基于Citespace 的水面无人艇路径规划与避障算法研究
2023-09-16周治国邸顺帆
周治国,邸顺帆
(北京理工大学 集成电路与电子学院, 北京 100081)
0 引 言
路径规划与避障一直都是水面无人艇研究的重要内容,水面无人艇需具备的自主能力之一是通过感知模块与外界未知环境进行交互获得信息,从而保证水面无人艇能据此进行路径规划和局部避障[1]。基于国内外发展现状以及路径规划与避障技术的重要性,本文针对水面无人艇路径规划与避障领域,运用科学知识图谱的方式对数据进行挖掘,总结技术发展趋势、展望未来研究方向。
1 无人艇感知模块
环境感知是无人艇实现路径规划与自主避障的前提。无人艇通过传感器感知环境信息,为后续识别和决策提供支撑[3]。无人艇的传感器大体上可以分为:1)用于外部环境感知,包括激光雷达(Lidar)、单目或双目相机、深度相机、毫米波雷达、红外等,多用于目标识别和跟踪,表1 为3 种Velodyne 激光雷达的性能参数对比,表2 为单目相机、双目相机和深度相机三者的优缺点对比;2)用于自身状态感知,包括惯性测量单元(IMU)、GPS 等,用于无人艇自身的定位及姿态矫正。
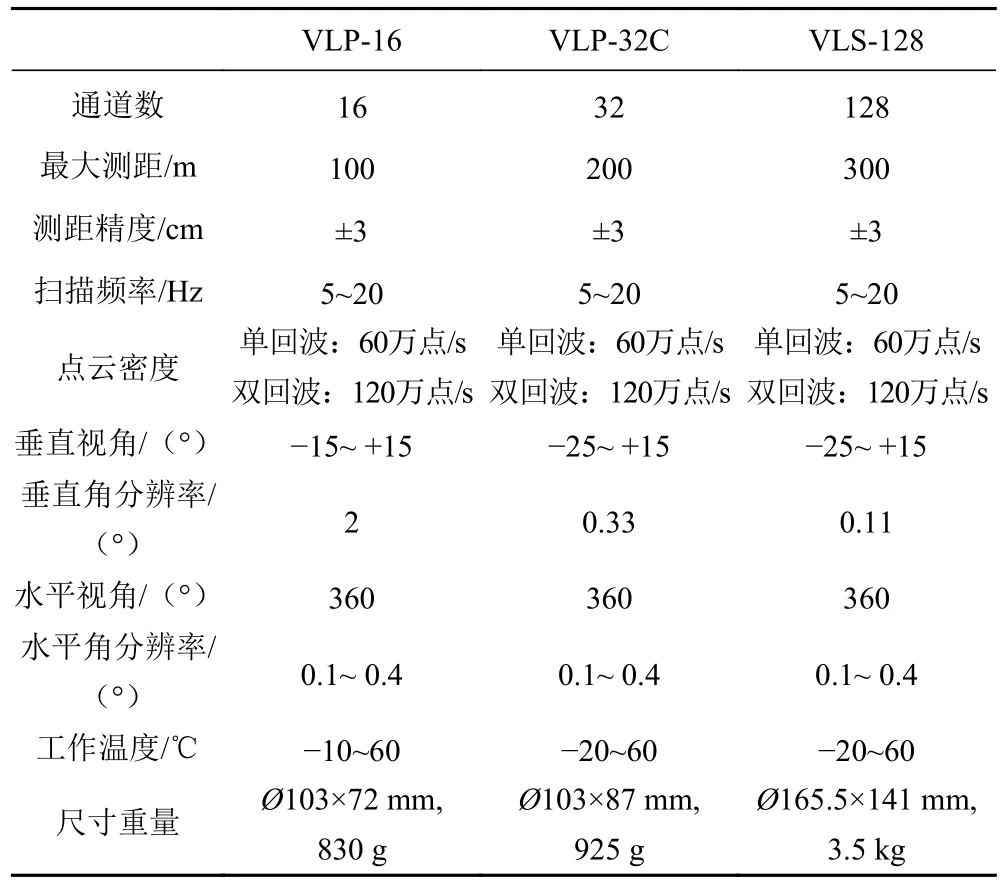
表1 Velodyne 激光雷达性能参数对比Tab.1 Performance parameter comparison of Velodyne Lidar
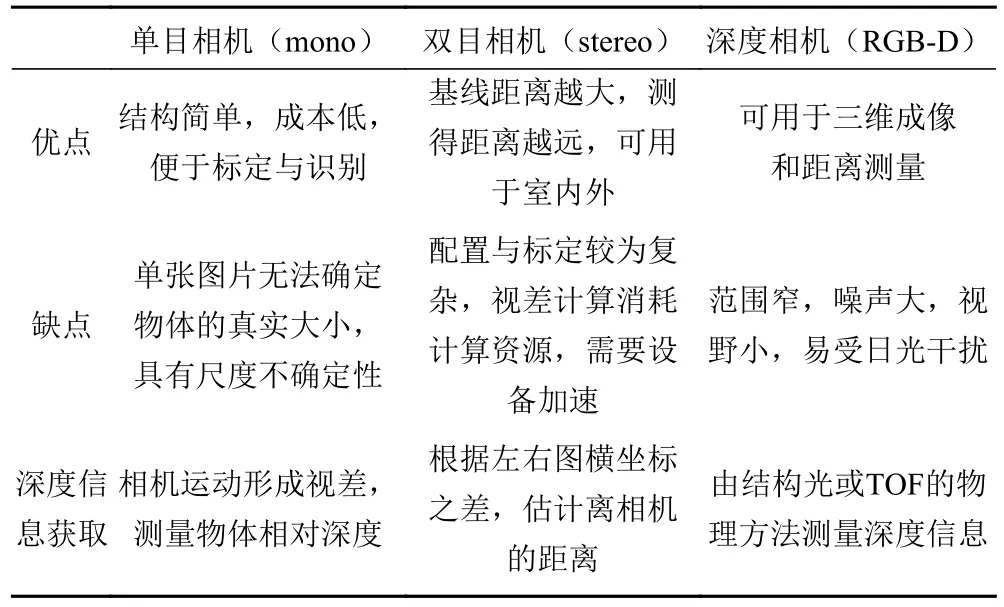
表2 单目、双目及深度相机对比Tab.2 Comparison of monocular, binocular and depth cameras
国内外研究者对于感知技术的研究通常集中在外部环境感知方面,如基于可见光成像的目标检测,基于双目或单目视觉的目标跟踪,以及使用激光雷达等测距传感器的水面障碍物定位。通常单一传感器不能全面地反映复杂海况,容易受到天气、距离、自身工作条件等因素的影响[6],出于提高水面目标跟踪与定位的精确度、改善实时检测及跟踪效果差等目的,现阶段环境感知信息的获取不再局限于单个传感器的输入,传感器融合的技术为无人艇感知技术开辟了新道路。David 等[7]在2017 年提出了一种基于激光雷达和视觉系统融合的海面目标检测跟踪定位方法, Mou 等[8]将双目相机同GPS 和电子罗盘等进行信息融合,得到了海面障碍物的准确位置。在传感器融合过程中如何克服各个传感器的缺点,提供实时、准确的环境感知信息仍是研究难点,但毫无疑问,多传感器信息融合是未来无人艇环境感知的关键技术[9]。
