基于多任务学习的机票价格预测模型
2023-09-13贾玉璇
卢 敏,贾玉璇
(1.中国民航大学 计算机科学与技术学院,天津 300300;2.中国民用航空局 民航智慧机场理论与系统重点实验室,天津 300300)
0 引 言
现有研究利用机器学习方法来揭示特征之间的潜在关系,建立机票特征模型,忽略每个票价等级的需求。航班的座位数量有限,机票需求会影响价格,其次,不同时间的不同航班,机票需求差异较大。为解决上述问题,本文提出一种机票价格预测的多任务学习模型,其关键思想是引入机票需求预测作为辅助任务,利用辅助任务预测每个票价等级购买的机票数量,机票需求特征表示时间序列在日、周、半月和月内的需求特征,并且通过一维卷积网络中不同尺度的卷积核和卷积步长来学习,最后通过共享多尺度需求特征联合训练两个相关任务,提高模型的泛化能力。本文的主要贡献是:①提出一种多任务学习方法,提高机票价格预测的性能;②设计卷积网络,学习不同层次的需求特征;③由于缺乏公开的数据集,现有的方法从在线旅游预订网站抓取数千万条记录进行实验,较之基准算法,该模型在准确率和F1分数方面提高将近6%,准确率达到51.02%。
1 相关研究
机票的动态定价规则是由航空公司保密的,传统的机票价格预测,通过历史销售情况预测未来价格。随着机器学习的发展,多数研究采用机器学习方法训练机票价格预测模型,输出机票的票价等级。由于机票定价的复杂性,机票的价格受到多种影响因素,机票价格预测具有挑战性。相关研究文献[1-4]分析了旅客因素的影响,介于乘客数据的稀疏性和保密性,仅凭借旅客特征进行定价,模型适用性不强。其次,机票价格还受其它因素的影响,例如:He等[3]和Kelemen等[5]分别将航线和航空公司纳入机票预测。上述方法基于机票特征进行建模,不考虑机票需求的影响,机票价格预测性能较差。
此外,机票价格受时间的变化影响,机票价格在时空上的分布具备一定规律,相关学者提出加入时间序列以预测价格趋势的方法。Liu等[6]利用上下文感知模型,预测从购买日期到出发日期之间特定路线的最低价格。Wang等[7]使用多种机器学习方法预测不同季节的平均机票价格,并得出随机森林算法在处理季度序列方面的性能最优。Zhao等[8]设计双阶段注意机制,向编码器和解码器同时加入注意力机制,以应对不同时间步长的影响。与上述方法不同的是,本研究聚焦于机票价格预测,而不是预测机票的价格趋势。
