多尺度注意力机制的双路人群计数网络
2023-09-14石祥滨吕浩杰
石祥滨,吕浩杰
(沈阳航空航天大学 计算机学院,沈阳 110136)
密集人群计数的目的是统计拥挤场景中人的数量,通常当人的聚集密度达到5.26人/m2及以上时称为密集人群。密集人群计数广泛应用于公共场所大规模人群踩踏、暴乱等重大事故的预警。然而,由于密集人群存在人的目标比较小、互相遮挡、尺度变化大等问题,通常难以准确计数,需要设计相应的算法,通过生成密度图对人数进行估计。
密集人群计数方法分为传统方法和基于卷积神经网络的方法。主要包括基于检测的方法和基于回归的方法。基于检测的方法通过检测人群中的每个行人来解决人群计数问题,这种方法具有一定效果,但在人群密集和严重遮挡的场景下效果较差。而基于特征回归的方法需要事先人为地构建人群图像特征,对特征的有效性要求较高,同时忽略了空间信息,导致局部区域的计数结果不准确。近年来,基于卷积神经网络的方法成为主流,然而,由于密集人群存在严重的重叠遮挡、尺度变化、视角扭曲、旋转、光照变化和天气变化等问题,单幅图片的人群计数仍是一项非常具有挑战性的任务。为了解决这些问题,研究者开展了大量的工作。为了解决极度密集人群图像计数问题,Wang 等[1]提出了一种端到端的深度卷积神经网络(Convolutional Neural Network,CNN)回归模型。该模型能够自动从图像中提取特征,提高了计数的准确性和效率。为解决人群尺度变化带来的性能下降问题,研究者提出了各种多分支结构,Zhang 等[2]提出了一种使用多列卷积神经网络进行人群计数的方法,不同的列使用不同大小的卷积核,分别处理大、中、小3 种不同尺度的人群。然而,由于计算量大且不能有效利用各分支学习的特征,导致不能获得令人满意的计数效果。为了降低网络的复杂度,Li 等[3]采用单列卷积神经网络结合空洞卷积的形式,有效扩展了接受域,以捕获上下文信息。然而,空洞卷积的特性带来训练过程中信息不连续的问题,导致该方法没有达到最理想的效果。为了应对背景干扰问题,Zhu 等[4]提出了一种基于视觉注意力机制的人群计数模型,通过生成注意力掩膜图指导网络进行密度图估计,从而有效地应对背景干扰。然而,该模型存在双列子网络参数量冗余、缺少显式模块来处理尺度变化等问题。Hossain 等[5]尝试使用注意力机制来引导网络自动聚焦人群所在区域,然而该方法的模型参数量和计算复杂度过高,在高密集区域的场景中效果依旧不佳。此外,研究者还从多任务学习、非监督学习等角度进行了人群计数研究,但人群尺度变化大和背景干扰问题仍是影响人群计数的关键因素。
综上,本文提出多尺度注意力机制的双路人群计数网络(two-way crowd counting net‐work with a multi-scale attention mechanism ,TWCNMA),旨在解决人群尺度变化大、背景干扰、特征融合导致的语义失调。