融合上下文及空间信息的拥挤行人检测算法
2023-09-06刘振兴宋晓宁
刘振兴,宋晓宁
(江南大学 人工智能与计算机学院,江苏 无锡 214122)
1 引 言
行人检测是计算机视觉领域的热门研究课题之一,其最终目的是准确识别行人类别并检测行人所处位置.行人检测算法作为关键技术已经被广泛应用于相关学术或工业领域,并在其中发挥着重要作用.随着该技术的快速发展,现阶段行人检测算法性能面临各种挑战,行人遮挡就是其中一个主要的挑战.在行人密度较大的拥挤场景中,很多检测算法性能相较于简单场景会大打折扣,被遮挡行人存在严重的漏检或误检问题.
在行人检测算法发展初期,许多传统的方法被用于解决行人检测问题,其中有基于Haar小波特征、梯度方向直方图(Histogram of Oriented Gradients,HOG)和轮廓模板的方法被提出.这一类方法在早期的行人检测任务中发挥了重要的作用.随着深度学习的发展,越来越多的研究者发现神经网络具有强大的特征表达能力,基于深度学习的行人检测算法逐渐成为了主流.现有的通用目标检测算法已经被证明能够完成简单场景下的行人检测任务,并且表现出较优的性能.不论是一阶段目标检测算法YOLO[1]、SSD[2],还是两阶段目标检测算法Faster R-CNN[3]、Cascade R-CNN[4]在行人检测任务中都有被广泛应用.然而,通用目标检测算法在拥挤场景下的检测性能会因严重的遮挡问题而大幅下降,这也使研究者开始关注行人遮挡问题.文献[5]提出一种行人检测和遮挡估计的方法,通过网络的两个分支分别预测行人全身和可见部分位置.类似地,文献[6]通过同时预测行人全身和头部位置,有效缓解行人遮挡带来的检测不准确问题.文献[7,8]针对遮挡问题对网络的损失函数进行重新设计,使得预测框和真实目标框更加接近.非极大线性抑制(Non-Maximum Suppression,NMS)[9]在目标检测中发挥着重要作用,能够有效地抑制大量非相关候选框.文献[10,11]提出具有针对性的NMS方法,能够在密集行人场景下更加准确地抑制目标框周围的非相关候选框.文献[12,13]使用注意力机制,让网络特征学习更加关注被遮挡行人的可见区域.文献[14]将行人检测问题转换为行人头部检测问题,有效应对行人遮挡问题.上述方法为解决行人检测中的遮挡问题提供了不同的可行策略,但是遮挡问题始终没有较好地方法彻底解决,这些方法依然存在许多不足.
本文针对拥挤场景下的行人检测任务,提出一种融合目标上下文及空间信息的检测方法.使用改进之后的特征金字塔网络抽取目标多尺度特征,有效应对检测目标尺度变化问题.此外,通过有效融合目标上下文信息和空间位置信息,使得特征学习网络充分挖掘行人的有效特征,降低因行人被遮挡导致整体信息缺失带来的影响.利用数据增强丰富行人遮挡的方式,有效提升网络模型特征表达能力,进一步提高在拥挤场景中算法的检测能力.在公开数据集CrowdHuman[15]和CityPersons[16]上实验证明提出方法的有效性,在不使用额外监督信息的情况下进一步提升了行人检测算法在拥挤场景中的性能.
2 Faster R-CNN算法
Faster R-CNN检测算法是目标检测任务中主流的方法之一,采用两阶段的网络结构设计,能够在各种任务中获得较为突出的检测性能,得到了研究者的高度认可.行人检测任务中使用Faster R-CNN或其优化算法也较为普遍.Faster R-CNN 网络结构以原始图像作为输入,经过ResNet-50[17]卷积神经网络做目标特征抽取,利用候选区域网络对已抽取特征进行第1个阶段的分类和回归,该阶段可以过滤掉许多与目标不相关的候选框.之后,将候选框特征输入到第2个阶段,经感兴趣区域(Region of Interest,RoI)池化操作和全连接层的输出特征作为最终的目标特征,最后网络分别对其做分类和回归预测完成目标检测.
