结合新颖的互注意力和门控机制的图像标题生成
2023-08-29胡卫兵米金鹏吴旭明杨芳艳
胡卫兵,米金鹏,吴旭明,3,刘 丹,杨芳艳
1(上海理工大学 机器智能研究院,上海 200093)
2(上海理工大学 机械工程学院,上海 200093)
3(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
图像标题生成是人工智能多模态领域的重要研究方向之一,它不仅涉及计算机视觉任务,同时也囊括了自然语言处理的相关知识.该任务主要目的是让计算机能够从给定的非结构化场景中理解其内容信息(包括属性、类别以及与周围事物的交互关系),并且能够自动生成语义丰富且结构自然的语句去描述场景内容[1].随着深度学习的快速发展,图像标题生成得到了越来越多研究者的关注,而且新的应用场景正在不断被提出.例如图像检索[2]、人机交互[3]、特殊场景的图像描述[4]以及帮助有视力障碍的人们感知周围的环境等.
随着对图像标题生成领域的不断探索,为图像生成一句话来概括其复杂场景内容的方法主要分为:基于模版的方法(template-based)[5]、基于检索的方法(search-based)[6]、基于编码-解码分析的方法(encoder-decoder)[7].近年来,图像标题生成任务的灵感来源于机器翻译,该任务是将一种序列的语言翻译成另外一种序列的语言,例如中文翻译成英文等.机器翻译模型主要采用“编码器-解码器”的结构,而且编码器和解码器均采用循环神经网络(Recurrent Neural Network,RNN)或者长短时记忆神经网络(Long Short-Term Memory,LSTM[8]).受到该任务的启发,研究者开始采用“编码-解码”的结构并将其应用于图像标题生成任务.两者唯一的区别在于机器翻译任务是属于模态内部的转换,而图像标题生成属于两种模态之间的转换.因此研究人员在编码器部分进行改进,采用预训练的卷积神经网络(例如VGG[9]、ResNet[10]、AlexNet[11]等)对图像的特征进行提取并将其映射为固定长度的特征向量,然后利用长短时记忆神经网络对编码后的特征向量进行解码,最终得到描述图像内容的语句.
2015年,机器翻译中的“编码-解码器”结构首先被Vinyals等[1]引入到图像标题生成的任务中,其主要利用在ImageNet[12]上预训练的卷积神经网络(Convolution Neural Network,CNN)提取图像的特征,并将该特征向量仅作为LSTM的初始输入,然后依次迭代将上一时刻的输出作为下一时刻的输入,直到整个句子完整生成.该方法使得在每个时刻模型并没有关注到图像重要区域的信息,并且由于LSTM自身固有的缺陷使得较远时刻的信息对于先前时刻信息的遗忘程度逐渐增加.而Mao等[13]提出的m-RNN模型在每一个时刻都将提取的图像特征向量输入到模型中,该方法输入的是图像的全局特征,并没有从更加细粒度的图像内容进行解析.李坤等[14]提出采用多时间维度信息融合的方式,利用横向和纵向的结构丰富解码器的输出.该方法存在的问题是忽略了场景的背景信息.而Anderson[15]等将目标检测技术应用到了图像标题生成的任务中,编码器采用在Visual Genome[16]上预训练的Faster R-CNN(Faster Region-based Convolutional Neural Network)[17]提取目标物体的局部特征、框的位置(bounding-box)和类别属性(class label)信息,与采用不同尺寸的特征图进行融合相比,该信息更加细粒度.
