基于预训练语言模型的早期微博谣言检测*
2023-08-31冯茹嘉张海军潘伟民
冯茹嘉 张海军 潘伟民
(新疆师范大学计算机科学技术学院 乌鲁木齐 830000)
1 引言
随着网络的迅速发展,各种社交软件蓬勃发展。新浪微博作为一种共享、开放、便捷、及时的媒介,成为人们发布和传播信息的重要渠道。新浪微博的月活跃用户已达5.86亿,用户数量庞大且类型跨度较大,使其成为社会谣言传播的主要渠道之一。谣言泛滥问题在微博上十分普遍,给人们的日常生活带来了困扰,影响了社会的稳定。因此,针对微博谣言的检测具有重要的现实意义。
当前自动识别谣言的方法主要包括:1)基于机器学习的方法:通过构建分类器来对文本或多媒体内容进行分类,判断其是否为谣言。2)基于社交网络分析的方法:通过分析社交网络中的信息传播路径和影响力,来判断某个信息是否为谣言。3)基于自然语言处理的方法:通过对文本数据进行处理和分析,提取其中的特征和模式,来判断其是否为谣言。4)基于知识图谱的方法:通过构建知识图谱,将已知的真实信息和谣言信息进行关联和比较,从而判断新出现的信息是否为谣言。5)基于深度学习的方法:通过利用深度神经网络结构对文本、图像等信息进行自动识别和分类,来判断其是否为谣言。
本文提出了一种基于预训练语言模型的早期微博谣言检测方法。首先分别使用ELMO、BERT和XLNet的预训练模型对谣言数据进行预训练,然后将预训练后的结果作为模型的初始参数,并利用Transformer 编码器学习微博谣言数据的深层语义特征,最后通过softmax 函数得到谣言的分类结果,并比较三种预训练方式在谣言检测任务中的效果。
2 相关研究工作
目前针对谣言检测任务,大多数研究者将其视为一个二分类问题。谣言检测方法经历了基于传统手工特征提取和基于深度神经网络模型的两个发展阶段。
早期的谣言检测工作主要侧重于寻找高区分度的特征,基于特征选择构建分类器。文献[1]通过Twitter 数据提取四类特征,并进行特征选择,之后基于选择后的特征构建J48 决策树分类器,最终模型的分类效果良好。Qazvinia[2]则通过提取用户行为特征与深层文本语义特征相结合,使用贝叶斯分类器进行谣言分类。而Kwon 等[3]则强调了谣言数据中情感词汇特征和时间特征的重要性,并构建了时间序列模型,最终在召回率上得到较大的提升。Yang[4]等基三方面特征:地理位置、用户特征和内容特征,基于新浪微博数据集,利用支持向量机构建了谣言检测模型,准确率为78.7%。