Faster R-CNN检测网络在拥挤场景下表现不佳.从网络结构出发分析导致性能下降的原因,首先是特征抽取网络的选取,深度残差网络ResNet-50从被提出开始就受到很多研究者的青睐,主要是因为其中的残差模块设计能够很好地解决梯度消失或爆炸、网络退化问题,在很多研究领域都有广泛应用.针对行人密度大的场景,由于行人和采样相机之间距离的不确定,以及行人尺度的多样化,导致被检测目标存在尺度变化问题,这对特征抽取网络ResNet-50网络来说是一个挑战.其次,因为被遮挡目标对特征有很大的敏感性,如果相互遮挡的行人特征提取不够或不准确都会使得检测网络产生误判,从而影响最终的检测结果.上述问题使得本文需要进一步的考虑行人检测算法的结构设计,通过改变网络模型的实现细节来优化算法性能.本文在继承Faster R-CNN网络两阶段结构的基础上,针对其应用于拥挤场景存在的问题进行相应的改进和重新设计,有效地提升了检测器在拥挤场景下的检测能力.
3 本文方法
3.1 算法框架
为了有效提升行人检测算法在拥挤场景下的检测能力,本文所提方法在网络结构的设计上选择能够获得更高精度的两阶段目标检测网络.如图1所示为提出方法的整体网络框架结构.原始输入图像首先经过数据增强做随机擦除预处理,将处理之后的图像输入特征抽取网络获得充分融合的多尺度特征.然后将这些特征输入上下文模块进而提取行人潜在的上下文信息和空间特征信息.融合了上下文信息及空间信息的特征被输入到候选区域网络做第1阶段的分类和回归任务.之后,将得到的候选框特征经过感兴趣区域对齐处理和全连接层输出,最后利用输出特征做第2阶段的分类和回归完成行人检测.
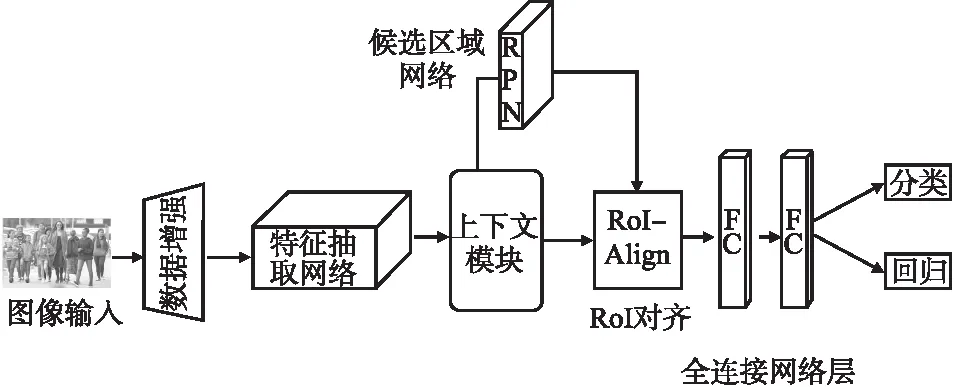
图1 本文提出算法网络图Fig.1 Network diagram of the algorithm proposed in this paper
两个阶段的分类和回归任务都使用多任务损失函数完成模型训练.其中分类和回归任务分别为交叉熵损失函数,Smooth L1损失函数,公式如下:
(1)
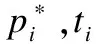
3.2 多尺度特征抽取网络
特征金字塔网络(Feature Pyramid Network,FPN)[18]的提出为解决目标检测任务中存在的多尺度问题提供了一个可行解.其结构如图2所示.该网络的输入为一张图像,输出为多层的不同比例大小的特征图.特征金字塔网络的结构主要由一个自下而上的路径、一个自上而下的路径和横向连接结构3部分组成.首先是一个自下而上的路径.如图2左半部分所示,一般选取ResNet特征抽取网络作为其自下而上结构,使用每个阶段(stage)的最后一个残差块输出的特征图,并将其定义为C2、C3、C4、C5,它们相对于输入图像的步幅(stride)为4、8、16、32像素.其次是一个自上而下的路径,如图2右半部分所示,自上而下结构将具有更强语义的高层特征图进行上采样获得高分辨率的特征.随后通过横向连接结构与自下而上路径的特征相融合得到增强,每一个横向连接都会合并两条路径中具有相同空间大小的特征图,这使得具有高级语义的特征能够和高分辨的特征在网络结构中得到融合.网络的特征输出被定义为P2、P3、P4、P5,与C2、C3、C4、C5相对应.
