基于人工智能技术的语言障碍评估初探
2023-09-05张小恒
张小恒
(重庆开放大学,重庆 400052)
语言障碍人群是指在语言产生或理解过程中存在障碍的特定人群,这类人群通常包括失语症患者、自闭症患者、口吃患者、听觉障碍患者、阿尔兹海默症患者、帕金森症患者等,涉及的人群从儿童到老年人都有[1],数量十分庞大。据相关数据统计,约10%的学龄前儿童存在不同程度的语言障碍。中国人口老龄化趋势明显,据估计,我国已有600~700万的阿尔兹海默症患者,其最典型的表现是认知障碍和语言障碍。中国约有1 300万人深受口吃之苦,且脑外伤、脑炎、帕金森、退化性疾病等均会导致语言障碍。
一、传统方法
由于语言障碍人群大都存在一定的生理缺陷,前期的评估一般多从患者的以往病史、行为及体格检查入手。例如,记录患者目前的语音情况;了解患者的认知、运动、社交和基本行为情况;检查患者的发声器官是否有异常;观察患者的手眼协调、注意力等。对于部分存在听觉障碍的人群,医护人员还要对其进行听力测试,了解其听力情况[2]。
目前,语言能力评估主要通过制定语言能力等级量表实现,国内已有《汉语失语症成套测验》[3]《汉语标准失语症检查量表》《汉语语法量表》[4-5]等。近年来,北京语言大学和美国西北大学在西北命名成套测验和西北动词语句成套测验的基础上,结合现代汉语语音、词汇、句法和语义特点以及中国人的认知心理,联合研发了适用于汉语母语者的失语症语言能力评估成套测验,于2017年3月制定了《中国失语症评估量表》[6]。这些传统方法已能覆盖大部分语言障碍人群,但仍存在如下不足:主要依靠测试员按照评估量表进行人工打分,存在主观的理解及评估差异;评估结果不客观,评估效率低下;成本高,且远程评估应用无法实施。
二、人工智能方法
人工智能技术在语音信号处理和自然语言处理(NLP)上已日趋成熟,将其用于语言能力评估可最大限度地排除人为主观因素,更加准确客观。因此,本文提出基于人工智能技术的语言能力评估的基本方法,如图1所示,包括训练和测试两个阶段。训练阶段的步骤如下:首先,进行传统量表评估准则的人工智能评估转换,将评估量表中模糊主观的人为评价准则转化为语音语言客观可量化的依据,然后收集大量语音障碍人群的原始语料(原始语音及对应识别的语言文字等),从语音的层次对语言障碍人群进行语音样本特征提取,并结合转化后的评估量表中的语音评估依据对测试人群的语音样本进行标签化,建立人工智能语音模型。其次,从语言的层次对语言障碍人群的语言进行NLP处理,并结合转化后的评估量表中的语言评估依据对语料语句进行标签化,建立人工智能语言模型。最后,基于已训练的语音模型和语言模型,建立语音语言相融合的联合预测评估模型。在测试阶段,医护人员用联合预测评估模型对训练语料之外的语言障碍人群的语音语言进行测试,得到评估等级。
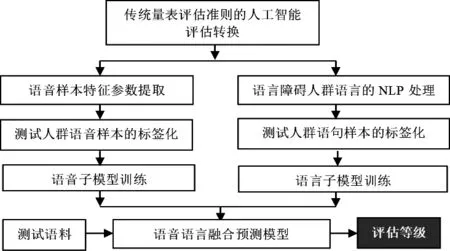
图1 基于人工智能技术的语言障碍评估方法流程
(一)传统量表评估准则的人工智能评估转换
首先,医护人员要对语言障碍人群语言能力评估的常规方法进行全面总结,对语言障碍人群的各个细分人群评估量表进行研究,从大量标准中挖掘出一般性分析方法,进一步实施基于人工智能技术的语言障碍人群语言能力评估。基于人工智能技术进行评估需要建立在传统评估量表的基础之上,因此,我们需要将量表中的主观描述性语言转换成客观判据。如描述构音障碍的“模糊含糊,吐词不清”等可以转换为语音的具体参数进行量化,而描述患者语言语法结构问题或语音逻辑问题的描述性语言可以转换为NLP中的相关指标进行判决。
(二)语音样本特征参数的提取及分析
这个阶段主要针对的是构音障碍。构音障碍人群的发声系统大都已经发生病变,因此,我们要自动化提取含有畸变信息的特征参数,并将这些特征参数的取值范围与语音清晰度有效对应起来。只有这样,智能化评估语音质量才有可能。
