基于集成学习优化的肉制品安全风险等级预警分析
2023-09-09穆书敏陈锂尹佳郭鹏程陈晨董曼赵锦徐晴雪文红桂预风
穆书敏,陈锂,尹佳,郭鹏程,陈晨,董曼,赵锦,徐晴雪,文红*,桂预风*
(1.武汉理工大学理学院,湖北武汉 430070)(2.湖北省食品质量安全监督检验研究院,湖北省食品质量安全检测工程技术研究中心,国家市场监管重点实验室(动物源性食品中重点化学危害物检测技术),湖北武汉 430075)(3.石首市公共检验检测中心,湖北荆州 434200)
随着我国全面建成小康社会的目标实现,人民的生活质量不断提高,人民群众对食物的需求也随之从温饱转为安全和营养。近年频发的食品安全问题事件不仅严重影响群众身体健康,还关乎社会稳定,食品安全问题已成为我国的民生问题[1]。食品安全风险管理是食品安全工作的主要内容,涉及原材料提供、加工、生产、销售、运输等多个环节,加强各环节的管控是降低食品安全风险的有效途径[2-4]。据调查,肉制品在我国居民日常食品消费中所占的比重越来越大,作为具有高营养价值的重要日常消费食品,也是具有较高安全风险和隐患的食品之一,保障肉制品质量安全满足消费者的需求刻不容缓[5]。但当前肉制品供应链环节复杂多变,经手的企业公司较多,且各企业之间无法相互监控,信息不对称使得肉制品安全问题缺乏可溯源性,难以有效的定位和管理[6]。囤积的肉制品检测数据具有数据量多信息量少的特征,挖掘该历史数据中的信息研究肉制品检测数据的食品安全风险评价预警反馈机制具有重要意义。目前数据挖掘工作受到学者的广泛关注,该研究对保障人民身体健康、实现肉制品的源头防控和主动预防具有重要意义。
大数据时代的到来推动了机器学习的发展,机器学习被广泛应用于各领域并取得了良好效果[7-9]。根据目前食品安全风险评估和预警研究现状,将经典方法与机器学习模型进行组合往往取得较好的效果[10-14]。而集成学习考虑综合不同机器学习算法的优点,将多种简单的机器学习模型结合起来,通过一定的策略形成一个集成学习模型[15,16],在食品生产以及其他领域有广泛应用[17-20]。荷兰食品和消费品安全局在2015年起草了关于红肉链的DT分类模型,Van Asselt等[21]使用三个DT分别对红肉中化学物质(禁用物质、污染物、兽药)进行分类,研究表明DT有助于化学物质的分类,可作为风险监测的计划工具。王小艺等[22]使用层次分析法(AHP)结合XGBOOST算法对大米安全风险进行预测,研究对比了支持向量机(SVM)、最邻近分类算法(KNN)、长短期记忆人工神经网络(LSTM),XGBOOST显示出较好的平稳性和准确性。Xu等[23]使用RF对家禽农场和加工环境中的菌落进行预测,该研究有效的帮助牧场家禽种植场指定食品安全控制策略。
本文基于全国肉制品抽检数据,采用独热编码对不平衡数据进行数据处理,以决策树为基础,分别构建决策树(DT)、极端梯度提升树算法(XGBOOST)和随机森林(RF)集成学习算法,建立食品安全风险评价预警模型,并通过准确率、精确度、召回率等一系列指标说明模型的应用效果。该研究有助于监管部门提高对于肉制品安全的监管效率,有助于构建更加完善的肉制品质量安全监督管理体系,也为集成学习在食品安全问题中的进一步应用提供了参考。
1 材料与方法
1.1 数据处理
1.1.1 数据来源
本文数据来源市场监督管理局[24]公开的2013~2017年全国(除港澳台地区)肉制品抽检数据和HBQT检验检测数据。原始数据的信息包括抽样地点、单位地点、被抽样单位名称、抽样编号、样品名称、生产日期、样品规格、保质期、检验项目、检验结果等79项内容,涵盖了熟肉制品和预制肉制品等多种肉制品类别,共计约4万条数据。本文以肉制品数据检验结果的综合风险等级为研究对象,通过与各产品的生产信息相关联来构造对于肉制品质量安全风险等级预警机制。但原始数据中如“商标”、“检验机构”等多列与研究无关,且部分列不能直接作为变量使用,需要对数据所含信息的内容进行整合、提取、清洗等处理后确定变量。
