融合SimAM注意力机制和双向ConvLSTM的异常检测方法
2023-08-29袁红春张文凤
袁红春, 张文凤
(上海海洋大学 信息学院,上海 201306)
1 引 言
近年来,监控视频数据急剧增长.随着人们对公共安全的重视程度的增加,监控视频的异常检测成为计算机视觉领域的重要研究方向.监控领域可用于智慧城市、市场、银行、商场、街道等多种公共场所.不同于普通二分类问题,视频异常检测的训练数据并不充分,导致异常行为和正常行为的数据分布严重不均衡.另外,异常行为的定义复杂且模棱两可,不同的场景中有不同的定义,作为异常事件的正类内的高方差可能包含多种不同的类.传统的视频异常检测方法一般通过人工提取特定视频特征[1,2],基于时空的方法侧重于提取空间与时间维度上的特征来表征视频的运动状态,通过计算阈值判断行为是否为异常.主要包括光流特征[3]、光流方向直方图[4]、方向梯度直方图[5]等.基于跟踪的方法主要利用速度、方向、位置、长度等特征建立正常轨迹,根据这类静态特征提取目标的运动轨迹,判断是否为异常轨迹点.如Wang等人[6]通过改进正则化方式提出密集轨迹算法用于行为识别.Tung[7]等人通过建立一个区域转换模型,获取物体的正常轨迹.训练时设定阈值为最大观测似然值,测试时大于该阈值的判定为异常.传统方法在简单的目标场景中能够根据选定的静态特征判定目标行为类别,但对于复杂的视频交互场景,选定的特征表示能力深受限制,且耗时费力.
近几年,无监督学习在视频异常检测领域显示出良好的竞争力.一类是重构模型,基于正态性建模的思想通过对编解码结构进行训练,并重新生成输入图像.测试时对异常事件进行重构会产生较大的重构误差.另一类是预测模型,通过前n帧预测后面帧,通过预测值和真实值的误差判断异常.
自编码器(Autoencoder,AE)被广泛地应用于重构模型,将高维输入X编码成低维的隐变量h,从而迫使神经网络学习最有用的特征,解码器的作用是把隐藏层的隐变量h还原到初始维度.重构模型的目标是通过最小化重构误差重建输入的视频帧,当训练好的模型遇到异常视频数据,会得到较大的重构误差.在重构建模过程中,可以采用多种技术表征监控视频中的正常行为.AE作为一种典型的时序特征提取算法,鉴于其具有良好的表征能力,现已经广泛应用于图像的重构工作.文献[8]利用卷积自编码器(Convolutional Autoencoders,CAE)构建时空模型用于学习正常行为的信息.Luo等人[9]提出一种基于深度学习的无监督学习模型,称为外观和运动深度网络(Appearance and Motion DeepNet,AMDN),模型第一阶段采用堆叠降噪自编码器(Denoising Autoencoders,DAE)提取外观和运动特征.第2阶段利用第1阶段得到的特征图,使用多个单类支持向量机(Support Vector Machine,SVM)模型计算异常得分.哈桑等人[10]提出使用CAE学习视频中的空间规则模式.这类方法利用2D卷积和池化运算作用在空间维度上,不能捕获异常活动的时间特征.为了提取时序数据的时空相关性,Shi等人[11]对降水预报的时空预测问题提出ConvLSTM(Convolutional LSTM Network),利用卷积提取同一时间步的空间关系,利用LSTM提取相邻时间步的相关性.对比光流法,其能够更好的处理边缘信息,泛化效果更好.Luo等人[12]提出将CNN与ConvLSTM结合,使用CNN对单帧视频进行编码,使用ConvLSTM记忆运动信息的外观变化.Ye等人[13]通过结合卷积LSTM和RGB图差异捕获长期运动信息.Park等人[14]引入记忆模块Memory,在记忆模块中记录正常数据,利用输入作为查询项检索记忆模块中最相似的一项进行重构,利用Hard Shringkage策略增加寻址权重的稀疏性,实现异常事件的检测.MEMAE(Memory-Augmented Deep Autoencoder)模型能够记忆重要的正态模式,用于基于重建的正态模型.但是,重建前景对象只使用非常少的一部分正态模式,只记忆重要的正态模式有时也会导致信息丢失.Lonescu等人[15]引入一种以对象为中心的CAE学习框架学习运动和外观特征,利用聚类方法训练异常分类器,实现正类样本与其他样本的分离.最近一项工作中,Li等人[16]利用双流自编码器架构分别提取外观和运动信息.然而,双流网络的结构调整和光流特征的提取需要较大的时耗.在视觉领域,注意力机制应用广泛,主体是通道注意力机制和空间注意力机制两类.SENet[17](Squeeze-and-Excitation Networks)通过门控机制,生成通道权重实现特征图的校准.Wang等人[18]提出对卷积网络的中间阶段堆叠注意力模块,添加注意模块增强特征信息.
