基于深度学习的中文命名实体识别研究综述
2023-09-06祁鹏年廖雨伦
祁鹏年,廖雨伦,覃 飙
(中国人民大学 信息学院,北京 100872)
1 引 言
命名实体识别 (NER) 作为独立的信息抽取工具,被广泛应用于各种自然语言处理应用中,如机器翻译[1]、文本理解[2,3]、信息检索[4,5]、问答系统[6]以及知识图谱[7]等.而且它在推动自然语言处理技术落地实践的过程中也占着非常关键的地位.下面是比较常见的应用场景:
1) 机器翻译
在机器翻译[1]过程中,像人名、地名、机构名以及专有名词等命名实体的翻译通常会根据特定的翻译规则,如中文名翻译成英文时先要把名字转化成拼音然后再调换姓和名的顺序.但对非命名实体单词的翻译则不需要添加额外的规则.可见,正确识别命名实体对机器翻译而言至关重要.
2) 知识图谱
知识图谱[7]主要由头实体、尾实体、关系及属性和属性值组成.顾名思义,知识图谱中的实体也在命名实体所涵盖的范围之内,所以实体不仅是知识图谱中最基本的组成元素,其抽取任务也是构建知识图谱的关键一步,所以命名实体识别的质量与知识图谱的质量息息相关.
3) 问答系统
在问答系统[6]中能否准确的识别出问题的各个组成部分及问题所属的领域和相关概念是影响后续任务的必要条件,这也是问答系统所面临的重点和难点.在分析问题时首先需要对用户输入的问题进行命名实体识别,抽取出问题所包含的实体,然后进一步使用关系分类、句法解析、指代消歧在内的其他自然语言处理任务,以便准确把握用户的意图.可见在问答系统中命名实体识别的重要性.
4) 语义网络
语义网络一般是由概念、实例以及对应关系组成.而语义网络中的实例一般是指命名实体,所以构建语义网络之前,命名实体识别是一个基础性的工作.
命名实体一般是指从预定义语义类型的文本中识别出有特殊意义或有很强指代性的名词(如人名、地名、机构名、时间和日期等).顾名思义,中文命名实体识别就是将中文文本中的上述实体抽取出来.然而,命名实体识别任务一开始是为英文文本而设计.但随着自然语言处理技术的不断发展,开始逐渐应用于其他语言文本中.由于英语和其他语言之间存在的差异,无法将其算法完全适配到其他语言文本中,因为英文中带有明显的形式标志,所以识别实体相对更加容易.与之相比,中文句子则由连续的汉字组成,实体本身也无明显的形式特征,识别难度更大面临更多问题.目前尚无系统介绍中文命名实体识别的研究成果发表,鲜有的工作也是围绕着英文命名实体识别展开,并以不同时期的技术发展为主线对现有的工作进行概述,没有从模型层面进行深入分析,对基于深度学习的方法介绍过于笼统.
近年来,命名实体识别技术不断发展,从基于规则的传统研究方法[8]到非监督学习[12],再从非监督学习到基于特征工程的监督学习[13]方法,最后到基于深度学习的研究方法[9-11].具体来说,基于规则的命名实体识别方法,将手工规则与实体库相结合并根据二者之间的相似性来做实体类型判断.基于无监督学习的方法通常利用统计模型来做命名实体识别,比如使用聚类算法将聚类组中上下文的相似性进行对比来识别命名实体.基于特征的监督学习方法,先从标注的数据样本中提取特征并利用这些特征来学习模型,然后从未标注的数据中识别出学习过的模式.基于深度学习的方法,凭借最优越的性能占据目前研究的主导地位,它利用向量化表示和深度神经网络处理,能够从大量训练样本中自动学习隐藏的特征.对中文命名实体识别而言,传统研究方法使用较少,主要围绕深度学习技术展开.所以本文将基于深度学习的CNER做了分类,根据不同的增强方法将其分为数据和结构增强两大类,对每个分类做了更细粒度的划分.
本文主要介绍了基于深度学习的CNER相关模型、数据集、评价标准及性能.第1节对该领域已有的方法进行了系统归纳,并提出了系统的分类方法.第2节主要介绍了用于测评CNER性能的相关数据集,并对4大常用数据集(OntoNotes 4.0、MSRA、Weibo、Resume)进行重点介绍,也分析比较了近期提出的新数据集.第3节讨论了模型的评价标准.第4节分析和对比了不同时期的经典模型.第5节探讨了CNER任务当下存在的挑战以及未来的发展机遇.
2 模型分类
在当下的CNER领域中,传统的研究方法使用较少,主要是基于深度学习的方法占据主导地位,而近些年陆续提出的模型也都是基于深度学习的.如图1所示,本文将基于深度学习的CNER方法分为3类,分别是数据增强和模型结构增强,以及二者同时增强.然后对每一类中的方法进行更细粒度的剖析.
