全流水线高速AES_GCM算法的FPGA优化设计
2023-08-29周清雷陈晓杰
赵 亮,李 斌,周清雷,陈晓杰
1(郑州大学 计算机与人工智能学院,郑州 450001)
2(数学工程与先进计算国家重点实验室,郑州 450001)
1 引 言
AES_GCM可视为AES算法的特殊工作模式,该模式提供加密和认证两种操作.常见的工作模式如AES-EAX和AES-CCM等模式因为只能采用串行的方式实现,所以只适用于中低速网络的场景;AES-CWC虽然适用于高速网络,但其包含127bit整数乘法,电路开销过大;AES-ECB模式在安全性方面存在泄漏明文的风险等.AES_GCM是一种可以保证数据保密性和信息完整性的算法模式[1],并且其加密过程可以基于并行或流水线技术实现,由于其出色的性能和较低的计算时延,可以被广泛应用于无线网络、光纤通信等领域.
当下,随着高速以太网的不断发展.高速通信网络的所面临的安全问题及需求日益凸显,不仅需要保护传统通信数据安全,更需要在100G网络的特点及背景下,确保在云端存储与传递、含有大量隐私信息数据的安全[2].
因此为了保证高速网络服务对于速度与高安全性的需求,同时对信息的来源进行认证,本文提出了一种全流水线架构优化的AES_GCM高速加密电路,利用FPGA可重构的特点[3],以流水线技术实现AES算法,以Karatsuba乘法器和快速求余优化GHash算法,并设计了具有较高自安全性的SBox模块,从而进一步满足100G网络的安全需求.
2 相关工作
随着网络业务流量增速、用户需求的不断加快和增长,其已经超出万兆以太网的能力范围,这不得不使研究者们加速推进100G以太网络的相关研究进程.针对100G以太网的应用环境及面临的安全问题,以及高速通信网络以高效可靠为目标的特点,需要对AES_GCM算法进行优化.
AES_GCM算法中P代表明文,Key表示密钥,IV表示初始向量,A为附加认证数据;输出为密文C和认证标签T.首先,对128bit的0加密得到哈希算子H存在寄存器.然后,利用哈希算子对A进行乘加运算,运算结束后,AES对初始向量IV加密,然后,加密的结果与明文P异或得到C;中间变量X,通过附加数据A乘加运算后再和密文进行乘加运算得到;X与IV加密结果异或,最后得到认证标签T.
对于AES算法,Chi-Jeng Chang等人[4]采用循环结构的32bitAES加密电路,吞吐率为876Mbps,资源消耗156个Slices,性能为5.16Mbps/slices,但吞吐率低于10Gbps,不适合高速接入网应用;M.Vanitha等人[5]采用展开结构对AES电路轮变换的内部进行流水线划分,吞吐率为22.89Gbps,资源消耗为14.522K个Slices,但电路性能仅为1.58 Mbps/slices;Harshali Zodpe[6]等提出了一种利用PN序列生成器生成SBox值和加密所需初始密钥的新方法,在XC6SLX150设备实现的最高频率为237.45MHz,吞吐量为30.39Gbps,但电路复杂度较高.
Karatsuba等人首次提出在实现有限域乘法器上有着较高效率的KOA算法,之后,Deepak Kapoor等人[7]结合KOA和移位相乘,设计了一种混合乘法器,有效降低了运算复杂度; Karim M等[8]从电路效率出发,提出基于流水线的GHash电路,吞吐率可达36.92Gbps,资源消耗7.74Mbps/Slices;Kavund等[9]提出针对DSP片和BRAM块优化的AES-GCM架构.
由上,可以结合FPGA的灵活性、并行性和集成性[10],对GHash结构进行优化,以减少电路资源消耗,保证电路吞吐率和效率.此外,对FPGA进行区域优化划分,从而使流水线的效果尽可能达到最优,满足高速网络的需要,保证高速网络安全、完整的传输数据.
3 算法分析及优化
3.1 AES算法及优化
AES加密算法的流水线实现,主要包含密钥扩展(Key extension)和轮变换(Round transformation).其中,以初始密钥作为基础的密钥扩展生成每一轮所需的轮密钥;轮变换包括字节代换、行移变换、列混合变换和密钥加法.
3.1.1 密钥扩展
将输入的128bit的key,经循环左移、字节替换、异或、缓存结果4级流水运算后,产生本轮的输出,并作为下一轮的输入,具体步骤如表1所示,其是以密钥矩阵的一列为单位进行运算,包括10轮迭代计算,每一轮运算划分为一个模块,模块内以流水线方式并按照算法流程实现相应运算,模块间以时钟控制数据赋值和输出,数据在相邻模块依次传递.