2 路径规划与避障
无人艇的避碰路径规划算法可以分为全局路径规划和局部路径规划两类[10]。
2.1 全局路径规划
全局路径规划是依据整个环境构造环境地图后在规定区域内进行的,不能处理规划过程中的突发状况,规定区域内进行的,不能处理规划过程中的突发状况,对实时性要求不高且一般可找到最优解。经典算法有Dijkstra 算法、A*算法、蚁群算法、遗传算法等。
Dijkstra 算法[11]是Dijkstra 是提出的全局规划最短路径算法,该算法虽简单但占用内存大、计算效率低,仅适用于小范围内的路径规划。A*算法[12]是经典的启发式路径规划算法,通过设置代价函数,寻找两点之间的最小代价。由于依赖于启发函数,A*算法计算量巨大,导致规划路径的时间较长。蚁群算法[13]和遗传算法[14]都属于智能仿生学算法,用于处理复杂环境下的路径规划问题。蚁群算法通过迭代模仿蚁群觅食行为寻找最短路径,具有便于并行和鲁棒性强的优点,但设置参数不准确或初期信息素缺少时会出现路径规划速度过慢的问题。张丹红等[15]针对无人艇海上巡逻路径规划问题,提出了A*算法与蚁群算法相结合进行最短巡逻路径优化的方法,效果如图1 所示。遗传算法是一种随机化搜索算法,其实质是一种在解空间中搜索与环境最匹配的自适应方法,通过逐步淘汰掉适应性函数低的解,增加适应性函数高的解,从而获得最优路径。遗传算法具有较高的鲁棒性,但其收敛速度较低且控制变量较多,所花费时间要更久。
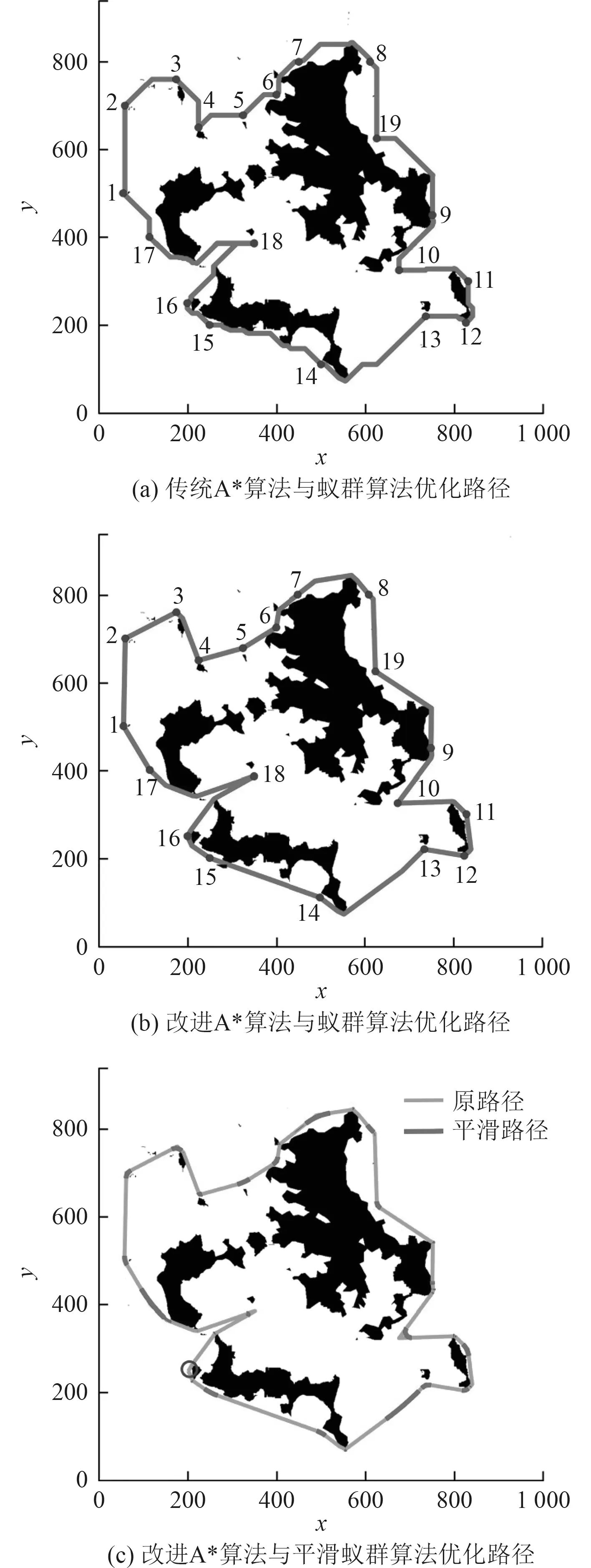
图1 A*算法与蚁群算法相结合的路径优化效果Fig.1 Path optimization effect of A* algorithm combined with ant colony algorithm
2.2 局部避障算法
局部避障即局部路径规划是在未知环境下通过传感器获取周围障碍物信息,包括其位置、形状、尺寸等,使无人艇自主生成安全可行的最优路径,其经典算法如人工势场法、动态窗口法、速度障碍法等。
