基于类原型与深度学习的类注释生成方法
2023-09-06李睿赵逢禹刘亚
李睿 赵逢禹 刘亚

关键词:代码注释;类注释模板;类原型;双编码器;深度学习
中图分类号:TP311 文献标志码:A
0 引言(Introduction)
在许多软件系统中,代码源文件的注释经常出现不完整、过时甚至缺失等情况,对这些系统代码进行维护与完善时,开发人员需要花费大量时间理解代码[1]。当代码内部有较准确的注释文本时,开发人员可以通过浏览注释文本快速理解相关代码片段的含义,从而节省维护时间,提高维护质量。
自动代码注释生成技术是用于提高代码可读性和可维护性的有效方法,目前针对代码注释自动生成的研究大致分为以下两类:基于模板的注释自动生成和基于深度学习的注释自动生成。基于模板自动生成的代码注释可读性较高,但缺乏对具体代码结构信息的获取能力,而基于深度学习的代码注释生成研究大多应用于方法粒度,对于复杂的类结构的注释生成比较困难。
针对上述两类自动代码注释生成技术存在的问题,本文结合模板与深度学习技术,提出一种为类自动生成注释的方法,首先确定当前类所属的类原型,并选择对应类注释模板,提取类中的信息填充到模板中,其次针对类中方法的注释生成问题,提出构建一种基于注意力机制的双编码器模型,实现代码到注释的映射,最后通过实验验证了本方法的可行性与实际应用效果。
1 相关研究(Related research)
基于模板的注释生成方法,首先需要预定义一组启发式规则,其次提取代码的关键信息并通过启发式规则生成自然语言描述。HILL等[2]提出一种基于软件单词使用模型(SoftwareWord Usage Model,SWUM)分析Java方法签名的方法,为Java方法生成自然语言注释。SRIDHARA等[3]在HILL等研究的基础上进一步考虑了方法体内含有的代码,提出一种基于启发式规则的方法为方法代码生成注释,该方法主要分为内容选择和注释生成两个阶段。MORENO等[4]将关注的代码粒度从方法级别提升到类级别,首先确定类和方法的原型,其次通过结合原型信息与预先定义的基于方法和数据成员访问级别的启发式规则,并通过现有的文本生成工具对Java类生成描述性摘要。基于规则模板生成的代码注释容易理解,但受限于模板只能为特定的代码结构生成注释,对于模板之外的代码无法灵活地生成有效的代码注释。
基于深度学习的注释生成方法通过神经网络对代码中包含的信息进行挖掘,得到其特征向量表示,并通过模型进行训练,最终得到自然语言描述。目前,大量的研究主要采用神经机器翻译(Neural Machine Translation,NMT)模型,通过提取不同的代码特征信息,使用不同的神经网络结构进行训练得到代码注释。IYER等[5]率先将深度神经网络引入自动代码摘要研究,提出代码-描述嵌入神经网络(Code-DescriptionEmbedding Neural Network,CODENN)方法,在长短期记忆网络(Long-Short Term Memory,LSTM)的基础上通过引入注意力机制构建一个端到端的学习网络,从而自动生成代码摘要。