基于迁移学习的小样本织物图像自动分类与检索系统
2023-09-15游小荣李淑芳雍成宇
游小荣,李淑芳,邓 丰,雍成宇
(1.常州纺织服装职业技术学院, 江苏 常州 213164; 2.常州市生态纺织技术重点实验室,江苏 常州 213164)
织物图像分类与检索被广泛应用于库存管理、纺织品设计和电子商务等领域[1]。随着电子商务的快速发展及织物图像的井喷式增长,原有的手工分类、文本标注检索已经不能满足当前“以图搜图”的图像分类及检索要求,基于深度学习的图像分类与检索成为当前研究的热点。常见图像检索包括基于文本的图像检索和基于内容的图像检索。基于文本的图像检索需要大量的人工标注,检索词汇与标注词汇不一致导致检索效果差,且只适合某一国语言,存在诸多缺点,而基于内容的图像检索是一种检索图像内容且过程自动化的方法,在各领域被广泛应用[2]。根据特征提取方法的不同,传统基于内容的图像检索又可以分为基于全局特征的图像检索和基于局部特征的图像检索。其中,基于全局特征的图像检索方法主要提取图像的低级特征(如颜色、纹理、形状和空间信息),主要方法包括颜色直方图、Gaber、傅里叶描述子、空间金字塔匹配等,缺点是无法区分图像中的对象和背景[3]。Srivastava 等[4]通过小波变换方法提取纹理和形状特征,在不同数据集上精度范围为35.37%~99.99%,存在部分数据集提取精度低的问题。而基于局部特征的图像检索方法提取局部描述符的形式,更关注图像的关键点(如角点、边缘等),对缩放、旋转、平移、背景变化具有很好的鲁棒性,基于局部特征的图像检索方法包括SIFT、SURF、LPB、HOG、Harris、FAST等[3]。Sarwar等[5]提出使用LBPV和LIOP 2个描述子提取特征,并通过使用SVM方法进行分类,在不同数据集上精度范围为69.23%~89.58%,但该方法未考虑空间信息。
随着机器学习的广泛应用,特别是深度学习的兴起,使用深度学习算法提取图像的高维特征,可以很好地减少低级特征和人类视觉感知之间的语义差距[6]。Tzelepi等[7]通过使用卷积神经网络方法进行图像检索,精度达到了98.59%,该方法的优势在于通过卷积层之后使用最大池化的结果作为特征表示,最大限度保留空间信息的同时降低特征描述符的维度,不足之处是检索时间非常长。Sezavar等[8]结合卷积神经网络和稀疏表示方法进行图像检索,其中卷积神经网络用于提取高级特征并作为分类器来查询指定图像的类别,稀疏表示用来降低计算成本,提升检索效率,在ALOI数据集上精度可达97.06%。但是,基于卷积神经网络的图像检索方法也存在一些问题,如数据集需要几十万幅甚至上百万幅图像、标记多、训练时间长、样本数据不足时容易出现过拟合或者陷入局部最优的情况[9]。现实中有些领域的训练数据非常昂贵或者难以收集,因此段萌等[10]基于小样本数据集,通过对原图像进行平移、旋转等几何变换方法扩充样本量,并借助迁移学习的方法,实现小样本图像分类识别。
