融合注意力机制及DenseASPP改进的DeeplabV3+遥感图像分割方法
2023-09-02周羿刘德儿
周羿,刘德儿
(江西理工大学 土木与测绘工程学院,江西 赣州 341000)
0 引言
近年来,随着遥感技术的快速发展,遥感影像的分辨率不断提高,高分遥感影像所能够表达的地表信息越来越精细,对遥感图像语义信息的提取方法也从目视解译的方法到传统的边缘监测、阈值、区域的分割方法,再到机器学习的支持向量机(support vector machine,SVM)、随机森林(random forest,RF)、马尔科夫随机场MRF,及boosting等方法[1]。遥感图像中场景复杂,同一场景下,地物分布以及形状不规则,同一物体尺度大小不一致,地物之间相互遮挡,复杂的背景下存在阴影遮挡,以及高分辨率遥感影像存在地物类别复杂,出现 “同物异谱、同谱异物”[2]“类内差异大、类间差异小”的特点[3]。因为以上算法自身存在局限性,只能够提取遥感图像的浅层特征,不能够充分提取其高维的特征。利用传统的方法,在高分辨率遥感图像语义分割中,存在精度上限低、鲁棒性差、分类时地物间容易混淆、不能很好地反映建筑物的空间连续性等空间特征等缺点。由于以上原因,以上方法已经不再适合作为高分辨率遥感影像的分割手段。
如今使用深度学习对高分辨率遥感图像进行图像分类及语义分割已经成为主流方法。其特点在于,其卷积神经网络中具有很强的特征提取能力以及空间层次结构的学习能力,可以很好地利用高分辨率遥感影像的空间特征以及光谱特征。目前国内外学者也利用深度学习对高分辨率遥感图像进行了一系列研究,取得了良好的效果。目前使用深度学习对遥感影像分割的比较常用的方法包括使用FCN[4]、U-Net[5]、SegNet[6]、DeeplabV3+[7]等网络,以及在这些网络的基础上改进的网络。
其中,Rui等[8]使用空洞卷积替换FCN中的标准卷积,同时利用图论的分割方法及选择性搜索的方法做数据增强,最后使用了CRF作为后处理方法,来细化分割边界。
何值蒙等[9]针对遥感图像中建筑物提取存在边缘模糊、细节丢失,以及转角圆滑等问题,在U-Net网络的基础上,提出了基于空洞卷积的增强型U-Net(enhanced U-Net,E-Unet),即在原始的架构中添加空洞卷积、跳跃连接,以及Dropout模块。同时在预处理中,将原始影像进行直方图均衡化、边缘检测(高斯双边滤波)、波段间比值后与原始图像一起转换为多波段的张量输入神经网络。通过改进,得到了一种有更强细节保留能力及抗噪能力的模型,提取精度也明显提高。
