面向三维重建的自适应步长视频关键帧提取
2023-09-15郑义桀陈卫卫罗健欣潘志松张艳艳孙海迅
郑义桀,陈卫卫,罗健欣,潘志松,张艳艳,孙海迅
(陆军工程大学 指挥控制工程学院,江苏 南京 210007)
0 引言
三维重建是利用二维图像恢复三维信息,以获得更直观的视觉效果。传统三维重建主要通过多视角的无序图像进行三维建模,因此对拍摄角度、图像清晰度要求较严格,且操作流程较复杂。随着多媒体信息发展,视频已成为信息的主要载体,相较于图像包含着更多信息,如果能通过视频进行三维重建将更有实际应用意义。
由于视频是连续图像帧的集合,基于视频的三维重建归根到底还是依赖多视角图像,但视频帧存在冗余量大、因相机抖动而造成图像模糊等情况,因此需要提取视频序列关键帧。当前,关键帧提取算法可分为基于时间间隔采样算法[1]、基于帧间差异提取算法[2-4]、基于内容聚类提取算法[5-7]、基于光流运动提取算法[8-9]。其中,基于时间间隔采样算法预先设定采样时间间隔,遍历所有视频帧提取关键帧,实现简单、速度较快、关键帧分布均匀,但在不同时间间隔下的结果存在较大差异,当相机处于非匀速运动时将造成部分关键帧冗余或缺失;基于帧间差异提取算法取视频第一帧为关键帧,与之后的图像帧逐帧比较相似度,当相似度小于阈值则提取关键帧,并以新的关键帧寻找下一关键帧,该方法能保留较多原视频的主要内容,但阈值的设定将直接影响关键帧提取的质量且计算量较大;基于内容聚类提取算法以图像间的相似性为度量,依据不同类间相似性最小、类内部相似性最大的原则,将图像聚类后从每类中选取一帧作为关键帧,虽然该方法图像冗余度相对较小,但聚类数目和聚类中心需提前设定,因此聚类数目和聚类中心设定的好坏将直接影响关键帧提取的质量且计算量较大;基于光流运动提取算法通过计算图像光点的运动信息,估计场景中相机的运动量,将一定时间范围内运动量最小的帧提取为关键帧,该方法需要计算运动量的局部极小值点,计算过程较复杂且消耗较长。
传统关键帧提取算法的主要目的是为了用尽可能少的图像代表整个视频,主要应用于视频检索和分类、目标检测和识别等任务。然而,三维重建任务需要在较清晰的图中提取关键帧,不同关键帧间还需具备较好的重叠度,因此需要改进传统关键帧提取算法,使其适应三维重建需求。陈旭等[10-12]采用一种层次化的设计解决该问题,但此类算法前期依然需要采用时间间隔采样来降低计算量,难以适应相机运动突变的情况。
为此,本文提出一种自适应步长视频关键帧提取算法。该算法结合基于多通道直方图欧式距离[13]的图像相似性度量算法和基于拉普拉斯梯度函数[14]的图像清晰性度量算法,可根据视频帧变换率和清晰度变换来实时确定视频帧采样步长,并剔除模糊视频帧。实验表明,该方法相较于传统算法,能提升视频关键帧采样的效率和质量。
1 自适应步长视频关键帧提取算法
本文算法总体流程如图1 所示,其中C代表清晰度,Cl代表清晰度阈值,S代表两幅图像的相似度,Sl、Sh分别代表相似度最低和最高阈值,step代表视频帧提取步长,K表示提取的关键帧。算法可分为两个阶段:

