城市轨道交通投资估算大数据分析与BIM 集成展示
2023-09-15张全秀ZHANGQuanxiu安晓冬ANXiaodong陈梦洵CHENMengxun王浩任WANGHaoren安文章ANWenzhang
张全秀 ZHANG Quan-xiu;安晓冬 AN Xiao-dong;陈梦洵 CHEN Meng-xun;王浩任 WANG Hao-ren;安文章 AN Wen-zhang
(①石家庄市轨道交通集团有限责任公司,石家庄 050035;②北京城建设计发展集团股份有限公司,北京 100037)
0 引言
土建投资估算大数据分析基于初步设计概算设计项目历史数据,利用随机森林等机器学习算法挖掘不同设计参数、环境地质、施工资源配置条件下,实现迅速对总体设计阶段车站、区间及人防工程的工程造价的评估预测,并结合BIM 数据集成与可视化展示的特点进行三维交互集成展示,迅速形成总体设计方案整体效果,辅助决策。
1 数据范围
投资估算数据资源为北京市某五条线地铁项目中的投资概算信息,包含车站工程、区间工程、车辆段与综合基地、轨道工程、人防工程等工程投资概算数据。每一个单项工程概算信息又包含工程信息和综合概算信息,且各工程包含数据形式和内容相似。以车站工程概算数据为例,车站工程信息和综合概算信息,包含有车站长度、车站宽度、基坑深度、板顶覆土、出入口(含安全口、无障碍口)数量、风亭数量、车站总建筑面积、主体建筑面积、出入口通道建筑面积、风道风井建筑面积、出入口地面厅建筑面积、风亭建筑面积以及车站土建总造价等工程建筑信息和车站主体、出入口通道、风道风井、施工监测量测、视频监控和施工门禁、车站装修和车站附属设施等工程费用信息。
2 数据需求
2.1 输入数据
按照不同的工程(车站工程、区间工程、车辆段与综合基地、轨道工程、人防工程等)进行划分,分别进行投资估算模型的建立,并确定该工程的输入数据,以车站工程投资估算为例(不同工程的输入数据相似但略有不同),其投资估算模型的输入数据。(表1)
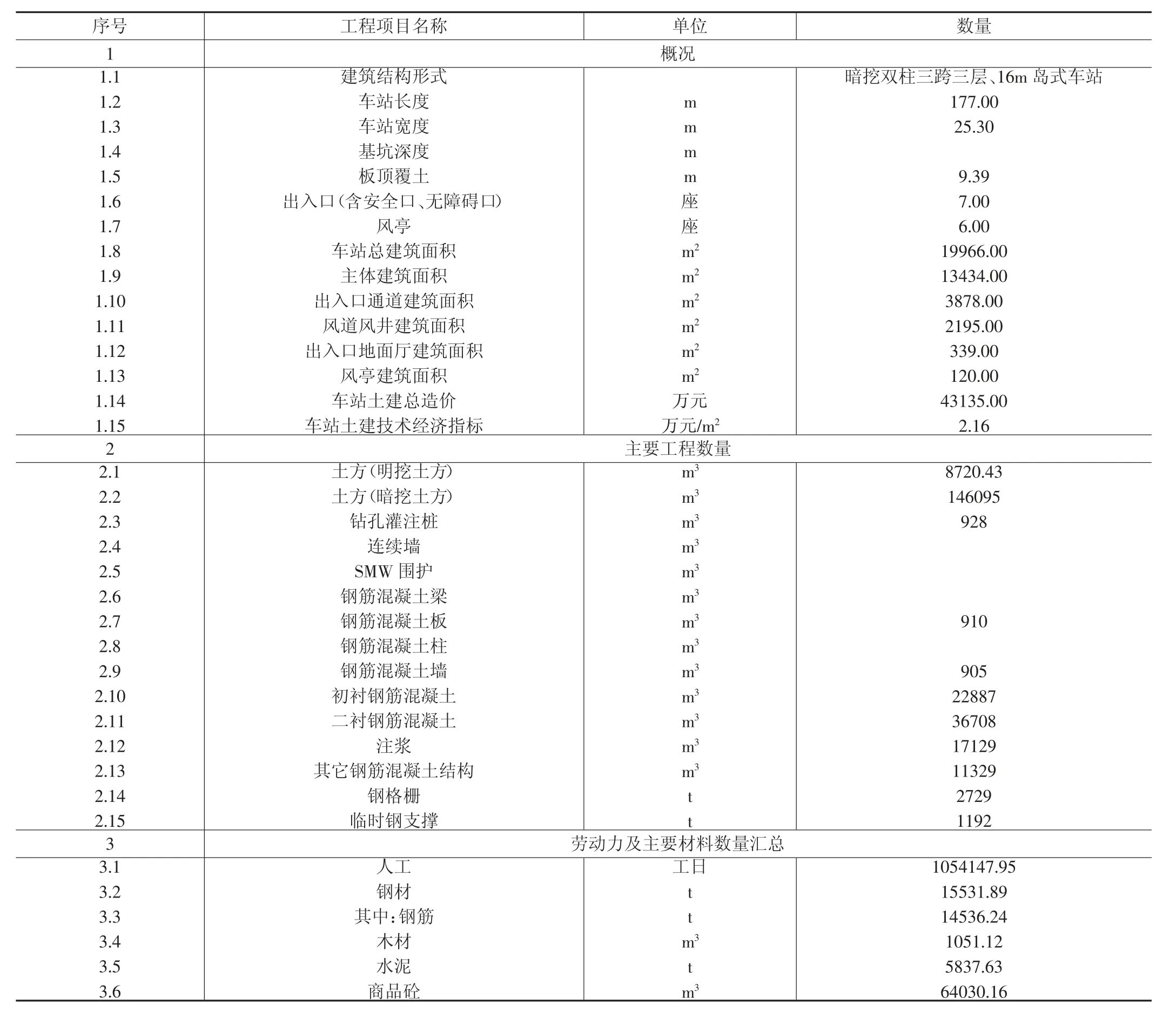
表1 工程信息(车站)
2.2 输出数据
按照不同的工程(车站工程、区间工程、车辆段与综合基地、轨道工程、人防工程等)进行划分,分别进行投资估算模型的建立,其模型输出为各工程的估算总造价。以车站工程投资估算为例,其投资估算模型的输出数据如表2、表3 所示。

表2 影响因子输出数据说明

表3 造价预测结果输出数据说明
3 分析逻辑
由表1 可知,工程信息共有39 个字段,按照工程信息的不同类型,可以分为int,float,varchar,三种类型,通过在给出的样本数据中找到最相似的的目标数据样本。
4 数据处理
对相应数据进行预处理,以满足后期采用算法的需要[1]:
①对缺失的数据用0 表示;
②对varchar 字符串字段采用数字转化的方式以满足数据计算的需要,例如,结构名称映射表转化{“缺失”:0,“A 建筑”:1,“A 建筑”:2};
