基于改进YOLOv5和边缘设备的法兰盘表面缺陷检测
2023-09-24李振轩孙福临刘羿漩齐振岭葛广英
李振轩,孙福临,刘羿漩,齐振岭,葛广英
(1. 山东省光通信科学与技术重点实验室,聊城 252059;2. 聊城大学计算机学院,聊城 252059)
0 引言
法兰盘是一种管道间相互连接的盘状机械零件,在管道工程中发挥着重要作用。法兰盘加工过程复杂,步骤繁琐,不可避免地会出现一些缺陷。其中法兰盘表面缺陷不仅影响产品外观,同时严重损害其性能,缩短使用寿命,甚至导致严重的安全事故。目前大多数企业采用人工检测,人工质检方法受工人工作经验等因素影响,无法形成统一、严格的判断标准,漏检、错检的情况时常发生,人工检测效率低下不仅阻碍企业扩大生产规模,而且增加企业生产成本,严重影响企业健康发展[1]。因此,设计一种效率高、成本低的法兰盘表面缺陷检测方法尤为重要。
随着人工智能技术的快速普及,深度学习算法在各个研究领域得到广泛应用,为实现简捷、高效的缺陷检测提供了新思路[2]。以Faster R-CNN[3]和Mask R-RCNN[4]等为代表的二阶段检测网络和以SSD[5]、YOLO 系列等为代表的单阶段检测网络在缺陷检测中都有不错的表现。吴越等[6]提出了一种基于改进Faster R-CNN 算法,通过改进Faster R-CNN 的RPN 网络,有效降低池化过程中的量化误差,提高了小目标的检测精度,但改进后的算法推理速度低于YOLOv3算法。针对传统铸件表面缺陷检测效率低、精度差等问题,马宇超等[7]将深度迁移学习的网络自适应策略与Mask R-CNN 算法相结合,构建了深度网络自适应优化的Mask R-CNN 算法模型,优化后的模型泛化能力得到提升,在三种常见铸件表面缺陷数据集中得到的平均检测精度为92%,但检测速率较低。魏智锋等[8]设计了一种适用于人造板表面缺陷检测的SDD-MoblieNet 算法模型,将SSD 算法中的VGGNet 网络替换为轻量级的MobileNet 网络,并将Inception 网络附加到多个特征映射上,不仅增强网络提取特征的能力,而且提高了模型检测速度,在五种人造板表面缺陷数据中,该模型的平均检测精度为93.76%,最快检测速度为75 帧/秒。程婧怡等[9]将YOLOv3浅层特征和深层特征进行融合并新增一个特征图层,形成四个尺度预测,提升了模型检测金属表面小尺寸缺陷和模糊缺陷的能力,在NEU-DET 数据集中,改进后的YOLOv3算法平均检测精度为67.64%,但检测速率低于YOLOv3 算法。张凯等[10]设计了基于YOLOv4 的轻量化发电机定子表面缺陷检测算法,将YOLOv4 提取特征的主干网络替换为改进的MoblieNetv3 网络,使模型体积大幅缩小,检测速度提升了45.4%。虽然这些算法的检测精度能满足基本要求,但是对硬件的性能要求高,难以部署在计算资源有限的边缘设备中,不利于在企业大规模推广使用。为实现算法模型在边缘设备的部署,本文对YOLOv5进行优化,实现网络轻量化,并将轻量化后的模型部署在边缘设备Jetson nano 中,验证模型在边缘设备中的推理效果。
1 YOLOv5算法概述
YOLOv5 算法是由Ultralytics LLC 团队设计的一种高效、便捷的单阶段目标检测算法,相较于先提取物体区域再对区域进行CNN 分类识别的两阶段目标检测算法,单目标检测算法将目标检测任务转换成一个回归问题,虽然会损失一定的检测精度,但有效缩短了检测的时间,满足实时检测要求。根据网络的复杂程度可以将YOLOv5 分为五个版本。本文以YOLOv5s 为基础实现法兰盘表面缺陷检测,网络结构模型如图1所示。
