基于Transformer的机动目标跟踪技术
2023-09-18党晓方蔡兴雨
党晓方,蔡兴雨
(西安电子工程研究所, 陕西 西安 710100)
随着信息技术的快速发展,目标跟踪技术被广泛应用于军事和民用领域。目标跟踪通过传感器量测数据(例如雷达、红外或声纳)来估计目标的运动状态。目标跟踪通常可分为机动目标跟踪和非机动目标跟踪,其中“机动”是指目标在不可预测时突然改变其运动状态。对于非机动目标跟踪,传统基于卡尔曼滤波器(Kalman Filter, KF)的跟踪算法被广泛应用于多种领域[1-3]。对于机动目标跟踪,传统方法使用多个模型来拟合复杂的运动状态,即多模型(Multi-Model, MM)算法[4]。为了使多个模型之间具有更好的协同效应,交互式多模型算法[5](Inter-active Mutil-Model, IMM)被广泛使用,大幅提高了机动目标跟踪的性能。因此,IMM逐渐成为一种被广泛应用的跟踪框架[6-8]。然而无论是MM还是IMM,均存在模型集与目标运动状态不匹配的问题,即模型集无法描述目标所有可能存在的运动状态。此外,当目标的运动状态发生变化时,MM和IMM都需积累一定数量的观测值,从而产生模型估计延迟问题[9]。
随着深度学习技术的发展,特别是具有记忆能力的递归神经网络[10](RNN)和长短期记忆网络[11](LSTM)被证明在解决序列问题上具有独特的优势,为解决MM和IMM所面临的问题提供了新思路[12-16]。RNN和LSTM可以从每一个时间步长的量测中估计目标状态。双向LSTM可以用于估计输出航迹和真实航迹之间的偏差[14]。虽然LSTM类方法能够对目标状态进行有效估计[15-18],但是对于较长的序列,LSTM的效果不佳[16]。
