改进YOLOv5的无人机影像车辆检测方法
2023-09-02范江霞张文豪张丽丽余涛钟林汕
范江霞,张文豪,张丽丽,余涛,钟林汕
(1.北华航天工业学院 遥感信息工程学院,河北 廊坊 065000;2.河北省航天遥感信息处理与应用协同创新中心,河北 廊坊 065000;3.中国科学院空天信息创新研究院 遥感卫星应用国家工程实验室,北京 100094;4.中科空间信息(廊坊)研究院,河北 廊坊 065001)
0 引言
随着经济与科技的迅速发展,车辆数量逐渐增加,交通拥堵已成为公路交通领域中的难题[1],智能调控车辆数量已成为一个热点问题。车辆检测是公路交通管理的重要环节,及时掌握交通信息、了解车辆分布情况,有助于对车流量进行管理、调度以及对交通拥堵情况的排查与预测[2]。
目前常用的车辆数据是通过感应线圈、压电式检测器、摄像头等地面传感器进行获取[3]。这类传感器设备成本比较昂贵,安装、维修等较为困难,且不易对其进行移动。相较于固定位置传感器获取车辆数据的方式,航空平台搭载传感器则更加灵活、高效。无人机拍摄的遥感影像进行车辆目标检测成为了新的研究方向[4]。
随着遥感技术的迅速发展,遥感影像的分辨率不断提高,影像上车辆的特征也更加清晰,这为使用遥感影像进行车辆检测提供了基础[5]。基于遥感影像的车辆检测方法可分为基于光谱或几何结构特征进行车辆检测、传统机器学习方法以及深度学习方法3类。基于光谱或几何结构特征进行车辆检测的常用方法包括阈值分割法、梯度比较法等。Alba-flores[6]使用多阈值和大津阈值分割法对Ikonos影像上的车辆目标进行检测;Larsen等[7]提出了双阈值法对车辆进行检测提取;曹天扬等[8]通过最大类间方差(OTSU)阈值分割法检测车辆目标。此外,Sharma等[9]提出了利用光谱特征进行梯度比较的方法识别车辆。该方法中,阈值分割法对车辆密集区域检测效果差;梯度比较法误检率高,不适用于遥感影像车辆目标检测。总之,基于光谱或几何结构特征进行车辆检测的方法检测精度较差,鲁棒性不强。传统机器学习方法通过梯度方向直方图(histogram of oriented gradient,HOG)等方法对车辆目标进行检测。Kembhavi等[10]通过HOG特征、颜色概率图特征、汽车结构特征与提取的偏最小二乘法(partial least squares,PLS)特征相结合的方法检测车辆;Liang等[11]结合HOG特征与哈尔小波转换特征,使用多核支持向量机(support vector machine,SVM)作为分类器识别车辆目标;阳理理等[12]将二值统计局部特征模式(local feature pattern,LFP)与多尺度多个方向卷积核二者结合对车辆进行检测。传统的车辆检测算法大多依靠人工进行特征提取,不一定能够符合多样性变化,且在遮挡情况下,检测效果不佳,漏检、误检现象较多,其鲁棒性与普适性较差。
