基于通道注意力的人脸表情识别
2023-09-15王传安吕雅洁陈雪敏
李 堃, 王传安, 吕雅洁, 陈雪敏
(安徽科技学院 信息与网络工程学院,安徽 凤阳 233100)
人脸表情识别是人工智能领域的一个重要研究方向,随着注意力机制[1]的广泛运用,研究者开始更多地使用基于注意力机制的方法开展表情识别研究。和传统的神经网络相比,基于注意力的模型可以在提高精度的同时,解决长距离依赖问题,并提升网络的可解释性[2]。在计算机视觉领域,注意力可以放大特征图的差异性,提升关键部分的权重[3]。在图像分类任务中,常用的注意力模型包括SENet、ECANet和CBAM等。
SENet率先将通道注意力[4]引入到图像分类任务中,通过全局平均池化和2个全连接层提取通道注意力。由于采用降维操作,SENet在提取通道注意力时,在特征上有一定的损失。针对这一缺点,Wang等[5]提出了ECANet。该模型使用一维卷积代替SENet中的全连接层,在保留所有通道信息的同时,实现局部通道信息的交互。CBAM模型同时包括通道注意力和空间注意力[6]。模型分为CAM和SAM两个部分,采用串联的方式分别提取通道和空间注意力。在提取通道注意力时,CBAM也采用了先降维再升维的方式。
以上模型在图像分类领域中均取得了很好的效果,因此研究者们开始将这些注意力模型引入表情分类。王珏[7]采用改进的ECANet构建通道注意力,认为ECANet使用的全局平均池化不利于表情纹理特征的保留,因此为网络并联了一路全局最大池化,将2个通道特征向量融合得到新的通道特征。张鹏等[8]将多尺度特征和SENet相结合,先使用Inception结构和空洞卷积获得人脸表情特征在不同尺度上的信息,再利用SENet引入通道注意力,提升模型对于关键特征的表达能力。包志龙等[9]基于CBAM模型,先利用金字塔卷积实现表情多尺度特征的提取,再使用通道和空间注意力加强关键特征的权重。
以上方法均在表情识别过程中使用了基于SENet、ECANet或者CBAM的通道注意力,并且相较于传统深度学习模型,在识别率上有了一定的提升。但是这些模型也存在一些缺点:SENet和CBAM因为在全连接层中使用降维操作,导致通道信息不可逆的损失;ECANet虽然不再对通道信息降维,但是使用一维卷积导致信息只在相邻通道间融合,跨通道融合能力不足。因此,针对目前模型对特征利用不充分、跨通道交互能力不足的问题,提出了基于SENet的改进方法。
改进后的方法利用Inverted Bottleneck[10]代替原模型中全连接层先降维后升维的操作,更加充分地融合各个通道的注意力特征;将提取注意力时使用的ReLU激活函数替换为GELU,以优化Inverted Bottleneck带来的过度融合问题,并且GELU函数更加平滑,有更好的泛化能力和优化能力,可以提高模型的性能;同时,为了体现不同通道特征图对表情识别的贡献度,利用信息熵[11]提取各个通道的信息量,并和Inverted Bottleneck的输出融合,将信息量作为注意力提取的依据之一。最后对Inverted Bottleneck结构中升维倍数进行研究并获取最优值。在CK+和Oulu-CASIA库上的试验表明,改进的模型可以更加充分地利用和融合不同通道的注意力特征。