机票需求是影响机票价格预测的关键因素,国内外学者对机票需求进行相关研究。Williams等[9]通过对随机需求的动态调整,揭示了需求与价格之间存在的关联关系。He等[3]使用异构的项目推荐框架来模拟乘客的旅行需求和行为模式,解决飞行的需求随时间变化问题,建立了时间序列预测模型。Shihab等[10]提出寻找需求控制问题的最优策略决策框架,建立时间序列预测模型,模拟特定时间段内的需求趋势。Wen等[4]通过研究航空旅客的购买时间与其特征之间的关系,预测需求的变化。Pan等[11]提出了一种基于LSTM的垂直时间序列模式,建模机票在不同日期上的需求。上述方法只考虑模拟日水平的需求特征,忽略了周和月水平的需求特征,难以提取不同周期下的机票需求特征,预测模型性能不佳。
2 融入航班需求的机票价格预测算法
机票价格受机票自身属性和机票需求的影响。如图1所示,该框架由两个相关的任务组成,主任务作为机票价格预测,输入机票相关特征并输出机票类别的概率,并且选择概率最高的类别作为预测标签。辅助任务是指对机票需求进行预测,基于未来趋势将与历史趋势相似的假设,通过分析购买历史数据概述对不同类别票价的需求。最后,这两个任务通过共享需求特征进行融合。
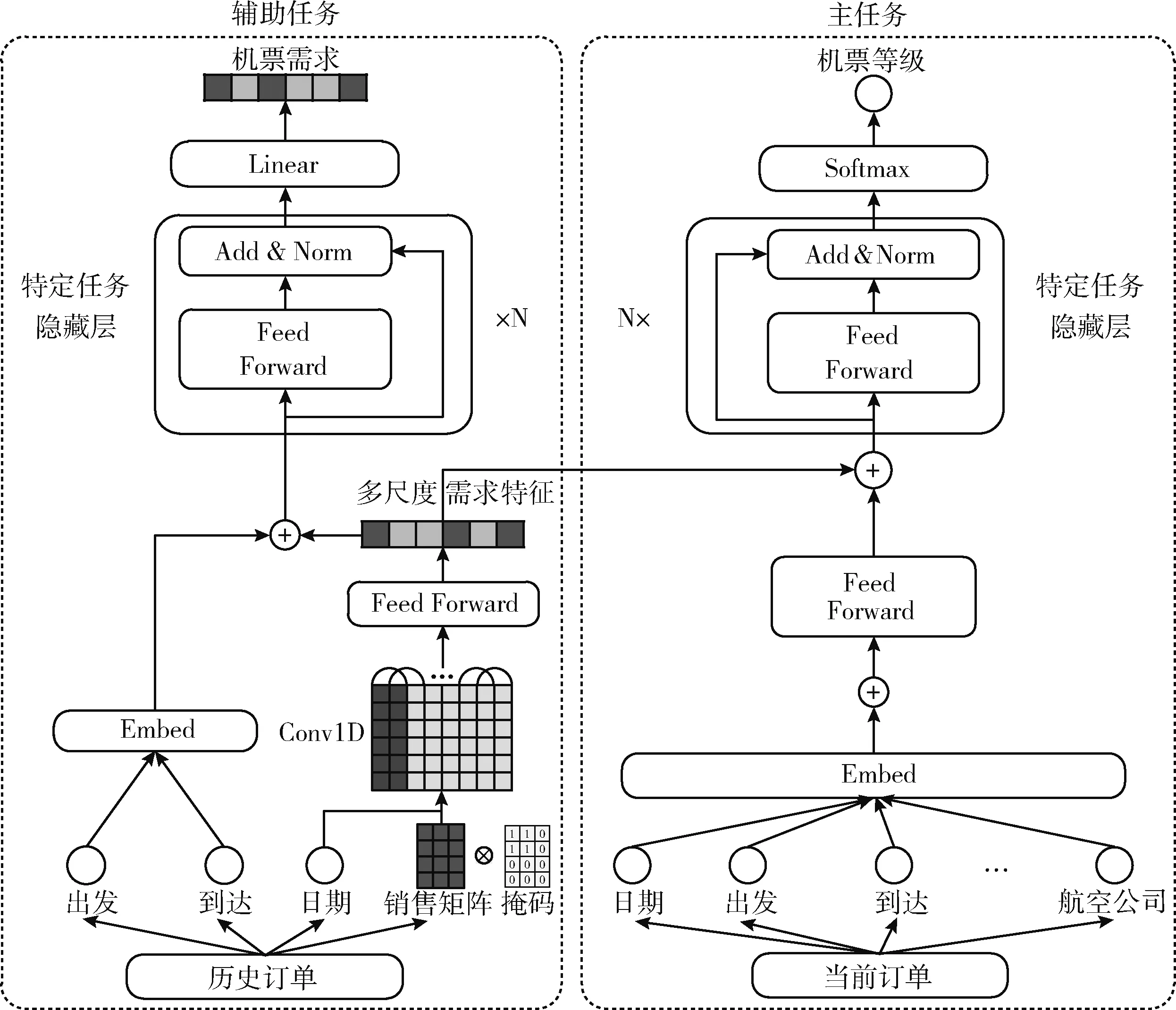
图1 基于多任务学习的机票价格预测框架
在训练中,两个任务的网络通过监督学习同时学习,联合损失函数Loss定义为
Loss=lossm+βlossa
(1)
其中,β表示多任务权重参数,lossm和lossa分别表示主任务和辅助任务的损失,在式(6)和式(12)中可以查看损失的详细信息。模型利用Adam优化器,通过最小化联合损失学习模型参数。在测试过程中,主任务和辅助任务遵循与训练中相同的预测过程,模型丢弃机票需求预测在测试集中的结果,输出机票价格类别。