针对织物在电子商务、库存管理等领域的应用存在分类繁琐、检索精度不高以及训练样本不足等问题,本文设计并实现了一种基于迁移学习的织物图像自动分类与检索系统。首先,设计并训练基于迁移学习的图像分类深度学习模型;然后测试不同微调模型对织物图像分类模型精度以及不同预训练模型对织物图像分类模型精度的影响;最后设计并实现基于Milvus向量数据库的织物图像检索系统,并对其进行检索精度和效率测试。
1 基于迁移学习的分类模型构建
1.1 迁移学习
迁移学习指通过学习到的旧知识来学习新的知识,其目的是将已经学会的知识快速迁移到新的领域中[11]。迁移学习是解决图像分类目标训练数据有限问题的一种非常有效的方法[10]。Tan等[12]将深度迁移学习分成了4类:基于实例的深度迁移学习、基于映射的深度迁移学习、基于对抗的深度迁移学习和基于网络的深度迁移学习。其中,基于网络的深度迁移学习指用在源域中预训练的部分网络(包括其网络结构和连接参数),将其迁移为在目标域中使用的深度神经网络的一部分。本文织物图像分类也选择这种基于网络的深度迁移学习方法。
1.2 基于迁移学习的织物分类模型
基于上述迁移学习理论,借助ImageNet大数据集训练好的预训练模型,保留或微调用于特征提取部分的网络,而分类层部分因为预训练模型和实际需求输出的类别数不同,需重新设计;然后基于小样本数据集,训练未被冻结的网络及重新设计的分类层,在训练过程中,将准确率最高时对应的模型作为新的分类模型。图1所示为基于迁移学习的织物分类模型,在实际应用过程中,输入未经过训练的织物测试图像,经新模型计算后,输出织物种类,并将图片放在相应分类的文件夹,实现织物自动分类。

图1 基于迁移学习的织物分类模型Fig.1 Fabric classification model based on transfer learning
2 织物图像检索系统
随着织物图像集的不断增加,传统的图像检索方法非常耗时,通过使用向量数据库进行图像检索,可满足亿级图像检索时间控制在1 s以内的实际需求。常见的向量数据库包括Milvus、Faiss、Hnsw等。由于Milvus具有支持语言多、高性能、可分布式集群、高可靠性等优点,本文选取Milvus作为向量数据库。此外,Milvus向量数据库对于浮点型的特征向量支持欧式距离和内积等相似度计算方法,其中内积方法要求数据进行归一化,归一化后与余弦相似度方法等价。
