融合压缩与激励模块的残差网络图像遮蔽识别
2023-09-04刘梦瑶李海涛王靖亚
刘梦瑶,李海涛,王靖亚
(1. 中国人民公安大学信息网络安全学院,北京 100038;2. 公安部第一研究所,北京 100044)
1 引言
随着深度学习网络技术的快速发展,图像伪造篡改、人脸替换、高质量超现实图像及视频合成等广泛用于盗版视频、色情产业链[1]、虚假新闻等[2],成为保护图像完整性和真实性、维护公民隐私权和肖像权、保持社会安定和谐的潜在风险。深度学习网络在篡改图像识别方面大有可为。Ahmed等[3]采用基于理论的改进型CNN技术对实时网络摄像和安全摄像进行伪造人脸重构建;Su等[4]基于注意力机制和卷积长短时记忆提取时间和空间维度信息,捕捉合成人脸中面部特征的大幅变化,检测效果显著。但对人脸细微特征变化检测不敏感;Tran等[5]运用手工蒸馏提取、目标提取等技术,基于CNN网络和动态阈值灵活分类减少过拟合问题,但并未探讨如何加快模型收敛的问题。文献[6]基于自编码器融合注意力机制用于图像多维特征提取;使用三层全连接层识别图像真伪。在小样本数据集下泛化性较好,不适用于大型复杂数据集识别研究;文献[7]以合成视频的视觉漏洞为突破口进行判别,包括疏于保持左右眼虹膜色彩统一,对光照处理能力弱等提取特征训练小型分类器,对人脸合成图像识别效果显著。但对于低分辨率图像视频识别率较低;文献[8]提出一个伪造人脸视频检测框架。利用时序和空间信息搭建全局时序和空间特征分类块检测多帧图像中的时序篡改痕迹和五官信息,检测效果突出。但模型通用性有待提升;Diogo.C.G[9]关注图片二次成像的莫尔条带效应,利用频域中伪装和真实图像的效应极大值差异判断分类;Mo等[10]提出一种基于卷积神经网络的篡改图像识别方法,对比训练预测值和真实标签,对高质量人脸数据集的篡改图像进行检测,但网络梯度消失,过拟合等问题有待解决。
2 残差网络ResNet原理
经典卷积神经网络在视觉图像分类识别等多分类任务上应用广泛。如在CNN网络最顶层加入XGBoost分类器[11]、使用基于光流的CNN[12]、3D CNNS[13]收集图像聚合多帧特征等。随着网络结构加深,层数和权重参数不断叠加,易出现复杂网络的梯度变化缓慢的问题。为减少神经网络叠加出现网络误差较大问题,提出ResNet。通过残差与恒等连接解决损失值降低停滞不前或产生波动问题,减少梯度下降衰减发生。但其易出现收敛波动,且收敛速度较慢。
3 改进残差网络SE_ResNet原理
将SE(Squeeze and Excitation)模块嵌入ResNet残差连接。首先,使用全局平均池化作为压缩操作;其次,全连接层负责构建通道间的关联性,特征维度降为原输入维度的1/16;Relu函数具有丰富的非线性,能更好拟合复杂通道间的关联性;通过乘法逐通道加权生成新的特征,完成对原始特征的重标定;最后,加入Sigmoid激活函数获得[0,1]区间归一化权重值,并将其分别加权到所有通道。
3.1 相关理论
为解决训练时易出现过拟合问题,在第一个卷积层和最后全连接分类层加入两层随机失活,节点保留率分别设置为0.2,0.5,生成压缩权重的平方范数,防止某一结点权重过大,引起权重失衡。
损失函数使用交叉熵,函数值越小,模型分类效果越佳。优化器采用SGD随机梯度下降法,每次小批量迭代后计算梯度并更新,算法公式为
xt+1=xt-ηtgt
(1)
式(1)中gt为随机梯度。
为避免复杂网络参数过大导致过拟合,在SGD的价值函数中添加权重衰减参数正则项,对其进行规范化,减少低质量参数对结果的影响
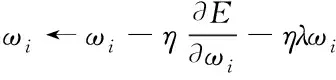
(2)
神经网络梯度沿负梯度方向下降,而添加动量项后,梯度下降加速,加速收敛效果显著。改进公式为
v=β×v-a×dx
x←x+v
(3)
式(3)中x为神经网络梯度,v为动量项。
3.2 SE模块计算通道方向注意力机制
1) 压缩操作(Squeeze):采用全局平均池化层将每个输入特征图的二维特征通道从H×W压缩至1,接近输入的层能够获取全局感受野。W和H表示特征图的宽和高,C为通道数。输入特征图大小为W×H×C,压缩操作后输出特征图大小为1×1×C。通过一个瓶颈层结构学习通道的内部关联性和注意力因子,构建相关性。方法如下