2.1 主任务
主任务是设计一个深度神经网络来输出机票的票价等级。机票特征包括出发机场、到达机场、航空公司、假期开始/结束等,机票特征的详细信息见表1。每个类别特征通过嵌入层Embedding编码映射成低维密集的向量表示。连接机票特征的嵌入向量,得到串联特征向量h1m,然后输入到一个两层的前馈神经网络,前馈网络的输出为
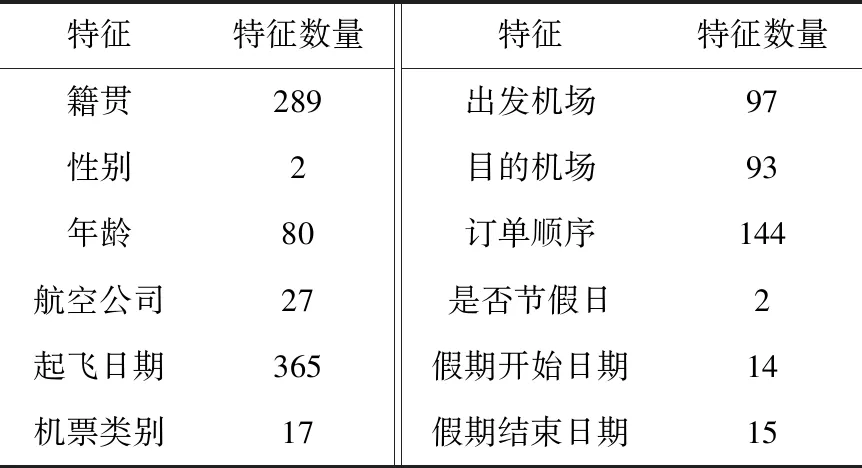
表1 实验数据集数据特性
h2m=max(0,b2m+W2mmax(0,b1m+W1mh1m))
(2)
其中,b1m、b2m表示偏差,W1m、W2m表示神经元的权重。使用max激活函数捕捉机票特征之间的非线性关系。
由于机票需求与机票价格高度相关,因此,将多尺度需求特征体融入主任务中。多尺度特征用来提取不同层次的需求特征(其计算详见第2.2节的式(7)),具体而言,将中间特征h2m和需求特征h1a的拼接向量h3m,输入到具有N个相同层的堆栈中,以学习特定的任务表示。每一层堆栈都是一个简单的、位置方面的全连接前馈网络。其中,隐藏层先使用残差连接[12],然后输入到下一层进行归一化[13],得到主任务的高维表征hN+3m,计算过程如式(3)、式(4)所示
h3m=h2m⊕h1a
(3)
hl+1m=hlm+max(0,blm+Wlm×LayerNorm(hlm)),l=3,…,N+2
(4)
hN+3m下一步传递到softmax层,如式(5)所示,输出机票类别的概率分布,主任务使用交叉熵损失函数来衡量预测分布和真实情况之间的差异,计算过程如式(6)所示
m=Softmax(bN+3m+WN+3mhN+3m)
(5)
lossm=-∑ni=1yimlog(im)
(6)
2.2 辅助任务
辅助任务主要是设计一个模型以学习机票的需求特征,然后将学习到的需求特征合并到主任务。如图1所示,辅助任务的输入包括出发/到达机场、日期和过去销售的矩阵M。每条航线由一对出发和到达机场表示,并使用矩阵M指定此航线的历史销售记录信息。矩阵M列数和行分别是365和17,其中矩阵M的每一列指一天中分别销售在17个票价等级的数量。辅助任务中,首先对矩阵M进行屏蔽,对本航班某一日期以后购买记录设置为不可见,然后将矩阵M输入神经网络。