HUANG等[6]采用门控循环单元(Gated Recurrent Units,GRU)作为编码器和解码器,并为代码块生成注释,GRU是对LSTM网络的一种改进,能够保留较长的上下文信息[7]。CAI等[8]提出使用树形长短期记忆网络(Tree-LSTM),通过引入语法类型信息对程序代码进行结构化编码,并在解码时采用多种策略对抽象语法树的节点进行筛选,最终生成代码注释。基于深度学习的自动代码注释方法可以较灵活地为代碼片段生成注释,在面对复杂程序代码时,仍然具有良好的结构学习能力,但目前大多只应用于方法粒度,针对类粒度的代码片段无法生成较为全面的注释。
2 类注释生成方法(Class annotation generationmethod)
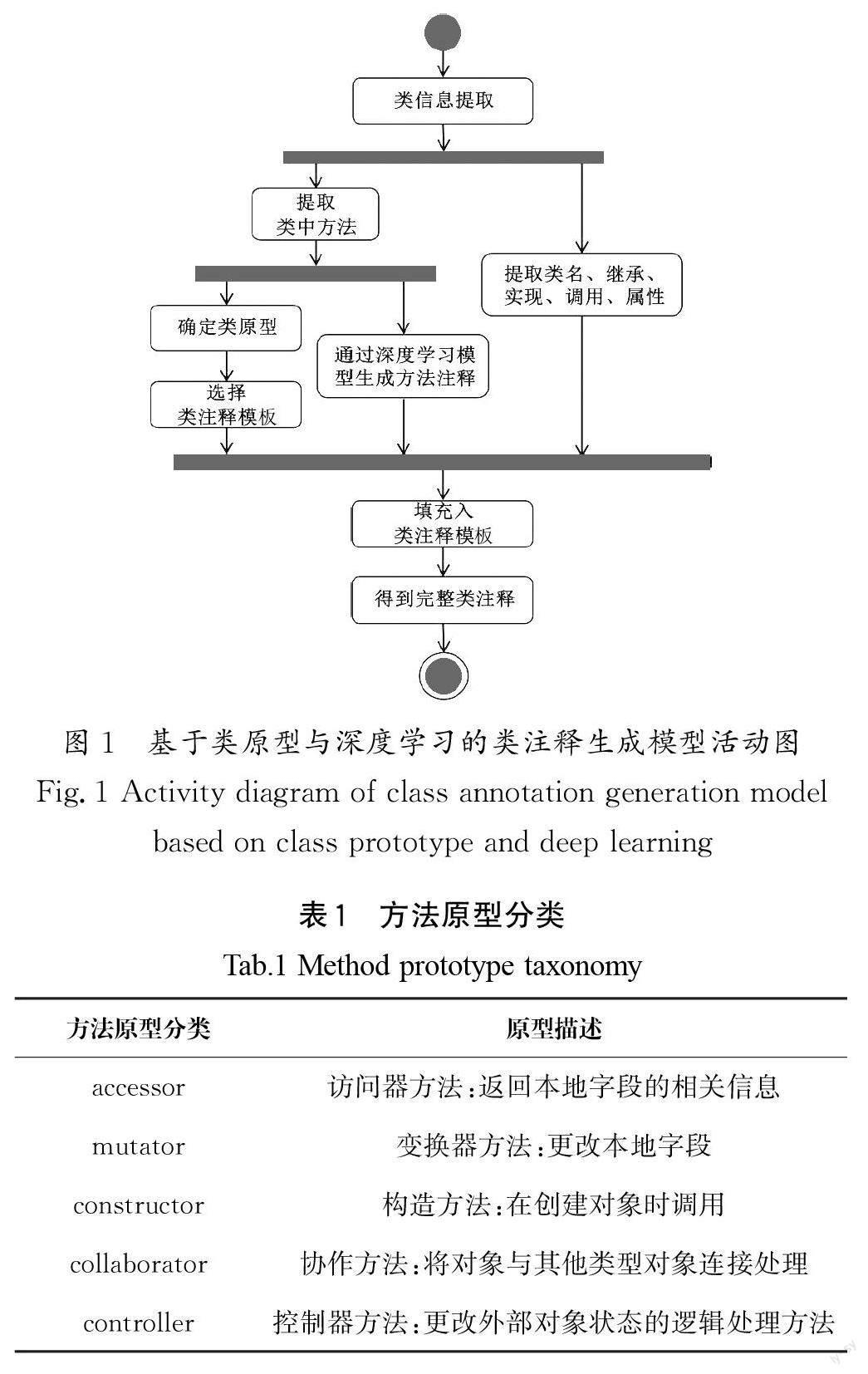
本文提出的基于类原型与深度学习为类生成注释的方法活动图如图1所示,主要包括以下几步:第一步,提取类中方法,确定类中方法原型,并通过类中方法原型的分布确定类原型;第二步,为不同的类原型选择不同的类注释模板;第三步,针对类注释模板中各部分的信息设计相应的提取规则,并将提取到的信息填充到类注释模板中;第四步,对于类中的主要方法通过深度学习模型得到方法注释,将方法代码注释填充到类注释模板中,得到完整类注释。
2.1 类原型分类
类原型是项目设计中类的角色和责任的简单抽象,开发人员可以通过类原型较快地了解类在系统中的一般职责。在软件的维护和发展过程中,对类原型的准确描述是必要的,STARON等[9]验证了类原型信息在程序理解任务中的有效性。本文首先对类的原型进行识别,确定类的职责,其次为不同的类原型选择不同的类注释模板。
目前,在类与方法的原型识别领域已有大量研究,文献[10]首先提出了一种方法原型的自动识别技术,并给出了方法原型的分类法;文献[11]在此基础上提出一种根据方法原型分布确定类原型的方法,并给出了类原型的分类法。为了构建符合类职责的注释模板,本文参照文献[11]对方法原型和类原型的分类方法进行重新定义,将方法原型分类为5类,类原型分类为4类,其中方法原型分布是类原型分类的重要特征。表1给出了本文定义的方法原型分类及原型描述,表2中给出了本文定义的类原型分类、原型描述及分类规则。
在表2的类原型分类规则中,acc 表示类中访问器类型方法的数量,mut表示类中变换器类型方法的数量,con 表示类中构造方法的数量,col 代表类中协作方法的数量,cont 表示类中控制器类型方法的数量,mtd 表示类中方法的总数。
2.2 类注释模板