人工势场法最初由Khatib[16]提出,通过建立势场解决实时避障问题,原理简单实时性高,但可能会产生局部最小值的问题。动态窗口法[17]是一种在线避障算法,在窗口不断滚动中实现优化与反馈,准确度较高且计算量小,但算法对航行器的控制要求较高,稳定性较差。汪流江等[18]提出一种基于A*与动态窗口法的混合路径规划算法,在A*算法得到全局路径生成局部目标点后,随着局部目标点的不断更新USV 使用动态窗口法航行至全局目标点,图2 为该混合路径规划算法与单独采用A*算法的路径搜索结果对比,可以看到混合路径规划对应的路线拐点更少且角度更小。速度障碍法[19]由Fiorini 等提出,通过在无人艇与障碍物间的速度空间内构建一个三角区域,当速度向量落入此三角区内判定二者发生碰撞,之后从非三角区域中找到一个最优的速度矢量,实现最优路径避障。速度障碍法考虑动态障碍物的运动信息,算法稳定性高且规划路径准确度高,但速度较慢。

图2 混合路径规划算法仿真结果Fig.2 Simulation results of hybrid path planning algorithm
2.3 强化学习算法
强化学习(Reinforcement Learning, RL)是机器学习的范式和方法论之一。强化学习的学习机制是智能体通过与环境交互获得对动作的反馈,以“试错”的方式进行学习,目标是使智能体获得最大的奖赏。按照算法的优化机制,强化学习分为基于值函数的方法(Value-based)和基于策略的方法(Policy-based)。前者的代表性算法为深度Q 网络(Deep Q Network,DQN)及其改进算法,后者的代表算法有策略梯度算法及其各种形式。
2.3.1 Q 学习及其改进算法
最初由WATKINS[20]提出的Q 学习是一种典型的Value-based 方法,该算法引入Q 值表保存每个状态下对应的动作值,然后通过增量的方式不断更新,Q 值越大则证明该状态下采取的策略越好。王程博等[21]建立了一种基于Q 学习的无人驾驶船舶路径规划模型,在仿真环境中验证了该方法可实现在未知环境中的自适应航行。Q 学习算法对环境模型的要求较低且收敛性较好,但在复杂水域环境中会因Q 值表无法存储大量状态行为信息而导致维数灾难的问题。封佳祥等[22]针对Q 学习算法在多任务约束条件下收敛慢的问题,提出一种基于任务分解奖赏函数的Q 学习算法,通过仿真实验验证了采用该算法进行无人艇路径规划的可行性,图3 为多任务约束条件下基于该算法的路径规划仿真结果。Sarsa 算法[23]与Q 学习算法类似,决策部分相同,区别在于该算法生成样本的值函数与网络更新参数使用的值函数相同,其优点是收敛速度快,缺点是可能无法找到最优策略。Zhang 等[24]提出一种基于Sarsa 强化学习的USV 自适应避障算法,在价值函数设计中将路线偏离角及其趋势引入到动作奖惩中,最后通过对比实验验证了所提算法的有效性。