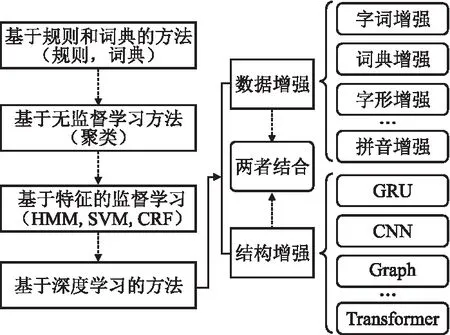
图1 基于深度学习的CNER方法分类Fig.1 CNER method classification based on deep learning
2.1 数据增强模型
1) 基于字词的方法
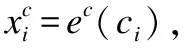
字符级表示对英文文本而言可以有效处理前后缀信息,而对中文文本来说也可以有效避免分词不准确导致的模型传播错误.文献[20-22]指出,在中文命名实体识别系统中基于字符级表示的方法比基于词级表示的方法效果更好.其中,He等人[20]针对中文分词和命名实体识别任务提出了一种基于字符的条件随机场模型,分别对比了字符级表示、词级表示以及词级表示加词性特征的中文命名实体识别任务,结果表明基于字符表示方法的效果最好.Zhang等人[25]使用输入的字符级表示并结合了分词和语法解析,实验表明基于字符的特征可以显著提高中文句法分析的准确性.Chen等人[23]将中文命名实体识别视为一个字符序列标注问题,构建了一个基于条件随机场(CRFs)的命名实体识别系统,其中包含基本的特征和基于条件随机场的附加特征.Lu[24]等人认为,字的使用非常灵活,每个字在不同的词中可以有不同的意思,通过对每个字符使用一个固定的表示很难完全捕获字符的意义.因此,提出了一种多原型字符表示方法,该方法在给定输入句子的情况下,可以同时做预测字符表示和字符语义.实验结果也表明,字符的多原型表示在中文命名实体识别任务上比单原型基准有更好的表现,而且多原型字符表示模型也成为了当时最先进的模型.Dong等人[26]将BiLSTM+CRF架构引入到CNER任务中,并使用了字符和部首级联合表示的方法,模型最终取得了不错的性能.
文献[14-16]中则采用了词级表示,使用无监督算法对大量英文文本进行预训练,并将预训练好的词嵌入作为输入,然后在NER模型训练时进行固定或进一步微调即可.这类方法的典型代表如连续词袋(CBOW)和连续skip-gram模型[18],而文献[17,19]也进一步证明了预训练词嵌入的重要性.目前,在中文命名实体识别模型的训练中,主要也是采用字符或词向量模型的预处理方法.以字符向量作为神经网络的输入不能使用单词的语义并且要放弃单词的显式边界信息,而以单词向量作为神经网络的输入则依赖于分割算法的准确性.因此,选择什么样的表示方式,这取决于不同文本的语言特征和具体的应用场景,也有研究将字和词的表示结合起来取得了很好的效果.Liu等人[21]使用序列标注的方法,研究了在中文命名实体识别任务中字符级和单词级表示应该采用哪一种表示粒度.结果表明,根据附加知识库的规模应该采用不同的方法.在相关知识不足的情况下,基于字符的方法适用于具有相同特征的姓名和地点的识别.在特征数量足够的情况下,基于词的模型对NER任务来说更有效.而且,基于词的NER模型在使用更有用的全局知识特征(如人名、地名等)的情况下,可以达到更好的效果.
由于字词表示都有其各自的优势与缺陷,所以有些方法使用字词融合的思路来取长补短.Ye等人[27]提出了一种基于字词向量融合的CNER模型CWVF-BiLSTM-CRF,该模型先利用Word2Vec得到字词向量和字词向量对应的字典.然后将字词向量集成到BiLSTM网络的输入单元中,并利用CRF解决标签序列不合理的问题.文中指出,该模型可以有效减少对分词算法精度的依赖,并能有效地利用词的语义特征.
2) 基于词典的方法
在基于字符表示的基础上融合中文分词信息已成为中文命名实体识别方向的研究热点,此类方法以中文更有效的字符表示为基础,尽可能多的融合其他外部信息来丰富所表示的特征,而且已有的大量工作表明借助外部词典信息可以有效提高中文NER的性能.因此,本节归纳了结合外部词典来做中文命名实体识别的系列工作.首先,介绍此类工作的开山鼻祖Lattice-LSTM[28],然后深入剖析了它的各种变体,最后做全面的分析.
外部资源信息已被广泛应用于命名实体识别任务中,特别是词典信息的使用,文献[34-37]中均使用词典信息来增加NER.LSTM已成为NER任务中序列建模的主要选择,但其受到基本架构的限制,只允许严格顺序的信息传播,因此Tai等人[29]将LSTM架构扩展成了基于树形结构的Tree-LSTM,如图4所示,该模型结构不仅可以支持多种网络拓扑而且每个根节点都可以融合其子节点的信息.已有的工作[28,30-33]中都使用Tree-LSTM结构来构建模型并取得了很好的效果.
Zhang等人[28]基于Tree-LSTM结构设计了一种中文命名实体识别模型,该模型是基于词典的中文NER的开山之作,此后有一系列的优秀工作都是在此基础上的展开.该模型使用当时英文NER中表现最好的LSTM-CRF[108]模型作为主要的网络架构.文中同时构建了基于字符和词以及Lattice结构的中文NER模型.其中,基于字符的模型使用的是BiLSTM+CRF架构,而且在字符表示的时候分别融入了二元语法(bigrams)信息和标签分割信息.而基于词的模型则是在词表示的基础上添加了词中所包含字的表示,也就是将字词表示相融合,并且文中对词中所包含字符的表示使用了3种不同的表示方法:第1种是使用一个双向循环神经网络来做字符的表示;第2种则为每一个字符使用一个单独的BiLSTM来获取前向和反向的特征;第3种是在每个词的字符序列上使用标准的CNN结构来获得其字符表示.而基于Lattice[28]的NER模型首先通过自动分割大量的原始文本构建词典,然后将所有的输入字符序列一同去字典中匹配相关的词.该模型以字符表示为基本结构,但是与基于字符模型不同的是需要考虑句子中的词在词典中对应的词序列,并在句子开始时候会使用一个细胞(Cell)来表示在词典中查到的词在RNN中的状态.实验结果表明:与单纯基于字和词的LSTM-CRF[108]相比,Zhang等人提出的方法在4个数据集上的表现都非常优异,而且Lattice模型不受分词结果的困扰,可以自由选择词典中的匹配词.
