基于迁移学习和卷积视觉转换器的农作物病害识别研究*
2023-09-11余胜谢莉
余胜,谢莉
(韶关学院信息工程学院,广东韶关,512005)
0 引言
粮食安全是国家安全的基础,而农作物疾病的防控是影响粮食安全的一个重要因素,及时准确地识别病害种类可以为农业生产提供有效的专业指导,从而提高农作物产量,减少经济损失[1-2]。
在农作物病害识别中,传统机器学习方法将识别过程分为图像预处理、图像特征提取和分类三个步骤,其中特征提取的结果是整个识别方法的基础,但特征提取方法往往需要丰富的经验和反复的试验,存在一定的主观性[3-4]。同时农作物病害图像存在背景复杂、病害目标区域不明显等特点,增加了特征提取与分类的难度。因此,基于传统机器学习的农作物病害疾病识别方法难以处理背景复杂的病害数据,且泛化能力较弱。
随着硬件设备计算能力的提升和人工智能技术的飞速发展,深度学习在各行各业都取得了非常优异的成绩,如人脸识别、机器翻译和行人检测与识别等方面。在农作物病害识别方面,基于深度学习的识别方法相比于传统机器学习方法在识别准确率和识别速度上同样有很大的提升;在图像分类识别方面,卷积神经网络(Convolutional neural networks,CNNs)是分类识别效果最佳的深度学习方法之一[5-6];在农作物病害识别方面,CNNs也取得了较好的分类识别效果[7-10]。洪惠群等[7]为了扩大网络模型的适用场景,将ShuffleNet网络中的ReLU激活函数用LeakyReLU激活函数代替,构建了轻量级神经网络用于农作物病害的识别。孟亮等[8]则以残差单元为基本网络结构设计了轻量级CNNs用于农作物病害识别。Mohanty等[4]构建了基于CNNs的识别模型,在PlantVillage数据集[9]上的识别准确率达到99.3%。马浚诚等[10]针对温室场景下黄瓜病害的卷积神经网络识别方法的平均准确率为95.7%。
卷积神经网络强大的特征自主学习能力在农作物病害的识别方面取得了不错的成绩,但也存在卷积神经网络训练参数量大、网络收敛速度慢、严重依赖于训练样本数据量等不足。近年来,迁移学习(Transfer Learning,TL)[11-13]使得网络模型能快速适应目标学习任务,可以有效缓解过拟合,提升模型性能。赵恒谦等[11]提出迁移学习与分步识别相结合实现对农作物病害种类的识别。张建华等[12]将ImageNet-1K数据集上预训练的VGG模型迁移到棉花病害数据集上,但ImageNet-1K数据集与棉花病害数据集相似度不大,迁移学习的知识没能很好地应用到目标数据集,最终识别准确率提升不明显。赵立新等[13]则首先在PlantVillage数据集上对模型进行预训练,然后在目标数据集棉花病害数据上对参数进行微调,获得平均93.5%的识别准确率。王东方等[14]基于迁移学习和残差网络提出农作物病害识别模型TL-SE-ResNeXt-101,在真实环境下病害农作物的识别准确率明显高于未采用迁移学习的模型。
以上的研究表明基于深度学习的农作物病害的识别准确率和鲁棒性方面都要远远优于传统机器学习的方法,但当前基于卷积神经网络的方法大多是在背景单一的图像数据集上训练学习和测试。在真实环境的农作物病害识别过程中,由于受各种噪声的干扰,实际的识别准确率会大大降低,难以满足实际应用的需求。
2017年Google的机器翻译团队成员Vaswani等[15]完全抛弃卷积神经网络和递归神经网络结构,仅采用注意力机制实现机器翻译任务,并取得当时的最佳效果。受Vaswani[15]的启发,Dosovitskiy等[16]尝试将Transformer应用到计算机视觉领域,提出Vision Transformer(ViT)模型。ViT包含输入图像分块、展平成序列、Transformer编码和分类识别等模块,不依赖卷积神经网络结构,对噪声的干扰有很好的鲁棒性,在图像分类任务上达到了很好的效果,ImageNet-1K上的分类准确率达到88.55%。
针对实际应用场景中包含复杂背景信息的农作物病害识别问题,本文在现有研究基础上,提出一种迁移学习与卷积视觉转换器(Convolutional Vision Transformer,CViT)模型相结合的农作物病害识别方法。
1 病害识别模型
1.1 卷积视觉转换器模型结构
标准的Transformer结构用于自然语言处理,输入为一维的标记嵌入(token embedding)向量。为有效处理输入图像,Dosovitskiy等[16]首先将输入尺寸为224×224的图像共划分为互不重叠的196个16×16大小的图像块;然后通过线性投影变换将各图像块映射到768维度的一维向量;最后将196×768特征矩阵输入到Transformer结构。
而在实现农作物病害识别时,不同种类病害的表观特征往往仅有细微的表观区别,有效学习到病害图像的细粒度特征对农作物病害的识别至关重要。为此,将卷积操作引入到ViT设计了卷积视觉转换器(Convolutional Vision Transformer,CViT)CViT模型,其整体框图如图1所示。对比ViT模型中的线性映像操作,本文设计了一个用卷积层组来实现输入图像映射到二维特征矩阵的过程。卷积模块共包含N层卷积,输入图像经过N层卷积操作后将映射到14×14×768的特征空间,并作为Transformer结构的输入。