图2为织物图像检索系统的运行过程,首先将数据集中所有织物图像经过新模型提取特征向量,先删除模型中的分类层,再通过网络输出特征向量;然后将提取到的所有特征向量保存到Milvus向量数据库,并将图片路径信息保存到MySQL关系数据库;将待测织物图像上传至系统,经新模型输出特征向量,选择内积相似度计算方法,与Milvus向量数据库存储的特征向量进行相似度运算,实现top k检索;最后,通过web应用程序呈现top k检索到的织物图像。
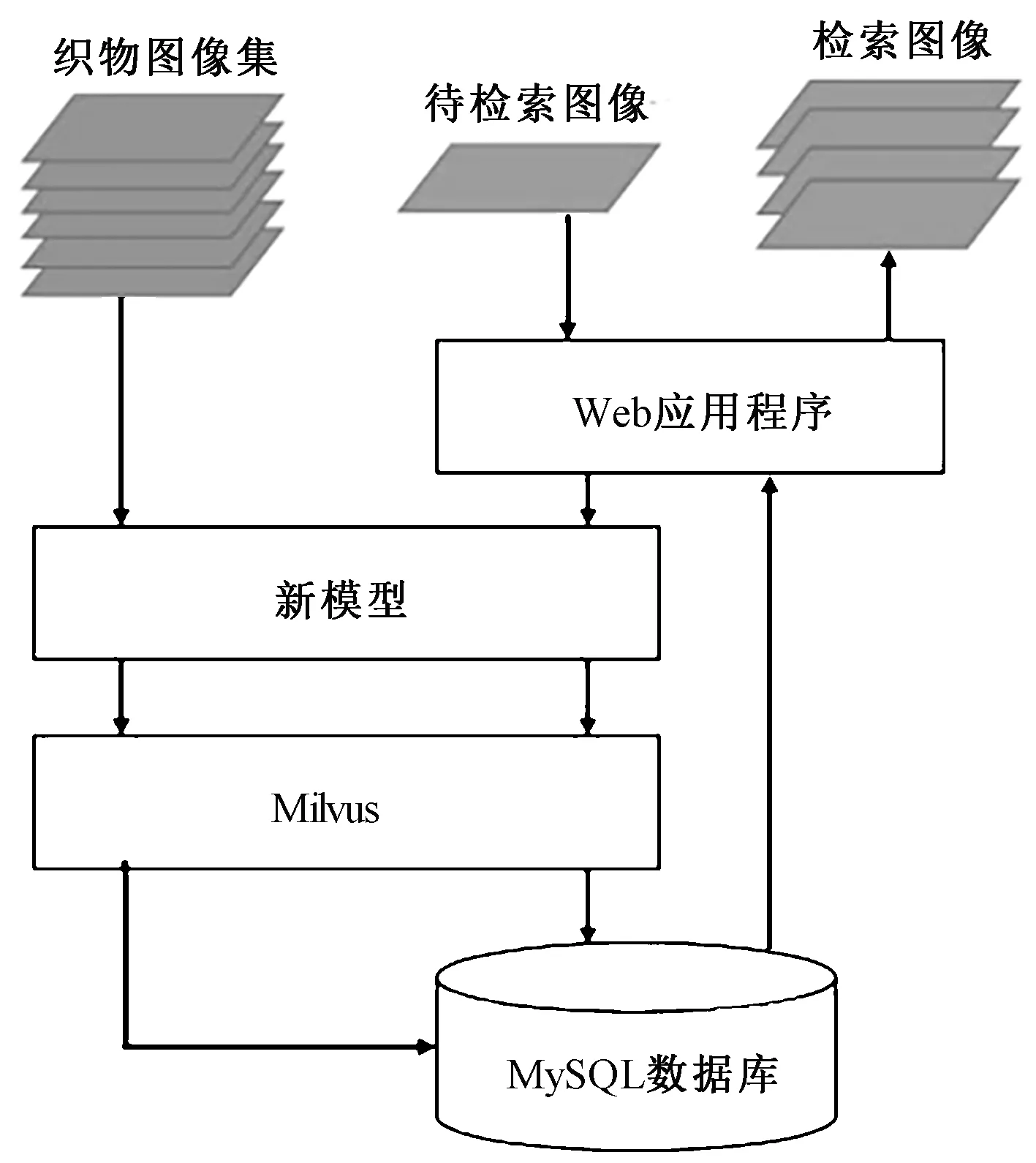
图2 织物图像检索系统Fig.2 Fabric Image Retrieval System
3 织物图像分类与检索实验
3.1 实验数据集
实验数据集的图像来源于国内织物生产企业。将图像分成迷彩、花类、格子、纯色、条纹5类,每一类图像选取500幅,共计2 500幅,80%图像用于训练,20%图像用于训练过程验证,另外再选取200幅未经过训练和验证的织物图像,用于分类与检索测试。实验数据集部分织物图像如图3所示。

图3 数据集中部分织物图像Fig.3 Some fabric images in the dataset
3.2 实验环境
实验硬件及软件环境如下:
硬件:Intel(R) Core(TM) i7-5500U CPU @ 2.40 GHz 2.39 GHz、16 GB内存、无GPU。软件:win 10操作系统(64 bit)、Python 3.10.2、Pytorch 1.11.0+CPU。
3.3 模型选择与微调
Pytorch环境下图像分类预处理模型包括ConvNeXt、DenseNet、AlexNet、Inception、ResNet、VGG等,以ResNet50模型为例,对网络进行微调实验如图4所示。预处理模型前9层用于特征提取,输出向量2 048个,分类层包括1个全连接层(fc),采用线性分类,处理后输出向量1 000个。微调实验包含4种微调方案,方案1和方案2保留模型特征提取层中的参数,只训练分类层,输出向量都是5个,方案1采用简单的线性分类,方案2则采用三级网络进行分类;方案3和方案4则冻结到layer3,后面未冻结部分和分类层则重新训练,方案3、4分类层部分分别采用线性分类和三级网络进行分类。
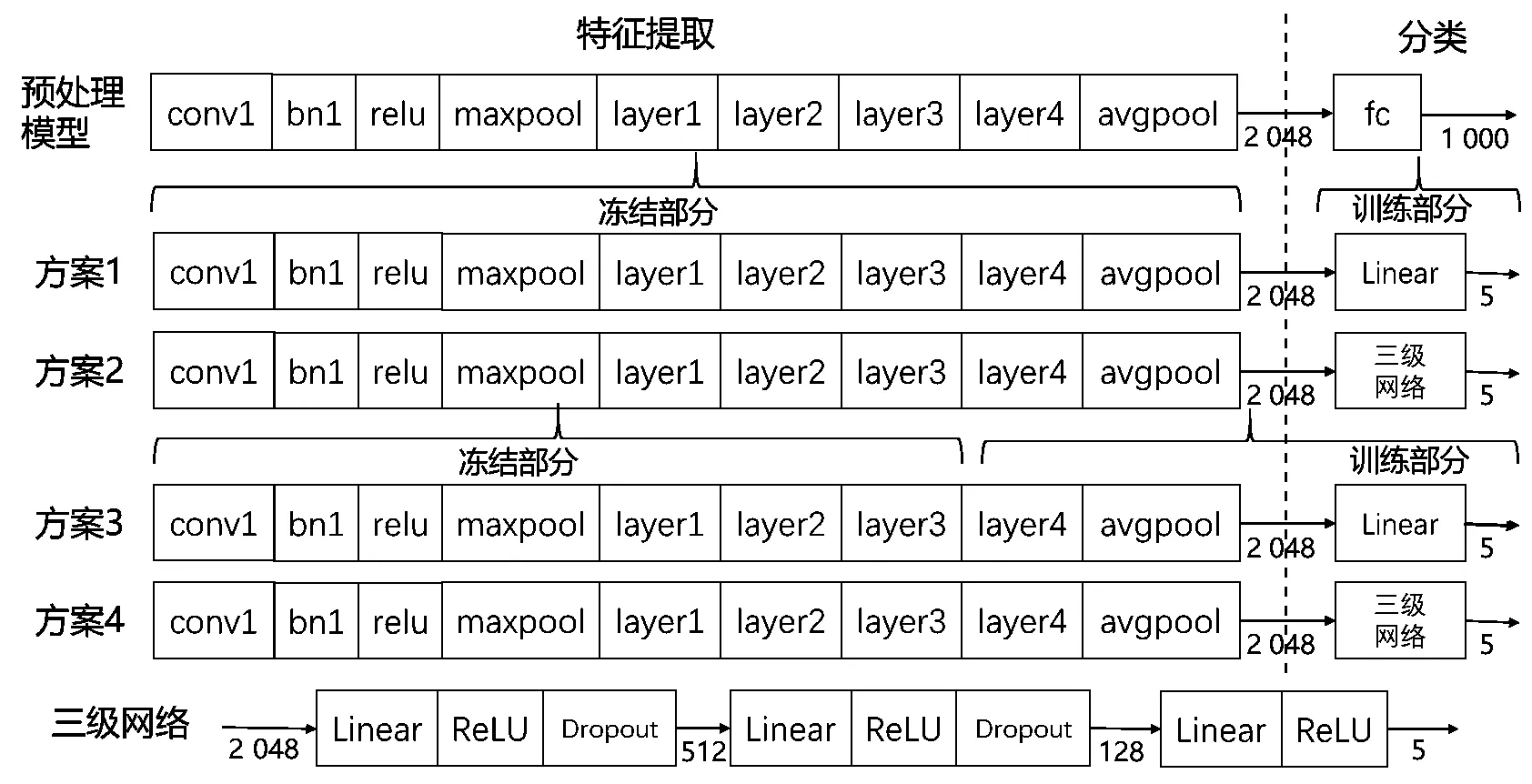
图4 ResNet50模型微调方案Fig.4 ResNet50 model fine-tuning scheme
3.4 训练过程与参数选择