1.1.2 数据清洗
数据的质量和特征决定了机器学习的上限,而模型和算法只是在逼近这个上限[8]。本研究中肉制品数据涵盖维度信息少,因此数据处理部分尤为关键。数据预处理的首要步骤为数据清洗,数据清洗主要包括删除重复值、统一规格、修正逻辑、数据压缩、补足缺失或空值、丢弃异常值等,该过程能有效地提高数据质量,保证数据的完整性、唯一性和合法性[25]。然而数据清洗工作同时存在复杂繁琐、耗时长,且影响结果分析的问题需要解决。综上所述,本文对肉制品数据处理工作主要通过计算机程序化解决,部分结合人工处理。本研究具体数据处理流程如图1所示。
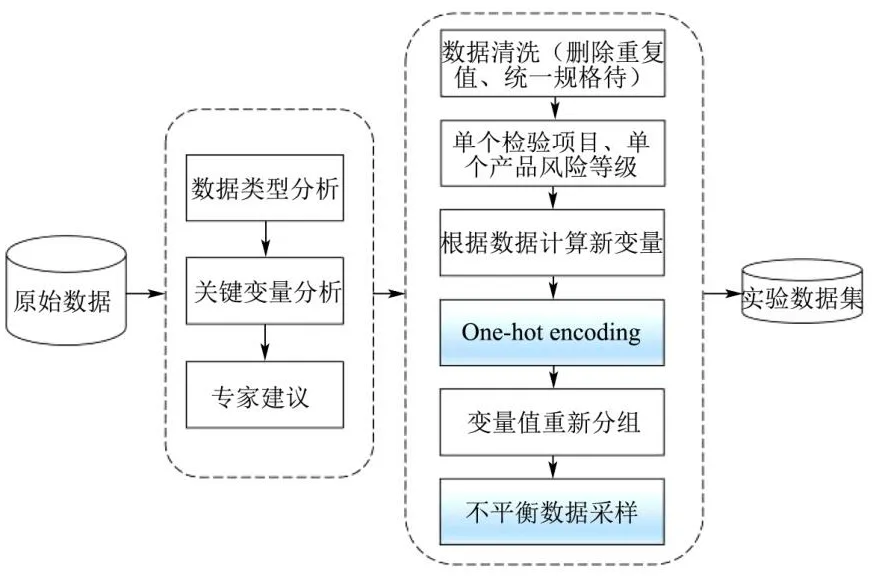
图1 数据处理流程图Fig.1 The flow diagram of data processing
选择与本研究中与肉制品安全风险等级预警有关的食品品种、生产省份、抽样省份、抽样地点、生产日期、保质期、抽样日期、是否大型生产企业、是否大型经营企业、是否进口、检验项目、检验结果作为数据源。其中食品品种、抽样地点、是否大型生产企业、是否大型经营企业、是否进口划分类别明确,且无缺失值,可直接作为输入变量。产品的生产日期和抽样日期记录形式有多种,需要进行统一,并将前者拆分为年(Year)、月(Month)两个变量便于特征重要性分析确定模型的输入变量。保质期中含有信息多、内容复杂,有30 d、6个月、12个月(25 ℃以下真空包装)、1年等多种记录,本研究中将保质期转化为以天为单位并去温度、包装完整性等条件,如12个月(25 ℃以下真空包装)转化为720 d,作为输入变量。检验项目的检验结果按照前期研究[26]的处理方式进行标准化和归一化进行去量纲,用于划分及计算综合风险等级,作为模型的输出变量。
异常值检测中,一个产品的抽检时间为2005年4月8日,对此判断为录入时的人工错误,将其年份修改为2015而不作删除。数据处理过程严格遵循完整性、合法性、唯一性原则。原始数据40 052条经处理后为38 315条,利用率达到96%。
1.1.3 获取等级数据
将抽样产品的检测结果进行分级区分有利于提高对于食品安全的敏感度和精准判断[27,28]。本文研究对象为肉制品综合风险等级,该等级通过两步得到:以抽样产品编号作为每个产品的唯一编号,第一步将去量纲后的检测结果通过专家打分划分为5个等级,1~5级分别表示安全、无警、轻度警、中度警、重度警;第二步将每一个产品的所有检测项目通过改进的softmax函数获取该产品的综合风险等级。综合风险等级用level表示,计算方法见公式(1),其预警程度和说明与检验项目一致。肉制品的项目分类和检验项目见表1,检验项目等级划分标准见表2。

表1 肉制品检验项目Table 1 Inspection items of meat products

表2 检验项目风险等级划分标准Table 2 Standard for risk classification of inspection items
式中:
i——风险等级值,取值为i=1, 2, 3, 4, 5;
wi——每个产品中检验项目等级为i的占比。
值得注意的是,综合风险等级加大了对严重损害身体健康的检验项目的惩罚力度,若一个产品的任一检验项目风险等级为5,则产品综合风险等级为5级,而不使用公式(1)计算。
1.1.4 特征构造
由于原数据中模型可用的特征较少,故利用清洗后数据集中的日期及省份变量进行特征构造。研究表明[18]通过多个字段构造新特征作为输入变量,新特征能够包含无法直接获取的重要影响因素。结合生产日期、抽样日期和保质期重新构造新特征“保鲜度”,用lasting表示,简记为l,具体计算方法见公式(2)。
式中:
li——自定义的第i个产品保鲜度;
ai——第i个产品的抽样日期;
βi——第i个产品的生产日期;
periodi——第i个产品的保质期。
保鲜度值分布在[0,1]区间时肉制品在保质期内,当保鲜度大于1时为过期产品。