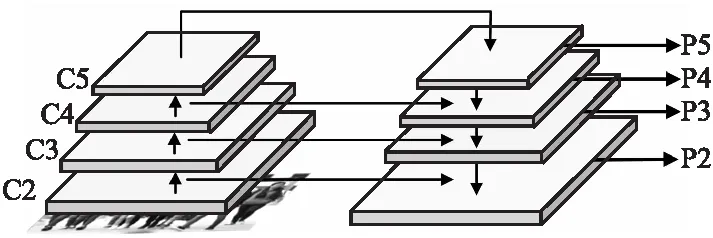
图2 特征金字塔网络Fig.2 Feature pyramid network
神经网络的浅层特征一般具有更多的空间细节信息,深层特征往往更多地具有较高的语义信息.通常,目标的定位更多地依靠网络的浅层特征,分类主要依靠深层更具判别性的特征.特征金字塔网络利用自上而下的增强分支很好地将网络高层语义信息与底层特征相结合,进一步提升了特征抽取网络的表达能力.受文献[19,20]启发,本文为了增强多尺度特征抽取网络,在特征金字塔网络的结构基础上进行改进,考虑网络低层特征对于目标定位的重要性,利用自下而上的带权融合分支将底层特征有效地传播到高层,使得整个特征网络得到增强,每一个层级特征有更好地表达能力.
为了使多尺度特征融合更加有效和充分,本文对特征金字塔网络做进一步的改进.考虑到在融合不同尺度特征时,不同的输入特征对最后的输出特征的贡献度或重要性是有所差别的.本方法在已有的特征金字塔网络多层输出之后增加一个带有权重学习的自下而上的分支,使得经过FPN网络初步融合的特征进一步与通过下采样得到的特征有效融合,进行融合的多尺度分支特征都带有可学习的权重参数,这样可以根据网络训练学习多尺度特征融合需要的权重.如图3所示为各层不同尺度特征进行带权融合的结构.该分支从特征金字塔网络的输出特征P2开始,对其进行卷积下采样,之后将所得特征通过图3的方式与下一层特征P3进行带权融合,其中W1和W2为可学习权重.经过带权融合的特征继续进行下采样与其下一层特征进行同样方式的融合.最终改进后的特征网络输出为E2,E3,E4,E5,与前面FPN的多层输出相对应.具有权重的多个特征进行相互融合不再是简单的叠加,而是通过网络训练学习得到合适的权重,不同特征对最后提取特征贡献不同,有效减少特征简单相加进行融合带来的特征冗余,从而使得融合更加有效.
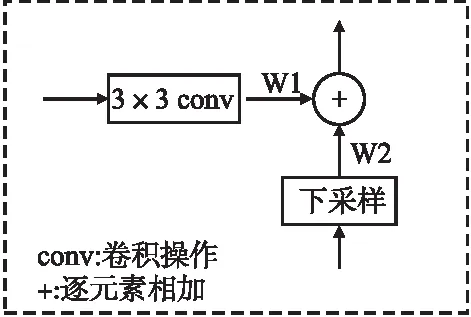
图3 横向连接结构Fig.3 Horizontal connection structure
改进后的特征金字塔网络可以很好地融合不同层特征,首先利用原始特征金字塔网络自上而下的结构将高层语义特征与底层特征相结合,然后通过提出的自下而上的带权融合分支将具有更多空间细节信息的低层特征传播到高层特征中.经过两个不同方向的多尺度融合使得底层特征也可以具有比较充分的语义信息,高层特征也可以具备更多利于定位的信息.改进后的特征金字塔网络的输出依然是是多层的特征,其中每一层的特征都具有不同的尺度,可以很好地适应行人检测目标尺度的变化.