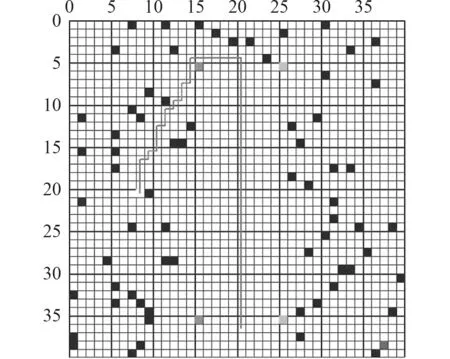
图3 多任务约束条件下基于Q 学习算法的无人艇路径规划仿真结果Fig.3 Simulation result of USV path planning based on Q-learning algorithm under multi-task constraints
2.3.2 策略梯度算法
策略梯度算法(Policy Gradient)[25]是一种典型的Policy-based 方法,针对最大化回报值的目标建立目标函数,通过不断调整参数使目标函数梯度上升,从而实现梯度最大化。该类算法要求的参数少且能够处理连续空间,但在每次梯度更新时并未参考之前的估计值,导致收敛缓慢并存在陷入局部最优的问题。将Value-based 和Policy-based 进行结合,Barto 等[26]研究者提出了执行-评估(Actor-Critic, AC)方法,该方法中Actor 负责通过策略梯度学习策略,Critic 负责值函数估计,二者相互影响,在训练过程中不断地多元迭代优化。然而该方法依赖于Critic 的价值判断,故存在难以收敛的问题。传统的强化学习算法应用于路径规划时对地图模型的要求较为简单,但面对大规模的复杂环境时,一方面受更新速度的限制,在处理较大数据量时容易引起维数灾难;另一方面泛化能力较差,在面对全新状态时需要消耗大量时间进行规划,从而难以达到实时避障的要求。
2.3.3 深度强化学习
深度强化学习(Deep Reinforcement Learning,DRL)已成为新的研究热点,并被尝试应用在无人驾驶领域[27]。
DRL 兴起之后,研究者们提出了许多对传统强化学习模型的改进算法:将卷积神经网络与Q 学习算法相结合的深度Q 网络(Deep Q-Network, DQN)模型[28]、采用2 套参数将动作选择和策略评估分离开的深度双Q 学习(Deep Double Q-Network, DDQN)[29]、基于竞争网络结构的DQN(ueling DQN)[30]、以及基于AC 架构的深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)算法[31]、近端策略优化(Proximal Policy Optimization,PPO)算法[32]等。
