基于统计特性的隐写密钥恢复方法*
2023-08-31郭微光李佳临徐明迪
郭微光 李佳临 徐明迪
(1.91001部队 北京 100841)
(2.武汉数字工程研究所 武汉 430205)
1 引言
信息隐藏是将信息嵌入到载体的冗余部分中,以不被察觉的方式进行秘密消息传输,从而实现隐蔽通信的一种技术。从古希腊战争、一战、二战到美俄间谍战、俄乌网络战,信息隐藏技术伴随人类军事、政治斗争的历史不断发展[1]。作为信息隐藏技术的重要分支,数字图像隐写技术将秘密信息隐藏在图像的视觉冗余部分并通过公开信道进行传输,既保护了通信内容的安全性也保护了通信行为的隐秘性[2]。隐写分析技术主要研究数字载体中秘密信息的检测和提取,其中秘密信息的提取是隐写分析技术面临的重要挑战和最终目标[3]。研究图像自适应隐写算法隐秘信息提取方法有助于及时发现非法隐蔽通信行为、获取非法通信内容,对维护网络环境的安全有所帮助。
隐秘信息提取的关键是找到隐写密钥。图像自适应隐写算法利用隐写密钥将秘密信息嵌入图像纹理复杂区域,抗检测性和抗提取性得到了提高[4~5]。当嵌入的信息为明文时,文献[6]提出了一种基于游程检验的隐写密钥恢复方法,利用明文和密文的随机性差异,对编码的子校验矩阵进行编码参数的盲识别。文献[7]从理论上分析了“选择载密对象”和“信息重复发送”两种条件下的隐写密钥恢复的可行性。文献[8]提出了在部分信息已知的场景下隐秘信息提取的方法,该方法基于编码的矩阵变形和方程求解,实现了隐秘信息提取。文献[9]给出了消息重复发送和密钥重复使用的条件下隐秘信息提取的方法。文献[10]提出了一种基于最优STC译码路线的隐秘信息提取方法,在已知载体图像条件下,实现隐写密钥的恢复。
在实际的隐蔽通信中,发送者可以使用数字隐写技术来传输未经加密的隐秘信息,如图1 所示。发送方使用隐写密钥通过STC 编码将隐秘信息嵌入载体图像中,利用公开信道进行传输,接收方使用隐写密钥通过STC 译码即可提取隐秘信息。在隐秘通信过程中,攻击者可在公开信道中获取可疑图像。对于空域明文嵌入,文献[6]中基于游程检验的隐写密钥恢复方法可能会将伪隐写密钥误判为真隐写密钥。