不同类原型代表不同的职责,代码注释主要关注的信息也不同,例如Entity类型代表实体类,重点关注继承关系、类中属性以及类在项目中的使用情况,由于Entity类中方法大多数为访问器、变换器及创建方法,因此不需要对类中方法进行注释;Boundary类型代表边界类,多用于与其他类进行通信,因此重点关注类在项目中的使用情况和类中方法的功能;Controller类型代表控制类,主要负责处理外部对象数据,重点关注继承关系、实现关系、类在项目中的使用情况和类中方法的功能。受篇幅限制,本文以Controller类原型为例,展示其注释模板(如表3所示)。
2.3 类中信息提取规则
表4给出了类注释模板中各部分注释内容的提取规则。首先,通过代码抽象语法树(Abstract Syntax Tree,AST)结构提取父类、接口的实现类和类中属性;其次,在项目中进行代码搜索提取其子类及该类在其他类中的使用情况,将上述信息填充到预定义的类注释模板中。类中方法是类功能的具体实现,类中方法的注释生成是类注释的难点。针对这一问题,本文首先识别类中的主要方法,对主要方法使用深度学习的技术建立方法代码到代码注释的映射模型,通过该模型获得方法代码的注释并填充到类注释模板中,最终获得完整的类注释。
3 基于注意力机制的双编码器方法代码注释生成模型(A model for code annotation generation inbi-encoder method based on attention mechanism)
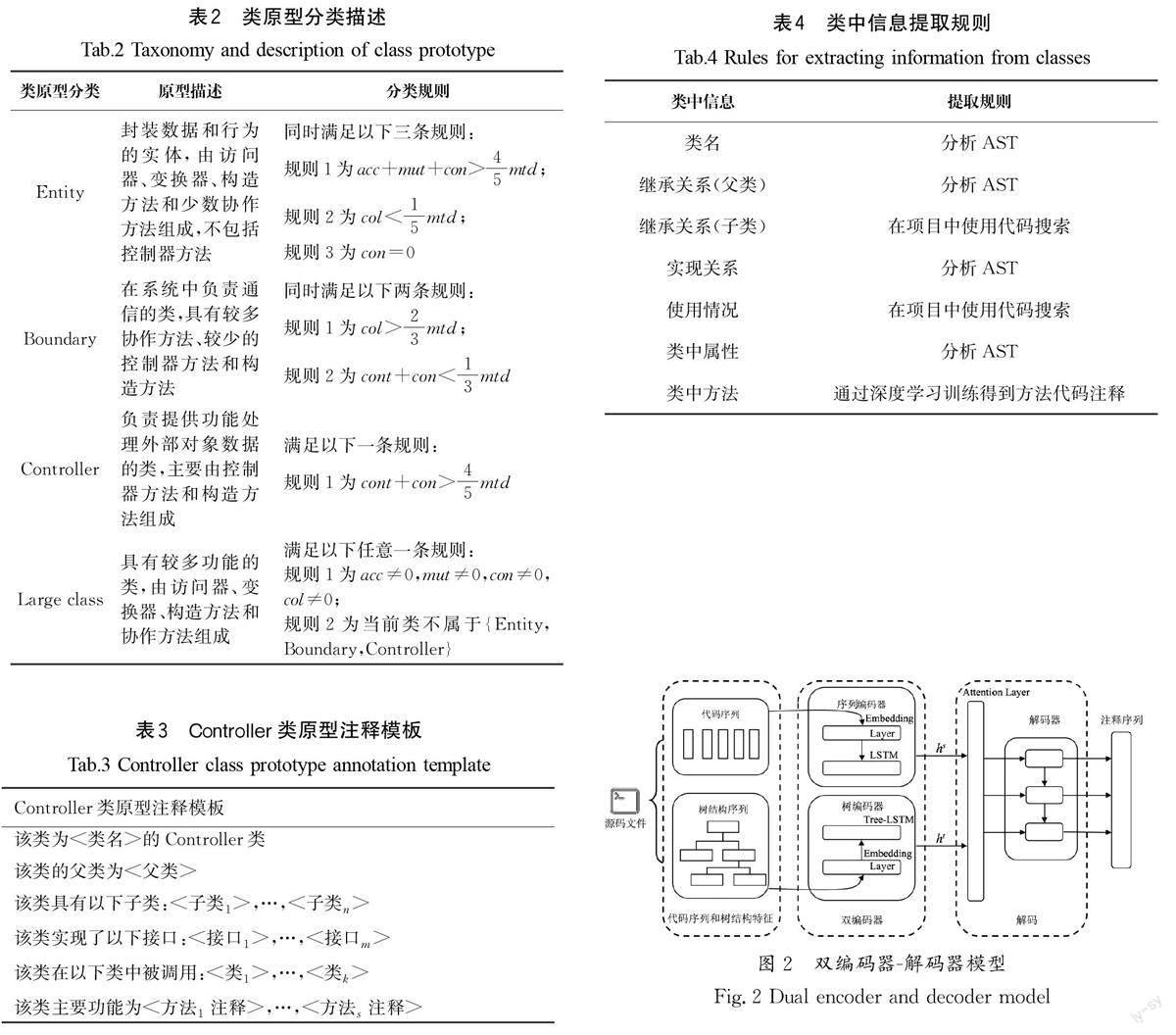
由于方法代码结构复杂,包含较多的序列信息和结构信息,因此仅使用预定义规则提取,无法为方法代码生成较为准确的注释,而深度学习可以捕捉代码的结构信息,并可以通过大量训练得到从代码到注释的映射,本文使用深度学习技术为方法代码生成代码注释。本文在經典编码器-解码器模型的基础上,提出了一种双编码器-解码器的方法代码注释生成模型,其中双编码器包括一个序列编码器和一个树结构编码器,图2展示了该模型网络结构。该模型首先对数据进行预处理,在源码文件中提取以方法为粒度的代码,构建算法提取代码序列和代码抽象语法树结构信息;其次分别将代码序列和抽象语法树序列的向量表示输入各自对应的编码器中进行训练;最后经过注意力机制关注解码重点,将序列向量和抽象语法树向量进行拼接后,由解码器解码得到方法代码注释序列。
3.1 序列编码器
在经典编码器-解码器模型中,编码器通常使用循环神经网络(RNN)按照时序提取代码序列特征,据目前已有的研究可知,当序列较长时,基于递归机制的RNN可能存在梯度消失或者梯度爆炸问题。GERS等[12]提出了一种长短期记忆网络(LSTM),相对于RNN而言,LSTM在处理长序列数据时表现更为出色。因此,本文选择LSTM 作为双编码器中的序列编码器处理代码序列信息。
为了构造序列编码器中的输入方法代码序列,首先利用Antlr4语法分析器生成工具将方法代码转化为抽象语法树(AST),其次对方法AST进行前序遍历,组成代码序列。算法1给出了提取方法代码序列的算法。