图1 CViT模型的结构框图
1.2 注意力机制
注意力机制可以描述为将一个查询和一组键值对映射到一个输出,其中查询、键、值和输出都是向量。输出值通过加权总和计算得到,其中分配给每个值的权重由查询与相应键的兼容性函数计算。根据兼容性函数的不同,可以设计出不同的注意力机制,本文采用文献[15]设计的缩放点乘注意机制。缩放点乘注意机制的结构如图2所示。

图2 缩放点乘注意机制
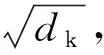
(1)
1.3 多头注意力机制
在实际应用中,根据给定相同的查询、键和值的集合时,模型能基于注意力机制学习到不同的目标特征信息,然后把不同的目标特征信息组合,捕获图像内多种信息间的依赖关系,达到提升模型识别性能的目的。传统注意力机制仅仅关注单一方面的注意力信息,为了从不同角度关注到不同的关键特征,Vaswani等[15]提出了多头注意力机制(Multi-Head Attention,MHA)。多头注意力机制首先独立学习得到h组不同的线性投影矩阵来变换查询、键和值;然后将h组变换后的查询、键和值将并行输入到注意力汇聚模块;最后将这h个注意力汇聚的输出串接在一起,并且通过另一个可以学习的线性投影进行变换得到最终的输出,具体计算过程如图3所示。
本研究结果显示,相对于NIPPV单用,纳洛酮联用NIPPV能显著增加PO2水平和降低PCO2水平,增加SaO2水平,两组比较差异均有统计学意义(P<0.01),说明纳洛酮联用NIPPV能显著纠正机体酸碱平衡,纠正低氧血症;其次,住院死亡率和再次有创气管插管率显著降低,说明纳洛酮能显著降低NIPPV治疗失败率,同时显著减少住院时间,有利于减轻患者经济负担。用药期间未发生严重不良反应,患者耐受性好,说明纳洛酮联用NIPPV安全性较好。

图3 多头注意机制
首先通过线性变换将Q、K、V映射到新的子空间,然后使用缩放点乘注意机制进行计算,其中第i个注意力机制的计算结果计为headi。
(2)
然后按式(3)将所有注意力机制的计算结果级联,同时再次使用线性变换转回原来的空间。
MultiHead(Q,K,V)=Concat(head1,…,headn)WO
(3)
2 试验结果与分析
2.1 农作物病害数据集
本文试验在PlantVillage[9]和ibean[17]两个公共数据集上完成。
1) 公共数据集PlantVillage。PlantVillage数据集共收集了14个物种38个分类和1个不包含植物叶片图像的背景类别共54 306张农作物叶片图像,各个子类的图像从275到5 357张不等,存在一定程度的样本分布不均衡问题。所有图像都是在实验室条件下采集,背景单一,图像分辨率为256像素×256像素。PlantVillage数据集部分样本数据如图4所示。

