基于隐写噪声深度提取的JPEG图像隐写分析
2023-09-07范文同李震宇罗向阳
范文同,李震宇,张 涛,罗向阳
(1.中国人民解放军战略支援部队信息工程大学 网络空间安全学院,河南 郑州 450001;2.数学工程与先进计算国家重点实验室,河南 郑州 450001;3.河南省网络空间态势感知重点实验室,河南 郑州 450001;4.常熟理工学院 计算机科学与工程学院,江苏 常熟 215500)
1 引 言
隐写术通过将秘密信息嵌入到载体中,从而在不引起第三方怀疑的情况下进行隐蔽通信[1]。由于隐蔽通信的过程很难被他人发现,一些犯罪人员和恐怖分子会利用它来危害社会稳定和国家安全。作为隐写术的对立技术,隐写分析旨在检测隐蔽通信的存在,并在与隐写术的对抗过程中不断发展。
随着互联网通信技术和图像处理技术的发展,在互联网中广泛传播的JPEG图像成为了隐写术的合适载体。因此,针对JPEG图像的隐写分析[2]也逐渐成为学术界的重要研究课题。JPEG图像隐写分析的目标是检测一张看似正常的JPEG图像中是否隐藏了秘密信息,判断所使用的隐写方法,估计秘密信息的嵌入位置,提取秘密信息[3]。其中,判断图像是否含有秘密信息是最重要的部分,这也是当前研究的重点[4]。含有秘密信息的图像称为载秘图像,其他的称为载体图像。
现有的隐写分析方法可以分为基于人工特征设计的传统隐写分析方法和基于深度学习的隐写分析方法。对于传统隐写分析方法,研究者们首先利用人工设计的高维特征提取方法来捕获图像中由秘密信息嵌入引起的统计异常,然后使用经过训练的分类器来确定图像中是否包含秘密信息。代表性的方法有空域富模型方法(Spatial Rich Model,SRM)[5]、离散余弦变换残差方法(Discrete Cosine Transform Residual,DCTR)[6]、相位感知投影模型(PHase Aware pRojection Model,PHARM)[7]和Gabor滤波器残差方法(Gabor Filter Residual,GFR)[8]。然而随着当前隐写技术[9-10]的发展,有效的高维特征提取方法越来越难以设计,设计出的特征提取方法也会受限于研究者的领域知识和启发式探索,这限制了隐写分析的发展。
随着深度学习的兴起,研究人员发现,神经网络可以学习图像的多层次特征,这样既可以减少启发式的特征设计,也能更好地反映图像的本质特征[11]。因此,研究者们开始将深度学习应用于隐写分析之中,并取得了大量成果。在各种深度网络中,卷积神经网络(Convolutional Neural Networks,CNN)[12]因为其独有的特性受到了研究者们的重视。卷积操作可以捕获图像中由秘密信息嵌入引起的细微变化,这种细微变化也被称为隐写噪声,这在功能上与传统隐写分析方法中的特征提取步骤类似。池化层和激活函数层也可以用来模拟传统隐写分析方法中的量化和截断步骤。因此,基于卷积神经网络模型的隐写分析方法[13]已成为图像隐写分析的主流。
根据针对隐写算法类型的不同,基于深度学习的隐写分析方法可以分为空域隐写分析方法和JPEG域隐写分析方法。现有的基于深度学习的隐写分析方法大多是针对空域隐写算法所设计的。TAN等[14]将深度学习应用于隐写分析之中,提出了名为TanNet的隐写分析网络。该网络只有4层,包括3个卷积层和1个全连接层。QIAN等[15]将传统卷积网络的预处理层替换为固定的高通滤波核来增强隐写信号,提出了一种基于深度学习的隐写分析模型QianNet。为了避免隐写特征的损失,在QianNet中使用了平均池化层来代替最大池化层。为了进一步提高隐写分析的性能,XU等[16]沿用了QianNet网络架构的特点,提出了XuNet。考虑到预处理层提取的噪声残差与符号无关,XuNet在第1个卷积层之前使用abs层来收敛特征图,其检测性能与SRM相当,甚至在某些情况下有所超越。YE等[17]将SRM的特征提取部分与深度学习相结合,提出了YeNet,其检测精度已经超过基于人工特征设计的传统隐写分析方法。ZHANG等[18]针对卷积核以及网络结构进行改进,提出了ZhuNet。该网络使用可分离卷积代替原有的卷积层来提高隐写信号和图像信号之间的信噪比。此外,还采用了空间金字塔结构来丰富特征的表达,检测效果有了相当大的提升。由于随意调整图像的大小会严重影响图像中的隐写信号[19],YOU 等[20]以孪生网络为基础,设计了一种新的隐写分析网络SiaStegNet,来实现在不重新训练参数的情况下对多尺度的图像进行隐写分析,在多尺度图像上的检测效果十分优秀。