TWCNMA由4 个部分组成:第一部分是以尺度增强模块(Scale Enhancement Module,SEM)和多尺度模块(Multi-scale Module,MSM)为核心的特征提取网络,可以捕获并融合不同尺度的特征,增加对人群尺度变化大的适应性;第二部分是多尺度注意力特征融合网络,通过构建以上下文注意模块(Context Attention Module,CAM)为核心的特征金字塔形式的多尺度注意力特征融合网络来促进不同语义级别特征之间的流动,同时缓解不同级别特征存在的语义失调问题;第三部分是注意力掩膜分支网络,通过生成注意力掩膜来抑制密度图回归过程中存在的背景干扰问题;第四部分是密度图生成,通过融合注意力掩膜和相应的密度图,网络能够生成高质量的密度图,从而使得全局人数估计更加准确。
1 多尺度注意力机制的双路人群计数网络
为了解决人群尺度变化大、背景干扰、特征融合导致的语义失调3 个问题,提出多尺度注意力机制的双路人群计数网络(TWC‐NMA),模型的具体结构如图1 所示,包括4 个模块:特征提取网络、多尺度注意力特征融合网络、注意力掩膜分支网络、密度图生成。在TWCNMA 中,使用VGG16[6]主干网络作为特征提取器,提取人群图像不同尺度的特征,然后通过多尺度注意力特征融合网络实现不同尺度特征的融合,得到人群密度图和背景密度图。同时,使用注意力掩膜分支网络生成注意力掩模图和背景密度图。最后,将相应的密度图和掩模图融合,得到最终的人群计数密度图。
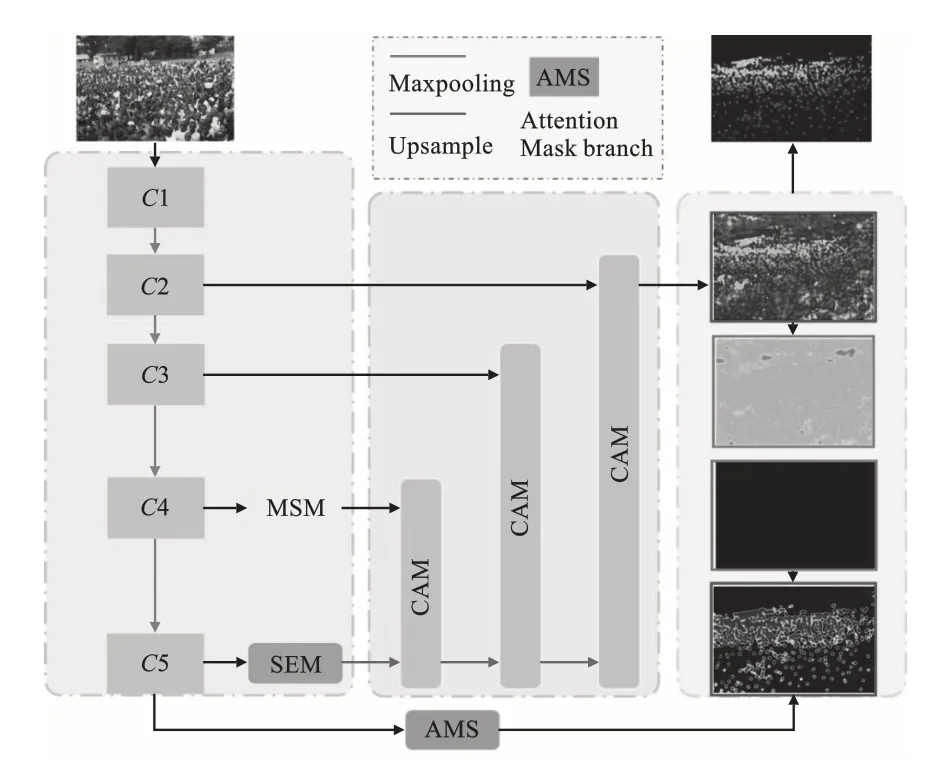
图1 TWCNMA网络结构图
1.1 特征提取网络
TWCNMA采用在ImageNet数据集上预训练的VGG16 网络作为基线网络,用于特征提取。得益于其出色的特征提取能力和便于迁移学习的特性,能够避免训练数据样本不足导致的过拟合。特征提取网络VGG16 的5 个子模块 Block_1、Block_2、Block_3、Block_4、Block_5 生成的特征,按照从下到上的顺序,分别表示为C1、C2、C3、C4、C5。由于浅层特征具有较多噪声,故选择C2、C3、C4、C5作为后续网络的输入。
此外,本节提出的尺度增强模块和多尺度模块,分别部署于C5和C4的后端,生成相应特征图,作为后续多尺度注意力特征融合网络的输入。
1.1.1 尺度增强模块
尺度增强模块(SEM)可以在多个感受野大小上明确提取特征,并学习图像上每个特征的重要性,从而增强对尺度快速变化的适应性。如图2所示,对于输入的特征图,首先按照4 个级别进行平均池化。由于人群图像具有场景复杂、目标众多且人群规模和尺度变化大的特点,因此本文将4 个级别的池化尺寸依次设置为1×1、2×2、3×3、6×6,通过多尺度池化操作,可以得到多个大小不同的子区域。之后,将各自比例的池化结果通过大小为1×1 的卷积降维,并且通过双线性插值操作将其上采样,使得此时的特征图尺寸等于输入尺度增强模块的特征图尺寸。然后,将4 个不同分支的特征先通过大小1×1 的卷积,再通过Sigmoid 函数得到不同分支的权值特征图。将权值特征图与之前各自分支特征图进行对应元素相乘,得到4 个加权特征图。将4 个加权特征图在通道维度上连接起来,得到与原始输入特征尺寸一致的特征图,随后与原始特征图拼接。最后,使用一个大小为1×1的卷积对拼接后的特征图进行跨通道融合并降维,从而产生模块的最终输出。
