TSCL-SQL:Two-Stage Curriculum Learning Framework for Text-to-SQL
2023-09-22YINFengCHENGLuyi程路易WANGQiuyue王秋月WANGZhijun王志军DUMingXUBo
YIN Feng(尹 枫), CHENG Luyi (程路易), WANG Qiuyue(王秋月), WANG Zhijun(王志军), DU Ming(杜 明), XU Bo(徐 波)
School of Computer Science and Technology, Donghua University, Shanghai 201620, China
Abstract:Text-to-SQL is the task of translating a natural language query into a structured query language. Existing text-to-SQL approaches focus on improving the model’s architecture while ignoring the relationship between queries and table schemas and the differences in difficulty between examples in the dataset. To tackle these challenges, a two-stage curriculum learning framework for text-to-SQL(TSCL-SQL) is proposed in this paper. To exploit the relationship between the queries and the table schemas, a schema identification pre-training task is proposed to make the model choose the correct table schema from a set of candidates for a specific query. To leverage the differences in difficulty between examples, curriculum learning is applied to the text-to-SQL task, accompanied by an automatic curriculum learning solution, including a difficulty scorer and a training scheduler. Experiments show that the framework proposed in this paper is effective.
Key words:text-to-SQL; curriculum learning; semantic parsing
Introduction
Text-to-SQL is the task of mapping a natural language query to a structured query language, which enables general users to query relational databases with natural languages. Limited by the scale of the dataset, early work can only complete the task on a single database with a few tables[1]. Recently, the release of the WikiSQL[2]dataset, which consists of more than 20 000 tables and about 80 000 natural language queries, presents a new challenge. The model is required to be generalized to unseen table schemas[2]and different kinds of queries.
To tackle this challenge, existing text-to-SQL approaches cast the problem as a slot-filling[3]task. Xuetal.[4]utilized a multi-task model to fill the predicted values into a pre-defined grammar template. Heetal.[5]and Lyuetal.[6]further improved the model architecture and achieved better performance. However, the current text-to-SQL models still suffer from two challenges.
The first challenge is that current approaches do not leverage the differences in difficulty between examples in the dataset. As shown in Fig.1(a), a simple query is related to fewer columns in the table, and the names of all related columns are mentioned in the query. In the simple example, the Winner and Runner-up columns are directly mentioned in the query. A complex query is shown in Fig.1(b). It is related to more columns, and some of the columns’ names are not mentioned in the query. In this complex example, the query is related to the Goals, Matches, Average and Team columns. However, the Team column is not mentioned in the query. The model must infer the column name from potential cell values. It makes sense that we can use the differences in difficulty to guide the training process.
The second challenge is that current approaches do not utilize the relationship between queries and table schemas. As shown in Fig.1, a column name might be mentioned directly or indirectly in the query. The model is required to ground these potential mentions to the table schema. However, existing methods only consider the query’s corresponding table schema, which makes it difficult for the model to learn query-schema alignment.
To address these shortcomings, a two-stage curriculum learning framework for text-to-SQL is proposed. Specifically, to leverage the differences in difficulty between examples, curriculum learning[7]is applied to the text-to-SQL task and an automatic curriculum learning solution is designed, including a difficulty scorer and a training scheduler. To exploit the relationship between queries and table schemas, a schema identification pre-training task is proposed to make the model choose the correct table schema from a set of candidates for a specific query. Experiments, including comprehensive ablation studies conducted on the WikiSQL dataset would demonstrate the effectiveness of the proposed method.

Fig.1 Examples of text-to-SQL task:(a) simple example; (b) complex example
1 Framework Overview
In this section, the text-to-SQL problem is formulated and the two-stage curriculum learning framework for the text-to-SQL problem is introduced.
1.1 Problem formulation
Given a natural language queryQand a table schemaS=
1.2 Overall architecture
As shown in Fig.2, the TSCL-SQL framework split the training process of the text-to-SQL task into two stages. Firstly, the query-schema alignment model was built at the pre-training stage. Specifically, a schema identification task was designed to retrieve the table schema for a specific natural language query. Based on the cross-encoder[8]with an in-batch negative[9]sampling strategy, the model chose the most similar table schema from the candidates for a specific query. Secondly, the curriculum learning was adopted, and the training process of the text-to-SQL task was re-designed with a difficulty scorer and a training scheduler at the curriculum learning stage. The difficulty scorer scored the difficulty of each training sample. The training scheduler organized training samples according to the score, from simple to complex, and split them into buckets to guide the optimization process.