虽然LSTM在一定程度上能缓解梯度消失,但是当序列长度超过一定限度时,其长时间的依赖性依然较差.因此Xu等[1]提出两种注意力机制来对图像中显著区域进行关注,分别为“soft”和“hard”注意力机制.其中“soft”注意力是对整个图像的特征区域加权求和,重点区域的权重最大.而“hard”注意力只关注了图像重点区域.为了能够从图像中提取出更加丰富的特征信息,盛豪等[18]分别对图像场景特征和目标显著性特征进行解码,并将解码后的特征进行融合,使得描述语句更加全面.Zhong等[19]提出一种基于自适应空间注意力的图像标题生成方法,将图像的全局和局部特征进行融合送入解码器,并在解码阶段使用注意力机制动态关注图像的区域.李晓莉等[20]引入主题语言模型和图像主题模型来解决在任何主题下单词分布一致的情况.Sammani等[21]提出对现有句子进行编辑,从而只需要专注于对细节的修改.Ke等[22]首次同时使用视觉注意力和文本注意力,使得模型在生成当前时刻的单词时,模型能够对之前时刻所有的隐藏层状态信息进行关注.Ding等[23]将心理学理论引入到图像描述中,提出了刺激驱动和概念驱动两种注意力机制用于检测图像中注意力分布,使其能够适应于更加复杂的场景.然而上述方法均有两点不足.首先,对于局部特征提取方面并没有关注到更加细粒度的信息,例如图像中物体的位置信息(bounding-box)和类别信息(class label).其次,模型的解码阶段都是从零开始生成一个句子,没有引入外部知识作为辅助信息进行更加细致化描述.
针对上述两点,提出一种结合新颖的互注意力和门控机制的图像标题生成方法.该方法主要由3部分组成:1)卷积神经网络(CNN)和Faster R-CNN模块分别用于提取全局和局部的细节化特征;2)新颖的门控机制(Gate-mechanism)用于决定是输出当前时刻的信息还是图像区域的信息;3)互注意力模块实现文本语义信息与图像语义信息的交互.
2 结合新颖的互注意力和门控机制的模型
为了能够从图像中提取出更加细粒度的信息内容以及增强图像和文本信息的交互.本文以ResNet-152和Faster R-CNN作为编码器分别用于提取图像的全局特征以及局部特征信息(包括目标特征、位置信息、类别信息),然后将两个特征信息分别送入解码器的第1层LSTM(Attention-LSTM)和第2层LSTM(Language-LSTM)进行解码,并将其作为模型的基准方法.