Yang等人[65]的研究结果表明,LSTM由于本身的门结构特征,有时错误的路径选择会使得Lattice-LSTM模型[28]退化成基于词表示的模型,而词模型面临着词边界检测错误的影响,这种情况下Lattice-LSTM就失去了结构优势.为此,Liu等人[63]提出了一种新的字词LSTM(WC-LSTM),用于将单词信息集成到基于字符的模型中,为了防止模型退化为基于词的部分模型,给每个字符分配固定的单词信息.该模型以LSTM-CRF作为主要的网络结构,但与标准LSTM-CRF模型之间的差异主要在于嵌入层和LSTM层.基于WC-LSTM[63]的模型,首先将中文句子表示为一系列字-词对,其目的是将单词信息集成到每个字符中.其次,为了使模型能够批量训练并满足不同的应用需求,文中引入了4种编码策略来从单词中提取固定大小但不同的信息.最后,使用链结构的字词LSTM层从字符和单词中提取特征.具体来说,在字词嵌入层,每一个向量都是由两部分组成,分别是对应的字符和分配的词,并且词按其长度进行排序.为了有效利用过去和将来的信息,模型使用了双向WC-LSTM.因为考虑到连续标签之间的依赖性,所以使用CRF层来做序列标记.最后该模型在几个常用数据集上进行评估,并以Zhang等人[28]提出的Lattice-LSTM模型为主要的比较对象,实验结果表明基于WC-LSTM的模型比Lattice LSTM模型更高效快速,并且和当时最新的模型相比都有一定的优势.
由于中文句子不是天然分割的,所以中文NER任务的一种常见做法是先使用现有的CWS (Chinese Word Segmentation)系统执行分词,然后对分词结果进行将词级序列标注.但CWS系统不可避免地会错误地对查询语句进行分段,这将导致NER中实体边界的检测和实体类别预测时出现错误.所以目前很多研究者直接在字符级别上执行中文NER任务,而这种方法被已有的工作证明是非常有效的.基于纯字符的模型无法有效融合词信息.但Lattice-LSTM[28]模型结构过于复杂,为了引入词典信息,在输入序列中不相邻字符之间添加了多个附加边,使得训练和推理的速度大大减慢.而且该模型很难移植到可能更适合于某些特定任务的其他神经网络模型中.由此,Ma等人[56]提出了一种更简单的方法来实现Lattice-LSTM[28]的思想,该模型以字符模型为基础,在字符表示形式中对词典信息进行编码,并设计编码方案以保留尽可能多的词典匹配结果.该方法避免了对复杂模型结构的需求,易于实现,并且可以通过调整字符表示层来快速适应任何合适的神经网络架构.具体来说,该模型依然使用BiLSTM+CRF结构来做序列建模,而字符表示层也是使用Lattice-LSTM[28]相同的方法,其创新点在于构建了SoftLexicon特征并将其融入到了字符表示层中.SoftLexicon的特征构建分为3步,第1步是分类匹配的单词,将每个字符的所有匹配单词根据字符位置的不同分类到4个词集“BMES”中.第2步是压缩单词集,也就是在获得每个字符的“BMES”单词集之后将每个单词集压缩为固定维向量.第3步是与字符表示相结合,即将4个单词集的表示形式组合到一个固定维特征中,并将其添加到每个字符的表示形式中.为了保留尽可能多的信息,文中选择了串联4个单词集的表示形式.该模型在4个基准中文NER数据集的实验研究表明,可以实现更快的推理速度和更好的性能.
3) 基于字形和部首的方法
部首对于汉语的计算处理非常重要,因为具有相同部首的字符通常具有相似的语义和语法角色.例如,动词“打” (hit) 和“拍”(pat)共享同一个部首“扌”(手),二者不仅语义相同,而且在句子中都充当动词.现有的中文处理算法通常以单词或字符为基本单位,忽略了重要的部首信息.Sun等人[66]提出了一种基于部首增强的中文字符嵌入模型,利用部首信息来学习汉字的连续表示.文中设计了一个专用的神经网络模型,该模型由两个模块组成:基于上下文的模块和基于部首的模块,其中基于上下文的模块主要是为了捕获上下文信息,而基于部首的模块则用于充分融合部首信息.该模型应用于汉字相似性判断和中文分词中并取得了不错的效果.Shi等人[67]深入探讨了汉语处理的特点和基本层次,也提出了一种新的“部首嵌入”方法,并通过3个实验验证了其可行性和实用性:两个关于短文本分类(STC)和汉语分词(CWS)以及一个搜索排名的现场实验.
从简单的词袋模型[77]和线性递归神经网络模型[77,78]到更加复杂的树结构[80]或卷积神经网络[81]模型均可学习如何将单词组合成一个有意义的完整句子.Liu等人[68]根据中文字符的视觉特征来创建嵌入,首先将每个字符的Unicode表示转换为图像,然后通过卷积神经网络来计算字符的表示,最后将得到的字符表示作为下游处理任务的输入.并且实验结果表明,在文本分类任务中,该模型能够更好地处理中文、日文和韩文等语言中含有罕见字符的句子.Dai等人[69]也明确地将中文字形的视觉特征纳入到字符的最终表示中,从而实现了一种新颖的汉字字形感知嵌入模型.在语言建模和分词这两个基本中文NLP任务中,该模型可以在字符级嵌入中有效学习其语义和句法信息.Su等人[70]也认为中文单词是由包含丰富语义的字符组成,一个汉字的意义往往与其组成汉字的意义有关.因此,汉语单词嵌入可以通过其组合字符嵌入来增强[80,81].此外,汉字由若干字形组合而成,具有相同字形的字符可能具有相似的语义或发音.而且除部首之外的其他成分可能包含单词表征学习中潜在的有用信息,所以文中首先使用convAE从位图中提取字符特征来表示字形,然后,使用与Skip gram[18]或GloVe[83]平行的模型从字符字形特征中学习单词表示.