通过自底向上的遍历,最终获取根节点的输出作为树编码器的输出,在图2中通过结构向量ht 表示该向量。
3.3 解码器
本文采用融合注意力机制的LSTM 作为解码器,首先将序列编码器输出的序列表示向量hs 和树编码器输出的结构表示向量ht 分别通过注意力机制进行加权求和重新计算权重。其次将注意力机制筛选后的向量进行拼接,得到综合编码向量作为解码器的输入向量。至此,解码器就同时融合了代码的序列信息和结构信息。
4 实验结果与分析(Experimental results andanalysis)
为了全面评估本文提出的基于类原型与深度学习为类自动生成注释的方法,将从以下两个方面进行实验验证:一是评估本文提出的基于注意力机制的双编码器方法代码注释生成模型的性能;二是评估本文提出的结合类原型与深度学习的类粒度注释生成的准确性。
4.1 数据集
本文采用文献[14]提供的Java-med数据集进行实验,该数据集收集于软件项目托管平台GitHub,包括1 000个Java顶级项目。该数据集包含约400万个方法,涵盖模型需要的源代码信息和注释信息。本文将数据集按照8∶2的比例划分训练集和测试集,其中训练集用于训练双编码器-解码器模型,测试集用于评估双编码器-解码器模型性能及Java类注释生成效果。
4.2 评估指标
本文从两个方面评估本文提出方法的应用效果。对于方法代码注释自动生成的双编码器-解码器模型的评估问题,采用BLEU[15]、ROUGE[16]和METEOR[17]评估生成方法代码注释的质量,这些指标广泛应用于机器翻译领域。其中,BLEU表示生成句子和真实句子的相似程度,更侧重于准确率,本文选择其中的BLEU-4作为评估指标;ROUGE与BLEU类似,但更加关注召回率,ROUGE-L基于生成句子和真实句子的最长公共子序列共现统计召回率和准确率;METEOR引入了同义词匹配,在计算得分时考虑了词性变换和同义词的情况。三种机器翻译性能评估指标与生成的自然语言注释质量呈正相关。
针对类粒度注释的准确性与完整性评估问题,由于类粒度注释生成的相关研究与通用数据集较少,因此本实验采用具有Java软件领域开发经验的工程师对类注释进行人工方式的准确性评估。
4.3 实验结果分析
4.3.1 方法粒度的注释生成模型性能对比
本文提出的双编码器-解码器模型基于Python编程语言和PyTorch深度学习框架实现,在训练过程中,使用Adam作为优化器,初始学习率设置为0.001。其中,双编码器和解码器均具有两个隐藏层,隐藏状态设为256维,嵌入单词的维度也设为256维。
为了评估本文在方法粒度的注释自动生成中提出的双编码器-解码器模型的有效性,选用方法注释生成领域中常见的注释生成模型进行实验对比。
(1)Seq2Seq模型+注意力机制[5]。Seq2Seq模型将源代码序列信息输入LSTM中进行编码,引入注意力机制,最终由解码器进行解码获得注释。