在此基础上解码端设计了两个模块,分别为带外部知识的互注意力模块和门控机制.其中门控机制用来控制模型是选择当前时刻的输入信息还是图像区域的信息,而互注意力模块用来将第2层的隐藏层状态向量与外部知识(现有模型AoA[24]所生成的语句)语言信息最接近的向量进行加权,再将加权后的向量去关注从Faster R-CNN中提取的局部特征信息.最后将第2层隐藏层状态信息、外部知识加权信息、关注的图像重点区域信息进行融合送入多层感知机,从而产生更加丰富的语句.总体框架图如图1所示.
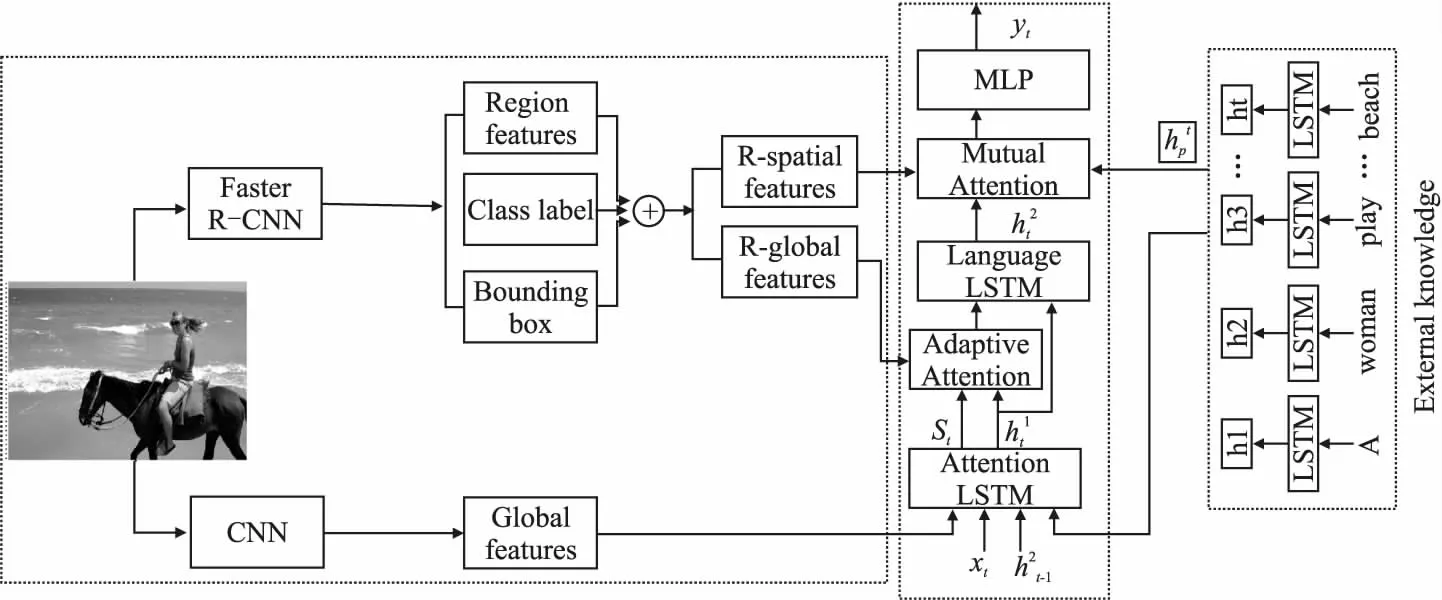
图1 结合新颖的互注意力和门控机制的图像标题生成总体框架图
2.1 图像特征提取
目前,基于“编码-解码器”结构的图像标题生成网络在编码器部分大多数采用ImageNet上预训练的卷积神经网络来提取图像特征.本文使用在ImageNet上预训练的ResNet-152模型提取图像的全局表征,另一个使用经过Visual Genome上预训练的Faster R-CNN模型作为目标检测器来提取图像的局部特征信息(包括目标特征、位置信息和类别信息),局部特征提取如图2所示.

图2 Faster R-CNN特征提取模块
给定输入图像I,经过两个分支,如图1所示.其中一个经过ResNet-152网络并提取倒数第2个Bottleneck的特征,然后经过一个全连接得到全局特征,并将特征图划分为64(8×8)个子区域.即:
VG=fCNN(I)
(1)
其中,VG={v1,v2,…,vL},vi∈D.L表示提取特征图的数量,D表示每个特征图的维度,本文中特征图的维度为2048维.fCNN(·)表示全局图像特征提取模块.
同理,图像I经过另一个分支Faster R-CNN网络,得到细粒度的图像特征,分别为目标区域特征R、位置信息B及类别信息C,即:
(R,B,C)=fFasterR-CNN(I)
(2)
其中,R={r1,r2,…,rL},ri∈D,R表示图像中目标物体的特征,特征向量的维度为D.位置信息B和类别信息C的特征图的数量均为K=50,而B用一个4维的特征向量表示(框的坐标x1y1x2y2),C用一个1601维的特征向量表示.fFasterR-CNN(·)表示局部信息特征提取模块,如图2所示.
