基于ChatGPT语言模型的虚拟数字人语音交互应用
2023-09-19严通
严 通
(南宁师范大学 美术与设计学院,广西 南宁 530100)
0 引 言
虚拟数字人的诞生,最早可追溯至2016年12月1日,日本虚拟主播“绊爱”在YouTube的“A.I”频道发布了第一个视频。直至2018年2月23日,该频道订阅人数达到了100万。由“绊爱”等虚拟主播带头,虚拟主播行业迎来了快速发展的时代[1]。尽管虚拟数字人具有巨大潜力,但现有的虚拟数字人交互应用仍存在一些限制,比如互动简单、内容单一及实时性不足等技术问题。为了提高虚拟数字人的交互效果和用户体验,本文立足于当前研究现状,旨在进一步研究和改进语音交互技术。本文采用虚幻引擎作为虚拟数字人交互的开发平台,通过设计和实施基于ChatGPT语言模型的实时语音交互程序来解决实时性语音交互应用问题,进而实现更自然、流畅和智能的交互体验。这种交互形式基于ChatGPT语言模型,将虚拟数字人与现实世界连接,能够为用户提供丰富多样且自然的对话体验。
1 ChatGPT语言模型的原理及虚拟数字人语音交互现状
1.1 ChatGPT语言模型原理
ChatGPT (Chat Generative Pre-Training Transformer)是由OpenAI实验室开发的大语言模型(Large Language Model,LLM)。在其之前,OpenAI基于Transformer开发了一系列LLM,包括GPT、GPT-2、GPT-3以及GPT-3.5[2]。在GPT-3.5的基础上,OpenAI实验室加入优化后的预训练、生成对抗技术以及基于人工反馈的强化学习技术。Transformer架构在处理自然语言序列数据时表现出色,通过使用自注意力机制,有效地提高了对上下文的理解能力。模型需要经过大量预训练,以学习语言结构、语法规则和从文本中提取信息的技巧。作为一种生成型语言模型,GPT能根据给定的上下文,使用概率生成预测文本串。为了使模型在特定任务上更加精确,微调是必要的,它可以提高模型在某些领域的专业知识。此外,可以通过调整温度参数来影响模型生成文本的随机性,从而在创造力和保守性之间取得恰当的平衡。
1.2 虚拟数字人语音交互现状
虚拟数字人的思想起源于赛博格(Cyborg)。1985年,哈拉维在其赛博格宣言中将赛博格定义为无机物机器与生物体的结合体,如安装了假牙、假肢、心脏起搏器等的身体。这些身体模糊了人类与动物、有机体与机器、物质与非物质的界限[3]。虚拟数字人的语音交互涵盖了许多技术和组件,使得人类可以与虚拟角色或数字人进行自然、流畅的语音交流。语音交互的主要元素包括自然语言处理(Natural Language Processing,NLP)、自动语音识别(Automatic Speech Recognition,ASR)和语音合成(Text to Speech,TTS)等多种交互技术。