前期利用CNN来提取字符视觉特征以丰富字符最终嵌入的工作[68-70,84]中,文献[68,69,84]得到的性能提升较为有限,而Su等人[70]也只证明了字形嵌入在单词类比和单词相似性比较中比较有用.Meng等人[71]则总结了使用CNN提取中文字符特征时最终效果不够理想的主要原因:首先,没有使用正确字体版本,因为汉字从易于绘制开始,慢慢过渡到易于书写,变得越来越不象形不具体,而迄今为止使用最广泛的简体中文是最容易书写的字体,不可避免地会丢失最大量的象形文字信息;其次,没有设计合适的网络结构,ImageNet[86]图像的尺寸大多为 800×600,而字符的灰度图尺寸明显小很多(通常为12×12),所以需要设计一个合适的CNN架构来捕获字符图像的局部图形特征;最后,由于常用的汉字字符大约只有10000个左右,所以需要考虑过拟合问题还要想方设法提高模型的泛化能力.基于这些考虑,Meng等人[71]使用不同时期的中文字体来丰富汉字的字形特征,还设计了专门的神经网络结构对中文字符图进行编码.此后,有一系列基于Glyce的工作出现,Sehanobish等人[72]就使用图像分类的方法来提取中文字符中“有意义的”特征,并且提出了一个自动编码器体系结构GLYNN对字形进行编码,然后将编码后的特征作为NER系统的附加特征.Xuan等人[61]则指出上述工作只对字形和分布式表示进行了独立编码,忽略了字符与上下文之间的交互信息,而多模态深度学习已经对此做了相应研究[86-88].此外,由于单个汉字的意义不完整,字符的单独编码并不是一个很好的方法,而相邻字符的符号之间的交互信息可能有利于NER任务.并且汉语中有很多相似的语义可以通过相邻符号之间的交互信息进行区分.为此,文中提出了一种融合字形和上下文信息的模型,其中使用CNN来获取字符的字形特征,使用预训练好的BERT捕捉相邻字符之间的潜在信息.此外,还设计了一种基于Attention的滑动窗口机制来融合字形特征和字符表示之间的交互信息.实验结果表明,该模型可以有效提高NER任务的性能,也进一步揭示了在OntoNotes 4.0和Weibo数据集上使用BERT可以大幅提高其性能.
Sun等人[73]指出目前基于中文的预训练模型忽略了汉语中的两个重要特性:字形和拼音,因为字形和拼音承载着重要的句法和语义信息,这对语言的理解来说至关重要.文中提出了一种将中文字形特征和拼音信息结合到预训练模型中的ChineseBERT方法.根据汉字的不同字体获得字形嵌入,能够从汉字的视觉特征中捕捉汉字语义,而拼音嵌入字符则是汉字的发音可以有效处理汉语中普遍存在的“异音异义”现象.首先将ChineseBERT模型在大规模无标记中文语料库上进行了预训练,在训练步骤较少的情况下与基准模型相比,具有显著的性能提升.
在英语中不同的单词可能有相同的词根或词缀,它们可以更好地代表单词的语义.而且根据英语单词的信息可知,词根或词缀往往决定了单词的一般意义[89].即使是最先进的方法,如BERT[50]和GPT[51],在大规模数据集上训练时也采用这种精细的词分割方法来提高性能.而对于汉字来说,也有类似于英语词根和词缀的结构.Wu等人[48]认为汉字从古代的象形文字进化而来其结构往往反映了更多有关汉字的信息,所以将汉字的结构分解为词根、头尾和结构成分3部分来获取字符级嵌入.由于LSTM基于时序建模的特点,使每个cell的输入依赖于前一个cell的输出,不仅模型结构比较复杂而且并行能力有限.所以文中使用FLAT[46]来实现高效并行计算并结合其在词汇学习方面的优势,在此基础上引入了汉字结构作为扩展.模型不仅具有FLAT的词边界和语义学习能力,还增加了汉字的结构信息,结果表明这对NER任务来说非常有效.
2.2 结构增强模型
1)基于字词的方法
虽然Zhang等人[28]提出的基于词典的Lattice模型在中文NER领域中取得了巨大的成功,但Gui等人[38]认为该方法明显存在着两方面的问题.首先,基于RNN的架构由于受到网络本身的限制不能够充分利用GPU的并行性[39].具体来说,Lattice-LSTM结构使用双重循环神经网络来处理字词表示,由于其顺序处理的特点使得处理效率严重受限.而且Lattice-LSTM也无法选择词典中的最优匹配词,这可能会误导模型.