因此,需要寻找校验矩阵所对应的译码序列中更能区分真伪的统计特征。本文通过对明文信息的统计分析发现,各个位平面的概率分布有差异。基于此,本文提出一种基于统计特性的隐写密钥恢复方法,该方法根据译码序列对应的子序列特征进行隐写密钥的识别。实验结果证明了本文方法能够缩小识别密钥空间的范围,提高识别自适应隐写编码参数的准确度。
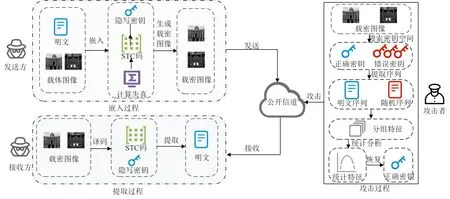
图1 明文嵌入条件下的隐蔽通信过程和隐写密钥恢复过程
2 STC编译码
传统的空域图像隐写算法通过对载体图像像素灰度值进行修改来实现信息的嵌入,而自适应隐写是根据载体图像的内容自适应选取合适位置并结合编码进行嵌入[11]。Filler等[12]提出的STC(Syndrome-Trellis Codes)编码具有使总体嵌入失真接近理论最小值的特点,效率高且性能好,已成为大多数自适应隐写算法的首选编码。空域自适应隐写算法如HUGO[13]、WOW[14]等,都是采用不同的失真函数结合STC 编译码来实现隐秘信息的嵌入和提取。STC 编译码的原理大致如下:定义载体序列为x=(x1,x2,…,xn)∈{0,1}n,载 密 序 列 为y=(y1,y2,…,yn)∈{0,1}n,m为待嵌入的隐秘信息,STC码的编码和译码的过程如式(1)、(2)所示:
其中,D(x,y)为嵌入失真函数,C(m)={z∈{0,1}n|Hz=m}表示待嵌入信息m的陪集,H∈{0 ,1}m×n为STC编码中使用的校验矩阵。由式(1)可知,STC编码的过程就是寻找满足Hy=m的向量y,且使得嵌入失真D(x,y)最小。从式(2)可以看出,正确的校验矩阵H结合载密序列可计算得出载密序列中的隐秘信息。因此校验矩阵H可看作基于STC编码的自适应隐写算法的隐写密钥。
校验矩阵H是由h行w列的子校验矩阵按照主对角线的顺序依次排列而成。子校验矩阵的高度h和宽度w为尺寸参数,数据的取值称为内容参数。宽度w与嵌入率α有关,若存在正整数k满足α=1k,则选取w=k,校验矩阵H由宽度为w的子校验矩阵H沿主对角线排列组成;否则寻找正整数k满足不等式1 (k+1)<α<1k,此时校验矩阵H由宽度为w1=k和w2=k+1 的两种子校验矩阵H1和H2按照主对角线的顺序交替排列构成。子校验矩阵的高度h影响编码的效率,通常取值6 ≤h≤15。