目前,现有的方法取得了一定的成果,但仍有提升的空间。由于遥感场景中,目标多尺度问题广泛存在,受到郭新等[10]的启发,在拥有multi-scale结构的网络上进一步引入多尺度结构进行训练能够更好地提升网络性能。考虑到捕获长距离依赖关系对于深度神经网络至关重要,而遥感影像中,长距离依赖需要非常大感受野才能捕获,不管是时域还是空域,使用卷积运算只能捕获局部领域信息,因此本文在网络中添加金字塔拆分注意力模块[11](pyramid split attention,PSA),通过金字塔结构获得更多的多尺度信息,并且帮助网络关注关键信息的同时建立长距离依赖关系。由于ASPP在使用较大空洞率时,空洞卷积可能出现效率低或失效等情况,为了避免空洞卷积出现效率低或是失效的情况,我们通过使用DenseASPP替换ASPP。本文提出改进的DeeplabV3+高分辨率遥感图像语义分割算法,该方法结合了PSA模块、编解码器与密集空洞金字塔池化[12],提供了一种有着更大感受野,能够有效地帮助网络在特征提取阶段提供更密集的特征金字塔层,获得更多的多尺度上下文信息,产生更好的像素级注意力。为了验证改进后的算法效果,使用了Vaihingen和WHDLD数据集进行验证,并与其他模型进行对比。
1 金字塔拆分注意力模块及DenseASPP的DeeplabV3+网络
1.1 DeeplabV3+网络结构
DeeplabV3+网络是基于DeeplabV3网络模型的一种改进,其主要特点是一种融合编解码器与空间空洞金字塔池化模块的结构。DeeplabV3+的第一个特点是使用编解码器结构,在编码器中,首先,将原始图像通过一个特征提取网络,分别得到原始图像的深层特征以及浅层特征;其次,将深层特征传入到ASPP模块中。在解码器中,使用通过ASPP模块后输出的特征经过上采样后与一次卷积运算后的浅层特征拼接,经过卷积和上采样后得到最终的特征图。DeeplabV3+的第二个特点是使用ASPP模块,该模块包括一个1×1卷积核,3个3×3卷积核,空洞率分别为6、12、18的空洞卷积,1个全局平均池化层。ASPP模块由以上卷积层并行组成,每个不同大小空洞率提取的特征单独处理,最终融合得到输出,输出的结果是多尺度的物体信息。一般卷积为了扩大感受野,需要使用较大的卷积核或者更大的步长,这样会导致计算量过大,或者损失分辨率,而ASPP模块由空洞卷积(atrous convolution)组成,在扩大感受野的同时,不会使分辨率降低太多,也不需要太大的计算量。