表1 密钥扩展流程
表1中T的表达式为T=SubBytes(CycShift(key[i])⊕Rcx[i]),SubBytes为字节代换,CycShift为循环移位,Rcx为轮常数,下同.CycShift对key[i]左移一个字节,然后进行SubBytes,最后,SubBytes的结果和Rcx异或,其中轮常数Rcx[i]=01000000,02000000,04000000,08000000,10000000,20000000,4000000080000000,1B000000,36000000,轮数i∈0…9.密钥扩展模块的单轮时钟周期为4,在每个时钟周期,将当前轮密钥输出,并传值给10组128bit的key数组,作为每轮加密模块的密钥输入.密钥扩展的具体实现过程如式(1)所示.
next_key[127:96] =key[127:96]^SubByte(CycShift(W[31:0]))^Rcx[i]
next_key[95:64]=key[95:64]^key[127:96],
next_key[63:32]=key[63:32]^key[95:64],
next_key[31:0]=key[31:0]^key[63:32]
(1)
3.1.2 轮加密
轮加密运算同样包括10轮迭代,每一轮运算划分为一个模块,各个模块之间并行运算,当数据连续输入运算模块中,在44个时钟之后,每个时钟可产生一个输出.其流程组成如表2所示.

表2 轮加密流程
首先,字节代换子模块采用16个SBox并行计算,1个时钟周期输出结果,其运算过程如式(2)所示,其中,0≤i≤15,data_in表示128bit的输入,data_sub2shift表示128bit的输出.
data_sub2shitf[(i×8)+7:(i×8)]=SBox(data_in)[(i×8)+7:(i×8)]
(2)
然后,SubBytes的结果传递至ShiftRows,并在一个时钟周期内完成行移位置换操作.ShiftRows在状态矩阵的每个行间进行并且是线性的,按照一定规律的偏移量循环左移运算,MixColumns与其相互影响,多轮变换后的密码得到充分扩散.第i行第j列的字节移动如式(3)所示,偏移量Oi依赖于Nb的取值.
(i,k)→(i,(j-Oi)modNb)
(3)
其置换具体实现过程如式(4)所示,其中State为8bit的状态矩阵,data_shitf2mix表示128bit的输出.
State[i]=data_sub2shift[(((15-i)×8+7]:((15-i)×8)],0≤i≤15,data_shift2mix[(15×8)+7:(12×8)={State[0],State[5],State[10],State[15]},data_shift2mix[(11×8)+7:(8×8)={State[4],State[9],State[14],State[3]},data_shift2mix[(7×8)+7:(4×8)={State[8],State[13],State[2],State[7]},data_shift2mix[(3×8)+7:(0×8)={State[12],State[1],State[6],State[11]}
(4)
然后,行移变换的结果传递至列混合子模块,在1个时钟周期内完成域GF(28)上的MixColumns.
(5)
列混合变换同样是线性变换,首先,把状态矩阵的列看做有限域G(28)上的多项式;然后,在模x4+1下与一个给定的多项式c(x)相乘;然后,b(x)=c(x)·a(x)mod(x4+1)(假设输入为a,输出为b);最后,利用有限域G(28)上的算术特性代换,表达式如式(5)所示.
列混合域乘0x02和0x03的过程如式(6)所示,其中,State_mulx2、State_mulx3分别表示域乘0x02、0x03后的结果.
State[i]=data_shift2mix[(((15-)×8+7):((15-i)×8)],
State_Mulx2[i]=(State[i]<<1)(8h1b&{8{State[i][7]}}),
State_Mulx3[i]=(State_Mulx2[i])^(State[i])
(6)
那么对于其第1列的操作如式(7)所示,其中data_mix2key表示128bit的输出.第2~第4列操作相同.
最后,对于AddRoundKey子模块,中间加密结果与Key
data_mix2key[(15×8)+7:(15×8)=State_Mulx2[0]^State_Mulx3[1]^State[2]^State[3],data_mix2key[(14×8)+7:(14×8)=State[0]^State_Mulx2[1]^State_Mulx3[2]^State[3],data_mix2key[(13×8)+7:(13×8)=State[0]^State[1]^State_Mulx2[1]^State_Mulx3[3],data_mix2key[(12×8)+7:(12×8)=State_Mulx3[0]^State[1]^State[2]^State_Mulx2[3]
(7)
extension的结果,在1个时钟周期内输出且完成异或操作.AES单轮加密的结构如图1所示,其过程为4级流水线.