Gui等人[38]使用CNN来并行处理整个句子和潜在的词以提高处理的速度,然后使用Rethinking机制[40]中的高级语义来细化嵌入词的权重以解决潜在词之间的冲突.Rethinking机制中提出了两个全新的层——反馈层和强调层,利用反馈层中候选对象类别的反馈后验概率来赋予网络模型在训练过程中对决策进行“反思”的能力.基于CNN和Rethinking机制的中文NER模型的构建分为3步,首先是构建基于词典的CNN网络,其次是添加Rethinking机制,最后使用条件随机场来做NER预测.Wu等人[111]提出了一种用于CNER的神经网络模型.该模型中,先引入了CNN-LSTM-CRF架构来捕获CNER任务中的本地和远程上下文信息,然后设计了统一的框架同时训练中文命名实体识别模型和分词模型来辅助CNER模型中实体边界检测.此外,基于卷积神经网络的模型主要集中于使用汉字的灰度图来提取字形的特征方法中,本文将在后面章节对其做系统的梳理.
2)基于图神经网络的模型
基于RNN的中文NER模型受到链结构特点的影响再加上全局语义的缺乏很容易产生歧义.而基于Lattice-LSTM[28]的模型,大多数使用RNN或CRF对句子进行顺序编码,语言的底层结构并不是严格顺序的,会遇到严重的词双值问题,特别是对中文文本来说更具挑战性.Gui和Zou等人[41]提出了一种将词典与图神经网络相结合的模型.该模型中使用词典知识来连接字符以捕获局部特征,并利用全局节点来捕获全局句子语义和远程依赖.而且基于图的字符、潜在词和整个句子语义之间的多种交互可以有效地解决歧义问题.该模型使用了一种高效的图消息传递架构[44],通过词汇信息来构造图神经网络以实现中文NER作为节点的分类任务.
Sui等人[42]则认为自动构建的词典虽然包含了丰富的词边界信息和词语义信息,但对基于词汇信息的汉语NER任务来说仍面临着两方面的重要挑战.第1个挑战是整合字符在词典中自匹配的词,字符的自匹配词是指词典中所有包含该字符的词.第2个挑战则是直接整合词典中最近的上下文词汇.因此,Sui等人[145]提出了一种基于字符的协作图网络.具体而言,在图形层中包含3个“单词-字符交互图”.第1个是包含图(C-graph),它用于集成自匹配词法单词并模拟了字符和自匹配词之间的联系.第2个是过渡图(T-graph),它建立了字符和最接近的上下文匹配单词之间的直接连接来应对直接集成最接近的上下文单词的挑战.第3个是格子图(L-graph),它受Lattice[28]模型的启发,L-graph通过多次跳跃隐式捕获自匹配词和最近的上下文词汇词的部分信息.这些图是在没有外部NLP工具的情况下构建的,不仅可以避免错误传播,而且这可以很好地互补.
地名词典被证明在命名实体识别任务中很有用[45].现有许多基于机器学习的NER系统中都纳入了地名词典,但目前仍然受限于手动选择,特别是同时涉及到多个词典时单纯的靠手动选择可能不会带到很好的效果.在中文NER任务中更是如此,因为词典中的词并没有被标记出来,所以可能会带来歧义.为了将多个地名词典自动的合并到NER系统中,Ding等人[43]提出了一种基于图神经网络的创新方法,该网络可以使用多图结构来捕获地名词典提供的信息.该模型由多图及经过改进的GGNN嵌入层和BiLSTM-CRF层组成.其中,多图显式地将文本与命名实体地名词典信息结合在一起,并使用改进的图神经网络对所有特征进行建模,然后使用BiLSTM-CRF架构来实现序列预测.
3)基于Transformer的模型
由于Lattice[28]模型天生拥有复杂的动态结构,而且LSTM只能进行顺序建模,无法有效利用GPU的并行能力.由此,Li等人[46]提出了一种将复杂Lattice结构转换为更为简单的平面结构的模型.模型借助Transformer结构特性并精心设计位置编码功能可充分利用格子信息并具有出色的并行化能力,整个过程构建分为两步,第1步是将Lattice的嵌入结构转化为由基本单元组成的平坦结构,第2步则对每一个基本单元进行相对位置编码.FLAT由一系列基本单元组成,而每一个单元(span)由对应的token、头部和尾部组成.其中,token是指字符或单词,而头部和尾部表示该token在原始序列中的首尾字符的位置索引,即在晶格中的位置.对于单个字符而言,其头和尾是相同的.为了对跨度之间的交互进行编码,模型使用了相对位置编码,对于晶格中的两个跨度xi和xj,它们之间存在3种关系:相交,包含和分离.模型不直接编码这3种关系,而是使用密集向量通过头和尾信息的连续转换来对它们之间的关系进行建模.Wu等人[48]利用FLAT[46]在高效并行计算和词典融合方面的巨大优势,结合双流Transformer提出了一种融合汉字结构信息的中文NER模型.具体来说,模型在一个双流Transformer中使用多元数据嵌入来整合部首级的汉字特征,因为利用汉字的结构特点可以更好地捕捉汉字的语义信息,而且模型又继承了FLAT的特性所以具备词边界和语义学习能力,实验结果也表明了该方法在性能上的优越性.Yan等人[110]也提出了一种自适应Transformer编码器,通过结合方向感知、距离感知和未缩放注意力来建模字符级特征和字级特征的NER架构.