基于深度神经网络模型的谣言检测方法克服了手工特征提取的局限性,具备自动学习深层特征的能力。Ma 等[5]按照时间序列,对每一个事件下的微博进行建模,使用循环神经网络,捕获文本隐藏表示,实现了较好的分类性能。文献[6]引入用户行为特征,提出一种结合自动编码器构建的循环神经网络模型,提高了谣言检测性能。Yu等[7]指出RNN 在谣言早期检测方面的不足,并使用卷积神经网络(CNN)构建谣言检测模型,在早期检测任务中表现出良好的效果。文献[8]提出一种CNN+GRU 的谣言检测模型,通过句向量化提取微博数据的局部和全局特征,实现了微博谣言检测并取得了良好的识别性能。
3 谣言模型的预训练
早期的词向量表示方法是一种静态文本表示,仅将下游任务的首层初始化,而其余网络结构仍需从零开始训练,这种预训练方法对深层语义信息的表达力不足,此外,传统文本处理方法难以解决词语歧义问题。相比之下,预训练语言模型通过在多层网络模型上进行预训练,可以为下游任务的多层网络模型提供更好的初始化。这不仅大大提高了模型的训练速度,还使得深层语义信息的表达能力得到优化。作为一种动态的学习词向量方法,预训练语言模型会根据上下文语境动态调整词向量的表示,增强了词向量表示的泛化能力,有效地解决了多义词的词向量表示问题。
本文通过多种预训练语言模型对微博数据进行预训练,并用以初始化下游的谣言检测任务,同时学习微博数据浅层语义信息和深层语义信息,对歧词进行准确的词向量表示,加快谣言检测模型的训练速度,提高谣言检测的精确率。

图1 基于预训练语言模型的早期微博谣言检测方法流程图
3.1 基于ELMO预训练方法
ELMO[9]属于一种自回归语言模型(autoregressive),通过两次带残差的双向LSTM 来构建文本表示,利用前向LSTM 捕捉上文词义信息,后向LSTM捕捉下文词义信息,消除了词语歧义。对于由N个单词组成的序列,预测第k 个词的前项LSTM 模型预测概率可表示为
预测第k 个词的后项LSTM 模型预测概率可表示为
优化目标为最大化对数前向和后向的似然概率:
其中,Θx表示映射层的初始共享参数,和表示长短期记忆网络前向和后向参数,ΘS表示softmax 层的参数。
对于第k个单词在L层的双向LSTM语言模型,共有2L+1个表征:
最终第k个单词的通过ELMO模型得到的文本表示为
γtask是缩放系数,允许任务模型去缩放整个ELMO向量,是softmax标准化权重。
3.2 基于BERT预训练方法
BERT[10]属于一种自编码语言模型(autoencoding),利用Transformer 编码器实现了双向信息融合,通过将多个Transformer Encoder 层层堆叠实现了BERT 模型的搭建。BERT 模型包含三个嵌入层:字嵌入、文本嵌入和位置嵌入,BERT 模型将三者的加和作为模型输入,如式(6)所示:
其中,E 表示模型输入,Esegment表示字向量,Eposition表示文本向量,Etoken表示位置向量。如图2所示,一条谣言文本“喝高度白酒可预防新冠病毒”输入后,经过三个嵌入层后,再将其作为Transformer的输入向量。
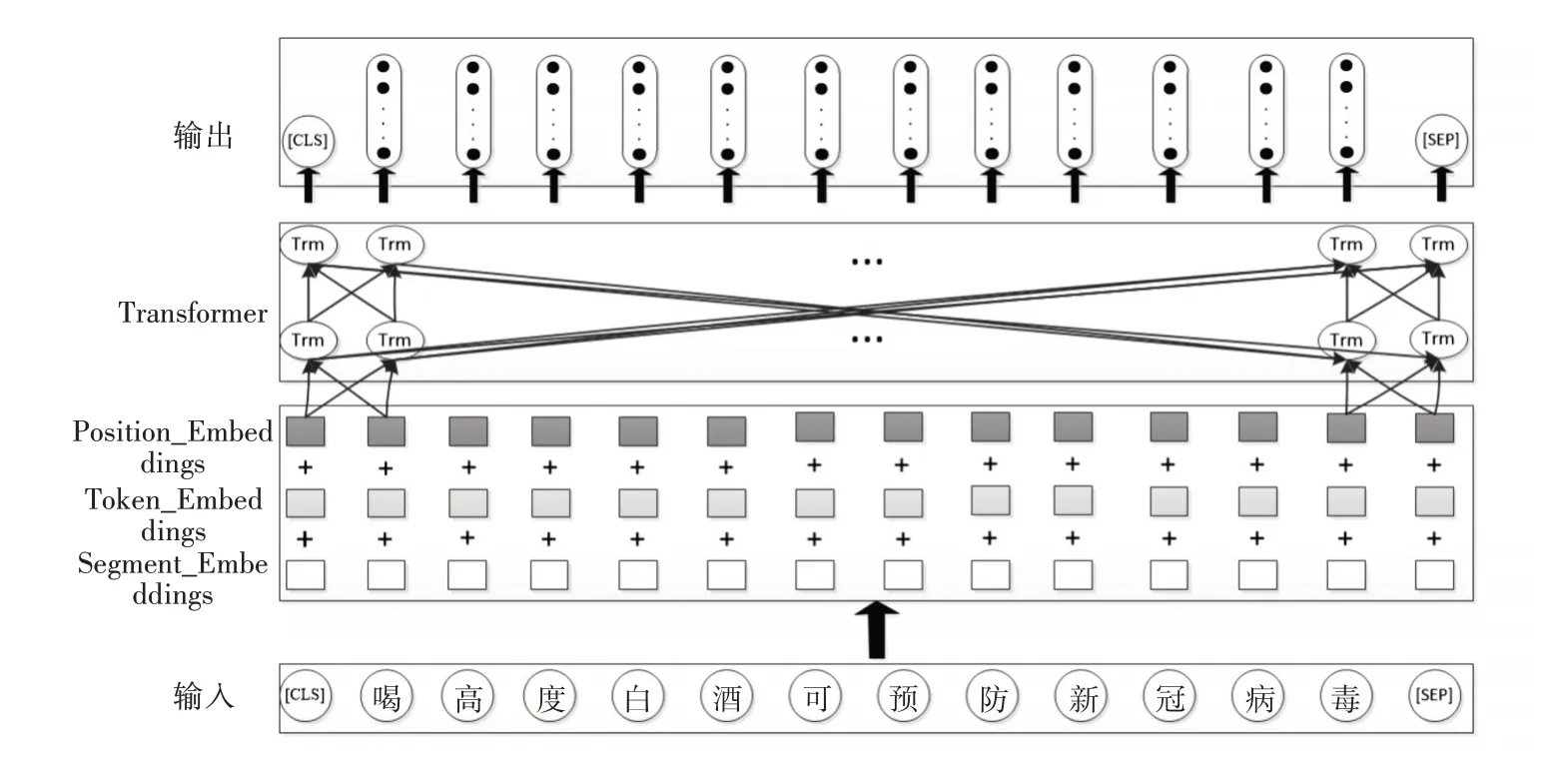
图2 BERT模型图
BERT 作为一种预训练语言模型,它使用大规模文本语料进行模型训练,逐步优化模型参数,使得模型输出的文本语义表征更加契合自然语言的本质。为完成预训练,BERT进行了两个监督任务:Masked LM和Next Sentence Prediction。
Masked LM 任务可以类比为完形填空问题,即在给定的句子中,随机遮盖一定比例的词语,然后通过剩余的词汇来预测被遮盖的词语。这个任务使得模型需要去理解上下文,从而更好地进行词汇预测和语言生成。对于在句子中被覆盖的词汇,其中只有10%依旧保持原词,10%替换为一个任意词,剩余80%采用一个特殊符号[MASK]替换。这将赋予模型一定的纠错能力,迫使模型在预测词汇时更多地依赖于上下文信息。
Next Sentence Prediction 任务可以理解为段落重排序问题,通过给定一篇文章中的两个句子,来预测是否为该文章中的前后两句。在实际预训练过程中,通过50%正确原始上下句和50%原始上句搭配随机下句来学习句子间的关系。
BERT 模型通过联合训练上述两个任务,进一步提高了模型在自然语言处理任务中的表现。通过联合训练这两个任务,BERT 模型不仅能够优化模型输出的词向量表达能力,还能为下游任务提供更加准确的参数初始化,从而取得更好的性能。因此,BERT 模型目前被广泛应用于各种自然语言处理任务中,并取得了非常显著的效果。