1.2 金字塔拆分注意力模块
面对自然界繁杂的消息,人们通过注意力来筛选重要的信息,避免大脑过负荷。在深度学习中,为了从复杂的信息中提取更有价值的信息,人们通过引入注意力机制,给关键的信息添加更大的权重,分配更多的运算资源。SE-Net(squeeze-and-excitation networks)[13]仅使用了通道注意力,忽略了空间信息的重要性。对于遥感图像,空间关系是其中十分重要的一个部分,因此在DeeplabV3+中加入金字塔拆分注意力模块,可以从更精细的层次上提取遥感图像的多尺度空间信息,并建立一种长距离的通道依赖关系。
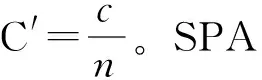
SE模块如图2所示。SE模块于2017年被提出,之后许多注意力机制都借鉴其思想,提出了各种改进。其主要步骤分为3步。第一步为特征压缩阶段,将大小为H×W×C的特征图通过全局平均池化的方法得到每个通道的大小为1×1×C的全局特征。第二步使用sigmoid激活函数来重新定标,其目的是学习各个通道之间的权重关系,通过计算不同通道的权重,得到1×1×C的权重。最后将权重与特征图相乘,在遥感图像的分割中,对于不同种类的分割,可以达到提升有用的特征并抑制对当前任务用处不大的特征的效果。
大学教师相对于中小学教师具有较高的文化修养,在某一专项领域也有一定的独特见解.大多数大学的足球教师拥有较高的实践能力.

图2 SE模块结构
金字塔拆分注意力模块总流程如图3所示。首先将H×W×C的特征向量利用SPC模块分成S块,通过金字塔结构得到通道方面的多尺度特征Fi,将由Fi合并之后的特征图U通过SE模块计算得到多尺度特征图通道注意力权重Zi,这样可以使PSA模块融合不同尺度的上下文信息,并为高级特征图产生更好的像素级注意力。接着,为了实现局部和全局通道注意力之间的交互,将softmax用于多尺度特征图通道注意力权重的重新校准,最后得到的结果ATTi既包含了空间上的位置信息又含有通道中的注意力权重。最后将重新校准的权重与特征图相乘,得到最终结果。在遥感图像语义分割中,使用PSA模块,可以将多尺度的空间信息与跨通道注意力整合,使得最后的结果既可以在更细粒度的级别提取多尺度空间信息,又可以建立一种更长距离的通道间的依赖关系。