图1 AES单轮加密结构
密钥拓展和加密模块采用并行处理,单轮内部均为4级流水线,整个AES流水线结构为42级,如图2所示.第1轮~9轮的操作完全相同,每轮使用其上一轮的结果.对于第10轮,没有中间的MixColumns操作.解密算法与加密算法类似,需要增加轮密钥缓存寄存器用于存储产生的轮密钥.
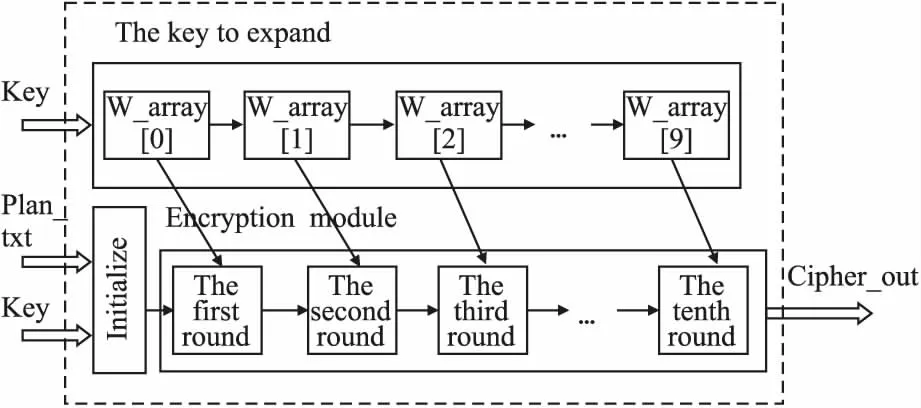
图2 AES加密流水线结构
3.2 GHash算法及优化
GHash函数是一个基于伽罗华域128bit的GF(2128)乘法器的Hash操作.在GF(2128)域中不可约多项式为:f(x)=x128+x7+x2+x+1,GHash函数运算的结果记为,其中Xi(x=0,1,…,m+n+1)的定义如式(8)所示.在前m个周期,将附加的认证数据A作为输入,进行相应的运算操作;接下来的n个时钟周期内,将加密密文C作为输入进行运算操作;在最后一个时钟周期,输入len(A)‖len(C)进行相应运算.
(8)
GCM电路结构及效率主要取决于GHash电路计算Xi时所采用的计算方法,其中变量Xi是GHash函数中附加数据或密文与哈希算子的乘加结果,它的串行计算公式如式(8)所示.
其中,变量Xi有迭代式、展开式和并行式3种计算方法,典型的AES_GCM密码电路结构主要有并行式和串行式两种,本文选择采用并行式的流水线型AES_GCM电路结构,并在此基础上采用Karatsuba算法和快速求余来提高Xi的计算速度从而提升电路性能.
在GF(2128)域上进行的所有运算是可逆的、能够还原的,且结果都在域中,不会溢出.假设A、B、C是GF(2m)域上的元素,它们的表达式如式(9)所示:
(9)
根据式(9),针对GHash模块设计了4级流水线结构的电路,其电路结构如图3所示.由于AES加密端的计算频率和GHash认证端的计算频率不同,因此采用FIFO作为数据缓冲.

图3 有限域乘法运算电路结构
采用流水线方式计算GHash的结果,计算速率可达每4个时钟周期计算3个密文,具体方式如表3及表4所示.表3的输出结果如式(10)所示,前4组数据可以连续输入,第2轮的前3个数据是密文输入,Q1作为第2轮的最后一个输入;从第2轮至最后一轮,每4个时钟周期计算3个结果.
q1=(l0H4)⊕(l1H3)⊕(l2H2)⊕(l3H) (10)

表3 第1轮运算

表4 第2轮运算
对于M组加密结果,有M=m+1组数据传入GHash中;当M值很大时,其计算出所有结果并输出所需要的时钟周期数如式(11)所示:
(11)
3.2.1 Karatsuba乘法器
因为GHash内部进行着大量的比特相乘,所以导致大量的资源消耗,而Karatsuba乘法器的性能对GHash模块的性能有着关键性影响,所以可以通过降低Karatsuba乘法器的复杂度来减少资源的消耗,以提升AES_GCM电路的整体性能.