虽然目前在互联网上传播的图像大多是JPEG图像,但相比于空域隐写分析方法,针对JPEG图像的隐写方法要少得多。ZENG等[21]提出了一个基于深度学习的JPEG域隐写分析网络,其检测效果与传统方法基本持平。后来,ZENG等[22]在之前工作的基础上,通过将JPEG图像转换为空域图像再进行隐写检测的方式,有效地提高了隐写分析的准确率。此外,在XuNet的基础上,XU[23]提出了一种名为J-XuNet的JPEG域隐写分析方法。该方法采用了20层全卷积网络来进行隐写分析,通过残差连接来防止梯度爆炸以及隐写特征的消失,其检测效果已经优于传统方法。考虑到之前的隐写分析方法仍然包含了一些手工设计的元素,BOROUMAND等[24]设计了一种基于残差网络的端到端隐写分析模型,名为SRNet。该网络在空域和JPEG域上都有非常出色的表现。2021年,SU等[25]提出了一种基于全卷积网络的端到端隐写分析模型,称为EWNet。该模型可以在不重复训练的情况下,针对任意大小的JPEG图像进行隐写分析,在JPEG图像隐写分析方面取得了最先进的检测效果。考虑到当前基于深度学习的隐写分析方法通常无法获得选择通道感知(Selection-Channel Aware,SCA)的知识,LIU等[26]将与SCA作用相同的剩余通道空间注意(Channel-Spatial Attention,CSA)模块引入到卷积网络中,来进一步提高模型的隐写分析性能。此外,为了获取多尺度的层次特征表示,文中使用空间金字塔池化来代替全局平均池化。该网络在JPEG隐写分析领域检测效果要优于SRNet。
当前,大多数基于深度学习的隐写分析方法会先提取图像中包含的隐写噪声,再对提取的隐写噪声进行分类。隐写噪声提取的准确度在很大程度上决定了隐写分析的性能。目前大多数方法通过将这两个阶段连接在一起,利用分类模块的误差优化隐写噪声提取模块,以此提高隐写噪声提取的准确度。然而,随着图像质量因子的提高,隐写噪声与图像内容的信号比例会急剧下降,隐写噪声也变得更加难以提取。基于端到端的隐写分析模型,在训练过程中没有为隐写噪声提取模块设定优化目标。当图像的质量因子较高时,这种训练方式可能会限制隐写噪声的提取准确度。为了解决这个问题,文中提出了一种基于有监督训练策略的隐写噪声深度提取模型,以此提高隐写分析的准确率。文中工作的主要贡献如下:
(1) 提出了一种基于隐写噪声深度提取的JPEG图像隐写分析方法。该方法可以减少图像内容对隐写分析的影响,准确地提取出隐写噪声,并判断该图像是否为载秘图像。
(2) 提出了一种指导隐写噪声深度提取网络的模型评价指标来选择最佳网络,并将其与针对隐写噪声所设计的分类网络相融合,得到完整的隐写分析网络。
(3) 在基准数据集上的实验结果表明,针对J-UNIWARD和UED-JC这两种隐写算法,文中方法要优于经典的基于深度学习的隐写分析方法。
2 基于噪声深度提取的JPEG隐写分析方法
与经典计算机视觉领域中的物体识别和图像分类等任务不同,隐写分析主要关注细微的隐写噪声而不是一般的图像内容。当图像的质量因子较高时,隐写噪声与图像内容的信号比例会急剧下降,隐写噪声很难被准确地提取出来。然而,基于深度学习的端到端隐写分析方法并没有为隐写噪声提取模块设置独立的优化目标,这可能会限制隐写噪声提取的准确度。为了克服这一局限性,文中为隐写噪声提取模块设置单独的优化目标来准确提取隐写噪声。
