融合用户评论和异构图神经网络的景点分类
2023-09-06李山山郭景峰张丽艳
李山山,郭景峰,郑 超,魏 宁,张丽艳
(燕山大学 信息科学与工程学院,河北 秦皇岛 066004)
(河北省计算机虚拟现实技术与系统集成重点实验室,河北 秦皇岛 066004)
1 引 言
互联网时代,用户不只是信息的使用者,也是信息的生产者.互联网中由用户生成的内容不仅丰富了网上的信息来源和内容,也为基于数据挖掘的互联网信息服务提供了新的机遇;同时,这些数据中隐含着重要的信息,对这些数据进行有效的挖掘具有许多实际的应用价值[1-3].用户评论作为用户生成内容的重要组成部分,包含着大量用户对某一产品或者服务的观点、态度等信息.对评论文本数据的挖掘不仅可以为用户提供决策支持,还可以为商家改善服务质量提供重要的反馈.例如,电商平台对用户已购买商品的评论进行分析可以了解用户的偏好,从而为用户更精准的推荐商品[4];人们在选择某种服务时,会以该服务的评论作为参考,选择口碑较好的服务,而商家也可以针对用户评论中反应较多的方面进行相应的完善,从而为用户提供更好的服务.
在当代,游客对文化旅游愿望呈现多元需求,为满足游客需求,其中,“互联网+旅游”成为目前最优的方式.游客可以通过互联网了解景点的介绍以及属性信息,旅游相关企业也可以根据游客通过互联网产生的数据,提升旅游品质,为游客推荐其感兴趣的景点,也助推了文化旅游事业的发展.同时,“互联网+旅游”模式的产生,使得推荐系统在文化旅游业广泛应用.景点类型作为景点特征的重要体现,对景点类型进行准确划分成为景点推荐系统的关键.然而,现有景点类型划分多是基于先验知识,且人工量较大.因此,对快速且准确率较高的景点类型划分方法的探究成为必然.
基于上述情况,从旅游网站和百科网站爬取国内部分5A和4A共计183个景点介绍及评论文本等信息,利用这些信息对景点进行分类.主要贡献有以下几点:
1)从景点评论信息中提取评论主题,构建由景点名称、景点评论、评论主题3种节点构成的异质信息网络,丰富景点名称的语义表示,提高了景点类型划分的准确率;
2)应用图卷积神经网络,通过聚合邻居节点的信息获得节点的低维特征向量,根据不同类型的邻居节点和类型相同但节点不同的邻居节点对其影响力不同,将注意力机制引入构建的异质信息网络,构造异质信息网络的图注意力卷积逐层迭代规则,以获得更符合实际的景点嵌入.
3)在爬取的景点评论数据集、公共数据集AGNews和MR上分别选取经典分类模型和文献[25]中模型与本文的SGAE模型进行对比实验,结果验证了SGAE模型在分类任务上的有效性.
SGAE模型框架如图1所示.

图1 SGAE模型框架Fig.1 Model framework of SGAE
2 研究现状
旅游景点类型的划分,对人类认识和开发旅游资源具有重要的意义.目前的景点分类方法主要是根据旅游景点的属性、特点以及事物之间的关系等信息,进行景点类型的划分.本文利用能够爬取到的景点评论以及景点介绍信息,对景点进行类型划分.下面对文中涉及到的相关技术的研究现状做一介绍.
2.1 评论文本
针对用户评论文本,有许多应用场景,如,电商评论分类,邮件自动回复,各种产品或服务的推荐系统,用户满意度调查等等.评论文本作为一种非结构化数据,有着丰富的语义信息,如何从用户评论中挖掘出有价值的信息,成为社会各界研究的热点[5,6].文献[7]分析数字银行评论,利用LDA构建主题模型,探索用户关注的问题,挖掘数字银行功能与审查分数之间的关联规则,为数字银行应用程序提供了优化方案,提高了用户满意度;文献[8]通过分析电影评论,利用TF-IDF模型生成文本TF-IDF矩阵,构建支持向量机(SVM)模型,并用隐含语义索引技术对标记过情感极性的影评文本进行主题建模.通过提取评论主题,对电影评论进行正负情感分类,分析观影者对电影整体的情感变化.