图3 金字塔拆分注意力模块总流程
1.3 DenseASPP
DeeplabV3+在模型中通过使用ASPP,在图像的特征提取时获得了更大的感受野,同时保证了特征图的空间分辨率。该模块使用多个空洞率大小不同的卷积层,构建了不同感受野的卷积核,从而得到多尺度特征信息。但是在遥感图像的语义分割中,ASPP同样也有一个缺点,即使用高分辨率的图像提取特征,通常需要更大的感受野,因此ASPP必须使用具有足够大空洞率的空洞卷积来扩大感受野。但是在进行卷积运算时,由于空洞卷积的特性,其每次只选取少量的像素点运算,因此会丢失掉大量的信息,并且随着空洞率的增加,空洞卷积效率也会随之降低甚至不起作用。
针对此问题,本文将DeeplabV3+模型中的ASPP模块替换成了DenseASPP模块,得到了一种能够兼顾更大的感受野以及获得更多的尺度特征的模型,可以更加适合高分辨率遥感图像的语义分割。
DenseASPP通过级联方式来组织扩张卷积层,每个卷积层的输出与输入特征图和来自较低层的所有输出连接起来,并将连接起来的特征图送入下一层。由此,可以得到多扩张率、多尺度的特征。相较于ASPP模块,该模型的扩张卷积通过跳跃连接共享信息,使得输出有着更密集的特征金字塔,即卷积中涉及的像素更多,存在的漏洞更小,以及具有更大的感受野。
本文构建的网络结构如图4所示,在使用ResNet101[14]作为特征提取网络的DeeplabV3+的基础上添加了PSA模块及将ASPP更改为DenseASPP模块的模型。

图4 本文网络结构
2 实验与结果分析
2.1 改进效果对比
本文进行的实验均使用Pytorch框架,其中Vaihingen数据集共包括33幅遥感影像,共标注了6种地物,将数据集按照8∶2划分训练集和验证集,其中训练集26幅,验证集7幅。为了减小计算机显存,提高效率,将原始图像按256×256的尺寸进行裁剪,裁剪后共得到训练集2 224个,测试集614个。WHDLD数据集[15-16]共4 940张图片,其中标注了6种地物,使用3 950张作为训练集,990张作为验证集。为了防止过拟合,增加样本多样性,在训练过程中使用了亮度增强,随机旋转等方法做数据增强。