本文提出了一种基于Transformer的机动目标跟踪网络,该网络的编码器部分完全使用Transformer中的注意力机制[19],而在解码器部分采用全卷积网络。鉴于目标跟踪问题的特殊性,即轨迹序列点之间的位置间隔并不固定,因此采取可学习的位置编码来学习输入的位置间隔信息。最后,本文提出了一种CN的归一化方法,将观测值从固定坐标系转化为相对坐标系,提高了网络向不同观测数据的迁移能力。实验结果表明,TBN网络在跟踪机动目标时,与基于LSTM的网络相比,位置和速度估计误差分别降低了11.2%和41.9%。此外,注意力机制的全局特性使得TBN能够处理序列存在缺失观测的情况,当缺失30%的观测值时,TBN的跟踪性能仅下降18%。
1 问题描述
本文用Zk、Xk分别表示目标在k时刻的量测值和状态值。本文主要考虑了X-Y坐标平面中的雷达跟踪问题。K代表了总观测时间。具体来说,Xk=[cx,k,cy,k,vx,k,vy,k]表示二维场景中的目标坐标和相应的速度分量,Zk=[θk,dk]表示雷达观测到目标的方位角和距离。

(1)
由于神经网络需要大量的数据进行训练,而实际采集数据的成本又过高,因此本文基于状态空间模型(State Space Model, SSM)模拟了100 000条轨迹段。SSM首先定义了状态转移方程和观测方程来描述状态的转移过程
(2)
其中,F为状态转移矩阵,用于描述目标运动规律;nk为转移噪声;h为观测函数,用于描述目标状态值和观测值之间的转化方式;wk为观测噪声。
对于雷达目标跟踪,Zk被定义为
(3)
其中,σθ为方位角的标准差;σd为距离的标准差。
为了能够更全面地描述客观世界中目标的运动规律,本文考虑了多种运动状态,其中包含匀速运动(CV)和匀速转弯运动(CT)。CV的状态转移矩阵定义为
(4)
CT的状态转移矩阵定义为
(5)
其中,w表示机动目标的转弯率;τ为观测值的采样间隔。由文献[20]可知,状态转移噪声nk=[nc,k,nc,k,nv,k,nv,k]可以建模为
(6)