由于图像自适应隐写算法采用编码的方式嵌入隐秘信息,采用隐写编码使得嵌入信息的过程和图像的所有像素有关,弱化了载密序列和隐写密钥之间的关联性,导致针对传统隐写的密钥恢复方法不再适用,因此需要寻找自适应隐写的隐写密钥恢复方法。基于上述分析,隐秘信息的提取关键在于隐写密钥的恢复,而隐写密钥的恢复归结于校验矩阵的识别。本文方法通过对不同校验矩阵所对应的译码序列进行分析,基于不同位平面的概率分布来区分真伪隐写密钥。
3 基于统计特性的密钥恢复方法
由STC编码方法的原理可知,嵌入信息长度和子校验矩阵是STC编码过程的重要参数,也是通信双方需要共享的信息。隐写密钥的恢复相当于校验矩阵的识别。如果识别出了正确的自适应隐写的校验矩阵,便可以通过STC译码方程求得译码序列,即嵌入的隐秘信息。由于明文信息嵌入载体图像时需要转化为二进制,因此可以通过二进制信息的特点来判断译码序列的真伪。
下面首先给出本文提出的明文嵌入条件下隐写密钥的恢复方法的原理框图和实现步骤,然后详细介绍其中的关键步骤的具体实现方法。
3.1 基本原理及主要步骤
隐秘信息提取过程的关键在于STC 编码参数识别,通过构建编码参数表、搜索编码参数、获取译码序列、检验正确性等步骤来识别自适应隐写所用的密钥。明文嵌入下自适应隐写的隐写密钥的恢复方法原理框图如图2所示。
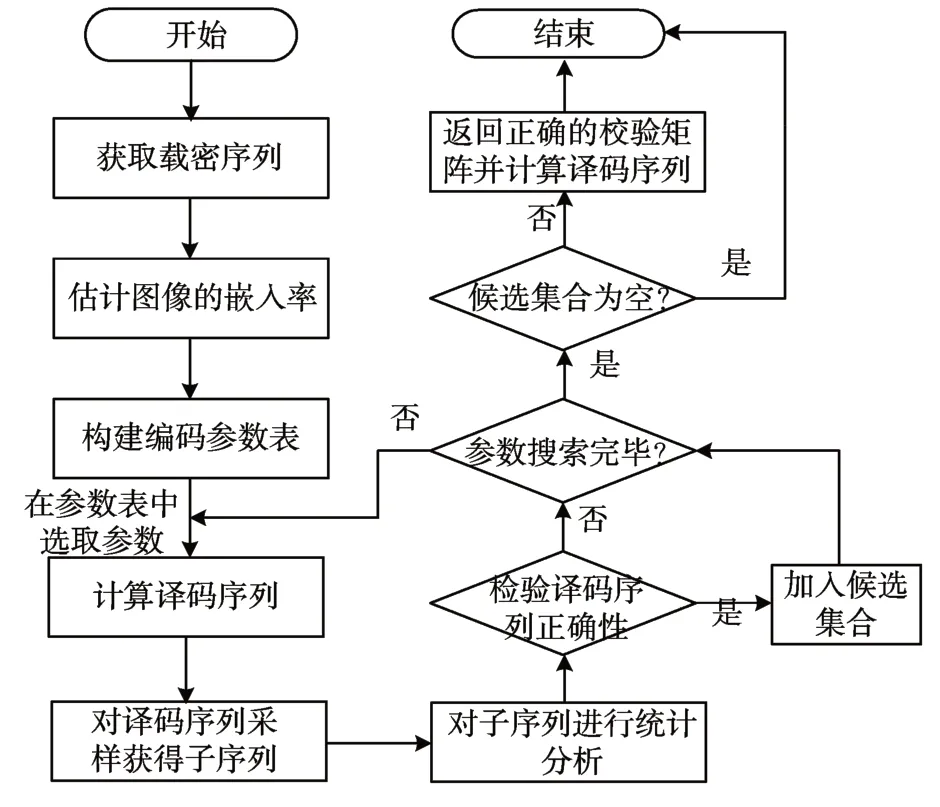
图2 明文嵌入下自适应隐写的隐写密钥的恢复方法
隐写密钥的恢复方法具体步骤如下:
1)获取载密序列。读入待检测的载密图像,根据载体序列的生成次序来获得载密序列。本文研究采用无置乱时的图像自适应隐写,对待检测的载密图像依此扫描其像素值,取出其最低比特位得到载密序列。
2)估计图像的嵌入率。STC 码中校验矩阵的编码参数与嵌入率有关,对待检测图像的嵌入率进行估计,结合误差分析确定待提取的载密图像可能的嵌入率范围,初步确定隐写密钥的结构。