图4 PlantVillage数据集图像样例
2) ibean数据集。ibean数据集是由Makerere AI实验室与负责乌干达农业研究的国家机构国家作物资源研究所(NaCRRI)合作在乌干达不同地区实地拍摄的叶子图像。数据集包含健康叶子图像、角斑病和豆锈病3个类别,其中训练集包含1 035个数据样本,验证集包含133个样本,测试集包含128个样本。ibean数据集是在田间拍摄,包含背景较复杂,符合实际应用环境,图5所示为部分样本数据。

(a) 角斑病
2.2 试验平台
在进行模型的训练中,试验的硬件配置情况为Intel Core i5-6600K CPU,TITAN X显卡,64 G内存。软件系统为Ubuntu18.04操作系统,Tensorflow深度学习平台,并使用CUDA和cuDNN作为支持。
2.3 评价指标
准确率(Accuracy)常作为分类模型的一个主要评价指标,但当样本数据不均衡时,准确率高低主要受占比大的类别影响。因此,本文通过准确率Accuracy、查准率Precision、查全率Recall和F1值四个指标评价模型的性能,各指标定义如式(4)~式(7)所示。
(4)
(5)
(6)
(7)
式中:TP——真实值为正且预测为正的数目;
FN——真实值为真而预测值为负的数目;
TN——真实值为负且预测也为负的数目;
FP——真实值为负但预测为正的数目。
2.4 卷积层组结构的选择
卷积层组的主要作用是将图像转换为视觉转换模块的输入,同时为对比增加卷积层后与原ViT模型的性能,本文设计的CViT模型的卷积层组最后的特征映射都统一为14×14×756,即与标准ViT模型视觉转换模块的输入维度一样。表1为本文对比试验的3种卷积层组结构,表2为不同卷积层结构在PlantVillage和ibean两个数据集上采用迁移学习方法所获得的识别准确率。