实验中,损失函数设置为交叉熵损失函数,实验时,选择的优化器为adam优化器,初始学习率设置为0.001,使用间隔调整学习率的策略,每训练5次,学习率下降为之前的0.8。
改进前以及改进后的实验精度如表1所示。从表中可以看出,在原始的DeeplabV3+网络中,无论是分别添加PSA注意力模块,或者是将ASPP模块更改为DenseASPP模块,都能有效地提高模型的分割效果,最后改进的模型添加PSA模块以及DenseASPP模块,相较于原模型,在 MIoU以及F1分数等指标方面都有了一定程度的提升。改进后模型相较于原模型的预测结果的提升如表1所示。之后,从各模型对高分辨率遥感影像的预测结果,也可以看出预测效果的提升,具体实验结果如图5所示。
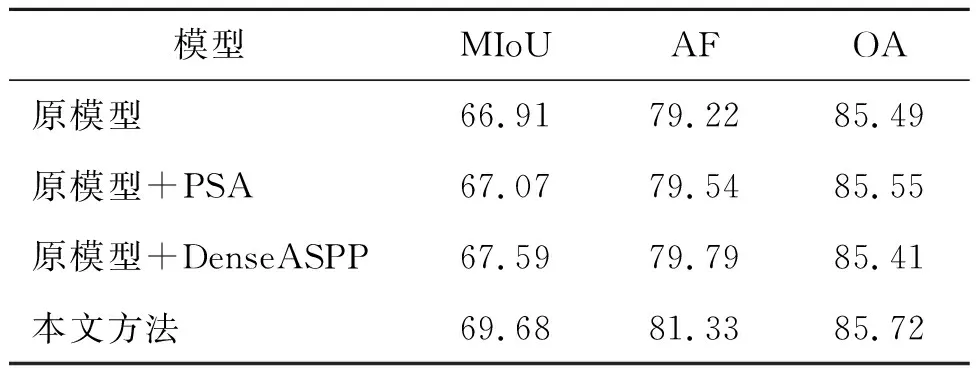
表1 DeeplabV3+及其改进模型精度对比(Vaihingen数据集) %

图5 模型改进前后实验结果对比
从图5中可以看出,相较于模型,在添加PSA模块之后,模型在分割中,对于每个类的识别更加精确,而原模型识别效果较差的小物体的识别效果也有了提升,相较于原模型的同类地物有了更高的识别率。这是因为在添加PSA模块之后,通过通道注意力机制,对于每个不同的类别的高级语义特征重新赋予权重,通过权重的添加,一些准确率低的地区可以更加准确地被划分到原来的类,因此能够更加清楚地识别出每个类别之间地物的区别,增加模型准确性。
而本文改进的模型在以上二者之上,综合了其中两个模型的优点。相较于原模型,在类与类之间的混淆率明显降低,可以精确地区分每个类别之间的差异,同时对于类之间的识别也更加精确,可以准确识别出每个类地物的详细信息。
2.2 不同模型对比
通过本文提出方法与其他模型的实验效果进行对比,可以看出本文提出的方法具有一定的优势,具体对比如表2、表3所示。相较于其他模型,所提出方法的MIoU、F1分数都有了一定的提高。相较于原始模型,Vaihingen数据集中MIoU提高了2.8%,F1分数提高了2.1%;WHDLD模型中MIoU提升了0.9%,F1分数提高了0.73%。具体预测结果的区别如图6及图7所示。
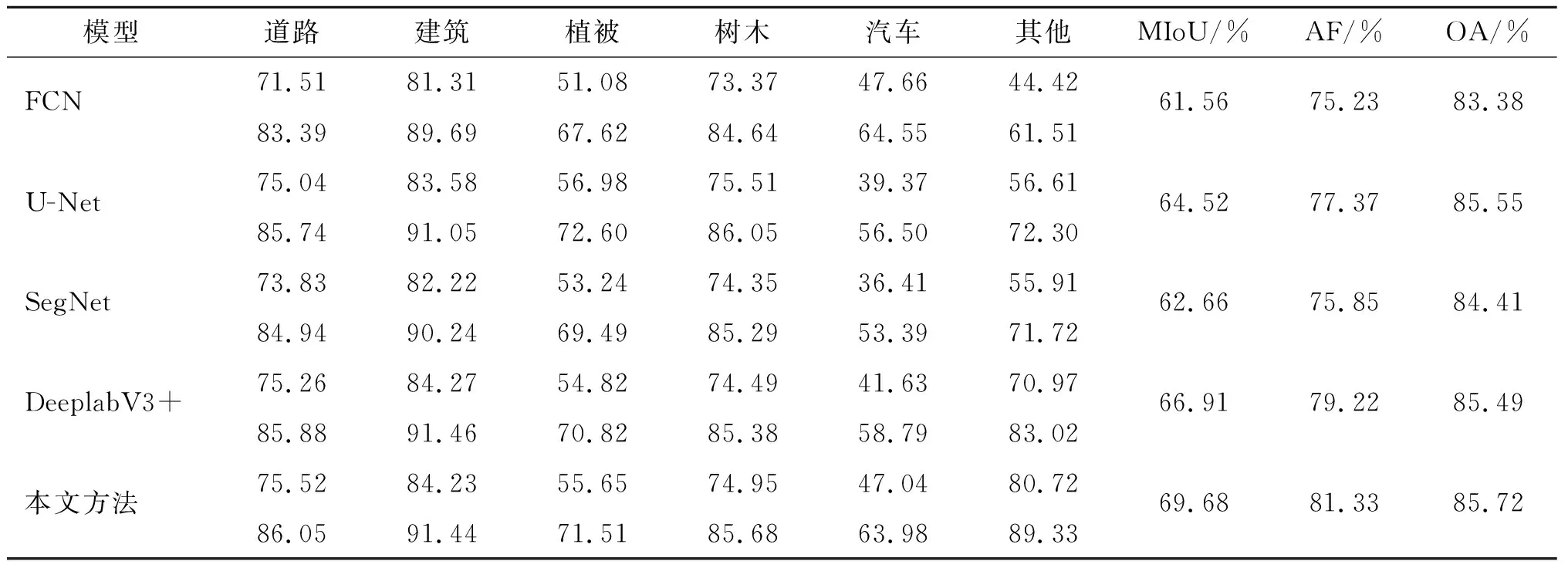