Karatsuba算法是基于分解相乘思想来进行设计的,将两个比特位数较大的二进制数乘法分解为几个位宽较小的二进制数的乘法,然后,在此基础上进行移位运算、加法运算,进而完成两个原有位宽较大的二进制数的乘法运算.例如,两个大整数X和Y相乘,其中X和Y分别为nbit,已知X=AB,Y=CD,对于AD+BC部分,两个乘法的时间复杂度为O(n2/4),一个加法的时间复杂度O(n),然后对AD,BC进行分解,如式(12)所示,从而降低复杂度.
AD+BC=AC+AD+BC+BD-AC-D=(A+B)(C+D)-AC-BD
(12)
最终整体算法只需要计算乘法AC,BD和(A+B)(C+D),以及6次时间复杂度为O(n)的加法或减法即可.
Karatsuba算法,其每层包括3次乘法,时间复杂度为O(n2/4);另外,括号外层需要两次加法,括号内部包括若干次加法,乘法规模随着Karatsuba算法的使用次数依次下降(n/2).所以,使用Karatsuba设计的乘法器能够有效降低电路的硬件复杂度.
当n较大时,在电路资源的利用上,Karatsuba乘法器的优势凸显.但当分解次数进一步增加时,电路的整体资源开销、延时会出现增加,所以需要找到一个平衡点,以平衡资源开销和延时,从而能更好的提升电路效率.数据分解流程如表5所示.
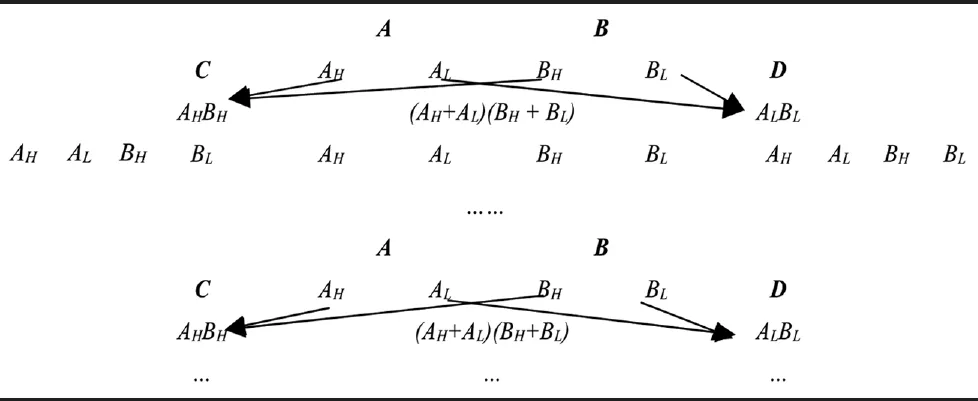
表5 数据分解流程示意
将KOA乘法器划分为KOA64、KOA32、KOA16、MOD这4种操作.对于KOA乘法器读取N组数据的计算,经过N+3个时钟周期即可得到其计算结果.由式(13)可知,当N值很大时,认为该流水线的吞吐量趋近于128f.
(13)
由公式(14)可知,当N值很大时,认为该流水线的加速比趋近于4.
(14)
随着分解次数r的增加,AES_GCM整体电路所需要的面积功耗也在不断变化,发现当选择3层KOA(Karatsuba-Offman-Algorithm,KOA)时,将数据从128bit分解到16bit时,相比于其他r-KOA所需的面积功耗更低,所以本文选择3层KOA进行全流水线AES_GCM电路设计.
3.2.2 快速求余
在经过Karatsuba优化之后,两个128bit的数据相乘得到一个256bit的中间结果,但前面提到,在GF(2128)域上进行的运算,得到的结果必须仍然属于这个域中,所以需要对256bit的中间结果进行求余运算.
传统的求余方法是让得到的256bit的中间结果的第254bit到第128bit和简化矩阵Q进行相乘操作,进而得到128bit的有限域乘法结果.
但是由于传统运算的矩阵乘法存在着大量的资源及时间消耗,且其无法利用流水线进行优化.所以采用Gueron S等[12]所提到的,舍弃了矩阵相乘的快速求余方法,对于余数的计算,其是通过一系列移位异或运算进行的,算法具体流程如表6所示.

表6 快速求余算法流程
由上,利用快速求余法来计算余数不仅能够减少电路上门的开销,而且还可以采用流水线技术以进一步提高电路效率.
3.3 多级数据缓存优化
多级缓存技术是实现高性能算法的重要方法之一.一方面,将多级缓存技术用于模块之间的通信数据,可以减少计算模块之间的耦合度,通过增加缓存寄存器或者存储器,建立模块之间的路由中断,增加布线的成功率;另一方面,将多级缓存技术用于数据信号对应的控制信号,使数据与控制分离,能够在数据处理后正确捕捉到对应的控制信号,增加算法运行时的可靠性.时钟域不同的模块之间的数据传输使用FIFO(First In First Out)进行,采用数据缓存匹配不同模块间的速率,提高运行速度.同时,FIFO仲裁控制简单,所以引入FIFO以完成数据缓存和突发传送数据.