2 模型介绍
2.1 Center-Max 归一化方法
输入网络训练的轨迹序列包含真值结果和带噪观测序列。在将轨迹序列数据送入网络之前,需要对数据进行预处理。为了消除观测值和状态值之间的维度差异性,首先将观测值转化到X-Y二维坐标系下:
(7)
文献[14~15]提出对分段轨迹进行归一化的方法,即对每段观测值分别除以对应轨迹段的距离最大值。这种方法虽然能够消除距离维和速度维之间的维度差异,但同时也消除了不同速度下相邻点之间的距离间隔的差异性,影响了对目标速度的预测,因而这种差异性也是TBN网络所需要利用到的语义特征信息,应当给予保留。
因此,本文提出使用CM归一化方法对数据进行预处理,以改善模型的泛化性,并保留了距离间隔的语义信息,其计算式为
(8)
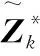
(9)

2.2 Transformer网络
受Transformer网络在序列建模问题方面的启发,本文将其引入雷达机动目标跟踪任务。Transformer利用注意力机制并行地处理输入序列数据,与LSTM相比,其可以更容易地捕获序列的局部相关性以及全局相关性。基于此,TBN网络由Transformer结构中的自注意力机制构成的编码器和1-D全卷积网络构成的解码器组成。
TBN网络由位置编码结构、N个堆叠的编码器结构和由3层1-D全卷积层构成的解码器组成。每个编码器结构由一个多头自注意力层、前馈全连接网络以及在先前结构之后的两个残差连接结构(层归一化结构)组成。图1展示了本文设计的TBN架构。
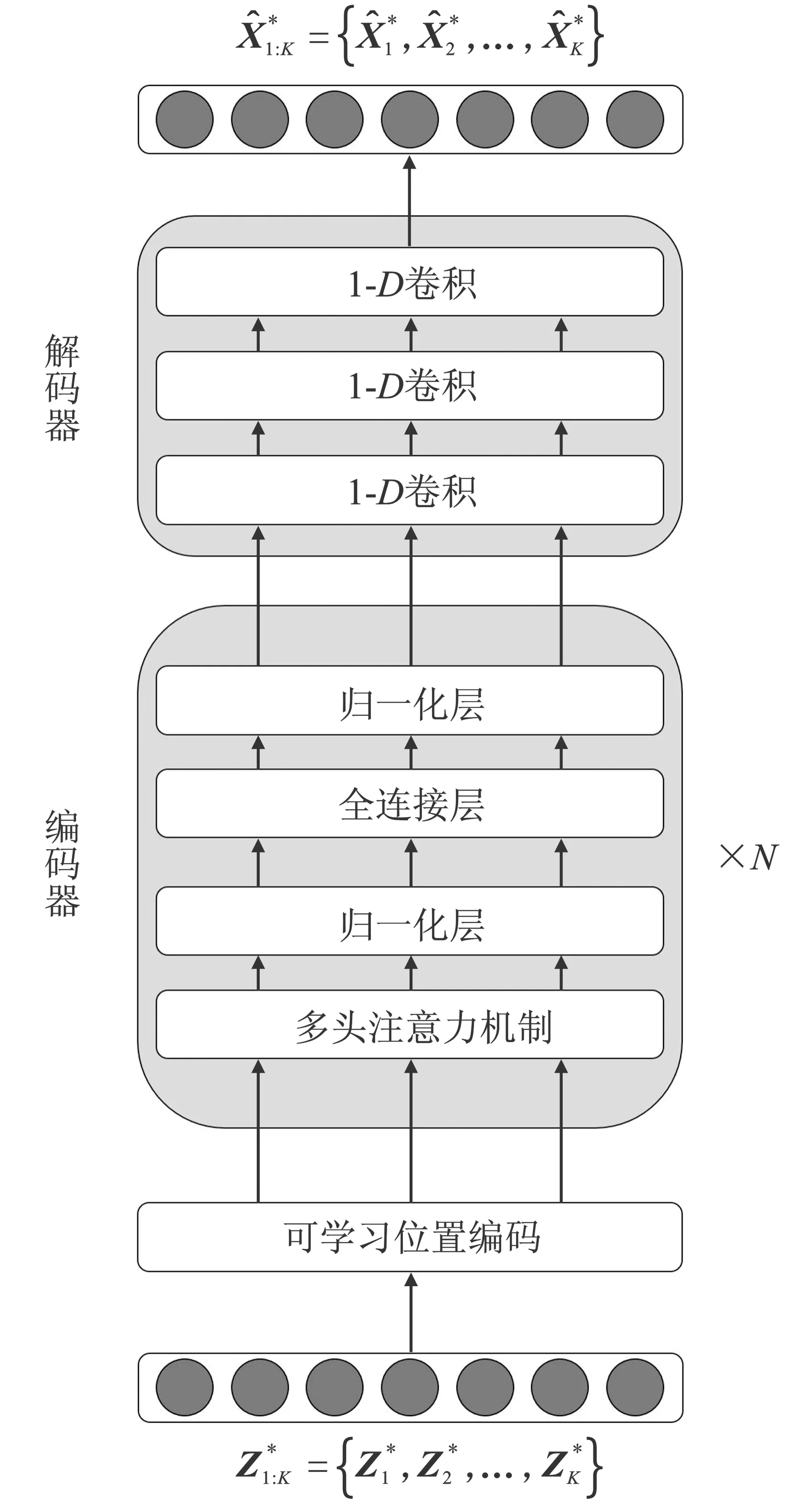
图1 TBN网络模型架构Figure 1. Architecture of the TBN
2.2.1 位置编码