基于预测的方法中,U-Net是一种典型的重构误差判别算法,通过添加跳跃连接分支减少降维导致的信息损失,在图像重构中被广泛使用.如Tang等人[19]将生成器设计成两个串联的 U-Net 网络,前一块U-Net用于未来帧做预测,后一块重建前一个U-Net生成的预测帧,未来帧预测只能预测正常事件的发生,有利于放大异常帧的重构误差,进而对异常事件的识别,重构有利于增强预测的未来帧,该模型实现了良好的异常检测效果.Nguyen等人[20]设计了一个未来帧预测框架,通过训练一个U-Net网络,网络输入T帧的训练视频片段,预测出时间为T+1的帧.Liu[21]等人基于U-Net的预测模型,通过计算规则性得分判断异常行为.Chen等人[22]根据目标帧和预测帧构造损失函数,提出利用滑动窗口的异常分数估计方法,该双向预测模型有效地提高模型的准确性.Li 等人[23]提出多变量高斯完全卷积对抗自编码器,依据普通视频的潜在表示基于先验分布,异常视频帧不处于先验分布的事实,采用基于能量的方法,根据训练模型的概率分数得到异常视频的异常得分.利用梯度光流表示视频片段的特征进一步提高模型的检测效果.
考虑到预测方法高度依赖先验知识,前后帧的任意变化对检测效果影响很大,本文选择构建鲁棒性相对较高的重构模型.R-STAE[24]在编码网络后添加单级残差模块有效地解决了深度网络中的梯度消失问题.Yang[25]等人依据著名神经科学理论提出SimAM注意力机制,利用能量函数并快速求解解析解的方式为每个神经元计算三维权重.鉴于SimAM注意力机制作为一种新型注意力操作,避免传统注意力机制需要训练对应子网络的权重.本文为R-STAE残差网络结合SimAM注意力机制,为每个特征点分配对应的动态权重值,实现更好的聚焦主体目标信息,提高CNN对视频帧序列的显著性区域的特征表示.再引入跳跃连接,带有跳跃连接的残差网络能够聚合网络不同层间的重要全局信息,降低信息传递中的特征损失.为了在时域方面捕获空间特征的关联性,Song[26]采用BiConvLSTM提取时间维度的空间特性,弥补循环神经网络(Recurrent Neural Network,RNN)无法捕捉图像序列中运动特性的缺陷.本文模型利用CNN联合BiConvLSTM捕获时空特征,着重分析人群局部外观和运动变化,在基准数据集UCSD-Ped1和UCSD-Ped2上,相比最先进的重构方法,本文提出的网络模型具有更优或相近的实验结果.
2 用于视频异常检测的注意力残差网络
近年来,深度学习得到迅速发展,自编码器通过损失最小化可以有效地编码任何给定的数据分布.最近的工作中,R-STAE通过设计带残差模块的自编码器,有效地检测到视频中的异常行为.为了提高模型表征特征图的重要区域的能力,本文为残差模块融入SimAM注意力机制.不同于R-STAE残差模块的作用点,本文将残差模块应用到所有的编码结构和解码结构(除了编码网络和解码网络的输出层),并对残差块引入稠密连接,最大程度地融合不同层间的信息.当前提取时序特征多选择LSTM网络和光流法,如Li等人[16]利用光流法提取时间流的运动模式,需要较大的时耗和网络结构调整.文献[9-12]利用ConvLSTM获取视频序列的外观和运动变化取得良好的实验结果.本文利用堆叠的BiConvLSTM获取时空相关性,融合前后序列信息 共同表达时空特征信息.