1.语音预处理
我们要构建多类型特征的特征提取估计模型,设计形如稀疏矩阵的优化因子对该模型进行全局优化,并设计以优化因子为未知变量的适应度函数,将适应度函数代入到进化算法(如遗传算法、粒子群优化算法及蚁群算法)中进行搜索,得到最佳优化因子,提高多类型特征在噪声环境下的提取精度。
2.特征参数提取
反映语音障碍的特征种类繁多,通用特征如基音周期(pitch)、梅尔频率倒谱系数(MFCC)、线谱频率系数(LPCC)、伽马通滤波器倒谱系数(GFCC)、PLP(Perceptual Linear Prediction,感知线性预测器)、DCT域特征、小波域特征等。专用特征包括频率微扰(Jitter)和幅度微扰(Shimmer)两类。频率微扰(Jitter)又可分为local、absolute、rap、ppq5、ddp五种测度方式。幅度微扰(Shimmer)又可分为local、dB、apq3、apq5、apq11、ddp六种测度方式。此外,反映语音障碍的特征还有脉冲数、周期数、基音周期平均、基音周期标准差、清音帧占比、语音中断的次数、谐波信噪比(HNR)等。通常情况下,单一的语音特征参数无法反映语音全貌,我们还需要对多个特征参数进行选择、组合及变换。
3.特征参数选择
早期,C Okan Sakar等人手动选择语音特征。后期,特征选择方法逐渐多样化,如通过主成分分析(PCA)、线性判别分析(LDA)、神经网络方法(NN)进行特征选择。
4.特征参数组合变换
我们要对特征集中的各通用特征和专有特征进行对应的组合计算,包括加、减、几何平均、算术平均、模等运算,形成新的特征集,该特征集则为多类型特征集。我们要对特征集进行组合计算,合并成一个新的特征集。该特征集中每个特征的值构成了一个特征向量,该特征向量即为该待检者所对应的特征向量。我们重复以上操作,提取完所有待检者的多类型特征向量,构成一个特征矩阵。
(三)语言障碍人群语言的NLP 处理
这个阶段,我们主要针对语言的语法及逻辑问题,收集整理语言障碍人群的预料进行NLP技术的处理。
1.常见语法逻辑错误
语法问题分为句法成分搭配不当、句法成分残缺、词语位置摆放不当几类。其中,句法成分搭配不当包含主谓不搭、述语和宾语不搭、修饰语和中心语不搭等;句法成分残缺具体表现为主谓宾及虚词的残缺;词语位置摆放不当具体表现为修饰、语序及介词使用不当,以及句法成分杂糅、代词指代不明及数量混乱等语法错误。
2.语言障碍人群的语法逻辑问题
语言障碍人群大脑中的语言功能区会发生不同程度的病变,导致语言障碍人群在说话时易出现严重的语法逻辑错误。然而,文化水平不足的人群也可能出现语法逻辑错误。因此,我们不能将对语言障碍人群语言的判断与语法的识别同等看待。目前,如何进行有效区分并没有严格的界限。从主观感受上讲,语言障碍患者的语言存在可懂度极低、不连贯断续等问题。从经验上看,我们一般可以将语法逻辑问题是否严重影响语意的表达作为衡量是否存在语言障碍的标准。
3.语言的NLP技术处理
通常情况下,语言障碍人群的语料以音频格式存在,如果要进行后续处理,我们需要将其识别保存为文字语料。现有成熟的语音识别工具可使用科大讯飞和百度公司的相应产品,特别是科大讯飞作为语音识别领域的头部企业,可使普通话及方言的识别准确率达到98%以上。随后,我们要对文字语料进行NLP处理,包括分词处理、词性标注、语义及句法分析等。进行NLP处理的相关工具比较多,如使用jieba进行中文分词、使用word2vec进行词向量的转换等。
(四)测试人群语音语言样本的标签化
标签化最终需要实现的目标是将评估量表中的主观描述语句进行有效分解,并将其与语音语言的客观特征进行有效对应,从而使标签化更加合理。