表1 卷积层组结构Tab. 1 Architectures of convolutional layer group

表2 不同卷积层组结构的识别准确率Tab. 2 Accuracy of different convolutional architectures
对比3种卷积层组的网络结构发现,在仅采用1个卷积层的情况下,两个数据集上都获得最高的识别准确率;当增加到3个卷积层时,准确率都有明显的下降。原因可能是单层16×16卷积核的卷积操完成了图像块的非线性映射,同时大尺度的卷积核可以较好地保留了图像的底层结构特征,这有利于ViT模型在此基础上实现高层语义特征的抽象。因此,本文设计的CViT模型采用的是单层卷积输入的结构模型。
2.5 训练过程中的模型准确率与损失值
将CViT、ResNet-50和EfficientNet-b0三个模型在PlantVillage数据集上的试验如图6所示,各模型都是迭代训练30个Epoch。在PlantVillage数据集上,除用ImageNet-1K数据集预训练后的Efficient-b0模型在前14个Epoch迭代的准确率和损失值有较多波动外,其他模型的收敛速度都比较快,各模型的准确率最终达到99.50%以上。但CViT模型在采取迁移学习方法后,迭代到第3个Epoch时准确率达到了99.52%,收敛速度要快于其它模型,说明在使用迁移学习后,模型在预训练过程中学习到了图像识别的公共特征,然后在目标数据集中能快速针对具体目标任务学习到对应的特征信息,实现目标数据集下的识别任务,达到节约模型的训练时间、提升识别性能的目的。
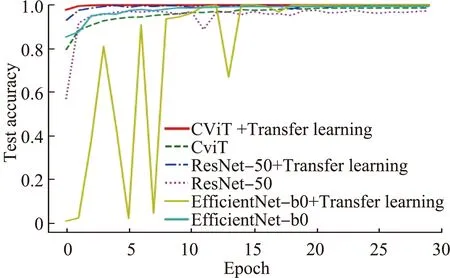
(a) 测试集准确率
ibean数据库中测试集上的准确率和损失值如图7所示,除使用采取迁移学习的CViT和ResNet-50两个模型在迭代到第5个Epoch后达到收敛,其它模型在前30个Epoch的准确率和损失值波动都比较大,没能达到收敛状态。
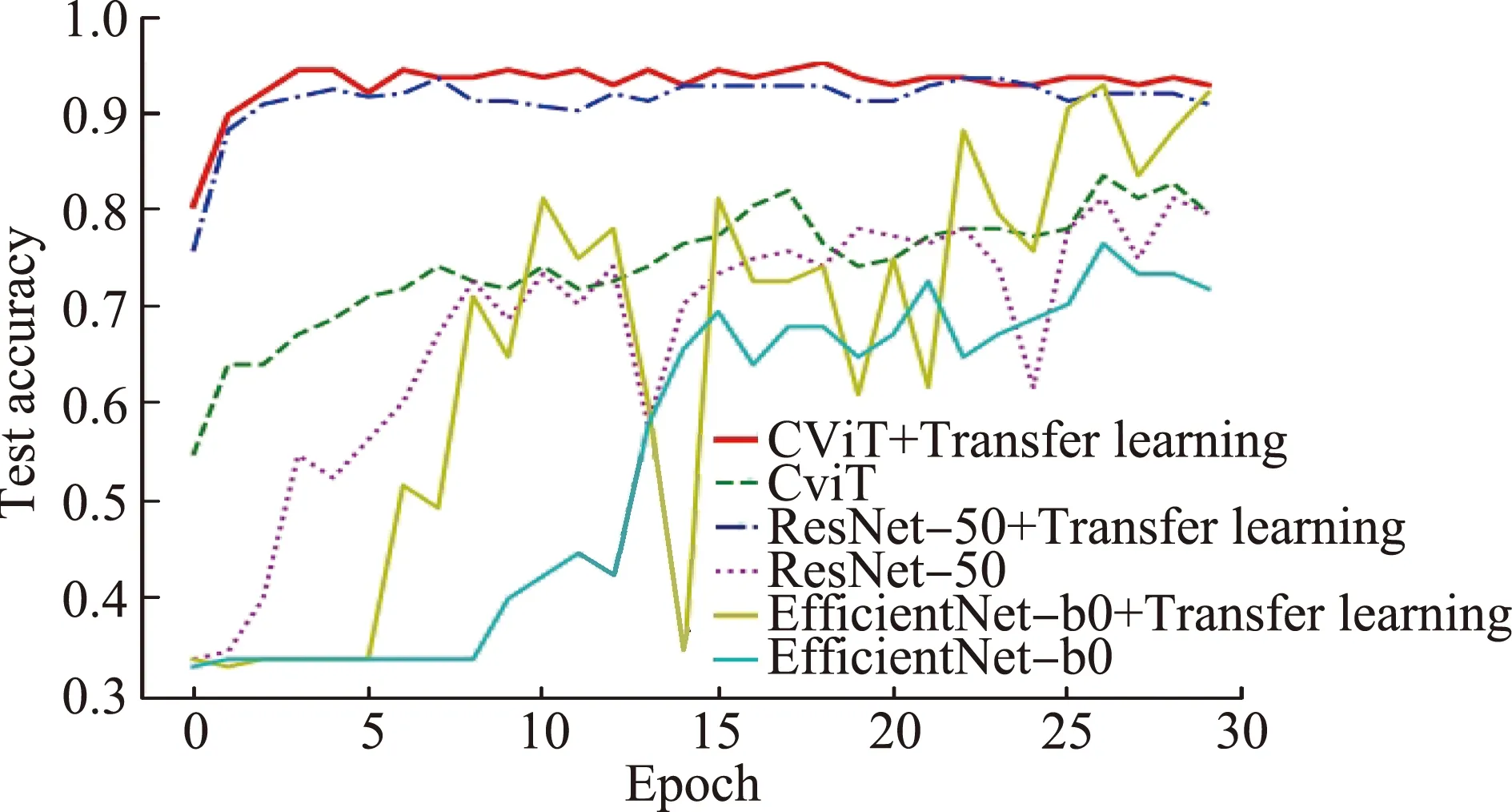
(a) 测试集准确率
导致该结果的可能有如下3个原因:(1)ibean数据集是在真实环境下采集,图像背景较复杂;(2)ibean数据集样本数目偏少,远小于PlantVillage数据集;(3)部分角斑病和锈斑病图像差距细微,难以辨别。但采取迁移学习后的CViT模型有较好的收敛过程,且达到了最高识别准确率98.12%,这说明设计的CViT模型使用迁移学习的方法后,在样本量少的情况下也能够从复杂的背景中学习到目标对象的细微特征信息,从而达到提高识别准确率的目标。
2.6 数据集中各子类的性能比较
为了解迁移学习过程中CViT模型对各子类的分类情况,试验中保存训练过程中训练好的最佳模型,然后用最佳模型对测试数据集进行测试,表3为PlantVillage测试集中各子类的查准率、查全率和F1值。

