基于改进RoI Transformer 的遥感图像多尺度旋转目标检测
2023-09-21刘敏豪王堃金睿蛟卢天李璋
刘敏豪,王堃,金睿蛟,卢天,李璋
(1.国防科技大学 空天科学学院,湖南 长沙 410000;2.国防科技大学 图像测量与视觉导航湖南省重点实验室,湖南 长沙 410000)
引言
基于深度学习的目标检测技术在遥感领域已广泛应用[1]。不同于前视图像中的目标,俯视的遥感图像中的目标具有方向任意的特点(如图1 所示),依赖于水平感兴趣区域(horizontal region of interest, HRoI)的通用目标深度学习检测方法通常会引起预测边界框和真实边界框之间的错位[2],在检测大长宽比(如桥梁、大船等)且具有任意角度目标时会包含大量冗余的背景信息。此外,遥感图像中复杂背景、目标的形态变化[3]、目标的密集分布[4]进一步增加了旋转目标检测的难度,针对遥感图像的高精度的旋转目标检测依然具有挑战。

图1 遥感图像(第1 行)和自然图像(第2 行)对比图Fig.1 Comparison between remote sensing images (the first row) and natural images (the second row)
近年来,在基于深度学习的通用目标检测基础上发展出了多种旋转目标检测方法。通用目标检测主要回归目标区域的(x,y,w,h),其中(x,y)表示HRoI 的中心,w和h分别表示HRoI 的长度和宽度,而旋转目标检测额外回归一个方向值θ,并输出目标区域旋转框(x,y,w,h,θ)。MA J Q 等学者设计了RRPN(rotated region proposal network)[5],通过对特征提取网络预定义的每一个anchor 位置添加一些方向参数,以此生成大量不同尺度、长宽比、方向的anchors,其还提出了RRoIs (rotated region of interest),可以将任意旋转候选区域投影到特征图。RRPN方法可以获得旋转的候选目标区域,提升旋转目标的检测精度,但是这些密集的旋转anchors 消耗了大量的计算和存储资源[6]。DING J 等人提出了RoI Transformer[3],该方法使用空间变换将水平边界框表示的候选区域转换为旋转框,可以大大减少旋转anchor 的数量并提高了检测精度。在RoI Transformer 的基础上,HAN J M 等提出了ReDet 来提取目标的旋转不变特征[7],其以旋转等变网络为骨干网络生成旋转等变特征,可以准确预测目标方向,降低对方向变化建模的复杂性,其还提出了RiRoIAlign(rotation-invariant RoI Align)算法,对每个候选区域提取旋转不变特征,进一步提高了旋转目标的检测精度。RoI Transformer 已成为当前最典型的旋转目标检测框架,然而,RoI Transformer 采用的骨干网络ResNet[8]会在提取特征时逐渐减小特征图的空间大小[3],因此它对目标的尺度变化非常敏感,对于不同分辨率图像的目标检测适应性不足。此外,RoI Transformer 使用基于SmoothL1 损失的回归方法来预测目标旋转角度,其无法解决旋转目标表示带来的角度周期性问题,其表现为角度边界不连续性[9-10]以及类正方形问题。