2.2 解码模块和门控机制
在模型的“解码器”部分采用了对于序列有长时间依赖性能力的长短时记忆神经网络(LSTM),它在一定程度上能够缓解循环神经网络(RNN)产生的梯度消失的问题.LSTM主要由4部分组成,分别为输入门(input)、输出门(output)、遗忘门(forget)、记忆单元(memory cell).如图1所示,解码模块由3部分组成,分别为注意力LSTM、语言LSTM和外部知识LSTM模块.LSTM模块在每一时刻进行单词更新时的公式如下所示:
it=σ(Wixxt+Wihht-1+bi)
(3)
ft=σ(Wfxxt+Wfhht-1+bf)
(4)
ot=σ(Woxxt+Wohht-1+bo)
(5)
gt=φ(Wrxxt+Wrmht-1+bi)
(6)
ct=ft⊙ct-1+it⊙gt
(7)
ht=ot⊙ct
(8)
其中,it、ft、ot、gt、ct、ht分别表示在t时刻时的输入门、遗忘门、输出门、当前时刻的记忆单元、更新后的记忆门和当前的隐藏层状态.W*x、W*m表示网络学习的权重,b*表示网络学习的偏置项,σ(·)表示sigmod激活函数,φ(·)表示tanh激活函数.
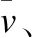
(9)
(10)
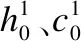
本文将Faster R-CNN提取的目标区域特征、位置信息、类别信息进行融合拼接,再通过两个全连接层将拼接后的特征分别映射到R-spatial features(空间信息特征Rs)和R-global features(属于局部的全局特征Rg).受到了 Lu等[25]的启发,如图1所示提出了一个新的门控机制,该机制使得模型在解码时能够选择性关注空间信息特征还是当前时刻解码的语言信息st.故使用一个自适应的注意力机制来进行适当的选择.具体公式如下所示:
(11)
(12)
st=gt⊙ĉt
(13)
其中,gt与LSTM中的门机制类似,ĉt为当前时刻模型输入到LSTM的信息向量,st为当前时刻模型产生的语言信息.W*为网络学习的权重,⊙表示点乘.
(14)
αt=softmax(zt)
(15)
(16)
(17)
(18)

2.3 互注意力模块
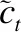

图3 互注意力模块
(19)
(20)
(21)
(22)
(23)
p(yt|y1:t-1)=softmax(MLP(call))
(24)

2.4 训练和优化
本文采用的评价指标为BLEU[26]、METEOR[27]、ROUGE-L[28]、CIDEr[29]、SPICE[30],该指标与模型在训练期间直接优化的目标并无直接关系且CIDEr是不可微的.故模型先使用交叉熵损失函数进行训练,再使用基于强化学习的策略梯度算法(SCST[31])进行优化训练.该策略是将语言模型作为智能体(agent),图片特征和单词作为环境(enviroment).在每一时刻,智能体根据从环境中观察到的状态产生下一个单词(动作),最终产生的句子通过短语匹配的指标来计算奖励reward,训练目标优化的是最小化负期望奖励函数.具体公式如下:
L(θ)=-∑logpθ(yt|y1:t-1;R;V)
(25)
(26)
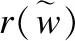
3 实 验
3.1 数据集
本文实验采用的数据集为MSCOCO[32]和Flickr 30k[33],并在这两个数据集上进行了模型的验证.MSCOCO数据集包含123287张图片,每张图片都有5个不同的标签描述,而Flickr 30k数据集相对COCO数据集较小,其包含了31014张图片,每张图片均有5个不同的标签描述.而在实验部分两个数据集均采用了Karpathy[34]的分割方法,将MSCOCO数据集分割为3部分,分别为训练集113287张图片,验证集和测试集各5000张图片,而Flickr 30k数据集同样分割为3部分,分别为训练集29000张图片,验证集和测试集分别为1014张图片和1000张图片.