利用景点的评论信息构建异质信息网络,丰富景点名称的语义信息,以此种方式对景点进行类型划分的工作目前较少.
2.2 图卷积神经网络
近几年,将深度学习应用于图的分析成为各领域的研究热点.如,Wu等[9]提出了一种新的基于图卷积网络的社交垃圾邮件检测模型,该模型通过考虑3种类型的邻居节点来操作有向社交图,并在两个真实的数据集上进行评估,结果优于最新的方法;对蛋白质之间接触面的预测在药物发现与设计中有着重要的实际意义,Alex Fout[10]等根据蛋白质的三维结构构建图网络,通过在感兴趣节点的部分邻域上执行卷积,学习节点的有效潜在表示,实验结果证明基于邻域的卷积方法得到了最优的性能;知识库补全旨在预测知识库中缺失的信息,Hamaguchi[11]等利用测试时提供的有限辅助信息,使用图神经网络(GraphNN)计算知识库外实体的嵌入,在WordNet数据集上检验了模型的先进性.
2.3 网络表示学习
将深度学习应用于图数据领域,其中,具有代表性的研究工作是网络表示学习[12](Network Representation Learning),也称图嵌入(Graph Embedding),主要过程是将图数据映射为低维、实值、稠密的向量形式.图2为网络表示学习的主要流程.
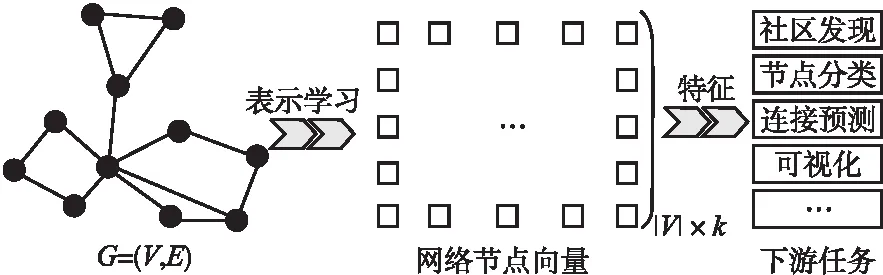
图2 网络表示学习流程图Fig.2 Flow chart of network representation learning[13]
图网络表示学习算法主要分为谱分解方法、矩阵分解法和图神经网络算法.
2.3.1 基于特征分解的方法
谱分解(Spectral Decomposition)方法主要是对网络中节点关系矩阵(主要是网络的邻接矩阵和Laplace矩阵)求解特征值以及对应的特征向量,以此达到对数据降维的目的,典型代表有:局部线性表示[14](Local Linear Embedding,LLE),该算法节点的表示由其邻居节点向量的线性加权得到;拉普拉斯特征映射[15](Laplacian Eigenmaps),该算法认为相邻节点在降维后的空间中应该很接近,节点的亲密程度由节点之间边的权重表示.
2.3.2 基于矩阵分解的方法
矩阵分解(Matrix Decomposition)法是一种常用的数据降维方法,形式简单,易于求解.对网络中节点间关系矩阵进行分解,以得到节点的低维表示.TADW[16]算法受DeepWalk算法启发,分解概率转移矩阵,使其包含文本特征,得到融合节点文本信息的嵌入.其矩阵分解形式如图3所示:T为顶点的特征,即文本信息,W和H为可训练的参数矩阵,从图3中可以看出,其损失函数中加入了文本信息矩阵.

图3 TDAW算法的分解形式Fig.3 Decomposition form of the TDAW algorithm[16]
2.3.3 基于图神经网络的方法
利用关系矩阵进行分解得到网络表示的方法,不适用于大规模网络,主要体现在两方面,一是对数据存储的能力要求较高,二是算法的运行时间开销大.然而,神经网络的出现成功解决了以上问题,受到不少研究学者的青睐,并取得良好效果.