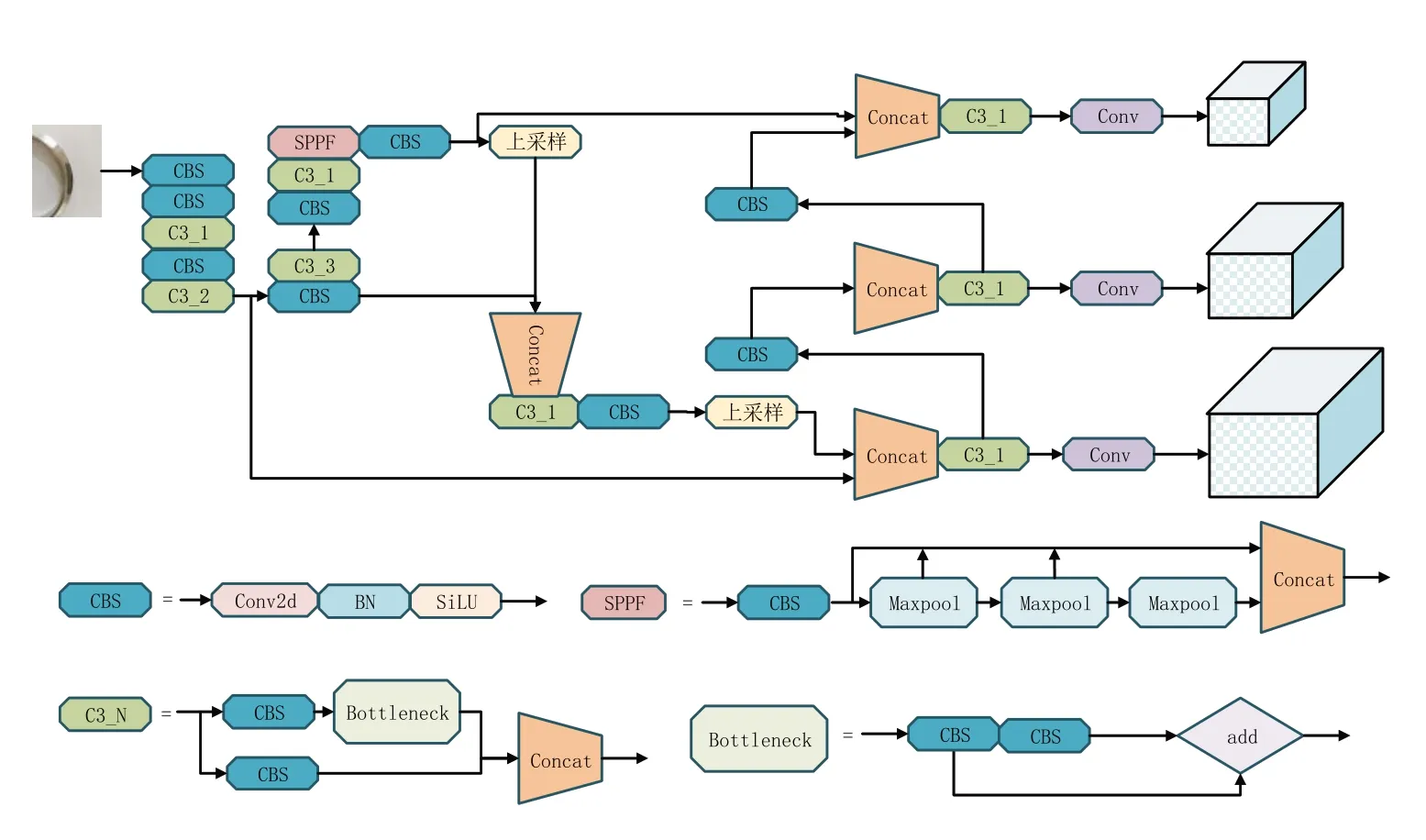
图1 YOLOv5结构
YOLOv5 网络结构由图像输入模块(Input)、负责输入图像特征提取的骨干网络(Backbone)、由特征金字塔和路径聚合网络构成的特征融合网络(Neck)和预测模块(Prediction)四部分组成[11]。YOLOv5 网络的输入模块沿用YOLOv4 的Mosaic 数据增强,将输入的四张图片做随机缩放、裁剪,然后再将其拼接,不仅丰富了检测数据集,而且增加了很多小目标,网络的鲁棒性得到增强,在进行归一化操作时会一次性计算四张图片的数据,降低了模型的内存需求,提升了网络的训练速度。由于数据集中图片的大小不一,通常是将原始图片按一定比例缩放到一个固定尺寸,然后对图片进行填充,填充较多会造成信息冗余。而YOLOv5通过自适应缩放算法,为缩放后的图片添加最少的填充,有效避免因过度填充造成的信息冗余,提升了网络的推理速度。在YOLOv5 6.0 版本中,使用Conv模块代替了骨干网络中的Focus模块,二者在理论上是等价的,但对于GPU 设备和现有的优化算法而言使用6×6 的卷积会更加高效[12],更有利于模型在边缘设备中部署。
2 YOLOv5算法改进
2.1 ShuffleNetV2
ShuffleNetV2[13]是旷视科技团队设计的针对嵌入式设备的高效轻量化卷积神经网络,ShuffleNetV2 作者通过大量实验得出不能单纯地以神经网络计算复杂度FLOPs作为衡量轻量化卷积神经网络指标的结论,并提出设计轻量化卷积神经网络的四条准则,分别为G1 输入输出通道数相同时,内存访问量最小;G2分组数过大的分组卷积会增加内存访问量;G3碎片化操作不利于并行加速;G4逐元素操作带来的内存和耗时不可忽略。作者根据这四条准则对ShuffleNetV1 加以改进和优化,设计出ShuffleNetV2。
ShuffleNetV2 主要由基本单元和下采样单元构成,其网络结构如图2所示。在基本单元中通道拆分(Channel Split)操作将输入特征矩阵的通道等分成两份,左支路不做任何处理作恒等映射,减少了碎片化操作,满足G3 准则。右支路经两次步长为1 的1×1 标准卷积(Standard Convolution,SConv)和一次步长为1的3×3深度可分离卷积(Depth-wise separable convolution, DWConv)[14],并且在卷积操作过程中输入输出通道数相同,满足G2 准则。为满足G4 准则ShuffleNetV2 放弃了ShuffleNetV1 中将左右两支路拼接的Add 操作而采用通道拼接(Concat)操作将左右两支路合并在一起。为保证左右两个支路的特征信息得到充分的融合,在Concat 操作后引入Channel Shuffle 模块,实现两支路间的信息交流,提升网络提取特征的能力。在ShuffleNetV2 基本单元中利用Channel Split 操作实现分组并将Shuffle-NetV1 中的分组卷积代替为DWConv,有效降低了分组数,满足G1 准则。ShuffleNetV2 下采样单元与基本单元结构相似,与基本单元相比少了对输入特征图Channel Split操作,并在左支路添加了步长为2 的3×3 DWConv 和1×1 SConv,增强网络提取特征的能力。由于下采样单元没有通道拆分操作使得左右支路在通道拼接后输出的通道数加倍。