在自然语言处理领域中,Transformer向序列添加位置编码,以表示每个字词在原序列中的相对或绝对位置。但在雷达机动目标跟踪领域,输入序列中的序列值为数值,并非单词。因此,不使用原始Transformer中采用的确定性位置正弦编码方式,而是采用了可学习位置编码方式[21]
(10)

2.2.2 多头自注意力层
自注意力机制为Transformer的核心机制,其在长序列建模问题中比LSTM等方法效果好的原因就在于自注意力机制。通过自注意力机制,解码器在任意时刻的输出信息均能查询到编码器中输入序列的全部序列信息,并找出对当前输出最有利用价值的序列信息,对其进行加权求和,得到最终的输出。而多头自注意力层是由多个自注意力层堆叠而成的结构。
对于多头注意力层结构,设其具有M个自注意力层,则输入序列S1:K∈Rde×K首先线性映射为查询向量Q、键向量K和值向量V
(11)
其中,WQ、WK、WV均为可学习的参数。

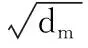
(12)
对于输入序列中的每个点都进行上述操作,便可得到任意自注意力层的输出结果为
(13)
最后将所有自注意力层的结果进行拼接,即可得到多头注意力层的输出结果
Sa=Concat(head1,…,headM)
(14)
其中,Sa的维度与S1:K的维度一致。在原始的Transformer结构中,在最开始每个自注意力层的输入均是de×K,因此在后续整合所有自注意力层输出时,拼接的输出向量将会异常庞大,且需要引入一个变换矩阵参数将其映射回原始维度,这会增加网络的参数量。而本文采用先沿着维度de分割的方法,避免出现异常庞大的矩阵,减少了网络所需要学习的参数量。
2.2.3 层归一化结构
为了避免出现梯度消失的问题,在多头注意力层输出后应与多头注意力层的输入进行相加,然后经过层归一化结构对输出进行标准化
(15)
其中,μ、σ分别代表输入数据的均值和标准差。