3.3 融合上下文及空间信息
对于拥挤场景下的行人检测,行人遮挡是一个较为突出的问题.被遮挡行人由于缺乏完整的特征信息导致检测器无法正确检出.为了使特征抽取网络获得足够的行人特征信息,缓解行人遮挡带来的目标特征抽取不充分问题,本文通过扩大特征感知范围,有效结合目标空间信息,提出一种有效融合上下文信息和空间特征信息的模块.
如图4所示,为了获得更多的特征上下文信息,本文方法使用卷积核大小不同的卷积分别对特征进行卷积处理,不同大小的感受野能够捕捉不同范围的潜在目标信息.本文使用卷积核大小为3×3,5×5和7×7的卷积分别对特征F∈RH×W×C进行卷积操作获得特征F1∈RH×W×C/2,F2∈RH×W×C/4和F3∈RH×W×C/4.此外,为了获得更多的空间位置信息,能够更多地帮助目标定位,如公式(2)所示,使用空间信息提取网络将特征F先通过一个基于通道的全局最大池化(Global Max Pooling,GMP)和全局平均池化处理(Global Average Pooling,GAP),得到两个大小为[H×W×1]的特征图.之后将两个特征图基于通道进行拼接作为卷积f的输入,经过卷积把通道数降维,降维之后的特征经过sigmoid函数得到携带空间信息的特征.
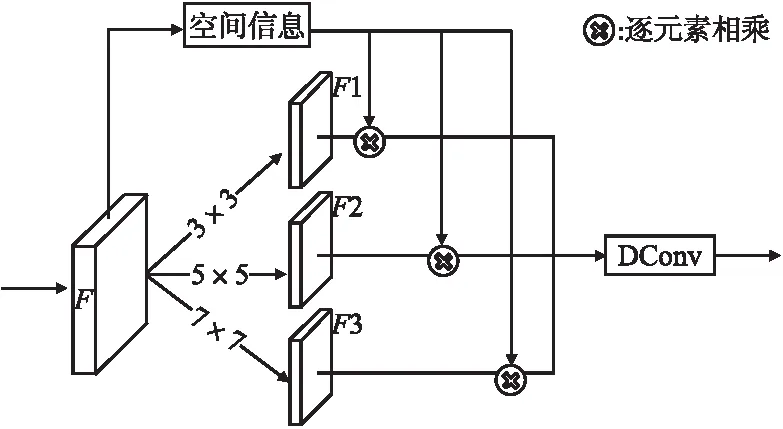
图4 上下文模块Fig.4 Context module
S(F)=δ(f([GMP(F),GAP(F))])
(2)
最后,为了使模块特征同时具有上下文信息和空间信息,对具有不同感受野的特征进行空间信息的融合,使其具备一定的空间信息,这有助于目标在缺失部分特征的情况下仍然可以被正确检出.将空间信息S与特征F1,F2,F3分别进行逐元素相乘,使得3个具有不同上下文信息的特征都携带有一定的空间信息.将融合后具有空间信息的特征基于通道进行拼接操作获得完整的特征上下文.在上下文模块的最后使用可变形卷积(Deformable Convolution,DConv)[21]做简单的特征对齐操作后输出模块的最终特征.为了验证提出方法的有效性,本文的实验章节通过在不同网络添加模块做消融实验,实验结果很好地说明了模块的有效性.