将0128、Y0Y1…Yn依次输入到AES模块中,每输入一个数据消耗一个时钟周期,每个数据花费44个时钟用于加密,获取H并存储,由于明文P0P1…Pn需要与相应的Y0Y1…Yn异或,因此采用多级缓存技术存储明文有效信号及相应数据P0P1…Pn,这些数据在缓存中等待44个时钟后与相应的E(Yi)进行异或运算,得到密文C,如图4所示.

图4 多级数据缓存
4 随机矩阵和时延的SBox结构
通常,碰撞攻击的实施常选择距离检测法和相关系数检测法[13].对于基于距离检测的相关碰撞攻击,为降低噪声的影响,首先,对两组能量曲线进行平均操作,得到两条平均功耗曲线;然后,计算n个关键点之间的距离;最后,对上一步进行判断,如小于提前设定的阈值,则认为出现碰撞,否则没有发生.对于基于相关系数的碰撞攻击,通常是对于能量迹的获取,然后根据预先设计的计算公式,计算正确的碰撞关系数值.
所以本文考虑设计一种SBox结构,以能够对其功耗曲线的相关性及一致性产生影响,使其无法准确计算出正确的关键点间的距离,从而使判定和阈值的准确性随之受到影响,对碰撞攻击具有防御能力.如图5所示,为基于随机矩阵和时延的SBox加密电路.
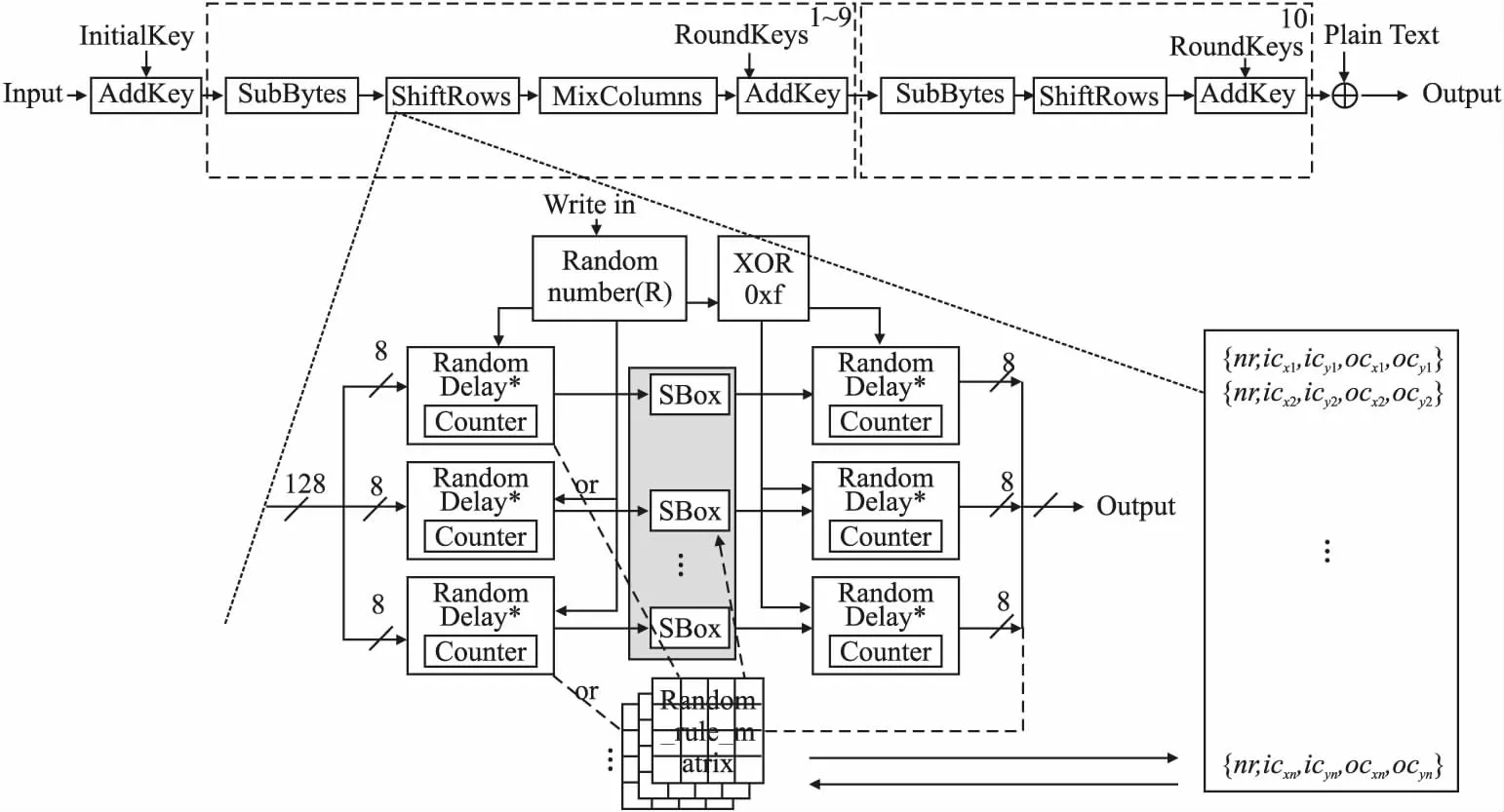
图5 随机矩阵和时延的SBox加密电路
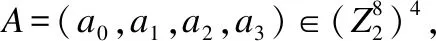
(b0,b1,b2,b3)=nl(A)=(SBox(a0),SBox(a1),SBox(a2),SBox(a3))
(15)
结合式(15),进一步将步骤1的过程转换为符号表示,设nr为当前的轮数,icx、icy为字节替换在4×4矩阵中选取的初始行列坐标,ocx、ocy为字节替换在4×4矩阵中选取的输出时行列坐标,如式(16)所示,系统最初最多生成16×16组这样的数据.因为轮数nr的差别,不同的行列坐标值可以对应相同的变换过程,所以很多值对应的相同变换过程都可以归并,进而能够进一步降低电路复杂性.
SubBytes原始输入值→{nr,icx,icy,ocx,ocy}→nl(A)→SBox实际值
(16)
