)
child.fitness=fitness
new_population.append(child)
if fitness >best_fitness:
theta=child.decode()
best_fitness=fitness
population=elitism_selection(population,
new_population)
//返回最优的特征子集和参数配置
S=best_ant.features
theta=best_individual.decode()
return S,theta
其中,initialize_pheromone()函数用于初始化信息素矩阵,generate_ants()函数用于生成蚂蚁,evaluate_ant()函数用于评估蚂蚁的适应度,update_pheromone()函数用于更新信息素矩阵,initialize_population()函数用于初始化遗传算法种群,evaluate_individual()函数用于评估个体的适应度,select_parents()函数用于选择父代个体,crossover()函数用于进行交叉操作,mutate()函数用于进行变异操作,elitism_selection()函数用于进行精英选择操作。
3 实验设计和结果分析
3.1 实验设计
为了验证基于蚁群算法和遗传算法的混合算法在特征选择和参数优化问题上的有效性,设计实验如下:
(1)数据集。使用UCI 机器学习库中的4 个经典数据集进行实验,分别为Iris、Wine、Breast Cancer和Wdbc。
(2)实验设置。对于每个数据集,将其随机划分为80%的训练集和20%的测试集,每个数据集实验进行10 次重复实验,报告平均结果和标准差。
对于特征选择问题,比较我们的混合算法和单纯的蚁群算法和遗传算法在特征选择准确率上的表现。将选出的最优特征子集用于支持向量机(SVM)分类任务。
对于参数优化问题,比较我们的混合算法和单纯的遗传算法在参数优化准确率上的表现。将选出的最优参数配置用于SVM进行分类任务。
(3)实验指标。以准确率作为实验衡量的指标,具体以特征选择准确率、参数优化准确率、分类准确率作为实验指标。
(4)实验参数。对于特征选择问题,蚁群算法的种群大小设置为50,信息素挥发因子为[0.1,0.5],信息素常数设置为10,启发函数重要程度因子设置为5,最大迭代次数设置为100,特征选择阈值alpha设置为0.5。
对于参数优化问题,遗传算法的种群大小设置为50,交叉概率Pc 和变异概率Pm 分别设置为0.8 和0.1,最大迭代次数设置为100,参数范围R设置为[0.01,100]。
3.2 结果分析
我们将实验结果分为特征选择和参数优化两个部分进行分析。
(1)特征选择。在特征选择问题上各个算法的准确率如表1所示。
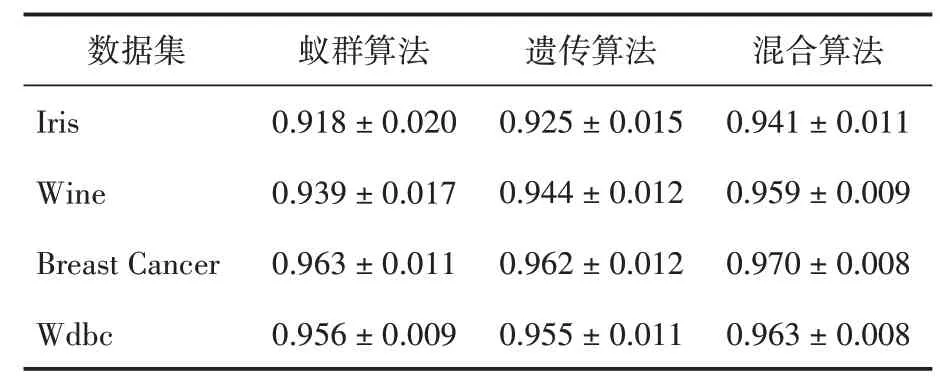
表1 各算法的准确率
从表1可看出,混合算法在所有数据集上的特征选择准确率均优于蚁群算法和遗传算法,表明混合算法可以更有效地挖掘数据集中的关键特征。
使用选出的最优特征子集来训练SVM,并在测试集上进行分类任务,各个算法在分类任务上的准确率如表2所示。

表2 各算法在分类任务上的准确率
从表2可看出,混合算法在所有数据集上的分类准确率均优于蚁群算法和遗传算法,表明混合算法选出的特征子集可以更好地区分不同类别。
(2)参数优化。遗传算法和混合算法在参数优化问题上的准确率如表3所示。
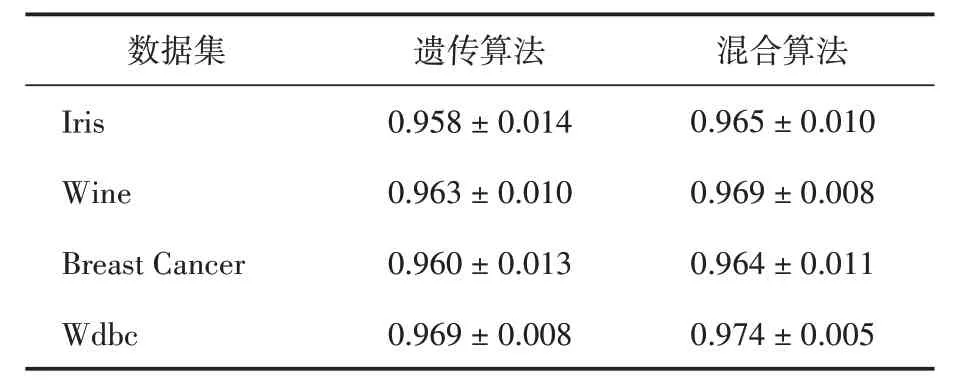
表3 遗传算法和混合算法在不同数据集上的准确率
从表3可看出,混合算法在所有数据集上的参数优化准确率均优于遗传算法,表明混合算法可以更快地找到最优参数配置。
使用选出的最优参数配置来训练SVM,并在测试集上进行分类任务,遗传算法和混合算法在分类任务上的准确率如表4所示。

表4 最优参数配置后遗传算法和混合算法的准确率
从上表可看出,混合算法在所有数据集上的分类准确率均优于遗传算法。综合实验表明,混合算法在参数优化和特征选择问题上都具有较好的性能。
4 结语
本文提出了一种基于蚁群算法和遗传算法的机器学习特征选择和参数优化混合算法。该算法首先使用蚁群算法来选择最优特征子集,然后使用遗传算法来优化SVM 分类器的参数配置。实验结果表明,混合算法在各个数据集上的分类准确率均优于蚁群算法和遗传算法,证明了混合算法的有效性。未来的研究可以探索更多的混合算法,如基于粒子群优化和遗传算法的混合算法,以提高机器学习准确度。
