基于生物电阻抗矢量分析的维持性血液透析患者贫血和营养状况的评估方法研究
2023-09-21张志坚陈涵枝周乐汀刘晓斌单炜薇
张志坚, 陈涵枝, 李 程, 周乐汀, 刘晓斌, 单炜薇, 刘 斌, 王 凉
(南京医科大学无锡医学中心/南京医科大学附属无锡人民医院 肾内科, 江苏 无锡, 214000)
终末期肾病(ESRD)是慢性肾脏病(CKD)的终末阶段,属于世界范围内的重大公共卫生问题之一[1-2]。维持性血液透析(MHD)是ESRD患者最常用的治疗手段,可极大改善预后与生活质量,然而患者仍会面临众多并发症的威胁,如贫血、营养不良、高磷血症、低钙血症和心脑血管意外等[3-4]。贫血和营养不良在MHD患者中相当普遍且与死亡风险升高相关,早期识别并干预可有效改善预后[5]。目前,生物电阻抗分析(BIA)因具有无创、简单、客观且快速等优点,已被广泛用于评估MHD患者的容量情况和营养状态[6-7]。受人体化学成分和物理成分的影响,生物电阻抗可能与血清生化成分和营养状况相关,但生物电阻抗矢量分析(BIVA)在评估MHD患者血清生化指标(尤其是贫血和营养状况指标)中的作用目前尚不明确。白蛋白(Alb)、总胆固醇(TC)、低密度脂蛋白胆固醇(LDL-C)、血红蛋白(Hb)是反映MHD患者贫血与营养状况的重要指标。本研究基于BIVA法分析人体成分分析仪(BCM)采集的MHD患者生物电信号数据,建立基于不同机器学习算法的预测模型,以期为MHD患者贫血和营养状况的评估提供辅助性依据。
1 资料与方法
1.1 一般资料
本研究共纳入1 925例尿毒症患者,年龄19~85岁,女758例(平均年龄60.3岁),男1 167例(平均年龄59.5岁)。排除标准: 测量前1个月内发生过急性心脑血管事件、严重感染者,肝功能异常、肺功能不全、原发性甲状腺疾病患者,恶性肿瘤或精神疾病患者。收集患者生物电阻抗数据3 742个和血生化指标数据109 234个,后者包括Alb(45 300个)、TC(14 765个)、LDL-C(9 047个)和Hb(40 122个),所有数据于2016年5月—2022年7月获得。
患者的一般资料于每次阻抗测量前收集,身高H(m)和体质量W(kg)根据国际标准测量,体质量指数(BMI)计算公式为W/H2。于每周第1次透析前为患者采血,使用自动化学分析仪(Beckman Coulter AU5800型号)和自动血液分析仪(Sysmex XN-9000型号)检测血生化指标水平。