近年来,基于深度学习的车辆检测算法相较于传统算法取得了更好的检测效果。基于深度学习的车辆检测算法可分为两类。一类是基于区域提取的车辆检测算法,具有代表性的算法有R-CNN[13]、Fast R-CNN[14]、Faster R-CNN[15]、Mask R-CNN[16]等,该类算法车辆检测精度较高,但建议框提取阶段计算复杂度高,实现实时检测仍面临着挑战[17]。另一类为基于端到端的车辆检测算法,具有代表性的算法有YOLO(you only look once)[18]、SSD[19](single shot multiBox detector)等,该类算法在速度上满足了实时性的要求,但相较于区域提取算法而言精度较低。姜尚洁等[20]使用YOLO算法对无人机遥感影像中的车辆目标进行实时检测;Chen等[21]使用深层卷积神经网络对高分辨率遥感影像中的车辆进行了检测识别。深度学习算法依靠卷积神经网络(convolutional neural network,CNN)进行图像特征提取,在一定程度上,该算法解决了传统算法漏检、误检等情况,但其需要大量训练数据学习车辆特征,花费时间较长,且该算法对硬件设施有较高的要求。
综上,针对已有的遥感影像车辆检测算法检测效果较差、复杂度高、体积大等问题,本文提出了一种基于改进YOLOv5s的轻量级无人机遥感影像车辆检测算法。以YOLOv5s模型为基础模型,采用锚框尺寸修正、加权框融合及增加注意力机制网络3种改进策略,并将检测结果与YOLOv3及原始YOLOv5s模型进行比较。
1 数据和方法
1.1 数据集的准备
使用公开的DroneVehicle数据集[22]进行训练与检测。该数据集所有影像均为配备相机的无人机拍摄,包含多场景(道路、居民区、停车场等)和不同类型车辆目标(汽车、公共汽车、卡车、厢式货车、货运车等)的真实影像数据,大小统一为840像素×712像素。该数据集利用4个顶点坐标{((Xi,Yi),i=1,2,3,4)}构成的四边形边界框对每个对象进行标注,每幅标注的影像均有相应的XML文件,标注框的位置、大小等在该文件中均可查询,标注样本如图1所示。

图1 样本标注
1.2 YOLOv5s网络体系结构的改进
YOLO算法是一种基于深度神经网络进行对象识别和定位的算法。该算法将目标提议阶段和分类阶段融合在一起,是最典型的单阶段目标检测算法之一。它采用卷积网络提取图像特征,使用全连接层得到最终预测结果。YOLOv5是YOLO系列的最新版本,它包括YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x 4个架构,它们的主要区别在于不同的卷积核数量和特征提取模块。为了防止过拟合现象的发生,本文选择YOLOv5s作为基础模型。针对无人机影像中车辆目标相对于自然图像较为复杂的背景,对原始YOLOv5s模型使用3种改进策略:锚框尺寸修正、加权框融合及骨干网增加注意力机制网络,以提升车辆检测效果。
1)锚框尺寸修正。锚框是YOLOv5s算法的重要组成部分,利用锚框进行车辆目标定位,可提高车辆定位的准确度。原始YOLOv5s算法中设置3个尺寸的初始检测锚框:[10,13,16,30,33,23]、[30,61,62,45,59,119]、[116,90,156,198,373,326],用于对小、中、大目标的检测,对自然图像车辆目标检测效果较好。但由于无人机影像中车辆目标尺寸不一、种类多样,且受拍摄角度影响,其形状特征发生改变等特点,初始水平矩形锚框并不适用。本文添加角度回归实现锚框旋转,利用K-means聚类算法,对初始锚框尺寸进行改进。该算法将数据分为k组,随机选取k个对象作为初始聚类中心,计算每个对象与各个种子聚类中心之间的距离,最后将每个对象分配给最近的聚类中心。每个聚类中心的值在迭代过程中不断更新,得到最好的聚类结果后结束。本文使用K-means聚类算法,结合无人机影像中车辆目标的长宽比,将锚框尺寸设置为:[14,34,27,32,72,34]、[11,30,26,13,33,22]、[24,81,30,17,18,36]。如图2所示,该示意图呈现了6组锚框。