在多样化的交流形式中,人机语音交互将极大地便利人们的日常生活和工作。随着技术的不断进步,虚拟数字人在这个阶段实现了更高程度的真实感。但是,以简单的二维动画或三维模型出现的虚拟数字人还不是十分智能化,只能将提前设计的内容进行循环播报,没有任何的互动和交流,其主要原因如下。
(1)在没有像ChatGPT这样的预训练语言模型的情况下,虚拟数字人将无法有效地根据用户给出的内容进行智能处理和回应。若只依赖于触发关键词的方式,很难满足用户对于真实、自然对话的需求。
(2)传统三维数字人往往无法实现实时表情动画驱动,这导致语音与嘴型的不匹配现象,进而使得声音表现与面部表情难以协调一致,从而降低了人物的真实效果和沉浸感。
(3)虚拟数字人在文本输入的模式下使用范围相对较窄,受限于操作台。若采用语音输入方式,用户可以摆脱操作界面的限制,在较广泛的范围内与虚拟数字人展开便捷、自然的交流互动。
2 ChatGPT语言模型在虚幻引擎中的语音交互设计与实现
2.1 虚幻引擎语音交互技术
虚幻引擎5(Unreal Engine 5),是由Epic Games公司开发的一款游戏引擎,以其优越的性能在游戏和影视行业中越发受欢迎。虚幻引擎提供了一套全面且易于使用的工具和技术,涵盖图形渲染高峰、精密的物理模拟、强大的人工智能能力、高品质音频支持、稳定的网络编程框架和高度可定制的游戏逻辑编辑器。
基于虚幻引擎的语音交互技术,指的是将现代先进的语音识别、语音合成和自然语言处理技术融入虚幻引擎,创建契合时代需求的用户交互体验。这一技术实现的核心方式主要有集成第三方库和开发自定义插件两种。通过这两种方式,虚幻引擎可以无缝地识别用户的语音输入,并针对输入内容做出相应的响应,最终呈现给用户一种高度互动与沉浸式的语音交流体验。这种结合虚幻引擎和语音交互技术的应用可以广泛用于各类场景,如游戏开发、虚拟现实、影视制作等,赋予角色更富有生命力的对话和反馈,从而显著提高用户的参与度和沉浸感。同时,基于虚幻引擎的语音交互技术也为行业创新带来了巨大的潜力,通过打破界限、拓展创意、提升体验,引领未来教育、商业、娱乐等多个领域的发展方向。
2.2 虚拟数字人语音交互在虚幻引擎中的程序设计
