基于个性化联邦学习的多源域MRI左心室分割
2023-09-19李纯真
李纯真
(福州大学 先进制造学院,福建 泉州 362200)
0 引 言
近年来,国家相关部委为推进“互联网+医疗健康”战略,多次发文倡导各医疗机构加快信息互通共享,推进信息化和数字化建设,全面推进医院转型发展。其中,医学影像对最终诊断病情起到了不可替代的作用,医院在常规临床诊断中产生了大量的影像数据。这些影像数据需要经验丰富的医生耗费大量时间进行标注,并且由于一些法律和道德的限制,收集患者数据并进行统一存储并不可行。利用分布式技术对存储在不同医院的影像数据进自动分析,成为未来医疗健康大数据的发展方向。
联邦学习提供了一种去中心化的隐私保护解决方案,可以在不共享本地数据的情况下,利用这些分散的数据在几个机构之间协同训练神经网络模型[1]。在一些医学影像分析任务如新冠肺炎检测[2]、乳腺癌分类[3]、脑肿瘤分割[4]上,联邦学习已经被证明与集中数据训练的模型性能相差无几。然而,上述任务所采用的数据集来源于单一的临床中心和相同的成像协议,无法模拟联邦学习面临的实际环境。实际上,由于成像仪器、患者的人口特征以及地域不同,不同医疗机构之间的采集的心脏磁共振成像(Magnetic Resonance Imaging,MRI)图像存在一些如图1所示的差异。传统联邦学习的做法是训练一个全局模型。尽管该模型在所有客户端上可以取得较高的平均性能,但是对于数据分布差异较大的客户端来说,该模型并不适配本地数据,造成性能损失。
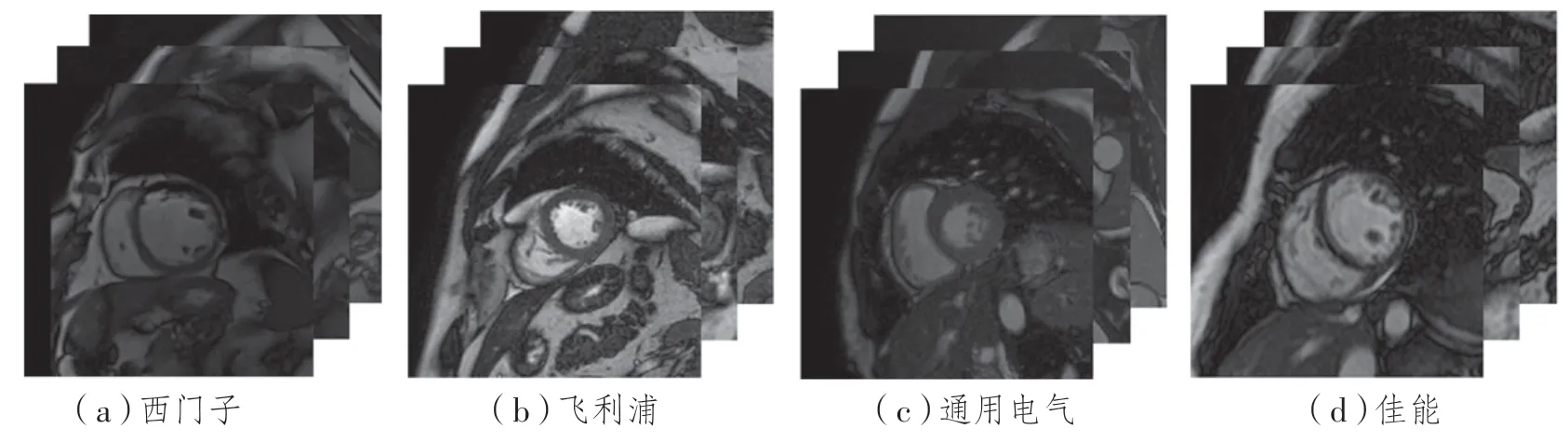
图1 不同制造商的MRI成像对比
与传统联邦学习对本地模型进行加权聚合的做法不同,个性化联邦学习是以分散的方式为每个客户学习个性化的模型。主流的个性化方法包括多任务学习、模型分层以及模型插值方法。DENG等人提出的自适应个性化联邦学习(Adaptive Personalized Federated Learning,APFL)算法将本地模型与全局模型进行自适应加权,获得个性化模型[5]。