(4)
2)激励操作(Excitation):由全连接层+Relu激活函数层+全连接层+Sigmoid激活函数层组成。全连接层设置缩放参数SERatio,通过减少通道数降低网络复杂度。
第一个全连接层包含C×SERatio个神经元,输入为1×1×C,输出为1×1×C×SERatio。
第二个全连接层包含C个神经元,输入为1×1×C×SERatio,输出为1×1×C。
压缩和激励操作网络结构如图1和图2所示。
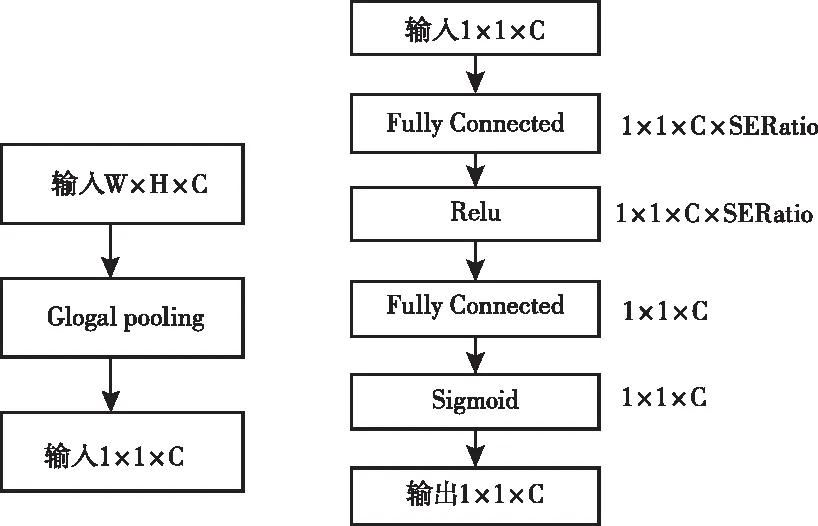
图1 压缩层 图2 激励层
4 实验结果与分析
4.1 数据集介绍
本实验数据来自4类公开人脸数据集,分别为LFW、AFLW、CASIA Face、BioID FaceDB。LFW数据集从日常场景中获取13233个人脸图像。使用openCV软件库进行人脸检测和中心化;AFLW数据库收集不同民族、肤色的人脸灰度图和彩色图数据。男女图像占比为6:4。在人脸属性检测方面应用较广;CASIA Face数据集收集了不同光照、背景条件下的图像;BioID FaceDB数据集收集了2500张亚洲人脸图像,数据集部分样本展示如图3所示。

图3 数据集样本展示
实验训练集和测试集样本分类见表1。

表1 数据集样本分类
4.2 数据预处理
分别对4类数据集进行5类篡改遮蔽处理:添加泊松噪音、均匀噪音、高斯模糊、中值滤波及图像压缩。从输入图像中随机截取多个图像块,单位大小为28×28。
4.2.1 泊松噪音
图像噪声由拍摄过程中各种随机条件造成,利用随机数进行算法模拟。泊松噪音强弱由泊松随机数sigma决定;噪音颜色分为彩色和灰度,灰度噪音要求位于同一位置的三通道随机数相同,彩色噪音无要求;噪声数量设置一定数量比例。使用带有泊松噪音的图像减去原始图像,得到噪音,将其乘以一个系数并加回原始图像,利用系数调节噪音强弱。满足计数噪音要求。
4.2.2 均匀噪音
均匀噪音随机数high和low决定噪音强弱。均匀噪音乘性噪声添加公式如下
noisy_image=image+image×noise
(5)
4.2.3 高斯模糊
高斯模糊处理使用低通滤波器,卷积核权重各不相同。像素权重值分布为中心高,边缘低,类似标准正态分布,是一种线性滤波方式。保留低能量像素,对高能量像素值运用加权平均算法二次计算其像素值,达到能量值降低,细节模糊化的低频图像效果。二维高斯函数公式如下
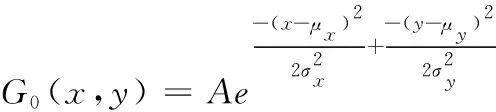
(6)
其中μ为峰值均值,σ为标准差,用于调节模糊效果(变量x与y均有一个标准差与均值)。使用Opencv图像处理库函数协助图像模糊化处理。
4.2.4 中值滤波
中值滤波处理,用数字图像邻域中间值代替本像素值,使周围像素值与真实像素值相近的高度非线性平滑技术。
4.2.5 图像压缩
压缩图像由RGB转为YUV色彩空间,由离散余弦变化替换为DCT变换矩阵以减少运算量。使用Opencv库函数,设置压缩质量指数以调整压缩强度。
4.2.6 预处理可视化
从两维度展示加入泊松和均匀噪音的样本图,维度1为原图,带alpha通道图和灰度图;维度2为原噪音和灰度噪音。如图4,图5所示,行表示维度1,列表示维度2。