3)构造编码参数表。编码参数表是进行隐写密钥识别和消息提取的重要基础。对隐写参数的取值范围进行估计,如子校验矩阵的高度、宽度以及可能的取值,将每种嵌入率及其对应的所有子校验矩阵关联组合起来,形成由子校验矩阵组成的编码参数表。
4)搜索编码参数表中的子校验矩阵并计算译码序列。在选取子校验矩阵时,按照从小到大的顺序对编码参数表中的子校验矩阵依次进行搜索。将子校验矩阵沿对角线依次排列,得到校验矩阵,利用校验矩阵和载密序列进行译码,得到译码序列。
5)对译码序列进行采样获得子序列。对译码序列的前8 比特,分别每间隔7 位取出来的比特组成一个子序列,可以得到8条子序列。
6)对译码子序列进行正确性检验。对于当前得到的译码子序列进行正确性检验。对子序列中0、1 的字符数出现的情况进行统计分析,判断子校验矩阵正确与否。
7)返回正确的校验矩阵并计算译码序列。若对子序列的检验过程未通过,则继续对编码参数表中的子校验矩阵进行搜索。当某一矩阵通过正确性检验时,将该校验矩阵加入候选集合直至参数表搜索完毕。对候选集合中的校验矩阵执行译码操作,并返回完整的嵌入消息。
3.2 获取译码序列并进行采样分组
载体图像的LSB 中的0、1 比特的统计特性近似于均匀分布,将明文秘密信息以自适应隐写方式嵌入之后会破坏这种平衡。STC 译码利用Hy=m计算出秘密信息,通过子校验矩阵结合载密序列可以得到对应的译码序列。对译码序列分别从第i(i=1,2,…,8) 位每隔7 位进行采样,获得8 条子序列,分别记作L1,L2,…,L8。若译码序列是正确的秘密信息,则8 条子序列分别对应着明文秘密信息的各个比特位的信息。
3.3 译码序列正确性检验方法
3.3.1 真隐写密钥对应译码序列的统计特性
在计算机中,英文字符以字节形式存储,汉字以双字节形式存储。根据对大量英文和中文字符的使用情况的统计,可以得到英文字母和中文汉字的出现频率表。依据英文的二进制表示,分别对不同比特位上0和1的出现概率进行计算分析。文献[15]对自然语言中英文的使用情况进行统计,得到英文字符的使用情况,由此可以得到大文本中英语各个字母出现的频率表,见表1。
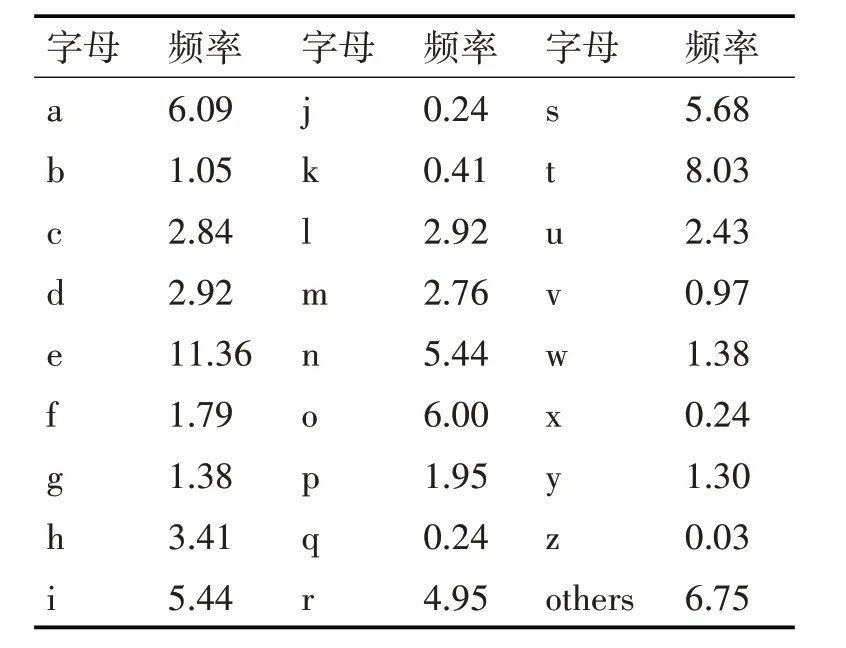
