一种利用注意力增强卷积的暗网用户对齐方法
2023-09-07杨燕燕杜彦辉刘洪梦赵佳鹏时金桥王学宾
杨燕燕,杜彦辉,刘洪梦,赵佳鹏,时金桥,王学宾
(1.中国人民公安大学,信息网络安全学院,北京 100038;2.北京邮电大学,网络空间安全学院,北京 100876;3.中国科学院 信息工程研究所,北京 100080)
1 引 言
随着互联网技术飞速发展,网络数据呈现爆发式增长,但网络信息良莠不齐。有害信息传播成为网络空间管控领域的一大难题。对网络文本作者开展身份识别,其中一个前提就是实现网络用户的对齐,对网络文本的特征进行提取,判定多个文本是否为同一作者所做。基于网络文本作者风格分类识别技术的作者身份判定技术,可以协助相关执法机构获取有害信息发布者的身份信息,为计算机取证提供依据,是净化网络空间的有效手段。暗网信息既具有短文本语料特征,又具有其独特的犯罪“黑话”特性,决定了其相对明网数据来说,更加依赖全局信息和长序列信息来判断语料的特征。
为了解决用户身份识别问题中易于识别的特征稀缺问题,文献[1]首先将文本卷积神经网络(Text Convolutional Neural Networks,TextCNN)模型用于用户身份识别,并在短文本语料上显示出了良好的结果。文献[2]在此基础上结合对上下文信息和时间特征的分析,提出了一个在红迪网和推特上建立社交媒体用户代表的模型。文献[3]基于此种模型引入异质图方法对上下文信息进行建模,构造用户嵌入,在用户跨市场识别上取得了较好的结果。然而,卷积运算有一个显著的弱点,即它只作用于一个局部邻域,缺少全局信息[4]。另一方面,自注意力机制可以很好地提取全局信息和长序列信息用以建模。自我注意背后的关键思想是产生一个从隐藏单位计算出的值的加权平均值。暗网论坛中的网络文本包含大量的长文本,已有的研究工作主要采用池化和卷积算子提取文本特征,比较适用于短文本,不适用于对暗网市场长文本的特征提取。增强提取长文本特征的能力是暗网文本特征提取面临的主要挑战。
针对已有的对暗网用户发布文本内容特征进行提取的方法不能有效处理长文本的问题,笔者提出了一种适用于暗网长文本特征提取的方法。通过自注意力机制增强卷积,实现长文本特征的提取。在公开的暗网市场数据集上,达到改进基于暗网用户发布文本内容对齐用户的效果。主要创新点在于提出使用自注意力机制与卷积网络相结合的方式提取用户文本内容的特征,并取得了较好的实验效果,并且验证了完全自注意模型比完全卷积结构差,当卷积和自注意相结合时才会得到最好的结果。实证研究表明,将卷积特征映射与一组通过自注意产生的特征映射连接,可增强卷积算子。大量的实验表明,注意力增强可以有效改进用户对齐的结果。
2 相关工作
暗网上的内容包括专门用于非法毒品交易、成人内容、假冒商品和信息、泄露的数据、欺诈和其他非法服务的资源[5],还包括讨论政治、匿名化和加密货币的论坛。
