基于ARIMA-RF组合模型的CPI预测
2023-09-14曾令麒

摘 要:居民消费价格指数(CPI)是一个重要的宏观经济变量,反映了国家的通货膨胀水平、居民的消费水平和生活成本,它与国家、社会和个人有密切的联系。基于Savitzky-Golay平滑滤波去噪后的2002年1月至2021年12月的CPI月度数据,构建ARIMA-RF组合模型,对CPI序列进行预测并与单一的ARIMA和RF模型进行比较。结果表明,ARIMA-RF组合模型的预测效果和稳定性均优于单一模型。
关键词:CPI;Savitzky-Golay平滑滤波;ARIMA;随机森林;ARIMA-RF
中图分类号:TP391;TP18 文献标识码:A 文章编号:2096-4706(2023)13-0013-05
CPI Prediction Based on ARIMA-RF Combined Model
ZENG Lingqi
(School of Mathematical Sciences, South China Normal University, Guangzhou 510631, China)
Abstract: Consumer price index (CPI) is an important macroeconomic variable, which reflects the inflation level of the country, the consumption level of residents and the cost of living. It is closely related to the country, society and individuals. Based on the monthly CPI data from January 2002 to December 2021 after Savitzky-Golay smooth filtering and denoising, an ARIMA-RF combined model is constructed to predict the CPI sequence and compare it with a single ARIMA and RF model. The results show that the prediction effect and stability of ARIMA-RF combined model are better than that of single model.
Keywords: CPI; Savitzky-Golay smooth filtering; ARIMA; random forest; ARIMA-RF
0 引 言
居民消费价格指数(CPI)是一个衡量消费者市场价格变动的定期测量指数,它综合了不同商品和服务价格变动的平均水平,用于衡量消费者物价水平的变化情况,也在一定程度上反映了当前的通货膨胀水平。由于CPI是基于收集的复杂金融数据而构成的,需要一定时间去收集、加工和处理数据,通常会出现延迟发布的情况[1]。而延迟发布会造成严重的信息流滞后,会对如企业高管、投资者和宏观经济政策制定者等需要实时监测经济状况并及时根据有关信息做出重大决定的人带了严重的问题,因此在不能够及时获得CPI实际数据的情况下,对其合理的预测就显得极其重要,所以建立一个合理、稳定、准确的模型来预测CPI,对于政府财政政策和货币政策的制定、企业经营决策、投资者决策以及居民消费决策都具有重要的现实意义。
近年来,国内外学者对CPI预测问题做了诸多的研究与探索,目前CPI预测方法主要有三类,分别是时间序列法、机器学习法和组合分析法。对于时间序列法,Mohamed和Weng[2,3]分别建立ARIMA(0,1,3)和ARIMA(12,1,12)模型对CPI进行预测,模型都通过了显著性检验且预测效果较好;李红娟[4]考虑到CPI的季节性,构建SAO-ARIMA-MA模型对CPI进行预测,其中使用X-11方法对季节进行分解,结果显示季节因子序列有明显的周期性,且利用此模型预测的效果优于普通的ARIMA模型。对于机器学习法,Zahara[5]等利用多层感知器和长短期记忆(LSTM)进行了基于云计算的多元CPI预测,实现了神经元数量、时代和隐藏层的架构变化,且模型运行速度快,结果符合实际;Qin[6]等采用遗传算法调整支持向量机参数,建立基于遗传算法-支持向量机(GA-SVM)的预测模型,该方法避免了人工选择参数的盲目性,提高了模型的训练速度和预测推广速度,并且大大简化了CPI的预测。对于组合分析法,吴晓峰[7]等建立了ARIMA-BP组合模型对北京市CPI进行预测,ARIMA模型提取序列的线性规律,BP神经网络对ARIMA模型产生的残差进行预测,以提取序列非线性规律,得到了精度高且稳定的结果;尹静等[8]将ARIMA模型和GMDH模型预測的CPI作为初始值,重新输入到GMDH模型中进行预测,以此构建ARIMA-GMDH组合模型,Bonferroni-Dunn检验结果显示该模型的抗干扰性较强。