2.2.4 前馈全连接层
为了让多头注意力结构的输出数据之间进行交互,即希望通过多头注意力结构的输出映射出所希望的输出向量结果,需要引入前馈全连接层。前馈全连接层由两层带有ReLU激活函数的全连接层构成。
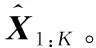
2.2.5 Transformer网络的优势
Transformer的架构模式使其能够并行地处理输入数据,而LSTM等时序网络需要串行地处理输入数据,即当前时刻的输出依赖于上一时刻的输出,当序列过长时,易出现梯度消失或梯度爆炸等问题。而Transformer网络的并行数据处理能力使得其不会受限于时序数据的长度,因此可以有效地避免梯度消失和爆炸的问题。
2.3 基于Transformer的机动目标跟踪网络
将实际的带噪观测序列进行分段处理,得到n份轨迹片段,将其通过数据预处理部分进行归一化后,输入到TBN中,并输出R个预测的轨迹片段,将其进行拼接并按照式(16)所示进行逆归一化得到最终的预测轨迹序列。
(16)
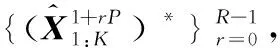
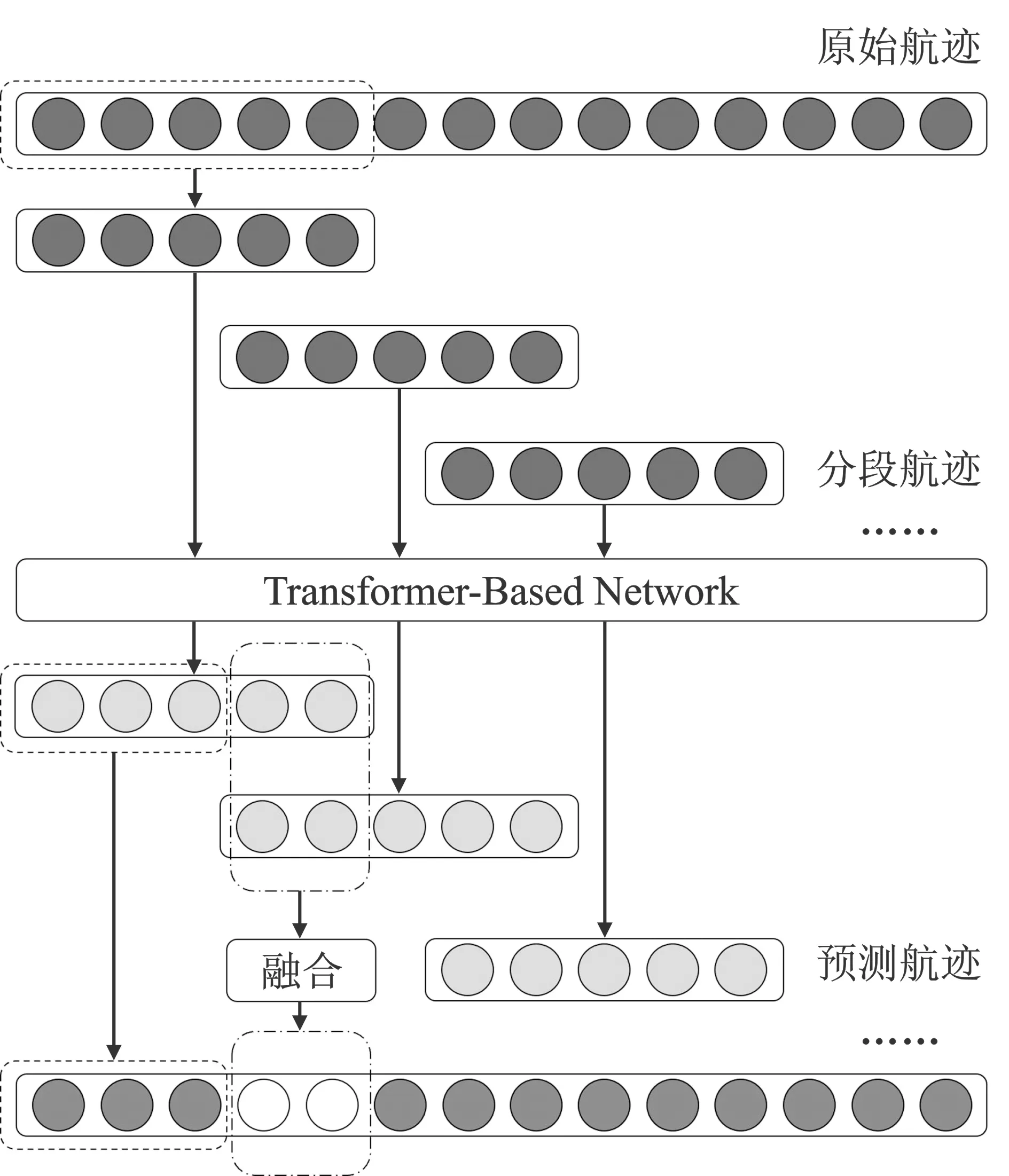
图2 轨迹序列处理流程Figure 2. Trajectory sequence processing
(17)
最终所有的输出轨迹片段都会经过拼接处理,得到完整的轨迹预测结果。
3 仿真实验和结果
本文给出了轨迹数据集和网络参数,并设计实验来测试和验证TBN模型的跟踪性能。
3.1 实验参数
设定轨迹序列数据集规模为300 000条。实验参数如表1所示。此外,假设Dmax=5 km且每间隔1 s观测一次目标。

表1 航迹数据集参数Table 1. Parameters of the trajectory data set