预训练模型[50,51,109]在各种中文NLP任务中已被证明其有效性[52-55].近期研究表明,在中文命名实体识别[46,56]、中文分词[57]以及中文词性标注[58]等领域均使用词典和BERT相结合的方法,其核心思想是将BERT和词汇特征的上下文表征集成到神经序列标注模型中.Liu等人[49]受BERT适配器[58-60]的启发,提出了一种基于词典增强的BERT(LEBERT)模型,该方法通过一个词典Adapter层将外部的词典知识直接集成到BERT层中.具体来说,使用字符到字符的双线性注意机制,动态地为每个字符提取最相关的匹配词将句子转换为字词对序列.Xuan等人[61]提出了一种将中文字形特征与BERT相结合的模型,该模型首先使用CNN提取中文字形特征,然后利用预先训练好的中文BERT对句子中的每个字符进行编码,最后将二者的输出融合成最终嵌入送到LSTM-CRF架构中做序列标注.值得一提的是,与常规的BERT微调策略不同,该模型先在训练集中用CRF层作为标记器对BERT进行微调,然后冻结BERT参数并将其应用于字符表示中.Xue等人[62]提出了一种为中文NER量身定制的Transformer编码器扩展模型—PLTE.PLTE在Lattice结构的基础上通过位置关系表示法来增强自注意力(self-attention),并引入一种多孔机制来增强局部建模并保持捕获丰富的长期依赖关系的强度.该模型主要由3部分组成,分别为:Lattice输入层、多孔Lattice Transformer编码器以及BiGRU-CRF解码层.其中,输入层是将tokens的语义信息和位置信息都融合到其嵌入中.多孔Lattice Transformer编码器中提出了两种编码机制,一种是Lattice感知的自注意力编码机制(LASA),另一种则是多孔多头注意力机制(PMHA).由于位置编码不能捕获Lattice结构中输入的相对位置信息,所以提出了相对位置关系矩阵来表示这样的位置信息,LASA就是将这种位置关系合并到Attention层中,而为了保持捕获长距离依赖项的强度并增强捕获短距离依赖项的能力,PMHA则是引用Guo等人[63]提出的枢轴共享结构来替换全连接结构以达到简化Transformer架构的目的.最后将字符序列表示形式送到BiGRU-CRF解码层中以进行序列标记.
2.3 其 他
CNER任务和中文分词(CWS)任务虽然都有各自的特点,但却存在许多相似的单词边界.Cao等人[47]指出,绝大多数工作中都没有考虑将中文分词系统中的词边界信息有效整合到CNER任务中,也没有考虑将分词任务中的特定属性过滤掉,所以将对抗迁移学习整合到CNER模型中,帮助模型在使用共有词边界信息的同时也能有效过滤分词专属的边界特性.此外,文中也使用了自注意力机制来获取句子的全局依赖关系.该模型结构可以分解为:输入表示层,共享-专用特征提取器,自注意力层以及特定的CRF和任务判别器.与其他神经网络模型一样,输入表示层就是将离散字符映射到分布式表示中.而共享-私有特征提取器的作用是分别提取分词任务与CNER任务共享的词边界信息和分词系统独有的信息.自注意力机制则用来捕捉字符之间的依赖信息,以此获取句子的内部结构特性.由于两个任务最终的输出标签不同,所以特定任务的CRF是为每个任务引入了一个特定的CRF层来打标签.受对抗网络[91]的启发,文中使用对抗训练来获取共享的边界信息.任务判别器的作用就是用于估计句子来自哪个任务.最后,该框架在两个数据集(WeiboNER和SighanNER)上取得了不错的效果.
Zhu等人[90]也提出了一种不依赖任何外部资源(如词典)的CNER卷积注意力网络模型,该模型使用两个不同的注意力层分别捕获不同级别的特征,其中基于字符的卷积神经网络(CNN)用于捕捉局部特征,而基于门控递归单元(GRU)则获取全局信息.模型将BiGRU-CRF作为基本架构,并设计三层结构来提取上下文特征,三层结构分别为卷积注意力层,GRU层以及全局注意力层.其中,卷积注意力层是将输入进行分布式表示并提取局部上下文特征,然后将最终结果输入到BiGRU中.通过卷积注意力层是对连续句子信息建模,而全局自注意力层的作用是处理句子级别的信息.实验结果表明,该模型在不同领域的数据集上都有不错的表现.
Wang等人[107]探究了如何在神经条件随机场的框架下,通过NER和成分分析联合建模来改善中文命名实体识别.文中将解析任务(Parsing Task)重新配置为高度受限的成分解析,从而降低计算复杂度,并且保留了大多数短语级语法.具体来说,该模型将神经Semi-CRF模型和神经Tree-CRF模型相统一,可以同时实现单词分割,词性(POS)标记,NER和解析任务.该联合模型的难点在于如何实现有效的训练和推断.因此,Wang等人设计了一种用于训练和推理的动态编程算法,其复杂度为O(n·4h),其中n是句子长度,h是限制高度.
Li等人[112]使用词与词之间的关系来建模NER问题,不仅使用新的数据编码模式,而且提出了全新的模型架构,在嵌套、非嵌套以及不连续数据集中均表现很出色,同样在4个中文数据集上也取得了不错的效果.Qi等人[113]提出的基于文本相似度和互信息最大化的CNER模型中,首先通过计算文本相似度寻找字符的潜在词边界,然后分别最大化字符、潜在词边界以及句子之间的互信息来增强输入特征.此外,还设计了特定的网络架构来做结构增强.该方法在4个CNER数据集上均取得了最好的结果.