根据产品生产省份和抽样省份信息构造新特征“省份一致性”,用province_consistance表示,若生产省份与抽样省份一致,则记为yes,若不一致则记为no。
1.1.5 独热编码(One-Hot Encoding)
为了进一步探究因素中的不同取值对食品安全风险的影响,采用one-hot encoding处理变量。one-hot encoding又称一位有效编码,可以处理非连续性数据特征,不但能一定程度上扩充特征维度,还可以处理缺失数据,是将类别变量转换为机器学习算法易于利用的一种形式的过程[29]。目前多用one-hot encoding处理特征作为输入变量来提高模型的分类精度、决策质量以及计算时间[30-32]。本文采用one-hot encoding对变量特征进行处理,不但能扩充数据特征的维度,还能具体比较各取值对肉制品等级分类的影响程度,但使用过程中需要慎重选择扩充的变量,盲目扩充所有变量易造成维度灾难,严重影响模型效果。为探究季节性因素对肉制品安全风险等级的影响,使用one-hot encoding对月份(month)变量处理将其转化为二进制输入形式,然后转化为稀疏0,1矩阵作为输入变量。处理后月份变量由1维增加到12维,程序中默认从0开始编码,故一月为month_0,二月为month_1,其余月份以此类推。表3给出one-hot encoding编码前后月份变量的比较。

表3 独热编码处理前后月份变量比较Table 3 Comparison of monthly variables before and after one-hot encoding
1.1.6 数据集变量说明
结合肉制品数据特征和研究目的,决策树模型具有较好的适用性,本文优化模型均以决策树为基础构造。但部分特征的变量种类过多,若按照原始类别建树易导致树过大、枝过多以及过拟合现象,为了提高构建的基础树质量,将部分变量的值重新分组后作为模型的输入变量,将各生产省份根据国家地理区域将其分为八个大类记作地区(Areas)变量,其中生产地非中国的抽样产品一律归为境外类别。抽样地区以实际情况对餐馆、生产线等进行合并记作位置(Location)变量。分组后变量的取值均用英文字符表示。数据经过处理变换后对相应的符号含义以及模型中的变量符号相关说明见表4。
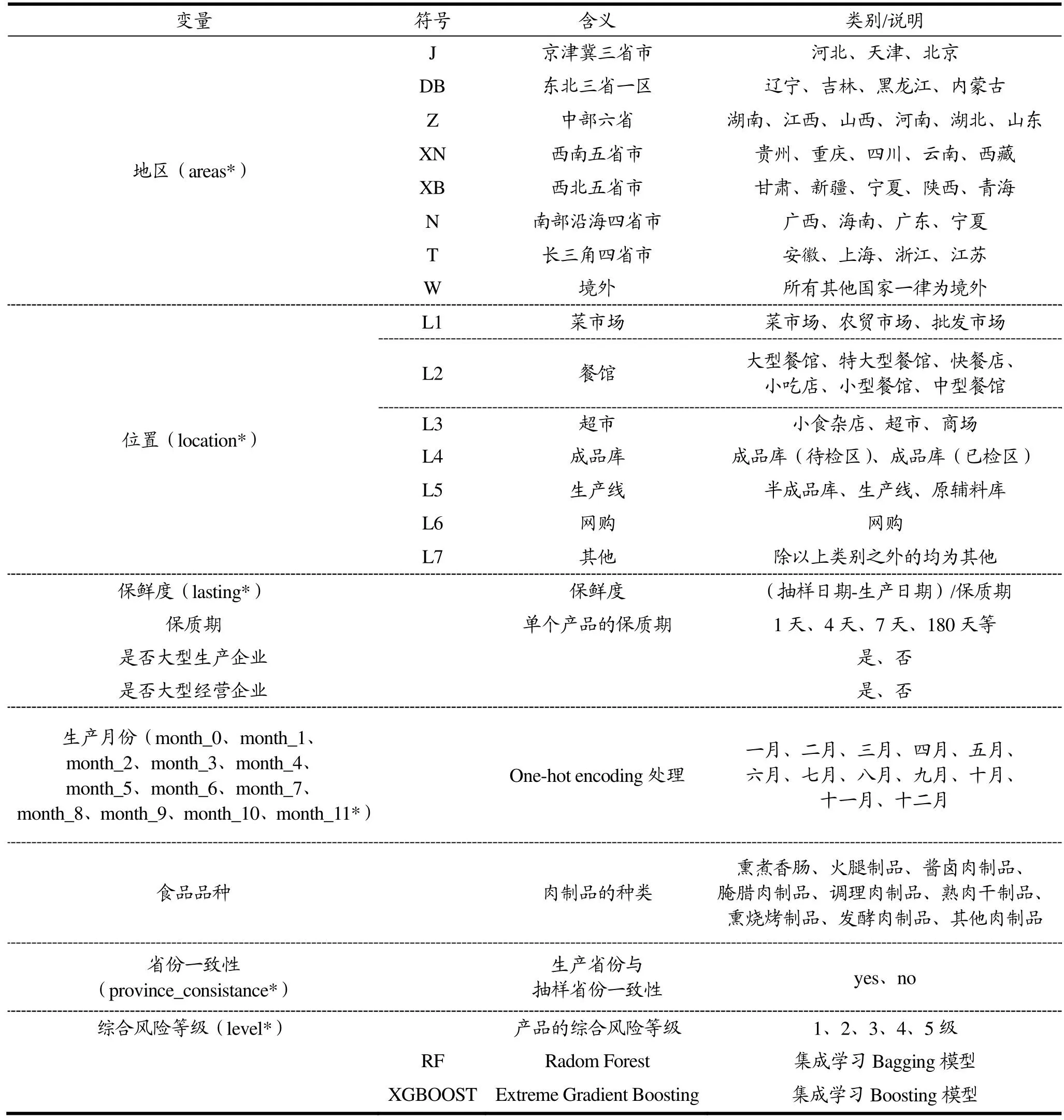
表4 变量及符号说明Table 4 Description of variables and symbols
1.1.7 数据重采样
经上述一系列处理后得到模型的输入和输出变量,可使用该数据集进行分类模型学习。分类模型基本假设为样本类是平衡的,而本文研究数据严重偏离平衡。不平衡样本下训练模型往往为达到更高的精确率,偏向于多类别的样本而忽略少类别的样本[33]。抽样肉制品数据中1级产品较多(安全),但需要重点关注对象为含有风险的产品,特别是5级(严重损害身体健康),以不平衡数据建模缺乏实际意义且影响模型分类效果,因此要解决不平衡数据问题。一般不平衡数据的处理方法有欠采样、过采样、阙值移动[34]。但由于阙值移动过于复杂,欠采样会损失大量样本信息,故选择过采样。过采样又称上采样,在本研究中即对除1级以外各等级的产品在原始数据中重复抽样以增大数据量,使其能够充分挖掘少量样本中的信息。图2为本研究的采样示意图。
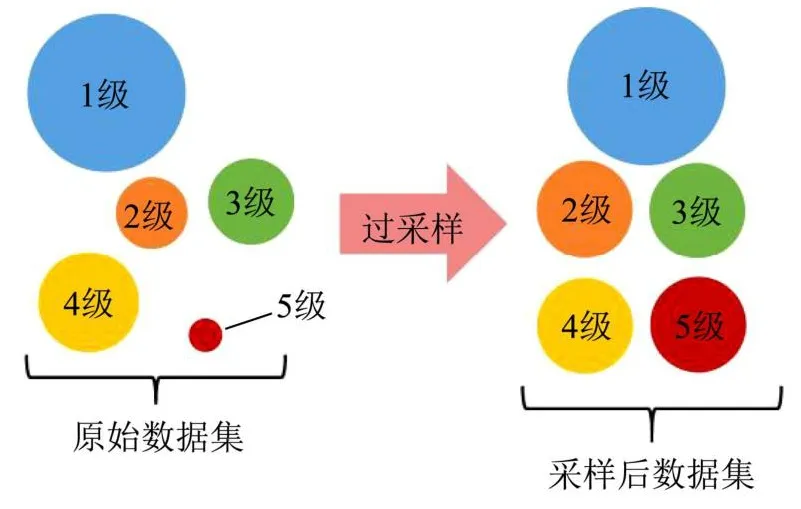
图2 采样示意图Fig.2 Demonstration of sampling