虚拟数字人语音交互应用程序使用虚幻引擎并整合了ChatGPT作为核心组件,以提供高质量的自然语言处理能力。通过将多个功能模块和技术相结合,本文创建了一个实现高效、自然语音交互的应用程序。其中包含以下几个关键环节,如图1所示,以下将以步骤形式详细说明实现过程。
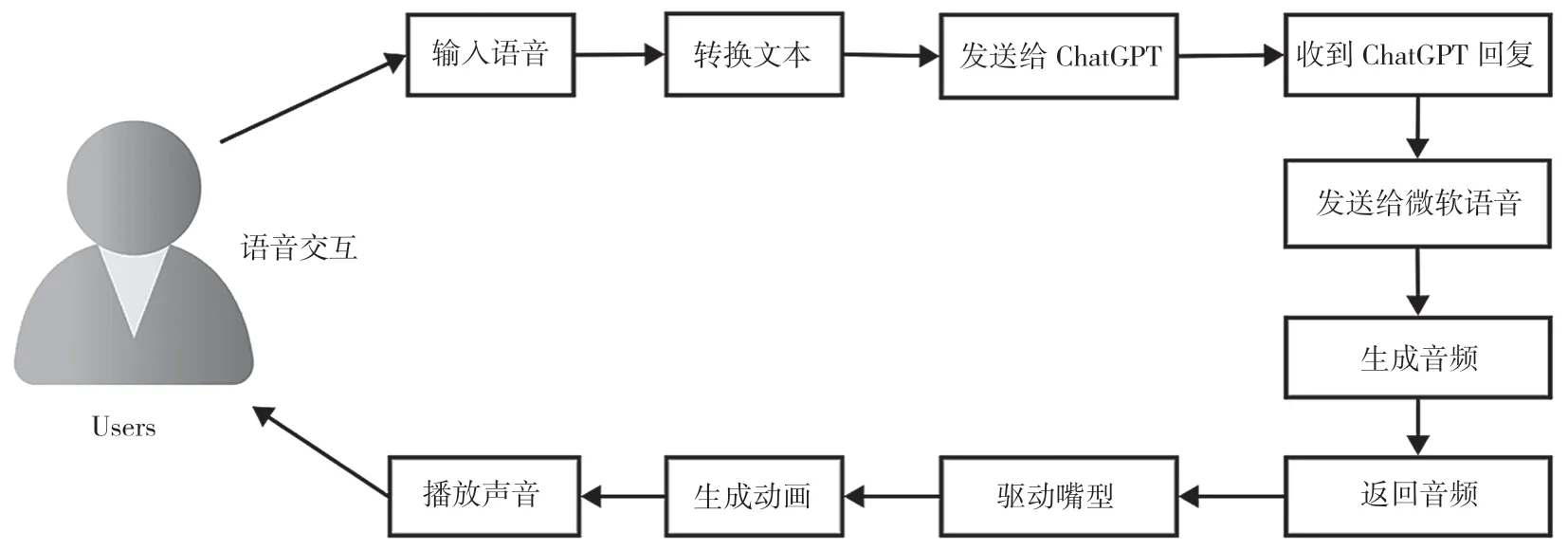
图1 设计流程图
(1)输入设备监听。应用程序设计的第一步是获取用户录音设备(如麦克风)的输入。在虚幻引擎中,可以利用内置的声音输入模块或引入外部第三方插件来实现此功能。模块在UI界面启动时、用户发出声音时自动激活,捕捉到音频数据并进行下一步处理。
(2)语音识别。语音识别是实现虚拟数字人语音交互应用程序的关键环节之一。应用程序接收到用户的语音输入后,需要将音频数据转换为可供chatGPT理解的文本数据。为实现这一目的,可以调用语音识别服务,通过云服务方式实现。
(3)与ChatGPT交互。将用户的语音成功转换为文本后,需要将这些数据发送给ChatGPT模型以生成相应文本回应。借助OpenAI提供的应用程序编程接口(Application Programming Interface,API),可以方便地实现与ChatGPT的通信。在虚幻引擎中,可以使用Set Open AiApi Key蓝图系统编写网络请求和数据处理功能。
(4)文本转语音。当应用收到ChatGPT所生成的文本回应时,需要将这些文字转换为实际的语音输出。这一步骤可借助文本转语音(TTS)引擎实现,其中,微软的TTS是一种可选方案。处理生成的音频数据后,需要将其转换为虚拟引擎支持的格式,以便应用程序调用。
(5)驱动虚拟数字人动画。成功获取音频数据后,需要将声音与虚拟数字人的面部动画融合,以产生协调一致的效果。根据音频信号,应用程序可自动生成虚拟数字人的嘴型、表情等动画效果,使模型更具真实感。
(6)动画与声音同步播放。为提供紧密协调的用户体验,需要同步播放声音和对应的嘴型动画。虚幻引擎提供了MetahumanSDKATL插件和动画蓝图(Animation Blueprints)这两个模块,可用于实现声音和动画的同步播放。
通过上述描述,在虚幻引擎中实现虚拟数字人语音交互应用,涉及多个重要环节和相关技术。这些关键模块需要高度协同,确保应用程序连接无缝、运行效果极佳。本文从输入设备的监听、音频数据传输到生成回应,再到最后的动画和声音相互搭配,打造出一款自然、引人入胜的数字人语音交互系统。
2.3 虚拟数字人语音交互在虚幻引擎中的实现方法
虚拟数字人语音交互在虚幻引擎中的实现,是将前面阶段中的程序设计转化为可执行的蓝图和配置。实现过程中需要用到多个技术模块和数字资源。以下是更详细的步骤。