3 数据集
在中文命名实体识别中使用最广泛的数据集包括:OntoNotes 4.0[92]、MSRA[93]、Weibo[94-95]、Resume[28].OntoNotes 4.0中文部分包括新闻专线数据250K、广播新闻270K、广播对话170K.其中新闻专线数据由100K的新华社新闻数据和150K光华新闻杂志数据组成.广播新闻数据选取使用LDC标注的用于自动内容抽取(ACE)程序的数据,广播对话数据取自LDC的GALE数据,其中50K的原始中文数据是用英文标注的,另外还有55K的数据是从将原始的英语广播对话翻译成中文的.MSRA是由微软亚研院标注的CNER数据集,该数据集中共有5万多条CNER的标注数据,其实体类别相对较少,分别为地点、机构、人物.Weibo是从中文社交媒体(微博)上选取的消息作为命名实体识别数据集,并根据DEFT ERE标注规则进行标注,其中实体类别包括名称.和名义上的提及.该语料库包含2013年11月~2014年12月期间从微博中抽取的1890条信息.Resume数据集是由Zhang等人[28]提供的从各类公司高管简历中随机抽取了一部分并使用YEDDA系统标注出来的CNER数据集,其中包含8种命名实体,分别为国家、教育机构、位置、人名、机构、职业、种族背景、职务.此外,近期公开发表的数据集CLUENER2020[105]是将文本分类数据集THUCTC进行了进一步处理得到的一个细粒度CNER数据集.CLUENER2020共有10个不同的实体类别,包括:组织、人名、地址、公司、政府、书籍、游戏、电影、职位和景点.常用的4个数据集中所包含的句子、字符以及实体数量统计如表1所示.

表1 数据集统计Table 1 Dataset statistics
如表2所示,本文列出了可用于中文命名实体识别几个工具.Fast NLP是由复旦大学NLP组开发的一款面向NLP领域的快捷工具包,提供了一些常用的预训练模型和数据集并支持多种NLP任务.NLPIR是中科院计算所开发的中文分词系统,有效支持多种依赖分词的下游任务,如NER、POS tagging、新词识别等任务,而且该系统支持跨平台、跨语言开发.LTP是哈工大开发的NLP工具包,也支持多种常见的NLP任务.斯坦福大学NLP组开发的CoreNLP已支持中文,其中也实现了命名实体识别任务.此外,由于传统的中文NER任务被分割成分词加序列标注两步实现,所以表2中也列出了常用的分词工具.Jieba作为分词工具的典型代表应用最为广泛.由清华大学开发的THULAC也支持中文分词和其他主流的NLP任务,而且与其他同类型工具相比速度更快、精度更高.ZPar是用C++开发的NLP工具包,支持中英文两种语言,用户可根据需求自行选择,支持中英文分词、词性标注、依存关系和短语结构解析等功能.

表2 可用于中文命名实体识别的工具Table 2 Available Chinese NER tools
4 评价标准
通常使用两个标准来评价一个命名实体识别任务.首先是能否正确识别实体的边界,另一个是实体的类型是否被正确标记.所以可能会出现以下几种错误,不能正确识别实体,实体边界正确而类型错误或实体类型正确而边界错误等.只有当实体边界和类型都被正确识别时,才能认为命名实体识别任务的正确性.对于NER任务来说,衡量的标准有精确度(Precision)、召回率(Recall)和F值(F-score),它们分别是由True Positive(TP)、False Positive(FP)、False Negative(FN)3个统计量计算而来,其中True Positive(TP)是指正样本预测判定为正、False Positive(FP)是指负样本被预测判定为正、False Negative(FN)是指被模型预测为负的正样本数,具体的计算如下所示:
精确率和召回率均不能单独衡量命名实体识别任务效果的好坏,所以F值是二者的调和平均值.
5 性能分析
表3~表6介绍了近年来大多数最先进模型的在4个公开数据集上的表现.‘*’表示在基于半监督学习的模型中使用外部标记数据,‘#’表示模型利用了离散特征,‘§’表示黄金分割.表3列出了OntoNotes 4.0数据集上的最先进结果,目前来看,使用BERT可以有效增强中文NER任务在该数据集上的性能.因为MECT[48]不使用BERT的F1值为76.92%,使用BERT以后则为82.57%,二者相差5.65%.表4列出了Resume数据集上的最先进结果,其中SSMI[113]的F1值最高,因为该模型从数据和架构两个维度去做增强.表5为Weibo数据集上的最新结果比较,其中使用字形增强方法相较于词典增强的方法有明显的性能优势.表6是MSRA上的实验结果汇总,由表可知,基于词典的方法和字形融合的方法在性能上相差不大,使用BERT对F1值有明显的增强.