经清洗处理后的数据集中含38 315条数据,风险等级为1级的产品为29 770条,占中总体的77.70%,2级、3级、4级、5级的数据分别为1 001条、1 686条、4 713条、1 145条,分别占总体的2.61%、4.40%、12.30%、2.99%。可见样本存在严重的数据不平衡现象。图3为不平衡样本数据集在决策树模型上的分类可视化结果(部分),由于1级产品数量远大于其他等级产品数量,图中显示多数分类结果为1级,失衡样本下模型的分类结果无法学习到有风险的产品,更难以挖掘具有严重安全风险食品与影响因素之间的关联,显然缺乏实际研究意义。综上所述,使用上采样改善不平衡数据,1级数量保持不变,将1级数量与2、3、4、5级产品数量分别按照8:2、7:3、6:4扩充数据量少数类的样本。表5为各比例上采样后的数据量。
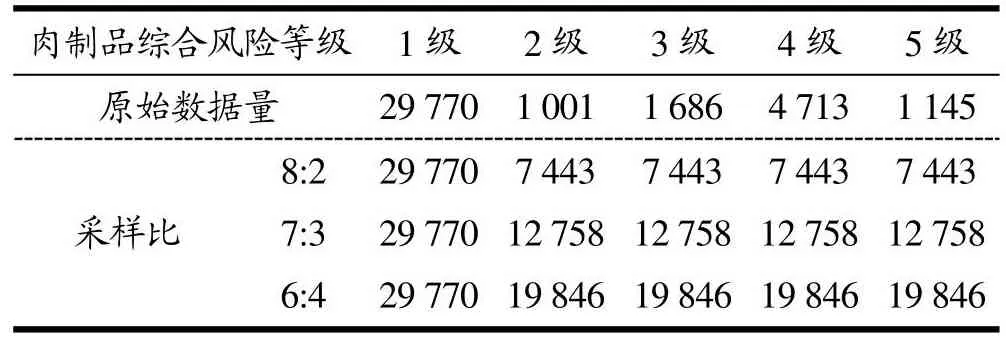
表5 上采样数据量说明Table 5 Description of volumes of oversampling
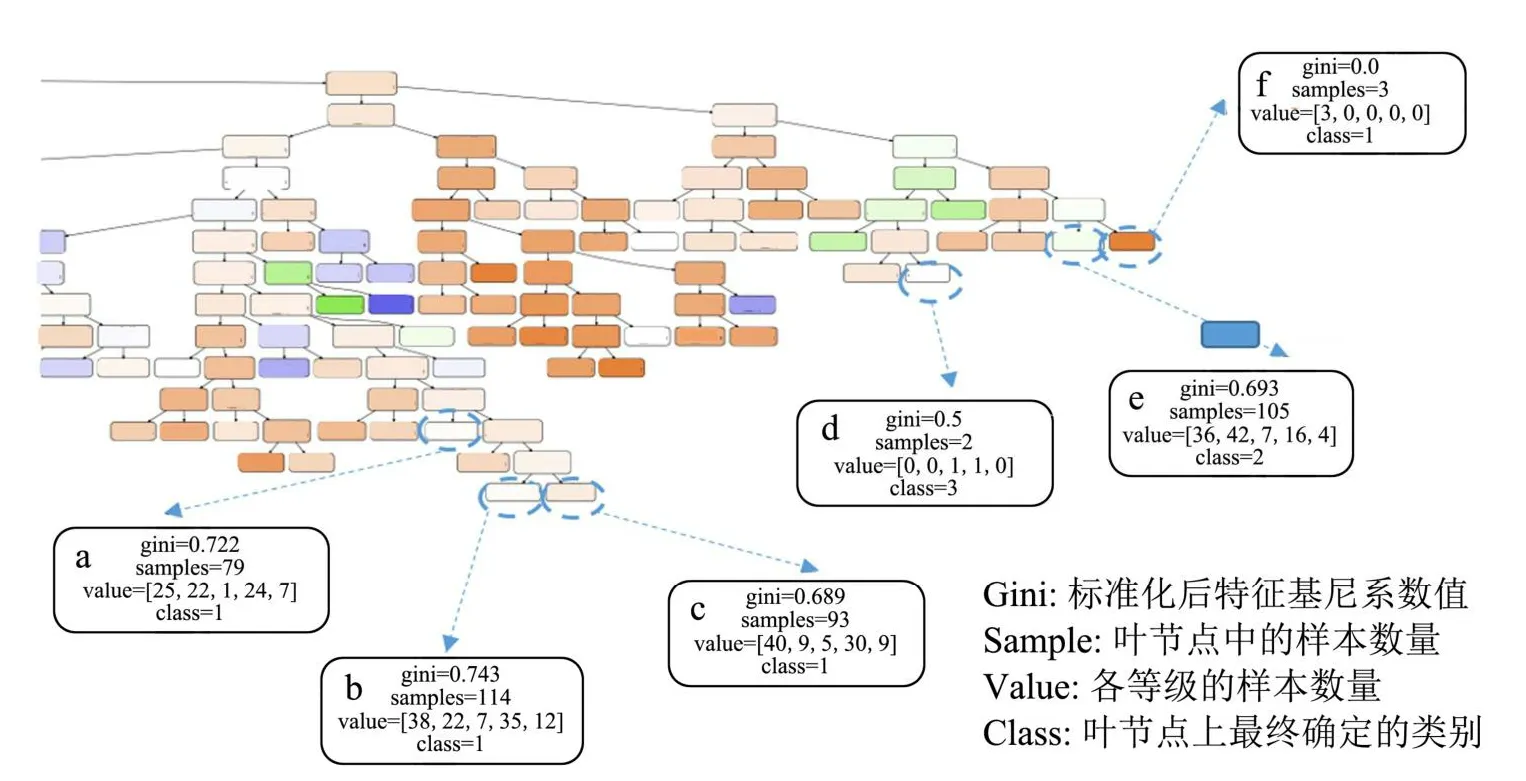
图3 决策树部分可视化结果Fig.3 A part of visualization results of DT
1.2 模型的构建
集成学习(Ensemble Learning)通过构建并结合多个学习器来完成学习任务,也被称为多分类器系统。相比于单一学习器,将多个学习器结合能获得显著优越的泛化性[34,35]。根据个体学习器生成方式集成学习分为Boosting和Bagging两类,前者个体学习器之间存在强依赖关系,必须串行依次生成新的学习器;后者个体学习器之间不存在强依赖关系,可同时并行生成多个学习器。图4为集成学习模型的构建示意图。
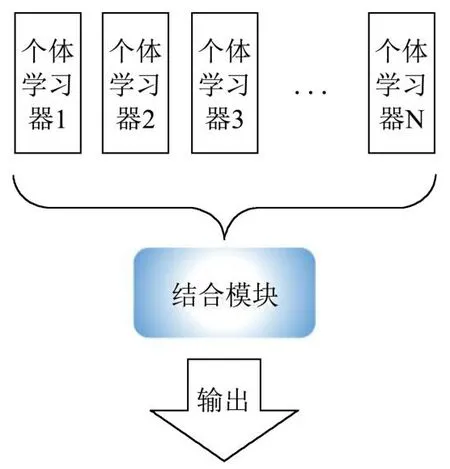
图4 集成学习示意图Fig.4 Sketch map of Ensemble Learning
其中个体学习器又称基学习器,相同个体学习器之间的集成称“同质”的集成,不同个体学习器之间的集成称“异质”的集成。本文以决策树为基学习器,分别构建XGBOOST和RF两个同质集成模型用于肉制品安全风险等级预警研究。
1.2.1 决策树(Decision Tree,DT)
决策树是常见的机器学习方法,其构建主要包括特征选择、决策树的生成、决策树的修剪[34]。特征选择依据信息论的相关理论进行,这一过程对应特征空间的划分和决策树的生成,而决策树的修剪利用验证数据集对已生成的树进行剪枝并选择最优子树。其中特征选择是决策树算法的核心,选择划分的特征依据该属性含有信息量,1948年香农提出的“信息熵”可以对信息量进行量化度量[36]。式(3~7)为决策树中信息熵(Ent)、信息增益(Gain)、信息增益率(Gain_ratio)、基尼系数(Giin)的计算方法。
式中:
D——样本集,第k类样本所占比例为Pk,k=1, 2, 3, …, |y|;
A——离散属性;
V——属性A包含的可能V个取值A1,A2, …,Av;
Dv——D中包含的所有属性A取值为Av的样本,Ⅳ(A)称为属性A的固有值,属性A的可能取值数目越多(即V越大),则Ⅳ(A)的值越大。
决策树经典算法有ID3、C4.5和CART,分别用信息增益、信息增益比和基尼系数来进行特征选择。决策树计算复杂度低,输出结果易于理解,对缺失值不敏感,可以处理不相关数据,但容易产生过拟合的问题,对此引入的集成学习模型,秉承了决策树算法优点的同时缓和了过拟合现象,能有效提高模型的性能。
1.2.2 极端梯度提升树算法(Extreme Gradient Boosting,XGBOOST)
XGBOOST是Boosting算法的经典代表之一,基模型按分步前向加进行,训练基模型的训练集加入了正则项的损失函数每次都进行一定的转化,在迭代完成之后才进行下一次迭代,这不仅能够提高运行速度和准确率还能够有效的抑制过拟合[22,34]。本研究中的基模型采用CART树,通过串行的方式对多个树进行迭代,最终输出结果为产品综合风险等级。图5为XGBOOST模型的构造过程。
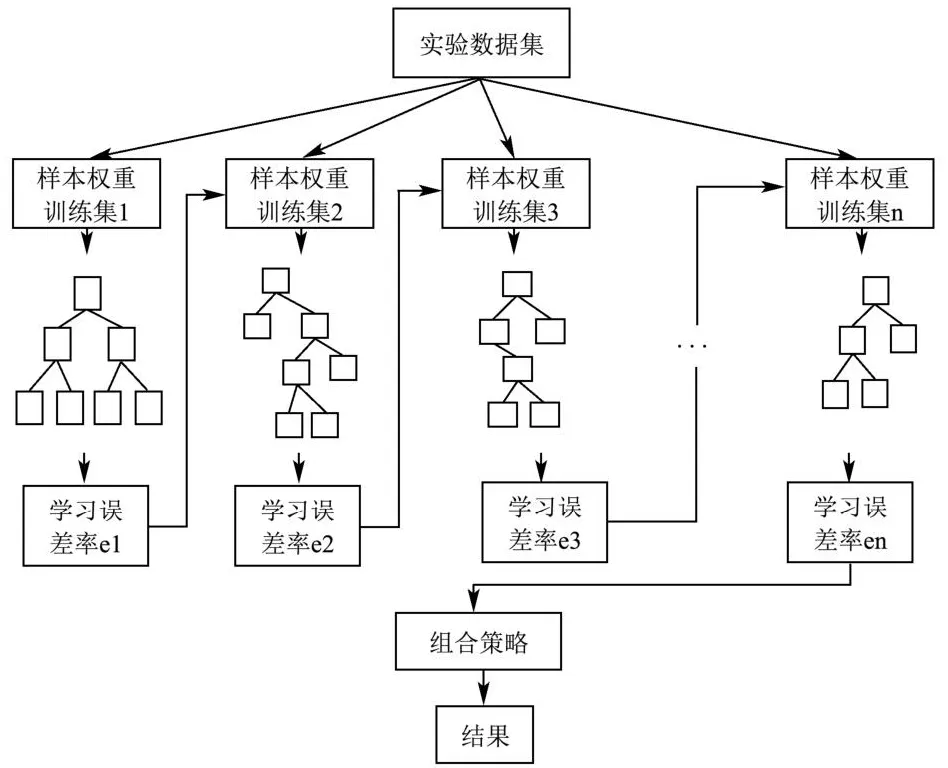
图5 XGBOOST原理示意图Fig.5 Schematic diagram of XGBOOST