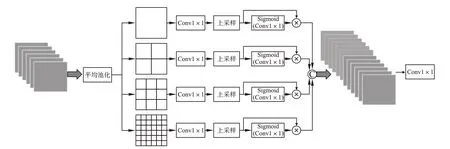
图2 尺度增强模块结构图
1.1.2 多尺度模块
多尺度模块(MSM)使用不同膨胀率的空洞卷积来提取目标对象的多尺度特征,并将这些特征级联在一起,以获取全局上下文信息。通过级联不同尺度的特征,MSM 可以同时捕捉到目标对象的局部和全局特征,从而提高目标对象的识别和定位准确性。如图3 所示,对于输入尺寸为H×W×C 的特征图,在每个分支上,首先通过1×1 的卷积将通道数降为输入特征图的1/4。接着,利用空洞卷积提取具有不同感受野的特征,生成尺寸为H×W×C/4 的特征图。然后,将4 个分支的特征图在通道维度上拼接起来,生成H×W×C 的特征图。最后,使用1×1的卷积聚合信息,生成尺寸H×W×C的多尺度特征图。

图3 多尺度模块结构图
1.2 多尺度注意力特征融合网络
多尺度注意力特征融合网络旨在解决密集人群计数任务中不同语义级别特征之间的流动问题以及特征融合导致的语义失调问题。网络采用特征金字塔的形式,由多个层次组成,其中每一层次都包括了不同尺度的特征图,使用特征金字塔生成不同尺度特征图的过程,如式(1)所示。在每个特征图层次中,引入了以上下文注意力模块(Context Attention
Module,CAM)为核心的多尺度注意力机制,能够提取不同尺度特征图的全局和局部上下文信息,并通过注意力机制使得特征之间的流动更加顺畅。同时,CAM还能够缓解不同级别特征融合导致的语义失调问题。图4 为CAM 的结构示意图。
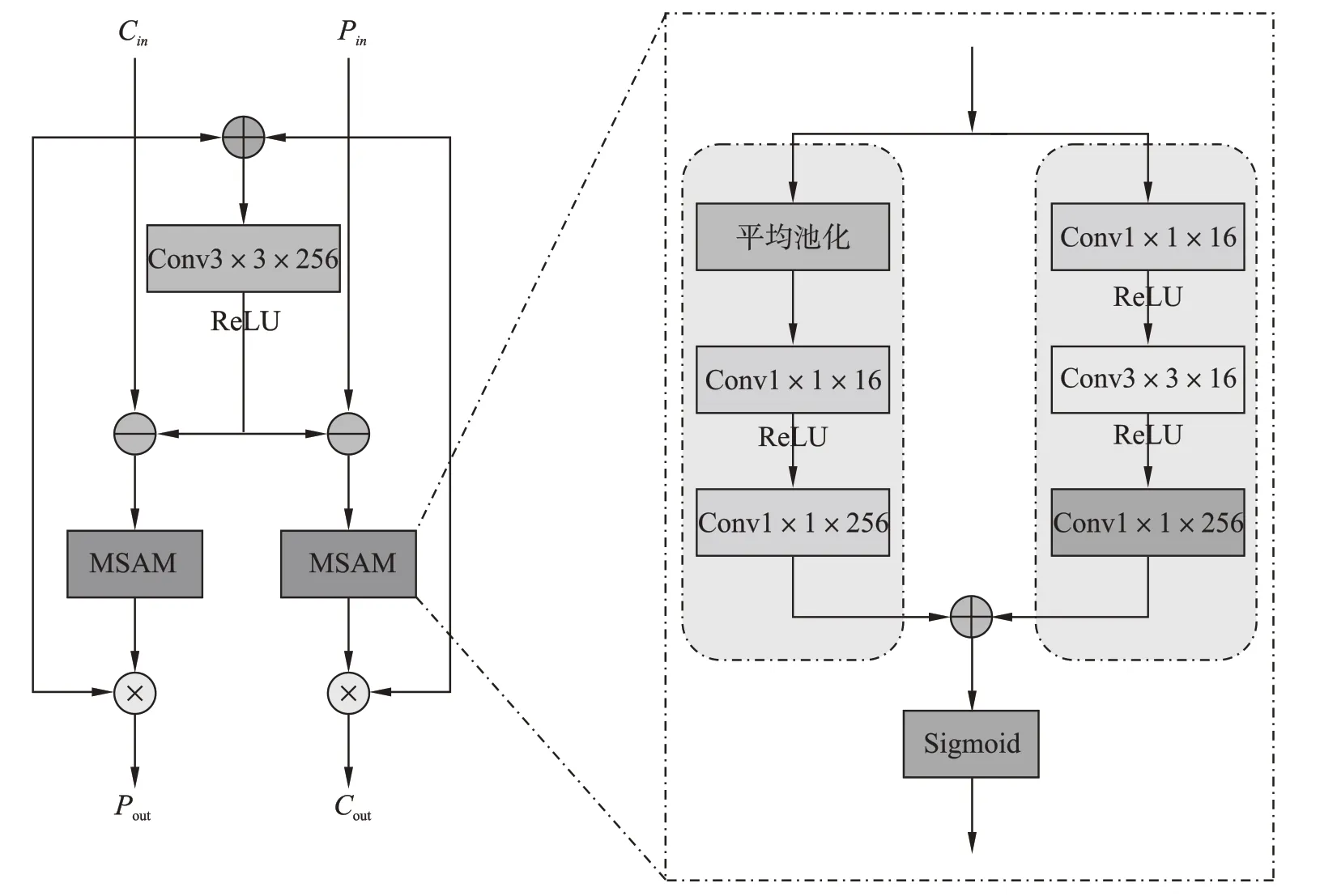
图4 上下文注意力模块结构图
式中:up()为双线性插值函数;Concat()为将两个特征图在通道维度上进行连接;Conv1×1()为进行1×1 卷积;Pi为生成的特征图;Ci为VGG16生成的不同尺度的特征图。
CAM 首先对输入的特征Cin和Pin逐像素相加求和,并将结果传递给一个3×3 的卷积层以获得联合特征表示。然后,将联合特征分别与不同级别的特征做逐像素的相减求差操作,以强调特征Pin和Cin的重要性。最后,将不同级别的特征通过多尺度注意力模块(Multi-Scale Attention Moudle,MSAM)来感知更多的空间细节信息,并生成相应的特征权重图。多尺度注意力模块包括两个子分支:全局上下文提取模块和局部上下文提取模块。在全局上下文提取模块中,输入特征首先通过全局平均池化层来聚合全局空间信息。然后,通过两个1×1的卷积捕获各通道间全局依赖关系,得到全局上下文特征。在局部上下文提取模块中,不使用全局平均池化层,而是使用一个3×3 的卷积来捕获局部上下文特征。最后,将提取的全局和局部上下文信息进行融合,得到多尺度上下文语义特征Pout和Cout。
1.3 注意力掩膜分支网络