1 相关工作
1.1 Inverted Bottleneck
Bottleneck是一种瓶颈结构,在ResNet和ResNeXt等网络中被广泛运用。该结构中输入的特征先被降低维度,再升维恢复至降维之前。与之相反,Inverted Bottleneck先将输入特征的维度升高,再降维恢复至升维之前。这种结构最早出现在MobileNetV2网络,在Transformer中也使用了这种结构。受到MobileNetV2和Transformer的启发,文献[10]中的ConvNeXt网络提出了Inverted Bottleneck结构。图1对比了ResNeXt网络中的Bottleneck和ConNeXt网络的Inverted Bottleneck结构:图1的左边为ResNeXt中Bottleneck结构,右边为ConNeXt的Inverted Bottleneck结构。通过Inverted Bottleneck结构,ConNeXt网络在ImageNet上的精度从80.5%增加到80.6%,为了更好地利用通道信息,本研究将Inverted Bottleneck引入SENet结构中,并对维度放大倍数的取值做了优化,选取最优值。
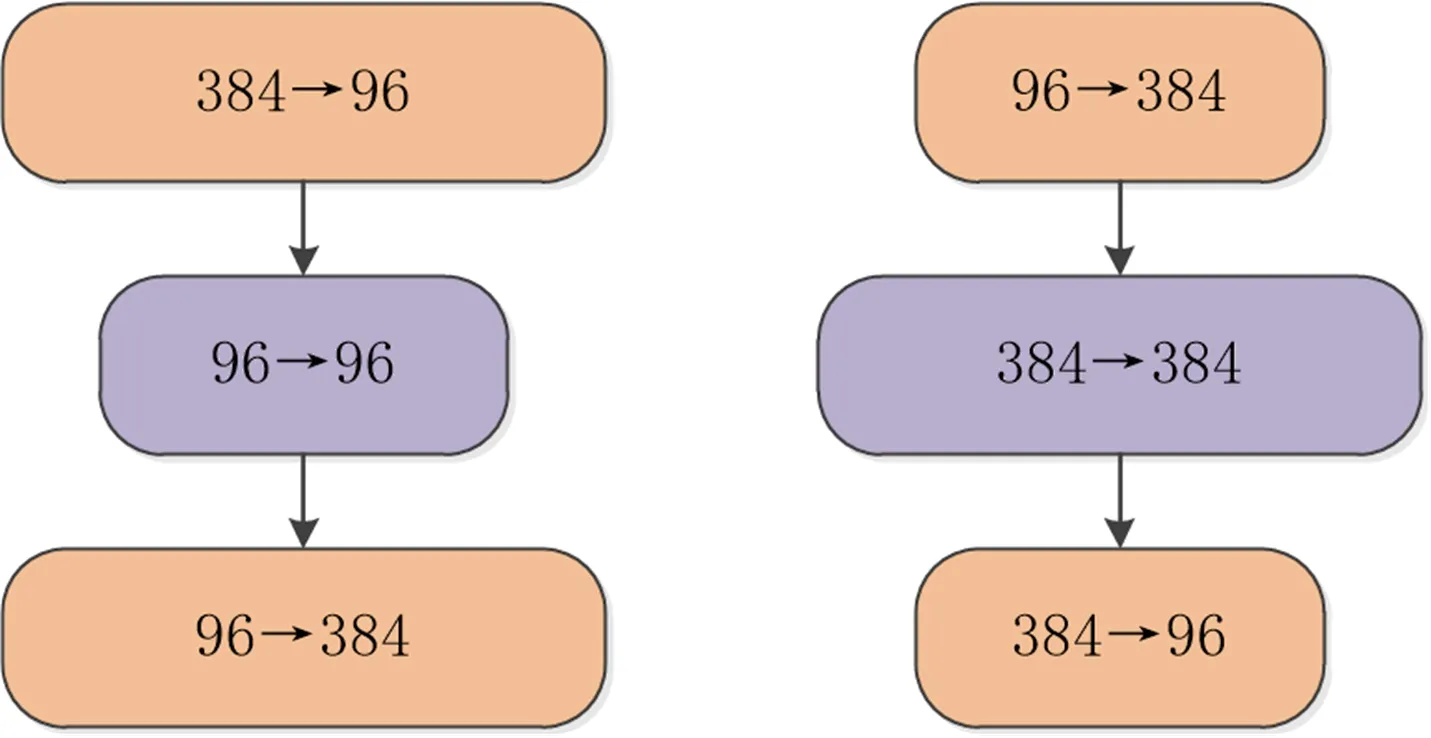
图1 Bottleneck和Inverted Bottleneck结构Fig.1 Structure of Bottleneck and Inverted Bottleneck
1.2 GELU激活函数
GELU是Transformer中常用的激活函数,可以看做是ReLU的平滑变体,是Dropout的思想和ReLU的结合。GELU函数具体形式如式(1)所示:
(1)
其中,μ表示正态分布的均值;σ示正态分布的标准差。
图2左侧为ReLU函数曲线,右侧为GELU函数曲线。可以看出,和ReLU相比,GELU表现出了更好的连续性。在自然语言处理中GELU表现出很好的性能,因此ConvNeXt网络将GELU激活函数用于计算机视觉任务并在精度上取得了一定的提升。
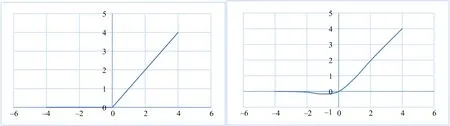
图2 ReLU和GELU函数对比Fig.2 Comparison of ReLU and GELU functions
1.3 信息熵
信息熵来源于信息论,用于描述一个系统中,某一属性值的不确定性,当熵值较高时,表明在系统中,该属性值的不确定性高;反之该属性值的不确定性低。对于离散型随机变量X,信息熵的计算公式如式(2)所示:
(2)