基于随机游走策略的方法将深度学习技术引入到网络表示学习领域.其中,典型代表有Deepwalk[17]算法和Node2vec[18]算法.Deepwalk算法,从每个节点出发,得到固定长度的游走路径,作为Word2vec模型的输入,采用skip-gram最大化中心节点的上下文节点出现的概率,获取节点的向量化表示.Node2vec在随机游走过程中引入广度优先和深度优先策略,充分考虑了节点的局部空间信息和节点之间信息,将游走序列输入Word2vec模型中,得到节点表示.
此外,一些基于深度学习框架的网络表示模型相继提出.DVNE[19]针对现实中网络的不确定性,在Wasserstein空间中利用高斯分布学习每个节点的表示,以保持网络的形成和演化的不确定性.当图中节点个数发生变化,已有算法需要重新训练节点的表示,对此,Xu等[20]提出GraphSAGE模型,通过一种“聚合函数”聚集邻居节点特征来学习当前节点的表示,当有新增节点加入时,这种方法可以快速生成节点表示,无需额外的训练过程.
本文旨在通过构建异质信息网络,丰富节点语义,利用图卷积神经网络模型学习到景点名称的表示,以对其进行较精准的景点类型划分.
3 预备知识
图卷积网络大致分为两类:基于谱域图卷积(Spectral Convolution)和基于空域图卷积(Spatial Convolution)[21].谱域图卷积根据图谱理论和卷积定理,借助傅里叶变换(Fourier Transform,FT)将数据由空域转化到谱域后进行相应的操作,有较为坚实的理论基础.FT变换公式如式(1)所示:
(f*g)(t)=F-1[F[f(t)]⊙F[g(t)]]
(1)
其中,f(t)是空域上的信号,F(t)是谱域上的信号,F-1表示傅里叶逆变换,*是卷积,⊙是哈达玛乘积,表示向量或矩阵的逐点相乘.
针对图上的卷积可以由式(2)表示,为:
(f*g)G=U((UTg)·(UTf))
(2)
其中,UTg看作可学习的卷积核,记为gθ,则图上的卷积公式可以进一步表示为式(3):
o=UgθUTf
(3)
谱域上的图卷积认为gθ是可学习的参数集合,并认为图信号有多通道.谱域上的图卷积操作可以用公式(4)表示:
(4)
基于空域的图卷积神经网络,其思想来源于传统神经网络对图像的卷积操作,核心是通过聚合邻居节点的信息,以得到节点新的表示.根据节点的空间关系,直接对相邻节点求卷积.空域上的图卷积操作可以表示为式(5):
(5)
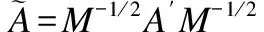
4 景点异质图注意力嵌入模型
为了通过利用用户的评论信息实现对景点的准确分类,首先要根据评论文本提取主题,进而构建异质信息网络;其次通过对异质网络的表示学习,得到景点的低维特征表示;最后利用学习到的景点特征,对景点进行类型划分.
4.1 构建异质信息网络
为获得景点名称的包含丰富语义且低维的特征表示,构建异质信息网络G=(V,E).其中,节点V={P∪C∪T},包含景点名称P=(p1,p2,…,pn)、景点评论C=(c1,c2,…,cm)、从景点评论中提取的主题T=(t1,t2,…,tr),E表示异质信息网络中节点之间的关系,如景点评论对景点的‘评价’关系.
首先,确定每条评论对应的主题个数k以及每个主题包含的单词个数θ.其次,利用LDA主题模型从景点评论中挖掘出潜在的主题t,每个主题由几个单词的概率分布表示,形式为ti=(wi1,wi2,…,wiθ),为景点评论分配相应的主题,以此建立景点评论与主题之间的关系.最后,根据与处理数据中景点名称与景点评论的对应关系建立二者之间的关系.
根据以上过程,构建了如图4所示的异质信息网络,各景点之间没有边,每个景点有多条评论,每条景点评论对应k个主题,具体k值将在实验部分给出.

