基于Bert-BiGRU-CNN的文本情感分析*
2023-09-04张鑫玉才智杰
张鑫玉,才智杰
(1. 青海师范大学计算机学院,青海 西宁 810016;2. 成都信息工程大学软件工程学院,四川 成都 610041;3. 藏文信息处理教育部重点实验室,青海 西宁 810008;4. 青海省藏文信息处理与机器翻译重点实验室,青海 西宁 810008;5. 藏语智能信息处理及应用国家重点实验室,青海 西宁 810008)
1 引言
情感分析指用数据挖掘算法对带有情感态度的文本自动进行情感倾向性分析及判定[1]。近年来随着信息技术的快速发展,用户通过网络平台表达和传递情绪,互联网上产生了大量用户参与的对于诸如人物、事件、产品等有价值的评论信息,且随着科技的发展和时间的推移呈指数增长。这些评论信息表达了人们的喜、怒、哀、乐等情感色彩和批评、赞扬等情感倾向,用户通过浏览这些带有主观色彩的评论了解大众舆论对某一事件或产品的看法。单纯依靠人工分析这些海量信息费时费力,借助计算机可以帮助人们分析并挖掘信息中潜在的价值,做出更科学的决策。
本文在情感分析现有研究成果的基础上,提出了一种Bert-BiGRU-CNN文本情感分析模型。该模型首先用Bert对文本进行向量化,然后通过BiGRU从整体提取序列特征,再利用CNN局部连接的特点学习局部特征,从而提高文本情感分析性能。
2 研究现状
自2000年初以来,文本情感分析逐渐成为自然语言处理中重要研究领域之一,其研究方法主要包括情感词典、传统机器学习和深度学习三种。基于情感词典的方法是通过计算情感词典中词语之间的相关程度来判断文本情感倾向。Kennedy A[2]等人使用关联分数计算语义方法,提高了文本情感分类的准确性。Md. Sharif Hossen[3]等人提出一种改进Lexicon的分析模型,提高了情感分类效果。为有效提高情感词典词语覆盖率,郝苗[4]等人将大规模语料库进行融合,朱颢东[5]等人在此基础上加入了表情符号和网络新词,高祥[6]提出STSA算法融合扩展词典,构造了适合微博文本的情感词典,情感分类的准确率均有所提升。但是基于情感词典的方法依赖于词典的构建,随着信息量的增加,该方法无法满足文本情感分析的需求。为了摆脱人工构建词典的约束,学者们采用基于传统机器学习的方法进行文本情感分析,该方法能从大量语料中自动获取信息以构建情感计算模型。基于传统机器学习的方法是通过数据训练模型,再由训练好的模型来预测情感。Abbasi A[7]等人提出了一种基于规则的多元文本特征选择方法,该方法考虑了语义信息和特征之间的句法关系,以增强情感分类。Mustofa RL[8]等人利用情感词典和朴素贝叶斯进行文本情感分析,结果显示准确率达到79.72%。王磊[9]等人采用最大熵模型的文本情感分析方法,结合上下文环境缓解了词语情感倾向的不确定性。张俊飞[10]通过PMI特征值TF-IDF加权朴素贝叶斯算法实现了情感分析,实验证明该方法优于传统算法分类方法。基于传统机器学习的方法取得了不错的成果,但该方法在文本情感分析时无法充分利用上下文信息,学者把目光聚集在基于深度学习的方法上,该方法自动学习特征,保留上下文语义信息,在文本情感分析方面取得较好的效果,成为了近年来文本情感分析的主流方法。J. Shobana[11]等人提出了APSO-LSTM模型,利用自适应粒子群算法得到了比传统模型更高的精度。曹宇[12]等人提出了基于BGRU的文本情感分析方法,实验对比发现该方法的分类效果优于其它模型,并且训练速度快。张瑜[13]等人采用多重卷积循环网络(CRNN)增强了模型的拟合能力和对长文本序列的分析能力。杨奎河[14]利用基于Bert和BiLSTM相结合的模型,得到了比传统词向量模型更精准的分类结果。
从近年来的研究现状可见,神经网络模型间的有机结合可以提高文本情感分析的性能。基于深度学习的方法进行文本情感分析的核心在于文本的向量表示和特征提取。本文采用深度学习方法,以文本向量表示和特征提取为研究点,发挥Bert、BiGRU和CNN各自的优点,提出了Bert-BiGRU-CNN文本情感分析模型。该模型采用Bert生成动态词向量,减轻一词多义现象带来的影响,同时利用BiGRU提取全局序列特征和CNN提取局部重点特征。从而使该模型既具有强大的词向量表示能力,又有文本特征的全面提取能力,经验证该模型取得了较好的文本情感分类效果。
3 Bert-BiGRU-CNN文本情感分析
3.1 文本情感分析
文本情感分析包括文本预处理、特征提取以及情感分析等模块,其基本流程如图1所示。

