电子鼻结合机器学习对污泥异味特征的识别研究*
2023-09-23张珊珊楼紫阳张瑞娜王罗春
张珊珊 楼紫阳 王 川 张瑞娜 宋 佳 王罗春
(1.上海电力大学环境与化学工程学院,上海 200090;2.上海交通大学环境科学与工程学院,上海市固废处理与资源化工程研究中心,上海 200240;3.上海环境卫生工程设计院有限公司,上海市环境工程设计科学研究院有限公司,上海 200232)
污泥是污水处理过程中的重要副产物,其组分复杂、来源广泛、产量极大,预计我国2025年污泥年产量将突破9 000万t(以含水率80%计)[1]。污泥中可能含有重金属、有机物与有毒有害污染物,堆填处理时易腐化发臭,其异味组分及异味特征与处理过程相关[2-3],即使是同一种污泥在不同处理阶段其异味特征及强度也有所差异[4-5],不利于污泥异味污染的管控,目前针对污泥异味组分鉴别尚缺乏有效的检测技术。
电子鼻是一种灵敏的异味检测仪器,可以在短时间内同时分辨多种化学成分,目前已有电子鼻产品用于恶臭组分分析,但其检测准确性仍有待提高。电子鼻结合机器学习算法可在一定程度上提高异味识别率,常用于分类的典型机器学习算法有多元逻辑回归(MLR)、随机森林(RF)、自适应增强(AdaBoost)、梯度提升决策树(GBDT)、朴素贝叶斯分类器(NBC)、支持向量机(SVM)、K近邻(KNN)等。MLR是一种将逻辑回归一般化为多类别问题而得到的分类方法[6];RF是通过集成学习的思想将多个决策树集成的算法,可以取得更好的分类效果[7];AdaBoost与GBDT是提升法的典型代表,核心在于将多个弱分类器序贯式集成为强学习器[8-9];NBC是一种应用广泛的简单分类算法[10];SVM是一种二分类模型[11],可用于支持向量回归(SVR),又可用于支持向量分类(SVC);KNN是最简单的有监督学习方法之一[12],可解决分类或回归问题,适用于数据分布很少或无先验知识的情况。
为实现电子鼻对污泥异味特征的精准分类和快速鉴别,本研究围绕污泥异味组分及其异味特征之间的关系,对比了电子鼻对农业、化工与居民生活等3类典型污泥异味特征的识别效果,并通过机器学习提升电子鼻对异味特征的识别能力,以期优化电子鼻类产品对污泥异味组分的鉴别性能。
1 材料与方法
1.1 材料与仪器
分别从典型农产品加工厂、化工染料厂和城镇居民区采集大豆污泥(记为泥样D)、印染污泥(记为泥样I)、市政污泥(记为泥样S),同时收集厌氧消化后的市政污泥(记为泥样YS)、脱水处理后的市政污泥(记为TS)进行异味特征识别。
检测仪器为PEN3.5电子鼻恶臭分析仪(德国AIRSENSE),配套Winmuster分析软件。电子鼻内含有10个金属氧化物传感器(MOS),其型号情况见表1。Winmuster通过记录待测气体的电导率与传感器经标准活性炭过滤气的电导率之比(RG),通过内置主成分分析(PCA)、线性判别分析(LDA)等模式分析采集数据从而实现泥样识别,数据采集频率为1次/s。