2.1 SimAM注意力机制
传统的注意力机制,如通道注意力机制与空间注意力机制,只能在单一维度上细化特征,而在其他维度上同等对待,利用特征图生成基于通道的一维权重和基于空间的二维权重,并拓展权重最终形成注意力特征图.SimAM注意力模块是一种能够同等对待所有维度的注意力机制,其能生成优于一维或二维权重的三维权重.视觉神经科学领域将放电模式明显不同于周围神经元的一类神经元认为是信息最丰富的神经元,该类神经元有明显空间抑制效应应当被赋予重要权重.为了找到具有空间抑制效应的神经元,Yang等人通过为每个神经元定义能量函数,如公式(1)所示,依据能量函数可以算出解析解表示每个神经元的能量值,进而计算出每个神经元的重要权重值.
(1)
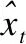
(2)
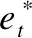
2.2 融合SimAM注意力机制的残差模块
本文设计的融合R-STAE残差模块和SimAM注意力机制的残差网络如图1所示,它由两组相同的结构组成,每组结构由级联卷积接一个批量归一化层和tanh激活函数,再融合SimAM注意力机制.大卷积级联会导致参数暴涨,通过级联卷积细化特征,使用小卷积核级联卷积能够减少参数计算,再通过批量归一化层和tanh激活网络层对特征图进行非线性映射.为了区分特征图中显著特征区域,嵌入SimAM注意力模块到卷积中,SimAM模块对多维特征图计算每个神经元的3维权重,得到在通道和空间均有显著性区别的特征图.考虑到relu函数没有上限,激活函数选择使用tanh函数.最后,残差模块接入按通道特征联合的跳跃连接,借助跳跃连接concatenate操作将残差模块输入和输出特征图按照通道维度进行合并,通道联合操作可以增强跨层间特征信息的传输,更多图像语义特征得以保留.
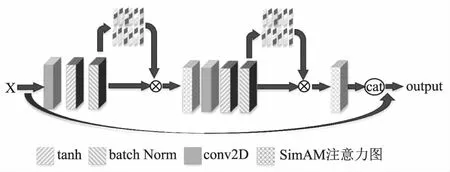
图1 融合SimAM注意力的残差结构
2.3 双向卷积长短时记忆网络
图2残差时空自编码器网络结构图的BiConvLSTM模块展示了BiConvLSTM网络结构.单一的ConvLSTM仅有前向传递的信息决定输出,而BiConvLSTM由一组前向ConvLSTM和一组后向ConvLSTM组成,当输入多维向量的特征后,由正反两个方向的ConvLSTM处理输入数据,可以捕捉长期和短期的潜在表示,两个方向上通过卷积操作不断更新隐藏层状态和存储单元状态,最终通过两个方向的隐藏层状态决定最终隐层状态.公式(3)给出了经过双向时空结构的输出结果yt,hf和hb表示t时刻的正向隐藏层和反向隐藏层的状态,tanh激活函数用于对正向和反向的信息进行非线性映射到输出.
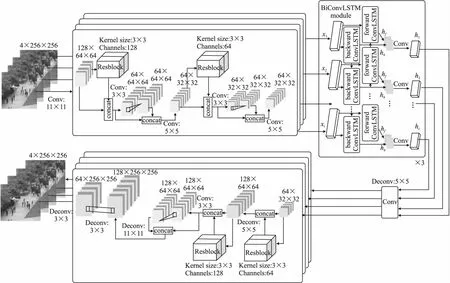
图2 残差时空自编码器网络结构
(3)
2.4 基于RS-BCAE的正态性建模
如图2所示,本文提出一种融合SimAM注意力机制和BiConvLSTM的残差时空自编码器模型.利用正常事件的视频数据训练自编码模型,空间自动编码器用于学习视频序列的空间相关性,BiConvLSTM用于学习空间结构的时间相关性.数据的空间表示和运动表示将被输入到解码器后进行信息重建.正态性模型训练完成后,利用测试结果与真实结果的偏差检测异常,根据重构误差计算每一帧视频的规则性分数.
主干网络结构部分,本文参考AlexNet网络的大卷积核以及Inception结构堆叠不同尺寸卷积核可获得比单一尺寸更丰富的特征,卷积核使用11×11和5×5的卷积核,这种大卷积核的选择使得网络感受野更大,获得的卷积信息更丰富.T帧视频序列先输入到卷积核为11×11的卷积网络,提取大量低级的局部特征.RS-BCAE残差是对R-STAE的残差部分的拓展,2组级联3×3的卷积融合无参SimAM注意力机制,卷积后添加了归一化层和激活层,不同于传统注意力机制(如通道注意力机制、空域注意力机制), 3D注意力SimAM对所有空间位置和通道都同等对待,且不需要额外设计子网络,利用能量函数计算每个神经元的权值,实现对特征增强处理,更好聚焦主体特征,降低大卷积核带来的参数暴增.特征降维处理中,考虑到下采样偏重于高级特征,易损失分辨率,分别使用步长为4,2的卷积操作降低特征维度.