图4 景点异质信息网络Fig.4 Heterogenous information network for scenic
4.2 景点网络表示学习
构建异质信息网络后,需要尽可能多的利用景点网络信息来提取景点名称的低维特征表示.为充分聚合节点的邻域信息以及网络的结构信息,利用图卷积神经网络聚合节点的局部信息以及网络的全局信息,以得到节点丰富的语义表示.
4.2.1 异质图卷积
由于GCN在卷积过程中没有考虑节点类型,因此只适用于学习同质信息网络的节点嵌入.针对景点类型划分构建的异质信息网络,不同类型节点的特征分布不同.因此,需要考虑将不同类型节点特征分布映射到同一隐式空间,再进行异质信息网络上的卷积操作,进而学习到节点的嵌入.根据式(5)结合上述分析,得出异质信息网络上的卷积运算如式(6)所示.
(6)

4.2.2 双重注意力机制
针对某一具体节点v,节点的低维向量表示由邻居节点的信息聚合而来,不同类型的邻居,对节点v的影响不同,即权重不同.在构建的景点异质信息网络中,景点名称受景点评论的影响大于评论主题的影响.此外,与节点v类型相同但不同的邻居节点对其影响也不同.同样,在构建的景点异质信息网络中,景点评论对应多个主题,但每条评论侧重描述的主题不同.基于此,论文从邻居节点类型和不同邻居节点对某一具体节点的影响不同,分别引入注意力机制(Attention Mechanism).
类型级与节点级的注意力机制的可视化如图5所示.其中,p为景点名称节点,与其直接相连的是评论文本节点c,间接相连的为评论主题节点t,用不同深浅色的背景代表对p的不同影响程度,即不同节点类型节点对p的影响程度不同.同时,为每条评论文本匹配k个主题,二者之间关系如图5左半部分,不同粗细的“连线”表示景点的评论文本侧重的评论主题不同,即同类型的不同邻居节点对某一具体节点的影响不同.
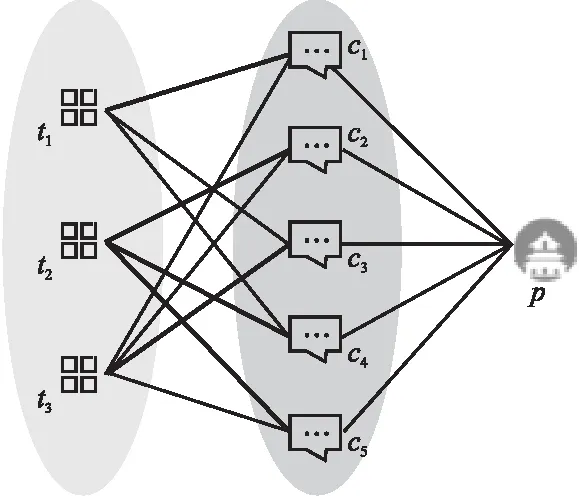
图5 可视化双层注意力机制Fig.5 Visualize two-layer attention mechanism
1)类型层注意力机制

(7)

基于当前节点v的嵌入fv以及由其τ类型邻居节点聚合得到的类型层嵌入fτ,利用式(8)计算当前类型层注意力得分.
(8)
其中,μτ是类型τ的注意力向量,‖表示向量的拼接运算,σ为激活函数,为避免神经元出现“死亡”现象,选用LeakyReLU.
然后,利用Softmax函数归一化类型层注意力得分,得到各类型层的权重,即不同类型邻居节点对节点聚合的重要性,如式(9)所示.
(9)
2)节点层注意力机制
针对节点v,计算节点层注意力可以捕获不同邻居节点的重要性同时降低噪声节点的影响.假设节点v的类型为τ,其τ′类型的邻居节点vτ′∈Nv,根据节点v的嵌入fv和τ′类型邻居节点的嵌入向量fvτ′以及τ′类型层注意力权重ατ′计算节点层权重,如式(10)所示.
bv vτ′=σ(vT·ατ′[fv‖fvτ′])
(10)
其中,v是节点层注意力向量.最后,规范化节点级注意力得分,如式(11)所示.