Fig.1 Adaptive step video keyframe extraction process图1 自适应步长视频关键帧提取流程
(1)自适应步长采样。根据图像间的相似度确定视频帧提取步长,目的是尽可能减少关键帧的提取操作和相似度、清晰度计算过程,以最快速度提取高质量的关键帧。算法开始时,假设相机匀速运动,按固定步长提取关键帧,一旦发现图像相似度增大则需增加步长,反之减小步长;如果图像清晰度较差则继续以原步长向前搜索,最后生成初始关键帧队列。
(2)深度去重。通过比较非相邻关键帧间的相似度,剔除相似度过高的关键帧,目的是避免因相机环绕物体拍摄而出现的前后场景重合的情况。该阶段将自适应步长采样阶段生成的初始关键帧队列的每个关键帧,与非相邻关键帧进行相似度计算,如果高于阈值则去除其中一个关键帧,最终生成关键帧队列。
其中,自适应步长采样阶段主要可分为以下3 个步骤:
步骤1:确定首关键帧。第一个关键帧的要求是清晰度高,为后续关键帧选取提供参照。从第一帧开始逐帧判断,满足清晰度要求即加入关键帧队列。
步骤2:确定初始步长。从第一关键帧后逐帧判断,将第一个满足清晰度和相似度要求的视频帧加入关键帧队列,并设其为参考帧,将两帧间的帧数作为初始步长。
步骤3:向前搜索关键帧。按照原步长在参考帧后向前搜索视频帧,此时有3 种情况:①当前帧满足清晰度、相似度要求时,将该帧加入关键帧队列并设为新的参考帧;②当前帧满足清晰度要求但相似度过低时,按照回退折半查找方法向后搜索关键帧;③当前帧满足清晰度要求但相似度过高或清晰度不够时,按原步长继续向前搜索关键帧。
1.1 回退折半查找关键帧算法
当前帧相似度过低进行回退折半查找时,由于视频变化存在一定规律,因此,一旦视频帧出现模糊帧,则此帧周围必然存在一定数量的模糊帧,为了提高效率,如图2 所示,若发现中间帧为模糊帧,则以本轮折半查找的最前帧作为关键帧,采用函数调用方式实现回退折半查找,如算法1所示。

Fig.2 Principle of split-half search for key frames图2 折半查找法搜索关键帧原理
算法1回退折半查找关键帧算法
1.2 向前搜索关键帧算法
当前帧相似度过高继续向前搜索关键帧时,同样采用函数调用的方法实现。如果当前帧相似度过高或出现模糊的情况,依然以原步长向前搜索;如果当前帧相似度过低,则采用回退折半查找方式搜索关键帧,具体流程如算法2所示。
算法2向前搜索关键帧算法
1.3 自适应步长视频关键帧提取算法
然而,回退折半查找法提取的视频帧并不一定满足相似度要求,也不能确定相机运动是否发生突变。因此,在更新步长时,如果当前关键帧与前一关键帧间的帧差与原步长不同,则需要判断两个关键帧间相似度是否满足要求,满足则更新步长,反之步长保持不变。自适应步长关键帧提取流程如算法3所示。
算法3自适应步长视频关键帧提取算法
1.4 关键帧队列深度去重算法
在深度去重阶段剔除非相邻关键帧间相似度过高的关键帧,具体流程如算法4所示。
算法4关键帧队列深度去重算法
2 基于多通道直方图欧式距离的图像相似性度量算法
2.1 算法原理
在本文提出的视频关键帧提取算法中,计算图像相似度是关键,目前基于直方图的相似度计算是较为常用的方法。首先进行灰度处理,记录像素灰度值;然后统计每个灰度的次数,生成图像灰度直方图;最后通过两个直方图的欧式距离代表图像相似性进行灰度处理,虽然能简化计算,但容易造成误差,尤其在三维重建中颜色不同将直接影响视角匹配的精确度。为此,本文采用基于多通道直方图欧式距离计算图像相似度。首先通过直方图欧式距离计算R、G、B 通道的相似性,然后计算3 个通道相似性的平均值,并将其作为两幅图像的相似性。对于任一颜色通道,两帧图像的直方图分别为H={h1,h2,…,hn}、G={g1,g2,…,gn},该颜色通道相似性可表示为:
式中:n为像素值划分数量,像素值范围为[0,255],为了提升比较效果,n取256。两幅图像的相似度可表示为:
2.2 相似度阈值
相邻两幅图像相似度需要设定合理阈值,相似度太高将造成图像冗余度大、后期三维重建计算量大;相似度太小则会导致图像匹配困难、三维重建精度不高。为了合理选择阈值,本文采用文献[15]的相机视角选择方式对每个视频帧进行评分。具体为,针对一段视频序列,首先选取某个图像i,计算该图像与其他图像j的匹配得分Score(i,j);然后按得分进行排序,选取得分最高的10 个图像。其中,匹配得分的计算方法如式(3)所示。
式中:p为图像i、j的可视三维点;θij(p)为p与视角i、j的相机中心连线夹角,计算方法如式(4)所示。
式中:ci、cj分别为视角i、j的相机中心。
Φ(θ)为分段高斯函数:
式中:θ0为一个确定的基线夹角,越接近该夹角得分越高,本文参照DTU 数据集参数设置方法,将θ0、σ1、σ2设置为5、1、10。
本文选取tanks and temples 数据集[16]进行测试,按照上述方法计算视频序列中每个图像与其他图像的匹配得分并排序。选取得分最高的前10 帧匹配图像后,计算各个图像与其他图像对应的10 帧匹配图像的直方图相似性,Museum、Panther、Horse、Family 视频结果如图3所示。