2.1 网络结构
文中所提出的隐写分析网络名为SNdesNet。该网络主要由两个部分组成,即隐写噪声深度提取网络(SneNet)和分类网络,如图1所示。
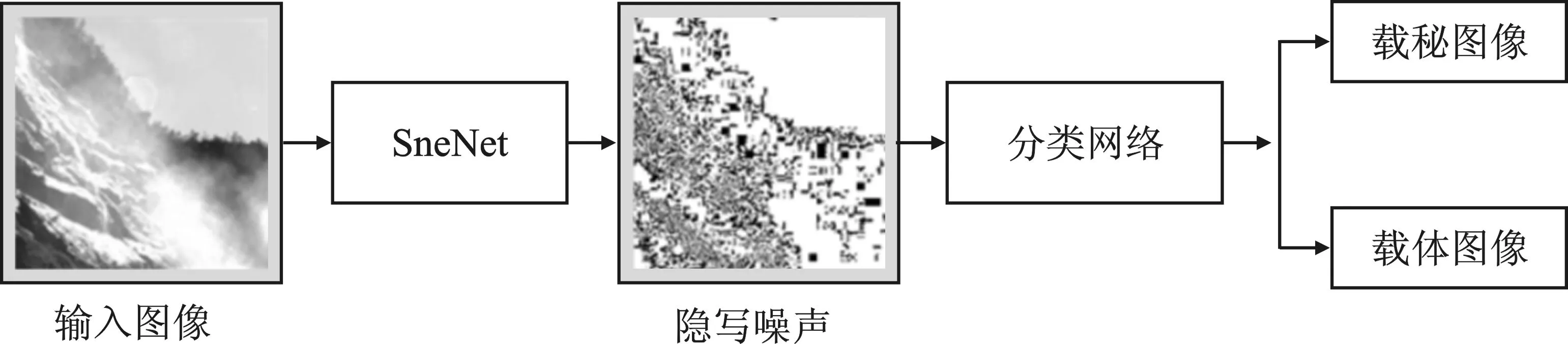
图1 SNdesNet检测流程
首先,使用SneNet从待检测图像中提取可能存在的隐写噪声;然后,将隐写噪声输入到分类网络,以确定输入是载秘图像还是载体图像。由于隐写噪声提取模块的优化过程是回归任务,其目标函数与分类模块不同,所以无法将两个网络连接在一起进行同步优化。出于这个原因,文中使用分段式的网络结构来分别对这两段网络进行优化。显然,文中方法的关键是隐写噪声深度提取网络和分类网络的构建。具体的网络结构将在后文中分别进行介绍。
2.2 隐写噪声深度提取网络
SneNet的目标是从输入图像中提取可能存在的隐写噪声。隐写噪声指的是载秘图像和载体图像之间的像素差:
Ri,j=Si,j-Ci,j,
(1)
其中,Si,j表示载秘图像(i,j)位置的像素;Ci,j表示载体图像对应位置的像素;两幅图像对应点像素之间的差值Ri,j就是图像中所含有的隐写噪声。
在输入的过程中首先将JPEG图像解压缩到空域,使用JPEG图像的像素矩阵作为网络的输入。这样网络的训练过程更容易收敛,也便于计算图像中所包含的隐写噪声。需要注意的是,隐写分析人员无法获得载秘图像的原始载体图像。因此,隐写噪声的提取问题可以转化为载体图像的预测问题,而这与图像去噪任务非常相似。不同的是,相比于图像的自然噪声,隐写噪声要细微得多,但仍可以从图像去噪领域中寻找灵感。文中提出的SneNet受到了图像去噪网络RIDNet[27]的启发,在其基础上进行了一定的修改,以达到隐写噪声提取的目的。对于修改的合理性将会在实验部分进行说明。
2.2.1 SneNet的网络结构
SneNet的网络结构如图2所示,其骨干部分主要由两部分组成,分别是高维特征提取模块和隐写噪声学习模块。
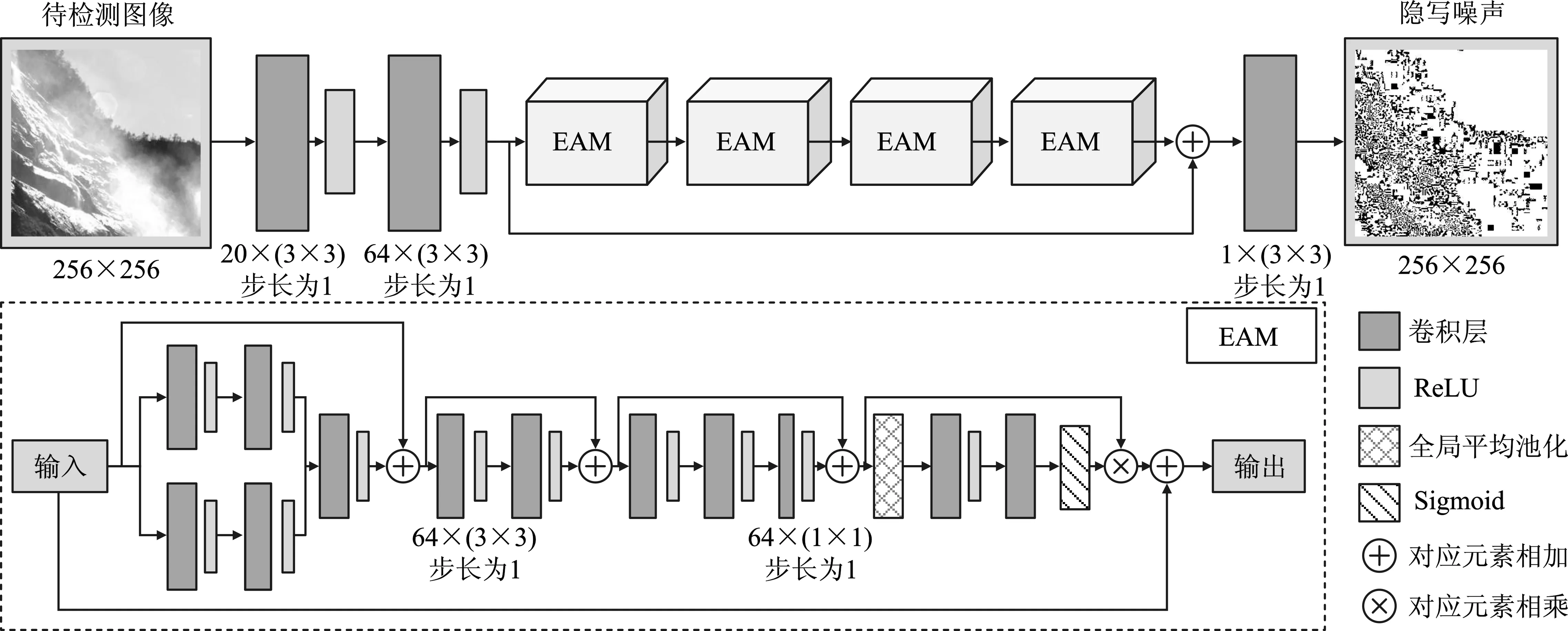
图2 隐写噪声深度提取网络(SneNet)的网络结构
高维特征提取模块由两个卷积层组成,在图像去噪网络的最前端添加了一个预处理层,以提取高维特征f0。与图像中的自然噪声相比,隐写噪声要小得多,所以直接使用去噪网络来提取隐写噪声会使网络难以收敛。为了加速网络的收敛,使用固定的滤波核来初始化卷积核,该步骤可以表示为
f0=Convp(x) ,
(2)
其中,Convp(·)表示在载秘图像上的预处理卷积操作。之后提取出的高维特征f0被输入到隐写噪声学习模块,通过有监督的训练策略来提取高维特征中的隐写噪声n,即
n=Mns(f0) ,
(3)
其中,Mns(·)为隐写噪声的学习过程,主要由图2中4个逐级连接的增强注意力模块(Enhancement Attention Module,EAM)组成。最后一个EAM模块输出的特征会再经过一层卷积来降低特征的维度,生成待检测图像中的隐写噪声n。
从图2的下半部分可以看出,EAM的输入特征首先经过一个并行的卷积层来扩大特征图的接收域,再将并行卷积层的输出结果合并来增加特征图的通道;接着,使用两个连续的卷积层来学习隐写噪声相关的特征,并通过增强残差块对特征进行压缩和展平;最后,使用通道注意力机制关注高维特征中的隐写噪声相关特征。
SneNet中使用的残差连接[28]可以有效地减少隐写噪声在网络传播过程中的损失。通过将网络的浅层和深层直接相连,网络可以避免退化,融合不同尺度的特征也能用来辅助网络对隐写噪声的学习。此外,使用隐写噪声而不是载体图像作为网络输出,与从载秘图像到载体图像的转换相比,从载秘图像到隐写噪声的转换更容易学习。载秘图像和隐写噪声之间的明显区别能够帮助网络收敛。
需要注意的是,在SneNet中没有使用批归化处理(Batch Normalization,BN)层来对特征图进行归一化。当前的隐写网络常用BN层来加速网络的收敛,防止模型过拟合。然而,使用BN层对图像进行归一化会破坏图像的对比度信息,这一点在图像去噪任务中得到了研究,因此不在SneNet中使用BN层。