基于RoI Transformer 的旋转目标检测常用于双阶段(two-stage)目标检测,其包含生成目标候选区域和目标检测分类两个步骤。最近有学者提出了一些单阶段(one-stage)旋转目标检测方法,例如R3Det(refined rotation RetinaNet)[11],一种基于RetinaNet 的端到端精细化旋转目标检测器,它采用从粗到精的渐进回归形式,首先使用水平anchor 以达到更高的召回率,然后在后续精细化阶段使用精细的旋转anchor 以获得更精确的定位。SASM(shape-adaptive selection and measurement) reppoints[12]方法提出样本自适应选择和分配策略,根据目标的形状信息和特征分布动态选择样本。Oriented reppoints[13]方法提出一种高效的质量评估和样本分类方法,还引入了一种空间约束来惩罚离群点,以实现鲁棒的自适应学习。其他典型的单阶段方法还包括SSD(single shot multibox detector)、YOLO(you only look once)及其改进方法[14]等。在单阶段目标检测中,一种基于高斯分布的回归损失被提出,用来解决目标表示的角度周期性问题,提高了旋转目标的检测精度,其核心步骤是将旋转边界框转换为二维高斯分布,采用的损失包括GWD(Gaussian Wasserstein distance)[9]、KLD(Kullback -Leibler divergence)[15]和KFIoU(Kalman filtering intersection over union)[16]等。单阶段方法一般可以获得比双阶段方法更高的检测效率,但其检测精度也会受到一定的损失[17]。
针对RoI Transformer 对多尺度遥感图像旋转目标检测精度不足的问题,本文提出了HRD-ROI Transformer (HRNet + KLD ROI Transformer)方法。首先,采用原始的RoI Transformer 检测框架获取RRoI,用于鲁棒的几何特征提取;其次,使用HRNet[18]作为骨干网络,提升模型对多尺度目标检测的适应能力;最后,借鉴单阶段目标检测的损失函数设计思路,以KLD 损失代替RoI Transformer检测框架中的SmoothL1 损失,解决旋转目标表示带来的角度周期性问题,进一步提高ROI Transformer 框架对旋转目标检测能力。
1 HRD-ROI Transformer
HRD-ROI Transformer使用RoI Transformer 作为基本框架。其采用HRNet 作为骨干网络,将高分辨率卷积和低分辨率卷积流并行连接,可在保持高分辨率特征提取的前提下提升模型对多尺度目标检测的适应能力。KLD 损失用来代替SmoothL1 损失,解决度目标表示周期性带来的角度边界不连续性和类正方形问题。
1.1 检测网络整体架构
HRD-ROI Transformer 的整体架构如图2 所示,主要包含4 个部分。
特征提取模块采用带有特征金字塔的HRNet提取多层高分辨率特征(见1.2 节)。
RPN 模块RPN 模块将任意大小的特征图作为输入,生成一系列粗略的HRoIs。
RoI Transformer 模块RoI Transformer 模块用于从HRoIs 的特征图中生成RRoIs。首先,通过RoI Pooling 或RoI Align 对不同大小的HRoIs 进行RoI 提取,得到固定大小(默认为7×7)的RoI 特征,然后将每个HRoI 特征输入到全连接层中,并对其进行解码,得到相应的粗略RRoIs。