③通过把结构名称转换成int 类型数据以满足后期数据处理的需要,为避免数据分布不均而影响算法结果的准确性,对数据进行标准化、分布统一化处理,处理公示如下:,其中:m 表示字段数据的平均值;s 表示字段数据的标准差;X 表示需要标准的数据值;X*表示标准化过后的数据值。
5 算法分析
样本数据集有100 条左右数据,目的是从这100 条左右数据中找到与目标数据最相近的样本,可以通过回归算法来计算数值来选取数值最详尽的样本,可以通过聚类算法来通过样本分类来找到与之相近的数据[2]。
5.1 常见的相似度计算方式
①欧式距离计算方式,主要用来计算样本在欧式空间中的距离计算,容易被少数大数值的维度所影响;②曼哈顿距离计算方式,主要用来计算样本的城市街区距离计算,计算样本的非直接距离,在目前需求中只需要考虑直接距离;③切比雪夫距离计算方式,主要用来计算样本的数值差的绝对值计算,计算样本的数值差的绝对值计算;④马氏距离计算方式,主要用来量纲无关的欧式空间距离计算,在协方差矩阵是对角阵的情况下就是标准化欧式距离,考虑计算复杂度,没有必要使用;⑤标准化欧式距离计算方式,主要用来标准化过后的欧式空间距离计算,在一个多维空间中找到一个与目标样本距离最近,相似度最高的样本,但是由于不同维度的数据可能存在不同的分布如果某一个维度的数据取值很大,那么结果很可能就被这个维度的数据所决定,所以需要解决不同维度数据分布的问题,在进行标准化过后的数据满足数学期望为0,方差为1,这样各个维度的数据相当于有了相同的数据分布,那么在多维空间中,每个维度对于距离的贡献度就变成了一致的,不会受某几个维度产生过大的干扰。
5.2 推荐算法:标准化欧式距离
计算方法:在上一步的数据标准化处理后,视样本为n 维向量(n 为样本字段数:100)。
两个n 维向量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的标准化欧氏距离的公式:
xij:i 代表第i 个样本,j 代表第j 个字段变量
d12代表样本1 与样本2 之间的距离后续记为d1:2,现有100 个样本数据集,与一个目标样本,通过数据处理后的标准化数据,将这100 个样本数据集和1 个目标样本转化为向量分别两两计算标准化欧式距离,目标样本为101,求出来的结果为:
为避免距离最小结果只取一个可能会导致由于数据同一字段的差值又不同字段相似来弥补造成的误差,所以建议最后取3 个与目标函数距离最近的样本:
Min(d_array,3)
取d_array 中距离最小的3 个样本,为我们需要的与目标样本最近的样本。
6 伪代码流程
数据集datas=[X1,X2,X3…… X100]
目标数据target=X101
映射集dict1={“A 名称”:1,“B 名称”:2}
距离结果集d_array =(100)[float] 长度为100 的浮点距离结果集
标准化函数normal_function(column_data)参数为对应字段所有的数据