表3 数据集OntoNotes 4.0 的最新结果比较Table 3 Results on OntoNotes 4.0
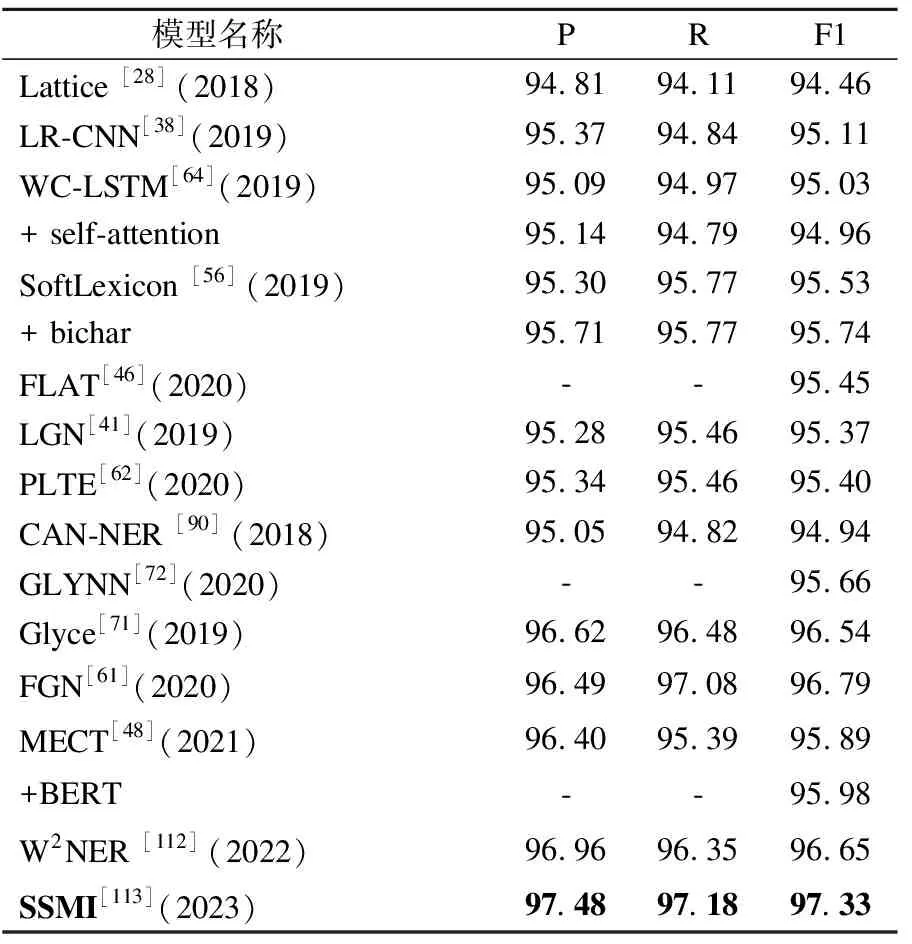
表4 数据集Resume的最新结果比较Table 4 Results on Resume

表5 数据集Weibo的最新结果比较Table 5 Results on Weibo

表6 数据集 MSRA的最新结果比较Table 6 Results on Weibo MSRA
6 挑战与展望
随着技术的飞速迅速,各种先进的模型不断被提出,然而目前依然面临诸多问题,如命名规则多样化、分类嵌套模糊以及非正式文本和未登录词等,仍需要不断地研究.总的来说,目前的NER任务仍处于向上发展的阶段,CNER是在英文的基础上,根据自身的语言特性衍生出了一套独特的处理体系.相比之下识别难度更大,但随着深度学习技术的不断发展识别精度也逐渐上升.但依然面临诸多挑战.比如:
1)数据标注问题
在基于监督学习的NER系统中,数据标注工作至关重要,因为标注任务不仅非常依赖领域知识而且相当费时费力,特别对特定领域来说更是挑战巨大.语言本身的多义性使标注质量和一致性很难得到保证.而且每个实体都不是采用通用的类型进行标注,可能存在多种标注规范.
2)实体嵌套问题
在NER任务中,嵌套实体非常普遍,不管是数据标注工作还是实体识别任务相较于普通实体而言都更加困难.Katiyar等人[106]指出,GENIA和ACE语料库中分别包含17%和30%的嵌套实体.在数据标注方面,还没有面向嵌套实体开发出通用的标注方案.
3)非结构化文本问题
基于结构化文本(如新闻文章)的数据集可以取得很好的实验结果.而基于非结构化的文本 (如推文、评论、用户论坛)大多面向特定领域,不仅简短而且嘈杂,相比于结构化文本更具有挑战性,如WUT-17数据集,最好的F1值略高于40%.但在很多应用场景中,NER系统往往需要处理很多非结构化文本,如电商平台用户评论等.
4)未登录词问题
对分词系统而言,识别不在词表和训练语料中的词常困难,一般的做法是系统中集成一个新词发现模块来挖掘新词,经过验证后才会加入到词典中,即便如此,对未登录词的识别并不理想.
基于以上的挑战,未来的研究工作可以从以下方面展开:
1)更细粒度的NER
目前的研究工作过于聚焦一般领域的粗粒度NER上,以至于忽略了对特定领域细粒度NER的究.相比之下,不同粒度包含不同的实体类型,显然细粒度NER有更多的实体类型并且不同实体类型会带来更多的复杂性问题.这需要重新定义NER的处理方法,其中将边界检测和实体类型识别解耦成两个独立的子任务是不错的解决方案.
2)结合实体消歧的NER
现有的研究大多将NER和实体消歧视为流水线环境下的两个独立任务.因为实体消歧不仅有助于成功检测实体边界而且对实体类型的正确分类也有帮助,所以如何有效的将实体消歧和NER任务结合在一起是一个值得探究的方向.
3)能处理非结构化文本的NER
基于深度学习的NER模型在非结构化文本中的性能很差,这驱使研究人员在该领域需要进行更多的研究.本文发现NER的性能显著受到外部资源可用性的影响,如地名词典的使用会提高NER在一般领域中性能,所以外部资源的辅助对NER来说是非常必要.
4)基于迁移学习的NER
将NER任务与迁移学习结合在的一起的工作很少,很多应用中都是用现成的NER系统来识别实体,但由于不同的标注方法以及语言上的差异使得模型在不同的数据集之间迁移很难得到较好的性能.为了节省人力物力,将NER任务与迁移学习结合是一个不错的研究方向.
7 结束语
本文主要介绍了基于深度学习的CNER相关模型、数据集、评价标准及性能.首先,对该领域已有的方法进行了系统归纳,并提出了系统的分类方法.然后讨论了CNER任务相关的数据集,对4大公用数据集进行重点解读.最后,分析了模型的评价标准及性能并深入探讨了中文命名实体识别任务存在的挑战和展望.期待能有更多研究人员参与到CNER的研究工作中,也希望本文能对CNER的研究有一些参考价值.