(11)
最后,将由包含类型层和节点层的注意力的双层注意力机制得到的节点间权重矩阵Bτ带入公式(6)中,得到引入双层注意力机制的异质图卷积网络中的逐层传播规则如式(12)所示.
(12)
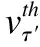
4.3 景点类型划分
根据183个景点的特征,论文将其分为3种类型.因此,针对构建的异质信息网络,将L-层SGAE模型学习到的景点名称的低维特征表示H(L),利用Softmax函数对景点名称进行分类,如式(13)所示,输出为一个三维向量,分别对应3种景点类型,将数值较大的对应的景点类型确定为该景点名称的类型.
C=Softmax(H(L))
(13)
模型训练过程中,选用L2-正则交叉熵损失函数,如式(14)所示.
(14)
其中,L是景点分类的类别,Ptrain是景点的训练集,Tij是相应的标签指标矩阵,Θ是模型的参数,η是正则化因子,‖·‖2是二范数.
5 实 验
为验证所提模型SGAE在景点分类任务上的有效性,对比实验分为两部分:一是在爬取的景点评论以及景点描述数据集上选用经典分类算法与论文算法SGAE对比;二是在公共数据集AGNews和MR上应用SGAE模型,再与已有的实验结果做对比.
5.1 景点信息数据采集与处理
从旅游网站和百科网站上爬取了全国部分5A和部分4A级景点信息以及景点的评论信息.共计景点183个,评论数据近20万条.通过对数据集预处理:1)删除对景点特征描述不明显的数据,如:景色不错,总体超赞,性价比高,有趣好玩等;2)删除重复的景点评论文本;3)删除评论中出现的特殊符号、连续使用的标点符号以及语气助词;4)删除字符长度大于150的评论文本.最终筛选出6150条评论数据.
5.2 实验设置与模型评价指标
5.2.1 对比实验所需数据集和模型
在以下真实的数据集上评估SGAE模型,数据集的统计信息如表1所示.

表1 数据集的统计信息Table 1 Statistics of the datasets
AGNews:采用了文献[22]中的数据集,并从中选取5000则新闻,平均分为4类,按照6∶2∶2的比例分为训练集、验证集、测试集.
MR:此数据集为电影评论数据集,且每条评论只包含一条由正标签或负标签标记的句子.论文采用文献[23]中的数据,并从中选取4000条数据,用于情感二分类.
5.2.2 模型评价指标
针对SGAE模型对景点分类的建模任务,选取准确率和F1值作为模型的评价指标.
准确率(Accuracy):分类正确的样本数量与总样本数量之比.
F1值(F1-Score):
(15)
其中,precision又名查准率,表示正确预测的正样本数量与实际预测为正样本数量的比值;recall即查全率,表示正确预测正样本数量与实际正样本数量的比值.
5.3 实验参数设置
对爬取的实验数据进行预处理之后,共选取183个景点的6150条评论文本,根据现有景点分类标准以及所爬取的景点特征,将景点分为3种类型.
将数据集随机分为训练集、测试集和验证集,比例为:6∶2∶2.其它超参数设置:学习率为0.0008,dropout率为0.5,权重损失率为5e-4.映射层对应不同类型节点的映射矩阵维度分别为10×512,128×512,768×512.SGAE模型的隐层大小设置为512×3.针对每条景点评论对应主题个数的确定,从图6中可以看出,当每条评论对应的最多主题个数增加时,测试集的准确率增加,当主题个数大于2时,准确率下降.因此,在构建的异质信息网络中,每条景点评论对应的主题数为k=2.