图2 改进的锚框结构图
2)加权框融合。经典的非极大值抑制(non-maximum suppression,NMS)应用于检测网络,是目标检测中常用的预测框生成算法。NMS算法在检测图像中的单个目标物时有很好的检测效果,但在实际场景中,车辆受到光线、建筑物、其他车辆等影响,导致阴影、遮挡等状况。该算法将置信度低的预测框过滤,提取置信度高的预测框,使车辆在检测过程中出现预测框计数不准确的情况。本文使用一种新的边界框融合方法,即加权框融合(weighted boxes fusion,WBF)。WBF的步骤如下。首先,按照置信度分数由大到小的顺序对所有边界框进行排序;然后,生成另一个可能的框“融合”列表,通过比较交并比(intersection of union,IoU)和指定阈值的大小,判断它们与原始框的匹配程度;最后,对框列表中所有框的坐标和置信度分数进行调整。新的置信度是所有被融合框的平均置信度,对新坐标进行类似的融合和加权,最终生成最合适的预测框,用数量信息生成正确的坐标。该方法将预测框进行合并,改善了计数不准确的情况。NMS与WBF预测框对比如图3所示。
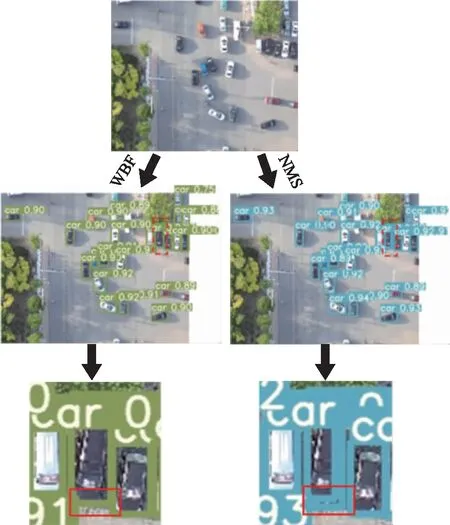
图3 NMS与WBF生成预测框对比图
3)骨干网的改进。由于车辆易受到实际场景影响且自身外形、结构、颜色等具有多变性,为了能更加快速准确地检测车辆目标,本文增加了轻量级注意力机制SE(squeeze-and-excitation)网络。SE网络结构特征(图4)有特征通道数(channel,C)、特征图的宽(width,W)、特征图的高(height,H)。该网络结构的步骤大体为给定一个输入X,经过卷积输出特征图U。首先,将大小为W×H×C的特征图U沿着空间维度进行特征压缩(squeeze);然后,压缩后的特征图通过全连接层(fully connected layers,FC)进行激活(excitation),为每个特征通道生成权重;最后,通过加权(scale)操作,将excitation输出权重应用于原来的每个特征通道,得到最终的输出结果。该网络通过学习不同特征通道的重要性,对车辆目标有用特征进行提升,并抑制车辆的无关特征。

图4 SE网络结构特征图
改进的YOLOv5s网络结构主要包括骨干网络、颈部网络和检测网络,如图5所示。骨干网络用来提取图像的一些通用特征,包括CSPDarknet53结构与focus结构两部分。首先,focus模块将多个切片结果进行堆叠(concat),使其深度连接;然后,将结果送入卷积层(convolutional layer,Conv),通过批量归一化(batchnormalization,BN)和LeakyRelu激活函数,将结果输送到BottleneckCSP模块,用于更好地提取图像的深层特征。Bottleneck模块是BottleneckCSP模块的主要组成部分,它是一种连接了卷积核大小为1×1的卷积层(Conv2d+BN+LeakyRelu激活函数,CBL)和卷积核大小为3×3的CBL的残差网络架构。