图1 文本情感分析流程图
文本预处理包括分词、去停用词和词性标注等步骤。分词是将连续的字分为单个独立的字或词,去停用词的过程是过滤掉分词过程中产生的噪声及对文本情感分析有负作用的字或词,词性标注是联系上下文对文本中的词进行词性标记。特征提取是从原始文本中提取对文本情感分析有效的特征。情感分析是将提取的特征与种子词进行比对,从而分析文本情感。
3.2 Bert-BiGRU-CNN文本情感分析模型
Bert-BiGRU-CNN文本情感分析模型包括输入层、特征提取层和输出层,模型结构图如图2所示。

图2 模型结构图
1)输入层
为提高文本语义表示,Bert-BiGRU-CNN模型在文本表示方面使用具有强大语义表示能力的Bert模型。Bert的输入表示是通过相应的Token Embedding、Segment Embedding和Position Embedding的单位和来构造。Token Embedding表示单词本身的嵌入信息,将词语转换为固定维数的向量表示形式,开始([CLS])和结束([S EP])处添加额外的tokens共同作为输入表示。Segment Embedding表示句对信息,其作用是对输入的两个语义相似的文本进行区分。Position Embedding表示每个词语在句中的位置信息。
2)特征提取层
特征提取是文本情感分析的核心,Bert-Bi GRU-CNN模型分别利用BiGRU双向结构从整体捕获特征和CNN自动获取局部特征。GRU由重置门和更新门组成,重置门决定前一时刻的隐藏状态信息ht-1和当前时刻的隐藏状态输出信息ht传递到未来的数据量,更新门决定过去信息传递。为提取更完整的文本特征,利用由两个方向相反的单向GRU构成的BiGRU获取长文本序列特征。为了进一步提升文本局部重点特征提取性能,在BiGRU之后连接CNN卷积层和池化层。
3)输出层
为节省权重空间参数,模型输出层的分类器采用Sigmoid函数。为解决输出层神经元学习缓慢的问题,模型的损失函数使用交叉熵。
3.3 Bert-BiGRU-CNN文本情感分析
Bert-BiGRU-CNN模型文本情感分析过程如下:
1)文本向量化
Bert-BiGRU-CNN模型采用24层Transfor mer构成的Bert-Large预训练模型,通过Mask language model和Next Sentence Prediction预训练和微调得到适合于文本情感分析的Bert模型,利用Bert中的Bert-as-service库对输入的句子进行向量化;
2)全局特征提取


(1)

(2)

(3)
其中GRU(,)表示向量的非线性变换函数,yt表示正向权重矩阵,vt表示反向权重矩阵,bt表示偏置向量。单向GRU在接收词向量序列后经重置门“重置”之后得到数据ht-1′,经过激活函数映射,使用更新门进行更新得到特征ht,表达式为
ht-1′=ht-1⊙r
(4)
h′=tanh(w[xt,ht-1′])
(5)
ht=(1-z)⊙ht-1+z⊙h′
(6)
其中r为重置门门控,z为更新门门控;
3)局部特征提取
对于从BiGRU传过来的句子向量利用卷积核进行级联操作生成特征向量。为同时获取不同特征,本模型采用窗口大小分别为2、3、4的过滤器提取特征,图3为一个33的过滤器工作示意图。采用最大池化法缩小特征参数矩阵的尺寸,保留卷积的重要特征;