其中,X用于表示1个随机变量,x表示随机变量X的某一取值,p(x)用于表示随机变量X取值等于x时的概率。通过公式(2)可以看出,当随机变量X取值的可能性多时,其信息熵值就相对较高;随机变量X取值的可能性少时,其信息熵值就相对较低。因此通过信息熵的值,可以衡量随机变量X可能取值的丰富程度。
对于图像而言,信息熵可以反映图像某一特征在统计学上的丰富程度。在处理灰度图像时,选定图像的像素点灰度值分布特征计算图像的熵,计算方式如式(3)所示:
(3)
其中,H表示图像中灰度分布的信息熵,pi表示第i个灰度级的像素点在所有像素点中所占的比例,灰度图像的像素取值区间为0~255。当图像中各个灰度级对应像素点的数量较为均衡时,图像的信息熵就较大;反之图像的信息熵较小。本研究使用特征图的信息熵衡量各通道的重要性。
2 提出的方法
为更加完整有效地提取和融合特征图的通道信息,将SENet中提取通道注意力的2个全连接层改为Inverted Bottleneck结构。针对充分融合导致的过拟合问题,将GELU激活函数引入Inverted Bottleneck结构中,因为GELU函数更加平滑且兼具正则,所以在泛化能力和优化能力上更强。同时,将信息熵和注意力相关联作为先验知识,基于信息熵计算各特征图的信息丰富程度,并与Inverted Bottleneck输出相融合作为最终的注意力,也为网络引入了更多的归纳偏置。
2.1 Inverted Bottleneck和GELU
SENet中提取通道注意力使用2个全连接层,第1个全连接层对输入特征做了降维处理,第2个全连接层对特征维度进行还原。SENet中的2层全连接层可以看做是1个Bottleneck结构,这种结构在保证性能的同时降低了计算量。但文献[5]中通过实验证明了降维操作对通道注意力机制的预测产生了副作用,通道和全连接层的直连效果要优于Bottleneck。对表情识别而言,脸部微小的变化都可能对表情的类别产生影响,每个卷积核提取的特征图都可能对表情识别至关重要,因此需要完整的保留各特征图的信息。
文献[5]认为全通道之间的依赖是不必要的,因此使用一维卷积,提取相邻通道间的交互信息。但是对于表情识别任务而言,表情的表达是多种特征的组合,因此对不同特征图做更加充分的融合就显得非常重要。因此本研究使用Inverted Bottleneck结构,构建通道间更加丰富、更加完整的信息交流。
在人脸表情识别过程中,需要充分挖掘不同特征组合对分类的影响,完全基于Inverted Bottleneck容易导致所有特征的过度融合进而影响整体性能。受到ConvNeXt的启发,本研究将ReLU函数替换为GELU。GELU函数相比较ReLU,其函数本身提供了随机正则性,可以防止Inverted Bottleneck过于充分的融合导致的过拟合问题,能够更好地判断不同通道特征组合对表情的影响;同时GELU在0点附近的连续性更好,有助于保持小的负值,从而稳定网络梯度流。
Sinv=σ(W2G(W1Z))
(4)