本文使用3层堆叠的BiConvLSTM提取视频序列的时空相关性.BiConvLSTM是ConvLSTM的增强网络,图2 BiConvLSTM模块展示了每层BiConvLSTM单元的具体组成.每个时间步长里,数据输入到多个BiConvLSTM单元进行级联处理,每个BiConLSTM单元由前向和反向ConvLSTM单元组成,上一个单元隐藏层状态和细胞状态输入到下一个单元.前一时间步长的输出作为后一时间步长的输入.所有的状态转换均经过卷积操作,并对隐藏层进行零填充保持输入和输出的大小一致.解码器结构主干层使用反卷积操作获得全局特征卷积核大小分别为5×5和11×11,由文献[27]启发,反卷积层后分别接R-STAE残差和本文设计的残差模块,交替使用卷积和反卷积进一步对特征图进行增强.反卷积是一种特殊的正向卷积,先按照一定的比例通过补0来扩大输入图像的尺寸,再进行正向卷积.本文分别使用步长为1,2,4的反卷积恢复特征图维度,最终获得与输入序列相同尺寸的T帧重构序列.
在异常检测中,采用标准化重构误差的量化方法,借鉴哈桑[10]等论文中提出的方法通过计算原始信息和重构信息之间的重构误差判断正常和异常行为,并通过绘制误差曲线反映该方法改进异常检测方面的直观性.
模型基于正态性建模思想,正常视频序列的均方误差值更小,异常视频序列的均方误差更大,利用欧氏距离计算输入视频序列和输出视频序列之间的均方误差,如公式(4)和公式(5)所示:
(4)
(5)
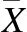
根据视频序列的重构误差,可计算出单帧误差,对单帧重构误差计算标准化分数,对结果做归一化处理,如公式(6)所示:
(6)
其中e(t)表示视频帧t的重构误差,e(t)min和e(t)max表示重构误差中的最小值和最大值,E(t)代表视频帧t标准化分数,当重构误差越大,标准化分数值越大.
3 实 验
3.1 数据集
实验所用数据来自加利福利亚大学圣地亚哥分校(UCSD)行人数据集UCSD-Ped1和 UCSD-Ped2.视频异常行为的定义是模棱两可、不明确的.对于不同的现实场景,同一个行为是否属于异常经常依据环境而定,人行道上行走是正常行为,但是,在草坪上行走就被认为属于异常行为.加利福尼亚大学圣地亚哥分校的研究人员收集了用于异常行为检测的数据集.Ped1数据集由34个训练视频和36个测试视频组成,Ped2数据集由16个训练视频和12个测试视频组成.训练视频仅包含正常行为,测试片段包含正常行为和异常行为,异常行为包括在步行区行驶机动车、自行车等.
3.2 数据预处理
本文按照视频帧提取、图像去噪、图像归一化、零均值化和数据帧合成的处理流程对视频数据做预处理.为了获取更详细的视频信息和降低漏报率,选择逐帧提取的方式,利用scikit-video包提取视频帧.
由于进行异常检测的视频一般是人员相对密集的公共场所,环境较为复杂,不可避免地存在大量噪声,需要对图像进行去噪.将视频帧转换为灰度图像以减少数据尺寸.本文采用中值滤波器法,对灰度图使用模板像素的灰度中值代替原有的目标像素值,中值滤波能在去除噪声的同时有效地保护边缘信息.
图像归一化[28]处理使用min-max标准化.对图像的像素值作线性变换,将值映射到[0,1]之间.本文将数据帧大小统一被调整为256×256,将像素值归一化为0~1.
零均值化将所有视频帧的灰度平均值中心化到0,通过改变图像灰度值的分布,这有利于降低数据大小,进而提高模型的计算能力.先计算所有待训练图像的灰度平均值,通过遍历n张图像的所有像素值计算灰度均值I*,转换函数如公式(7)所示.再用原始图像减去灰度均值I*,得到零均值化图像,该操作使得图像均值为0,灰度值分布发生平移.
(7)
其中I*表示图像灰度均值,n表示图像数量,I(x,y)表示图像某点的像素值.