利用掩码对未来区域设置为0,对历史区域设置为1,以保留当前日期之前的历史订单,然后掩码矩阵输入到一维卷积层,对历史订单进行特征提取。通过设置多尺度的卷积步长,来获取不同周期下的需求特征,矩阵的多尺度特征代表航班在日、周、月层面和需求相关的时间序列特征。这些特征通过两个步骤获得,第一步是利用一维卷积核获取历史订单数据不同周期长度的时间序列特征,即将卷积步长设置1、7、14、28,以捕获连续几天、几周和几个月的机票需求特征,并将卷积后得到的特征通过向量拼接进行连接;第二步是在连接后的特征上应用前馈神经网络,以获取机票需求特征的高维表示,计算过程如式(7)、式(8)所示
h0a=Conv1D(M⊙M*,k1,s1)⊕…⊕Conv1D(M⊙M*,kn,sn)
(7)
h1a=max(0,b1a+W1ah0a)
(8)
其中,k1,…,kn和s1,…,sn分别表示一维卷积核大小和卷积步长,M*表示掩码矩阵,⊙表示连接操作。
然后,将需求特征和出发机场、到达机场的嵌入向量进行拼接得到h2a,同样地,拼接向量h2a输入到N个相同层的堆栈中,其中每一层都由一个前馈网络层和一个残差连接层组成,计算过程为
h2a=h1a⊕Embed(起飞机场)⊕Embed(到达机场)
(9)
hl+1a=hla+max(0,bla+Wla×LayerNorm(hla)),l=2,…,N+1
(10)
将hN+2a输入线性层进行变换,预测不同类别票价的数量。因此,辅助任务使用均方误差损失函数衡量预测值与真实值之间的差异,计算过程如式(11)、式(12)所示
a=bN+2a+WN+2ahN+2a
(11)
lossa=1n∑ni=1(yia-ia)2
(12)
3 实验及结果分析
本文实验是在真实的海量订单数据集上进行。主要从以下3个方面验证模型的有效性:首先,验证本文提出方法,较之基准方法,是否可以获得更高的性能,其中基准算法包括的算法有SVM、ACEC、LSTM、BERT和STL,并在实验中采用4种评价措施从多个方面对模型的性能进行对比分析;其次,通过特征分析验证多任务学习机制的有效性;最后,分析卷积核的不同步长对多尺度需求特征的影响。