其中,Sinv表示嵌入了Inverted Bottleneck的通道注意力权重,大小为1×1×C,C表示通道数。σ表示Sigmoid函数;W1为全连接层1的权重矩阵,维度为C×(C×e);W2为全连接层2的权重矩阵,维度为(C×e)×C,e表示扩张系数,是一个超参数,在实验中验证最优值。Z表示GAP操作的结果;G表示GELU激活函数。
2.2 通道信息熵计算
在表情识别过程中,不同通道的特征图对表情识别的贡献是不同的,在提取通道信息的时候,仅通过全局平均池化并不能够有效表达通道的信息。Wang等[12]在对神经网络进行剪枝操作的时候,以各特征图的信息熵值为依据,保留信息熵值高的特征图而去除信息熵值低的特征图。因为信息熵可以表达特征图包含信息的丰富程度,因此信息熵值大的特征图所包含的信息量比较高,对分类效果的影响也就会比较大。
受到文献[12]的启发,本研究使用信息熵值来衡量表情信息的丰富程度。为验证信息熵和表情信息的相关性,本研究将原表情图像做分块处理,横竖各平均分为4份,得到4×4个子块。分别计算图像各个分块的熵值。式(3)计算的是整张图片的信息熵值,计算各个子块的信息熵值方法和计算整张图片的信息熵值相同,但是把计算区域限制在分块之内,如式(5)所示:
(5)
当p为0时,设0log0=0。其中,Hb表示第b个子块的熵值,p(b,i)表示在第b个子图像中,第i个灰度级的像素点在整个小块所有像素点中所占的比例。原表情图和通过公式6计算各个子块信息熵后得到的分块效果如图3所示。

图3 信息熵分块效果Fig.3 Information entropy blocking effect
计算熵后的图像中,亮度较高的区域为信息熵值较大的区域,亮度较低的区域为信息熵值较小的区域。可以看出,对表情贡献度高的眼睛、嘴巴等区域包含的信息更加丰富,对应的子块亮度较高。将图3的效果推广到不同特征图之间的比较,则可以基于信息熵来判断特征图的重要性。
CNN可以使用更少的数据得到更好的模型,是因为其具备局部性和平移等变性2个归纳偏置。而认为信息熵高的特征图对表情识别贡献更大应该给予更高的权重,也可以看作是为情识别领域的归纳偏置。因此融合信息熵的通道注意力可以获得更多的先验知识。特征图的像素点数据和原图相比,数据更加分散,为减小特征图信息熵的计算量,先根据特征图信息将所有像素点的数值映射到1个整数区间[0,K]。映射方式如式(6)所示:
(6)
其中,xmap表示特征图像素点映射的结果,ceil(·)函数表示向上取整函数,xi,j表示特征图第i行第j列个像素点,min(·)表示取最小值函数,b的计算方式如式(7)所示:
(7)
其中,max(·)表示取最大值函数,K即为映射区间的上界。K的取值参考文献[12],设为32。
项目质量的好与坏决定于施工总承包单位的实力,整体管理水平,作为建设单位,控制项目质量的关键点在于施工总承包单位的选择。EPC建造模式的总承包单位可以更加科学地设计和管理,使承包单位不断的比较、对照、择优。传统建设流程通常是要等到施工图设计出图后,才进行施工承包商单位招标,这样会造成开工日期推迟,从而项目总建设周期也会因此而加长,同时施工总承包单位不能介入施工图设计就会对质量控制带来许多不利。