文献[1]引入了卷积神经网络进行文本嵌入,利用多个不同大小的卷积核来提取句子中的关键信息(类似于多窗口大小的n-gram模型),从而能够更好地分类捕捉局部相关性。在关于用户身份识别的后续工作中,[6-7]利用这些想法来证明卷积神经网络模型优于其他模型,特别是对于短文本语料。对子词标记化的进一步研究[8],特别是字节级标记化,使得多种语言跨数据共享词汇表成为可能。使用子词标记器建立的模型在特定语言[9]和跨多语言社交媒体数据[2]的用户对齐任务上表现良好。自2013年以来,非英语和多语言暗网市场的数量一直在增加[10]。笔者的工作建立在以上想法的基础上,通过使用面对暗网的注意力增强卷积神经网络(Darkweb Attention augmented Convolutional Networks,DACN)模型,对句子中字符和子词级标记进行实验。
自注意力机制[11]是一种最新的捕获全局信息的方式,主要应用于序列建模和生成建模任务。值得注意的是,文献[12]首次提出将注意力与递归神经网络结合起来,用于机器翻译中的对齐。利用自我注意与卷积是最近在自然语言处理和强化学习的工作中常用的一个机制。例如,文献[13-14]的Transformer架构分别在自注意层和卷积层之间交替进行问答应用程序和机器翻译。此外,针对视觉任务提出了多种注意机制,以解决卷积的弱点。例如,文献[15-16]使用从整个特征地图中聚集出来的信号来重新加权特征通道,而瓶颈注意模块(Bottleneck Attention Module,BAM)[17]和卷积注意力机制模块(Convolutional Block Attention Module,CBAM)[18]模型在信道和空间维度上独立地细化卷积特征。在非局部神经网络中[19],通过在卷积结构中使用自注意的一些非局部剩余块,在视频分类和目标检测方面得到了改进。
文献[4]使用自注意力机制替代卷积,引入了一种新的二维相对自注意机制,证明了其在取代卷积作为图像分类的独立计算原语方面具有竞争力,最后证明了当卷积和自注意相结合时,图像分类结果最好。最近的工作利用异构信息网络嵌入的概念来改进图建模,其中不同类型的节点、关系(边)和路径可以通过类型实体来表示[20-23]。文献[24]使用异构信息网络在暗网上建模市场供应商西比尔(sybil)账户,其中代表一个对象的每个节点都与各种特征(如内容、摄影风格、用户简介和物质信息)相关联。类似地,文献[25]提出了一种多视图无监督的方法,该方法结合了文本内容、物质和位置的特征来生成供应商嵌入。文献[26]提出了一种新颖的方法,将时间、内容风格与访问身份结合,以建模和增强用户表示,从而用于识别暗网论坛中的相同用户。文献[3]在此基础上引入异质图方法对上下文信息进行建模,从而增强用户嵌入,并首次应用到暗网上,在暗网用户跨市场对齐上取得了较好的结果。
通过对已有工作的广泛调研,发现文本特征的提取是用户对齐的先决条件,而用户的一些网络行为也在发挥着越来越重要的作用,如发帖时间、用户之间的交互行为等。然而,目前的文本特征提取工作对于文本特征的表示能力不足,尤其是面对大规模训练文本时,以卷积神经网络为代表的特征提取器特征提取的能力受到显著制约,与池化或卷积算子不同,加权平均运算中使用的权值是通过隐藏单元之间的相似性函数动态产生的。输入信号之间的相互作用取决于信号本身,而不像在卷积中由它们的相对位置来预先确定,故自我注意力可以捕捉全局信息。受到近年来自注意力机制对于大规模数据特征提取有效性的启发,笔者提出采用自注意力增强卷积的方式提取用户的文本特征,并通过广泛的实验验证了其对用户对齐方法改进的有效性。