TBN网络由4个编码器组成,每个编码器中的多头注意力层包含8个注意力层。本文将编码维度设置为512。解码器中的1-D卷积层的输出维度分别是64、16、4。网络使用参数为β1=0.90,β2=0.98,ε=10-9的Adam优化器进行迭代优化参数。学习率在前10次迭代采用线性热启动的方式启动,并在后续迭代中采用动态调整策略进行衰减。设置批次大小为32,迭代次数为400次,计算显卡设备为NVIDIA TITAN Xp GPU。
本文将提出的TBN+CM归一化模型与IMM算法和LSTM+min-max归一化模型(LSTM+MM)进行对比。同样,也构建了LSTM+CM归一化模型。
3.2 实验结果
设置初始状态为[2 km,2 km,50 m·s-1,0 m·s-1]且转弯率为0°的目标,并进行蒙特卡罗实验生成名为A1的60步长轨迹段。在第10步和第40步时,目标的转弯率机动变化为-1°和5°。在轨迹A1上评估了TBN+CM、LSTM+MM、LSTM+CM和IMM算法。跟踪结果如表2和图3所示。

表2 航迹数据集A1实验结果Table 2. Numerical results of several methods for tracking trajectory A1
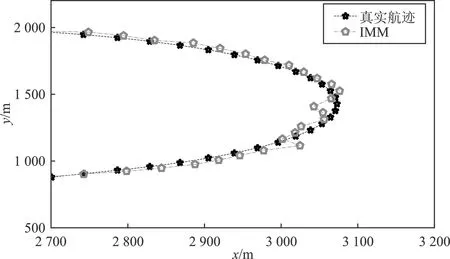
(a)

(b)
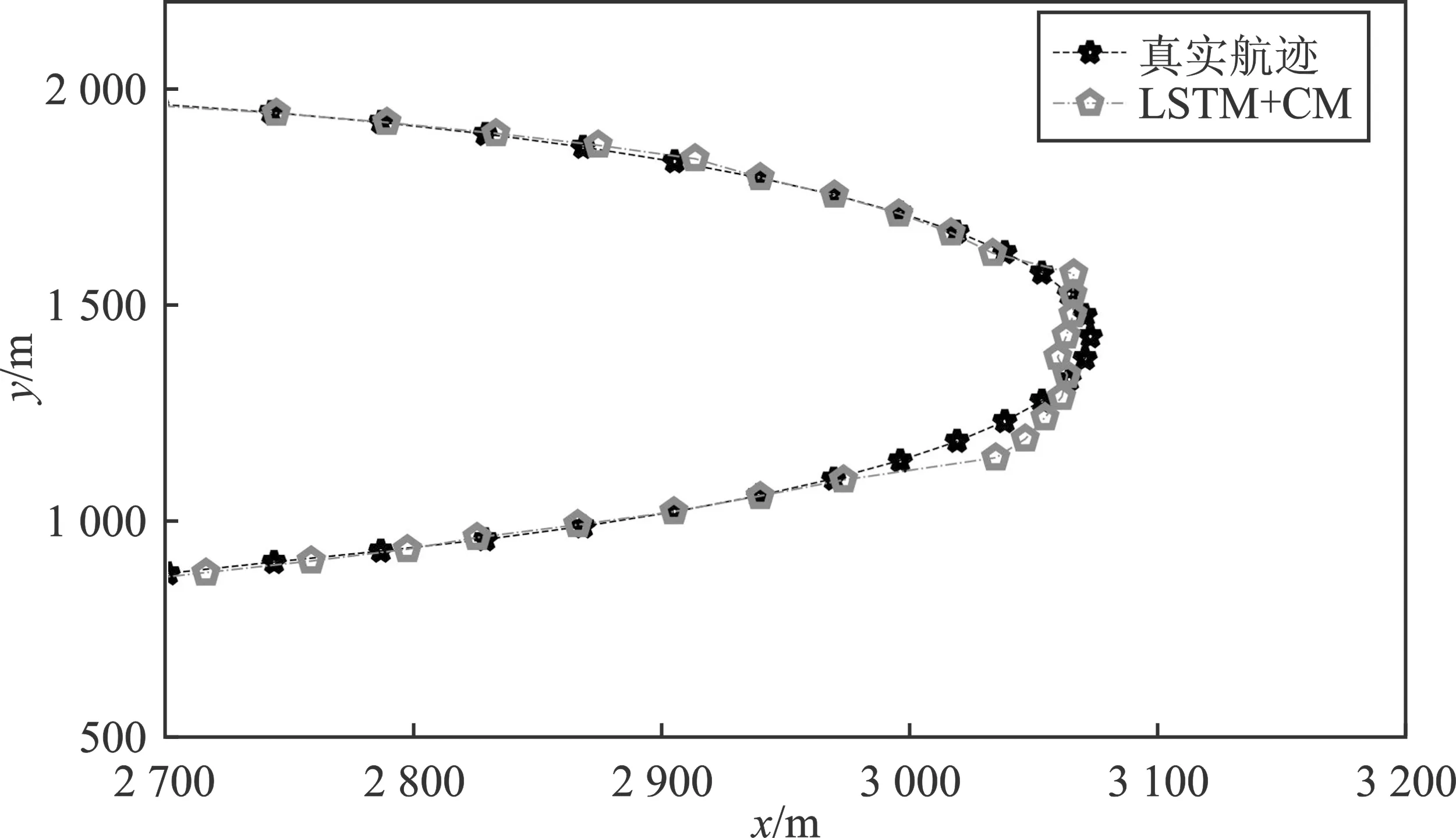
(c)
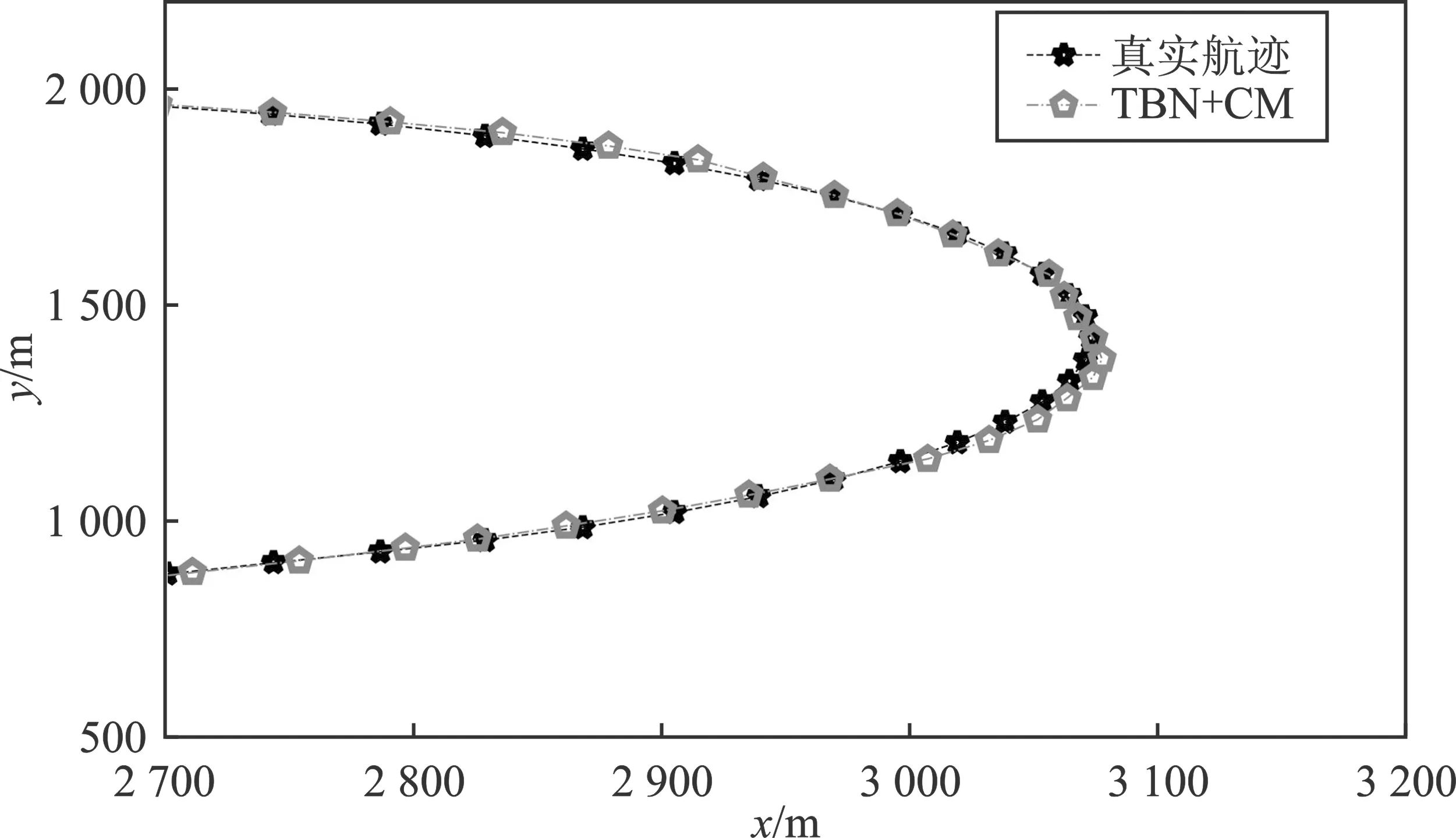
(d)图3 机动目标跟踪结果Figure 3. The results of tracking a maneuvering target
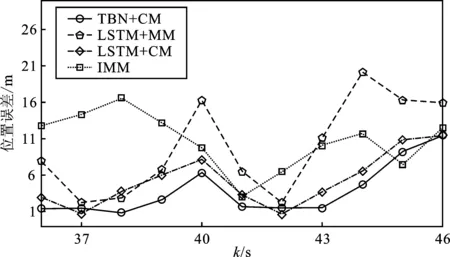