3.3 基于XLNet预训练方法
XLNet[11]是一种泛化自回归语言模型,它融合了自回归语言模型和自编码语言模型的优点,并避免了它们各自的局限性。与传统语言模型只能在一个方向上捕获语义不同,XLNet 可以实现双向语义理解,XLNet采用的是Permutation Language Model(PLM)方法,即将文本序列分解为若干排列序列,并在每个排列序列上执行语言建模任务。具体而言,XLNet 先通过一个置换函数生成一个随机的排列序列,然后利用该排列序列和其他信息来建立条件概率模型,对当前位置的单词进行预测。这样,每个位置都能够利用整个序列的信息进行预测,从而消除了BERT 中的独立性假设问题,使得模型能够更好地捕捉序列中的双向依赖关系,提高了模型的性能和泛化能力。
例如当给定一个谣言文本x={x1,x2,x3,x4},来预测x3时,使用一种序列语言建模目标,文本序列的排列方式应该有4!种,但为了减少时间消耗,实际只能随机的采样4!里的部分排列,比如:2→3→4→1,3→2→1→4,1→4→3→2,4→2→1→3。下面展示了分解方式为1→4→3→2的图示。
如图3 所示,当预测x3时可以充分利用到x1和x4的信息,而看不到x2的信息。当遍历完上述4 种排列方式后,模型就能获得所有的上下文信息,从而实现双向语义的同时获取。此外,需要注意的是,输入依然是原始句子的顺序,而序列的排列则通过Attention Mask 来实现。在编码x3时仅让它依赖于x1和x4的信息,而把x2的信息[masks]掉。
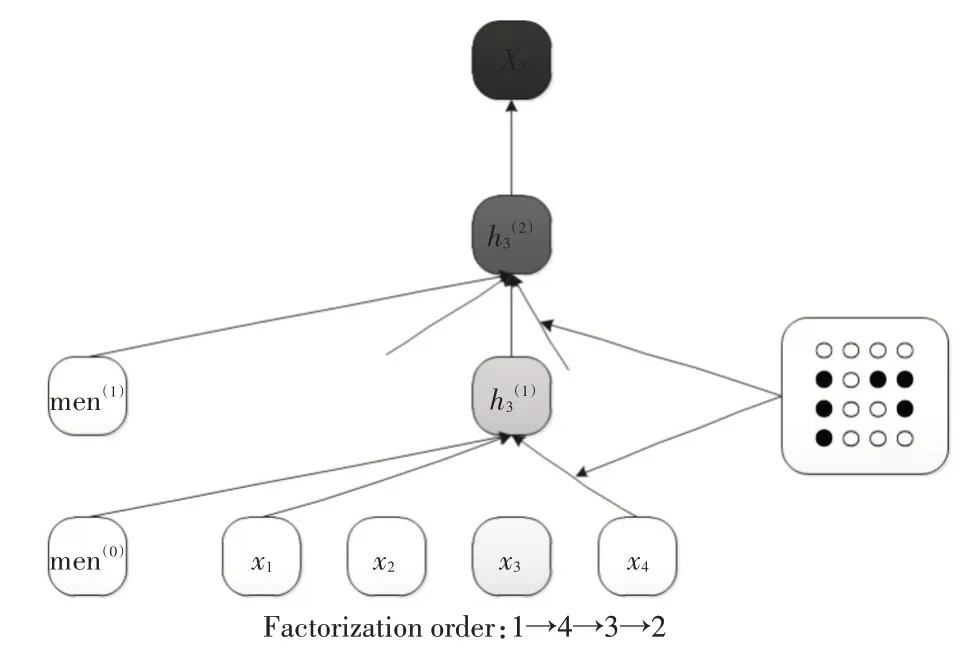
图3 排列语言模型图
最终优化目标如式(7)所示:
其中,用zt表示第t个元素,z ≤t-1 表示z的第1 到第t-1个元素。z是集合ZT的其中一种排列方法,ZT表示所有排列方式的集合。
4 基于BiGRU-MHA 模型的微博谣言检测模型
本文通过融合了多头注意力机制(Multi-head self-Attention mechanism,MHA)的双向GRU 网络模型来实现微博谣言检测。双向GRU 网络对学习句子序列特征有非常好的效果,多头注意力机制可实现对全局范围内的文本上下文深层语义特征的提取,因此,二者的结合有助于全面理解文本信息,从而更好地实现微博的谣言识别任务。