图2 ShuffleNetV2结构
2.2 GSConv
目前,大多数的轻量化网络通过大量使用DWConv,减少模型对计算资源的依赖,提升检测速度,但在一定程度上影响模型检测精度。Li等[15]针对DWConv 固有缺点,将SConv 与DWConv 相结合,设计出兼顾速度与精度的GSConv模块。其结构如图3所示。设输入特征图X的通道数为C1,输出通道数为C2,特征图X经一次SConv 操作得到通道数C2/2 的特征图X1,再经DWConv操作得到特征图X2,通过Concat操作将X1、X2按通道进行拼接,然后利用Shuffle 操作将来自SConv 的特征信息完全混合到DWConv 输出的特征信息中,最后得到通道数为C2的特征图X4。这种操作既保留了SConv 的全部特征信息,降低了因轻量化带来的精度损失,同时还具备较高的检测速度。

图3 GSConv结构
2.3 改进后的网络
改进后的YOLOv5 网络结构如图4 所示。利用ShuffleNetV2 替换YOLOv5 骨干网络,网络模型的复杂度和参数量大大降低,有利于部署在计算资源有限的边缘设备中。为进一步降低模型对硬件设备的性能要求,提升模型在边缘设备中的运行速度,在替换骨干网络的YOLOv5中引入兼顾速度与精度的GSConv,实现模型在边缘设备中的快速推理,满足法兰盘加工过程中实时检测的需求。

图4 改进后YOLOv5结构
3 实验推理流程
3.1 实验数据集的建立
由于目前没有公开的法兰盘表面缺陷数据集,本文所使用的数据集采集自某法兰盘生产厂,本数据集包含黑皮、切伤、渣孔三种缺陷,如图5所示。本文对采集到的图像改变亮度、对比度并进行平移、旋转、缩放等操作实现数据集的扩充。经图像增强处理后法兰盘表面缺陷数据集一共有8540 张图片,包含三种法兰盘表面缺陷,黑皮2890张,切伤2920张,渣孔2730张,将得到的数据集按9 ∶1的比例划分为训练集、验证集。利用LabelImg 工具对数据集进行手工标注,保存生成的XML文件。

图5 法兰盘表面缺陷数据集
3.2 实验平台环境
本次模型训练使用的服务器硬件配置为Intel(R) Xeon(R) Platinum 8350C CPU, RTX A5000(24 GB)GPU,45 GB RAM。所使用的系统环境为Ubuntu 18.04,深度学习框架为PyTorch,其中torch版本为1.9.0+cuda11.1。
3.3 边缘设备简介
本次模型前端部署使用的边缘设备为英伟达生产的Jetson nano。Jetson nano 是一款外形、接口类似树莓派的微型电脑主板,相较于其他同类设备,Jetson nano性能强悍、价格适中。在硬件方面它配备了基本时钟频率为1.43 GHz 的Cortex-A57 四核处理器,内存为4 GB LPDDR4。与树莓派相比Jetson nano 最大优势是它配备了一块128 核Maxwell™架构的NVIDIA GPU,算力能够达到472 GFLOPs。它采用高效、低功耗的封装方式,具有5 W/10 W 功率模式和5 V DC 输入。软件方面Jetson nano 支持JetPack SDK 和多种主流的AI框架和算法,例如PyTorch,Tensor-Flow 等。JetPack SDK 是NVIDIA 用于构建AI 应用程序的开发环境包,支持Jetson模块和开发套件,具有Linux 内核、Ubuntu 桌面环境以及CUDA-X 加速库和API,用于深度学习、计算机视觉、加速计算和多媒体。Jetson nano 基本参数见表1。