3.2 实验数据及硬件配置
本文实验平台为Ubuntu 16.04,模型所使用的深度学习框架为pytorch1.6.6,编程环境为python3.7.7,GPU为TITAN V,CUDA版本为10.0,显存12G.MSCOCO和Flickr 30k数据集均进行相同的预处理,单词的长度最大设置为18,将词汇表中单词出现次数少于2次的进行移除,最终MSCOCO和Flickr 30k词汇表中分别包含13368和9848个单词.在图片进行预处理部分,为了加速模型的训练,本文将图片大小统一处理成256×256并将其写入HDF5文件中.使用ResNet-152提取的全局特征维度为2048,Faster R-CNN提取的目标物体特征、位置信息、类别信息特征向量的维度分别为2048,4,1601,特征图数量设置为50.解码阶段LSTM隐藏层状态向量维度为512.优化器使用Adam,编码器的学习率设置为0.00001,解码器的学习率设置为0.00005且每训练4轮解码器学习率乘以系数0.7,从而进行学习率衰减.Batch Size设置为64,训练20轮.为了在训练过程中监控模型性能最大化,设置了一个早停机制,如果BLEU-4指标连续8轮没有改善,则停止训练.在模型验证和测试阶段解码生成单词时使用beam search.MSCOCO数据集和Flickr 30k数据进行测试时beam size分别设置为5和3.
3.3 评估模型
为了衡量模型性能,本文采用BLEU1、BLEU2、BLEU3、BLEU4、METEOR、ROUGE-L、CIDEr、SPICE作为评估模型性能的指标.BLEU是来源于机器翻译评价指标,用于分析模型生成的候选语句与真实标签中n元组一同出现的程度.METEOR主要解决BLEU评价标准的一些缺陷,其基于精度和召回率调和平均值来评价,评判结果与人工相关性较高.ROUGE-L是基于模型生成句子和真实标签中单词共现程度,其共现程度越高,则模型生成的语句质量越好.CIDEr是通过将句子表示成TF-IDF(Term Frequency Inverse Document Frequency)向量的形式,然后计算每个n元组的权重来衡量图像标题语义内容的一致性.SPICE是通过使用基于图的语义表示来编码句子中的物体、属性以及之间的关系.
为了验证外部知识模块和门控机制的有效性,进行了消融实验,其中S和EK分别表示门控机制和外部知识模块.结果如表1所示.
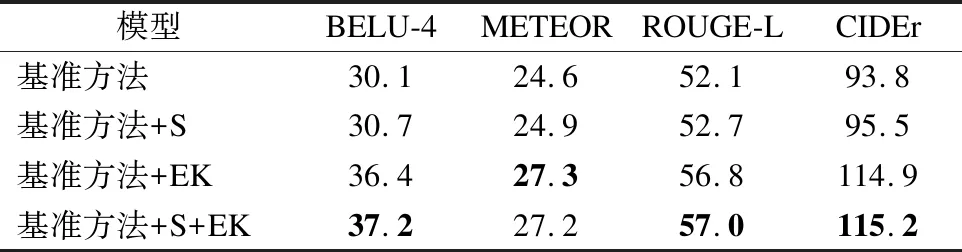
表1 不同模块对模型性能的影响
从表1中可以看出模型加入了门控机制和外部知识模块,模型的性能均在基准方法的基础上有大幅的提高.在基准方法上加入S时,BELU-4和CIDEr分别提高了0.6%和1.7%.而当引入外部知识模块时,模型性能均在基准方法的基础上有大幅提高,BELU-4提高了6.3%,METEOR提高了2.7%,ROUGE-L提高了4.7%,CIDEr提高了21.1%.当模型同时融入S和EK模块时,模型性能相较于加入EK进一步提高,BELU-4提高了0.8%,CIDEr提高了0.3%.消融实验的结果表明,融入外部知识模块和门机制对模型性能是有效的.
为了验证本文提出方法的有效性,将本文的方法与当前主流的图像标题生成模型的方法在MSCOCO数据集上分别在使用交叉熵训练和SCST优化训练两部分进行了对比.
通过表2、表3以及表4对比实验发现,本文提出的模型性能在一定程度上取得了较好的结果,通过在外部知识模块的引导下将图像到语言再到图像之间的语义关系体现出来.其关注的是语义级别信息特征的对齐,从而使生成的图像标题更加丰富且符合人的描述.本文的方法仅在使用交叉熵训练下时模型的性能在3个指标上低于Shen[18]提出的模型,究其原因是其提出的模型在进入语言模型之前进行了融合(即concatenate)的操作,从而降低了一部分图像噪声.而本文的方法在BELU-4指标上比它的模型性能高,侧面说明本文是通过图像-文本-图像来提高视觉注意力的准确能力,并且使用SCST方法优化后本文的指标在各方面均优于Shen[18]的模型,从而进一步说明本文方法有更大的潜力去挖掘出深层次的图像语义信息.