2.2.2 SneNet的训练过程
在网络的训练过程中,使用L1 损失来计算网络的损失,计算公式为
(4)
其中,yi为真实噪声,f(xi)为网络的提取噪声,N是同一批次输入的图像数量。图像去噪网络常用L2 损失作为网络的损失函数,但它对孤立点更为敏感,而L1损失则更为稳定。此外,实验结果表明,使用L1 损失作为损失函数的SneNet性能要比使用L2 损失高约2%,因此选择L1 损失作为损失函数。
此外,使用峰值信噪比(Peak Signal to Noise Ration,PSNR)[29]作为衡量标准来评估隐写噪声提取的准确度。该值可用于评估图像经过重建后的图像质量,PSNR值越高,说明重建后的图像质量越好。因此选择这个指标来评估SneNet的隐写噪声提取能力。去噪后的图像与原始图像之间的PSNR值越高,提取的隐写噪声就越准确,PSNR定义为PPSNR,即
PPSNR=20 lg(MAX)-10 lg(MSE) ,
(5)
(6)
其中,I是原始图像;K是去噪后的图像;l和w分别是图像的长和宽;MAX是图像中可能存在的最大像素值。实验中使用的图像为8位像素,因此MAX为255;MSE是I和K之间的均方误差。
此外,实验结果还表明,由PSNR值最低的网络提取的隐写噪声并不具有最佳的分类性能。事实上,从载秘图像和载体图像中分别提取的隐写噪声之间有较大的差异也很重要。为此,设计了一个模型评价指标P来评估SneNet的隐写噪声提取性能,指导模型的选择。P的计算公式为
P=psc(pcc-pss) ,
(7)
其中,psc为去噪后的载秘图像和载体图像之间的PSNR值,pcc是去噪后的载体图像和载体图像之间的PSNR值,pss是去噪后的载秘图像和载秘图像之间的PSNR值。psc越高,从载秘图像中提取的隐写噪声与真实隐写噪声越相似。而pss和pcc之间的差值越大,从载秘图像和载体图像中提取出的隐写噪声之间的差异就越大。评价指标P同时考虑了隐写噪声的准确提取以及载秘图像和载体图像提取噪声的差异。因此,P值越高,提取的隐写噪声越利于分类网络进行检测。
为了扩大从载秘图像和载体图像中提取噪声的差异,可为载秘图像和载体图像设定不同的优化目标。将隐写噪声用作载秘图像训练的监督,同时由于载体图像中不包含隐写噪声,因此使用零值作为伪噪声来优化载秘图像的训练。使用载秘图像和隐写噪声作为正样本,载体图像和伪噪声作为负样本,来共同构建训练数据集。
2.3 分类网络
隐写噪声分类网络的目标是对SneNet所提取的隐写噪声n进行分类,判断输入图像是否属于载秘图像。考虑到提取的隐写噪声可以看作是一种特殊的图像,基于现有的图像分类网络Swin Transformer[30]的骨干构建分类网络,该网络的输出即为文中隐写分析方法的检测结果。分类网络的具体结构如图3所示。
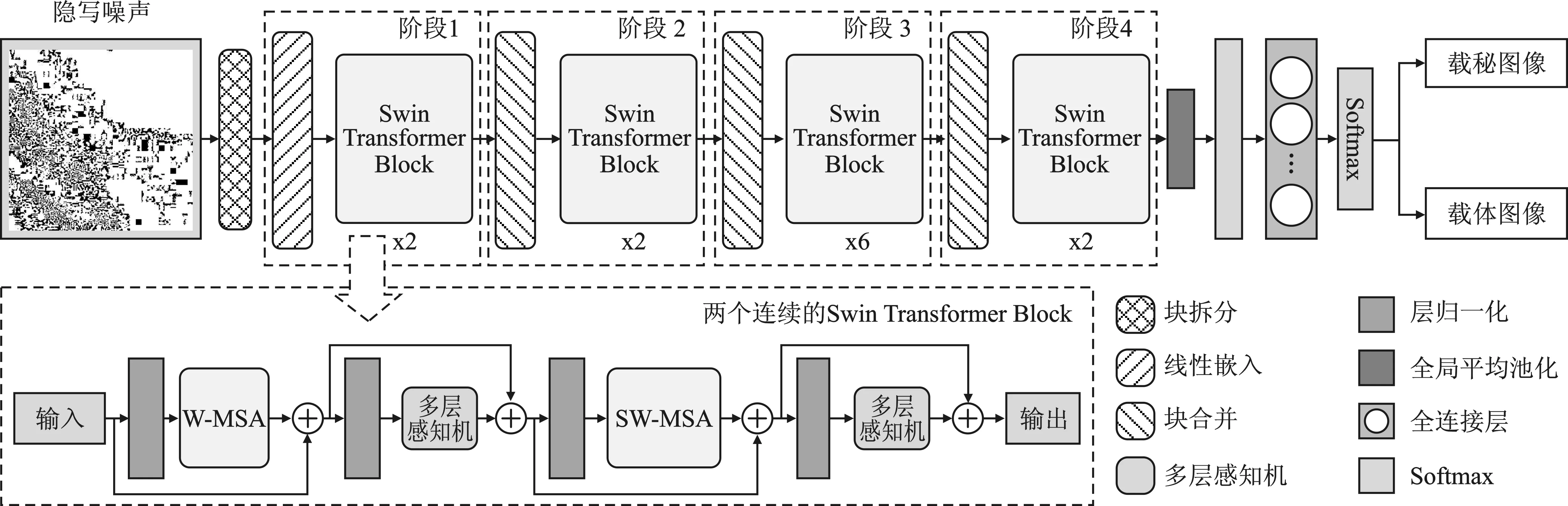
图3 分类网络结构
从输入图像中提取的隐写噪声首先被Patch partition模块分割成多个非重叠等尺寸的Patch,再通过全连接层进行嵌入,扩充Patch中特征的维度;然后,嵌入后的Patch被送入4个连续的Swin Transformer Block中,以获得输入图像的层次化特征图;最后,提取的特征图依次通过LayerNorm层、平均池化层和全连接层,得到输入图像的分类结果。两个连续的Swin Transformer Block中的主要模块是窗口多头自注意力模块(Window Multi-headed Self-Attention,W-MSA)和滑动窗口多头自注意力模块(Shifted Window Multi-headed Self-Attention,SW-MSA)。W-MSA模块基于局部窗口计算注意力矩阵,减少了计算工作量。同时为了获得特征图的全局注意矩阵,在W-MSA模块之后,使用SW-MSA模块来进行窗口之间的信息交互。