Fig.3 Matching image similarity between different video frames图3 不同视频帧匹配图像相似度
图3 横轴为匹配图像序号,纵轴为相似度。由此可见,每个图像与其匹配图像的相似度在0.60~0.90,且总体随得分呈下降趋势。此外,结合文献[10]中指出相邻图像相似度应低于0.88,因此本文将相似度阈值设置为0.60~0.88。
3 基于拉普拉斯函数的清晰性度量算法
3.1 算法原理
由于本文在评价图像清晰度时无参考图像,因此可将该问题归为无参考图像清晰度评价,采用常用的拉普拉斯(Laplacian)梯度函数进行计算。Laplacian 算子的定义如式(6)所示,图像清晰度函数定义如式(7)所示。
式中:G(x,y)为像素点(x,y)处Laplacian 算子卷积。
3.2 清晰度阈值
为确定清晰度阈值,研究tanks and temples 数据集中视频清晰度的变化规律。首先,对原图添加3 种不同程度的运动模糊[17];然后比较不同模糊下清晰度值发生的变化,Horse、Family 的测试结果如图4 所示。其中,横轴表示视频帧序号,纵轴表示清晰度。

Fig.4 Image sharpness changes after different degrees of blur图4 不同程度模糊后图像清晰度变化
由图4 可见,原图清晰度均在70 以上,经过模糊后清晰度下降明显,均在50 以下。为了尽量保证图像质量,本文将清晰度阈值设为70。
4 实验与结果分析
4.1 实验环境与评价方法
本文编程语言为Python,在Ubuntu18.4 Intel(R)Xeon(R)Gold 5118 CPU 系统上进行测试。首先提取视频关键帧,然后通过MVE[18]进行三维重建。MVE 是一个开源、基于传统方法的三维重建系统,从输入多视角图片开始,包含了运动重建、稠密重建、网格重建、纹理贴图整个流程。由于本文主要比较重建效果,因此只采用运动重建、稠密重建这两个模块。
将本文算法与时间间隔采样算法[1]、帧间差异提取算法[19]、K-means 聚类提取算法[5]和光流运动提取算法[8]进行比较,根据关键帧提取时间、关键帧数量、关键帧质量和三维重建质量分析各算法特点。具体的,关键帧质量包括有无模糊关键帧或相似度过高的关键帧;图像相似度过高定义为两幅图像间基于多通道直方图欧式距离>0.88;图像模糊定义为图像的拉普拉斯梯度函数值<70;三维重建质量主要用来比较重建的三维点云与真实物体的相似程度,可分为点云精确度和完整度。其中,精确度通过重建的三维点云与真实物体点云的距离来衡量,表示重建点的精度;完整度表示物体表面被重建的完整程度,一般以两者间的平均值作为最终点云质量的评价指标。
本文采用DTU 数据集评价计算方法,假设基准三维点云中空间点gi,重建点云距离gi最近的三维点ri的欧氏距离为di,具体精确度计算方式为:
式中:|R|表示重建点云中参与评价的点云数量,重建点云精度越高,精确度值Acc越小。
完整度计算方式为:
式中,|G|表示基准三维点云的空间点个数,重建点云的完整度越高,完整度值Comp越小。
整体度为两者平均值:
4.2 实验数据
通常情况下,以tanks and temples 数据集中的视频Caterpillar 片段作为数据集进行实验,但该视频均为高清视频且相机匀速运动,因此本文参考文献[20]的方法制作了一段虚拟视频Visual Car,并且虚拟视频通过人工控制相机运动,可方便、有效的评估视频帧提取算法。其中,Caterpillar 是高清匀速视频、Visual Car 是变速且包含模糊帧的视频。
本文利用Unity3D 引擎搭建了一个虚拟场景,设置相机匀速、加速和减速运动并增加抖动情况,因此该视频包含了变速和模糊情况,可有效检测算法在不同情况下的性能。图5 展示了两段视频中的部分视频帧,具体参数如表1 所示。为了比较点云重建质量,采用tanks and temples 数据集给出的Caterpillar 基准点云,Visual Car 的基准点云需手动制作。首先通过Unity3D 生成多视角图像和视角相机参数,然后通过深度学习多视角网络PatchMatchNet[21]生成三维点云,如图6所示。