图4 泊松噪音样本 图5 均匀噪音样本
图6为原样本,图7各行分别展示3个不同样本加入高斯模糊、中值滤波、图像压缩的遮蔽效果。

图6 原样本 图7 后3种遮蔽样本
为提高数据丰富性,避免测试集出现过拟合,泛化能力不足问题,以随机分布方式一次截取图像多个图像块,增大图像块覆盖率,提升训练速度。融合ROI(Region Of Interest)功能,获取原始图像块和ROI图像块左上角坐标值的偏移量。剔除接近边界的冗余图像,指定ROI区域获取高质量图像块。通过固定步长得到所有图像块的左上角坐标,加上图像块宽和高,获取右下角坐标。检验图像块坐标是否越过图像边界,若坐标溢出通过重剪裁左上方和右下方坐标值避免溢出,保证图像块大小不变。为保持训练数据的鲁棒性,设置每张图像块最多保留数目,保证训练数据分布均衡有序。
4.3 改进模型实验结果
本实验使用GPU为Nvidia GTX1080Ti,显存容量8GB,操作系统为Ubuntu,深度学习框架为Pytorch-1.2.0。实验设置batchsize大小为32,迭代20轮。实验环境如表2。
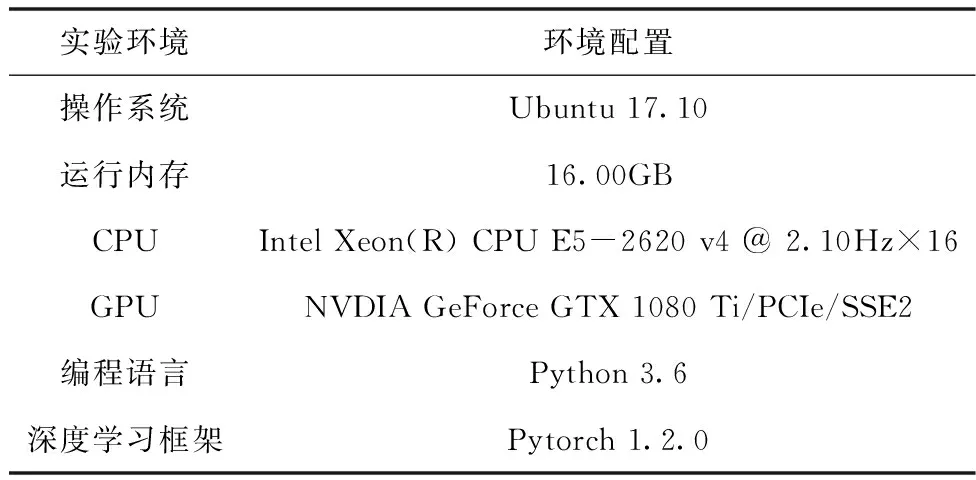
表2 实验环境
总体网络结构如表3。
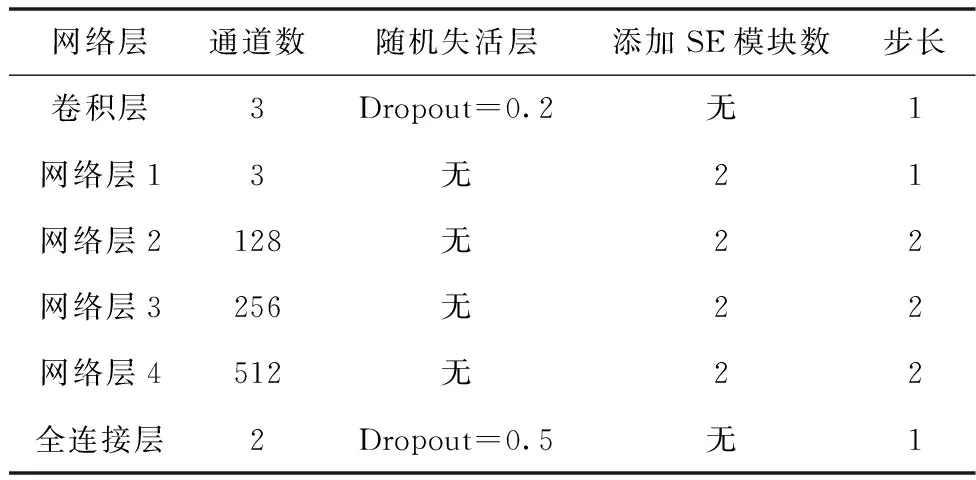
表3 总体网络结构
改进SE_ResNet实验流程图如图8所示。