基于KLD 损失的RCNN 模块类似于RoI Transformer 模块,通过旋转RoI Pooling、旋转RoI warping 或旋转RoI Align 将不同尺寸的RRoIs 进行旋转,RoI 提取得到固定尺寸的RoI 特征,再输入到全连接层进行分类和更加精细的边界框回归,其中以KLD 损失调整边界框回归的结果,最终输出结果。
1.2 高分辨率网络
为了提升检测网络对不同尺度目标的适应性,本文采用高分辨率网络HRNet 代替ResNet 作为骨干网络。HRNet 的基本结构如图3 所示,包含并行多分辨率卷积和重复多分辨率融合。

图3 HRNet 结构图[18]Fig.3 Structure diagram of HRNet[18]
图3 中conv.unit 表示步长为1 的3×3卷积,strided.conv 表示步长为2 的3×3 卷积,upsample表示双线性上采样后进行1×1 卷积。并行多分辨率卷积是指以一个高分辨率子网络作为第一阶段,并逐步增加一个由高分辨率到低分辨率的子网络,形成新的阶段,并将这些多分辨率子网络并行连接起来。重复多分辨率融合是指在各个并行子网络之间引入交换单元,使每个子网络能重复地从其他并行子网络接收信息。
该模型的主要特点是整个过程中特征图始终保持高分辨率,通过在高分辨率特征图主网络中逐渐并行加入低分辨率特征图子网络,不断进行不同网络分支之间的信息交互,同时保持强语义信息和精准位置信息。在RoI Transformer 网络的基本结构中,FPN(feature pyramid networks)作为特征提取中重要的一个环节,是将低分辨率强语义的深层特征和高分辨率弱语义的浅层特征通过一种自上而下的方式进行特征融合,使得不同层次的特征增强[19],而HRNet 并非是FPN 的扩展,它不仅有逐层的特征融合,还有子网络之间多次重复地交换信息,可以持续保持高分辨率的特征。
1.3 基于KLD 的参数联合优化
尽管RoI Transformer 方法在旋转目标检测中具有良好的效率和精度,但由于其旋转目标表示方式带来的角度周期性,会存在角度边界不连续性(图4)和类正方形问题(图5),导致模型训练的不稳定。此外,其采用的smoothL1 回归损失对目标表示的各个参数是进行独立优化的,使得损失对任何参数的欠拟合都很敏感,影响了旋转目标的检测精度。本文引入的KLD 损失,将旋转目标表示为高斯分布基础上,采用联合优化的策略,可有效解决角度周期性问题,提高目标的检测精度。

图4 角度边界不连续性示意图Fig.4 Schematic diagram of angle boundary discontinuity

图5 类正方形问题示意图Fig.5 Schematic diagram of square-like problem
1.3.1 旋转目标表示的角度周期性