构建好微调模型后,需对这些微调模型进行重新训练。具体训练步骤为:①深度复制模型参数;②判断所有的步长是否训练完成,如果是,跳至步骤⑩执行,否则继续;③间隔选择训练模式和验证模式,如果选择训练模式,继续执行步骤④,否则跳至步骤⑤;④加载1个批大小的标签和图像数据;⑤将参数梯度归零; ⑥前向运算,经过模型输出数据并计算损失值; ⑦如果存在验证模式提供的损失值,则进行后向传播并优化; ⑧完成1组批大小后,累计计算平均损失率和平均准确率,更新最佳模型及最佳准确率等参数; ⑨输入验证用的图像数据,根据网络输出值,计算损失值;⑩完成1个步长后,选择最高准确率及对应的模型,深度复制网络参数,输出新模型。
训练过程中,步长设置为50,批大小设置为16,学习率(lr)为0.001,Momentum为0.9,损失函数选择交叉熵损失函数,梯度下降算法选择随机梯度下降算法(SGD)可以获得较好的训练效果。
图5为上述4种方案训练过程中对应的准确率和损失率。从4组训练结果看,方案3最优,最高训练准确率为98.84%、验证准确率达到了99.01%。此外,对部分用于特征提取的网络层参数进行优化,比全部保留特征提取的网络层参数要好,分类层采用三级模型不如一级线性模型。

图5 4种方案训练过程对应的准确率及损失率Fig.5 Accuracy rate and loss rate in the training process of the four schemes
3.5 织物图像分类实验
新模型生成后,将训练模式改成评价模式,为织物图像分类实验做好准备。对比经过微调后的ResNet50、AlexNet、VGG 16模型在本文测试集上的平均分类精度,如表1所示。3种模型微调后分类精度都在98%以上,ResNet50微调后的模型分类精度略高一些,达到了99.5%。

表1 不同深度学习模型对应的平均分类精度Tab.1 Average classification accuracy corresponding to different deep learning model
3.6 织物图像检索实验
为了测试每个分类模型的检索效果,选用平均精度均值(mAP)进行衡量。表2所示为top 5检索后mAP对比情况,其中文献[13]方法虽然也使用了预训练模型,但未进行微调训练,直接提取特征向量并进行检索实验。从表2可以看出,ResNet50模型优于其它模型和文献[13]方法。
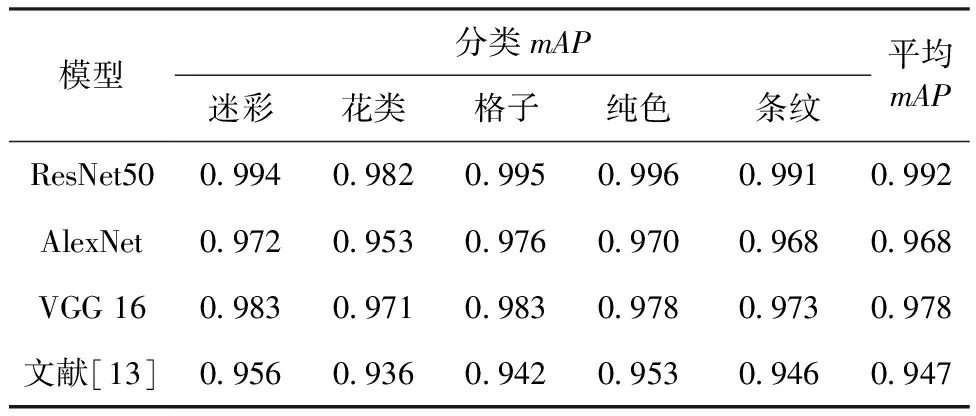
表2 各模型平均精度均值对比情况Tab.2 Comparison of the average mAP of each model