从图1中可以看出,隐写噪声在空间上的分布是不连续的,这说明隐写噪声的局部特征不能准确地代表隐写噪声的特性。因此,分类网络需要对隐写噪声的全局特征给予足够的重视。众所周知,Swin Transformer中使用的自注意模块扩大了网络的感受野,能够捕获输入图像的全局特征。此外,网络中使用的滑动窗口策略也可以解决自注意模块的高计算复杂性问题。因此,文中基于Swin Transformer的骨干网络构建隐写噪声的分类网络。
3 实验设置
为了评估所提方法的隐写分析性能,使用两种自适应JPEG隐写算法在不同图像质量因子和嵌入率下进行了一系列的对比实验。网络的性能是通过在测试数据集上的检测错误率来评估的,该错误率的计算方法为假阳性率和假阴性率的均值。接下来将对实验设置、数据集生成和各种实现细节进行具体说明。
3.1 数据集与对比方法
文中实验的数据集采用了来自BOSSBase-v1.01[31]和BOWS2[32]中的20 000张灰度图像。这两个数据集各包含了10 000张大小为512×512的灰度图像。在数据集生成的过程中,首先将大小为512×512的原始图像裁剪成4张互不重叠的256×256的图像,然后随机选择这4张图像中的1张进行实验。使用这种方法生成实验数据集可以减少网络训练的成本,并保持原有的图像质量。接着,将所有挑选出的图像压缩为质量因子为75和85的JPEG图像,使用这些压缩图像构建载体图像数据集。
为了验证文中方法在JPEG图像上的隐写分析性能,使用了两种经典的自适应JPEG隐写方法:J-UNIWARD[33]和UED-JC[34],对载体图像进行嵌入,分别生成嵌入率为0.1、0.2、0.3、0.4和0.5 bpnzac的载秘图像。对于每种质量因子、隐写算法和嵌入率,随机选择BOSSBase数据集中的4 000张图像和整个BOWS 2数据集用于网络训练,再从BOSSBase数据集中剩余的6 000张图像中随机选出5 000张图像用于检测,最后的1 000张图像用于验证。将选出的载体图像和对应的载秘图像一起共同构建实验的训练集、测试集和验证集。这种数据集的划分方式与SRNet[24]和EWNet[25]的划分相同。
在图像的读取过程中,所有的图像首先被解压缩到了空域,使用JPEG图像的像素矩阵作为网络的输入。为了增强模型的拟合能力,也采用了随机镜像和旋转的方式对数据集进行数据增强[35]。
为了对比评估文中方法的隐写分析性能,进行了一系列的实验。采用的对比方法是针对JPEG图像的隐写分析方法,分别是:
(1) J-XuNet[23]:一个20层的全卷积深度网络,采用残差连接来减少特征的损失。
(2) SRNet[24]:一个48层的端到端隐写分析网络。该网络去除了以往深度学习隐写分析模型中的手工设计元素,使用神经网络的强大学习能力来自主学习合适的参数。
(3) EWNet[25]:一个全卷积深度网络,采用反卷积层来对特征图进行上采样,以此丰富用于分类的特征。该方法可以在不重新训练参数的情况下对任意大小的JPEG图像进行隐写分析。
(4) CSANet[26]:一个端到端的隐写分析网络,使用CSA模块来为网络引入选择通道感知的相关知识,此外还通过空间金字塔池化结构来获取不同尺度的层次特征表示。
3.2 实现细节
文中方法包括两个组成部分:隐写噪声深度提取网络和分类网络。因为两个子网的网络结构和优化目标并不相同,所以为其设置了不同的训练参数。
对于隐写噪声深度提取网络,网络中所有卷积层参数采用均值为0,标准差为0.01的高斯分布进行随机初始化。采用Adam算法优化损失函数,模型初始学习率设置为1×10-3,采用余弦退火策略对学习率进行动态调整,最小学习率设置为1×10-5,对于每一次迭代,mini-batch设置为16,即8个载体-载秘图像对。网络经过训练直至收敛(约150个epoch),选择在测试集上P值最高的网络来进行隐写噪声的提取。