Bottleneck模块的最终输出是通过残差结构将这部分的输出和初始输入相加。BottleneckCSP模块的初始输入被输入到两个分支中,通过两个分支的卷积运算,特征图通道数减半。使用堆叠操作使两个分支输出的特征图深度相连,之后通过BN层和Conv2d层输出与BottleneckCSP模块的输入相同的特征图。骨干网络的第10层为空间金字塔池(spatial pyramid pooling,SPP)模块,它将任意大小的特征图转换为固定大小的特征向量,以此来改善网络的感受野。将卷积层输出特征图与通过3个并行最大池化层(maxpooling)下采样的输出特征图深度连接,经过一个卷积层得到最终的输出特征图。骨干网络还加入了注意力机制SE网络,通过学习自动获得车辆目标不同特征的重要程度,提升其有用特征,并相应地抑制一些不重要的特征。颈部网络是融合图像特征的特征聚合层,主要用于生成特征金字塔网络(feature pyramid network,FPN),然后将输出的特征图传输到检测网络。新的FPN结构增强了自底向上的路径,提高了底层特征的传递,增强了对不同尺度物体的检测。因此,不同大小和尺度的同一目标对象可以被准确识别。检测网络是模型的最后一部分,由3个检测层组成,用于检测不同大小的图像对象。每个检测层最后输出一个向量,然后生成并标记原始图像中车辆目标的预测边界框和类别。

图5 改进的YOLOv5s结构框架图
1.3 评价指标
本文利用每秒帧数(frames per second,FPS)、精确率(precision)、召回率(recall)、平均精度(average precision,AP)以及均值平均精度(mean average precision,mAP)对最后的实验结果进行评价。
2 结果与分析
2.1 模型训练结果
本文在AMD Ryzen 7 4800H处理器、NVIDIA GeForce RTX 2060显卡、16 GB存储卡的硬件条件下构建了PyTorch深度学习框架,实现了无人机影像车辆目标检测模型的训练和测试。模型训练期间,采用Adam优化器进行网络优化,将模型训练的批量设置为2,训练迭代次数为200。图6为改进的YOLOv5s模型训练结果示意图。图6(a)为训练损失函数图。从图6(a)可知,模型训练的前25个阶段,损失值迅速下降;160个阶段之后,该模型的训练趋于收敛。图6(b)为均值平均精度(mAP)图,该图表明,在训练过程中没有出现过度拟合现象,模型训练结果较好。训练结束后,保存YOLOv5s模型的权重文件,并通过测试集对模型性能进行评估。
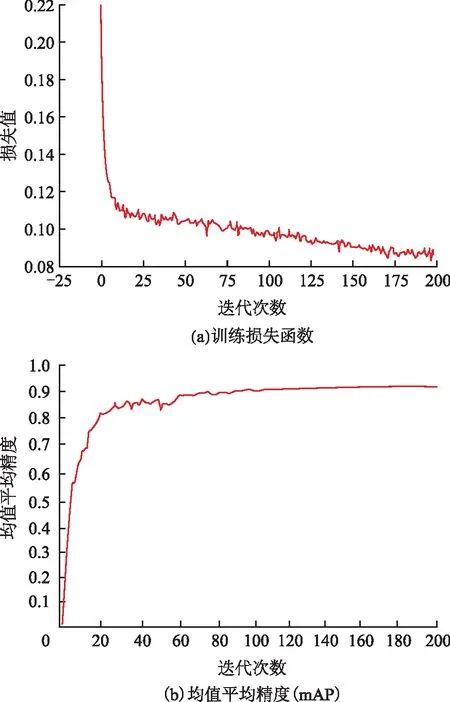
图6 改进的YOLOv5s模型训练结果
2.2 模型检测结果
为验证改进的YOLOv5s模型性能,本文选择755张无人机影像作为测试集进行分析,共有车辆目标10 136辆,其中汽车5 049辆、公共汽车1 272辆、卡车1 847辆、厢式货车937辆、货运车1 031辆,真实被检测到的车辆目标为9 425辆。车辆目标检测的FPS、precision、recall、mAP分别为30.19、92.10%、91.19%、90.01%。改进的YOLOv5s模型检测结果如图7所示。从检测结果可以看出,本文所提出的模型可以较好地识别车辆目标。