标准化欧式距离计算函数distance_function(data1,data2)参数为待求距离的两个样本数据
最小值函数min(d_array,n)参数1 为距离结果集,参数2 为number 为从小到大排序前n 个值
Step1:
for data in datas: #对现有数据进行循环计算
for column in data: # 对每条数据的每个字段进行循环计算
If data[column] is null:#对空值进行处理
data[column] = 0
If data[column].type is varchar:
data[column] = dict1.get(data[column]) # 根据字符串字段值转换为对应int
Step2:
for data in datas: #对现有数据进行循环计算
for column in data: # 对每条数据的每个字段进行循环计算
data[column] = normal_function(datascolumns)# 对样本的对应字段标准化计算
Step3:
for data in datas:
distance = distance_function(data,target)
d_array += distance
Step4:
data1,data2,data3 = min(d_array,3)
data1,data2,data3 为需求结果
7 BIM 集成示范应用平台可视化
安全性评价可视化界面包含三部分:一是安全事故影响因素分析;二是事故预警分析;三是安全等级评价分析[3]。
土建投资估算可视化实现主函数为:Feature_analy sis,该函数主要利用随机森林算法、相关性算法等对土建投资估算进行影响因素分析,得到影响投资估算的关键因素并确定其关键影响指标和权重排序以及最终的投资估算总造价。最终可视化输出为影响投资估算的关键因素(如板顶覆土、出入口、风亭、车站总建筑面积等)和关键因素的排序和权重(如板顶覆土权重、出入口权重、风亭权重、车站总建筑面积权重等)以及车站工程土建总造价,本模块分析结果可视化如图1 所示。

图1 影响因素分析结果界面
通过BIM 数据集成平台,以单位工程(车站或区间)的数据ID 关联模型,进行定位展示。
8 总结与建议
在对样本数据进行了空值处理,字符串转化,标准化过后,通过选取与目标样本标准化距离最小的3 个样本为最终结果。
在此需求中由于各个数值贡献度不一样,标准化过后可能最后结果不够准确,因为标准化过后各个字段的贡献值没有差别,如果不进行标准化那么数值分布较大的占比会比较重,但是明显不应该仅仅因为数值较大就占比高,所以如果可以应尽可能提高数据量,然后通过回归算法来估算近似样本,在目前数据量下回归算法不足以学到足够的参数保证结果;后续可根据样本数量的增加可以选择相应的回归算法进行相似度计算,进行pca 降维对数据进行预处理,对线性相关的维度进行降维处理,减少计算复杂度,避免数据维度相关的影响[4]。