为了捕获数据在时间维度上的关联关系,采用特定的T帧在时间轴上堆叠数据,生成HDF5文件.模型不需要任何的特征变换,使用长度为T的滑动窗口进行特征提取.当T取值增加时,将容纳更长的运动信息,因而也会导致模型收敛时间变长.本文在实验阶段设置时间步长T分别为4和10.
3.3 异常检测指标
受文献[10,29]的启发,将AUC(area under curve,AUC)和等错误率(Equal Error Rate,EER)作为模型性能的评估指标,AUC是指通过计算不同阈值的受试者操作特性曲线(receiver operation characteristics,ROC)下面积.在正负样本的分布发生变化时,ROC有良好的不变性特性,如异常检测中的类不平衡现象.对于二分类问题,基于机器学习的模型一般将分类问题转化为概率,将AUC作为评价指标,避免通过手动设置阈值,将预测概率转化为类别的过程.等错误率EER是ROC曲线上假阳率FPR与假阴率FNR相等的点,表现为[0,1]与[1,0]的连线同ROC曲线的交点.算法性能评估AUC面积越大,EER越小,表示性能越好.
3.4 实验结果
本文设计两类对比实验,第1组消融实验对RS-BCAE的残差模块、跳跃连接以及 BiConvLSTM的有效性做了评估.公用数据集上,RS-BCAE的残差模块的AUC对比R-STAE残差模块、不含残差模块、经典残差结构ResNetV1、ResNetV2的实验结果.将残差结构替换成上述其他残差结构时,自编码器主干网络结构保持不变.如表1所示,本文设计的融合注意力机制和R-STAE的残差结构的AUC值高于其他残差模块的实验结果,精度提高4%以上,相比R-STAE,本文将残差模块应用于CAE的所有层,不仅仅是编解码中间部位.由实验结果可知,融合SimAM注意力机制的残差结构及调整残差模块作用点更好地优化网络结构,整体提高了模型检测性能.

表1 残差模块对比结果
为了减少信息在传递过程中的损失,让正常前景细节尽可能得到保留,残差模块末端引入跳跃连接,利用稠密连接融合浅层特征和残差输出的深层特征图,增强层间信息提取能力.表2分别给出按特征图的通道维度连接、求和跳跃连接、不包含跳跃连接的RS-BCAE性能对比结果,按特征图通道维度连接的方式能够保留更多的全局信息,降低信息损失.
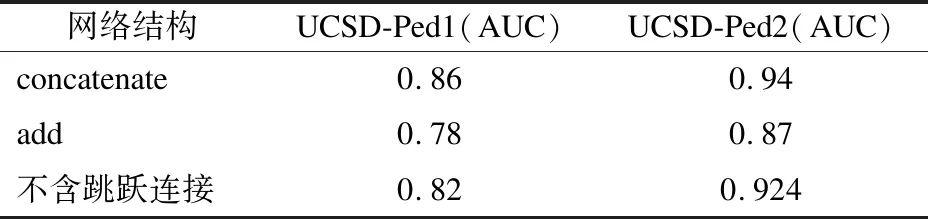
表2 跳跃连接有无性能对比结果
不同于FC-LSTM,ConvLSTM中的输入和隐藏层、隐藏层间均将全连接替换成卷积操作,用于提取同一时间步长内,待测值之间的空间相关性,内部的LSTM结构用于提取相邻时间步长之间的相关性.BiConvLSTM使用前向与后向两组ConvLSTM的最后状态共同决定信息流.本文为此做了另一组消融实验如表3所示,对比两者之间对时序特征提取的能力.在时空特征提取上,BiConvLSTM在时空相关性的表达上略优于ConvLSTM,且模型的稳定性相对更高.

表3 两种记忆网络的对比结果
第3组实验对比其他重构模型Conv AE、ConvLSTM AE以及MEMAE的AUC值.图3和图4表示模型在数据集上UCSD的AUC值和EER值,在UCSD-Ped1和UCSD-Ped2上分别为0.865和0.94,EER值分别为0.209和0.12.以UCSD-Ped2为例,图5展示模型在残差块性能方面的对比图,文中分别实验包含RS-BCAE残差、ResNetV1、ResNetV2和不含残差模块的模型,其中RS-BCAE残差得到的精度高于其他残差模块,高于不包含残差模块的实验结果,且精度高于R-STAE精度.本文的融合SimAM注意力机制的残差结构对提高模型精度具有有效性.图6分别绘制重构模型Conv AE、ConvLSTM AE、MEMAE、RS-BCAE的ROC曲线,本文RS-BCAE的精度比Conv AE模型提高约5%,比ConvLSTM AE模型高5.2%,比MEMAE记忆网络模型提升约4%,记忆网络模型MEMAE重建前景对象只使用非常少的部分的特征表示,这种只记忆重要的正态模式有时也会导致信息丢失.本文对CAE的所有层(输出层除外)均使用按通道连接的跳跃连接,尽可能地融合全局特征信息,降低长程信息的损失.