图4(a)是目标预测框的理想表示形式,黄色旋转框和绿色加粗旋转框分别表示目标的预测值和真值,其目标框的表示分别为(xp,yp,wp,hp,θp)和(xt,yt,wt,ht,θt),两者只存在角度和中心点的细微差别。旋转目标表示一般有OpenCV 表示方法[20]和长边定义法[21]。若采用OpenCV 定义表示旋转框(图4(b)),会存在长短边交换的问题。由于OpenCV表示方法的定义中θ∈(0,π/2],其锐角的一侧定义为w,因此,图4(b)中的预测框角度 θp是短边与水平轴正方向的夹角,与图4(a)中的理想形式的 θp相差π/2,且预测框的长宽与真值相反,这种旋转框定义方式有可能会造成较大的回归损失,导致模型训练不稳定,尤其大长宽比目标,该问题会更加突出。若采用长边定义法表示旋转框(图4(c)),由于定义中长边与水平轴正方向的夹角θ∈(-π/2,π/2],图4(c)中与图4(a)中的预测角度 θp相差 π,因此θp与θt存在较大差异。
对于类正方形的目标(如图5 中的棒球场,其长宽比接近于1),若预测框的长边正好与真值的长边相反,对于长边定义法的目标表示方式,θp与θt会相差π/2,同样会导致模型训练不稳定。
1.3.2 KLD 损失
为解决ROI Transformer 原有的目标表示方式存在角度周期性问题,本文在RoI Transformer 框架中引入KLD 损失。首先,将目标表示的旋转框(x,y,w,h,θ)转换成高斯分布N(m,Σ):
式中:R表 示旋转矩阵;Λ表示特征值的对角矩阵。
在式( 1 )中,高斯分布具有以下几个属性[10]:
属性1:Σ(w,h,θ)=Σ(h,w,θ-π/2)
属性2:Σ(w,h,θ)=Σ(w,h,θ-π)
属性3:Σ(w,h,θ)≈Σ(w,h,θ-π/2),w≈h
根据属性1,旋转目标的OpenCV 表示方法造成的长短边的交换问题得以避免。根据属性2 和3,旋转目标的长边定义法造成的类正方形问题也可以得到解决。综上,角度周期性因高斯分布的三角函数表示方式得以避免,表现出边界连续性。
预测框和真值对应的高斯分布 Np(mp,Σp)和Nt(mt,Σt)的KLD 为
显然,Dkld(Nt‖Np) 中的每一项都是由部分参数耦合组成的,所有旋转框参数(x,y,w,h,θ)都形成了一种链式耦合关系,使其在训练过程中相互影响,联合优化和自动调节。
最后,为了保证评估测度和回归损失之间的一致性,采用非线性变换将Dkld(Nt‖Np)转换为近似IoU 损失:
式中:f(·)表示一个非线性函数,对距离Dkld(Nt‖Np)进行变换,如f(D)=或f(D)=ln(D+1);τ是一个超参数,用来调节整体损失。
上述分析表明,基于KLD 的损失可以保证旋转框参数(x,y,w,h,θ)在训练过程中联合优化,优化一个参数,其余参数可以作为其权重动态调整,并且通过非线性变换使得该损失可以和评估测度保持一致性。相比SmoothL1 损失的参数独立优化,基于KLD 的损失理论上可以得到更高的目标检测精度。
2 实验和讨论
2.1 数据集
本文使用带有旋转目标标签的DOTA v1.0[22]和DIOR-R[23]数据集进行方法的测试和比较。DOTAv1.0 数据集的图像大小从800×800 像素到20 000×20 000 像素不等,包含各类具有各种方向、尺度和外观的目标,是迄今为止最具挑战性的旋转目标检测数据集,共包含2806 张图片,将188282个目标实例分为飞机(plane, PL)、船舶(ship)和储罐(storage tank, ST)等15类,其中训练集、验证集和测试集的比例分别为1/2、1/6 和1/3,更多有关各个类别的统计数据可以参考文献[22]。DIORR 数据集是DIOR[24]数据集的扩展,与DIOR 数据集共享相同的图像,主要用于旋转目标检测。该数据集中有 23463 张图像和192518 个实例,涵盖各类典型场景和20 个常见目标类。DIOR-R 中的目标类别包括飞机(airplane, APL)、机场(airport,APO)、棒球场(baseball field, BF)和篮球场(basketball court, BC)等。