3.4 数据增强
行人检测的遮挡场景一般可以分为两种,第1种是类间遮挡,即行人目标被其它类别的物体(如汽车、墙体等)所遮挡,这类遮挡会使得行人缺乏完整的特征信息;第2种是类内遮挡,这种遮挡是由于行人密集而导致的行人之间的互相遮挡,往往这类遮挡会因为特征信息的相似度极大而影响最终的检测判别.在公开的数据集中第1种遮挡模式相较于第2种少许多,为了有效丰富数据中的遮挡模式,基于随机擦除算法[22],本文通过随机的擦除人群区域的某一部分来模拟遮挡.这样的遮挡可能会遮挡除某个目标之外的其他行人或一些背景信息,这也是出于对本文上下文模块获取信息的考虑.因为目标的上下文信息对遮挡目标的检出很有帮助,通过随即擦除一些目标周围信息,在模型训练过程中使得上下文模块获取潜在的行人有效信息更加准确.
原始图像定义为I∈[H×W×C],其中前两个维度为图像的高和宽,最后一维是通道数.将擦除区域内的三通道RGB值设置为{0.49,0.48,0.45},本文提出的方法有效地控制擦除区域的大小,从而避免图像中的行人被完全遮挡.提出方法设置擦除区域的宽不超过原图像宽W的一半,同时也保证其不小于0.3×W.除此之外,设置擦除区域的高度为0.1×H.为了防止遮挡过多导致模型训练困难或出现网络收敛问题,本文对每一张输入图像至多做两次相应的数据增强.图5为数据增强效果示例,左边为原始图像,右边为使用数据增强后.在原始图像输入网络前通过这样的方式做数据预处理,很好地丰富了数据中行人遮挡的模式.

图5 数据增强示例Fig.5 Data augmentation example
4 实验结果与分析
4.1 实验环境
本文所有实验均在以下环境开展:Ubuntu16.04.7操作系统,CPU型号为9900K,内存为64G,GPU型号为NVIDIA RTX 2080Ti,使用深度学习框架为Pytorch.
4.2 数据集与评价指标
为了有效且准确地评估所提出方法,本文使用目前行人检测研究领域主流的两个数据集CrowdHuman和CityPersons展开实验.CrowdHuman数据集是由旷视研究院于2018年发布,该数据集涉及大量的人群场景,能更好地评估检测器.CrowdHuman数据集规模大且具有丰富的数据标注,图像中的每个行人标注包括头部标注框、可见区域标注框和全身标注框.其中包含15000、4370、5000张图像,分别用于训练、验证和测试.仅训练集和验证集中就包含47万个行人实例,每张图像平均包含23个行人,数据集包含各种遮挡形式.CityPersons数据集是用于语义分割任务的数据集Cityscapes的一个子集,其中只对行人进行了标注.CityPersons数据集包含2975、500、1575张图像,分别用于训练、验证和测试.该数据集是在3个国家中的18个城市的3个不同季节中采集的,每一张图像平均包含7个行人,每个行人标注都包含可见区域标注框和全身标注框.
CrowdHuman数据集相较于其它的行人数据集有着更高的复杂程度,人群场景更加多样,不同程度的遮挡分布相对均衡.为了充分的说明本文方法的有效性,在实验环节使用该数据集作为主要的实验数据集,通过不同方式的实验对比验证网络模型.CityPersons数据集作为辅助数据集更好地验证模型的泛化能力.
提出算法在不同数据集上进行评估验证,需要有比较好的评价指标.在本实验中选择使用平均精度(Average Precision,AP)和丢失率(Miss Rate,MR-2)两项指标对模型进行全面评估比较,其中AP是目标检测任务中常用的一项评价指标,该指标越高说明模型性能越好,MR-2指标数值越低说明检测丢失率越小,模型性能更优.