密集人群计数通过生成密度图并对其计数来得到人数。然而,在实际情况下,检测的图像往往会受到严重的背景干扰,导致生成的密度图受到背景噪声的影响,从而影响计数性能。为了减少背景干扰的影响,提升计数性能,设计了注意力掩膜分支网络。
如图5 所示,注意力掩膜分支网络由5 个结构组成。第一个结构是大小为3×3 的卷积,通道数为256。接下来的3 个结构与第一个结构类似,都是大小为3×3的卷积加双线性插值,区别是卷积核的通道数分别为256、128、64。最后一个结构是大小为3×3 的卷积,通道数为32。注意力掩膜分支网络的输入为特征提取网路得到的C5特征图,经过注意力掩膜分支网络的处理得到32 通道的R5 特征图。然后,通过使用一个大小为1×1的卷积进行通道拼接并执行Sigmoid 操作,得到人群注意力掩模图。最后,通过阈值筛选得到背景注意力掩膜图。
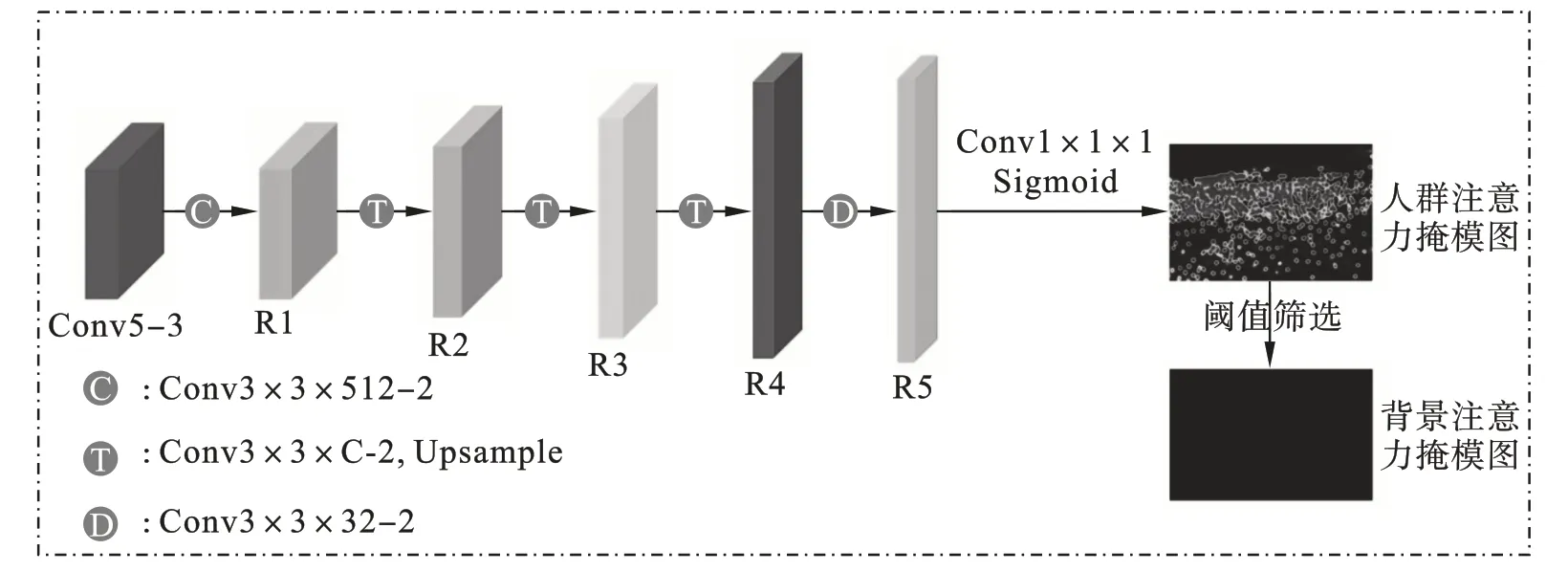
图5 注意力掩膜分支网络结构图
假设fatt为R5 特征图,则通过注意力掩膜分支网络生成的人群注意力掩膜图和背景注意力掩模图的过程分别如式(2)、(3)所示
式中:W 和b 是1×1×1 卷积层的权重和偏置;⊗为卷积运算;Sigmoid 为Sigmoid 激活函数。Sigmoid 激活函数给出(0,1)概率得分,使得网络能够区分头部位置和背景
式中:阈值设置为0.001;i 是相应人群注意力掩模图中的一个坐标;Matt(i)是相应人群注意力掩膜上像素点的值;Matt2是得到的背景注意力掩膜图。
1.4 密度图生成
在人群计数任务中,可以采用以下步骤来生成密度估计图。首先,将输入的图像经过特征提取网络提取多尺度特征。接着,通过多尺度注意力特征融合网络生成粗略的人群密度图和背景密度图,同时通过注意力掩膜分支网络生成相应的人群注意力掩膜图和背景注意力掩膜图。然后,将粗略的密度图和相应的注意力掩模图按位相乘,得到更精确的人群密度图和背景密度图。接下来,使用一个大小为1×1的卷积动态学习两者之间的关系,从而得到较为准确的人群密度图和背景密度图。最后,将人群密度图和背景密度图相加求和,得到最终输出的密度估计图,以上过程可以用式(4)、(5)表示
式中:fden1为人群密度图;MAtt1为人群注意力掩膜;fden2为背景密度图;MAtt2为背景注意力掩膜;⊗为对应元素相乘;F1为人群密度图;F2为背景密度图;Conv1×1()为1×1 卷积;+表示对应元素按位相加。
1.5 损失函数
对于密度图回归任务,使用均方误差损失函数进行优化,均方误差损失函数定义如式(6)所示。除了密度图回归任务外,在注意力掩膜分支网络中,使用两个交叉熵损失函数来监督生成人群注意力掩模图和背景注意力掩模图,交叉熵损失函数定义如式(7)所示
式中:F(Xi,θ)为估计的密度图;θ 为该网络中一组可学习参数;Xi为输入图像;DGTi为真值密度图;N 为一个批次的图像个数;AGTi为注意力掩膜真值图;Pi为预测的注意力掩膜图中每个像素被sigmoid函数激活的概率。