目前较少学者使用随机森林(RF)回归算法对CPI进行预测,本文基于2002年1月—2021年12月的CPI序列数据,分别利用ARIMA模型、RF模型和基于残差优化的ARIMA-RF组合模型预测CPI,通过综合比较三个模型预测的绝对误差、相对误差、MAE、MAPE、MSE、RMSE,ARIMA-RF组合模型的预测效果和稳定性优于单一模型。
1 理论基础
1.1 ARIMA模型
自回归移动平均模型(ARIMA)是Box和Jenkin等人提出的用于时间序列预测的方法,也称B-J方法。ARIMA模型是ARMA模型和差分运算结合而成的,ARMA模型可以较好地拟合平稳序列。若原始序列非平稳,则常常对原始序列进行d阶差分提取其蕴涵的确定性信息,以将其转化为平稳时间序列,进而对d阶差分后的序列建立ARMA模型拟合。上述过程即为ARIMA模型建立过程,ARIMA(p,d,q)结构如下:
1.2 RF模型
随机森林(RF)模型是以决策树为基学习器构建的bagging集成机器学习算法,在决策树的训练过程中引入随机选择,常用于处理分类、回归等问题[9],本文使用RF回归算法对CPI序列数据进行建模。
RF回归首先使用Bootstrap重抽样方法在数据集进行有放回的随机抽取n个样本,重复K此这种抽样方式,进而得到K个训练样本集合,同时将K次抽样中未被抽到的样本组成K个袋外数据(OBB),以生成K个测试样本集。进而可以使用K个训练样本集合构建回归树,以所有回归树的预测均值作为最终的预测值。下面介绍回归决策树生成原理[10]。
回归树会遍历给定样本数据的所有特征,对每个特征的取值进行划分,对划分后的数据计算损失函数,直到找到最小损失值的划分,计算公式如下:
其中j、s分别为切分变量和切分点,c1、c2为划分后两个结点的输出值,R1、R2为划分后形成的两个区域。
继续对两个子区域进行上述步骤,直到满足设置的停止条件,最终输入空间被分为M个区域R1,R2,…,Rm,生成回归树:
最终一共生成K棵回归树,将这K棵回归树进行组合就可以构造随机森林回归模型,预测值可以用如下公式表示:
1.3 ARIMA-RF模型
CPI时间序列数据xt中既存在线性部分Lt和非线性部分Nt,因此可以表示成如下数学形式[11]:
单一的ARIMA模型仅能够充分提取CPI序列数据的线性特征,而RF可以充分提取序列的非线性特征,因此将两者结合理论上可以提高模型的预测效果,ARIMA-RF模型的建模步骤:
1)ARIMA建模。首先使用ARIMA模型对CPI序列数据进行拟合,提取出CPI序列的线性部分 ,那么残差et可表示成如下形式:
2)RF建模。若ARIMA模型通过显著性检验,说明CPI序列的线性部分已被充分提取,那么残差中仅含有CPI序列的非线性部分,利用RF模型对残差序列进行建模拟合。RF建模前需要将时间序列数据通过滑动窗口处理转化为有监督学习的数据,本文将过去5个月的CPI数据作为特征进行RF建模,因此残差序列拟合模型可表示成如下形式:
其中f为非线性部分,εt为随机误差。通过RF模型拟合残差后,最终预测结果可以表示为:
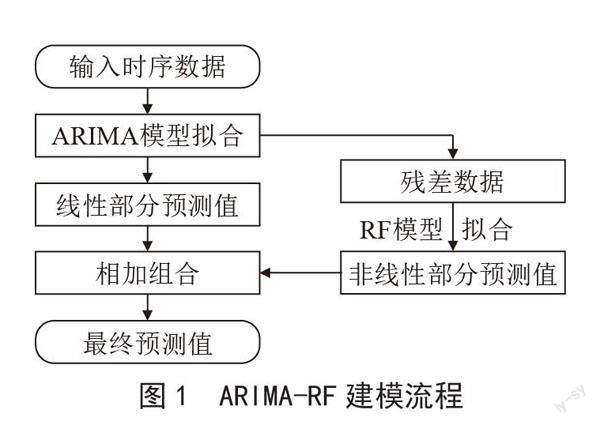
图1为ARIMA-RF模型建模流程。
1.4 评价指标
本文主要采用四个指标来评估模型预测效果,分别是平均绝对误差(MAE)、平均绝对百分比误差(MAPE)、均方误差(MSE)、均方根误差(RMSE),他们的计算公式如下:
MAE反映了预测值与实际值的相似程度,MAPE反映了预测值与实际值相似程度的百分比,MSE和RMSE则反映了预测值与实际值之间的总体偏差。这些评价指标都是数值越小,模型的预测效果越好,预测精度越高。
2 CPI预测
2.1 数据说明
本文数据来源于choice金融终端数据库。由于月度数据量大,较年度数据可以提供更加准确详细的信息,因此本文选取2002年1月到2021年12月的数据,共计240条数据,无缺失值。该时间段的数据走势,如图2所示。
2.2 数据去噪
宏观经济系统复杂多变,CPI的影响因素众多,因此CPI数据通常会具有高噪声的特点。为了清除不真实的和不重要的信号,以便准确地识别和预测CPI的未来趋势,本文在建模预测之前先对原始CPI序列进行去噪处理,去噪方法选用Savitzky-Golay平滑滤波法,其核心思想是:在小窗口范围内,使用多项式拟合方法来确定一个更平滑的窗口内数据曲线,然后用拟合出来的曲线来取代原始窗口内数据。它有助于去除噪声并平滑数据中的不规则变化,使得序列趋势更加清晰。