图6 评论对应k个主题的模型准确率Fig.6 Model accuracy of k topics corresponding to review
为使SGAE在测试集上取得较好的结果,分别计算主题数t=8,10,12,15时测试集的准确率以及训练集损失值,绘制如图7和图8所示的折线图.从图7中可以看出,在模型进行了50次迭代,不同主题个数的测试集的准确率均达到收敛且t=10时准确率最高;从图8中可以看出,不同主题个数对应的训练集的损失值在epoch<50以内,均达到收敛状态且t=10时损失值最低.综上,论文构建的异质信息网络中评论主题个数确定为t=10.
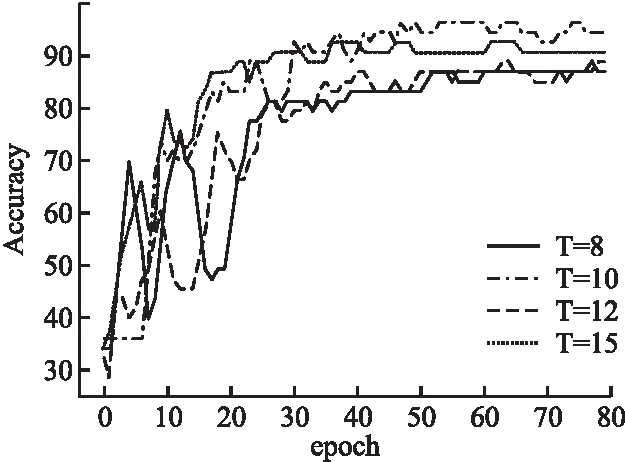
图7 不同主题个数的测试集的准确率Fig.7 Accuracy of test set with different number of topics
作为网络嵌入的重要应用之一,可视化可以更加直观地检验模型对于异质信息网络中节点特征提取的效果.为验证景点特征学习的效果与SGAE模型层数的关系,用一层和两层的SGAE,分别表示为SGAE-1和SGAE-2,学习景点的低维特征表示,并利用t-SNE[24]将低维向量映射到2维空间,图9和图10分别为SGAE-1和SGAE-2可视化的结果,不同形状代表不同的景点类型.从图9的可视化效果中看出,不同类型的景点均趋向于中心聚集,且重叠部分较多,边界不明显;然而,图10中除个别景点外,同种类型景点之间聚集度较高,不同类型景点间边界较明显.
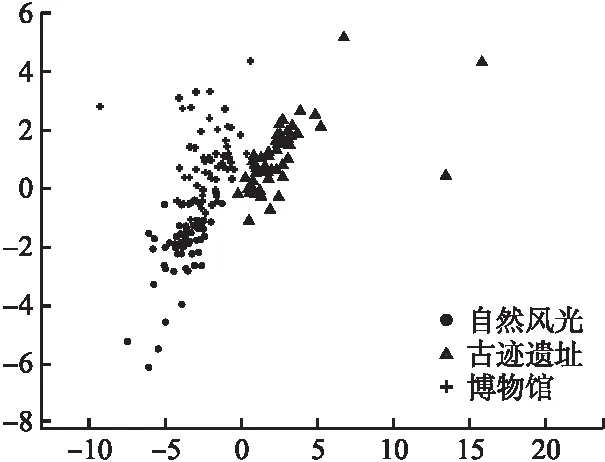
图9 SGAE-1景点可视化效果Fig.9 SGAE-1 scenic spot visualization
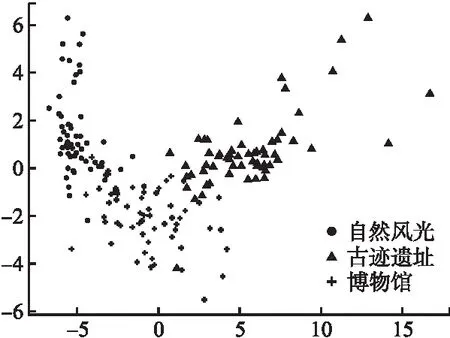
图10 SGAE-2景点可视化效果Fig.10 SGAE-2 scenic spot visualization
表2为二者在景点分类任务上的对比结果.SGAE-2在景点类型划分任务上的准确率和F1值均高于SGAE-1.