表1 传感器阵列Table 1 Sensor arrays
1.2 实验方法
为了确保有足量的有效数据进行机器学习,整个实验分为两批次进行,第1批次为实验组,第2批次为平行实验组,两个批次的实验条件完全相同。在每批次的实验中,将采集的5种测试泥样装瓶密封,静置发酵1 h后开始检测,每隔10 min采样1次,共检测20次。为减少误差,当电子鼻检测基线值明显偏离1时,关闭仪器20~25 min后再检测。检测期间实验室平均温度为16~21 ℃,平均湿度为51%~77%,通风橱风速为3~4级。检测方式为手动进样,将进样探针和补气针插入装有5 g泥样的离心管中采集数据,单次采样时间为60 s,电子鼻采样完成后产生1个包含60条数据的nos文件,鉴于57~60 s的响应信号较为稳定,最能反映气味的综合信息,最终选取每个nos文件中57~60 s的4条数据进行分析。两批次实验共采集200组响应数据,将筛选后得到的800条数据读入Python,按7∶3的比例划分为训练集和测试集,进行机器学习。
2 结果与讨论
2.1 电子鼻对典型污泥组分异味特征的识别
2.1.1 典型污泥组分异味特征分析
分别取泥样D、泥样I和泥样S的20个nos文件数据输入Winmuster,建立3种泥样异味特征的预测模式,利用Python进行样本响应值的可视化呈现,结果见图1。PCA结果显示,3种泥样响应值的第1主成分解释率为70.3%,第2主成分解释率为26.6%,2个主成分对泥样异味响应值的总解释率高达96.9%,能综合反映3种泥样的异味特征信息,但泥样D和泥样S存在信息重叠区,可能发生误判。LDA结果显示,LDA对样本响应值识别正确率为91.9%,3种泥样异味特征的区分效果明显。综上可见,PCA与LDA皆可用于电子鼻对3种泥样异味特征的响应值分析,但PCA的区分效果不及LDA明显。

图1 3种泥样电子鼻响应值的PCA、LDA识别效果Fig.1 Identification performance of PCA and LDA for electronic nasal response values of three types of sludge
2.1.2 污泥异味特征随处理过程的变化
在3种典型泥样的基础上加入泥样YS及泥样TS,深入探究电子鼻对于5种泥样异味特征的识别效果。由于电子鼻最多只能分析400条污泥异味信息数据,因此各泥样分别取20个nos文件数据输入Winmuster,建立5种泥样的异味特征预测模式,利用Python进行样本响应值的可视化呈现,结果见图2。5种泥样响应值的PCA结果显示,第1主成分与第2主成分对样本响应数据总解释率为96.6%,但5种泥样响应值出现两处交叉区,错判率较高;5种泥样响应值LDA的识别正确率为87.7%,大于85%,可基本作为5种泥样的区分依据,但其正确率相较3种泥样的LDA分析结果下降4.2百分点。综合分析可知,在添加两种不同处理的市政污泥后,电子鼻训练集数据从240条增加到400条,PCA与LDA的识别效果皆下降,误判的可能性加大。由于电子鼻异味信息数据处理量有限,无法通过加大样本量建立更灵敏的预测模式来提高电子鼻识别效果。