对于表7中步骤1及式(16),例如原本SBox替换值′0x9E′对应′0xb1′,而现在引入了随机变换矩阵后,则可以把其中的一种变换过程称为′0xb1′,更为详细地:例如一个4×4矩阵的第2行第1列先左移7次,然后上移15次,最后下移3次,变换后的位置在第2行第2列,根据本文的设计,把这个过程取名叫′0xb1′,也就是′0x9E′的对应值,原先的值′0x9E′不再直接与SBox表相应值对应,而是对应于这个变换过程,同理,其他生成的随机变换也是以这样的方式与原始SBox值一一对应,最后简化为优R4生成的如式(16)所示的一串数据,其中nr受R5产生的随机数限制.

表7 基于随机矩阵和时延的加密电路流程
对于表7中步骤2,详细地:
1)4×4矩阵从上至下从左至右分别标号0~15,对应的坐标值为(0,0)~(3,3),所以R3生成的随机数的作用是随机选择矩阵的位置标号以对应坐标;
2)时延总和设为16,R1随机生成总和为16的10个随机数,每轮中,根据R10的随机值,从R6~R9中选取一个数(或不执行),随机对SBox进行时延操作;
3)R2用于选择哪些SBox执行随机变换操作,生成的随机数需剔除已确定执行时延的SBox编号,然后根据在限定范围内的随机数,相应SBox执行预先设置的随机变换操作;
解密过程与加密类似,需要增加缓存寄存器用于存储产生的随机坐标值{nr,icx,icy,ocx,ocy}.
5 整体结构设计
如图6所示,其为一个模块的基于GHash优化的全流水线AES_GCM结构.采用松耦合架构,将整个程序优化为3大模块:AES模块、GHash模块和控制逻辑模块.其中AES模块用于加解密运算,GHash模块用于生成认证标签,两模块之间的调度优化由控制逻辑模块实现,各模块依赖程度低,可扩展性强.

图6 基于GHash结构优化的全流水线AES_GCM结构
在松耦合架构的基础上,采用FIFO技术来匹配AES模块和GHash模块的计算频率,并采用AES_GCM控制模块作为顶端控制,协调两模块的运算.控制逻辑模块的初始化控制模块首先对AES模块和GHash模块进行复位,AES_GCM模块将初始化向量0128和Y0Y1…Yn连续传送给AES模块,并保存E(Y0),然后将密文C、哈希算子H和附加数据A传入GHash模块,GHash模块会将密文C和附加数据A传入缓冲器FIFO中,避免因速率不匹配造成数据丢失,待GHash完成计算后获取其结果Xm+n+1,并传送至结果输出模块.结果输出模块将Xm+n+1和E(Y0)异或得到认证标签T并将其输出.