使用多频阻抗分析仪(Fresenius, 上海)在50个频率上测量阻抗矢量Z(Ω)和相位角φ(度),并导出对应的细胞内电阻Ri(Ω)、细胞内电阻率ρi(Ω/m)、细胞外电阻Re(Ω)、细胞外电阻率ρe(Ω/m)、细胞膜电容Cm(F)、细胞膜介电常数ε(F/m)等,共计106个变量。血生化指标分类标准: ① Hb, <110.0 g/L为低, 110.0~130.0 g/L为正常, >130.0 g/L为高; ② TC, <3.0 mmol/L为低, 3.0~5.7 mmol/L为正常, >5.7 mmol/L为高; ③ LDL-C, <1.6 mmol/L为低, 1.6~3.4 mmol/L为正常, >3.4 mmol/L为高; ④ Alb, <35.0 g/L为低, 35.0~55.0 g/L为正常, >55.0 g/L为高。
本研究通过主成分分析(PCA)对原始106个生物电学指标变量和年龄、身高、体质量进行分析,并通过各主要成分的贡献率以及方差值实现对原始变量的降维,消除变量冗余特征。选取前8个贡献率最高的特征作为模型的输入特征。随机选择80%的生化-生物电记录作为训练集,其余记录则作为测试集。
1.2 个体相关性分析
对主要生物电学指标测量值与生化指标测量值进行个体相关性分析,考虑到数据在个体内被多次测量,本研究采用重复测量相关性分析来确定记录的共同个体内关联。与简单回归相关性分析不同,重复测量相关性分析不违反观察独立性假设,且具有更强大的统计能力[8]。
具体流程如下: ① 在主要生物电学指标(Ri、ρi、Re、ρe、Cm、ε)测量值和生化指标(Alb、TC、LDL-C、Hb)测量值间进行线性回归分析,得到斜率值和残差自由度值。根据斜率值的正负来判断生物电学指标测量值与生化指标测量值的相关系数方向。② 将每种生物电学指标变量从模型中删除后进行线性回归分析,并分别计算删除每个变量后的残差平方和。③ 根据残差平方和的比较结果,计算出删除每个变量对应的统计量F值,得出生物电学指标测量值与生化指标测量值的相关系数的P值。
1.3 基于随机森林算法建立评估模型
随机森林模型通过集成学习Bagging的思想将不同参数的树模型进行集成,并将CART决策树作为弱学习器。由于随机森林模型在分类领域中应用广泛,本研究基于CART分类树评估MHD患者的营养生化指标(Alb、TC、LDL-C、Hb)。算法过程: ① 用N表示训练数据集个数,用M表示特征数目,即生物电学指标8维PCA值。② 输入特征数目m, 用于确定决策树上一个节点的决策结果,其中m应远小于M。③ 从N个训练数据集中以有放回抽样的方式取样N次,形成一个训练集(即bootstrap取样),并用未抽到的用例(样本)作预测,评估其误差。④ 对于每一个节点,随机选择m个特征,决策树上每个节点的决定都基于这些特征确定。根据这m个特征,计算其最佳分裂方式。⑤ 每棵树都会完整成长而不会剪枝,这有可能在建完一棵正常树状分类器后会被采用。⑥ 对于最后的分支节点,采用投票算法得到每个样本的类别信息。