表1 大文本中英文字符的相对频率
根据英文字母的二进制表示,由表1 中的数据可以分别计算出每个位平面对应的0 的出现概率。位平面1 对应最低比特位平面,位平面8 为最高比特位平面,各个比特位平面中“0”出现的概率分布见表2。
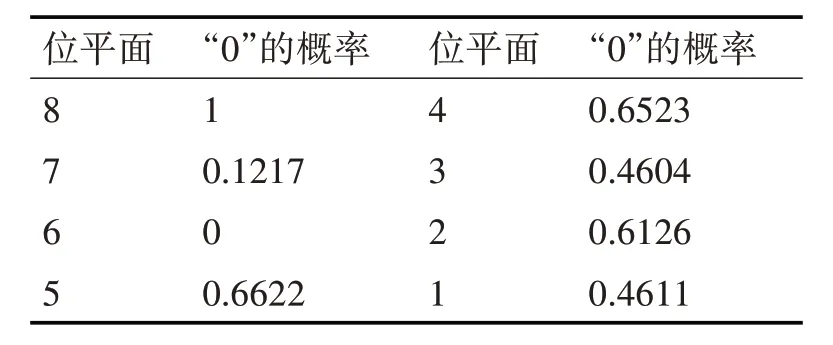
表2 各个位平面中“0”的概率
由表2 可知,各个位平面中0 和1 出现的概率不相同,最高比特位平面对应比特0的概率为1,第6 比特位平面比特0 出现的概率为0。因此想到可以依据不同位平面的统计概率差异识别真伪隐写密钥。
3.3.2 伪隐写密钥对应译码序列的统计特性
当子校验矩阵选择正确时,提取的信息为嵌入的隐秘信息,当子校验矩阵选择错误时,提取的信息为随机序列。经过对伪隐写密钥对应译码序列的实验结果分析,伪隐写密钥提取出的子序列中0、1概率的接近于相等。
3.3.3 根据统计特性进行检验
根据明文二进制序列的特点进行验证,如最高比特位序列L8,如果其中的比特“0”和“1”出现的频率较高,出现的概率大于0.5 且接近1,则其可能为英文明文对应的二进制序列。进而对其他子序列中的比特分布情况进行统计。以最高比特位对应的子序列为例,计算出子序列的各个比特出现的概率,来对译码序列进行判断。
则序列中比特“0”出现的概率为
通过对各个子序列中的比特进行统计分析,来进行判断。由于中英明文序列对应的比特0和1的分布具有一定的特征,因此若为正确密钥对应的译码序列,子序列也应具有此特征。若为错误密钥对应的译码序列,子序列为无序序列,比特0和1的分布比较均匀,为0.5 左右。因此可以根据此特征判断所得译码序列是否为明文嵌入下的秘密信息。
4 实验
4.1 实验设置
为验证本文提出方法的可行性,在如下环境中进行实验:Windows10 操作系统、CPU 为Intel i7、内存为8GB;编程语言为C/C++,集成开发环境为Visual Studio2015。
本实验从BOSSbase_1.01 库中随机选取100 幅空域载体图像,采用HUGO 隐写算法进行嵌入,嵌入信息为英文明文转化的二进制流,嵌入率为0.5bpp,生成载密图像。对于载密图像,依次扫描图像的各个像素,提取出各个像素的最低比特位构成载密序列。