Table 1 Video data parameters表1 视频数据参数

Fig.5 Video part video frame图5 视频部分视频帧

Fig.6 Datum point cloud图6 基准点云
4.3 实验结果
本文调整时间间隔采样算法的时间间隔、K-means 聚类提取算法的类间距和光流运动提取算法的光流变化阈值等参数,使3 种算法生成的关键帧数量与本文算法基本相同,并将帧间差异提取算法的帧间差异阈值与本文算法中相邻图像相似性阈值设置一致。
表2 展示了各算法提取Caterpillar 关键帧的结果,图7为重建的点云效果。由此可知,时间间隔采样算法耗时最少,但由于该算法不比较帧之间的变化,容易存在高相似帧情况,重建效果一般;帧间差异提取算法需比较每两帧间的差异,用时最长,不具备高相似帧,重建结果相对较好;K-means 聚类提取算法用时较长,存在高相似帧,重建结果最差;光流运动提取算法需提取图像光流信息并比较光流变化,耗时最长且重建点云完整性较差;本文算法耗时虽然为时间间隔采样算法的3 倍,但仅为帧间差异提取算法的1/13.5、K-means 聚类提取算法的1/9.1、光流运动提取算法的1/15,且不存在高相似帧,重建质量最优。

Table 2 Comparison of Caterpillar key frame extraction results表2 Caterpillar关键帧提取结果比较

Fig.7 Comparison of reconstruction effect of different algorithms in Caterpillar图7 不同算法在Caterpillar的重建效果比较
表3 展示了各算法提取Visual Car 关键帧的结果,图8为重建的点云效果。由此可知,时间间隔采样算法虽然耗时最短,但不存在高相似帧和模糊帧的识别能力,重建点云质量较差;帧间差异提取算法可剔除高相似帧,但提取时间最长且包含大量模糊帧,因此重建点云质量较差;Kmeans 聚类提取算法耗时长,包含高相似帧和模糊帧,重建点云完整性不高,存在较多杂点;光流运动提取算法用时最长,存在较多高相似帧和模糊帧,重建点云质量一般;本文算法用时虽然相较于时间间隔采样算法耗时更长,但仅为帧间差异提取算法的1/5.19、K-means 聚类提取算法的1/4.29、光流运动提取算法的1/5.56,且不存在高相似帧和模糊帧,重建点云质量最优。