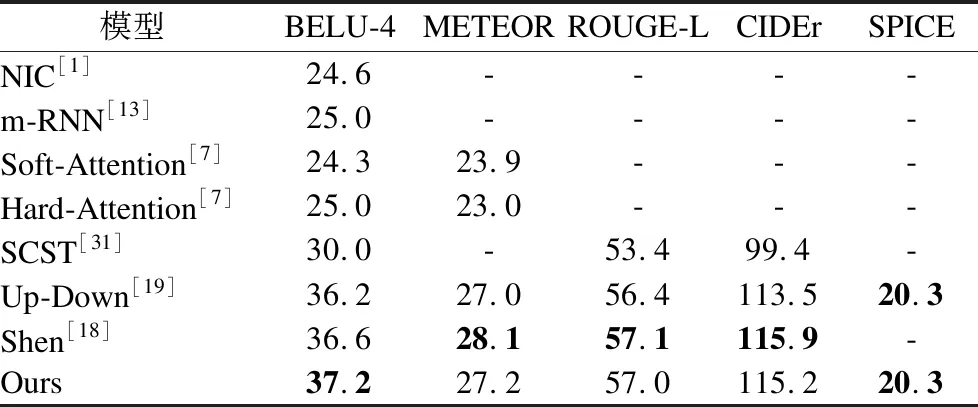
表2 不同模型在MSCOCO数据集上性能比较的结果
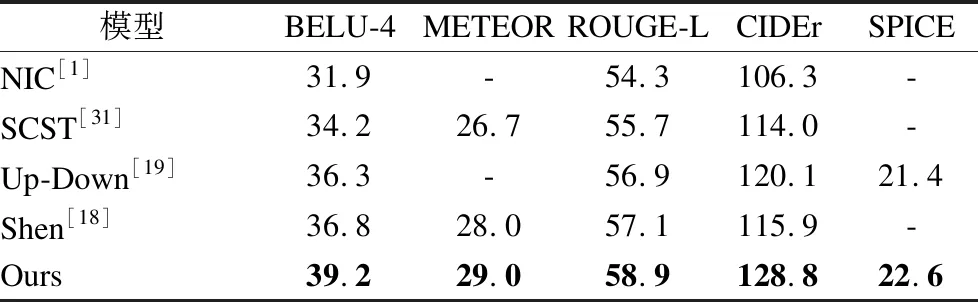
表3 在MSCOCO数据集上不同模型使用SCST下优化的结果

表4 不同模型在Flickr 30k数据集上性能比较的结果
同时为了验证本文提出模型实验数据的真实可靠性,将模型在2014MSCOCO test数据集上进行了验证,该数据集无真实标签,故将生成的结果提交MSCOCO在线测试平台,并上传评估服务器进行评估.评估结果如表4所示.其中B-1、B-2、B-3、B-4、M、R、C分别表示BELU-1、BELU-2、BELU-3、BELU-4、METEOR、ROUGE-L和CIDEr.表4中,C5和C40分别表示每张图片的真实标签有5句话和40句话.从表5中可以看出,本文提出的模型在MSCOCO测试平台上,BELU-4和CIDEr分数相较于其他模型取得了较高的结果.本文随机从样本中抽取出6张图片以及相应的3句真实标签和对应模型生成的语句.使用NLTK工具对模型生成的图像标题和外部知识语句进行了可视化对齐的操作.如图4所示,可以看出本文模型生成的语句与外部知识语句的相似度非常高,但是生成的语句并不是完全一样,再一次说明本文的模型是从外部知识中提取出了高层的语义信息去引导本文模型语句的生成.从图5(a)可以看出,模型生成的描述相比于外部知识而言,关注到了图像中的场景信息“grass”和局部信息“apple”、“boy”.其对图像中更加细粒度的信息有更加显著的关注.