1.4 基于Adaboost算法建立评估模型
Adaboost算法是针对同一个训练集训练不同的弱分类器,然后将这些弱分类器集合起来,构成一个强分类器。本研究采用CART决策树作为弱分类器,用于MHD患者的营养生化指标(Alb、TC、LDL-C、Hb)评估。算法过程: ① 用N表示训练数据集个数,先通过对N个训练样本的学习得到CART决策树作为第1个弱分类器; ② 将被弱分类器分错的样本和其他新数据一起构成一个新的N个的训练样本,通过对这个样本的CART决策树学习得到第2个弱分类器; ③ 将弱分类器1和弱分类器2都分错了的样本加上其他新样本构成另一个新的N个的训练样本,通过对这个样本的CART决策树学习得到第3个弱分类器; ④ 为几个弱分类器指定权值,得到最终经过提升的强分类器,某个数据被分为哪一类由各分类器权值决定。
1.5 基于支持向量机(SVM)算法建立评估模型
SVM的基本思想是构造一个超平面将训练数据分开,并且使分隔面与每一类数据点间的距离最大化,即“支持向量”。假设有M个训练数据点(x1,y1), (x2,y2),…, (xm,ym), 其中xi是特征向量,每个数据点包含由多频阻抗分析仪中导出的110个生物电学指标变量计算得到的2维PCA值;yi是标记(yi∈{-1, +1}), 每个数据点包含血生化指标的含量分类值(“低”或“正常”或“高”)。因此,支持向量机的问题就是求解超平面w·x+b=0, 使得∀i∈{1,2,…,m},yi=(w·xi+b)≥1, 同时使得‖w‖最小化。求解SVM问题的方法是对‖w‖2/2求解拉格朗日乘数,并对乘数进行求解,最终得到w和b。当分类问题存在非线性可分情况时,可以通过在特征空间内使用核函数(如多项式核、高斯核等)构造高维特征,从而解决非线性可分情况。主要步骤: ① 使用核函数将低维的生物电学指标2维PCA值输入空间映射到高维的特征空间。② 通过上述优化算法,针对血生化指标含量分类值求解出最优的分离超平面,得到w和b。③ 对于新的生物电学指标输入数据,使用已经得到的最优分离超平面对其对应血生化指标进行预测,即可将其分配到相应类别。
1.6 模型效能评估
通过常见的评估指标,如准确率、召回率和F1值等,评估并比较基于随机森林算法模型、基于Adaboost算法模型和基于SVM算法模型的性能。
2 结 果
2.1 个体相关性分析结果