ARIVAZHAGAN等人将模型分成个性化层和基础层,所有客户端模型共享基本层,不同客户端具有不同的个性化顶层来适应本地数据分布[6]。THAPA等提出将模型最后一层保留在本地客户端,减少因标签传输导致的通信成本增加问题和数据泄露问题[7]。FALLAH等借鉴元学习思想,将服务器发送给客户端的模型进行初始化,然后,客户端根据自身私有数据再进行若干次训练,从而达到联邦个性化元学习的效果[8]。
目前,联邦学习在医学影像分析上的研究,致力于在多个非独立同分布漂移的客户端数据集上学习到一个健壮的全局模型。例如,CHANG K等人[9]采用联邦学习在几个医疗机构之间联合对Kaggle糖尿病视网膜病变分类任务进行建模,取得了与集中性训练相当的实验结果。JIANG等人[10]通过协调局部和全局漂移解决数据异质性引起的整体非独立同分布漂移问题,帮助全局模型向收敛最优解优化。以上这些工作通过生成对抗网络和模型正则化等方法有效降低了数据异质性的影响,但是,目前针对个性化联邦学习在多源域心脏MRI数据的可行性与性能表现的研究依然较少。
为了解决上述问题,本文提出了一种联邦学习个性化方法来对左心室进行多源域联合分割。在联邦学习框架下引入直方图匹配,减少客户端灰度分布差异,提高全局模型的健壮性,并在此基础上进行本地微调训练以适应客户端数据分布,从全局和本地两个方面解决非独立同分布问题,提升分割的准确性。
1 方 法
1.1 联邦学习
在医疗领域,联邦学习一般由多家医院与一个可信第三方作为中心服务器组成客户-服务器架构,如图2所示。
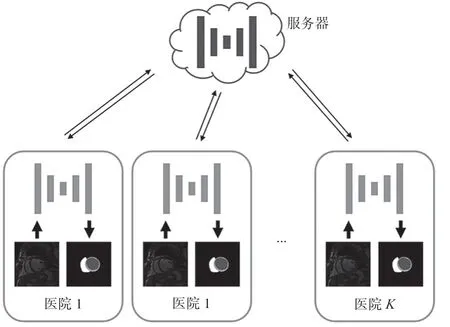
图2 联邦学习任务场景
假设一共有K个医疗机构参与联邦建模,这些机构是数据的拥有方,pk表示第k个机构的数据分布。服务器用于模型参数的聚合,是模型的拥有方。首先,中心服务器将初始化的全局模型发送给各机构。然后,每个客户端使用学习率η和梯度gk在其各自的本地数据集上进行至少一轮的更新,使更新完成的模型权重被发送到服务器,以与每个中心的样本数量成比例的方式聚合到全局模型中:
聚合后,服务器将新模型重新分配给客户端,以执行下一轮本地模型训练。当达到设置的迭代轮次或者收敛条件,训练结束,并获得最终的全局模型。
1.2 直方图匹配
针对不同医疗中心数据之间的分布漂移问题,本文提出基于灰度直方图匹配的数据增强方法,使用直方图匹配来缩小多源之间的数据分布差异。由于灰度直方图描述了MRI图像中每种灰度级出现的频率,且不会提供有关像素之间空间关系的任何信息,因此,共享均匀化的灰度直方图序列并不会导致信息泄露。直方图匹配主要分为局部累加和全局平均两个过程。首先,给定来自第k个客户端的样本灰度级在[0,L-1]内,其直方图是一个离散函数,定义为
式中:n是像素总数,nk是第k个灰度级的像素总数,rk是第k个灰度级,k=0,1,…,L-1。灰度直方图反映了图像的灰度分布信息。客户端对本地图像的直方图进行累加并平均,以获得局部灰度直方图H k:
其次,中心服务器通过一轮通信,得到K个参与方的局部灰度直方图,进行全局平均:
最后,本地客户端对本地数据进行直方图匹配,使输出图像的概率密度函数等于全局灰度直方图H。图3展示了源图像、目标图像和增强图像的一些样本。
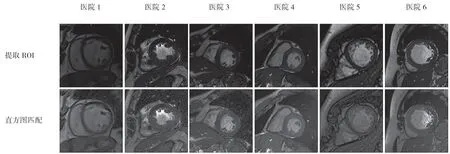
图3 源图像经过直方图匹配后的效果
2 实验结果及分析
2.1 实验细节
2.1.1 数据集及客户端设置
为了模拟真实的联邦学习环境,本文设计了一个独特的数据集。该数据集由来自M&Ms多中心心脏图像分割挑战赛数据集[11]的5个中心和ACDC2017心脏病自动诊断挑战赛数据集[12]的1个子集作为第6个中心组成,使用的数据集详细信息如表1所示。该数据集一共包含380个受试者的T1加权心脏Cine-MRI序列,并根据受试者来源分为6个医院。每个医院按照0.50∶0.25∶0.25的比例随机划分为训练集、验证集和测试集。
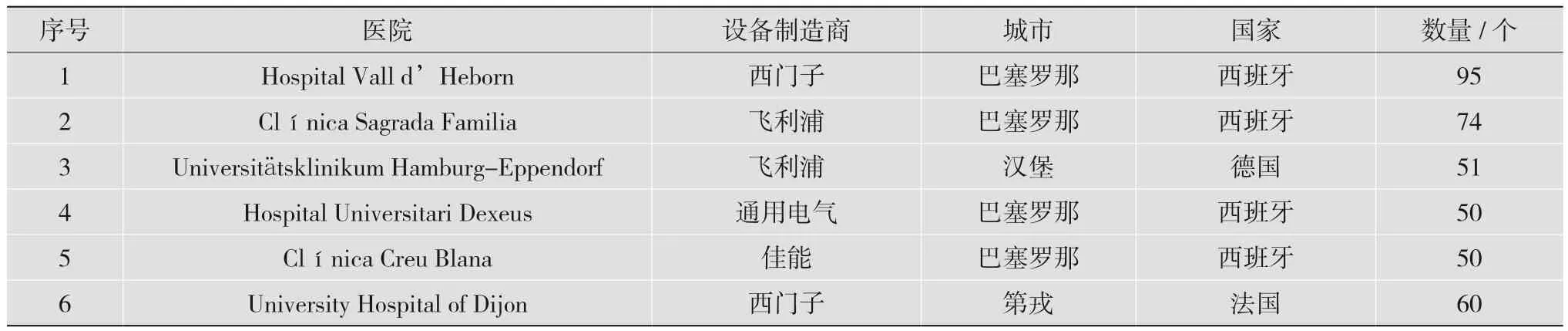
表1 数据集所含的各医疗中心信息