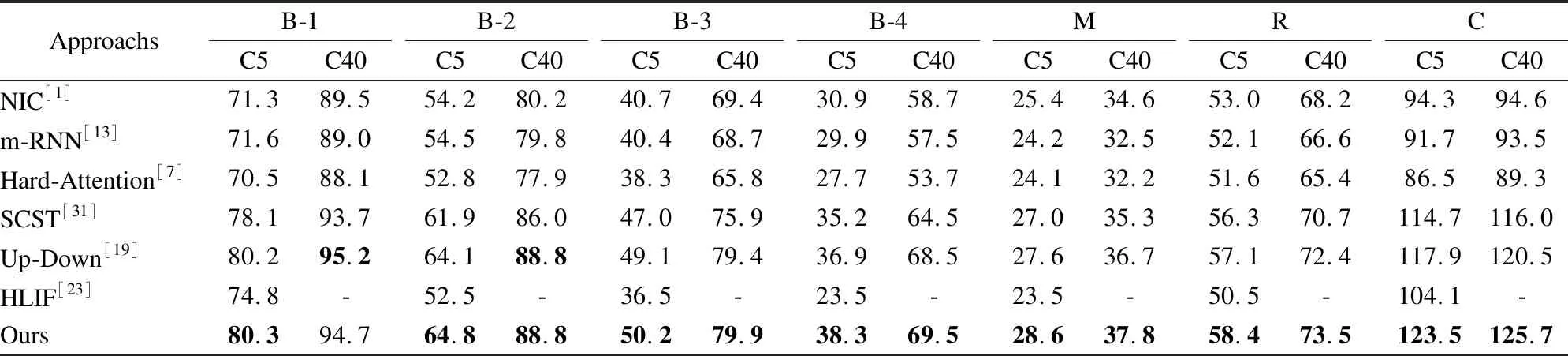
表5 MSCOCO在线测试平台测试结果
图4 图像标题对齐热力图

图5 图像标题生成的示例
在图5(d)中看出外部知识语句关注的细节和本文模型关注到的细节信息有所区别,外部知识语句缺乏对“snowy mountain”的描述,而本文模型可以关注到这是一座雪山.在图5(e)中,本文的模型生成的描述学习到了真实标签内容以外的单词“road”,而道路单词其中就包含了“city street”,但是其范围太广,而外部知识语句更加贴合真实标签.该示例原因可能是同时融入全局和局部特征时,引入了一部分噪声.但是通过定性的分析,本文提出的模型在一程度上可以概括图像中的局部和全局的信息,而且提出的方法所生成的语句是从外部知识模块中学习到了高层次的语义信息,从而使得本文生成的语句内容更加丰富,如图5所示.
4 结束语
针对现有图像标题生成任务的不足之处,本文提出了一种新的框架结构进行改善.首先,在编码阶段本文使用预训练的ResNet-152网络提取图像的全局信息.为了能够提取出更加细粒度的信息,使用Faster R-CNN网络对图像的局部特征、位置信息以及类别信息进行了进一步的提取.其次,在解码阶段,基于外部知识引入了互注意力模块和门控机制.其中,门控机制使得模型在第1层LSTM中能够区分视觉信息和当前时刻的文本信息,在第2层LSTM中将提取出的语义信息和图像特征以及外部知识融入互注意力模块.在互注意力模块中进行了信息间的交互,从图像语义到文本信息再到图像的特征.实验结果表明,本文提出的模型所生成的描述语句更加丰富,对图像中的内容理解的也更加全面.在未来的工作中将考虑对于特征信息的进一步筛选,剔除噪声信息,结合Transformer[35]来生成图像标题.