Fig.2 TSCL-SQL framework:(a) pre-training stage; (b) curriculum learning stage
2 Pre-training Stage
The objective of the pre-training stage is to enhance the encoder for the text-to-SQL task by establishing a strong alignment between the natural language query and the table schema. In order to build the alignment, a novel schema identification task is proposed to retrieve the relevant table schema for a given query. To facilitate this task, a dataset specifically designed for schema identification is constructed based on the WikiSQL dataset. The schema identification task is completed using a cross-encoder approach with an in-batch negative sampling strategy, effectively leveraging the power of the model to accurately identify and match query-table schema pairs.
2.1 Dataset construction
As shown in Table 1, the dataset mainly consists of the query and the table schema’s meta information. Since Wikipedia is the data source of the WikiSQL dataset, the corresponding table ID, article title, and section title from Wikipedia are concatenated as descriptions for each table schema. Figure 3 shows an example of the data source.

Table 1 Information of schema identification dataset

Fig.3 Data source of descriptions for a table schema
2.2 Query-schema alignment model
The query-schema alignment model aims to build a better encoder representation for the text-to-SQL task. A retrieval-based schema identification task of selecting the most similar table schema from a set of candidates for the given query is proposed. Figure 4 shows the architecture of the query-schema alignment model. It took the query and the description of the table schema as input and output a score representing the semantic consistency between the query and the table schema. The one with the highest score was chosen as the query’s corresponding table schema.

sim(Qi,Di)=Linear(red(Encoder
([CLS]Qi[SEP]Di[SEP]))),
(1)
whereEncoder(·) represents the encoder of a pre-trained language model based on transformers[10];red(·) is a function that takes the representation of the first token from the last layer of the encoder;Linear(·) is a fully connected layer; [CLS] and [SEP] are special tokens.

Fig.4 Architecture of query-schema alignment model
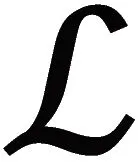
(2)
3 Curriculum Learning Stage
The curriculum learning stage aims to use a curriculum learning framework to train a text-to-SQL model. A curriculum learning framework for the text-to-SQL task is introduced. Then, the implementation of two core components of the framework is described in detail.
3.1 Curriculum learning framework
The curriculum learning framework consists of a difficulty scorer and a training scheduler. The difficulty of each training sample is measured by an automatic difficulty scorer to avoid the uncertainty of hand-crafted rules and consider more about the feedback from the model. The overall process is as follows.
Firstly, the difficulty scorer scores the samples and sorts them from easy to complex. Secondly, the training scheduler initializes an empty subset of the training set as a training stage starts. Sorted samples are split into buckets. For each training stage, a new bucket is added to the subset according to the difficulty. If the training on the subset is converged, the scheduler moves to the next stage until all the buckets are trained. Finally, the full training set is used for training for another few epochs.
3.2 Difficulty scorer
The difficulty scorer aims to score every training sample based on its difficulty. Due to the lack of existing information about which training samples are more difficult, instead of hand-craft rules, the model’s training loss is used as a measurement of the difficulties. A higher loss indicates that the sample is more complex and difficult.

(3)

Fig.5 Template used for slot-filling task
3.3 Training scheduler
The training scheduler aims to arrange the scored training samples for curriculum learning. As shown in Fig.6, the scheduler first sorts the training samples from easy to difficult and splits them intoNbuckets. Then it starts training with the easiest one. If the training process reaches convergence or a pre-defined number of epochs, a more difficult bucket will be merged. The scheduler will shuffle the data in the bucket and start training. After all the bucket is merged, it will train for several extra epochs on the complete training set.

Fig.6 Training scheduler
4 Experiments
4.1 Dataset and metrics
The proposed framework is evaluated on the WikiSQL dataset. It consists of tables from Wikipedia, natural language queries and their corresponding SQL statements. The basic characteristic of the WikiSQL dataset is shown in Table 2.

Table 2 Basic characteristics of WikiSQL dataset
Specifically, the natural language queries and their corresponding SQL statements are stored with JavaScript object notation. The tables are managed with SQLite database. Figure 7 shows an example of the training set.