图3 UCSD-Ped1 ROC曲线
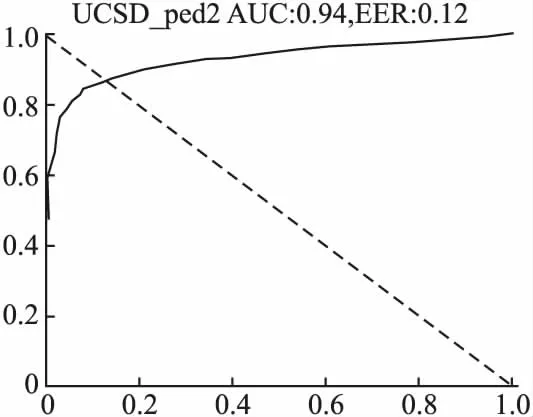
图4 UCSD-Ped2 ROC曲线
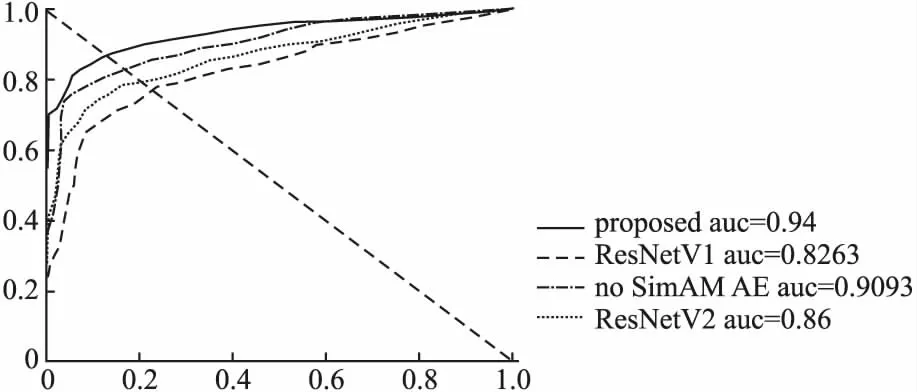
图5 帧级ROC 上不同残差块的比较
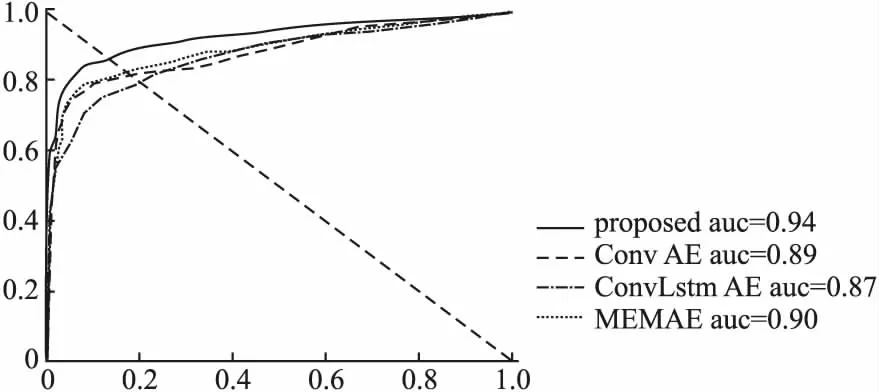
图6 帧级ROC上不同重构模型的比较
为了说明RS-BCAE模型的有效性,在基准数据集UCSD-Ped1和UCSD-Ped2上,本文模型分别列出几种经典算法、深度学习的重构算法.深度学习方法中包含近两年的方法,如MEMAE、ST-CaAE和R-STAE等.如表4所示,RS-BCAE模型的精度远远高于传统模型的性能,在UCSD-Ped1上,RS-BCAE模型低于时空级联自编码器的实验结果,高于其他模型精度.在UCSD-Ped2上,RS-BCAE模型高于其他重构模型精度,且EER值低于其他模型.可以看出在基准数据集UCSD上,本文的模型在重构模型中有良好的竞争效果.