对于隐写噪声分类网络,采用Swin Transformer网络的预训练参数对分类网络进行初始化,优化算法采用Adadelta优化器,模型初始学习率为1×10-3,同样采用余弦退火策略来动态调整学习率,最小学习率为1×10-4,每一次迭代的mini-batch设置为24,即12个载体-载秘图像对。使用验证集上性能最好的网络在测试集上进行测试。
实验采用的显卡均为TITAN XP(12 GB),内存为64 GB,搭建的深度学习环境为Tensorflow 1.12.0和Pytorch 1.7。J-XuNet、EWNet和CSANet 3种模型所用的代码为对应论文中给出的源码,SRNet则是在Pytorch环境中自主复现。4种网络的参数设置都与对应论文中的参数保持一致。需要注意的是,复现的SRNet并没有达到文献[24]中的检测精度,这主要是因为数据集的预处理方式不同。文献[24]将原始数据集中的512×512大小的图像直接压缩为256×256的JPEG图像,这会导致图像内容更加平滑,所以隐写痕迹更容易被检测。而实验中则是先将原始图像首先被裁剪成256×256的图像,再压缩成具有不同质量因子的JPEG图像,这种处理方式生成的图像更难被检测。
此外,在训练的过程中还采用了课程学习的训练策略来帮助网络更好的收敛。具体来说,对于每种隐写方法,分别在不同质量因子和嵌入率下进行课程学习。对于质量因子,采用质量因子为75条件下训练得到的网络参数对质量因子85条件下训练的网络进行初始化;对于嵌入率,按照0.5-0.4-0.3-0.2-0.1(bpnzac)的顺序进行渐进式学习,使用前一个嵌入率下训练得到的网络参数对后一个将要训练的网络进行初始化。
4 实验结果与分析
4.1 参数合理性分析
为了确定SneNet的损失函数和学习率等参数,还进行了以下实验分析。采用的隐写算法为UED-JC,图像质量因子为75,嵌入率为0.5。
对于损失函数,使用L1损失,L2损失和Charbonnier损失来进行对比实验。L1损失用于最小化预测图像和目标图像之间的像素差值的绝对值之和,L2损失可以获得更好的PSNR值,而Charbonnier损失能够帮助网络更好的收敛。实验结果如表1所示。

表1 使用L1损失、L2损失和Charbonnier损失作为损失函数的PSNR值与准确率
实验结果表明,虽然L2损失具有最好的PSNR值,但是pcc和pss之间的差异是最低的,仅为2.59,比L1损失要低0.99。与L1损失相比,Charbonnier损失虽然能够帮助网络更快的收敛,但P值和准确度都要低于L1损失。因此,选择L1损失作为网络的损失函数是合理的。
为了确保网络能够正常地提取隐写噪声,需要单独设置载体图像训练的学习率,采用二分法来确定最合适学习率。具体来说,选择了1×10-3,5×10-4,2.5×10-4,1×10-4,1×10-5来作为实验的初始学习率。实验结果如表2所示。
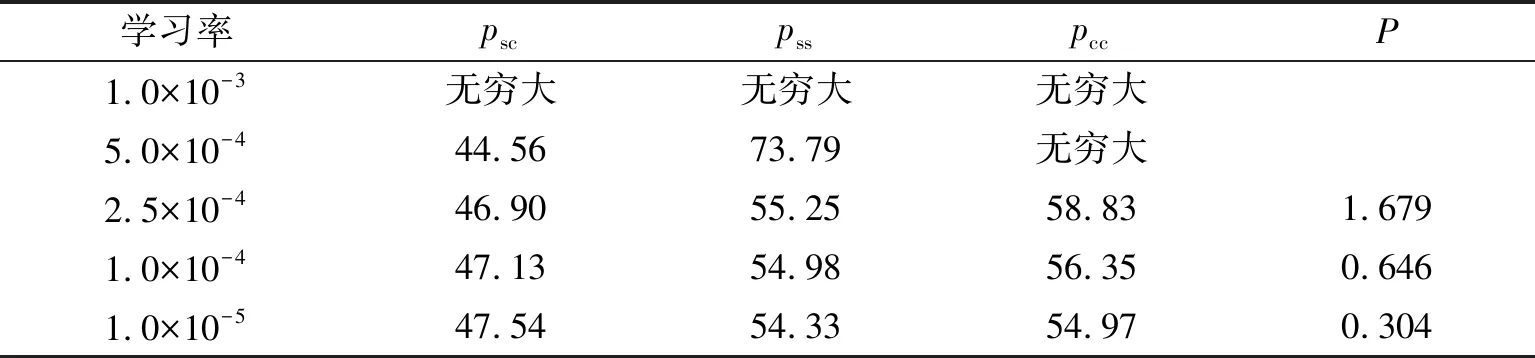
表2 不同初始学习率的PSNR值与准确率
实验结果表明,当学习率为2.5×10-4时,网络对隐写噪声的提取效果最好。当载体图像的学习率接近载秘图像的学习率时,伪噪声会对网络的训练产生很大的影响,训练后的模型基本不能提取任何隐写噪声。而当学习率较小时,psc更高,pss更低,从载秘图像和载体图像中提取的隐写噪声之间的差异十分微弱,这不利于分类网络的训练。因此,选择2.5×10-4作为载体图像的初始学习率。
为了直观地展示网络从载体图像和载秘图像中提取的隐写噪声之间的差别,在图4中展示了多组载秘图像和载体图像所提取的隐写噪声。为了达到更清晰的视觉效果,对隐写噪声的像素值进行了翻转,其中越暗的像素点表明该点隐写噪声越强。所用的隐写算法为J-UNIWARD,嵌入率为0.5。

图4 提取噪声与真实噪声的可视化结果