本文选取2002年1月到2021年6月的去噪后的CPI序列作为训练集,2021年7月到2021年12月的CPI序列作为测试集。设置滤波窗口长度为5,平滑阶数为3,绘制出去除噪声后的2002年1月到2021年6月的CPI时间序列,如图3所示,后文的实验均基于去噪后的数据进行。
2.3 ARIMA模型预测
2.3.1 平稳性检验和白噪声检验
由图3可以初步看出,CPI数据基本上在102上下波动,且无明显的趋势和周期性特征,可以初步判断其为平稳序列。对2002年1月到2021年6月的CPI时间序列数据进行ADF单位根检验,结果显示τ统计量的P值小于0.05,拒绝原假设,认为CPI序列是平稳的。因此不需要对序列进行差分运算,直接拟合ARMA模型。接着对序列进行白噪声检验,结果显示各阶数延迟下LB统计量的P值均小于0.05,因此拒絕CPI序列为白噪声的原假设,认为该序列为非白噪声序列,具有研究的意义。
2.3.2 模型识别和参数估计
绘制得到的平稳非白噪声CPI序列的自相关函数图(ACF)和偏自相关函数图(PACF),结果如图4所示。
由图4可知CPI的自相关系数拖尾,而偏自相关系数无法准确地判断其是拖尾还是截尾,因此尝试拟合多个ARMA模型,结合AIC准则和BIC准则找出相对最优的模型。Python的statsmodels.api模块中的sm.tsa.arma_order_select_ic()函数,可以快速找到使得AIC值和BIC值最小的模型,结果显示两个准则的最优模型均为ARMA(4,4)。进而使用极大似然估计得到ARMA(4,4)的模型口径为:
xt = 102.135 - 0.287xt-1 + 0.166xt-2 + 0.594xt-3 + 0.336xt-4 + 2.423εt-1 + 3.273εt-2 + 2.277εt-3 + 0.860εt-4 + εt,εt?WN (0, 0.063)
2.3.3 模型检验
模型检验主要是对残差进行正态性检验和白噪声检验,残差正态性可由Q-Q图判断,残差分位点基本分布在45度对角线上,表明残差序列服从正态分布。计算得到延迟6阶的LB统计量的P值大于0.1,因此可以认为残差序列为白噪声序列,表示拟合的模型显著。
2.3.4 预测分析
模型通过了检验后,先利用ARIMA(4,0,4)重新对2002年1月到2021年6月的CPI序列进行预测,拟合效果如图5所示。
由图5可知,ARIMA(4,0,4)拟合效果非常好,但是其预测能力需要进一步探讨,下面利用ARIMA(4,0,4)模型对2021年7月到2021年12月的CPI数据进行预测,预测结果如表1所示。
由表1可知,除了2021年11月以外,其余月份预测值与实际值都非常接近,绝对误差的绝对值都低于0.5,相对误差的绝对值均低于0.5%,特别是2021年7月绝对误差仅为0.002 7,相对误差仅为0.002 7%,可以看出ARIMA(4,0,4)做一步预测的效果非常好,前六步预测的效果也较为优秀。计算各评价指标分别为:MAE为0.388,MAPE为0.459,MSE为0.267,RMSE为0.517。结合各评价指标含义可知模型总体预测效果较好,但是预测值并不稳定。
2.4 RF模型预测
使用Python的sklearn库中的RandomForest
Regressor()函数直接构建随机森林回归模型,对2002年1月到2021年6月的CPI序列进行预测,拟合效果如图6所示。
由图6可知,RF拟合效果较好,但是结合图5可知其拟合序列的效果比ARIMA(4,0,4)模型更差,下面对其预测能力进行探讨,利用RF模型对2021年7月到2021年12月的CPI数据进行预测,预测结果如表2所示。
由表2可知,6个月份预测值与实际值都比较接近,绝对误差的绝对值都低于1,相对误差的绝对值均低于1%,可以看出RF模型做六步预测的效果还不错。计算各评价指标分别为:MAE为0.504,MAPE为0.497,MSE为0.342,RMSE为0.585。所有评价指标都高于ARIMA(4,0,4)模型预测的结果,其中MAE较ARIMA(4,0,4)模型提高了0.116,因此在本文CPI的预测中,ARIMA(4,0,4)模型精度优于RF模型。
2.5 ARIMA-RF模型预测
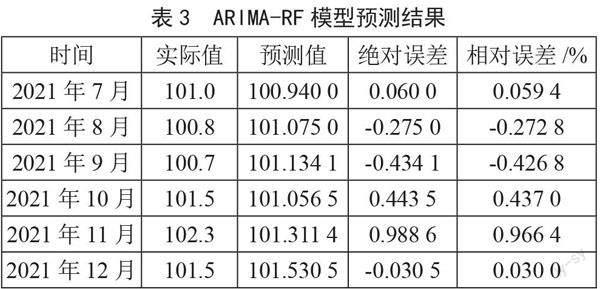
根据前文可知,ARIMA(4,0,4)模型已经通过显著性检验,说明残差序列为白噪声,ARIMA(4,0,4)模型已经将CPI序列数据中的线性相关性特征充分提取出来,因此残差序列中仅存在非线性特征,利用RF模型对残差序列进行建模预测,以充分提取其中的非线性相关信息。根据ARIMA(4,0,4)模型和RF模型预测残差的结果,利用式(1)得到最终预测结果如表3所示。