图8 实验总流程图
引入评价指标准确率(Accuracy)。
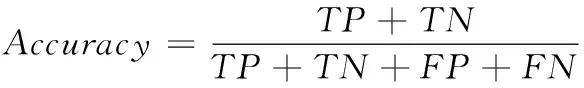
(7)
初始学习率为10-5,变化区间为[10-5,4×10-4]。前5轮迭代学习率呈线性上升,后15轮迭代学习率呈指数下降,指数衰减因子设为0.8。学习率改进如图9所示:
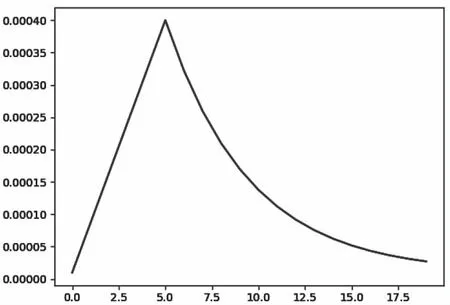
图9 学习率改进图
表4和表5统计了改进前后的残差网络在4类数据集测试集上的准确率。经过20轮迭代,改进SE_ResNet模型与ResNet相比,在测试集的准确率有显著提升。
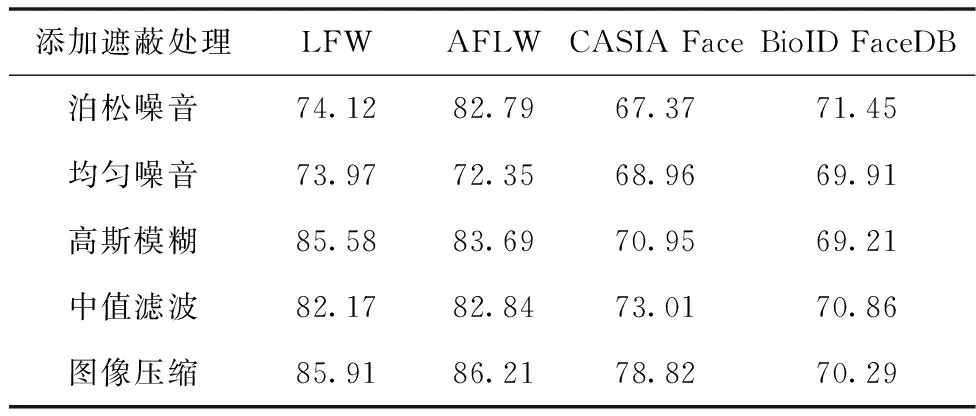
表4 ResNet模型在测试集的准确率(%)

表5 改进ResNet模型在测试集的准确率(%)
多次迭代训练SE_ResNet神经网络,在SE模块通过全局平均池化将二维通道特征压缩为实数,获得全局视野。通过全连接层建构网络内部关联性,同时Relu激活函数增加网络非线性特征,泛化性能提升。Sigmoid函数将输出结果归一化至[0,1]。压缩和激励操作后,输出特征加权到各通道中进行参数重标定,提升高质量参数表现力,降低低质量参数权重值。全连接分类层中加入随机失活层,节点保留指数设为0.5。前5轮迭代学习率线性上升,最高至0.0004,后15轮迭代学习率呈指数下降,设置学习率衰减指数和优化器动量等,避免过拟合。加入SE模块后,全连接层模型参数和计算时间有额外增长,但在5类遮蔽识别准确率得到显著提升。经过20轮迭代,准确率均值为87.30%,最高可达92.50%。
5 结论
本文提出融合压缩与激励模块的残差网络图像遮蔽识别。在ResNet网络8个残差模块内部添加SE模块。经过20轮迭代,ResNet网络在四类数据集上遮蔽识别准确率均值为76.02%;引入压缩与激励模块,改进学习率和梯度优化动量后,图像识别准确率均值提升11.28%,最高可达92.50%。SE模块通过嵌入残差单元,增加少量参数和计算复杂度,在神经网络中应用广泛。未来旨在利用更复杂场景下的篡改遮蔽图像技术训练网络模型,例如小目标复制[14],移动设备端图像遮蔽[15]等。在不同网络深度下加入SE模块,提升篡改遮蔽网络的增益效果和目标的泛化性能。