3 基于注意力增强卷积的暗网用户对齐方法
对于暗网用户的对齐,首先需要获取每个用户在一段时间内发布的帖子,然后从用户发布的帖子中提取有效的特征。除此之外,还需获取帖子的文本内容、时间和上下文信息,组合形成用户最终的嵌入式表示。所提方法的建模框架是受到了文献[3]的启发,并且使用注意力增强卷积的方法添加了长文本语料特征,从而增强了模型的表示能力。
本框架分为两个主要的部分:① 将用户在同一时间片段内发布的帖子集合中的每一条帖子的文本、时间和上下文信息分别解析为长、短文本特征、时间戳特征和上下文特征,即向量化过程;② 使用度量学习方法gφ训练f(θ),使同一用户获得相同的向量化表示,具体的建模过程如图1所示。在接下来的节中,将根据各个组件来介绍所提方法。

图1 文中方法的建模过程
3.1 文本嵌入
文本嵌入的功能是从文本输入中提取语义特征,并将语义特征投影到信息空间中。首先,填充句子,以保持所有句子的统一长度,使得文本嵌入输入是固定长度为m的句子s。其次,通过独热编码(one-hot)将每个词映射到dt维连续空间,得到单词嵌入向量k。然后,将所有的词向量连接起来,形成一个m×dt矩阵作为模型输入:X=[X0,X1,…,Xm-1]。最后,应用语义特征提取器在嵌入矩阵上产生潜在的语义特征映射。
3.1.1 短文本特征
利用卷积算子对短文本预料特征进行嵌入,通过一维卷积来获取句子中的n-gram特征表示,利用多个不同大小的卷积核来提取句子中的关键信息(类似于多窗口大小的n-gram模型),从而能够更好地捕捉局部相关性。具体工作机制是:卷积窗口沿着长度为n的文本一个个滑动,类似于n-gram机制对文本切词,然后和文本中的每个词进行相似度计算,后面拼接最大池化层。最后,拼接全连接层,生成短文本语料特征嵌入。
3.1.2 长文本特征
由于Transformer模型直接处理整个句子的信息,因此必须提供每个字的位置信息给Transformer模型,这样它才能识别出语言中的顺序关系。对于输入的句子X,通过文本嵌入得到该句子中每个字的字向量,同时通过位置向量得到所有字的位置向量,将其相加(维度相同,可以直接相加),得到该字最终的向量表示,其计算公式为
MultiHead(Q,K,V)=Concat(Att1,Att2,…,Attn)w0。
(1)
多头注意力机制可以为注意力模块提供多个表示子空间。Atti表示第i个注意力头,w0为词语的初始向量标识,Concat分别表示n个不同的注意力头相拼接。因为在每个注意力模块中,采用不同的Q,K,V权重矩阵,每个矩阵都是随机初始化生成的。然后通过训练,将词嵌入投影到不同的表示子空间中。在上一步得到了经过多头注意力机制加权之后输出,再通过前馈神经网络生成潜在语义特征图。
3.1.3 注意增强卷积