图2 5种泥样电子鼻响应值的PCA、LDA识别效果Fig.2 Identification performance of PCA and LDA for electronic nasal response values of five types of sludge
2.2 机器学习模型对比分析
2.2.1 关键特征选择及机器学习模型的搭建
利用Python分析10个传感器响应值的皮尔逊系数矩阵,发现MOS1、MOS3、MOS5之间,MOS6、MOS8、MOS10之间以及MOS9、MOS7之间的响应值出现多次共线性,交叉响应情况严重,故分别采用PCA降维(PCA-)或LDA降维(LDA-)剔除冗余特征。
通过分析特征数与精确度的关系,发现特征数为4时模型准确率达到平稳高峰期,为降低数据冗余度,在MLR、RF、AdaBoost、GBDT、NBC、SVC、KNN 7类机器学习模型搭建时均输入4个特征。其中,SVC模型分别基于线性核函数、多项式核函数与径向基核函数进行构建,分别标记为SVClinear、SVCpoly、SVCRBF,为便于模型性能对比,各机器学习模型的随机种子均取固定值。
将两批次实验共采集的200组响应数据读入Python,其中560条划分为训练集,240条划分为测试集,在Python中导入适当的库和函数,然后使用这些函数来计算模型的性能指标,具体结果见表2。
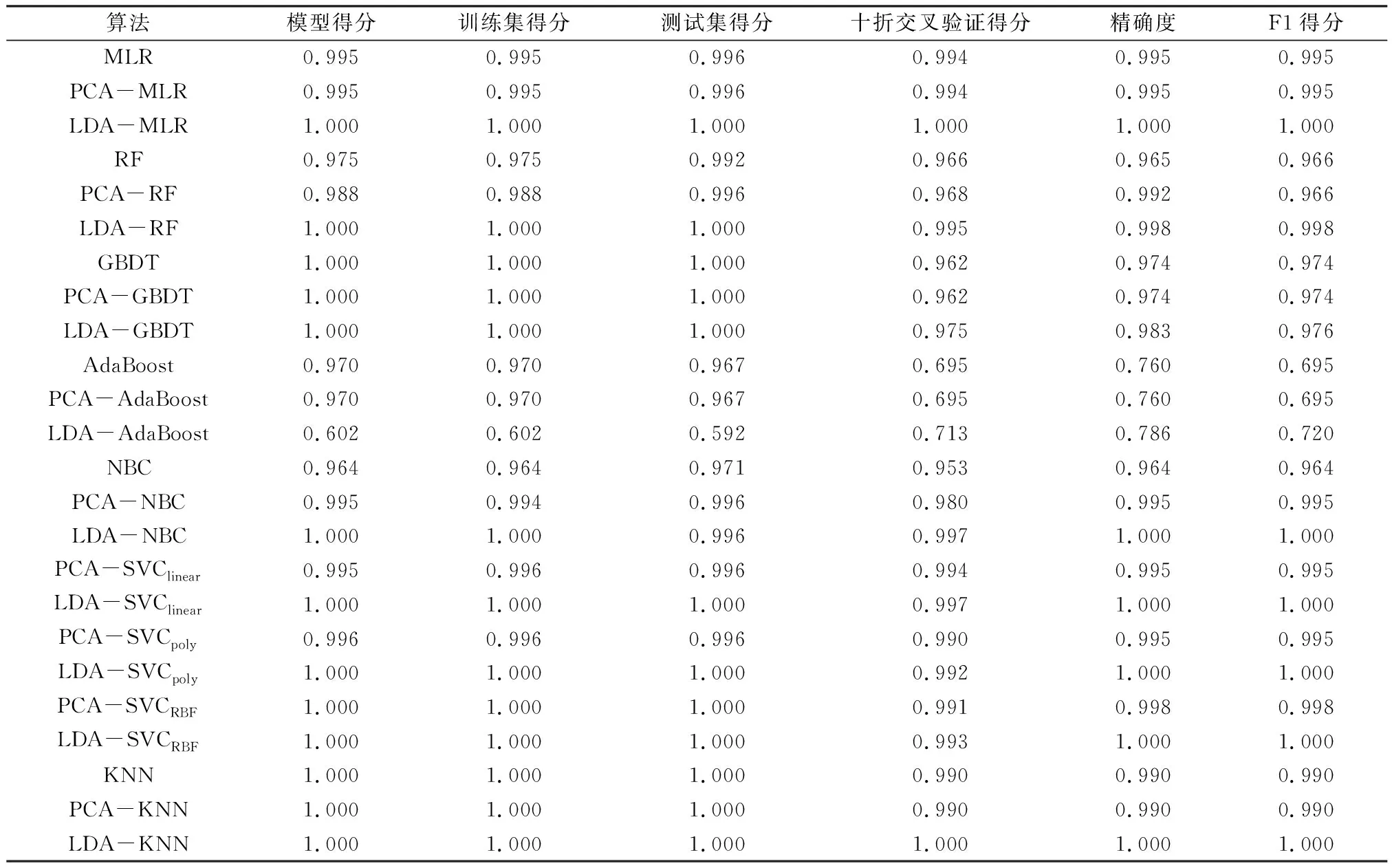
表2 不同机器学习模型的得分对比 Table 2 Comparison of scores of different types of machine learning algorithms
2.2.2 机器学习模型的分类结果
合理、科学、有效的评估模型预测效果可为模型优化提供指导。十折交叉验证是用于评估模型算法准确性的一个重要指标,得分在0~1之间,得分越接近1,模型预测结果越准确。F1得分是一种在统计学中常用的度量二分类的模型精确度指标,它综合考虑了模型的准确率和召回率。F1分数可以看作是模型准确率和召回率的一种加权调和平均,F1得分越接近1,表示模型泛化性能越优越。
MLR模型在收敛最大迭代次数为252时性能最好,测试集正确率可达99.6%,结合PCA降维后MLR模型质量不变,结合LDA降维后模型质量上升,测试集预测正确率高达100.0%。可见,MLR模型本身对5种泥样异味特征已具备较好的辨别能力,PCA降维对其分类效果提升无较好贡献,LDA降维可以将模型性能优化至最佳。