3.1 实验设置
3.1.1 实验数据
实验数据集是由周期为一年的民航旅客订票日志PNR(passenger name record)生成的,其中PNR是机票预订的内部记录。一条PNR记录是一次订票信息,主要字段包括旅客籍贯(信息加密)、航空公司、起飞日期、票价类别、出发机场和到达机场、订单顺序等,示例见表1。实验的数据集大小为52.2 GB,总共66 928 656条记录,包括13 943 370名乘客、2675条航线、19 748趟航班,示例见表2。此外,实验数据集由两部分组成:一个是机票特征,其本质是PNR数据;另一个是机票销售矩阵,其中机票销售矩阵数据中的一列表示一天中售出17个票价等级的数量。

表2 实验数据集数统计
3.1.2 评价指标
本文的评价指标采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1分数。准确率表示正确分类的机票占总机票数的百分比。精确率表示正确预测为正例的机票数占实际为正例机票数的比例。召回率表示实际为正例的机票数占预测为正例机票数的比例。F1分数表示精确率与召回率的调和平均数,对精确率和召回率的结果进行综合,可以客观全面地反映模型性能。对于准确率、精确率、召回率和F1分数而言,均是值越高模型越性能越好,具体计算公式如下
Accuracy=TP+TNTP+TN+FP+FN
(13)
Precision=TPTP+FP
(14)
Recall=TPTP+FN
(15)
F1=2×Precision×RecallPrecision+Recall
(16)
其中,TP(true positive)、TN(true negative)、FP(false positive)、FN(false negative)分别表示在多分类模型中被预测为正例的正样本、被预测为负例的负样本、被预测为正例的负样本和被预测为负例的正样本。