4.3 实验参数设置
本文实验的基线算法网络模型以FPN作为特征抽取网络,设置每批次训练的图片数为2,训练使用随机梯度下降法(Stochastic Gradient Descent,SGD)作为优化器.整个模型总共训练40 个周期,网络训练的初始学习率设置为0.0025,分别在第24和34周期时学习率衰减10%.数据预处理使用水平翻转,Anchor高宽比设置为{1∶1,2∶1,3∶1}.此外,为了更好地完成模型在CityPersons数据集上的训练,本文在实验过程中考虑了CityPersons数据集的数据量相对较少,数据集中的图像分辨率高的因素,重新调整模型训练的迭代次数,设置网络训练25个周期,在第17个周期时学习率衰减10%.其它部分的参数设置与CrowdHuman数据集保持一致.
4.4 模块消融实验
为了更好地评估模块的有效性,本文在CrowdHuman数据集上进行各模块消融实验.通过逐个添加模块的方式,比较添加模块前后算法评价指标,综合评估网络模块的性能优劣.消融实验所有的实验结果均是在CrowdHuman数据集的训练集上完成模型训练,验证集上面进行验证.表1的消融实验结果很好地证明了提出方法的有效性,在评价指标AP和MR-2上都有明显的提升.本文在实验中以使用特征金字塔网络做特征抽取的Faster R-CNN网络作为基线算法,在其基础上展开各模块的消融实验对比.基线算法在加入了数据增强方法后,平均精度和丢失率指标都有明显的提升,通过随机擦除的方式模拟遮挡,可以增加数据中的行人遮挡模式,使得网络模型泛化性有所提高,可以适应不同程度和方式的遮挡.除此之外,提出算法使用不同的特征抽取网络进行比较,使用改进后的特征金字塔网络做特征提取更加有效,能够更多地融合不同尺度的特征,有效帮助模型应对行人多尺度问题.相较于原始的特征金字塔网络,平均精度AP增加1.4%,丢失率下降2.0%,两项指标变化说明提出方法的有效性,增加的带权融合分支结合了不同层级的特征信息,输出多尺度特征,减少不同尺度行人的漏检或误检.同时,本文方法使用特征金字塔网络作为特征抽取网络,添加上下文模块后两个指标都有相应地提升,平均精度AP增加1.1%,丢失率MR-2下降2.8%.将特征抽取网络替换为改进后的特征金字塔网络,在添加了上下文模块的情况下,平均精度AP增加0.5%,丢失率下降1.7%.实验表明在不同的网络中添加上下文模块,算法检测精度都得到了进一步提升,丢失率大幅下降很好地说明提出方法有效的减少行人漏检,能够在拥挤场景中更好地完成检测,缓解遮挡带来的严重漏检问题.通过一系列的消融对比实验可以证明提出方法的有效性.本文算法与基线算法相比,AP整体提升1.9%,MR-2下降3.7%,这也很好地提升了行人检测算法在拥挤场景中的检测能力.
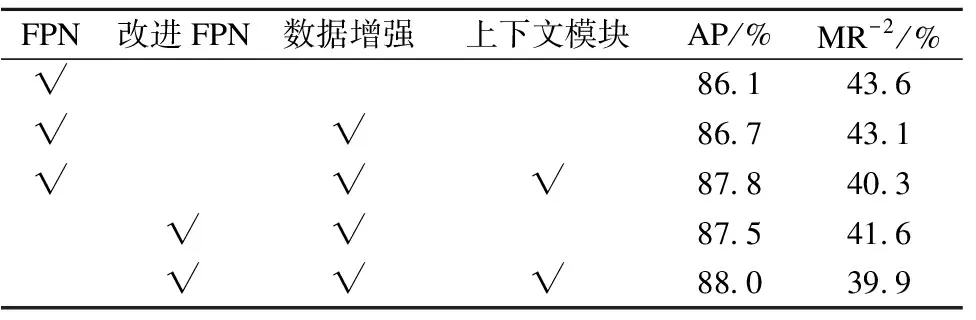
表1 消融实验结果Table 1 Ablation experiment results
4.5 实验结果比较
本文提出的方法在两个不同数据集上都做了实验评估,也同其它现有的行人检测算法展开比较,综合评估提出方法的有效性.对比实验的所有算法均是在训练集上进行模型的训练调优,在验证集上进行验证评估,为了对比实验公平有效,本文方法也采用相同的处理方式进行实验.