相对于卷积算子受到其局部性和缺乏对全局上下文的理解的限制,所提的方法有如下优点:① 使用一种注意机制,该机制可以共同关注空间和特征子空间(每个头对应一个特征子空间);② 引入额外的特征映射。图2总结了提出的增广卷积,其中Ti表示句子的第i个字符,Ei表示第i个字符对应的向量表示,Hζ表示句子向量经过注意力机制的投影空间,HΦ表示经过卷积和的投影空间,Hξ表示最终的投影空间。连接卷积和注意特征映射:形式上,考虑一个通道数量为mc,级联分类器数量为nc的卷积算子,和一个通道数量为mt,级联分类器数量为nt的注意力特征映射。相应的注意增强卷积计算公式为
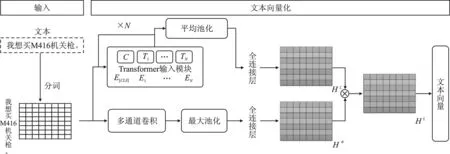
图2 文本嵌入模型图
AAConv(X)=Concat[Conv(X),MultiHead(X)] ,
(2)
其中,Conv(·)和MultiHead(·)分别为上文介绍的卷积函数和多头注意力函数,AAConv(·)为所提注意力增强的卷积神经网络。这样的结构可以直接产生额外的特征图,而不是通过加法、乘法或门控重新校准卷积特征。这一特性允许灵活地调整注意力通道的比例,考虑从完全卷积到完全注意模型的一系列架构。
3.2 时间嵌入
每个帖子的时间信息对应于帖子创建的时间,文中用每篇文章的日期数作为时间特征,它是一个维数为dτ的嵌入向量标识,dτ的纬度与词汇矩阵EW中每个词汇的维度相同。
3.3 上下文嵌入
文献[26]使用了子论坛作为红迪网文章的背景。借鉴此方式,将一篇文章的子论坛编码为一个独热向量,并使用它来生成一个上下文嵌入。在前面提到的工作中,这个嵌入是随机初始化的。文献[3]改变了这种设置,使用一种基于论坛帖子构建的异构图的替代方法来初始化这种嵌入。
定义1(异构图) 异构图G=(V,E,T),是每个节点v和边e与边的类别TI∈T关联,其中,关联是由映射函数φ(v):V→TV,ψ(e):E→TE给出的;其中,|TV|+|TE|>2。
构建一个图,其中有4种类型的节点:用户(U)、子论坛(S)、线程(T)和帖子(P),每条边都表示新线程的帖子(U-T)、回复现有的帖子(U-P)(评论)或包含(T-P、S-T)关系。为了学习这种异构图中的节点嵌入,利用了metapath2vec框架为暗网论坛设计的特定元路径方案。metapath2vec通过最大化异构邻域的概率来生成维度为dc的嵌入。每个元路径方案都可以将特定的语义关系合并到节点嵌入中。
因此,为了完全捕获异构图中的语义关系,使用了7种元路径方案:UPTSTPU、UTSTPU、UPTSTU、UTSTU、UPTPU、UPTU和UTPU。学习到的嵌入将保留每个子论坛、所包括的帖子以及相关用户之间的语义关系。
3.4 用户发布帖子片段集合
一个用户的多个帖子中每个组件的嵌入被连接到一个de=dt+dτ+dc维嵌入中。因此,有L个帖子的集合有L×de维的嵌入。文中为每个集合生成一个最终的嵌入。对于Transformer模型,集合嵌入作为Transformer模型的输入[11,27],每个嵌入作为总序列中的一个元素。在平均池化中,集合嵌入是后置嵌入的平均值,导致了一个维化的集合嵌入,得到一个de维的嵌入表示。在这个池化架构中不使用位置嵌入,如图3所示。

图3 用户建模模型图
3.5 基于度量学习的用户对齐方法