Fig.7 Example of training sample
In Fig.7, table_id represents the corresponding table of a query; question is the natural language query, sql is the annotated SQL statement; agg and sel represent the column name and the aggregate function of the SELECT statement, respectively; conds are triplets (column-name, operator, value) of the WHERE statement.
Logic form accuracyAccland execution accuracyAcceare used to evaluate the performance. Logic form accuracy considers whether the predicted SQL statement matches the ground truth. Execution accuracy considers if the execution result of the predicted SQL statement is the same as the execution result of the ground truth one. The formulas are as follows.
(4)
(5)
(6)
(7)
whereNdenotes the size of a specific split of the dataset;SQL′ andSQLdenote the predicted SQL statement and the ground truth one, respectively;Y′ andYrepresent the execution result of the predicted SQL statement and the ground truth one, respectively.
4.2 Execution-guided decoding
Execution-guided decoding[11]uses beam search to expand the search space of candidate SQL statements and uses the execution result to filter the candidates. The main idea of execution-guided decoding is as follows. If the execution result of the predicted SQL statement is empty or the SQL parser cannot parse the statement, it is believed that the predicted SQL statement is wrong and another SQL statement will be selected from the candidates. In the following experiments, execution-guided decoding is used to further improve the performance.
4.3 Parameter settings
All the experiments were conducted on an entry-level server. Hardware and software configurations are shown in Table 3.

Table 3 Hardware and software configurations
Due to the limitation of the hardware, the implementation is based on RoBERTabase[13]. At the pre-training stage, the encoder was trained for three epochs. The initial learning rate was 3×10-6. At the curriculum learning stage, the model was first trained on the full training set for two epochs to get the difficulty scorer. Then the scored training samples were split into four buckets. After that the model was trained for three epochs for each training stage until all buckets were trained. Finally, the model was further trained on the full training set until converge.
4.4 Baselines
In order to establish a comprehensive performance comparison, multiple baseline methods for the text-to-SQL task are implemented and evaluated.
1) HydraNet:HydraNet[6]proposes a hybrid ranking network, which casts the text-to-SQL problem as a column-wise ranking and decoding problem. It uses RoBERTa[12]as the encoder.
2) HydraNet+Pt:the query-schema alignment pre-training method is implemented on that of the original HydraNet.
3) HydraNet+CL:curriculum learning is applied to the original HydraNet.
4) TSCL-SQL:the proposed method utilizes both query-schema alignment pre-training and curriculum learning.
4.5 Results and analyses
The results are shown in Tables 4 and 5, which demonstrate the framework’s performance under two scenarios, namely with execution-guided decoding (EG) and without EG.
1) When EG is not applied, the logic form accuracy and the execution accuracy of the re-produced HydraNet model on the test set are 80.8% and 86.4%, respectively. The proposed model, TSCL-SQL, improves performance by 1.5% and 1.4%, respectively.
2) When EG is applied, although the execution accuracy on the test set is already 91.0%, TSCL-SQL still improves the logic form accuracy and the execution accuracy by 0.9% and 0.5%, respectively.
3) Ablation studies are conducted to investigate the effectiveness of the pre-training stage and the curriculum learning stage. If the pre-training stage is removed, the logic form accuracy and the execution accuracy will drop 0.5% and 0.6%, respectively, on the test set when EG is not applied. When EG is applied, there is still a slight decrease on the logic form and the execution accuracy if the pre-training stage is removed. It demonstrates that the pre-training stage would help the model initialize a better representation.

Table 4 Performance of TSCL-SQL framework without EG

Table 5 Performance of TSCL-SQL framework with EG
Tables 6 and 7 show the performance comparison on all sub-tasks. TSCL-SQL achieves a performance improvement of 0.4% on the S-AGG sub-task compared to the baseline on the test set. On the other sub-tasks, the performance is still comparable. Therefore, TSCL-SQL is effective.

Table 6 Development accuracy and test accuracy of various sub-tasks on Wiki SQL dataset without EG

Table 7 Development accuracy and test accuracy of various sub-tasks on Wiki SQL dataset with EG
Through analysis, it is found that both the pre-training stage and the curriculum learning stage are important. The pre-training stage provides a better representation for downstream tasks. The curriculum learning stage lets the model learn from easy tasks to complex tasks. It is beneficial for the model to approach the global minimum gradually and smoothly.
5 Conclusions
In this paper, a two-stage curriculum learning framework for text-to-SQL (TSCL-SQL) is proposed. At the pre-training stage, a schema identification pre-training task is proposed to build an alignment between queries and schemas. At the curriculum learning stage, an automatic curriculum learning solution is proposed for the text-to-SQL task. Experimental results demonstrate the effectiveness of the framework proposed in this paper.
猜你喜欢
杂志排行

Journal of Donghua University(English Edition)的其它文章
- Image Retrieval with Text Manipulation by Local Feature Modification
- Multi-style Chord Music Generation Based on Artificial Neural Network
- Polypyrrole-Coated Zein/Epoxy Ultrafine Fiber Mats for Electromagnetic Interference Shielding
- Design of Rehabilitation Training Device for Finger-Tapping Movement Based on Trajectory Extraction Experiment
- High-Efficiency Rectifier for Wireless Energy Harvesting Based on Double Branch Structure
- Review on Development of Pressure Injury Prevention Fabric