2.2 评估标准
本文的目标检测结果主要采用精度 (precision,P)、召回率(recall,R)、平均精度均值 (mAP)、检测速度作为评价标准。精度及召回率公式如下:
式中:Tp是真正例(true positive)数量;Fp为假正例(false positive) 数量;FN为假反例 (false negative) 数量。mAP 是一种综合了准确率和召回率的评价标准:每个类别都可得到一条PR(precision-recall)曲线。计算曲线下的面积可得到该类别的平均精度AP(average precision),mAP 则为各个类别 AP 的均值,是评判目标检测网络整体性能最常用的指标之一。
2.3 实现细节
实验基于i9-10920X 处理器,使用4 个NVIDIA GeForce RTX-2080Ti GPU,内存为256 GB,利用mmrotate平台[25],以ImageNet数据集预训练好的模型进行骨干网络参数初始化。采用随机梯度下降算法(stochastic gradient descent,SGD)对模型进行训练,momentum 为0.9,权重衰减为0.0001,初始学习率为0.005,共训练12 epochs,在第8 和11 个epoch 时学习率衰减为前一阶段的1/10[26]。
对于DOTAv1.0 数据集,本文将所有训练集和验证集的原始图像以824 的步长裁剪出1 024×1024像素大小的图像块(其中为避免目标在切割图像时被分割,保留图像重叠度为200)。对于DIOR-R数据集,图像大小保持800 × 800 像素的原始大小。
训练集的图像块通过一组图像归一化、随机翻转、随机裁剪等数据增强预处理方式之后,输入到模型中用于训练。在DOTAv1.0 数据集的实验中,使用训练集对模型进行训练,使用验证集对模型进行评价。对于DIOR-R 数据集,则使用训练验证集进行训练,使用测试集对模型进行评价。
2.4 实验结果分析
表1 和表2 分别展示了HRD-ROI Transformer与典型的旋转目标检测方法在DOTAv1.0 和DIOR-R数据集上的对比。针对旋转目标检测,双阶段算法的检测精度一般会高于单阶段算法[17],因为双阶段算法能在第一阶段提取的特定候选区域的基础上进行旋转框的精细化回归,而且相比于单阶段算法,正负样本更加均衡。

表1 不同方法在DOTAv1.0 数据集上的表现对比Table 1 Performance comparison of different methods on DOTAv1.0 dataset
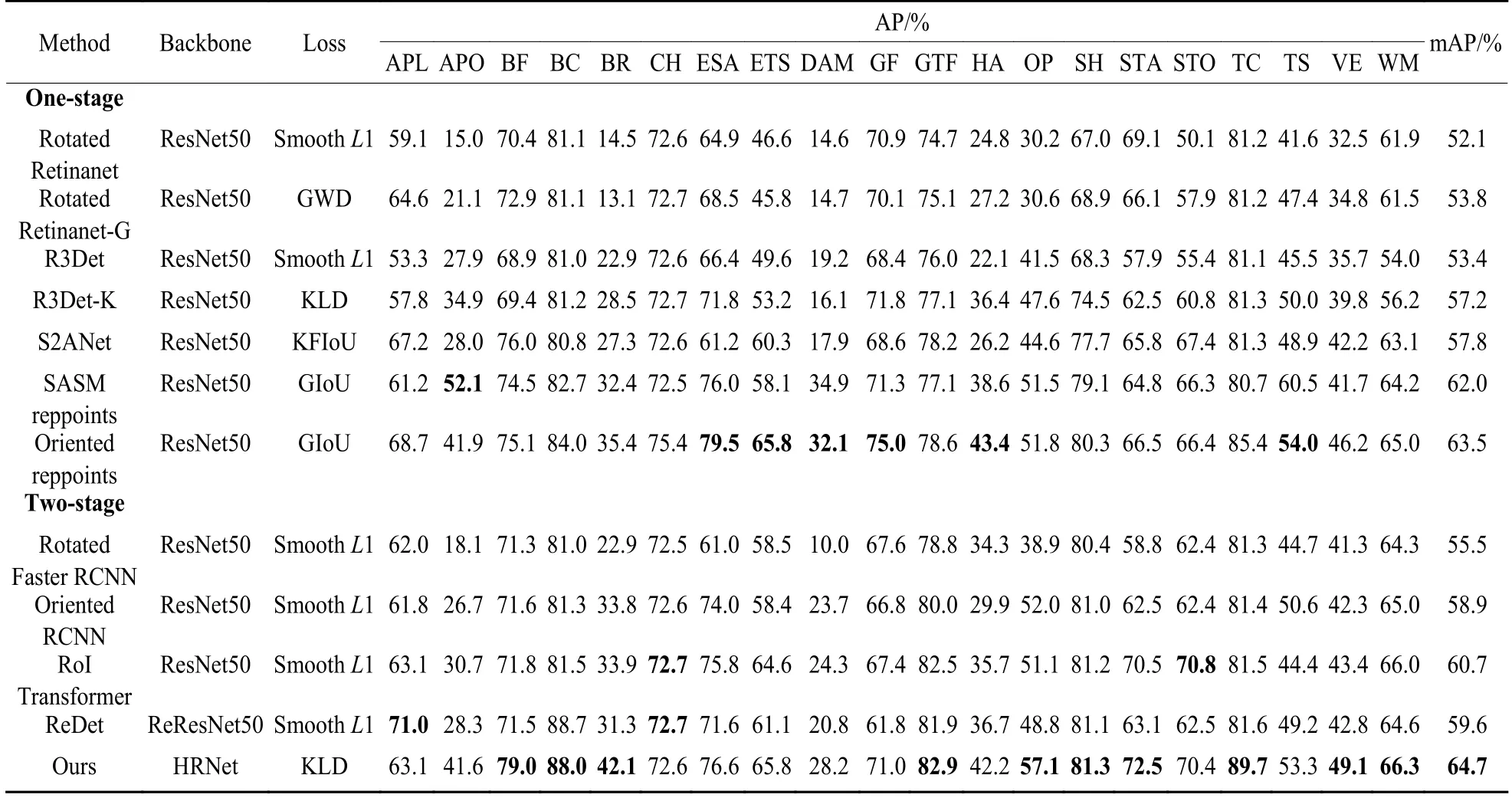
表2 不同方法在DIOR-R 数据集上的表现对比Table 2 Performance comparison of different methods on DIOR-R dataset