由于机票价格预测是一个多类别分类预测问题,故在上述指标的基础上加入宏观平均(Macro-average)和微观平均(Micro-average),从多个方面对多分类任务的性能进行客观评价。在宏观平均中,先对每一个类统计指标值,然后再对所有类求算术平均值,即所有类别都被平等对待。相反,微观平均根据真实实例的数量对每个类的分数进行加权,建立全局混淆矩阵,然后计算相应指标
MacroF1=(F1class1+F1class2+…+F1classn)n
(17)
MicroF1=(F1class1*f1+F1class2*f2+…+F1classn*fn)n
(18)
其中,f1,f2,…,fn表示n个类中实例的比率。
3.2 实验结果
3.2.1 基准方法
为验证所提出方法的有效性,本文将所提出的模型与其它现有的5个分类方法进行对比。
SVM[14]是多分类的支持向量机模型,通过求解几何间隔最大,对高维的机票特征进行分类,输出票价类别。
ACEC[6]是一种自适应上下文感知集成模型,用于根据时间序列分析具有不同上下文的机票数据,最后将softmax层应用于上下文以输出票价类别。
LSTM[15]是指基于LSTM的分类模型。该模型使用LSTM来捕获需求特征,这些特征被送入多分类层进行预测。
BERT[16]是指基于双向Transformer编码的分类模型,经过BERT提取特征之后,通过一个多分类器输出机票等级。
STL建立一个与所提出的方法具有相同网络架构的模型,这两个方法在是否包含机票需求损失方面存在差异。实际上,模型STL是所提出方法的一个特例,其权重参数β=0,这表明STL只存在机票价格预测任务,忽视机票需求预测,以此验证多任务学习的有效性。
本文在模型训练实验过程中的参数设置如下:批量大小batchsize、训练过程的最大轮数epoch、学习率和dropout分别设置为4096、100、0.01和0.1,模型的嵌入层维数设置为64。为平衡多个任务的学习率,即对更新快的方向,设置较小的学习率,对更新慢的方向,设置较大的学习率,将多任务学习中组合损失的权重参数β设置为0.001。最后,为捕捉不同层次的需求特征,内核大小和内核步长分别取1、3、5、7和1、7、14、28的组合。