Table 3 Comparison of extraction results of Visual Car key frames表3 Visual Car关键帧提取结果比较
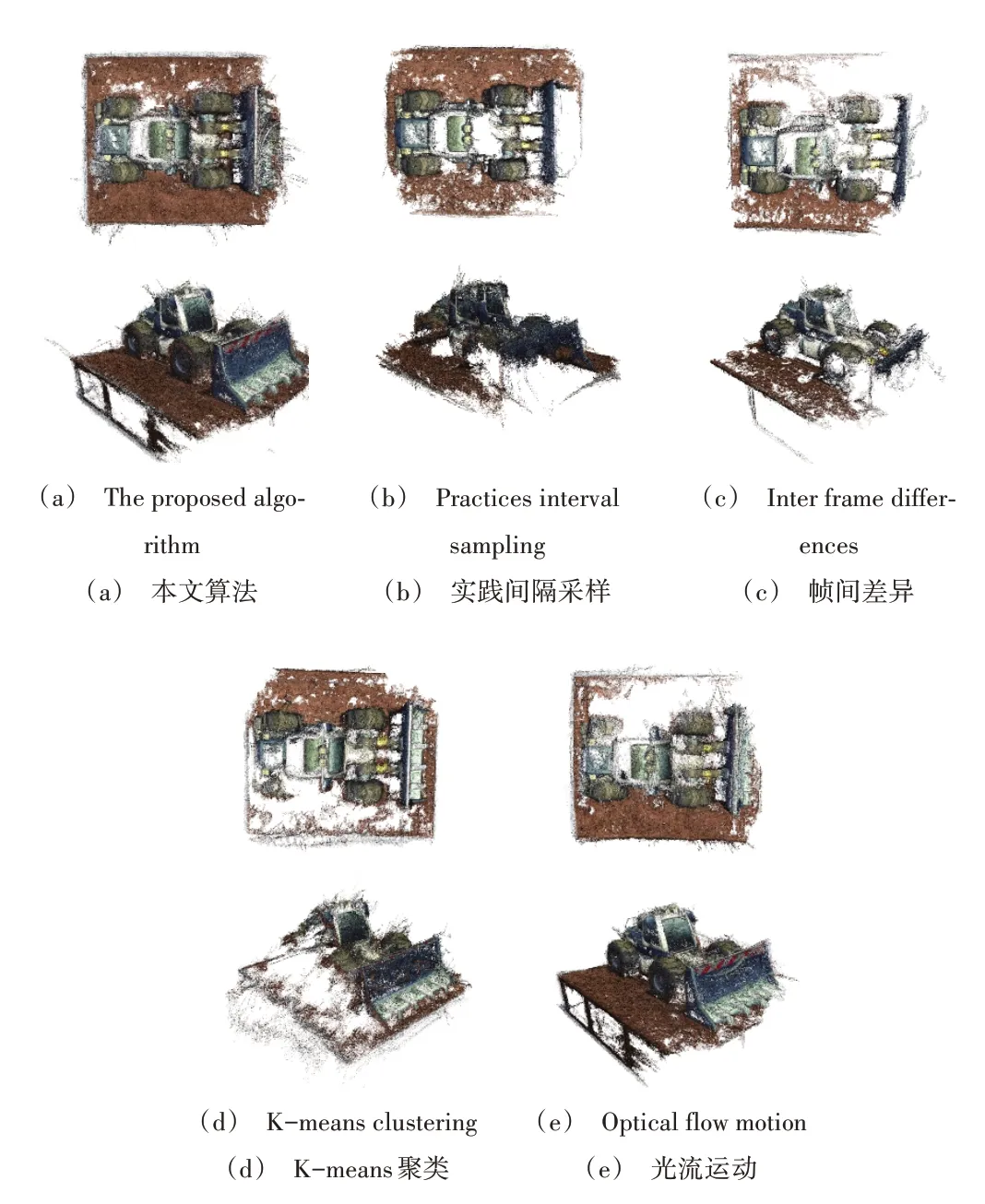
Fig.8 Comparison of reconstruction effect of different algorithms in Visual Car图8 不同算法在Visual Car的重建效果比较
综上所述,时间间隔采样算法需提前调整时间间隔,K-means 聚类提取算法需提前设置类间距,光流运动提取算法需提前设置光流变化阈值,因此难以适应动态变化的视频,且不具备高相似帧和模糊帧的识别能力。本文算法在高清匀速视频或变速模糊视频下,在提取关键帧时相较于现有方法存在一定优势。
此外,帧间差异提取算法计算量过大,且不具备模糊帧识别能力。本文算法通过设置步长可减少视频帧间的比较计算用时,通过清晰度判断剔除模糊帧、帧间差异的变化以动态改变步长,既保证了关键帧间具有较好的视角变化,又能快速确定下一关键帧的位置。
为了进一步比较算法的通用性,本文通过相机随机拍摄了3 个物体的视频,分别采用上述5 种算法提取关键帧,并采用MVE 进行三维重建,重建点云效果如图9 所示。由此可见,虽然本文提出的关键帧提取算法无法保证点云重建效果总为最优,但算法鲁棒性较强,重建的点云质量普遍较高。

Fig.9 Comparison of reconstruction effect of objects taken by camera图9 相机拍摄物体重建效果比较
5 结语
本文基于多通道直方图欧氏距离的图像相似性与拉普拉斯梯度函数的图像清晰度计算方式,提出一种面向三维重建的自适应步长视频关键帧提取算法。根据视频帧的变化快慢、清晰度,以实时确定视频帧采样步长、去除模糊视频帧。
实验结果表明,该算法相较于多种传统算法能提升视频关键帧采样的效率和质量,三维重建效果最优,但提取的视频关键帧数量仍然较多。下一步,将重点研究关键帧数量与三维重建效果的关系,以改进关键帧提取算法,进一步提升视频关键帧提取的效率和质量。