1.2.3 随机森林(Random Forest,RF)
RF是bagging的扩展变体,以DT为基学习器构建bagging集成,进一步在决策树训练过程中引入随机属性选择[34]。RF准确率高,泛化能力好,能够有效处理大数据集,在众多现实任务中展现出强大的性能[18]。本研究将处理后的实验数据集作为输入变量,首先随机选择包含k个属性的子集,其次以包含不同子集的N个子数据集分别构建决策树,最后通过投票机制确定最终肉制品的风险等级类别。图6为RF模型的构建过程。
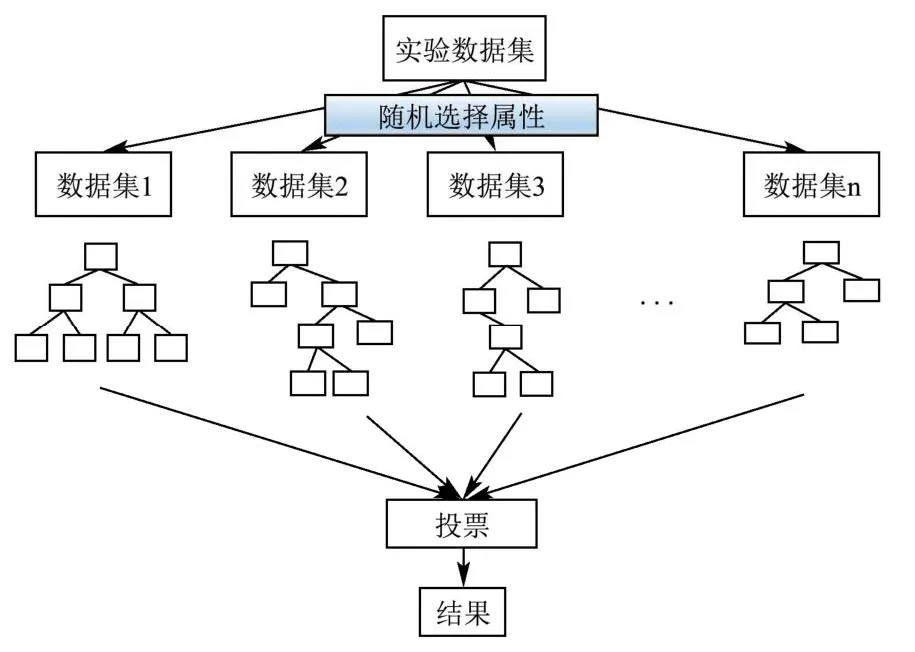
图6 随机森林原理示意图Fig.6 Schematic diagram of random forest
1.2.4 最优模型技术路线图
本文以DT为基础,将集成学习引入肉制品安全风险等级预警模型的应用中,构建了XGBOOST和RF两个模型,并以肉制品风险等级分类的结果以及评价指标来比较说明模型效果。经特征构造、数据重采样、超参数优化等优化处理后XGBOOST在肉制品安全风险等级预警中效果最佳(对比分析见2.2.2节模型比较分析)。图7为本文最优XGBOOST模型的构建框架。
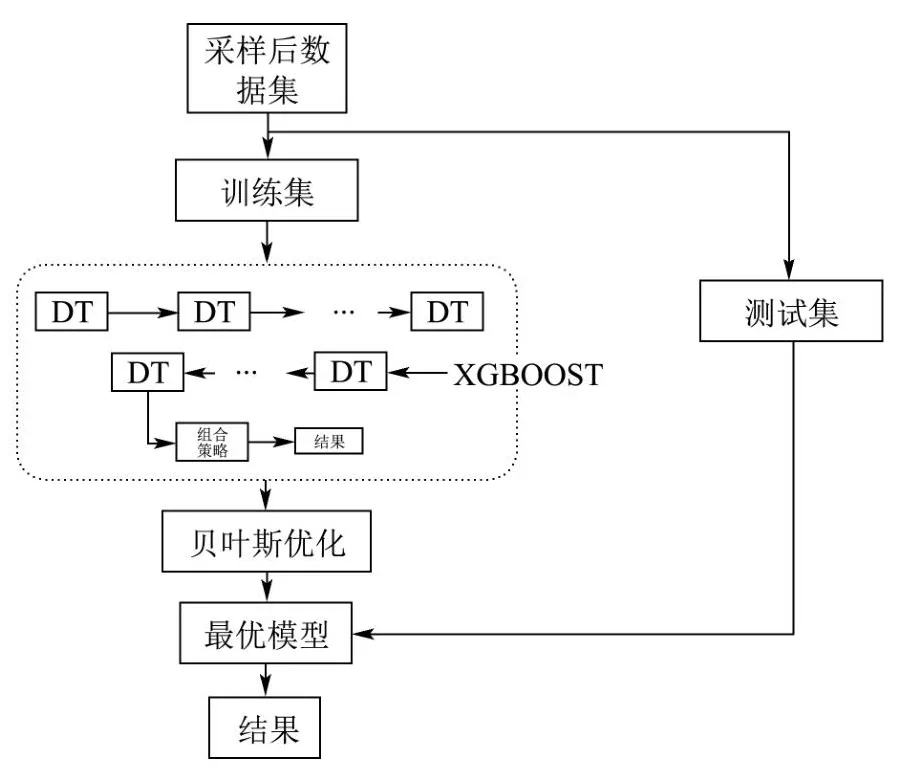
图7 肉制品安全风险等级预警的最优模型Fig.7 Optimal model for risk level warning of meat products
1.3 模型的评价
1.3.1 特征重要性
基于树的集成模型,特征的重要性是在所有单颗树上该特征重要性的一个平均值,单颗树上特征重要性是该特征进行分裂后平方损失的减少量的求和,即把这个变量在所有树上出现的节点数累计求和,若该特征在所有树上出现的次数越多则越重要。
模型的输入变量为1.1.6节中处理后的变量,每个变量称为特征xj,其中j取值为areas、location、lasting、保质期、食品品种、是否大型生产企业、是否大型生产企业、是否进口、month(/month_1,…,month_12)。记作重要程度,特征xj在整个模型中的重要程度:
特征xj在单独一棵树上的特征重要程度:
式中:
M——模型中的树的数量;
Tm——第m棵树,满足m∈{1, 2, …,M};
L-1——树中非叶子节点数量;
vt——在内部节点t进行分列式选择的特征;
——内部节点t分裂后平方损失的减少量。
本文将one-hot encoding处理后变量作为集成模型的输入变量,再通过计算特征重要性排序,能够更精确对比不同特征取值对于肉制品安全风险等级分类的影响程度。
1.3.2 性能度量指标
分类模型的评价指标通常为分类准确率,以准确率作为评价指标便于理解,但对于多分类问题来说相对单一[37,38]。为了更全面地选择最佳模型、评估模型性能,使用混淆矩阵和多个评价指标综合比较分析模型的效应。本文使用的评价指标有准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值(Precision和Recall的调和平均数)。表6和公式(10~13)为混淆矩阵以及各指标计算方法,本文对于模型的整体效果主要以F1综合判断,辅助参考Accuracy、Precision和Recall指标。
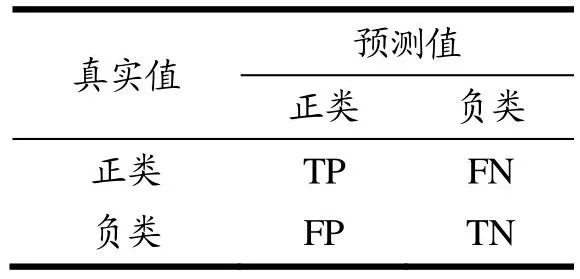
表6 混淆矩阵Table 6 Confusion matrix
1.4 数据分析