如表3所示,SVM模型表现出的性能最差,主要原因如下:一方面,SVM模型不能很好地处理大量的分类特征;另一方面,SVM模型没有考虑机票需求特征。ACEC模型在所有评估措施方面都优于SVM模型,这是因为ACEC模型在捕获序列数据方面具背一定优势,同样地,ACEC模型没有处理需求特性。与ACEC模型相比,LSTM模型通过捕获需求的时间序列特征,准确率提高了11.04%,验证需求特征的有效性。与LSTM模型捕获以天为单位的需求特征不同,BERT模型使用双向Transformer编码,对捕捉长距离时间序列特征更加有效,相比LSTM模型,BERT模型在所有评估指标方面至少提高了6.83%。
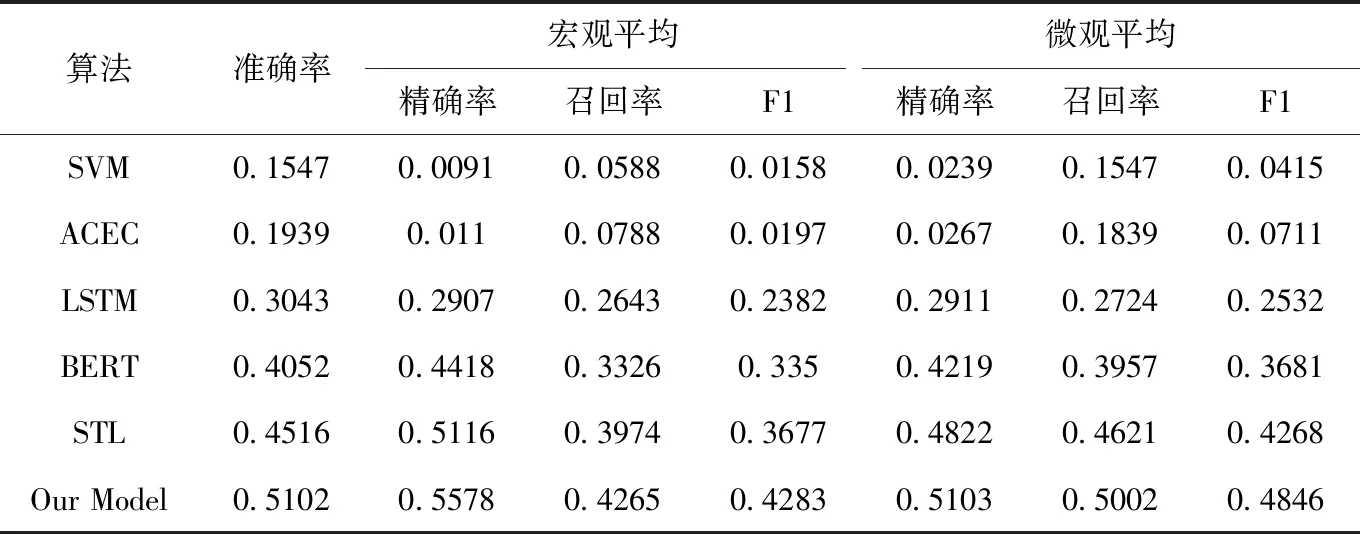
表3 不同模型的性能结果
与BERT模型对捕获长序列的需求特征不同,STL模型包含不同级别的多尺度需求特征,对长序列和短序列特征捕捉方面更有效。表3表明,在宏平均精确率指标方面,STL模型提高了6.98%。由于STL是本文所提出方法在多任务权重参数β=0时的特例,本文所提出的模型是β≠0时的改进,以显示辅助任务中多尺度特征提取的优势。同时,与模型STL相比,所提出的方法在权重参数β=0.001时,宏观平均F1分数提高了6.06%。这表明β=0.001时,多任务联合训练效果明显,模型可以更好地利用需求特征进行票价预测。
3.2.2 特征分析
机票特征与机票价格的关系。本小节旨在研究机票特征与价格之间的相关性。图2显示了航空公司和机票等级之间的相关性。航空公司“A”比其它航空公司提供更多的低成本机票,其潜在解释是低成本航空公司倾向于以较低的价格增加销售额。从图3可以看出,航线价格分布不同,例如“NGB→CAN”和“PEK→CTU”,其中“NGB”、“CAN”和“CTU”是机场的IATA三字母代码。然而,该分布显示往返航线的规律是相似的,例如“NGB→CAN”和“CAN→NGB”,其原因是往返相似的旅客对机票价格的敏感程度相似。

图2 航空公司与机票类别的相关性分析