RF模型用于污泥异味特征的分类识别时,测试集预测正确率达99.2%,精确度为0.965,F1得分为0.966。结合PCA、LDA降维后,模型各项指标得分均有提升,LDA降维对模型性能提升效果更好,测试集预测正确率最高可达100.0%,精确度最高达0.998。
GBDT模型是对AdaBoost模型的推广,比较两种模型对5种泥样异味特征的分类性能差异,发现GBDT模型的精确度比AdaBoost高28.2%,F1得分高0.279,GBDT质量优于AdaBoost。LDA降维有利于GBDT模型分类性能的提升,AdaBoost模型精确度不到0.8,出现高偏差,且无法预测已知或未知数据,极可能欠拟合。
NBC模型测试集预测正确率为97.1%,十折交叉验证得分为0.953,模型分类效果良好。PCA与LDA降维后,模型质量均有提高,两种降维方式的提升效果相近。
对比SVClinear、SVCpoly、SVCRBF的分类情况,3类核函数构建的SVC模型结合PCA、LDA降维处理后,对污泥异味特征判别均表现优异,LDA降维效果更好,LDA-SVClinear模型分类性能最优,LDA-SVCpoly、LDA-SVCRBF模型分类准确性略差,极可能是因为输入模型的数据量少,且降维处理后复杂度不高,导致线性核函数构建效果相对更好。
KNN模型分类质量良好,F1得分达0.990,泛化能力好,测试集预测正确率高达100.0%。结合PCA降维后,模型质量不变,结合LDA降维后,模型各项得分均达最高值。
综上分析可知,AdaBoost模型算法可能出现欠拟合,其余机器学习模型预测正确率均在97.1%以上,基于LDA降维的LDA-MLR、LDA-KNN与LDA-SVC模型算法比电子鼻LDA识别正确率高12.3百分点,对异味特征辨识度大大提高。此外,几种机器模型中出现了F1得分为1.000的完美模型情况,现实中基本不存在预测效果完美的情况,此处是因为输入模型的总样本量仅为筛选后的800条响应值,其特征信息进行了良好的泛化处理,测试集与验证集的数据量均不够大[13]。
2.2.3 可视化验证
借助Python实现MLR、KNN、SVC模型分类结果的二维平面可视化呈现,比较PCA、LDA降维处理对决策边界分类效果的差异。
由图3可见,PCA-MLR与LDA-MLR基本完成异味特征响应值分类,有少量样本出现在决策边界上。由图4可见,PCA-KNN中5种泥样异味特征响应值可基本区分,类间距离不大,十折交叉验证结果表明模型有1.0%的评价失真概率。LDA-KNN的类间距离在PCA-KNN的基础上变大,模型泛化能力提高。KNN为不规则决策边界,分类效果优于MLR,但预测速度低于MLR,适用于特征数较少或类域交叉较多的情况,MLR多用于处理特征或变量数目不太大的线性可分问题,二者都不适用于样本不平衡的情况。实际生产应用中,难以保证每次输入的样本量平衡,这制约了KNN与MLR的应用范围,此处MLR与KNN模型均表现较好,部分原因是本实验设置的5种泥样输入的样本集均衡。