4.1 双向GRU网络
门控循环单元是循环神经网络的一种变形,它加入了两个门控信号:更新门和重置门。更新门判断当前词是否要带入到下一个状态中;重置门用来控制当前词的是否被忽略,当重置门越小时,前一时刻的信息被忽略程度越大。
本文通过输入特征向量的正序,利用前向层的GRU 神经网络,得到前向的特征向量,输入基本特征向量的逆序,利用后向层的GRU 神经网络,得到后向的特征向量,将前向特征向量和后向的特征向量进行融合,得到文本特征向量;即为双向GRU 网络的隐藏层状态,如以下公式所示:
4.2 多头注意力机制
将长度为n 的微博文本词向量表示为x={x1,x2,…,xn},xi为微博文本x 中的第i 个词向量。自注意力机制是通过一系列加权计算,学习微博文本的内部依赖关系。构建Q(Query Vector)、K(Key Vector)、V(Value Vector)三个矩阵进行线性变换,获取多组注意力值,然后将注意力值拼接输出,如以下公式所示:
Q、K、V 分别表示查询、键和值矩阵,用于将原始词向量映射到子空间中,并用softmax 函数的归一化处理,得到了最终的注意力数值。其中dk是querie和key的维度,除以的目的是防止梯度消失。
多头注意力就是对输入的Q、K和V进行h次线性映射,头之间的参数不共享,每次Q、K、V 进行线性变换的参数W不一样,再对线性映射后的结果进行加权计算,将h 个注意力结果连接并输出,即为多头注意力向量表示:
本文将双向GRU 网络输出向量Ht作为多头注意力机制的输入向量,并与融合注意力机制的权重向量,实现谣言的分类,具体过程如下:
首先生成权重向量:
使用softmax 函数对权重矩阵做归一化处理:
α=softmax(W) (15)
最终注意力值可表示为
A(Ht)=αHt(16)
最后,微博谣言文本特征向量可表示为
h*=tanh(A(Ht)) (17)
5 实验
5.1 实验数据集
本实验数据主要基于Ma 等[5]在2016 年公布的社交媒体谣言检测数据集中的新浪微博数据,另外通过新浪微博API爬去了309条新型冠状肺炎话题数据,共包含4973 个事件,其中谣言事件2622条,非谣言事件2351,每条数据均已标注,每个事件中又包含有若干条微博,总数据集共包含4050456条微博。
5.2 模型训练设置