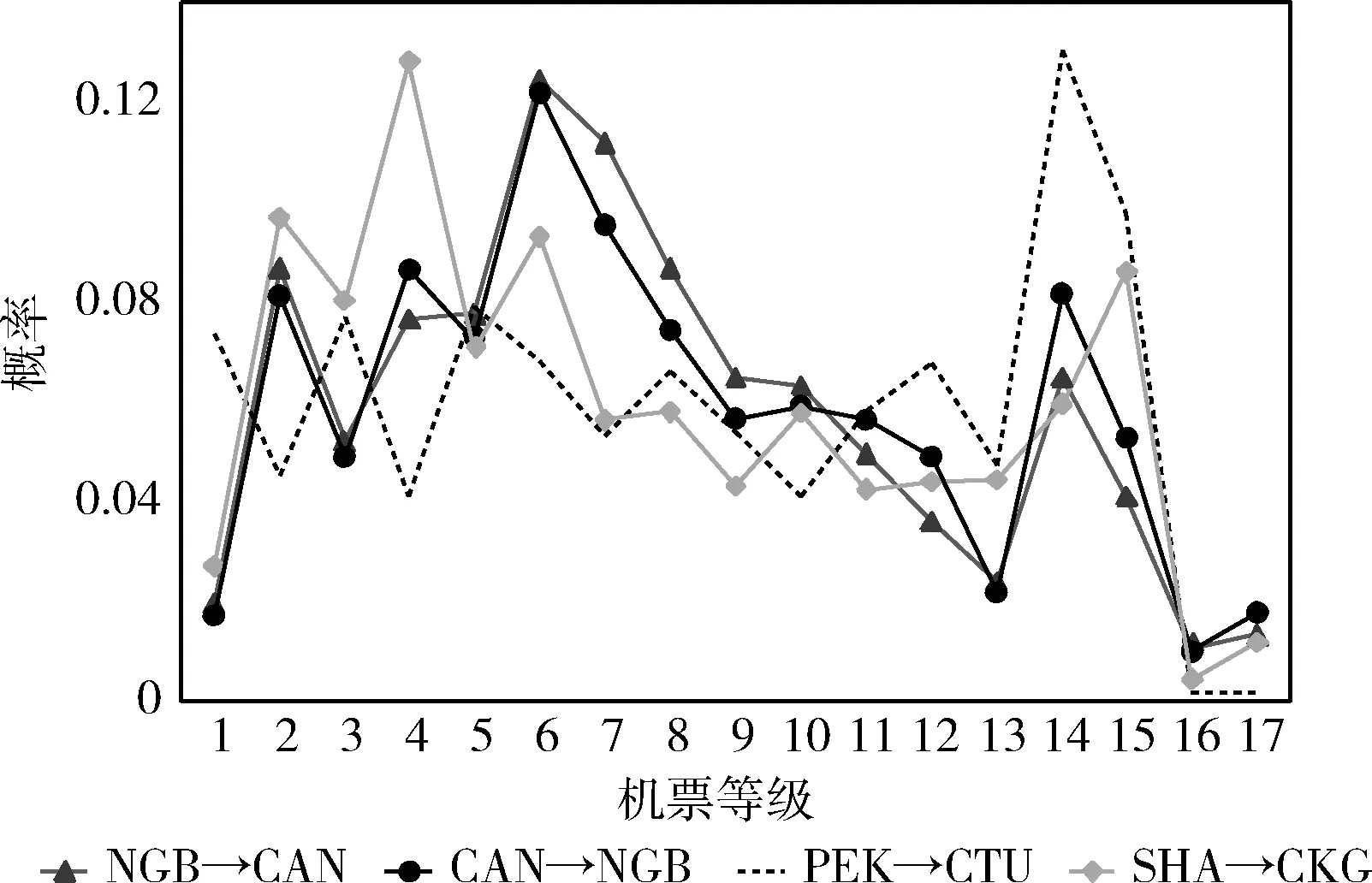
图3 航线与机票类别的相关性分析
3.2.3 超参数分析
通过设置不同的参数对随机选择的180条航线进行分析,共有4 517 548条订单记录,研究了模型训练中权重参数β和卷积核移动步长(Strides)的影响。
权重参数β目的是平衡主任务和辅助任务的损失,保证主任务和辅助任务学习率一致。在模型训练过程中,直接使用损失函数相加的方式,易导致多任务学习被机票预测任务或机票需求任务所主导,当模型倾向于拟合其中一个任务时,另一个任务的效果会受到负面影响,多任务学习模型效果会变差。通过多次实验得出的经验,将β设置为0.001、0.01、0.02、0.05和0.1。如表4所示,所提出模型在β=0.001时的准确率最高。它表明辅助任务确实利用相关信息来提高性能。
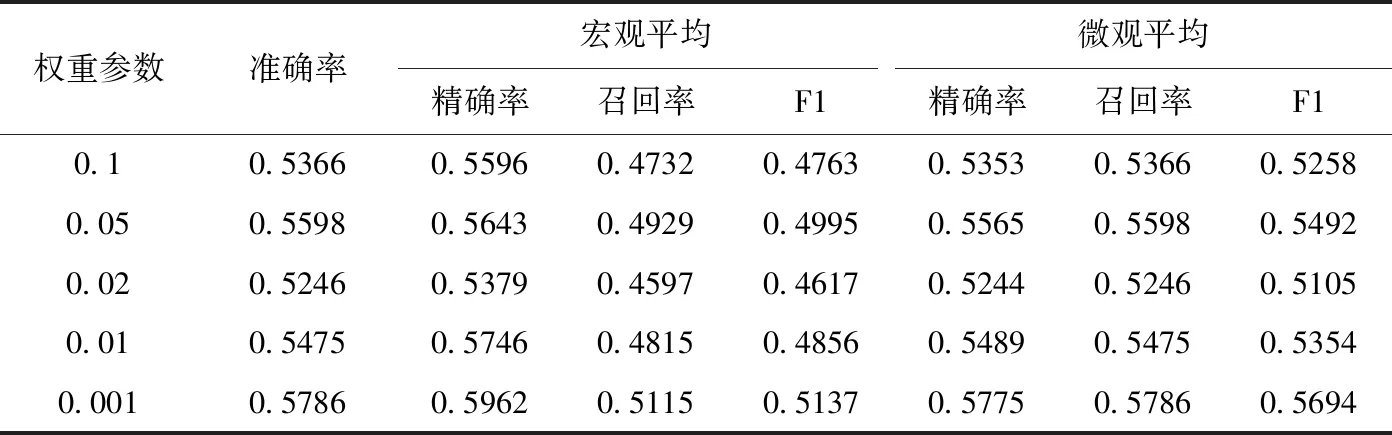
表4 对随机选择的180条航线上的权重参数β分析
卷积步长(Strides)在学习多尺度需求特征方面起着关键作用。步长为1、7、14、28分别代表日、周、半月、月层次的机票需求特征。如表5所示,通过设置不同的卷积核步长组合,验证所提出的方法在步幅1、7、14、28的组合情况下达到了最好的性能,这表明不同层次的需求特征可以提高价格预测的性能。
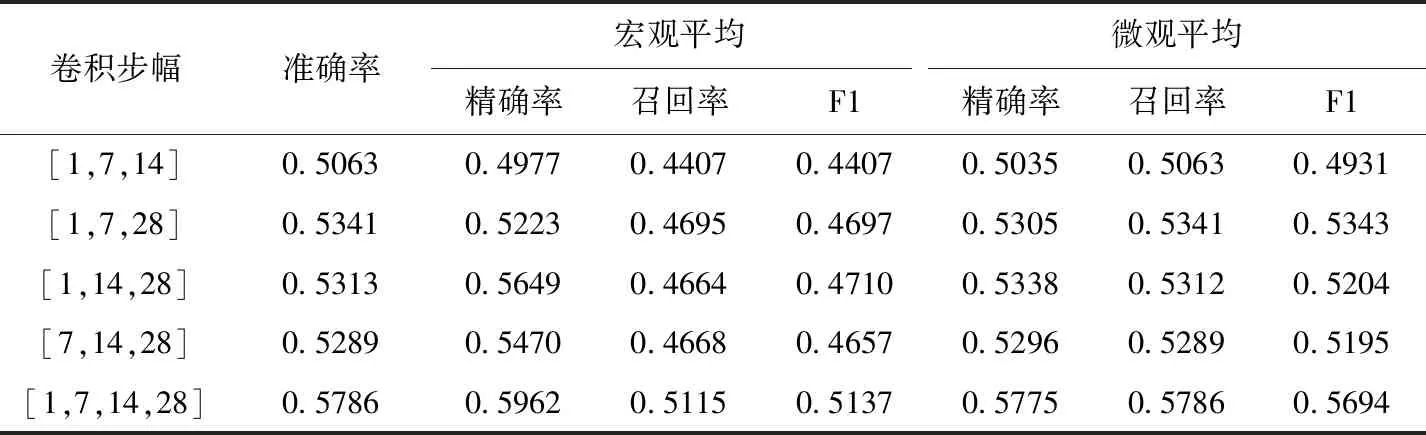
表5 对随机选择的180条航线上的卷积步幅分析
4 结束语
本文针对机票价格预测未考虑机票需求问题,设计了一个多任务学习框架,旨在将机票需求特征集成到机票价格预测,该框架为机票价格预测和机票需求预测分别设计了深度神经网络。首先,本文提出的网络学习每个任务的低纬向量表示;然后,主任务和辅助任务通过共享多尺度需求特征进行关联;最后,模型设计一个带有残差连接层和归一化层的前馈神经网络,学习特定的任务表示。模型在大规模旅客订单数据集上进行广泛实验,验证了多任务学习机制的有效性。此外,实验验证并分析多任务融合参数和多尺度特征对机票价格预测结果的影响,为航空公司进一步优化机票定价模型提供参考。