Xm+n+1=M1⊕M2⊕M3⊕M4
M1=(I1H16⊕I5H12⊕I9H8⊕I13H4…)H4
M2=(M1H12⊕I17H12⊕I21H8⊕I25H4…)H4
M3=(M2H12⊕I29H12⊕I33H8⊕I37H4…)H4
M4=(M3H12⊕I41H12⊕I45H8⊕I49H4…)H4
(17)
因为设计的电路结构需要满足高速网络场景,所以本文采用4个AES_GCM模块并行的方式进行进一步优化设计,如图7所示.首先,FPGA模块对接收来的数据进行一个预处理,仲裁器I对传入的数据进行分组,分组策略即按照模块顺序由上至下进行平均循环分配.因为GHash算法的特殊性,同时本文采用的是四模块并行的加密认证方式,所以需要对原有GHash计算公式进行改进,根据文献[14]的GHash运算公式并结合本文优化后的公式(10),得到式(8)中Xm+n+1新的计算公式,如式(17)所示,其中M1~M4分别代表4个模块.对于每次新的加密任务,H4、H8、H12、H16可以预先初始化好,从而进一步减少时间消耗.最后,仲裁器II对加密认证后的数据进行排序整合,按照数据的输入顺序输出,进而满足100G高速网络数据的加密认证需求.
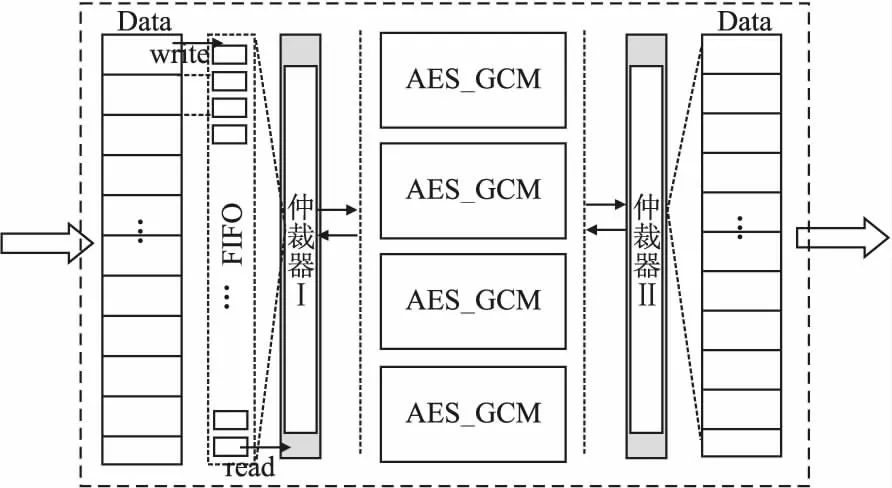
图7 4模块并行的的全流水线AES_GCM结构图
6 实验及分析
6.1 实验环境
本实验的硬件平台为FPGA加速卡,芯片型号为Xilinx公司的ZYNQ XC7Z035-FFG676-2,使用Verilog语言实现AES_GCM算法,软件平台使用Vivado 2019.2.通过对算法的各个模块进行优化设计,给出了资源占用情况,如表8所示.并与其他实验进行对比分析,最后结合实验情况,对实验做出整体的分析评价.
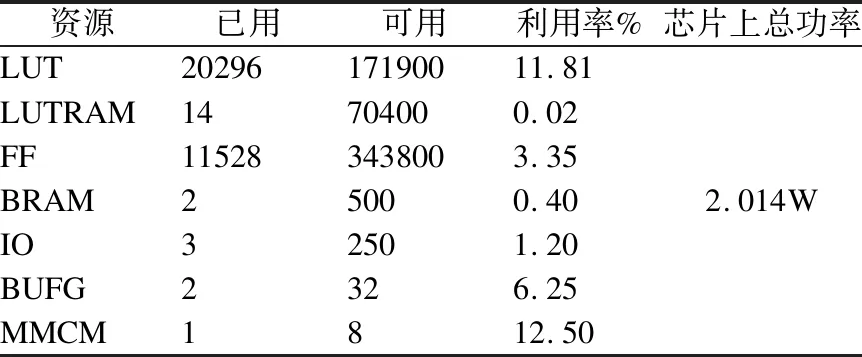
表8 AES_GCM资源占用
6.2 性能分析
由表9可知,本文实现的AES算法与文献[14]和文献[15]相比,具有较高的频率和吞吐率;文献[16]吞吐率为79.70Gbps,但与本文相比较,其电路设计并未进行安全方面的考虑.