图3展示了本文所提算法跟踪目标的情况。图4(a)和图4(b)展示了轨迹A1的RMSE结果。此外,轨迹A1的平均RMSE列在了表2中。在表格2中,LSTM+CM的RMSE小于LSTM+MM,证明了本文提出的CM归一化方法通过降低轨迹学习的复杂性,从而提高了网络的跟踪性能。同时,表2中加粗的结果表明TBN+CM的跟踪误差最小。因为引入了CM归一化的方式,使得基于CM的方法估计速度时,总是优于基于MM的方法。
(a)
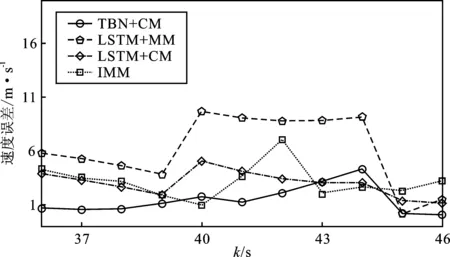
(b)图4 机动目标跟踪RMSE误差结果(a)位置误差 (b)速度误差Figure 4. The RMSE of tracking a maneuvering target(a)Position error (b)Velocity error
此外,将轨迹A1的初始位置进行变化,得到轨迹A2和A3。对表3中列出的轨迹设置了不同数量的缺失值。表3中的结果表明,本文提出的TBN+CM可以对缺失值进行有效预测,然而LSTM+MM由于其固定的归一化方式导致其跟踪有缺失值的轨迹失败。
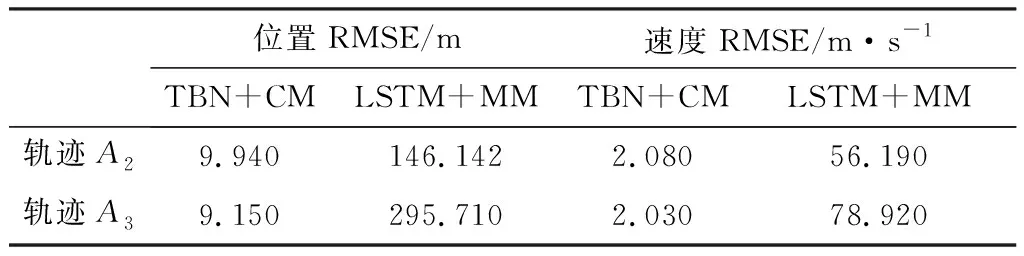
表3 在不同初始位置的轨迹跟踪结果Table 3. Results of tracking trajectories at different initial position
4 结束语
本文设计了一种基于注意力机制的TBN网络以跟踪雷达观测的机动目标轨迹,并构建了一个大规模的轨迹数据集用于训练网络,最终提出了具有良好迁移能力的CM归一化来预处理轨迹。实验结果表明,TBN算法优于现有基于LSTM的跟踪网络和IMM等传统算法。此外,TBN网络可以在缺少观测值的情况下工作。未来的工作可以考虑使用轻量级Transformer网络来改善跟踪性能。由于本文未考虑数据关联问题,因此关联跟踪集成网络也值得探索。