网络最终的损失函数包含3个单独的损失函数,分别为密度图回归损失、人群注意力掩模图的交叉熵损失和背景注意力掩模图的交叉熵损失。通过使用Cipolla 等[7]提出的使用同方差不确定性自动调整各损失函数权重的方法,取得了较好效果。具体来说,假设有N个任务,每个任务有一个损失函数Li,其中i = 1,2, …, N,第i 个损失函数的方差为σ2i,噪音参数αi=1/σ2i,这里的噪音参数表示该损失函数的可靠性。如果噪音参数过小,会导致该损失函数的权重过大,从而导致模型过拟合。如果噪音参数设置过大,会导致该损失函数的权重过小,从而导致模型欠拟合。优化过程是最大化一个高斯似然目标。具体是对模型权重W 和噪声参数αi通过反向传播和随机梯度下降进行优化,使以下目标最小化
式中:损失函数L1、L2分别属于第一任务和第二任务。通过最小化损失式(8)可以自适应地学习损失L1(W)和L2(W)的相对权重σ1 和σ2,当σ1 增加时,意味着L1(W)的加权值降低,同时通过式(8)中的最后一项来限制σ1 和σ2,起到正则化的作用,可以很好地平衡不同的回归和分类损失。网络最终的损失函数为
式中:Lden为均方误差损失函数;L1为人群注意力掩膜损失函数;L2为背景注意力掩膜损失函数;α1和α2分别为人群注意力掩膜任务和背景注意力掩膜任务的噪音参数。
2 算法实现
2.1 真实密度图以及注意力掩膜真值图生成
为了获得真实密度图DGTi,使用几何自适应的高斯核[8]处理人群场景。假设在像素点xi处有一个点表示场景中的人头位置,则可以将该点用单位冲激函数δ(x-xi)表示,通过使用高斯核模糊每个人头标注计算出相应的真实密度图DGTi,即将δ函数与具有参数σi标准差的高斯核函数进行卷积。密度图DGTi的生成可以表示为
式中:N为总人数;在实验中,ShanghaiTech数据集设置σ 为5;UCF_CC_50 数据集设置σ 为15;UCF-QNRF数据集σ的设置通过最近邻来得到。
根据已有的标注信息及密度图可进一步生成注意力掩膜真值图。首先,使用高斯核函数生成人群真实密度图,然后基于阈值0.001[4]对相应密度图真实值进行二值化处理,生成注意力掩膜真值图。相应公式如下
式中:i 为相应人群真实密度图中的一个坐标;D(i)为人群真实密度图上像素点的值;A为注意力掩膜真值图。
2.2 数据预处理和数据增强
在训练过程中,首先处理短边小于512 的图像,将图像的短边调整为512,对于UCFQNRF数据集图像分辨率过大导致计算量过大的问题,将图像大小调整为固定的1024×768。其次按比例[0.8,1.2]随机变化,将图像随机裁剪成固定大小(400×400)的图像块,然后以0.5 的概率随机水平翻转,并使用参数[0.5,1.5]以0.3 的概率进行伽马对比度变换处理,以进行数据增强。对于ShanghaiTech A 这种带有灰色图像的数据集,以0.1 的概率随机地将彩色图像改为灰色。为了与网络的输出尺寸相匹配,密度图和注意力掩膜图的真值图分辨率大小都被调整为输入图像的一半。
2.3 训练过程中的超参设定