表1 Jetson nano基本参数
3.4 实验结果分析
本文网络模型训练实验的参数如下:输入图片的大小为640×640,batch-size设为300。将训练好的网络模型复制到已搭建YOLOv5运行环境的Jetson nano 中,在Jetson nano 中运行推理程序,完成推理任务,实现法兰盘表面缺陷的检测。
本文以YOLOv5s 作为法兰盘表面缺陷检测的基础算法,通过对YOLOv5s 引入不同的优化策略实现模型的轻量化,为验证优化策略对模型的影响,设计了消融实验,具体结果见表2。

表2 YOLOv5s消融实验
由表2可知,YOLOv5s在法兰盘表面缺陷检测中平均检测精度可达到95.4%,但GFLOPs、参数量和模型体积较大,难以在边缘设备中部署。Changed(1)算法与YOLOv5s 相比,平均检测精度下降了0.9 个百分点,这是由于模型骨干网络轻量化,提取特征的能力下降所导致。但替换骨干网络后模型的GFLOPs、参数量和大小分别变为YOLOv5s 的37.5%、45.4%和46.2%,证明利用ShuffleNetV2 替换YOLOv5s 的骨干网络,可有效降低网络的复杂程度,快速实现网络的轻量化,同时这种轻量化方法对平均检测精度的影响较小。Changed(2)算法在YOLOv5s的Neck 网络引入GSConv,较YOLOv5s,其平均检测精度提升了1.5 个百分点,模型的GFLOPs、参数量和大小虽略有下降,但仍处在较高水平,下降程度不足以满足网络轻量化的要求。本文算法融合了Changed(1)算法和Changed(2)算法的优势,既实现了网络轻量化又保持了较高的检测精度。与YOLOv5s 相比,本文算法的GFLOPs、参数量和模型大小分别下降了66.9%、60.9%、59.4%,便于在资源有限的边缘设备中部署。
为验证本文优化后模型在边缘设备中的推理性能,将消融实验得到的算法模型部署到Jetson nano 中,对100 组数据进行多次推理,其结果见表3。

表3 模型推理结果
由表3 中的实验结果可知,由于YOLOv5s参数量大,网络层数深,对计算资源要求高,导致解析YOLO 层花费时间长,推理速度慢,推理速度仅为6.62 FPS,无法满足实时检测的要求。Changed(1)算法将YOLOv5s 的骨干网络轻量化,使得参数量和网络层数明显降低,大幅缩短YOLO 层解析时间和模型推理时间,与YOLOv5s相比,推理速度提升了76.3%,基本满足了实时检测的要求。Changed(2)算法将YOLOv5s 的Neck 网络轻量化,平均检测精度得到提升,同时缩短了YOLO 层解析时间,但网络层数加深,在模型推理时间和推理速度方面与YOLOv5s 基本持平,没有达到轻量化要求,难以在资源有限的设备中实现实时检测。本文算法弥补了Changed(1)算法因骨干网络轻量化造成的精度损失,与Changed(1)算法相比,平均检测精度增长1.1 个百分点,同时进一步降低Changed(2)算法参数量和网络层数,大幅缩短模型推理时间,推理速度得到有效提升,变为Changed(2)算法的1.79倍。
本文将模型部署实验所使用100组数据的推理时间绘制成图,如图6所示。本文算法与其他消融实验算法相比所需推理时间最短,推理过程相对平稳,推理时间在0.063~0.071 s 之间上下浮动,本文算法在边缘设备中的推理速度方面优于其余三种网络。本文算法推理效果如图7所示。

图6 推理时间折线图

图7 推理效果图
4 结语
本文构建了法兰盘表面缺陷数据集,提出了一种基于改进YOLOv5s 的法兰盘表面缺陷检测算法,通过替换YOLOv5s 骨干网络,引入GSConv,实现网络轻量化。其中,该模型的平均检测精度可以达到95.6%,在Jetson nano 中平均推理速度为12.38 FPS,有较高检测精度的同时也具有较高的检测速度,为企业提供了一种法兰盘表面缺陷实时检测的参考方案。在接下来的研究工作中,还需对数据集进行扩充,丰富法兰盘表面缺陷类别,对该模型做进一步的验证;由于该模型在平均检测精度方面还有提升空间,将尝试对该模型做进一步的优化以提高平均检测精度和检测速度。