(2)Code2Seq模型+注意力机制[14]。Code2Seq模型通过使用抽象语法树中组合路径的集合表示代码片段,使用BiLSTM作为编码器,并在解码时使用注意力机制选择相关的路径最终解码获得注释序列。
(3)Tree2Seq模型+注意力机制[18]。Tree2Seq模型使用Tree-LSTM作为编码器,将源代码转化为抽象语法树结构,使用编码器自下而上递归对AST节点进行编码,然后由基于注意力机制的解码器进行解码。
表5展示了4种模型在选定的Java数据集上的实验评估结果对比。从表5中可以看到,本文提出的双编码器-解码器模型的BLEU-4分数达到35.2,并且在各项指标上均优于其他三种对照方法。相对于其他三种模型,本文模型既融合了代码的序列信息,又融合了代码的结构信息,同时引入了注意力機制(Attn),能充分地获取代码信息,进而提升了注释生成效果。
4.3.2 类粒度的注释生成性能评估
为了评估本文结合类原型与深度学习生成类注释的性能,从类原型识别的准确性及类注释的准确性两个方面进行评估。首先在测试数据集中选择部分类,通过人工识别方式进行类原型分类;其次使用本文提出的类原型识别方法对这些类进行原型识别。从表6可以看出,本文提出的类原型识别规则能较准确地识别类的原型。
为了评估生成类注释的准确性,评估者阅读选定类的主要功能和结构并给出对相应类的注释描述,然后与本文生成的类注释进行对比。表6展示了对不同类原型的类注释准确性的评估,评估者认定当类原型为实体类和边界类时,本文方法能较准确地生成符合该类职责的注释,对于类中方法数量较少的控制类能够较为准确地描述类的使用情况,但对于类的功能描述信息较少,对于大类(Large class)能较为准确地描述类中具体方法的功能,从而反映类的功能。
4.4 示例展示
本文首先通过确定类的原型选择类注释模板,其次提取类中信息填充到模板中,最终生成完整的类注释,表7展示了实验中类原型为Controller类最终生成的类注释结果。
5 结论(Conclusion)
本文通过结合类原型与深度学习技术,提出一种为类生成注释的方法,首先通过确定类原型选择类注释模板,其次提取类中的信息填充模板,对于类中的方法使用带有注意力机制的双编码器模型训练后得到方法注释,最终得到完整的类代码注释。实验表明,本文在方法粒度中提出的双编码器模型在性能和效果上优于对比模型,完整的类粒度的注释经人工评估后确定具有较高的准确性。未来,可以结合信息搜索以及其他深度学习方法,融合更多的代码信息与注释文本,进一步提高自动生成类注释的质量。
作者简介:
李 睿(1999-),女,硕士生。研究领域:自然语言处理,深度学习。
赵逢禹(1963-),男,博士,教授。研究领域:计算机软件与软件系统安全,软件工程与软件质量控制,软件可靠性。
刘 亚(1983-),女,博士,副教授。研究领域:信息安全,密码学。