图3 过滤器工作示意图
4)输出层
全连接层将池化后的特征进行拼接,输送到Sigmoid函数得到情感标签。
4 实验及数据分析
4.1 实验数据集及评价指标
1)实验数据集
为了评估Bert-BiGRU-CNN文本情感分类模型的效果,用酒店评论[15]和网络购物[16]两个公开数据集对模型进行训练和测试。酒店评论数据集为谭松波老师整理的4000条酒店管理评论数据,其中积极和消极评论各2000条,数据集按4:1分为训练集和测试集。网络购物(Onlin e_shopping_10_cats)数据集共60000多条评论数据,包含书籍、衣服、酒店等10个类别,其中正、负评论各约三万条,数据集按4:1分为训练集和测试集。
2)实验评价指标
本实验通过准确率、精确率、召回率和 F1值等四个指标来评判模型的优劣。准确率(Accur acy)表示所有样本预测的准确度,其表达式为

(7)
精确率(Precision)表示所有预测结果为正的样本中实际为正的概率,其表达式为
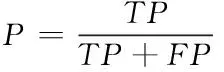
(8)
召回率(Recall)表示样本中为正且被预测正确的概率,其表达式为

(9)
F1值表示精确率和召回率的加权调和平均值,其表达式为

(10)
其中TP表示预测为正且实际为正的个数,FP表示预测为正但实际为负的个数,FN表示预测为负但实际为正的个数,TN表示预测为负且实际为负的个数。
4.2 实验及结果分析
1)实验参数
为验证Bert-BiGRU-CNN文本情感分析模型的有效性,本文在相同实验平台、环境和参数的条件下做了对比实验。实验平台为Linux,系统环境为Ubuntu18.04,开发语言为Python 3.6,开发IDE为Pycharm,深度学习框架为Tensorflow-gpu 2.2.0,词向量特征提取框架为Keras-Bert,模型超参数设置见表1。

表1 超参数设置表
Rate为学习率,L2Reg表示L2正则化参数,Max-length为数据集的最大句子长度,Dim表示BiGRU隐藏层维度。
2)实验结果及分析
为验证Bert-BiGRU-CNN文本情感分析模型的分类性能,以Multi-GRU[17]模型、BiGRU-CNN[18]模型、Bert-CLS[19]模型为基线进行了对比实验。Multi-GRU模型由多层GRU堆叠而成,利用窗口方法进行数据预处理,使用单输入、双输入和多输入通道将特征输入到GRU预测模型中,通过Sigmoid函数得到情感分类标签。BiGRU-CNN模型是由双向门控循环单元和卷积神经网络构成的复合模型,BiGRU双向提取上下文特征信息,然后Text-CNN准确的提取关键特征,最后经过Sigmoid函数得到二分类情感标签。Bert-CLS模型在Transformer中加入了适配器,在融合层的运算过程中融入了句向量CLS,生成结合语义的特征向量,经由全连接层和Sigmoid函数预测文本情感倾向。实验结果见表2。

表2 对比实验结果
由表2的结果可以看出,Bert-BiGRU-CNN文本情感分析模型在酒店评论测试集上的最高准确率、精准率、召回率和F1值分别达到了98.4%、97.4%、97.6%和97.5%,在线购物测试集的准确率、精准率、召回率和F1值分别达到了98.8%、97.9%、98.9%和98.4%。从实验数据可以看出,Bert-BiGRU-CNN文本情感分析模型在两个数据集上的分类效果都明显高于基线模型。该模型利用Bert得到高质量的文本向量语义表示,BiGRU对长文本序列特征的有效提取和CNN对局部重点特征的高效获取,提升了模型的特征提取能力,从而取得了较好的分类效果。
5 结束语
针对文本情感分析任务中静态词向量和特征信息提取效果不佳的问题,本文提出了一种Bert-BiGRU-CNN文本情感分析模型。模型首先采用Bert一次性读取要分析的整个文本序列,从词语的两侧学习词之间的上下文关系,使得同一词在不同语境下具有不同词向量,解决了一词多义现象对文本情感分类的影响;其次结合BiGRU和CNN各自的特点,分别从整体和局部提取特征,提升了文本情感分类的特征质量。经在酒店评论和在线购物数据集上的测试,其准确率分别达到98.4%和98.8%,体现了模型具有良好的文本情感分类效果。今后在此模型的基础上,进一步研究多模型整合的文本情感分类方法,以提高情感分类的准确率。