准备虚拟数字人模型。需要一个3D模型来作为虚拟数字人的形象,确保模型包含面部动画(如骨骼、混合形),以支持语音同步产生的嘴型动画。将3D模型导入虚幻引擎项目中,设置骨骼与模型的绑定,使用虚拟数字人来设置起始场景。使用相应的动画蓝图,确保虚拟数字人能完成所需的基本动作,如图2所示。

图2 虚拟数字人模型绑定
配置用户麦克风输入,实现语音识别。通过第三方插件AzSpeech-Voice and Text插件来实时获取用户的麦克风输入数据。将插件模块添加到蓝图,添加Speech to Text with Default Options库,对接收到的音频数据进行识别,将识别结果保存为字符串变量,传输至ChatGPT API交互阶段。
连接ChatGPT API。在虚幻引擎中安装并启用OpenAI API插件,以支持与ChatGPT 语言模型的交互功能。在蓝图中创建一个新事件来与ChatGPT API进行交互。使用插件提供的“Set OpenAI API key”功能来设置并获取API密钥,从而实现与ChatGPT服务器的连通。配置API密钥,即可在虚拟数字人项目中搭建起与ChatGPT API通信的渠道。请求节点成功后,分析返回的JSON数据,以提取ChatGPT返回的文本内容,为接下来的文字转语音和嘴型动画环节提供数据。
实现文字转语音服务。通过文字转语音(TTS)服务将ChatGPT API返回的文本内容转换为音频。本案例采用微软云服务,以AzSpeech-Voice and Text插件作为语音转换模块。将Text To Sound Wave with Default Options库添加到项目,编写自定义函数以接收文本数据并调用TTS服务。音频文件可以被保存为WAV或者MP3格式,并传输至虚拟数字人音频播放阶段。
设置音频播放和嘴型同步动画。需要将虚拟数字人的面部动画(骨骼、混合形)联系起来,实现声音与嘴型动画的同步。在虚拟数字人的蓝图中,配置ATLMapping info映射信息。在Pose Asset中选择mh_arkit_mapping_pose映射姿势,实现数字人嘴型的绑定,如图3所示。同时,使用MetaHumanSDKAPIManager获取为引擎子系统,把ATL Audio to Lipsync库获取音频播放长度创建动画节点,同步对齐嘴型,保持实时音频同步状态。根据语音的长度控制嘴型动画,在音频完成播放后,虚拟数字人嘴型回到初始闭合状态,等待新的语音播放,如图4所示。

图3 虚拟数字人表情绑定
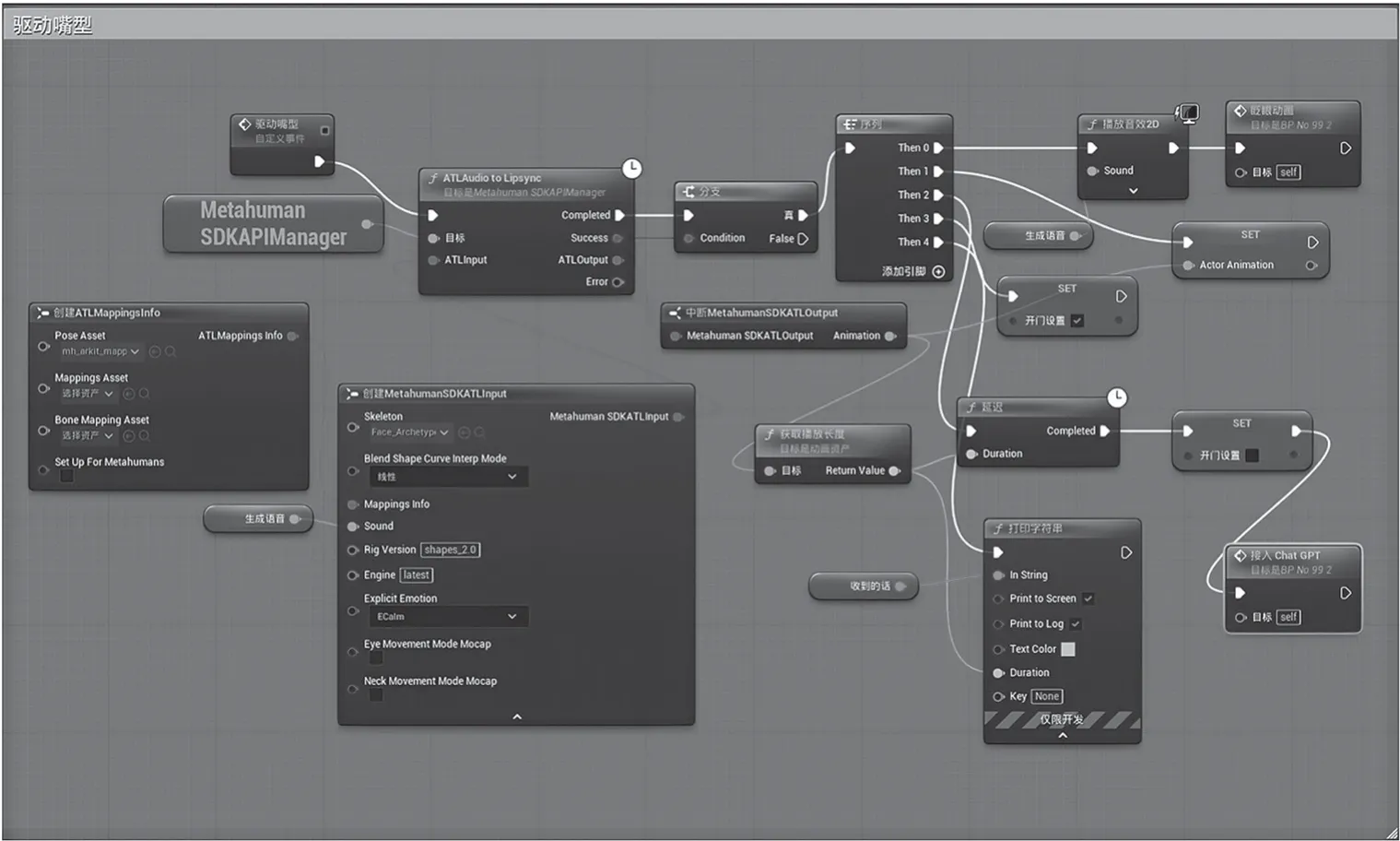