采用前13 层预训练的VGG-16 作为前端特征提取器,其余的网络参数由均值为0、标准差为0.01 的高斯分布随机初始化。对于ShanghaiTech、UCF_CC_50 数据集采用学习率为1e-4、权重为5e-3 权重衰减的Adam 优化器对模型进行训练,对于UCF-QNRF数据集采用学习率为1e-5、默认权重衰减的Adam 优化器对模型进行训练,在训练过程中使用批量大小为4,以稳定训练损失的变化。本文所有实验皆在Ubuntu 18.04 系统下、使用python 3.6 在Pytorch 深度学习框架下完成,采用RTX 2070 SUPER显卡来加速训练。
3 实验及结果分析
3.1 评价指标
与大多数基于卷积神经网络的密集人群计数方法相同,本文设计的方法也使用平均绝对误差(Mean Absolute Error,MAE)和均方误差(Mean Square Error,MSE)作为评估准则。MAE 反映了模型的准确性,而MSE 反映了模型的稳健性,这些指标定义如下
3.2 ShanghaiTech数据集实验
ShanghaiTech 数据集[2]包含1 198 张标注图像,共计330 165人。该数据集由A和B两部分组成。A 部分包含482 张从互联网上随机下载的高度拥挤的场景图像,图像场景中人数变化范围从33到3 139,其中300张图像构成训练集,182 张图像构成测试集。B 部分包含716 张来自上海繁华的街道上相对稀疏的人群场景,人数变化范围从12 到578,其中400 张图像构成训练集,316张图像构成测试集。
表1 列出了本文提出的TWCNMA 与其他代表性算法在ShanghaiTech数据集上的实验结果。可以发现,TWCNMA 在两个数据集上都实现了最好的准确率,同时在鲁棒性指标MSE 上也取得了较好的结果,说明该算法在不同密集程度的场景中具有较好的适应性。在ShanghaiTech_A 数据集上,与计数性能第二的SFANet 相比,TWCNMA 在指标MAE 和MSE 上分别优化了4.3%和3.1%。在Shang‐haiTech_B 数据集上,TWCNMA 的准确率和鲁棒性优于大部分网络,仅在鲁棒性指标MSE 上次于SFANet[4]和C2FNet[9]。SFANet使用的也是包含前端特征提取和后端特征融合的结构,但SFANet 在ShanghaiTech 数据集上的MAE 和MSE 的表现很大程度是由于其使用了UCF-QNRF 数据集预训练权重作为初始权重。C2FNet 生成了由低分辨率到高分辨率的密度估计图,并通过分布式监督促进密度图融合,实现了更低的MSE。

表1 ShanghaiTech数据集上的实验结果
图6 展示了ShanghaiTech 数据集中部分测试图像的可视化结果,第一、二行是Shanghai‐Tech_B 上的估计结果,第三、四行是Shanghai‐Tech_A 上的估计结果,第一列是人群图片,第二列是真值密度图,第三列是预测密度图。可以发现TWCNMA 在人群密集的场景及相对稀疏的城市街道场景下均展现了较好的结果,其生成的密度图也与真实密度图一样能正确反映人群的分布情况。