图4为网络提取噪声和真实噪声的可视化结果。其中载体提取噪声为SneNet从载体图像中提取的隐写噪声,载秘提取噪声则是SneNet从载秘图像中提取的隐写噪声。最右列的真实隐写噪声为载秘图像中所包含的真实隐写噪声,而主要隐写噪声则是真实隐写噪声在去除了所有像素值为1的点后的噪声图,主要描绘真实噪声中幅度较大的部分。从图4中可以看出,载秘提取噪声与载体提取噪声相比,包含的信息要更加丰富,且两种噪声之间有着很大的差异,这种提取噪声的差异构成了分类网络对载秘图像和载体图像分类的基础。从图4中还可以看出,载秘提取噪声与真实隐写噪声的分布十分相似,说明文中方法可以减少图像内容的影响,更加关注图像中所包含的隐写噪声。同时也能说明文中使用PSNR的差值来表示载秘图像和载体图像提取噪声的差异是合理的。而且载秘提取噪声可以较为完整地覆盖主要隐写噪声所出现的区域,这说明隐写噪声深度提取网络能够有效地提取载秘图像中所包含的隐写噪声。
4.2 网络结构合理性分析
为了分析SneNet网络结构的合理性,选择了多种图像去噪网络来进行对比实验。对比实验的数据集与2.1节中的相同,为了降低训练的成本,仅使用了嵌入率为0.4和0.5 bpnzac的数据集。使用去噪后的载秘图像与对应的载体图像之间的PSNR值来评估网络对隐写噪声的提取能力。
在图像去噪网络方面,选择了一个经典的去噪网络DNCNN[36]和一个近期的网络MIRNet[37]来进行实验。DNCNN是一个端到端的卷积去噪网络,在合成噪声上展现出了良好的去噪性能,在不同噪声上的泛化能力也很强。MIRNet通过对特征图进行下采样来获得多尺度的噪声特征,这对隐写噪声的提取很有好处。
此外,还对这些网络进行了一些修改,使得网络对隐写噪声的适应性更强。为了减少隐写噪声在网络传播过程中的损失,在DNCNN中添加了残差连接[27],通过将网络的浅层和深层直接相连,能够避免网络的退化。不同层次的图像特征进行融合也能辅助网络对隐写噪声的学习。对于MIRNet,学习从载秘图像到隐写噪声的变换,帮助网络的收敛。此外通过使用高通滤波核来初始化这两个网络第1个卷积层的卷积核,以此移除不必要的图像内容信息。通过减少图像低维信息的影响,辅助网络的学习。将修改后的网络称为DNCNN+和MIRNet+,在实验中,分别使用DNCNN、RIDNet、MIRNet、DNCNN+、MIRNet+以及文中所设计的SneNet提取隐写噪声。实验结果如图5所示。
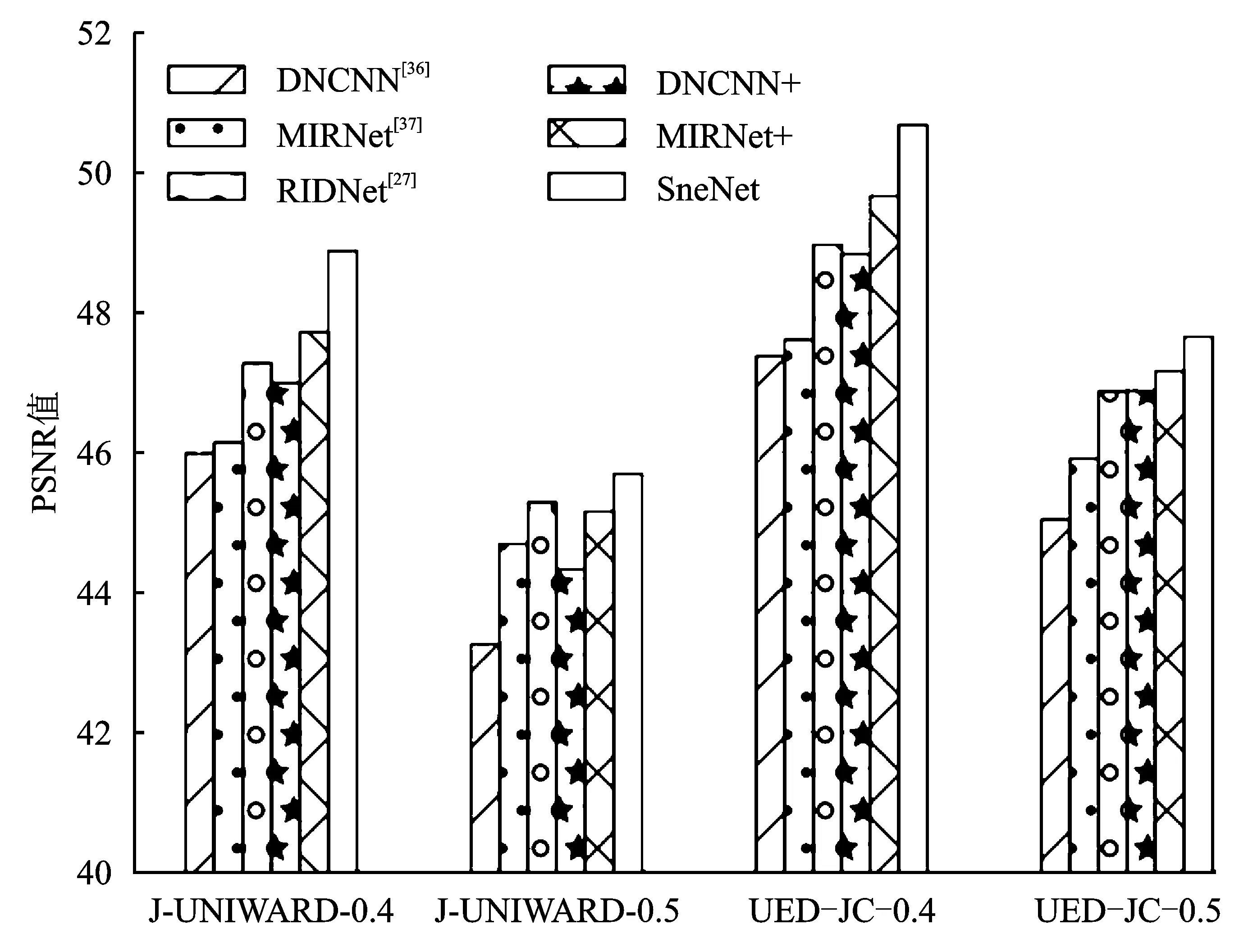
图5 使用6种网络去噪后的载秘图像与对应载体图像的PSNR值
实验结果表明,SneNet在多种情况下都取得了最高的PSNR值。通过比较DNCNN、MIRNet、RIDNet、DNCNN+、MIRNet+和SneNet的结果,可以看出,残差连接能够提高隐写噪声的提取效果,防止图像中微弱的隐写噪声在网络的传播过程中丢失。而且,通过将网络的浅层和深层直接相连,网络能够更加有效地融合不同层次的特征。融合后的特征更加全面,可以增强网络对噪声的提取能力。
与DNCNN相比,RIDNet和MIRNet在隐写噪声的提取方面表现更好,这是因为RIDNet和MIRNet是针对真实噪声的去噪网络。然而,MIRNet中使用的多尺度特征融合模块在隐写噪声上并不是很适合。经过多次下采样处理后,细微的隐写噪声难以保留,这会对隐写噪声的提取产生影响。因此,文中方法在RIDNet的基础上构建SneNet是合理的。此外,MIRNet和MIRNet+的实验结果表明,采用固定滤波核对卷积层进行初始化也能够抑制图像本身内容的影响。经过初始化的卷积层可以提取图像的高频信息,使网络专注于隐写噪声的提取。
4.3 隐写分析性能研究
为了评估文中方法的隐写分析性能,使用所提方法在J-UNIWARD和UED-JC这两种隐写算法上进行了一系列的实验,采用的对比方法是4种经典的针对JPEG图像的隐写分析方法EWNet、SRNet、CSANet和J-XuNet。图像的质量因子为75和85,嵌入率为0.1~0.5.实验结果如表3、图6和图7所示。