随博文等[33]提出一种基于深度Q 网络的USV 避障路径规划算法,利用深度神经网络估计Q 函数,有效解决了传统Q 学习算法在复杂水域环境中易产生维数灾难的问题,该算法与A*算法的路径规划效果如图4所示。Xu 等[34]在经典DQN 算法的基础上进行改进,提出了一种基于深度强化学习的COLREGs 智能避障算法(COLREGs Intelligent Collision Avoidance, CICA),使得无人艇可在国际海上避碰规则下(COLREGs)成功躲避动态障碍物—移动船舶,实验验证该算法同传统局部避障算法相比表现更佳。Meyer 等[35]利用PPO 算法实现USV 在国际海上避碰规则(COLREGs)下遵循期望路径行驶并避免与沿途船只发生碰撞。

图4 深度Q 网络与A*算法在相同仿真环境下的路径规划效果对比Fig.4 Comparison of path planning effect between deep Q network and A* algorithm in the same simulation environment
3 结 语
无人艇实现自主航行的关键在于能够通过传感器采集到的信息进行路径规划,同时在沿途遇到危险能够进行局部避障,最终安全到达目标点。近年来该领域得到了越来越广泛地关注,应用场景更加丰富,但目前国内外在实现真正无人化作业方面仍有待提升。
感知技术方面,由于无人艇工作在水域环境中,存在光照反射、天气变化等的影响,其检测结果会受到较大干扰。传统的感知算法虽具有理论性强、可靠性高、应用广泛的特点,但在目标检测准确率上存在局限性,而深度学习感知算法有着鲁棒性强、准确度高的优点,随着机器学习的不断发展,将其合理运用将使得无人艇的感知能力得到进一步提升。
路径规划与避障方面,大多算法仅限于在二维仿真环境中进行训练和测试,实用性有待提高。一方面,仿真环境的建模要考虑水流、风浪、光照等环境因素;另一方面,无人艇不应该是简单的质点,其物理模型在构建时要考虑自身运动的实际情况,如横向纵向速度、转动角速度以及来自水流和螺旋桨的外力等;另外,在规划避障路径时,由于真实环境中遇到其他船舶时只有双方均安全航行才能保证避障成功,故双方应遵循相同的规则,比如海洋环境中考虑国际海上碰避规则,国内河流环境考虑中国内河避碰规则等。只有考虑到这些实际环境因素,才能产生实际可行的避障路径,提高避障于路径规划算法的适应性。