图6 ShanghaiTech上TWCNMA算法生成密度图可视化示例
3.3 UCF_CC_50数据集实验
UCF_CC_50[15]数据集内涵盖音乐会、抗议活动、体育场和马拉松比赛等不同场景,包含50 幅不同视角不同分辨率的图片。每幅图片标注的人数范围从94 到4 543 不等,平均人数达到了1 280,这使其成为了人群计数任务中最有挑战性的数据集。
表2 列出了TWCNMA 与其他代表性算法在UCF_CC_50 数据集上的实验结果。可以发现,TWCNMA 的准确率和鲁棒性优于大部分网络,仅在鲁棒性指标MSE 上次于CAN[10]和LA-Batch[13]。CAN同样使用VGG16作为前端特征提取网络,同时提出了一种基于上下文感知卷积神经网络的方法来自适应地学习和利用不同尺度的上下文信息。但由于UCF_CC_50 数据集样本较少,并且全部为灰度图,因此该方法在该数据集上的预测误差均较大,验证效果可能偏弱,不能很好地说明模型效果。与计数性能第二的C2FNet 相比,TWCNMA 在指标MAE和MSE上分别优化了3.2%和7.9%。

表2 UCF_CC_50数据集上的实验结果
图7 展示了UCF_CC_50 数据集中部分测试图像的可视化结果,可以发现TWCNMA 算法能有效应对训练数据较少且人群极度密集的情况,生成接近真实人群分布的估计结果。

图7 UCF_CC_50上TWCNMA算法生成密度图可视化示例
3.4 UCF-QNRF数据集实验
UCF-QNRF[16]包含1 535 张密集的人群图像,其中训练集有1 201 张图像,测试集有334张图像。UCF-QNRF 数据集拥有更多高计数的人群图像和注释,以及更广泛的场景,包含最多样化的视角、密度和照明变化。除了高密度区域外,该数据集还包含建筑、植被、天空和道路,因为它们出现在野外捕获的现实场景中,因此使得该数据集更加真实且获取难度大。
表3 列出了TWCNMA 与其他代表性算法在UCF-QNRF 数据集上的实验结果,可以发现,TWCNMA 在准确性指标MAE 和鲁棒性指标MSE 上达到了可竞争的水平,仅次于SFANet[4]和C2FNet[9],但与性能最佳的算法仍有一定差距。性能最佳的C2FNet 通过使用单列架构,在主干网络后串联多个相同的模块来充分挖掘深层抽象信息,并使用中继监督模块来优化密度图达到了最佳的效果。与C2FNet相比,TWCNMA 避免了前者较为臃肿的结构,并通过注意力图来抑制背景噪声的影响。但在UCF-QNRF数据集上的表现不尽如人意,这可能是TWCNMA 在某些情况下的泛化能力不足,同时也可能是因为没有在UCF-QNRF数据集上进行足够的超参数调整,优化器的参数不是最优的。
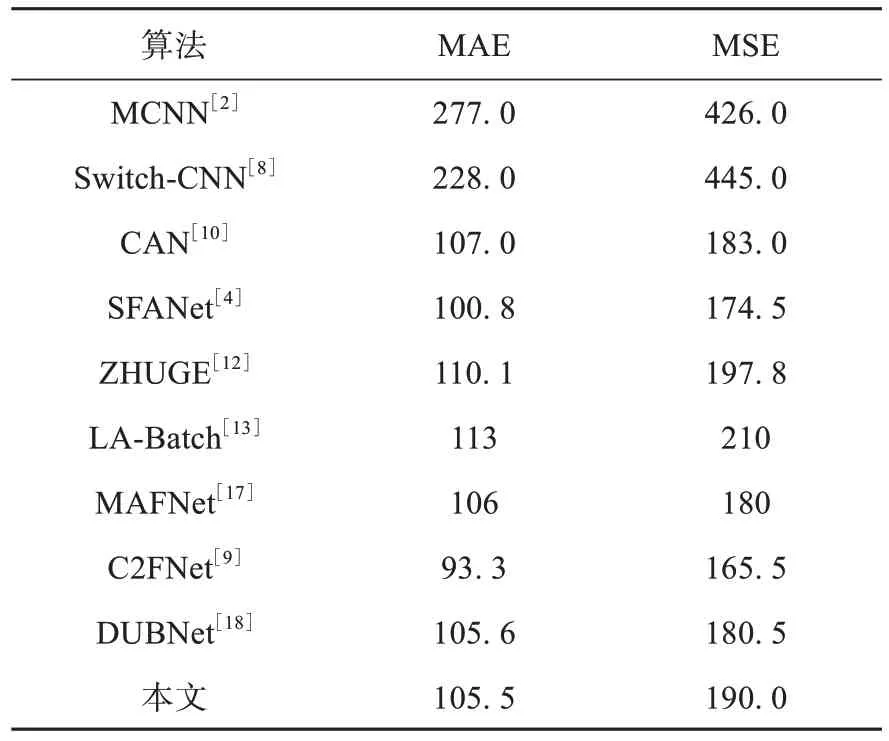
表3 UCF-QNRF数据集上的实验结果
图8 展示了UCF-QNRF 数据集中部分测试图像的可视化结果,可以发现TWCNMA 能有效应对背景噪声干扰、人群尺度变化大、人群极度密集等情况。