基于式(6)~(7),特征图信息熵的计算公式如式(8)所示:
(8)
其中,Xl,m表示第l层卷积第m个通道特征图,E(·)表示Xl,m的信息熵;Hl和Wl分别表示第l层特征图的高和宽;f(·)函数用于计算信息熵的统计直方图。
为了便于提取的信息熵值可以被训练,将通道信息熵输入1个全连接层并做激活,将结果和Inverted Bottleneck提取的信息融合作为最终的通道注意力。融合后的通道注意力既包含了特征图的平均特征,又包含了信息量特征,可以更好地为通道加权。
2.3 模型处理过程
结合Inverted Bottleneck、GELU和信息熵的注意力提取模型,处理过程如图4所示。

图4 模型流程图Fig.4 Model flow chart
图4中X表示输入的特征图,Cl、Hl、Wl分别表示第l层特征图的通道数、高度和宽度;Entropy表示对特征图求熵,AVG表示全局平均池化。FC表示全连接层,用于训练通道信息熵,FC的输入和输出均为Cl。FC之后的激活函数为Sigmoid函数。注意力融合过程中的符号“×”表示特征向量间的点乘。
特征图输入注意力提取模型后分为两路,分别基于信息熵和原始信息训练出两组注意力向量,然后将二者相乘得到最终的通道注意量,并和原输入特征图X逐点相乘,得到最终的输出。
3 结果与分析
实验基于Ubuntu系统、Pytorch 1.12.0和Python 3.8,显卡为NVIDIA GeForce RTX 3090,显存为24 G,CPU为AMD EPYC 7302。数据集选择了CK+和Oulu-CASIA表情库,这2个集合都是目前人脸表情识别应用较为广泛的数据集。
3.1 表情数据集
CK+表情库包含了123个被拍摄者的593个表情序列。本研究从中选择了327有标签的序列,将每个序列的最后3张图像用于实验,共获得981张表情图像。这些图像分为7类,包含135张愤怒、57张蔑视、177张厌恶、75张恐惧、207张高兴、84张悲伤和246张惊讶的表情图像。
Oulu-CASIA表情库由80位被拍者在3种光照强度下的表情序列组成,这些序列包含6种表情,分别为:愤怒、厌恶、恐惧、高兴、悲伤和惊讶。每种强度各包含了480个序列。每个序列也是由表情从初始到峰值变化的图像组成。选取每个序列最后3张用于试验,共获得1 440张表情图像,每类表情均为240张。
在实验前,对2个库的图像做了预处理:先转为灰度图,再通过MTCNN检测人脸,最终剪裁成224×224的大小。图5为预处理后各类表情示例,其中第1行是CK+库处理后的图像,第2行为Oulu-CASIA库处理后的图像。

图5 预处理表情图像示例Fig.5 Examples of preprocessing facial expression image
3.2 实验设置