表3 文中方法SNdesNet与EWNet、SRNet、CSANet和J-XuNet的检测错误率对比

(a) 质量因子为75

(a) 质量因子为75
从表3、图6和图7可知,SNdesNet的检测错误率要普遍低于SRNet和J-XuNet。当质量因子为75时,SNdesNet的隐写分析性能要低于EWNet,与CSANet相近;当质量因子为85时,SNdesNet的检测效果优于CSANet;当嵌入率较高时,与EWNet相比,SNdesNet具有更好的检测效果。
当隐写算法为J-UNIWARD时,在质量因子为75的情况下,SNdesNet的检测错误率要优于SRNet和J-XuNet,与CSANet相近,略高于EWNet。在质量因子为85的情况下,SNdesNet的检测错误率要普遍优于其他4种对比方法。当隐写算法为UED-JC时,在质量因子为75的情况下,SNdesNet的检测错误率要优于SRNet和J-XuNet,略高于与EWNet和CSANet。在质量因子为85的情况下,当嵌入率大于0.3时,SNdesNet的检测错误率要优于其他4种对比算法,当嵌入率小于等于0.3时,SNdesNet的检测错误率要优于SRNet和J-XuNet,与CSANet相近,略低于EWNet。
与SRNet、CSANet和J-XuNet相比,SNdesNet更关注隐写算法给图像带来的变化。SNdesNet可以抑制图像内容的影响,网络中采用的残差连接也能减少隐写信号的丢失。通过捕获隐写噪声的全局特征,基于Swin Transformer骨干构建的分类网络也能拥有更好的分类能力,因此文中方法取得了更好的检测效果。
与EWNet相比,当质量因子为85且嵌入率比较高时,SNdesNet的检测错误率要更低。这是因为在这些情况下,图像内容对隐写分析的影响更严重,SneNet提取的隐写噪声更准确,因此分类效果要更好。然而,当质量因子较低时,EWNet中使用的反卷积层可以通过对特征图进行上采样来丰富用于分类的特征。所以,在这种情况下,EWNet拥有更好的检测效果。
在相同硬件条件下,对5种网络的平均训练时间进行了比较,结果如表4所示。

表4 5种网络的平均训练时长
从表4可以看出,文中方法的平均训练时间相对较长,这主要是由于噪声提取网络的训练相对耗时。在噪声提取网络的训练过程中,以去噪网络为基础进行设计,图像在网络中传播时大小并没有发生变化,这增加了噪声提取网络的计算量,极大地增加了训练的时长,该网络的训练时长为24.92 h。训练获得的噪声提取网络将作为一个预处理网络添加在分类网络之前,因此训练分类网络时无需再对噪声提取网络进行训练。而由于文中提出的方法抑制了图像内容对隐写分析的影响,提出的评价指标P也使提取的隐写噪声有利于分类网络的检测,因此分类网络在训练30个epoch后就可以达到收敛,这极大地减少了训练的时间,分类网络的训练时长为3.61 h。整个网络的训练时长为两个子网络分别训练时长之和,即28.53 h。
5 结束语
为了提取更准确的隐写噪声,提高隐写分析的准确率,文中提出了一种基于隐写噪声深度提取的JPEG图像隐写分析方法。该方法首先通过有监督的训练策略构建隐写噪声深度提取网络,而后利用文中提出的模型评价指标选择最优网络,最后,使用隐写噪声深度提取网络和分类网络共同构建文中的隐写分析模型。在实验中,对文中方法所提出网络参数和结构的合理性进行了分析。与现有的基于深度学习的JPEG隐写分析方法的对比实验结果表明,与SRNet、CSANet和J-XuNet相比,文中方法可以获得更高的检测准确率。当图像质量因子较大、信息嵌入率较高时,文中方法的隐写分析性能与EWNet相比略有提高。但是文中方法仍有不足之处,如当嵌入率过低时,该方法难以非常准确地提取出隐写噪声,同时隐写噪声深度提取网络和分类网络的组合导致了模型的规模较大。未来的工作包括:一方面是提取更加准确的隐写噪声;另一方面是对模型进行压缩,提升训练的效率。