4.2 隐写密钥的识别
对自适应隐写的隐写密钥恢复可看作是对载密图像进行编码参数识别,具体来说是对子校验矩阵的识别。在编码参数表中搜索子校验矩阵,由子校验矩阵组成校验矩阵,并利用校验矩阵和载密序列得到对应的译码序列。对译码序列从开始第一个比特起,每隔7 位选取一比特,组成一个子序列。依次类推,可以组成8 条子序列。分别对8 条子序列中比特0和1的个数进行统计。下面分两种情况对子校验矩阵的识别情况进行分析。
1)子校验矩阵选取错误
由上述子校验矩阵组成的校验矩阵和载密序列进行译码操作后,对相应的译码序列进行采样分组,并统计分析。子校验矩阵识别错误时,各子序列中出现比特“0”的概率结果见表3。
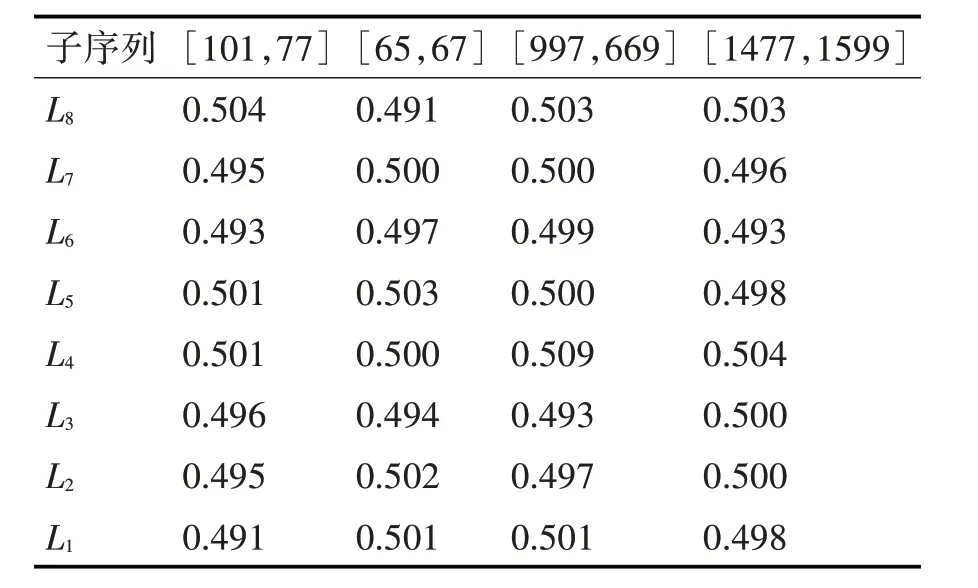
表3 错误子校验矩阵对应子序列中比特0的概率分布
如表3 所示,当选取的子校验矩阵的高度和宽度正确但取值不正确、子校验矩阵的高度错误、子校验矩阵错误时,获得的译码子序列中比特“0”的概率为0.5 左右,可以看出错误的子校验矩阵对应的译码序列中0 与1 的分布比较均匀,也证明了伪隐写密钥提取出的子序列是随机的,比特0 和1 的概率接近0.5。
2)子校验矩阵选取正确
入时使用的正确的子校验矩阵。使用该子校验矩阵进行译码过程,得到对应的译码序列,对译码序列进行采样分组。各个比特位对应的子序列统计比特“0”出现的概率,统计结果见表4。

表4 正确子校验矩阵对应子序列中比特0的概率分布
如表4 所示,使用正确的子校验矩阵进行译码计算,采样分组后统计比特“0”出现的概率。不同于矩阵错误时比特“0”和“1”均匀分布,“0”出现的概率出现了明显差异。子序列L8对应明文信息的最高比特位,比特0 出现的概率为1。子序列L6对应第6 比特位,比特0 出现的概率为0.0282 接近0。真隐写密钥对应的译码序列子序列的分布与英文字符二进制对应的位平面分布一致。