表3 PlantVillage测试集的各子类查准率、查全率、F1值Tab. 3 Precision, recall and F1 value of CViT on PlantVillage dataset for each class
从表3可以看出,各个类别的查准率和查全率以及F1值都比较高,出错相对较多的是玉米北方叶枯病、玉米灰斑病、番茄早疫病和晚疫病。通过对识错图片的比对分析发现,玉米北方叶枯病和灰斑病、番茄早疫病和晚疫病的图像相似度较高,容易出现误判的情况。表4为ibean数据集在测试数据上的试验结果,平均查准率为0.946 1,平均查全率为0.945 4,平均F1值为0.945 6。试验结果表明基于迁移学习的CViT模型在真实环境下,可以较高效的完成农作物病害的识别工作。
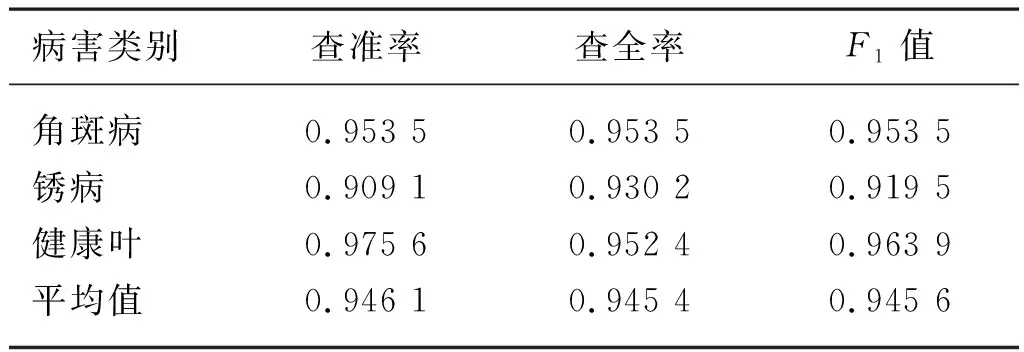
表4 ibean测试集的各分类查确率、查全率、F1值Tab. 4 Precision, recall and F1 value of CViT on ibean dataset for each class
2.7 各模型最佳准确率
为了验证本文识别方法的有效性,在PlantVillage和ibean两个数据集上与当前最佳网络模型进行对比,试验结果如表5所示。基于迁移学习的CViT模型在PlantVillage中准确率高于ViT模型0.33%,比ResNet-50模型的准确率高0.28%,也高于Efficient-b7模型0.05%。在ibean数据集中,本文提出模型的测试准确率高于ViT模型0.46%和Efficient-b7模型0.68%。试验表明,本文提出的模型在两个数据集上都获得了最高准确率99.91%和98.12%。

表5 PlantVillage和ibean数据集上不同模型的平均准确率Tab. 5 Average accuracy with previous state-of-the-art methods in PlantVillage and ibean datasets %
3 结论
1) 为提升农作物病害识别系统的性能,本文将迁移学习和ViT模型用于设计农作物的识别模型。为验证设计方法的有效性,在公共数据集PlantVillage数据集和自然环境下采样的ibean数据集完成相应的试验。在PlantVillage数据集包含了38个农作物病害类别以及一个背景图像类别共39个类别,最终达到了99.91%的评价识别准确率,0.999 0的查准率,0.998 2的查全率和0.998 6的F1值。在ibean数据集中同样获得了98.12%的平均识别准确率,以及查准率、查全率和F1值分别为0.946 1、0.945 4、0.945 6。经过对比试验结果表明,CViT方法在相同情况下具有更高的识别准确率、查全率和查准率,具有很好的鲁棒性,能获得较好的识别性能。
2) 本文提出的基于迁移学习的ViT农作物病害识别方法,可以作为农作物病害诊断系统的预警。相关从业人员可以根据诊断系统的识别结果,及时对有疾病的农作物采取有效措施。本文算法通过进一步优化后可以部署到移动端进行实时识别,提高识别系统的便携性,为农业智能化发展做出贡献。