图7 改进的YOLOv5s模型检测结果
2.3 消融实验与不同目标检测模型检测结果比较
1)消融实验。实验采用3种策略对YOLOv5s模型改进,包括锚框尺寸修正、WBF及增加SE网络。为了验证以上策略的有效性,以YOLOv5s为基线模型,分别进行实验,结果如表1所示。从表1可知,通过将锚框尺寸进行修正,mAP提升了1.11%;在此基础上,将NMS替换为WBF,mAP增加了2.79%;最后将SE网络添加到模型中,mAP高于基线模型4.59%,mAP达到了最大值。

表1 消融实验结果
2)不同目标检测模型。为了进一步分析改进的YOLOv5s模型性能,本文将755张无人机影像测试集分别使用YOLOv3与原始YOLOv5s模型进行检测,与改进的YOLOv5s模型检测结果对比分析,如表2所示。从该表可知,改进的YOLOv5s的mAP值最高,比原始YOLOv5s模型提升4.59%,高于YOLOv3模型5.88%。本文算法精度优于原始YOLOv5s模型、YOLOv3模型。改进的YOLOv5s模型 FPS为30.19,相较于原始YOLOv5s提升了5.82,是YOLOv3的2.2倍。表3为Sun等[23]利用不同检测模型针对此数据集的实验结果。从该表可知,改进的YOLOv5s模型mAP值最高,该实验的真实框与预测框的IoU大于0.5,则认为车辆目标被真正检测到。结果表明,改进的YOLOv5s模型不仅保证了车辆目标检测精度,同时也有效地实现了检测速度的提升。
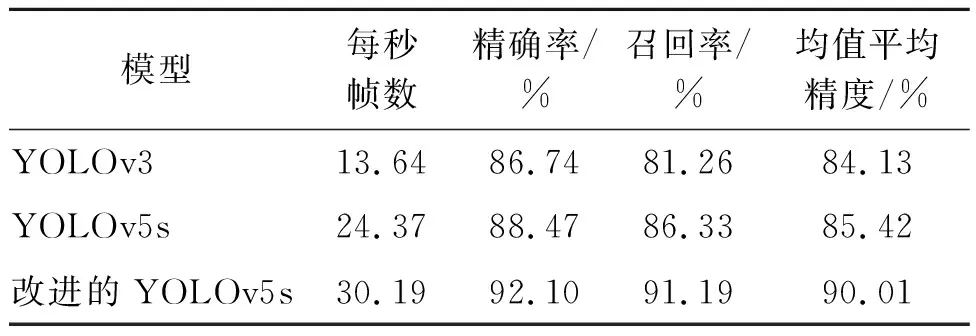
表2 不同模型检测结果比较
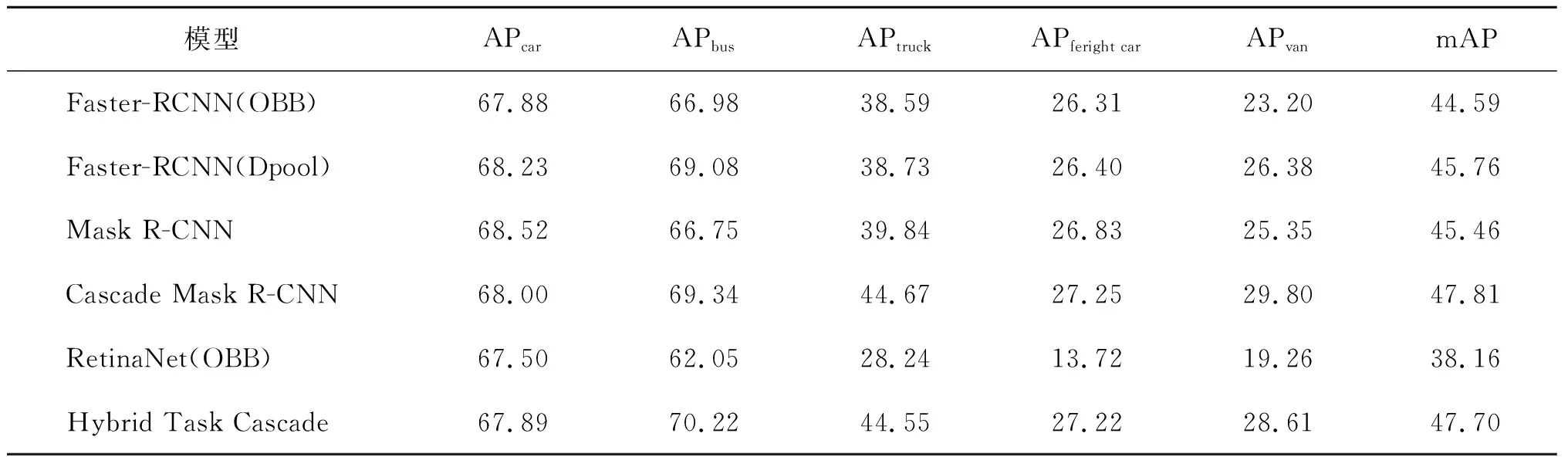
表3 无人机车辆数据集评估 %
2.4 实验结果分析
实验结果表明,改进的YOLOv5s模型对于无人机影像车辆目标的检测识别有着较好的结果。YOLOv5s主干网CSPDarknet53增强了CNN学习能力,在轻量化的同时保证了精度,优于YOLOv3主干网Darknet53,具有更好的车辆检测能力。但由于无人机影像车辆数据集中存在不完整车辆,且如果车辆不完整度等于或大于1/2时,该算法对其检测识别精度降低,如图7(b)、图7(c)所示。
3 结束语
本文使用基于改进的YOLOv5s模型对无人机影像中的车辆目标进行检测识别。针对无人机影像车辆目标易受实际场景等因素影响,在已有YOLOv5s模型的基础上做了如下改进。
1)增加角度回归,实现锚框旋转,并利用K-means聚类算法高效、收敛速度快且聚类效果较好等特点,对锚框重新聚类。
2)由于WBF在某些情况下能够改善漏检、误检等问题,所以将模型原有的NMS方法替换为WBF方法。
3)增加注意力机制SE网络,自动学习不同特征通道的重要程度,通过重要程度提升车辆的有用特征,并抑制了车辆无关特征。
改进的YOLOv5s检测算法具有以下优点。
1)改进的YOLOv5s模型FPS为30.19,相较于YOLOv3、原始YOLOv5s模型具有更快的检测速度。
2)该模型均值平均精度为90.01%,能够准确识别车辆目标。
3)本文提出的改进算法检测模型为轻量级网络,体积为16.1 MB,对硬件设备配置要求相对简单,降低了车辆检测模型的部署成本。