RoI Transformer[3]由于提取了更为精准RRoI 特征,所以达到了比Rotated Faster RCNN[19]更好的性能。如表1 所示,ReDet[7]在DOTAv1.0 数据集上的mAP 相较于RoI Transformer 提高了0.9%,它是一种基于RoI Transformer 的检测方法,可以提取旋转不变特征。本文所提方法的mAP 达到了72.5%,相较于RoI Transformer 提高了3.7%,相较于ReDet提高了2.8%。
本文用DIOR-R 数据集评估HRD-ROI Transformer 模型的适应性。根据DIOR-R 数据集的特性,将用于DOTAv1.0 数据集模型的的输入图像大小调整为800 × 800 像素,检测目标类别调整为20,并使用DIOR-R 数据集重新训练和测试模型。结果如表2 所示,本文方法仍然是所有双阶段算法中性能最好的,mAP 达到了64.7%,比RoI Transformer 高4%,比ReDet 高5.1%。SASM reppoints[12]和Oriented reppoints[13]也在DIOR-R 数据集上取得了较好的检测效果,但mAP 仍分别比我们的模型低2.7%和1.2%。
尽管ReDet 采用ReResNet 提取旋转不变特征,但它的高分辨率特征语义信息很弱,对于小目标的检测效果不佳。而本文方法中使用的HRNet 保持了高分辨率表示,保持强语义信息的同时,提高了网络对各种尺度目标的鲁棒性。如表3 所示,DIOR-R数据集中的船舶(SH)、车辆(VE)、风车(WM)和DOTAv1.0 数据集中的小型车辆(SV)、船舶(SH)是典型的小目标,本文方法的检测结果均优于ReDet。
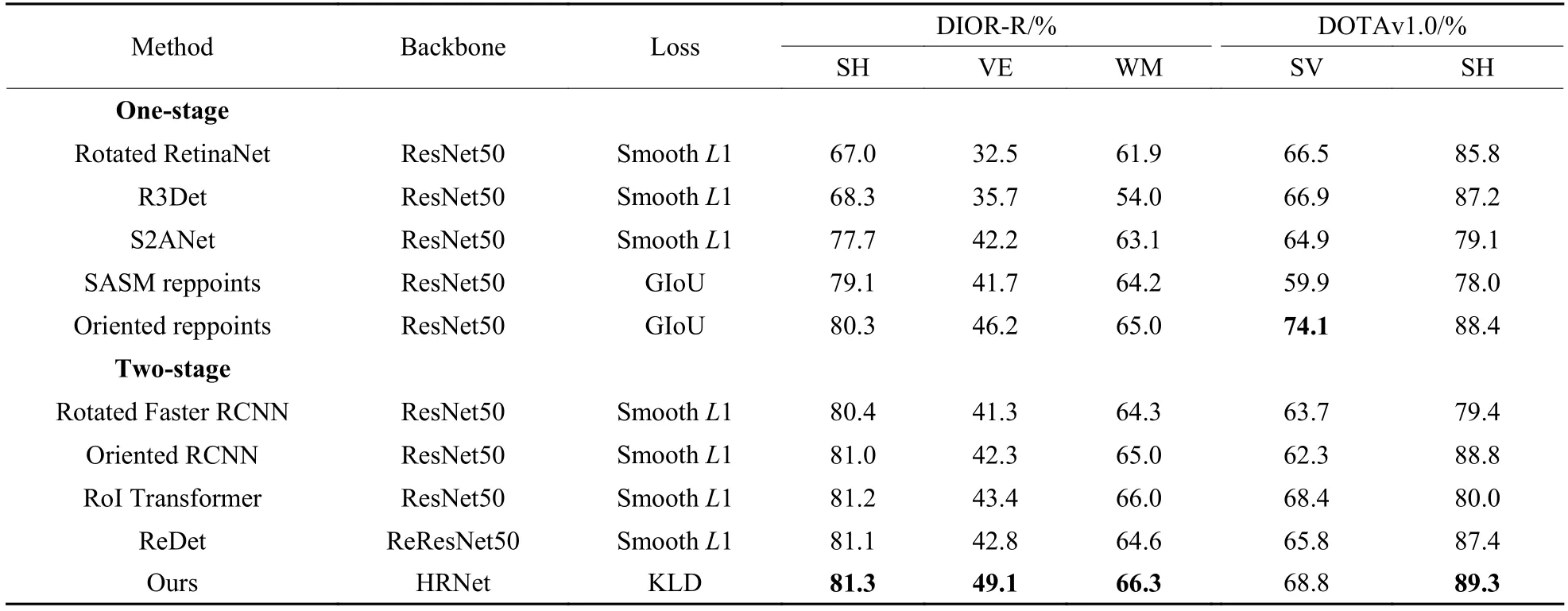
表3 DOTAv1.0 和DIOR-R 数据集的小目标检测效果Table 3 Detection effects of small object on DOTAv1.0 and DIOR-R datasets
图6(来自DIOR-R 数据集)和图7(来自DOTAv1.0数据集) 主要展示了双阶段检测方法在典型场景旋转目标检测的结果。图6 第1 列是Rotated Faster RCNN 的检测结果,第2 列是Oriented RCNN 的检测结果,第3 列是RoI Transformer 的检测结果,第4 列是ReDet 的检测结果,第5 列是本文方法的结果。图6 第1 行的机场区域检测结果中,前4 列的方法各有不同程度的误检,Rotated Faster RCNN 将航站楼误检为立交桥,将飞机误检为风车;Oriented RCNN[6]、RoI Transformer 和ReDet 均将飞机误检为风车。本文方法没有出现这种误检,是因为HRNet提取了尺度适应性更强的特征,能很好地分辨风车和飞机,而且对于第1 行图中航站楼、第2 行中的桥梁这两种大长宽比的目标,KLD 损失规避了角度周期性带来的问题,提升了检测性能。图7展示了不同检测方法的漏检情况,可以看到,KLD 损失对于港口、大型车辆这类大长宽比目标效果良好。

图6 检测结果对比(误检)Fig.6 Comparison of detection results (false detection)

图7 检测结果对比(漏检)Fig.7 Comparison of detection results (missed detection)