本文方法在CrowdHuman数据集上的验证结果同多个不同的行人检测算法进行比较,表2展示了具体比较结果.经典的两阶段目标检测算法Faster R-CNN用于拥挤场景中的行人检测,其各项指标相较于本文方法都有大幅的下降.本文在第2章对Faster R-CNN算法用于拥挤场景的行人检测存在的不足做了具体的分析说明,通过本文提出方法的改进和优化,行人检测算法在拥挤场景中的检测能力有大幅度的提升.Adaptive NMS和R2NMS算法都是使用改进后处理方式NMS的思想来降低行人的漏检或误检.CaSe算法合理利用行人可见部位的特征信息完成整个行人的检测任务.与这些方法不同,本文方法通过改进多尺度特征抽取网络,充分结合高层与底层特征信息.同时利用上下文模块有效缓解遮挡带来的特征信息缺失,挖掘更多的潜在信息.本文提出的行人检测方法与不同算法之间的进行对比,在平均精度和丢失率两项指标上都有着比较好的表现,在CrowdHuman数据集上丢失率MR-2指标能够降低到39.9%,能够更多地检测出拥挤场景中的行人.能够达到这样的检测效果,得益于本文方法更多关注行人遮挡导致的特征缺失,很好地利用目标的上下文信息捕捉潜在的有效特征,在其中融入目标的空间位置信息帮助检测器更好地定位.通过各个算法的比较,提出方法在挑战性极高的CrowdHuman数据集上优于已有算法的检测水平.
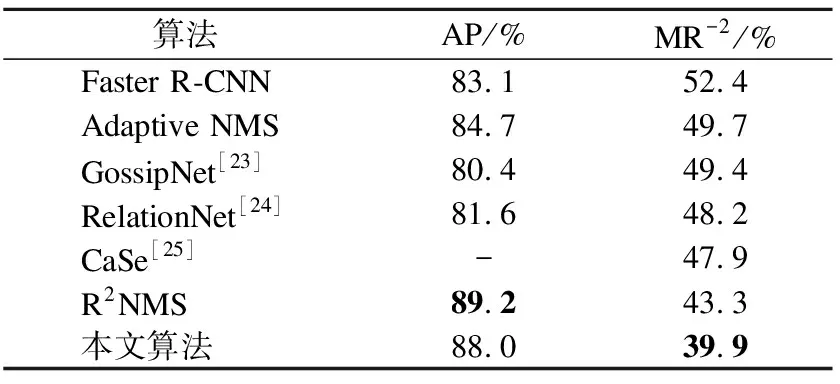
表2 CrowdHuman数据集各算法实验结果对比Table 2 Comparison results of various algorithms in CrowdHuman dataset
进一步验证算法在其它数据集上的性能,评估模型泛化能力,本文提出方法与其它不同算法在CityPersons数据集上展开对比实验.为了对比公平有效,本文选择与其它算法一致的数据集子集,使用CityPersons数据集的子集Reasonable进行训练和验证实验.该子集图像中包含的行人遮挡率保持在区间0~0.35之间,行人尺寸大于50像素.相较于CrowdHuman数据集,该数据集的行人遮挡和行人密集程度低一点.CityPersons数据集中图像分辨率较高,并且数据集中训练集数据量较少,为了更好地完成模型训练和验证,本文在该数据集上的训练也做了相应的调整,具体在实验参数设置小节已做详细说明.表3为本文方法与现有算法的对比,提出方法在CityPersons数据集上丢失率MR-2指标可以达到11.2%.Repulsion Loss算法和OR-CNN算法更多地关注损失函数,均采用重新设计网络损失函数的方式使得目标框的回归更加准确.ATT-part算法利用对身体局部的注意力机制完成行人检测.此外,在该数据集上本文方法和Faster R-CNN算法相比,丢失率指标有明显的下降,这也反映出本文方法针对拥挤场景的行人检测更加有效.相较于其它行人检测算法,本文方法有较好的指标表现.在两个数据集上进行算法对比实验,不管是在行人密度较高的CrowdHuman数据集,还是在行人密度相对稀疏的CityPersons数据集上本文方法都有着较为优异的表现,各指标也很好的反应了方法的有效性,尤其是在存在不同程度遮挡的拥挤场景下.