谣言检测模型包含四个层次:嵌入层、双向GRU 网络层、多头注意力机制层和输出层,其中嵌入层与双向GRU 网络层迁移预训练语言模型相应层的参数,采用Frozen和Fine-tuning的迁移学习方法。在Frozen 方法中,冻结预训练层,不再更新参数,而在Fine-tuning 中,对预训练层进行微调。而多头注意力机制层和输出层,都从头训练网络参数。
采用tanh 函数作为激活函数,训练序列长度batch_size 设为64。实验基于Python 3.5 及其库(Keras-gpu)软件平台实现,使用Adam 优化器,学习率为0.001,迭代次数为20。
5.3 实验结果与分析
5.3.1 与传统词嵌入方法实验结果对比
本实验采用word2vec获取词向量,并作为BiGRU-MHA 模型的输入向量,以此作为对比实验,对比预训练语言模型对谣言检测任务的效果。分别与ELMO+BiGRU-MHA 模型、Bert+BiGRU-MHA 模型和XLNet+BiGRU-MHA模型做实验对比,对比结果如表1所示。
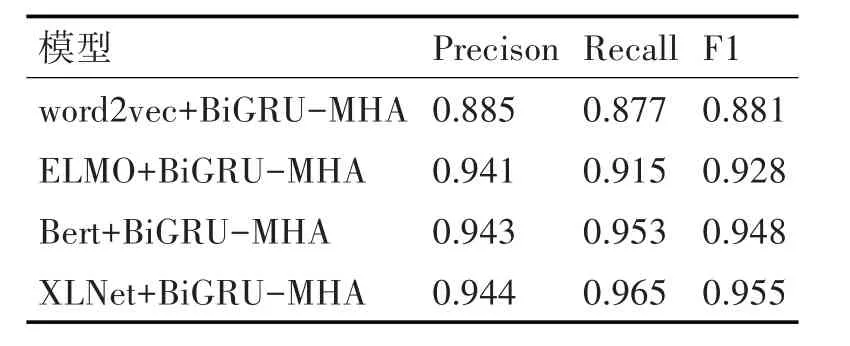
表1 传统词嵌入方法的实验结果对比表
通过与传统词嵌入方法相比,加入预训练模型后有了更强大的语义表示,能捕捉更丰富的语义信息,对于长距离依赖以及多义词的理解和表达更有效;预训练模型为每个词生成基于上下文的嵌入向量,而word2vec 产生静态词向量,不能区分同一单词在不同上下文中的意义;通过在大规模语料库上进行预训练,模型能够学到通用的语言知识,结合少量标注数据进行微调,可以在特定任务中取得较好的性能。
5.3.2 与基准方法的实验结果对比
本文选取了在当前谣言检测任务中具有代表性 的 四 种 方 法:DTC 模 型[1]、SVM-RBF 模 型[3]、GRU-2 模型[5]和CAMI 模型[7],作为本文的对比基准实验,实验结果如表2所示[17]。
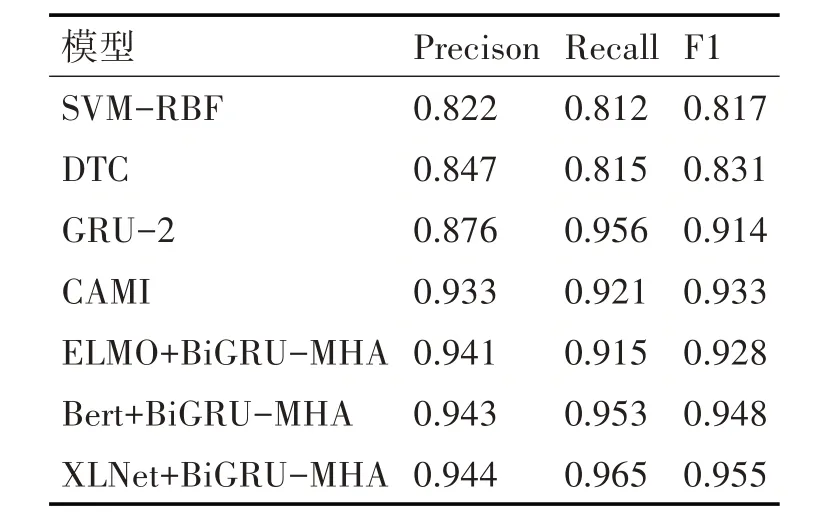
表2 与基准方法的实验结果对比表