此外,RoI Transformer 对于大长宽比的目标定位不够精准。如图8 所示,大坝是典型的大长宽比的目标,可以清楚地看到,本文方法在检测精度方面明显优于其他4 种方法。这证明KLD 损失的参数联合优化是有效的,在检测大长宽比目标时表现出良好的性能,这在消融实验中将进一步讨论。

图8 检测结果对比(大长宽比目标)Fig.8 Comparison of detection results (objects of large aspect ratios)
2.5 消融实验
本文利用消融实验分别测试KLD 损失函数和HRNet 对模型性能的影响,并对比了GWD、KLD 和KFIoU 3 种用于旋转目标检测的损失函数的性能。
模型(a)是RoI Transformer 框架中仅以KLD 损失函数替换Smooth L1 损失函数,模型(b)是RoI Transformer 框架融合HRNet 特征提取网络,模型(c)即为本文提出的HRD-ROI Transformer 方法。表4 和表5 展示了消融实验的结果。
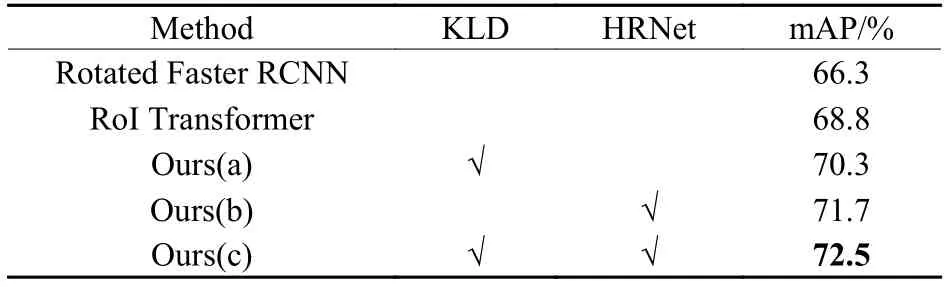
表4 KLD 和HRNet 在DOTAv1.0 上的有效性对比Table 4 Comparison of effectiveness of KLD and HRNet on DOTAv1.0 dataset
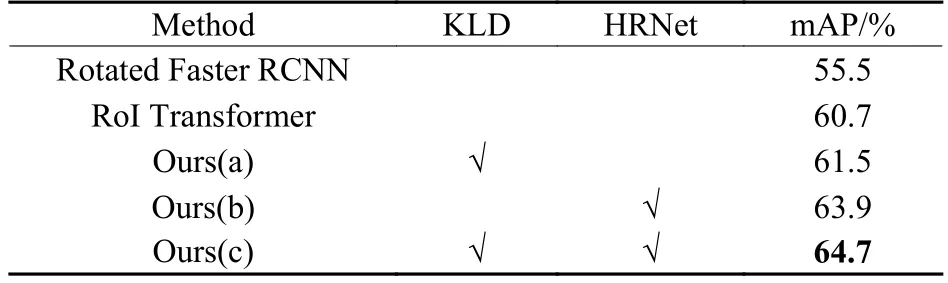
表5 KLD 和HRNet 在DIOR-R 上的有效性对比Table 5 Comparison of effectiveness of KLD and HRNet on DIOR-R dataset
在DOTAv1.0 数据集上,RoI Transformer 的mAP达到68.8%,而仅使用KLD 损失的模型(a)达到了70.3%,仅使用HRNet 的模型(b)达到了71.7%,相比于RoI Transformer 分别提升了1.5%和2.9%。这表明这两个部分对于最终的检测结果都有贡献。结合KLD 损失和HRNet 的模型(c)的mAP 进一步达到了72.5%。上述结果充分验证了基于KLD 损失和HRNet 的有效性。模型(a)、(b)和(c)在DIOR-R数据集上的mAP 分别比原始RoI Transformer 高0.8%、3.2%和4%,也验证了本文模型的适应性。
模型(a)和RoI Transformer 的检测结果对比如图9 所示,其中第1 行是RoI Transformer 的检测结果,第2 行是模型(a)的检测结果。港口、立交桥和桥梁是DIOR-R 数据集中典型的大长宽比目标。造成检测精度不高的主要原因之一就是目标回归的中心定位不准,与RoI Transformer 相比,模型(a)对目标的定位更加准确。

图9 KLD 在DIOR-R 上的有效性Fig.9 Effectiveness of KLD on DIOR-R dataset
GWD、KLD 和KFIoU 3 种损失函数的性能对比如表6 所示。以RoI Transformer 为基础框架,采用GWD、KLD 和KFIoU 3 种损失函数分别训练模型,得到不同模型的mAP。可以看到,不管是在DOTAv1.0 还是在DIOR-R 数据集上,KLD 损失的mAP 都明显高于KFIoU 损失。虽然在DIOR-R 数据集上,KLD 损失的mAP 仅比GWD 损失高0.1%,但是综合所有模型来看,KLD 损失仍旧是三者中性能最优的损失函数。