对主要生物电学指标(Ri、ρi、Re、ρe、Cm、ε)测量值与主要营养指标(血生化指标Alb、TC、LDL-C、Hb)测量值间进行个体相关性分析,结果显示,生物电学指标与营养指标显著相关(P<0.05或P<0.01), 提示生物电学指标可用于评估MHD患者相关血生化指标,见表1(男性)、表2(女性)。

表1 男性患者主要生物电学指标与主要营养指标的个体相关性分析结果

表2 女性患者主要生物电学指标与主要营养指标的个体相关性分析结果
2.2 模型效能评估与比较结果
经过优化调参,基于SVM、Adaboost和随机森林算法的各模型参数见表3。基于不同算法的3个模型对Alb、TC、LDL-C、Hb进行分类的结果见表4~表7。总体而言,基于随机森林算法的模型表现最佳,表明其在相关指标预测方面具有较强的鲁棒性(Hb: F1值0.808、召回率0.773、准确率0.904; Alb: F1值0.844、召回率0.827、准确率0.880; LDL-C: F1值0.775、召回率0.710、准确率0.879; TC: F1值0.742、召回率0.664、准确率0.937)。此外,无论男女,基于随机森林算法的模型均表现出较好的分类准确性,相关结果明显优于基于AdaBoost算法的模型和基于SVM算法的模型。

表3 基于支持向量机、Adaboost和随机森林算法的各模型参数
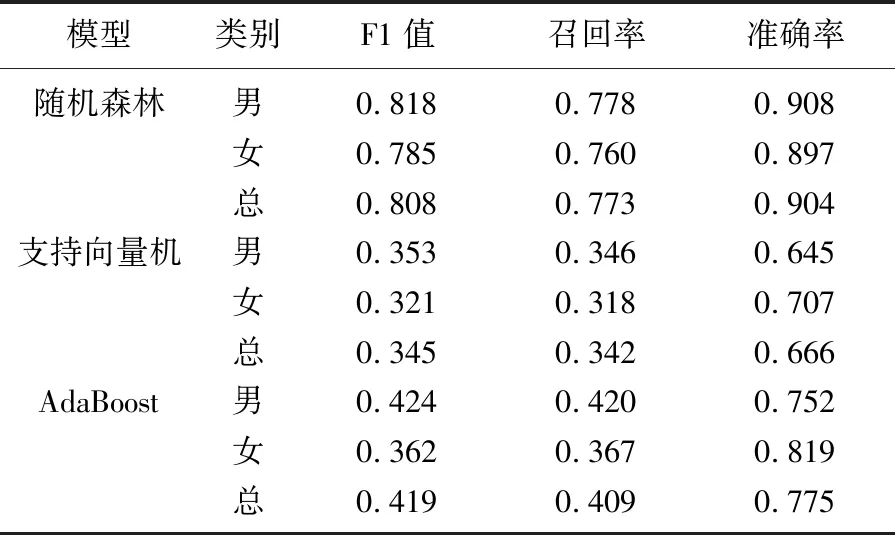
表4 基于不同算法的3种模型对血红蛋白的分类结果

表5 基于不同算法的3种模型对白蛋白的分类结果

表6 基于不同算法的3种模型对低密度脂蛋白胆固醇的分类结果

表7 基于不同算法的3种模型对总胆固醇的分类结果
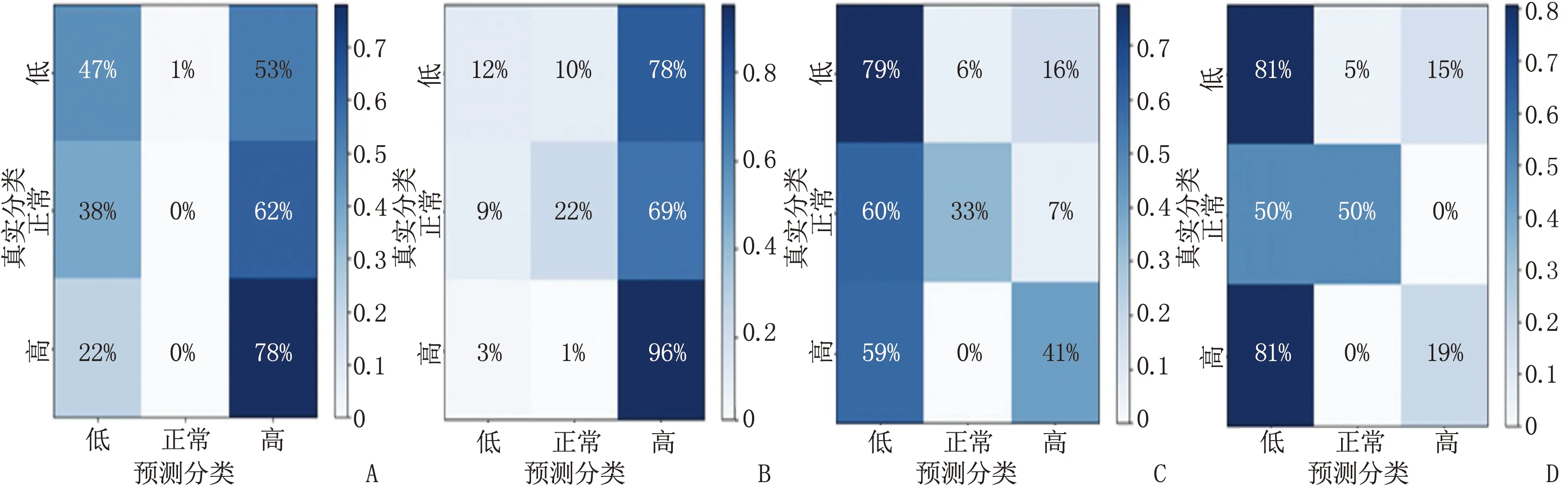
基于随机森林、Adaboost、SVM算法的3种模型对4个血生化指标变量(Alb、TC、LDL-C、Hb)预测性能的混淆矩阵见图1~图3, 结果显示,基于随机森林算法的模型在对角线上的预测值最高,说明该模型对Alb、TC、LDL-C、Hb这4个变量的预测性能最佳。

A: 白蛋白; B: 血红蛋白; C: 低密度脂蛋白胆固醇; D: 总胆固醇。
A: 白蛋白; B: 血红蛋白; C: 低密度脂蛋白胆固醇; D: 总胆固醇。
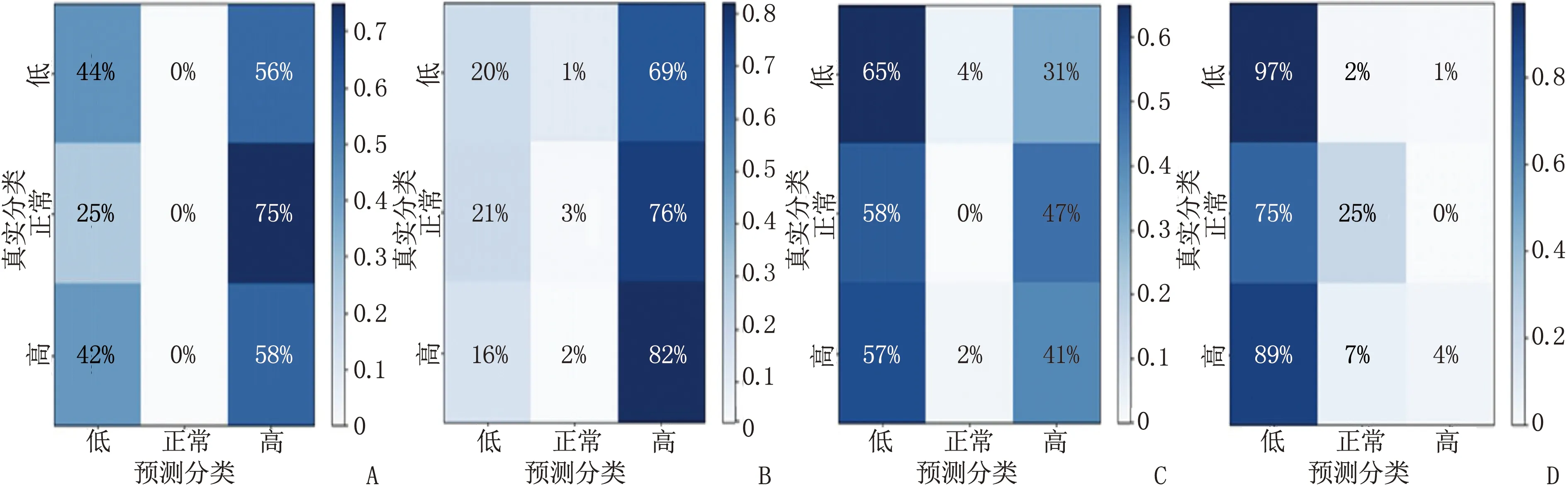
A: 白蛋白; B: 血红蛋白; C: 低密度脂蛋白胆固醇; D: 总胆固醇。
3 讨 论