表9 AES与其他方案对比
从表10可以看出,本文FPGA上实现的GHash算法较文献[1]具有较高的频率和吞吐量;文献[17]吞吐量为40Gbps,但是其每次固定加密8组数据,而本文方案可以处理任意大小数据,具有灵活性.

表10 GHash与其他方案对比
使用R表示占用资源数量取值为Slices,PE表示性能,使用PR代表性能资源比,则性能资源比的计算公式如式(18)所示:
(18)
根据表11可看出,本文方案与文献[14]相比具有较高的吞吐量和频率;文献[18]采用的是Arria10 FPGA,无论其基础性能还是造价都远高于本文所采用的板卡,从资源、性能及功耗等多方面综合来看,本文方案较其具有更高的性价比,同时,本文的性能资源比PR与其比较也有比较大的优势.

表11 AES_GCM与其他方案对比
在算法实现以后,为满足面积和功耗最优,选择不同策略的多种组合进行编译测试,在满足布线时序的情况下,选择面积和功耗最优的策略组合:Flow_AlternateRoutability和Performance_ExtraTimingOpt,从而通过综合策略的选择进一步实现面积和功耗优化.
基于GHash结构优化的全流水线AES_GCM实现在300MHz时钟下,每秒可以处理约300×96bit数据.关于面积功耗优化,利用Karatsuba设计的乘法电路达到了降低AES_GCM消耗资源、减少整体电路的硬件复杂度的目的,实现了对AES_GCM的整体优化.对于本文所设计的方案,当密钥不发生变换时,其综合性能可以更高;当加密数据量较大时,具有更好的性能.
6.3 安全分析
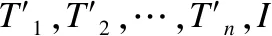
(19)
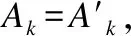
(20)
(21)

最后,对本文设计的加密电路进行碰撞攻击测试,得到的功耗曲线距离如图8所示,计算得到的阈值Tv为0.14,图中虚线为阈值Tv.
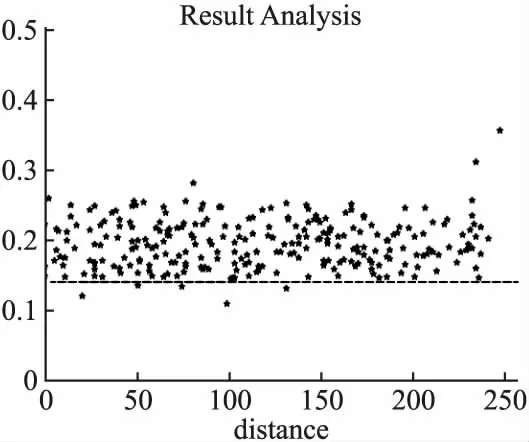
图8 SBox功耗距离图
由图8可知,对其进行碰撞攻击测试后,因为出现了多个小于阈值的点,这些点即是发生碰撞的值,所以表明其未能正确的检测出碰撞,进而说明了本文所设计的加密电路具有一定的碰撞防御能力.另外,加密过程中每轮都可能存在随机时延,但它是依据加密时的环境安全情况由初始变量控制其是否开启的,关闭时对电路整体性能没有影响;开启时,十轮总时延最多16个时钟,根据设计,每轮都有时延的概率为8.59%,平均情况下,电路性能降低约2.37%.
7 结束语
本文采用流水线和并行技术实现AES_GCM算法的优化,并在此基础上采用Karatsuba算法和快速求余来提高GHash函数运算结果Xi的计算时间,从而进一步提高电路性能,以及考虑到电路自身的安全性,并提出相应设计.在AES_GCM优化中采用了松耦合架构和多级缓存技术等.本文实现方案的吞吐量达到了115Gbps,能够满足100G高速网络加密认证需求.对于本文所设计的架构可以进行相应调度调整来满足更高速率的数据处理要求.同时,本文设计的AES_GCM算法可通过PCIe与计算机配合使用,可应用在如物联网等场合,具有实际的应用价值.
高速网络的设备及服务等随时可能发生巨大的变化,应用场景多样且繁杂,网络发展趋向边缘化,所以传统的安全方法可能难以适用,网络可能存在着更多的漏洞可以被攻击.为解决这些问题,不仅需要设计更高效的通信数据加密算法及更优的硬件架构,同时也更需要从各个方面着手设计更加安全的方案及安全体系,以保证高速网络的高安全性和高可信度.