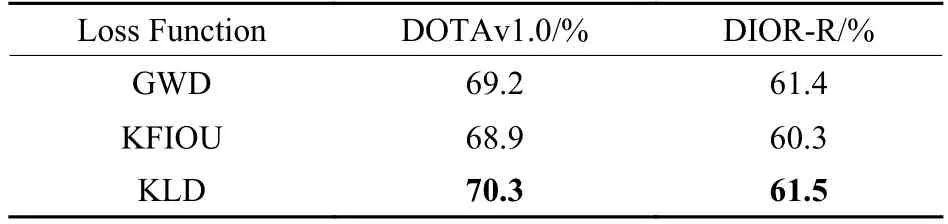
表6 3 种损失函数模型的mAP 比较Table 6 Comparison of mAP for three loss function models
2.6 HRD-ROI Transformer 误检样本分析
表2 所示的DIOR-R 数据集的检测结果中,机场(APO)和高尔夫球场(GF)的检测效果欠佳,其真值(ground truth)和检测结果的对比如图10 和图11 所示。
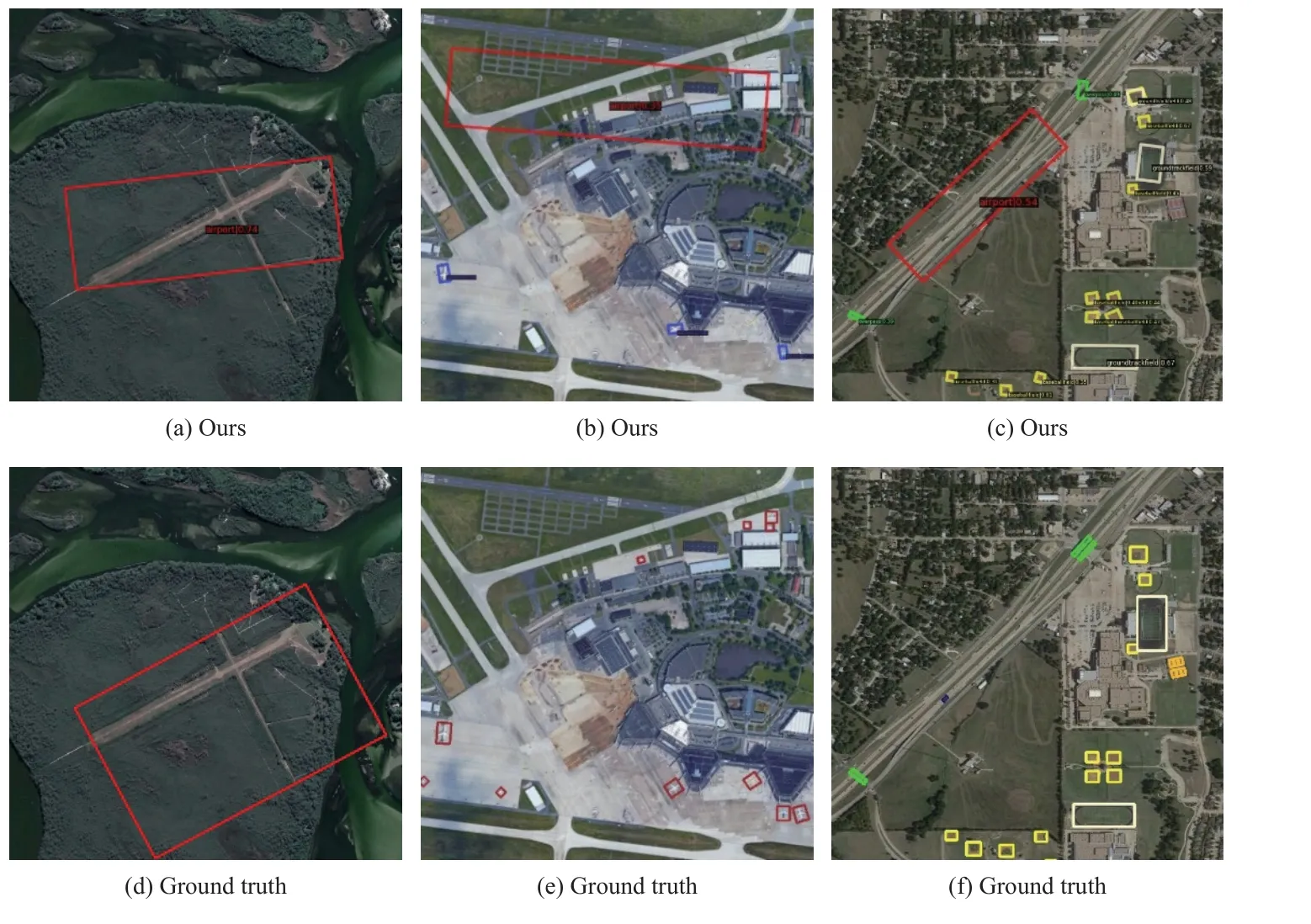
图10 机场检测结果Fig.10 Detection results of airport
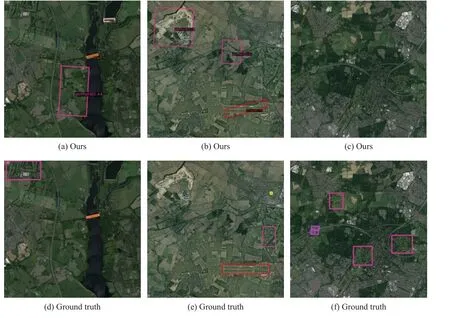
图11 高尔夫球场检测结果Fig.11 Detection results of golf course
图10 中第1 行的红色框表示本文方法检测出的机场区域,第2 行红色框表示机场区域的真值,可以看到,第1 列两张对比图中,检测的机场的定位不精准;第2 列两张对比图中,检测到了真值没有标注的机场区域;第3 列两张对比图中,将道路误检为了机场。机场的典型特征一般是跑道,其形状容易和道路混淆,且机场的边界特征不清晰,会导致回归的旋转框不准确。
图11 中第1 行的玫红色框表示本文方法检测出的高尔夫球场,第2 行玫红色框表示高尔夫球场的真值。图11 中第1 列和第2 列的两张对比图的农田均被误检为高尔夫球场,且均有高尔夫球场被漏检;第3 列两张对比图中,3 个高尔夫球场均被漏检。当图像分辨率较低时,高尔夫球场的纹理特征急剧变弱,与农田等绿色植被相似度过高,检测过程中很容易混淆。
3 结论
本文提出了一种基于RoI Transformer 的遥感图像多尺度旋转目标检测方法HRD-ROI Transformer,该方法采用HRNet 作为骨干网络,提高了模型对目标尺度变化的适应性,在小目标检测效果上优于现有典型旋转目标检测方法;此外,本文所提方法引入KLD 损失,可对旋转边界框参数进行联合优化,提高了模型对旋转目标,特别是大长宽比旋转目标的检测精度。在两个公共数据集的的比较试验证明了HRD-ROI Transformer 可以适应目标尺度变化,并解决了角度周期性问题,在旋转目标的检测精度方面优于当前主流的方法。
本文方法对DIOR-R 数据集中的机场(APO)和高尔夫球场(GF)检测效果欠佳,后续将根据这类目标的特性做数据增强,并将SAM(segmenting anything model)嵌入检测模型中[27],以SAM 分割的高细粒度结果指导目标检测中低细粒度的边界框的生成,提升模型对这类目标的检测能力。针对小目标的检测问题,本文方法的检测精度有所提升,后续还可以通过引入特征层注意力机制[28],增强模型对小目标的关注,或者采用优化的低耦合网 络(optimized low coupling network, OLCN)[29]避免小目标的丢失。此外,使用的HRNet 包含多个特征融合,可能会造成较大的训练存储成本,因此,网络轻量化也将是未来重要的研究方向。