近年来,ESRD的发病率逐年上升,己成为世界范围内影响人类健康的常见疾病。MHD患者常合并不同程度的贫血、营养不良,与其生活质量下降和死亡风险升高密切相关[9-12], 早期识别贫血和营养不良具有重要的临床意义。然而, MHD患者往往难以接受频繁的有创检验,故亟需探寻可无创且快速评估贫血与营养状况的方法。生物电阻抗是人体电特性的一种度量指标,由电阻和电抗变量组成,其中电阻主要与体内导电物质的浓度有关,尤其是水和电解质,电抗则主要与人体内细胞膜脂质双分子层两侧的电容性质有关[13-15]。MULASI U等[16]通过评估临床人群的肌肉组织,发现了BIA在评估营养状况方面的准确性和其他优势。BIVA可以克服传统BIA受身高和体质量个体差异影响的缺点[17]。ONOFRIESCU M等[18]基于131例MHD患者的随机对照试验发现了BIVA在血液透析液体管理中的价值; 赵新菊等[19]通过BIVA评价血液透析患者的干体质量,证实其可作为估计干体质量的敏感辅助工具。生物电阻抗数据目前已被广泛应用于MHD患者容量负荷的评估中,但其在贫血和营养不良诊断中的作用仍有待进一步研究。本研究基于MHD患者资料分析BIVA与重要血生化指标的关联,并开发基于BIVA的机器学习算法模型,以期为扩展生物电阻抗的临床应用范围提供理论基础。
由于MHD患者的水含量经常变化,传统的营养评估方法无法准确评估其营养状况。本研究发现, BIVA指标与Alb、TC、LDL-C、Hb等指标均存在显著关联,表明BIVA指标可在一定程度上反映患者贫血及营养状况,与既往研究[18]结论相符,这为建立基于BIVA及机器学习算法的预测模型奠定了理论依据。本研究结果表明,通过BIVA对MHD患者进行定期监测和随访,有助于临床医生及时了解MHD患者的体液、贫血、营养状态,从而有针对性地指导治疗。借助基于随机森林算法的预测模型,临床医师可通过常规生物电测量初步评估相关生化指标情况,实现早期预警和早期干预,这对提高MHD患者生活质量、节约医疗资源具有重要意义。但本研究亦存在一些局限性: 营养不良、贫血和生存质量也可能与患者年龄和原发病有关,并会对统计学结果产生一定影响,未来应基于性别、年龄和健康状况进行分层研究; 本研究为横断面研究,无远期随访观察结果,未来应进一步深入研究。
综上所述,本研究基于MHD患者常规随访的BIVA数据和3种机器学习算法(随机森林、SVM和Adaboost算法),建立了针对Alb、TC、LDL-C、Hb这4个血生化指标的3个预测模型。3个预测模型中,基于随机森林算法的模型表现最优(预测Alb、LDL-C、Hb、TC的准确率分别为0.880、0.879、0.904、0.937), 可为MHD患者贫血和营养状态的无创评估提供辅助决策意见。