本文的实验环境为64位Windows10计算机处理器和操作系统,相应配置的CPU:Intel第11代处理器,处理器型号为i5-1135G7,主频2.40 GHz,内存16 GB。Anaconda作为开源的Python发行版本,包含大量工具包且能够并存多个版本Python。本研究代码基于Anaconda 4.10.3中的Jupyter Notebook平台通过Python 3.7实现,数据处理使用numpy和pandas包,集成学习模型的构建通过调用sklearn模块中的Random Forest Classifier和xgboost模块中的XGBClassifier,展示分类结果的混淆矩阵图使用matplotlib包绘制,模型的超参数优化借助于Bayesian Optimization库。将1.1.7节重采样后的数据集中的areas等特征作为输入变量,产品综合风险等级level作为输出变量,按照8:2将数据分为训练集和测试集,设定划分数据集的种子为66以保证不同模型下训练集和测试集的一致性。
2 结果与分析
2.1 分类结果分析
2.1.1 混淆矩阵分析
本文将2013-2017年的肉制品监测数据经处理采样后分别在决策树、XGBOOST和RF模型中进行分类综合评价,得到各模型下测试集分类的混淆矩阵。图8为以8:2采样的编码和超参数调节前后生成的混淆矩阵,本文肉制品数据类别为5类,当对少数类以8:2进行采样时,安全肉制品(1级)与有风险肉制品(2级、3级、4级和5级)的数量比例恰好为1:1,相对均衡(其他比例采样以及模型的混淆矩阵不展示)。在混淆矩阵中右侧的颜色深浅可直观看到各类的数量,颜色越深数量越多,左侧坐标0~4分别表示实际等级1级、2级、3级、4级和5级,底部坐标0~4分别表示预测的等级1级、2级、3级、4级和5级,对角线上的值表示实际类别和预测类别一致的数量。
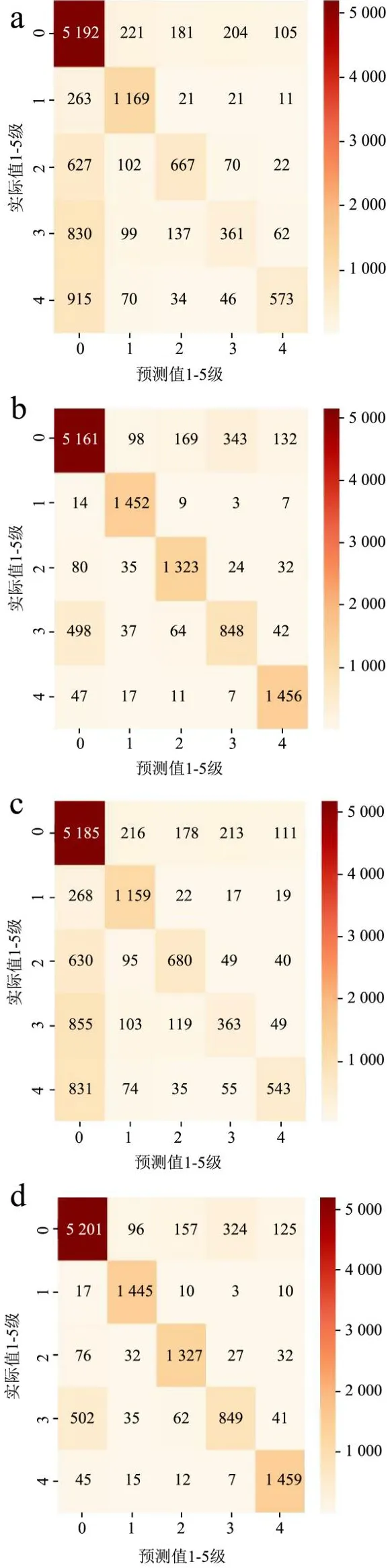
图8 测试集混淆矩阵Fig.8 Confusion matrix of test set
由图8混淆矩阵,首先对比(a)和(b),参数优化后对角线上的颜色明显加深,最左边一列的颜色变线,说明经过超参数优化后的预测效果明显提升;其次对比(a)和(c),对角线上前2个颜色较深,其余均较淡,左边第一例中后3个颜色较深,说明1级2级分类效果好,而3、4、5级分类较差,但经过处理后(c)对角线上以外区域颜色比较淡,说明错分类别有显著的改善,从方格中标注数据量也能够证明效果的提升;最后(d)展示出来颜色对比较为鲜明,说明了双重处理下比单一处理更有效。
2.1.2 评价指标分析
混淆矩阵简单直观展示了分类的大致趋势,为了进一步说明肉制品模型分类的有效性,表7给出XGBOOST模型(决策树和RF模型的处理方式相同,本文不展示决策树和RF各类别分类结果数据,仅在2.2.2节中给出综合指标进行比较)不同采样情况下测试集的超参数调节以及one-hot encoding处理前后各肉制品风险等级分类的具体指标。
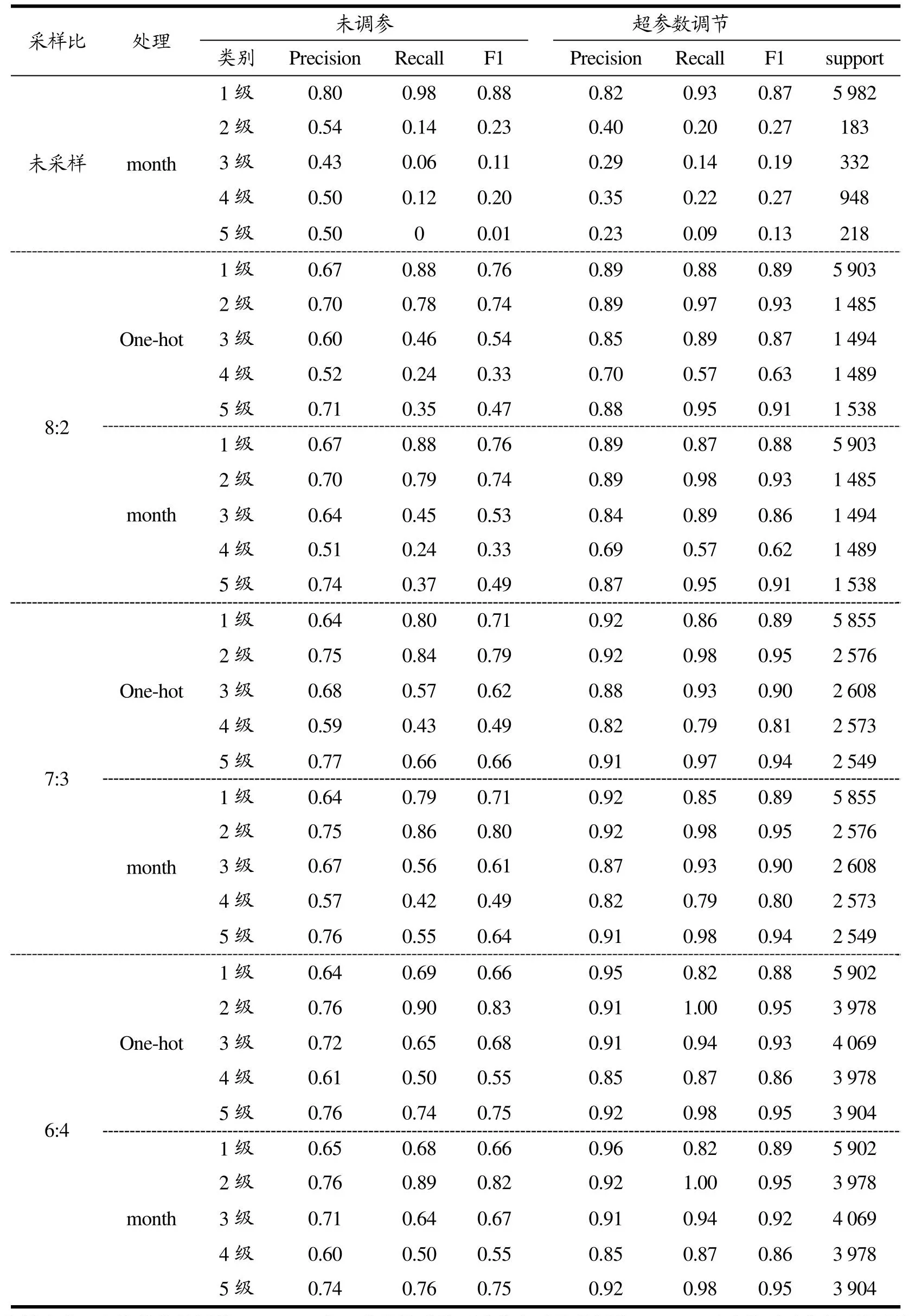
表7 测试集各级产品评价指标Table 7 Test set product evaluation indexes at all levels
由表7中结果可得:在XGBOOST模型中,(1)首先对比独热编码处理,该编码后模型的肉制品风险等级分类的各指标有小幅度提高,使用one-hot encoding提高F1值的同时能够更加具体分析月份取值的影响程度;(2)其次分析超参数优化,结果显示,经贝叶斯优化后各指标上升效果显著,Precision平均提高了0.18、Recall平均提高了0.22、F1值平均提高了0.2;(3)最后比较各个风险等级肉制品的总体分类效果在不同处理下的情况,1级Precision最高,2级和5级Recall最高,2级和5级F1值最高,综合看2、5级分类效果最好,其次是1、3级,相比之下4级的分类效果稍差。综上,XGBOOST模型在肉制品安全风险等级分类中的应用效果较好,且随着one-hot encoding处理和超参数调节,稳定性进一步得到了提高,能够较好的实现肉制品风险等级的分类预警。
2.1.3 特征重要性分析
利用特征重要性分析对原始特征进行变量选择并确定时间维度的变量,以及one-hot encoding处理后的各因素分析。由于编码后变量较多,仅保留前十个重要特征分析,图9为变量的特征重要性结果。