原始数据集轴向平面上包括大小从196×240 px到320×320 px不等的图像,通过计算掩码质心,继而中心裁剪获得128×128 px大小的感兴趣区域(Region of Interest,ROI),减少无用信息的同时使心脏区域具有相似的视野,并通过直方图匹配将不同医院数据的灰度分布进行均衡化,如图4所示。
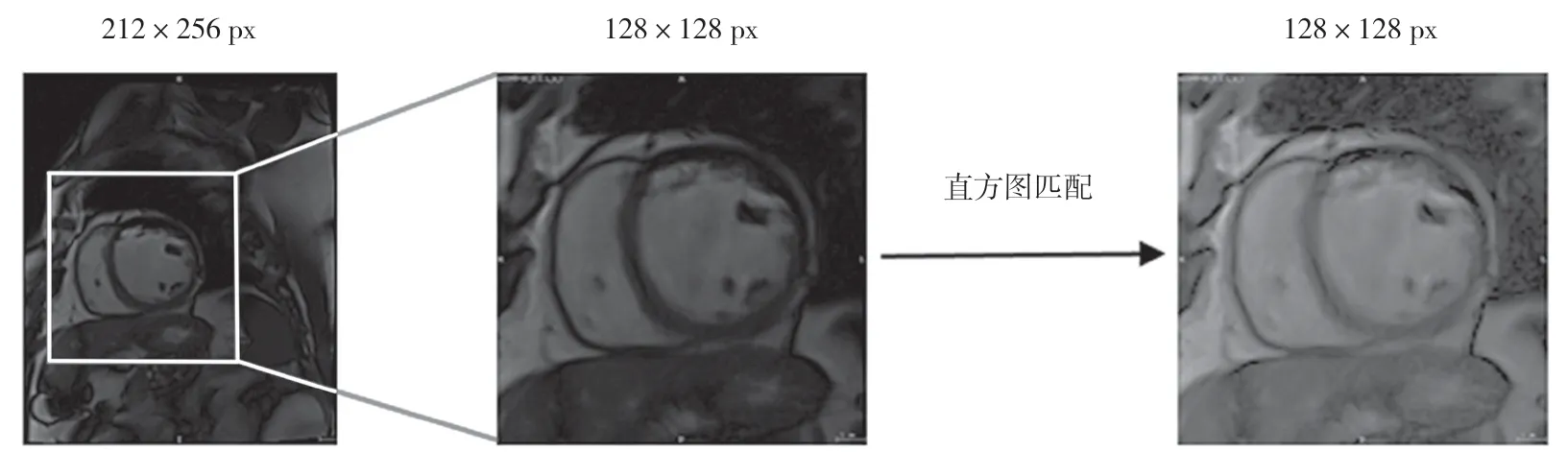
图4 图片预处理
2.1.2 超参数
在联邦训练过程中,将每个数据来源视为一个医院,所有医院使用相同的超参数设置。采用学习率为0.000 1,动量为0.9和0.99的Adam优化器对本地模型进行训练,批大小均设置为16。根据McMahan等的实验结果,较大的本地训练次数有助于减少通信成本,但是性能略有损失。通信成本不是本文所考虑的问题,因此,每一轮的本地训练次数Epoch设置为1。
2.2 实验结果
为了验证本文个性化联邦学习的有效性,分别对本地训练、集中式学习、增量学习和传统联邦学习在MRI左心室分割任务上的性能进行对比。表2为本文方法和其他联邦学习方法在左心室分割任务上的实验结果。集中训练表示收集各医疗机构数据进行传统深度学习训练。由表2的结果能够看出,本文方法在左心室分割精度上分别比增量学习和联邦平均高出4.79%和1.12%,并且达到集中训练的理论上限结果的99.63%,证明了本文个性化联邦学习方法在多机构协同合作与隐私保护方面的巨大潜力。
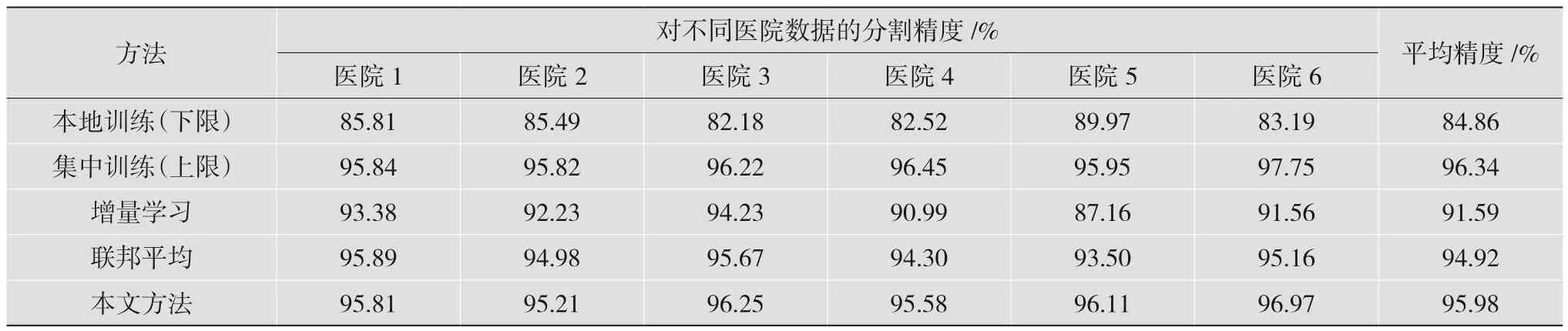
表2 左心室分割任务实验结果
3 结 语
本文针对联邦学习在面对医学影像分析任务时遇到的非独立同分布问题,提出了一种个性化联邦学习的方法,主要在不同客户端之间进行直方图匹配以减少客户端数据差异,提高全局模型的健壮性,在本地利用模型微调的方法获得个性化模型。相较于其他隐私保护分布式学习方法,本文方法在多中心心脏MRI数据集以及左心室分割任务上均取得了更高的精度。实验结果表明,本文所提的个性化方法可以在非独立同分布设置下提高联邦学习的性能。