图4 关键实现蓝图
3 虚拟数字人在语音交互领域的典型应用
3.1 虚拟数字人在娱乐领域的应用
虚拟数字人在娱乐领域的应用得益于语音交互技术的发展和研究。语音合成指将以文字为主的媒体内容转化为人类语音输出。和语音识别一样,语音合成也是智能语音技术的重要组成部分。借助这一技术,虚拟数字人能更好地为用户服务,定制个性化的互动方案。用户能够与虚拟数字人进行自然且愉快的语音对话,来分享内心的想法和感受。每个虚拟数字人根据用户的问题进行智能的回复,这样设计的目的在于满足用户在娱乐方面的多样化和个性化需求。总体上说,虚拟数字人和语音交互技术的结合,确保了用户在使用过程中能够获得流畅、清晰且富有逻辑性的互动体验。
3.2 虚拟数字人在教育领域的应用
基于ChatGPT语言模型开发的虚拟数字人在教育领域得到了广泛关注。教育数字人具备高度的拟人化特征,其外观和性格特征均可与真实人类媲美。无论是在微表情、发质还是肤质等方面,教育数字人都能够还原真实人类的模样,并且能够在不同的光影条件下进行对应的渲染和模拟,呈现出与真实教育从业者极为相似的虚拟形象[4]。总之,教育数字人的高度拟人化特点,使其在教育领域的应用价值日益凸显。虚拟数字人通过创新的互动方式与学生沟通,激发学生的学习好奇心与兴趣,从而提高他们的学习积极性。基于ChatGPT语言模型的虚拟数字人被赋予了与学生进行语言交流的能力,可以根据学生的问题提供针对性的解答和指导。
3.3 虚拟数字人在影视制作中的应用
虚拟引擎在影视制作中发挥着重要作用。它打破了严格的制作流程,使模型和贴图处理能够同时进行,特效制作也可以提前进行。虚拟引擎支持动作捕捉设备,拓展性和容错度更好,给创作团队带来了更大的灵活性和便利性[5]。虚拟数字人可以在影视作品中担任虚拟角色。在基于ChatGPT语言模型的虚拟数字人语音交互应用中,虚拟数字人与实际人物或其他虚拟角色展开自然的对话与互动,从而极大地丰富观众的观影体验。得益于ChatGPT强大的语言处理能力,借助虚拟数字人这一宝贵素材,导演和编剧既能节省角色创作成本,又能丰富剧情表现,全面提升作品艺术价值,从而使观众流连忘返于独特的视听盛宴。
4 结 语
随着人工智能技术的飞速发展,虚拟数字人作为一种新兴交互形式受到了广泛关注。虚拟数字人能实现精准、高效的语音交互体验,已走进人们的视野。虚拟数字人打破了传统界限,为跨领域合作提供了空间,推动了娱乐、教育、影视、数字媒体等多规模产业的革新与发展。基于ChatGPT语言模型的语音交互技术,将逐渐成为推动虚拟数字人普及应用的重要驱动力。