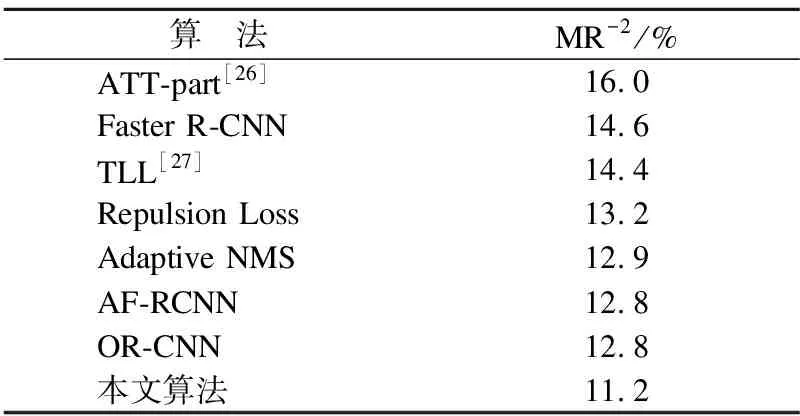
表3 CityPersons数据集各算法实验结果对比Table 3 Comparison results of various algorithms inCityPersons dataset
4.6 可视化实验
为了验证提出算法的有效性,将基线算法与本文算法的检测结果进行可视化对比.对CrowdHuman数据集中的验证集图片进行可视化得到的部分效果图如图6所示.其中,图6中上面的两幅图像为基线算法的检测结果可视化,下面的两幅图像为本文提出算法的检测结果可视化.通过图6的几幅图像对比可看出,在行人密度较大的场景中,基线算法的检测存在普遍地漏检或误检,有一些被严重遮挡的行人无法被正确检出,有一部分行人框的定位不精确.本文提出算法的可视化结果相较于基线算法表现较好,能较为完整和正确地检出拥挤场景中各行人,很好地改善了行人遮挡带来都漏检现象,有效地提升了行人检测算法的检测能力.

图6 行人检测可视化Fig.6 Pedestrian detection visualization
5 结 论
为了解决行人拥挤场景下的一系列检测问题,本文对通用目标检测方法适用于行人检测存在的不足进行分析,提出了融合上下文及空间信息的行人检测算法.利用改进的特征金字塔网络作为特征抽取网络,增强多尺度特征的表达能力,有效应对行人目标多尺度变化问题.通过有效融合目标上下文信息和空间信息,模型能更加充分地抽取行人特征信息,有效改善因行人被遮挡导致的特征抽取不充分或缺失问题.此外,为了丰富数据中的行人遮挡模式,利用提出的数据增强方法模拟遮挡,进一步提升模型的泛化能力,使得模型能够在不同数据集上都有好的表现.本文提出方法在CrowdHuman和CityPersons数据集上开展了大量的实验对比,得到了较为充分地验证,实验数据结果和可视化结果说明了提出方法的有效性,在各个指标上均取得较优的结果.但是,在实验论证过程中也发现提出方法存在性能不稳定情况,仍然有检测不够精准,模型轻量化和检测速度的问题.因此,在接下来的学术工作中将进一步分析具体导致问题的原因,提出具有更优性能的行人检测网络模型,为行人遮挡问题的解决提供更好的可行解.