图3 PCA-MLR、LDA-MLR分类的可视化情况Fig.3 Visualization of PCA-MLR and LDA-MLR classification
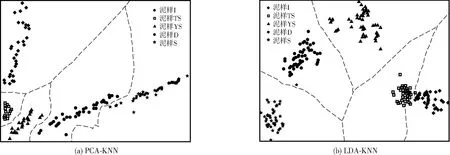
图4 PCA-KNN、LDA-KNN分类的可视化情况Fig.4 Visualization of PCA-KNN and LDA-KNN classification
由图5、图6可见,基于3种核函数构建的SVC模型分类效果均较好,结合LDA降维的SVC模型有部分样本点在决策边界上,但其泛化能力高于PCA降维的SVC模型。此外,SVC模型不受各类样本容量大小的影响,可根据实际选择相应的核函数解决线性可分或非线性问题,应用范围广泛。
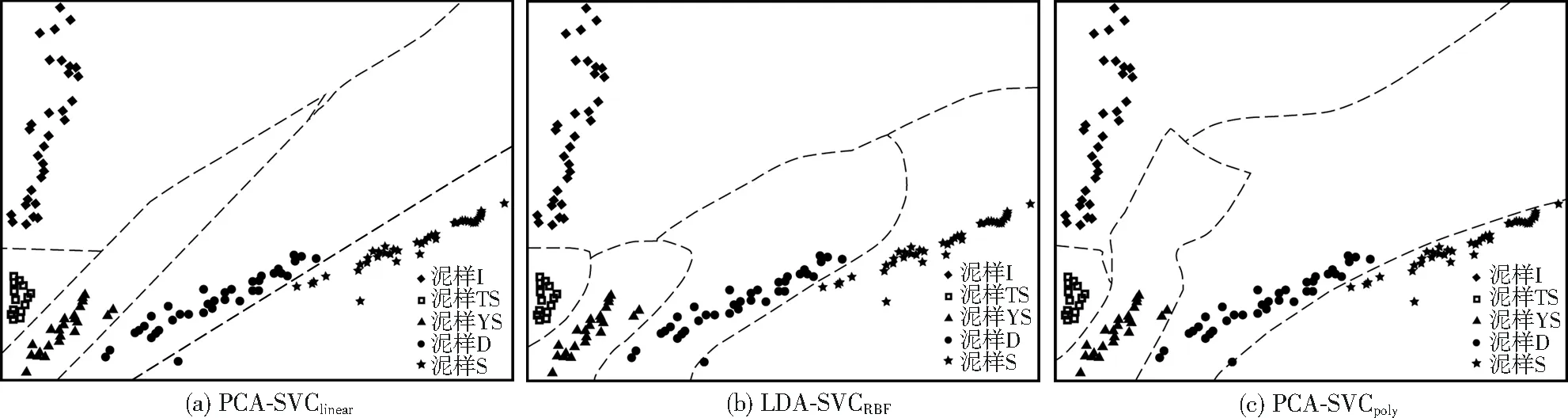
图5 PCA-SVClinear、PCA-SVCRBF、PCA-SVCpoly分类的可视化情况Fig.5 Visualization of PCA-SVClinear,PCA-SVCRBF and PCA-SVCpoly classification

图6 LDA-SVClinear、LDA-SVCRBF、LDA-SVCpoly分类的可视化情况Fig.6 Visualization of LDA-SVClinear,LDA-SVCRBF and LDA-SVCpoly classification
综上可知,LDA-SVClinear模型可视化分类程度高,实际可应用范围更广,电子鼻系统结合LDA-SVClinear模型有助于污泥异味特征的快速判别,提升识别正确率,可为多场景的污泥处理质量评估提供有效手段。
3 结 论
(1) 电子鼻通过PCA或LDA可以实现对3种典型泥样异味特征的判别,PCA对异味特征响应值总解释率高达96.9%,LDA对样本响应值识别正确率为91.9%,但LDA的分类可视化效果更好,对污泥异味溯源工作有一定价值。在3种泥样信息中再加两种不同处理的市政污泥,原有预测模式的错判概率增加,PCA总解释率降低0.3百分点,LDA识别正确率降低4.2百分点,且训练样本不能超过400条,无法通过增大样本量建立更灵敏的预测模式来提高电子鼻识别效果。
(2) 将多种机器学习模型用于5种泥样的异味特征判别,发现基于LDA降维的LDA-MLR、LDA-KNN与LDA-SVC模型算法比电子鼻LDA识别正确率高12.3百分点,解决了电子鼻分析数据量受限的问题。此外,LDA-SVClinear模型可视化分类程度高,实际可应用范围更广,电子鼻系统结合LDA-SVClinear模型有助于污泥异味特征的快速判别,提升识别正确率,可为污泥储存场地检测及污泥处理质量评估等场景的应用提供有效手段。