从分类来看,花类的分类mAP相对低一些。如图6所示,图6(a)为待检索图像,图6(b)为ResNet50模型检索结果图像,其中图6(b)第2、3张检索类别发生错误,对应的相似度分别为0.795和0.793,说明花类图像种类繁多,会发生与迷彩图像相似的情况,从而导致检索结果错误。

图6 部分分类错误情况Fig.6 Some misclassification cases(a)Unretrieval image; (b)Retrieval result
此外,利用平均查准率和查全率2个指标定量验证模型对整个数据集检索的效果,表3所示为top 5检索后平均查准率和平均查全率对比情况。可见基于ResNet50的检索精度优于其他方法。
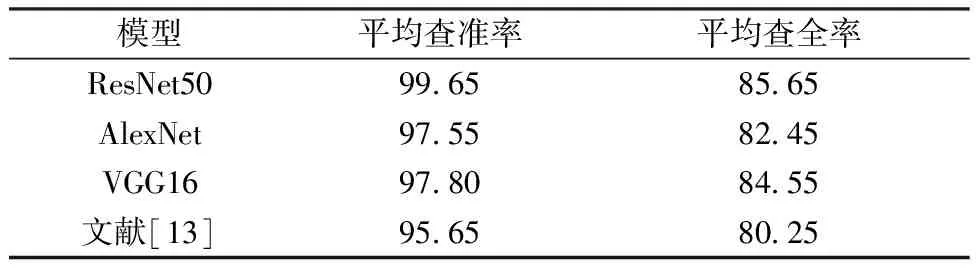
表3 不同模型平均查准率和查全率对比情况Tab.3 Comparison of the average precision and recall of different model %
最后,选取训练和验证数据集,提取所有图像的特征向量,并保存到Milvus向量数据库,再基于未经过训练和验证的200幅织物图像,进行织物图像检索效率测试。图7所示为基于Django框架开发的web织物图像检索软件对一个查询图像的检索结果。待测织物图像经过软件上传后,提取特征向量,并与存储在Milvus向量数据库中的特征向量集进行基于内积方式的相似度运算,排序输出top 5检索结果。经过对200幅织物图像的测试,统计出平均每幅图像的检索时间为0.165 3 s。

图7 基于Django框架的web织物图像检索软件Fig.7 Web fabric image retrieval software based on Django framework
4 结 论
通过基于迁移学习的织物图像分类方法解决手工分类、小样本、分类精度及检索精度不高的问题,采用Milvus向量数据库解决图像检索效率低的问题。实验结果表明,针对织物图像分类问题,对部分用于特征提取的网络层参数进行优化,比全部保留特征提取的网络层参数更好,分类层采用三级模型不如一级线性模型;模型选择方面,基于ResNet微调后的模型分类和检索精度均优于其它模型,分类精度达99.5%,top 5检索的平均精度均值可达0.992、平均查准率为99.65%。此外,经过测试发现,采用Milvus向量数据库后平均每幅图像的检索时间为0.165 3 s,实用性强。通过系统的实施,可为小样本织物图像分类与检索领域现存问题提供可行的解决方案。