图8 UCF-QNRF上TWCNMA算法生成密度图可视化示例
3.5 消融实验
为了验证本文所提出的多尺度注意力机制的双路人群计数网络(TWCNMA)的有效性,将从两个方面进行结构性消融实验并作相应的分析:(1)多尺度注意力机制的双路人群计数网络中不同模块的有效性分析;(2)注意力掩膜分支网络的有效性分析。
首先,为了验证和分析提出的多尺度模块(MSM)、尺度增强模块(SEM)及上下文注意模块(CAM)的有效性,从网络中移除某一模块,并在ShanghaiTech 数据集的PartA 部分进行训练并评估其性能表现。实验共包含3 种设置,其中W/O MSM 表示移除多尺度模块、W/O SEM 表示移除尺度增强模块、W/O CAM 表示移除上下文注意力模块。
表4 展示了移除不同模块后的网络在ShanghaiTech 数据集的PartA 部分性能比较。结果表明,相比同时采用MSM、SEM、CAM 的TWCNMA,单独移除一个模块后,模型的性能都有所下降。同时采用MSM、SEM、CAM能够获得最优的MAE 和MSE 指标,大幅提升模型性能。这表明,MSM、SEM 和CAM 模块在TWCNMA 中都起到了重要的作用,有助于模型更好地捕获多尺度信息和上下文信息,提高了模型的性能。
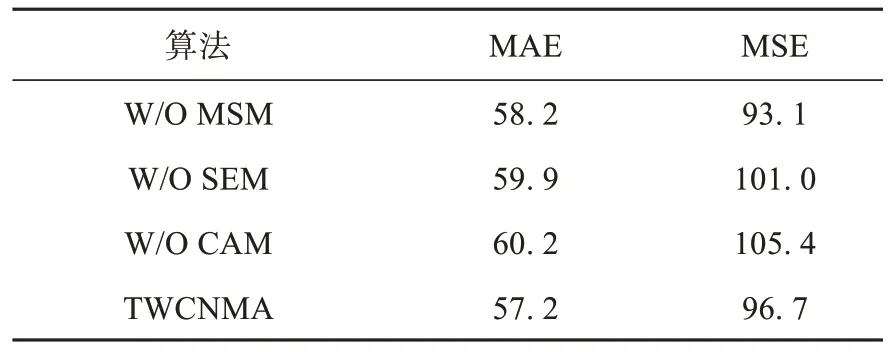
表4 不同模块的性能比较
其次,为了验证注意力掩膜分支网络的有效性,进行了另一个消融实验。实验包含两种设置,其中TWCNMA 表示多尺度注意力机制的双路人群技术网络,W/O 注意力掩膜分支网络表示移除注意力掩膜分支网络,结果如表5所示。通过在网络中添加注意力掩膜分支,生成用于指导网络生成更高质量密度图的注意力掩膜,可以提升网络的性能、抑制背景噪声的影响。相较于移除注意力掩膜分支,MAE和MSE分别提高6.38%和1.82%。

表5 注意力掩膜分支网络的消融实验结果
TWCNMA 的部分可视化结果如图9 所示。由图9 可知,注意力掩模图可指示人群所在位置,在它的指示下,生成的预测密度图接近真实密度图。

图9 TWCNMA可视化示例图
4 结论
本文提出了一种多尺度注意力机制的双路人群计数网络TWCNMA 用以解决密集人群计数领域中人群尺度变化大、背景干扰、特征融合导致的语义失调这3 个问题。首先,提出了以多尺度模块和尺度增强模块为核心的特征提取网络,捕获不同尺度的特征,增强网络对人群尺度变化大的适应性;其次,提出了以上下文注意力模块为核心的多尺度注意力特征融合网络,有效感知并融合多尺度信息,缓解不同级别特征存在的语义失调问题;最后,使用注意力掩膜来抑制背景噪声的干扰。通过在一些公共数据集上与其他人群计数算法对比可知,提出的人群计数网络取得了较好的计数精度,同时在多个数据集上也展现出了很好的鲁棒性。尽管如此,提出的方法在UCFQNRF 数据集下表现欠佳,需要进一步提高算法的泛化性。未来,TWCNMA 可以应用于预防公共场所中大规模踩踏事故的发生等场景,并可以进一步探索如何提高算法的泛化性,以便在更多的数据集和实际场景中得到更好的应用。