1.测试人群语音样本的标签化
能够使用机器学习或深度学习等人工智能技术分析患者语音数据的前提是需要大量的标签化训练数据,因此,我们要收集大量语言障碍人群的语音,并为这些语音样本打标签。语言障碍人群在语音上的障碍主要表现为声带等发声器官病变导致的构音障碍。因此,我们可以从语音角度将语音清晰度分为不同等级,并进行标签标注。
2.测试人群语言样本的标签化
我们可以从语言的语法结构角度将语言障碍进行具体分类。语言障碍主要表现为语言障碍人群的大脑语言中枢受损,导致言语表达出现中断、字词重复、音调异常、明显逻辑混乱或者完全无法表达完整语意等情况。考虑到不同的患者由于患病严重程度的不同,语言能力也会存在差异,以及同一患者在不同时间段及不同语义上会呈现一定语音能力波动变化,这一步的标注工作需要大量有经验的评估人员完成,并对大量语料的语音能力等级进行划分,如划分为轻微、中度、严重三个等级。目前没有公开的已进行语言能力标注的语言障碍人群公共语料库,导致语言样本标签化是整个研究过程中工作量最大、最耗时的一个阶段。
(五)语言障碍人群人工智能评估子模型训练
1.语音子模型训练
语音模型的构建方式有很多,以二分类为例,我们将采集好的受试者语音信息视为训练语音库,并将受试者分为健康组和患者组,从中提取多类型特征向量。健康组的标签为0,患者组的标签为1。随后,我们可以构建二分类模型。我们可采用支持向量机(SVM)、邻近算法(KNN)、随机森林(RF)等机器学习方法,也可以采用深度神经网络(DNN)、卷积神经网络(CNN)等深度学习模型。如果语音样本的数据量不大,机器学习模型往往优于深度学习模型。从工程效率角度进行考虑,SVM特别是线性SVM的计算复杂度最低。
2.语言子模型训练
语言模型的构建通常会考虑语句中的词语搭配及前后的逻辑关联性,因此,更多使用循环神经网络(RNN)、长短期记忆网络(LSTM)等连续时间依赖性的深度学习方法。我们通过分词、词向量等处理过程将语料库转化为矢量样本库,并将受试者分为健康组和患者组。健康组的标签为0,患者组的标签为1。随后,我们构建了稳定的LSTM模型。同理,如果要构建多级(如5级)语言障碍评估模型,我们可以将二分类标签数据进行进一步细化,设置0、1、2、3、4等多个等级标签。因为深度学习模型的优劣在很大程度上取决于语料库规模,所以我们收集大规模的患者语料十分重要。
3.语音语言模型融合预测评估
语音模型和语言模型构建完成后,将其进行有效融合是构建完整的语言障碍人群人工智能预测评估模型的关键。不同的语音障碍患者在构音障碍方面及语音逻辑方面的严重程度并不完全相同,且同一个语音障碍患者在不同语料上的严重程度也不同。因此,相对简单有效的方法是给语音和语言设置不同的权重,并将其进行加权融合,再进行有效预测评估。联合预测模型权重及语音语言子模型参数通过在训练过程中达到最佳训练准确率得到,但训练准确率的高低并不能直接决定联合预测模型的性能是否优良。
(六)语料测试
得到语音语言联合预测模型后,我们需要输入训练语料集之外的测试语料进行测试,以检验模型的性能。我们通过预测可以得到语音能力等级,并将其与专家通过量表进行打分的语言能力评估等级进行比较,得到测试准确率。如果测试准确率不高,或者需要进一步提升性能,我们可以调整联合预测模型的超参数,再进行测试。
三、结论
本文提出了基于人工智能技术进行语言能力评估的系列方法步骤,包括对语音样本进行特征提取、标签化、模型化;对语言样本进行NLP技术处理、标签化、模型化;构建语音语言联合预测模型。笔者希望本研究能为目前的语言障碍评估提供一种新的思路。基于人工智能技术的初步评估方法增强了语言障碍评估的客观性,最大限度地排除了人为主观因素,且能大幅提高评估效率,为语言障碍人群语言能力的提升奠定良好的基础。