实验时,批量大小设置为32,epoch次数为50,优化器为Adam,初始学习率为0.001,每10轮迭代学习率减小10倍。主干网络为ResNet18。试验时对数据做了增强,将集合内所有图片按照[-15°,-10°,10°,15°]进行旋转,旋转后数据集扩展为原来的5倍。增强后,CK+集合扩展为4 905张图像,Oulu-CASCI扩展为1 440张图像。
因为2个表情库只包含表情序列,并未区分训练集和测试集。因此本研究在2个库上使用了十折交叉法,试验过程中嵌入了Inverted Bottleneck和GELU的注意力模块放置于ResNet18网络的残差模块之后,如图6所示,CA模块被置于残差模块之后,通过CA模块获取的注意力和残差模块输出融合后,再与原特征X融合。
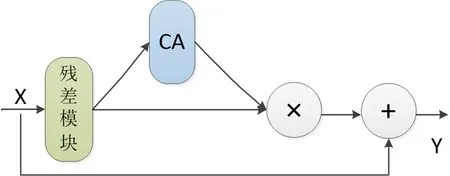
图6 嵌入位置Fig.6 Embedding position注:X表示输入特征图;CA表示通道注意力模块;Y表示输出特征。
3.3 Inverted Bottleneck实验
在Inverted Bottleneck中e是超参数,将提出的通道注意力模块嵌入ResNet18进行实验,并对超参数e的取值进行测试。表1中的Inv表示嵌入Inverted Bottleneck的网络,Inv后的数字表示e的取值,结果如表1所示。可以看出,在CK+库上直接使用Inverted Bottleneck模块,在e为1的时候识别率高于直接使用SENet,e为其他值时略低于SENet,说明e较大时产生了过度融合现象,而当加入GELU函数后,只有e为1时识别率有所下降,其他情况下识别率均有所提高。在Oulu-CASIA库上,在e为4的时候识别率略低于直接使用SENet,其他情况下均高于SENet,加入GELU函数后,从e为4开始,识别率均有所提升。2个库均是在e取8,并和GELU结合使用时,性能达到最佳。

表1 取不同e值识别率
3.4 对比实验
为验证本方法的有效性,将本模型和其他模型做了对比。本模型中的Inverted Bottleneck使用识别率最高的Inv8+GELU的组合。对比结果分别如表2所示,可以发现,在CK+库上本研究方法识别率高于其他方法。在Oulu-CASIA上本研究方法仅低于文献[18]的方法,并高于其他方法。因此基于Inverted Bottleneck和GELU的通道注意力可以提升人脸表情识别模型的性能。

表2 CK+对比结果Table 2 Comparison of CK+
CK+库上实验结果的混淆矩阵如图7所示。其中惊讶的识别率最高,达到了99.59%。高兴和厌恶等表情也取得了较高的识别率,分别达到了98.94%和98.87%。以上表情识别率表现很好,是因为表情特征明显且样本数量较多。蔑视、恐惧和悲伤的识别率较低,其中蔑视最容易被误识别为悲伤,恐惧容易被误识别为高兴,悲伤容易被误识别为生气。这是因为这些表情的样本数量较少,且和其他表情的相似性也很高。在Oulu-CASIA库上,当e取8时实验结果的混淆矩阵如图8所示。其中高兴和惊讶表情的特征最明显,因此识别率也最高,分别达到了98.08%和96.25%。生气和厌恶表情识别率最低,分别为86.08%和87.17%,且这2种表情彼此间的误识别率也是最高,这是因为在Oulu-CASIA库上,这2种表情的相似度很高,人工分辨也很难判断。