表2 本文提出方法与其他模型精度对比(Vaihingen数据集)
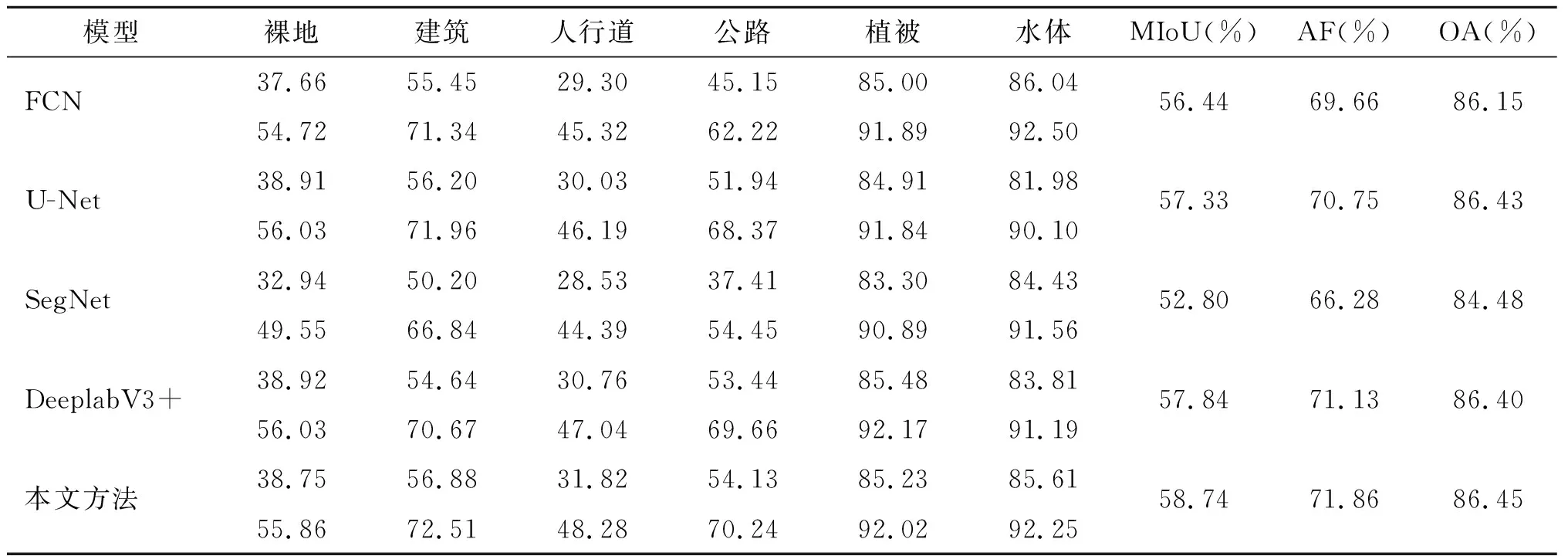
表3 本文提出方法与其他模型精度对比(WHDLD数据集)


图6 不同模型结果对比(Vaihingen数据集)
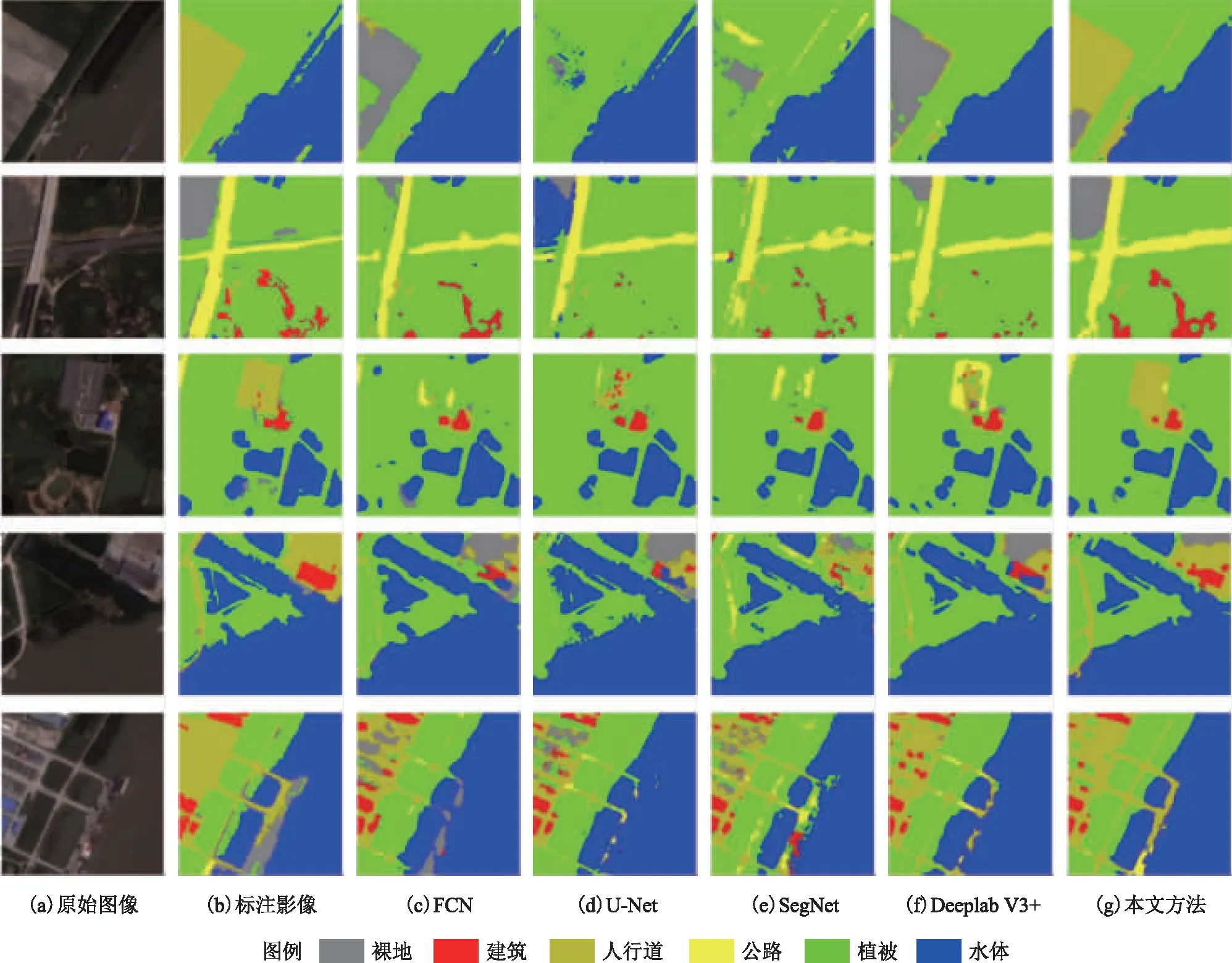
图7 不同模型结果对比(WHDLD数据集)
通过实验结果可以发现,FCN在物体分割时有着一定效果,能够大概识别出各类物体,但是错分率较高,各类之间的混淆较多,同时对建筑物的分割常出现漏分或错分的情况。U-Net对于物体的边界轮廓信息分割得较好,但是同类之间的分割不够精确,不同种类混淆程度较高、错误率较高,同样不符合空间地物分布逻辑。SegNet识别大规模分布的物体(如建筑)的效果较好,但是在分割细节上表现得十分粗糙,物体的边界也不够细腻,出现的噪点较多。未改进的DeeplabV3+模型,相对于前几个模型分类效果更佳,但是在不同种类物体的边缘处分类效果不佳。本文提出的方法相对于以上几个模型,能够更加精确地区分每个地物类别,对于同类地物分类更加精确详细,同时分割的结果更符合地学逻辑,也没有其他模型的噪点较多的缺点,不同种类物体之间边缘的提取更加精确。
3 结束语
本文针对遥感图像的语义分割,提出了一种基于DeeplabV3+模型的改进模型,在DeeplabV3+模型的基础增加了金字塔拆分注意力模块,同时将DeeplabV3+模型中的ASPP模块更改为了DenseASPP模块,得到了一种在语义分割上表现更加优异的模型。该模型在编码器阶段,通过金字塔拆分注意力模块,使得高级特征图有了更好的像素级注意力及更细粒度级别的多尺度空间信息。通过使用DenseASPP模块,使模型能够考虑更多像素,兼顾更大的感受野以及获得更多的尺度特征,同时解决了空洞率增加导致卷积失效的问题。相较于原模型以及其他常用的语义分割模型(FCN、U-Net、SegNet),该模型有着更加高的准确率。
但是新模型仍有以下问题需要解决。首先是阴影对分割的结果影响仍然存在,在阴影严重的区域,模型不能很好地识别出地物的种类;其次是受到图像本身的限制,二维图像不能很好地体现出物体本身的高度特性,导致模型不能很好地识别树木与较矮的灌木之间的差异;最后是各类物体的边缘与真实情况之间仍存在一定的差异。