在基于用户发帖内容得到了用户的向量表示之后,采用对分类的方法对齐用户,主要是基于用户的表示向量计算用户表示向量的相似度。为了训练嵌入的f(θ),文中将其组成为一个鉴别分类器gφ:RD→RY,参数φ通过训练预测一个集合的用户,其中Y是训练集中的用户数量。
分类损失函数Softmax(SM):定义了参数φ=W,W∈RY×D为一个可学习的权重矩阵,并定义参数为φ=W的映射gφ(z)=softmax(W*z)。当使用这个损失函数时,可以使用欧几里得距离比较嵌入。
4 实验分析
4.1 数据集
文中使用了两个暗网市场的数据集——丝绸之路(SR)和广场市场(Agora)。数据来源主要是基于文献[3]构造的数据集,该数据集通过基于规则和人工分析的结果标注数据。文中将数据集分成大小相等的训练集和测试集,并按时间顺序在中间进行分割。除此之外,测试数据中包含了训练集中没有的用户。
4.2 对比模型
为了验证每个建模贡献的优点,将其与下面描述的3个对比模型进行了比较。经过查阅文献可知,笔者较早开展了注意力增强卷积对齐用户的工作,将已有工作分为文本嵌入模型和用户表示模型两类,在公开数据集上,通过实证实验对比突出所提方法的优势,验证了所提方法的有效性。
4.2.1 文本嵌入模型
(1) TextCNN(2014)模型[1]:一个基于短文本预料特征的用户多账号关联模型。该模型使用文本卷积神经网络对每个文本进行嵌入,不支持其他属性(时间、上下文),同时只考虑每次发表1个文本。

表1 预处理后的数据的统计数据 个
(2) Transformer(2017)模型[11]:一个基于长序列信息的用户多账号关联模型。该模型使用Transformer对每个文本进行嵌入,不支持其他属性(时间、上下文),同时只考虑每次发表1个文本。
4.2.2 用户表示模型
(1) IUR(2019)模型[2]:该模型不考虑基于图的上下文信息。
(2) SYSML-CNN(2021)模型[3]:该模型使用文本卷积神经网络对每个文本进行嵌入,同时考虑到时间和上下文信息,构建用户嵌入,进行用户多账号关联。
(3) SYSML-Transformer(2021)模型[3]:该模型使用Transformer对每个文本进行嵌入,同时考虑到时间和上下文信息,构建用户嵌入,进行用户多账号关联。
4.3 评价方法和参数设置
虽然无法获得拥有多个账户的单个用户的真实标签,但单个模型仍然可以通过衡量它们在用户对齐上的表现来进行比较。对每种方法生成的嵌入都使用基于检索的度量标准进行评估。将所有事件嵌入的集合表示为E={e1,e2,…,en},并让Q={q1,q2,…,qK}∈E为采样子集。计算了查询事件嵌入与所有事件的余弦相似度。让Ri={ri1,ri2,…,rin}表示E中的事件列表,按它们与事件qi的余弦相似性(不包括事件本身)排序。使用了以下度量方式。
平均倒数排名(Mean Reaprocal Rank,MRR)是一个国际上通用的对搜索算法进行评价的机制,即第1个结果匹配,分数为1,第2个匹配分数为0.5,……,第n个匹配分数为1/n,如果没有匹配的句子分数为0。最终的分数为所有得分之和,其计算公式为
(3)