表2 SGAE-1和SGAE-2性能对比结果Table 2 Performance comparison results of SGAE-1 and SGAE-2
综合以上分析,SGAE-2的性能优于SGAE-1,即聚合2阶邻居节点信息学习到的景点特征更完备.在构建的异质信息网络中,景点的低维特征表示通过聚合景点评论和评论主题的信息得到,丰富了节点的语义信息,更好的表达了景点的特征,对于后续的研究具有重要的意义.
5.4 对比实验
在SGAE中,随机初始化各项参数并采用随机梯度下降法多模型进行优化.为保证结果的更精确,误差尽可能少,将模型运行10次的准确率和F1值取平均作为最终的模型评价指标值.
在所爬取的景点数据集上,选取经典分类算法与SGAE算法做对比,结果如表3所示,从模型的准确率和F1值两项评价指标上可以看出,模型SGAE性能均优于其他基准模型,相比于性能较好的HGAT模型在准确率和F1值分别高出5%和4%,这验证了SGAE算法在景点类型划分任务上的有效性.

表3 论文数据集对比实验结果Table 3 Comparative experimental results of paper data sets
由于SGAE模型采用的是半监督的学习方式,其学习程度受训练集中已知标签节点数量影响.表4为取不同比例的景点数据作为训练集,计算SAGE模型的Acc值和F1值.结果显示:当训练集样本数量较少时,SGAE模型的性能较低,随着训练集样本数量的增加,模型的Acc值和F1值逐渐上升,当训练集数量占总样本数量的44%时,模型性能增长趋于平缓,直到训练样本数量为66%时,SGAE模型性能仍有提升.然而,半监督学习方式在少量训练样本上取得较好效果的模型更具实际意义.综合考虑,训练集数量的最佳选择为55%的总样本.

表4 论文数据集对比实验结果Table 4 Comparative experimental results of paper data sets
表5是在公共数据集AGNews和MR上,论文所提算法与文献[25]中选取方法得到的分类准确率和F1值做对比,可以发现:

表5 AGNews与MR数据集对比实验结果Table 5 Comparison of experimental results between agnews and MR data sets
1)使用预训练的模型,CNN-pre和LSTM-pre相对于通过随机初始化的CNN-rand和LSTM-rand,在分类性能有了显著的提升.原因是预训练模块可以按照实际任务需要对词向量进行适当的预训练,且词向量在模块的训练流程中也可以实现优化.
2)基于词共现学习文本嵌入的PTE模型性能较差,原因可能是AGNews数据集和MR数据集的评论文本较短,PTE不能较好的捕获语义信息所致,而LEAM模型比PTE模型在AGNews数据的准确率和F1值均高出约82%,在MR数据集上准确率和F1值均高出约9.7%.
3)基于图卷积神经网络的TextGCN和HGCN-RN模型,准确率和F1值均较高,说明根据数据集构建的异质信息网络丰富了节点的语义表示,且GCN有效的提取了文本的特征,使得分类性能有所提升.
4)SGAE模型的性能明显高于所有基准模型,相比于分类效果较好的HGCN-RN模型,在AGNews上的准确率和F1值分别提升了1.95%和1.98%,在MR上的准确率和F1值分别提升了3.92%和6.96%.
综上,SGAE模型在根据数据特征构建的异质信息网络中,可以充分的聚合邻居节点信息,有效学习了节点的低维特征表示,对节点短文本分类中的有效性.
6 总 结
根据不同类型节点间关系构建的异质信息网络,在丰富节点语义的同时,充分挖掘了节点的潜在特征.从爬取的景点评论中提取出评论主题,构建包含景点名称、景点评论和评论主题3种类型节点的异质信息网络,有效的提取了景点名称的特征,提出了适用于景点分类的SGAE模型,在爬取的景点数据集和公开数据集AGNews和MR上分别与经典分类模型和文献[25]中的模型做对比,结果显示,SAGE模型提升了图神经网络的分类性能.
接下来,将进一步在更多数据集上以不同的任务验证模型的有效性,以及从景点类型多分类的角度继续探索.