SVM-RBF和DTC模型是基于传统的机器学习构建分类器的方法,从表2 中可以看出,预训练模型能自动从文本中抽取丰富的特征,而传统机器学习方法通常依赖手工设计的特征或浅层次特征表示;此外,预训练模型通常具有更好的长文本处理能力。例如,BERT 使用Transformer 结构,对长距离依赖关系的捕捉更有效。GRU-2 和CAMI 模型是基于神经网络的方法,由表2 数据可知,与通用深度神经网络相比,预训练模型更容易实现端到端训练,直接从输入文本到分类结果进行优化,减少了中间环节的不匹配问题,并且预训练模型在大量无标签数据上进行预训练,捕获了丰富的语言知识,从而在特定任务上具有很好的起点和优势。
而本文所提出的三个谣言检测方法,均不逊于基准方法,甚至效果更佳,因此可以证明在深度神经网络的基础上加入预训练语言模型将使得模型性能更优。
5.4 预训练语言模型对早期谣言检测结果的影响
本文使用了三种预训练语言模型对谣言检测数据分别进行了预训练,为了验证它对早期谣言检测实验结果的影响,本文选择了GRU-2 模型作为对比实验,设置了一系列的检测截止日期,并且在测试过程中只使用从谣言初始散播时间到相应截止时间的微博数据。
图4展示了本文所提出的三种方法与GRU-2模型在不同截止日期下的谣言识别性能。ELMO+BiGRU-MHA 模型、Bert+BiGRU-MHA 模型和XLNet+BiGRU-MHA 模型均可以在较短的时间内达到较高的精度,而GRU-2模型大约在48h后才能达到较好的效果。此外,XLNet+BiGRU-MHA 模型的F1 值在任何阶段都处于领先地位。由此可说明,预训练语言模型对早期谣言检测起到重大作用,对于更早的识别谣言从而遏制谣言散播有实用效果。
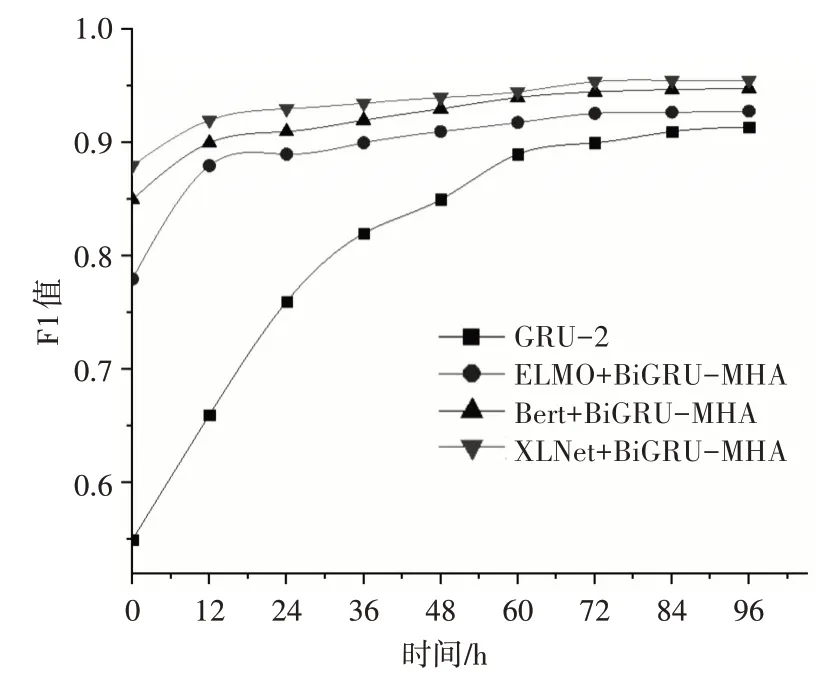
图4 早期谣言检测性能图
6 结语
本文提出了一种基于预训练语言模型的微博谣言检测方法,该方法选用了ELMO、BERT 和XLNet 对微博数据进行预训练,提高了模型的训练速度,增强了词向量表示的泛化能力,优化了深层语义信息的表达能力,解决了一词多义情况的词向量表示问题。采用了BiGRU-MHA 模型对下游任务进行学习,该模型能够有效地捕捉句子中的语义信息,包括上下文关系和语境信息,多头注意力机制能够让模型自动学习哪些部分是重要的,并加强对相关信息的关注;BiGRU模型能够处理句子中的前后关系,从而更好地把握句子的含义;模型能够同时考虑不同层级的信息,提高了模型的准确性和鲁棒性。
在未来工作中,由于许多谣言具有图片加文本或视频加文本的形式,大大提升了谣言的煽动性,本文将考虑加入多模态的数据对模型进行测试,以此增强模型的适应性。