由上可知,通过对不同的子校验矩阵所得的译码序列进行分组统计,子序列中比特0 和1 的概率分布不同。对100 张载密图像进行译码后统计分析,正确的子校验矩阵=[109,71] 和错误的子校验矩阵=[101,77] 、=[1477,1599] 所得译码序列的各个比特位平面中比特“0”出现的概率如图3所示。
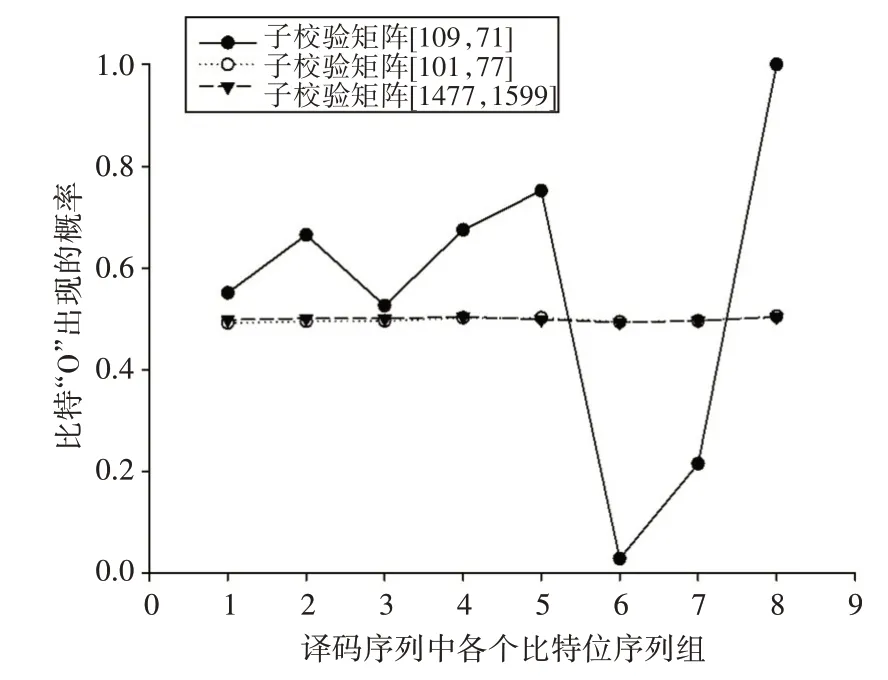
图3 译码序列中的各个子序列中“0”出现的概率
从图中可以看出,正确的子校验矩阵下对应的译码序列中0、1 比特的分布和自然语言中英文二进制位平面的统计概率有相似的分布,因此可以通过对译码序列中0、1 比特的分布情况来判断子校验矩阵的正确与否。
根据不同的子校验矩阵和载密序列所得译码序列的统计特性不同来对隐写密钥进行筛选和识别。由于英文明文嵌入时,最高比特位都为0,因此可以利用最高比特位的特点来进行筛选。与文献[6]中基于游程检验的方法进行比较,两种方法识别出的隐写密钥的个数和本文方法识别隐写密钥的正确率情况见表5。
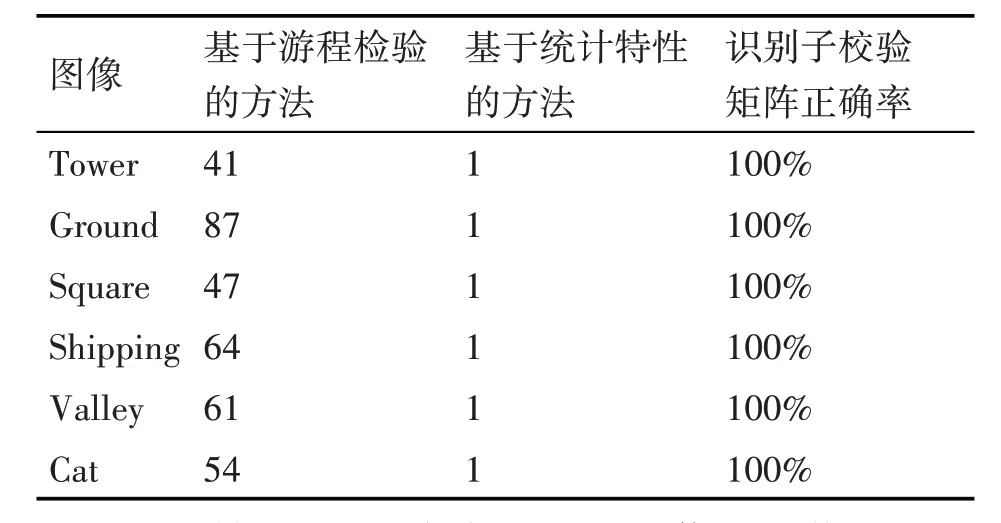
表5 本文方法与文献[6]识别出的隐写密钥个数比较
实验结果表明,当嵌入的秘密信息为英文明文序列时,本文方法可以唯一识别出自适应隐写使用的隐写密钥。基于游程检验的方法通过对译码序列的随机性进行判断来识别子校验矩阵,一些错误的译码序列被识别为非随机的,因此识别出多个隐写密钥。本文方法通过利用英文明文的统计特性进行筛选,识别出唯一正确的子校验矩阵,提高了密钥恢复的准确率。在实验的效率方面,本文方法和基于游程检验的方法都需要对子校验矩阵进行搜索,搜索过程占据了较多时间。因此在识别的效率方面,两种方法时间接近。在保持识别效率的基础上,本文基于统计特性的隐写密钥恢复方法提高了识别的准确率。
5 结语
针对明文嵌入条件下的载密图像,本文提出了一种基于统计特性的隐写密钥恢复方法。该方法利用校验矩阵和载密序列通过STC 译码方程求出译码序列,对译码序列进行采样分组,基于明文信息的统计特性对子校验矩阵进行识别。实验结果表明,该方法能够盲识别出正确的隐写密钥,与现有的盲识别算法相比,缩小了求解出的密钥空间的范围,更加精确地对编码参数进行识别。下一步工作将继续研究如何利用载密序列的特点缩小密钥空间,提高搜索效率。