其中,k表示用户个数,A(rij)表示根据用户发帖结果计算的排名值。Recall@k表示同一用户的发布帖子内容是否发生在子集内,MRR(Q)表示所有查询样本中这些召回值的平均值。
4.4 实验结果
理论上自注意力机制在取代卷积作为独立计算单元方面是有竞争力的,但是在消融实验中发现,将自注意力和卷积组合起来的情况可以获得最好的结果。因此,笔者并没有完全抛弃卷积,而是提出使用自注意力机制来增强卷积,即将强调局部性的卷积特征图和基于自注意力机制产生的能够建模更长距离依赖的特征图拼接来获得最终结果。评估结果见表2。
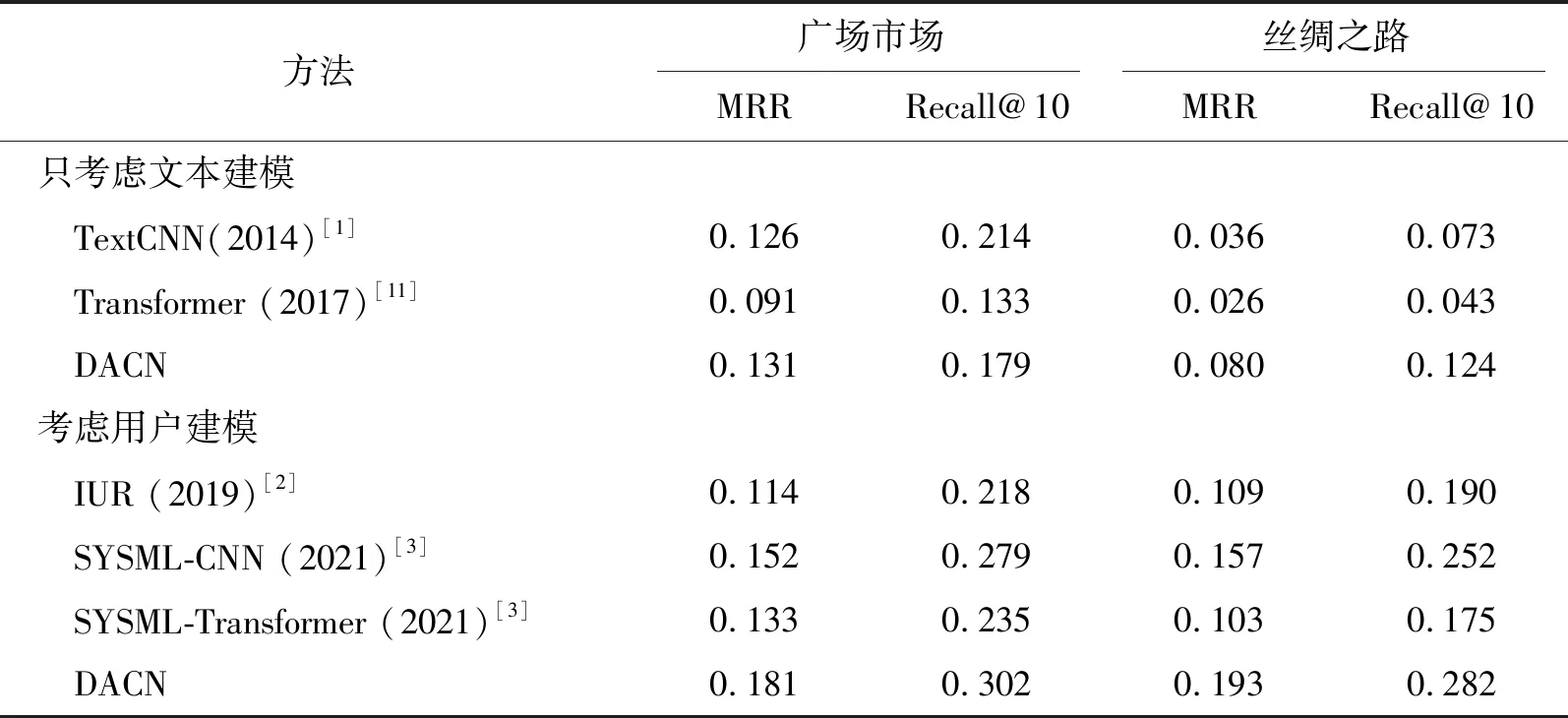
表2 DACN两个数据集的评估结果
MRR为平均倒数排名指标,Recall@10表示计算前10名的召回率。由表2可以看出,在只考虑文本建模的模型中,DACN模型比TextCNN模型的MRR值平均高约2.45%,Recall@10值平均高约0.16%;DACN模型比Transformer模型的MRR值平均高约4.70%,Recall@10值平均高约6.35%;在用户模型中,DACN模型比IUR模型的MRR值平均高约7.55%,Recall@10值平均高约8.80%; DACN模型比SYSML-CNN模型的MRR值平均高约3.25%,Recall@10值平均高约2.65%;DACN模型比SYSML-Transformer模型的MRR值平均高约6.90%,Recall@10值平均高约8.70%。我们发现,注意力增强卷积都实现了一致的提升。另外,完全的自注意模型(不用卷积那部分),可以看作是注意力增强模型的一种特殊情况,但结果比完全卷积结构略差。
在对两个数据集的结果观察后发现,在Recall@10中用户正确匹配的位置数量对比中,前10个用户正确匹配的位置,无论在哪个位置,所提模型的匹配数量均比SYSML-CNN 和SYSML-Transformer模型多,说明所提模型优于SYSML-CNN 和SYSML-Transformer模型,具体如图4和图5所示。
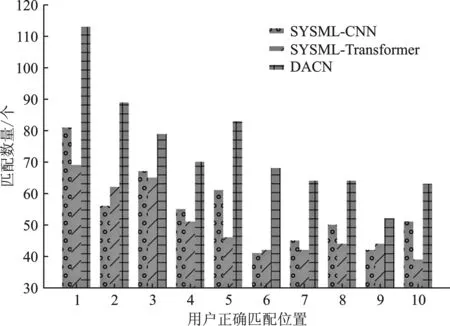
图4 广场市场数据集用户正确匹配个数对比图
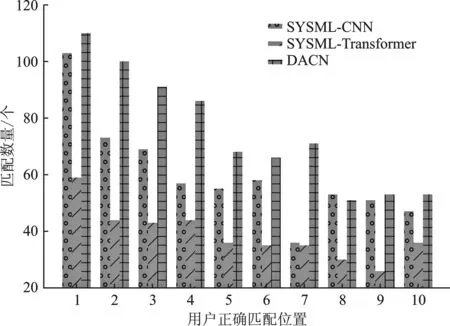
图5 丝绸之路数据集用户正确匹配个数对比图
5 结束语
暗网因其匿名性吸引了大量犯罪分子从事违法犯罪活动,同时也给执法人员带来了极大困难。近年来深度神经网络在各个领域取得广泛成功,越来越多的研究者开始利用神经网络对匿名的网络文本作者进行身份识别。针对已有的方法主要面向短文本、不擅长处理全局和长序列信息的问题,提出了一种自注意机制来增强卷积算子,利用长序列信息来建模暗网用户发表的网络文本的方法,从文本内容入手,对匿名的暗网用户进行多账号关联,达到聚合多个匿名账号信息的目的,为获取用户的真实身份提供更多线索。在公开数据的实验中,结果表明,所提方法优于已有工作,验证了所提方法的有效性;同时,在探索不同的注意机制如何权衡计算效率和表征能力的消融实验中,发现注意力机制很大程度上增强了卷积算子提取用户特征的性能。