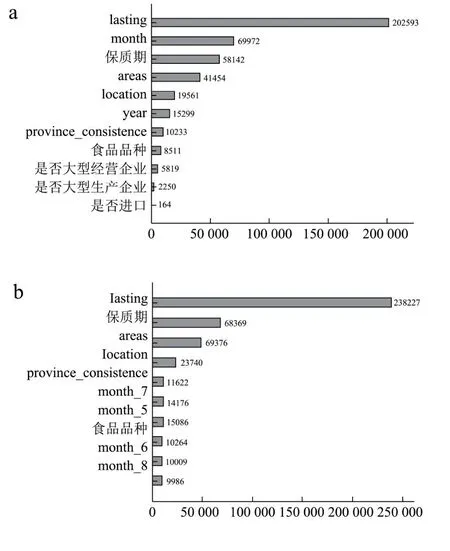
图9 变量选择和特征重要性分析Fig.9 Variable selection and feature importance analysis
图9a为原始特征的部分特征重要性排序,位居前三位的分别是lasting、month、保质期。Lasting对食品安全分级影响最大,而是否进口、是否大型生产企业、是否大型经营企业分类的影响程度很小,结合原始数据情况,进出口数据较少使得对于风险等级的分类不够明显。是否是大型生产企业、是否是大型经营企业的分类影响最小,由于原始数据中对于生产企业、经营企业的规模化分不够具体,该分类辨识度较低,没有中小型等企业,类别划分过于粗略对风险等级分类有一定程度的影响。原始特征的重要性排序显示出变量月份对肉制品安全风险分级的重要性,故而对月份进行one-hot encoding,再根据特征重要性比较月份取值的影响程度。此外还对其他变量进行了one-hot encoding处理,经过XGBOOST模型验证F1值没有提高,仅有月份处理后有了一定的提高,故本文仅对月份进行扩充,同时避免了维度灾难。
图9b中处理后的特征重要性可分为三个层次。(1)lasting;该指标直接反应抽样产品的新鲜程度也间接包含了存储的温度要求、包装等难以获取的复杂因素,该指标所处位置一定程度反映了食品安全中的不确定风险包含因素多。(2)保质期、areas;两者相差不大,保质期长短对于保鲜剂以及存储条件有不同限制,在不同环境下也有可能引起食物出现安全问题,该环节的影响也要重视。(3)食品品种新、location、province_consistance、month_7、month_6、month_8、month_5;食品种类和抽样地点表明不同产品生产条件等情况的差异,对食品安全风险的影响较大。province_consistance对食品安全风险等级的分类影响同样较高,该指标表示生产省份和抽样省份是否一致,包含了产品抽检前阶段经历的运输时长和路程的信息量,结果显示对食品安全的影响较为重要。使用one-hot encoding能具体了解各个月份对于食品安全风险等级分类的影响,位列前面的分别是6月、4月、5月和7月,月份作为季节性因素直接表现变量,包含了整年度外部温度环境,季节性需求、季节性生产量等难以收集的复杂因素,处理前后月份的重要性充分说明了其中包含的信息量多,对肉制品安全风险影响之大。
2.2 模型比较
2.2.1 模型参数优化
由于各算法参数配置存在差异,对不同模型下的重要参数进行调节,使用贝叶斯优化(Bayesian Optimization)对超参数调节,该方法比sklearn中的网格搜索(Grid Search CV)调节效率更高,运行速度更快且更加稳健[39]。本文通过贝叶斯优化调节DT、XGBOOST和RF的相关超参数,在训练数据集中使用5折交叉验证调整优化。
表8中展示的为三个模型重点调节的超参数。max_depth为树的最大深度,min_samples_leaf表示叶子节点最少样本数,max_feature决定单个决策树使用特征的最大数量,min_samples_split内部节点划分需要的最小样本数,learning_rate可提高模型的鲁棒性,n_estimators为迭代次数,表示生成树的数量,subsample控制每棵树随机采样的比例,可调节过拟合和欠拟合。consample_byterr表示每棵树随机采样特征占比,min_child_weight表示最小叶子节点权重和。每个模型下通过贝叶斯优化寻找最优的参数组合进而优化模型性能,结合分类各指标结果表明经过超参数调节之后的模型性能得到了进一步提升。

表8 不同模型的参数配置Table 8 Parameter configuration of different models
2.2.2 模型比较分析