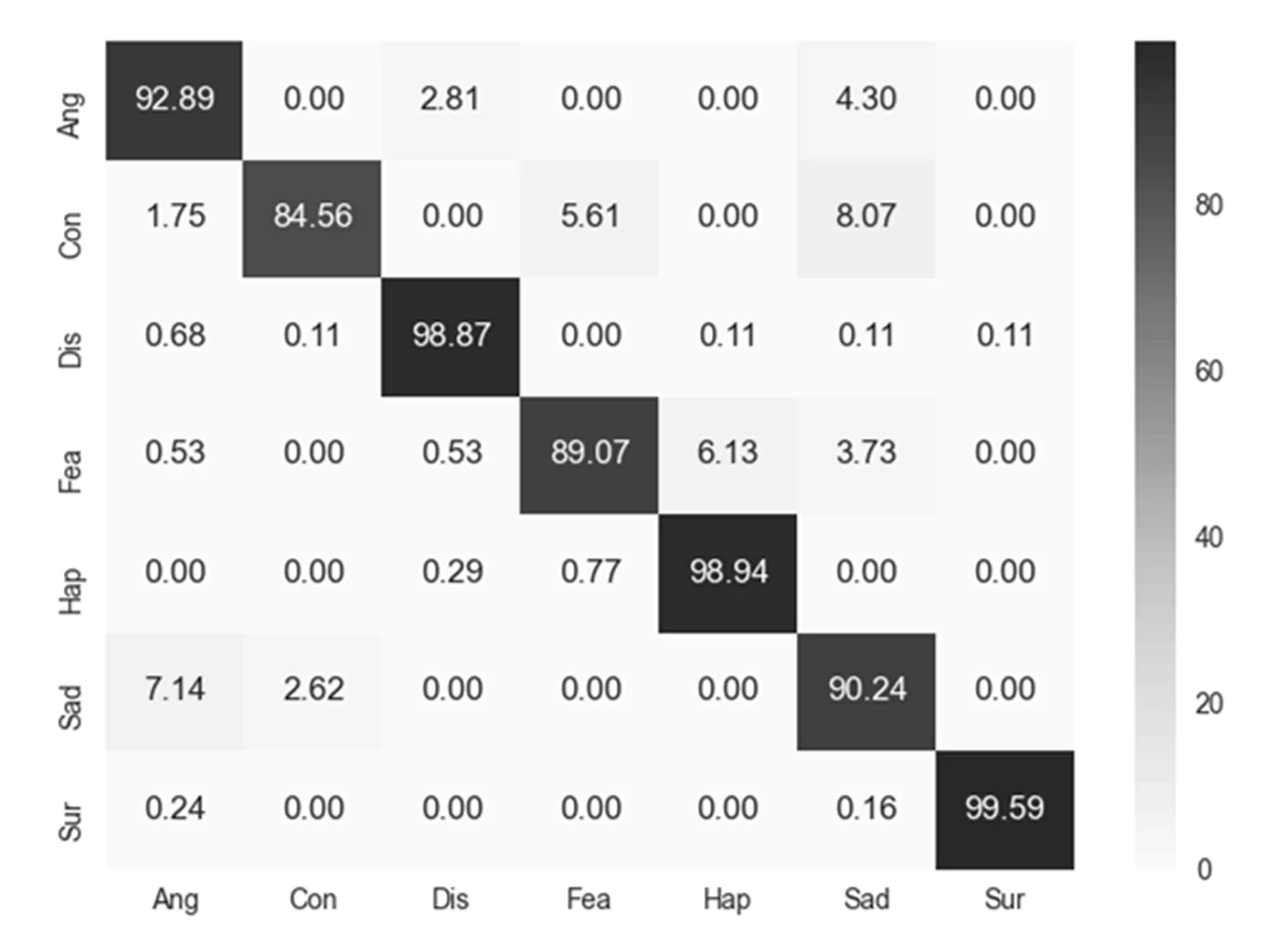
图7 CK+混淆矩阵Fig.7 CK+Confusion matrix

图8 Oulu-CASIA混淆矩阵Fig.8 Oulu-CASIA Confusion matrix
3.5 消融实验
为进一步验证模型的有效性,对本研究方法进行了消融实验,结果如表3所示。首先直接使用SENet和ECANet进行表情识别;然后将SENet中的ReLU函数改为GELU开展实验;再基于3.3节中的Inv1和Inv8开展实验;然后将Inv8和GELU相融合进行实验;最后将基于信息熵的通道信息和Inv8与GELU结合进行实验。表3中直接使用的SENet和ECANet的识别率较低且低于Inv1,说明在表情识别任务上跨通道信息的充分融合非常重要,而保留完整的通道信息有助于模型性能的提高。SENet+GELU方法的识别率在2个库上也较低,说明对降维后的通道信息使用GELU会导致性能的下降。Inv8+GELU组合高于Inv8,说明在充分融合通道信息的基础上,引入随机正则能够更加有效地提升方法的精度。最后,基于信息熵+Inv8+GELU的组合取得了最高精度,说明将信息熵融入注意力提取过程能够更加有效地提升网络性能。

表3 消融实验

表3 Oulu-CASIA对比结果
4 结论与讨论
表情是人类内心复杂情感的表达,面部不同区域的动作及其幅度的组合都会对表情产生重要的影响。针对这一特点,在表情识别任务中,需要完整保留卷积核提取的每一类特征,并对不同特征的组合进行充分的融合;同时,考虑到不同特征图包含的信息量不同,因此依据平均池化获取通道信息并不能够有效体现通道信息的差异性。目前经典的通道注意力模块均不能满足以上需要:SENet通道注意力因为使用了降维操作导致部分通道信息损失;ECANet因为仅仅捕捉了相邻通道信息导致了特征融合不够充分。因此本研究提出了基于信息熵和Inverted Bottleneck的表情识别方法,首先利用信息熵提取各通道特征图的信息量信息,然后基于全局平均池化保留特征图的原始信息,将2组信息分别训练后得到2组注意力向量,融合后对原特征图加权得到最终的输出特征。本方法中的信息熵将特征图信息量作为注意力的计算依据,能够更好地反应不同特征图的重要程度,而Inverted Bottleneck能够更好地保留和融合原通道信息,引入GELU函数则可以防止信息的过度融合。实验结果也验证了本方法的有效性。在后续研究中,将进一步完善注意力模块,在通道注意力的基础上引入空间注意力,以捕捉同一特征图不同区域对表情识别的影响。