由表3可知,6个月份预测值与实际值都非常接近,除了2021年11月以外,其余预测结果绝对误差的绝对值都低于0.5,相对误差的绝对值都低于0.5%,可以看出ARIMA-RF模型做六步预测的效果非常好。计算各评价指标分别为:MAE为0.372,MAPE为0.366,MSE为0.240,RMSE为0.490。所有评价指标都低于ARIMA(4,0,4)模型和RF模型预测的结果,尤其是MAPE,较ARIMA(4,0,4)模型降低0.093,較RF模型降低0.131。因此在本文CPI的预测中,ARIMA-RF模型精度优于ARIMA(4,0,4)模型和RF模型。
3 结 论
CPI会影响消费者价格水平、金融利率、企业的投资与经营和国家宏观政策的制定等,与国家、企业和个人都有很大的关联。因此,准确地预测CPI对国家制定经济政策、企业调整经营管理活动和居民调整消费等都是十分重要的。本文首先使用Savitzky-Golay平滑滤波法对CPI序列进行处理,使得序列数据更加平滑,趋势更加清晰,序列预测的准确度更高。进而运用ARIMA模型和RF模型分别对CPI预测,预测效果均较好,且ARIMA模型效果好于RF模型。由于CPI序列数据具有线性和非线性两种特征,传统ARIMA模型可以充分提取时间序列数据的线性特征,随机森林(RF)模型可以提取残差序列中的非线性特征,将二者结合可以实现互补,以此构造优化残差的ARIMA-RF组合模型,结果显示使用该组合模型预测CPI的精度和稳定性比单一模型更好。
参考文献:
[1] 唐孝银.基于因子分析和机器学习算法的通货膨胀预测 [D].重庆:西南大学,2022.
[2] MOHAMED J. Time Series Modeling and Forecasting of Somaliland Consumer Price Index:A Comparison of ARIMA and Regression with ARIMA Errors [J].American Journal of Theoretical and Applied Statistics,2020,9(4):143-153.
[3] WENG D D. The Consumer Price Index Forecast Based on ARIMA Model [C]//2010 WASE International Conference on Information Engineering.Beidai:IEEE,2010:307-310.
[4] 李红娟,卢天哲,祝汉灿.国房景气指数对CPI和CCI影响及CPI预测模型研究 [J].数学的实践与认识,2022,52(8):70-77.
[5] ZAHARA S,SUGIANTO. Multivariate Time Series Forecasting Based Cloud Computing For Consumer Price Index Using Deep Learning Algorithms [C]//2020 3rd International Seminar on Research of Information Technology and Intelligent Systems (ISRITI).Yogyakarta:IEEE,2020:338-343.
[6] QIN F H,MA T R,WANG J H,et al. The CPI forecast based on GA-SVM [C]//2010 International Conference on Information,Networking and Automation (ICINA).Kunming:IEEE,2010:142-147.
[7] 吴晓峰,杨颖梅,陈垚彤.基于BP神经网络误差校正的ARIMA组合预测模型 [J].统计与决策,2019,35(15):65-68.
[8] 尹静,何跃.基于ARIMA-GMDH的GDP预测模型 [J].统计与决策,2011(5):35-37.
[9] 李欣海.随机森林模型在分类与回归分析中的应用 [J].应用昆虫学报,2013,50(4):1190-1197.
[10] 周志华.机器学习 [M].北京:清华大学出版社,2016.
[11] 苗元鑫.基于机器学习和组合模型的汇率预测研究 [D].济南:山东大学,2022.
作者简介:曾令麒(2003—),男,汉族,湖南衡阳人,本科在读,研究方向:应用统计学。
收稿日期:2023-02-09