本文研究了DT、XGBOOST和RF目前广泛应用的三个模型,其中集成学习模型XGBOOST和RF分别以DT为基础的改进,通过肉制品抽检数据的分类来对食品安全风险等级进行预警,不同采样情况的训练集和测试集随机种子设定为66以保证数据集的一致性和可比性,表9为不同采样情况下三个模型的最优结果对比。
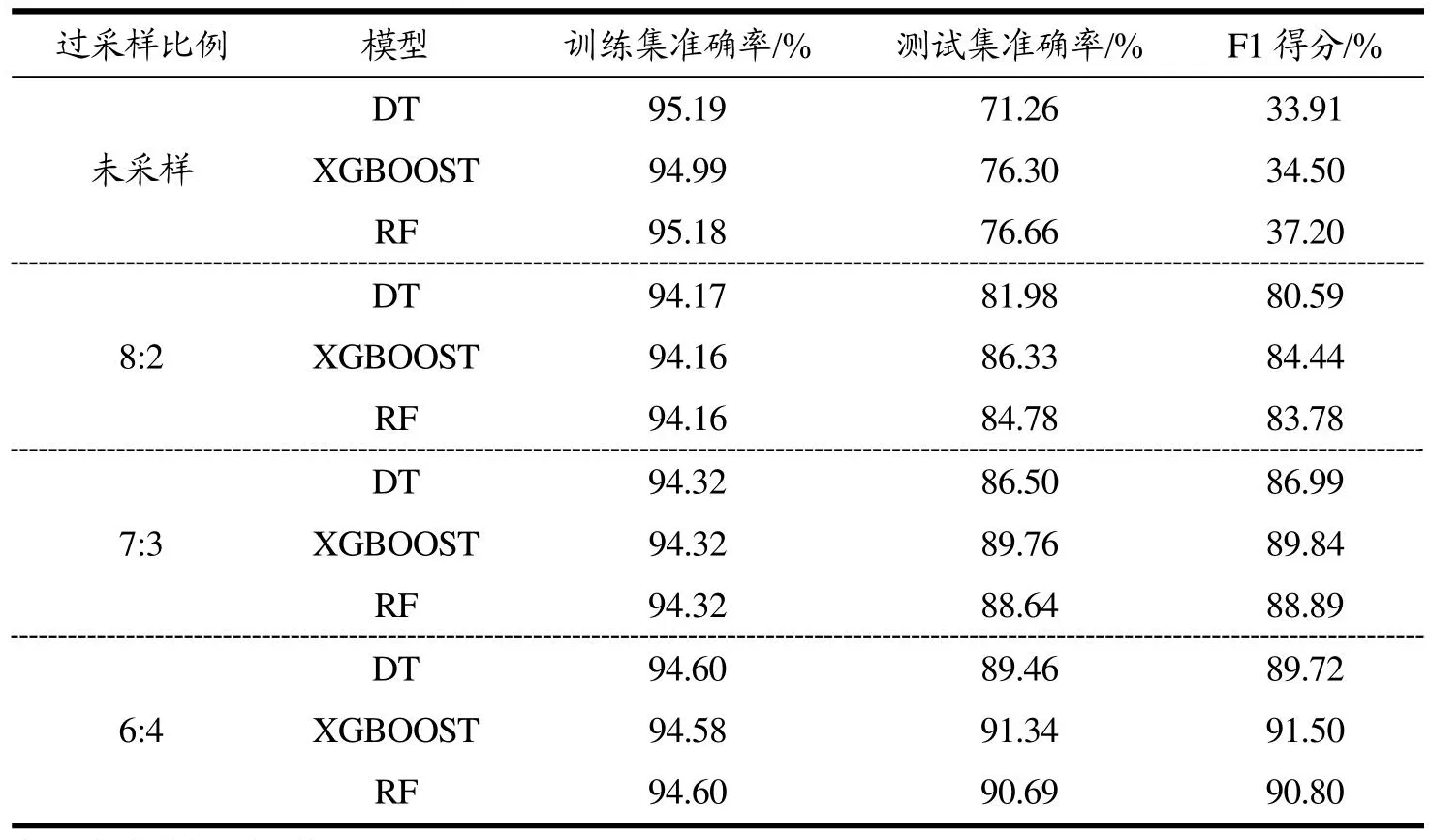
表9 不同模型评价指标对比Table 9 Comparison of evaluation indexes of different model
由各模型下的训练集测试集准确率以及F1值得出,(1)在采样之后模型的分类效果F1值均能达到80%,整体效果较好,模型的测试集准确率达到了94%,学习效果较好且各模型的训练效果没有显著区别。但根据测试集的分类准确率反映出不同模型的泛化能力差别,测试集和训练集的准确率的平均误差中DT、XGBOOST和RF分为0.09、0.05和0.06,以综合指标F1值来看XGBOOST得分最高,相比之下集成模型中XGBOOST更适合肉质品抽检数据的安全风险评价分析。(2)根据不同采样情况分析得出,随着小样本比例的提高,模型的学习能力有了显著的提高。在样本严重不平衡情况下,三个模型的训练集准确率均高于采样之后能够达到95%,测试集准确率在70%~80%之间,若只凭借准确率来判定分类效果均在可接受范围内,但从F1得分(综合Precision和Recall)得分看效果显然较差,F1平均值仅有35.20%,说明在不平衡样本中仅凭准确率作为模型评价标准的可信度较低。采样后的F1值至少提高45%,当采样比例由8:2增加到6:4模型的F1值平均升高了7.73%,DT、XGBOOST和RF分别提高了9.13%、7.06%和7.02%,虽然DT整体提升效果最高,但综合来看XGBOOST的提升F1值最高。综合分析得到集成学习在肉制品安全风险分类中的效果较好,其中XGBOOST模型在肉制品安全风险评价分析中的应用效果优于单棵DT和RF,且随着不平衡类别的处理,模型的效果得到显著改善。
3 结论
针对目前食品安全检测数据囤积的情况,本文基于全国范围内肉制品抽检数据提出了一种基于集成学习的肉制品安全风险等级评价的方法,以抽样产品的综合风险等级为目标变量,并采用3种上采样改善不平衡数据,以DT为基础分别构建2个集成学习模型,联合使用one-hot encoding和贝叶斯优化进行指标细化和模型优化,有效的弱化了不平衡数据影响、细化了影响因素、提升了模型效果。实验结果表明6:4重采样结合XGBOOST的集成优化模型在肉制品检测数据中显示出最佳效果。研究表明集成模型比决策树单一模型更适用于肉制品食品安全监测,通过one-hot encoding进一步反应出变量取值对于食品风险的影响程度,为日常监测中的食品抽检重点方向提供参考,同时为今后集成学习在食品安全风险评预警的应用提供了思路。对于未来的研究工作,将从以下两个方面改进:一是对不平衡数据的处理深入讨论。本文随机重采样一定程度缓解了不平衡中的过拟合和欠拟合,但有优化提升的空间,下一步通过研究不平衡数据采样方法的组合进一步改善过拟合和欠拟合。二是特征构造的变量一定程度弥补了数据的不足,但仍有多种复杂的因素需要挖掘。后续研究将针对此类检测数据继续挖掘影响肉制品安全风险的因素以提高分类的效率,深入分析各因素的影响程度。
4 建议
本文以肉制品检测数据的风险等级分类,通过提取的基本信息反应出各环节对于食品安全风险等级的影响。食品安全抽检部门以及相关食品安全管理局可根据各环节的影响程度调整抽检力度和重点关注环节,提高工作效率。食品安全涉及环节多,如运输时长、路程、温度、存储条件等信息难以有效记录,本研究的特征重要性分析结果显示这些信息对食品安全的影响较为重要。肉制品原始数据具有数量大、信息密度低的特点,建立更加完善的信息录入系统提高食品数据的信息质量,不但有利于对食品安全的监管,还为今后在该领域开展深入的研究奠定了数据基础。