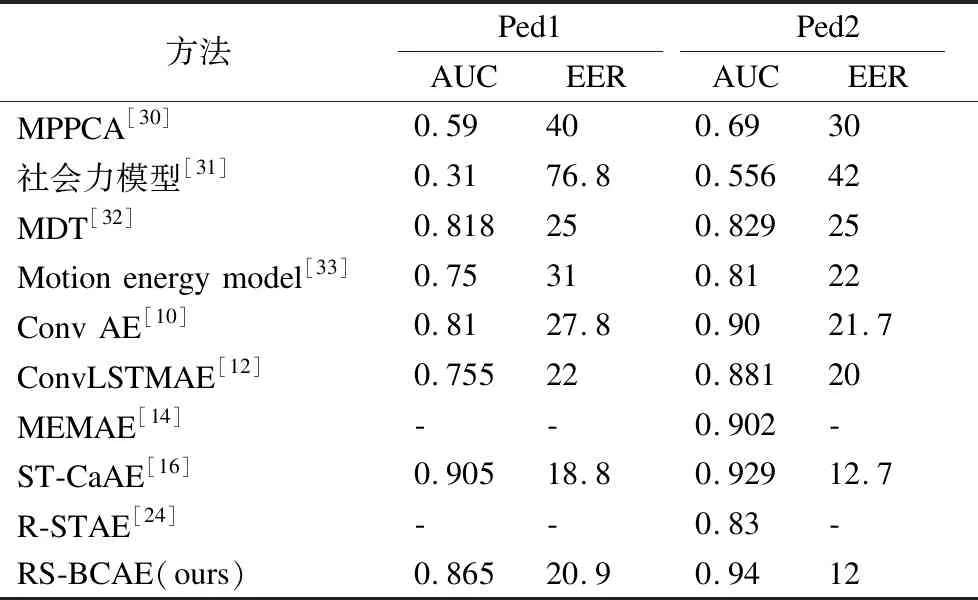
表4 UCSD数据集上不同算法的对比结果
为了提高算法的观测效果,本文绘制了测试视频序列的得分曲线图,可视化重构误差值.图7(a)和图7(c)是视频帧原图,图7(b)和图7(d)分别对应图7(a)和图7(c)的误差可视化结果,通过对模型输出的重构图和输入图之间的误差值做可视化处理,异常行为存在的像素区域更加明亮,表示误差值较大.图7(b)中步行区域出现骑行行为,图7(d)步行区域出现汽车行驶和骑行的异常行为,图中这些异常行为区域颜色较为明亮,其误差值较大.图8(a)和图8(b)分别展示了UCSD-Ped1和UCSD-Ped2的某个视频片段,灰色区域表示实际异常行为的发生时间,图8(a)在第175-200帧出现了人行道上骑车的异常行为.图8(b)在第31~180帧之间出现人行道上骑行的异常行为.本文基于正态性建模思路,模型仅学习正常行为事件,而没有学习异常行为的规则模式.当待测视频出现异常行为的时候,预测帧和输入帧之间的重构误差会增加,根据公式(6)得出,灰色区域规则性得分会严重上升.
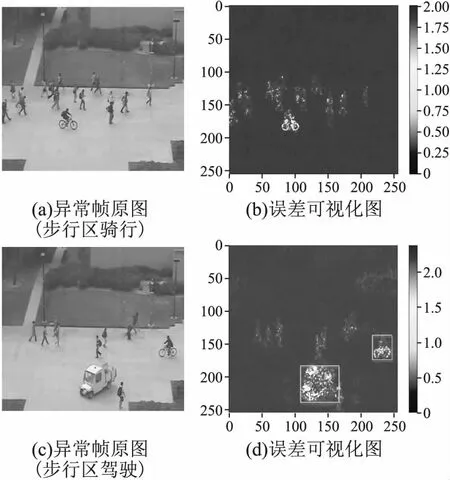
图7 异常帧原始图和误差可视化结果图

图8 UCSD数据集的异常片段
4 结 论
本文提出一种基于SimAM注意力机制和BiConvLSTM的残差时空模型对时空事件进行检测,利用卷积神经网络和深度BiConvLSTM分别提取视频序列的时空特征.设计一种融合新型注意力机制和R-STAE残差结构的残差结构,使用按通道连接的跳跃连接聚合不同层次间的全局特征.本文设计三组消融实验和一组模型对比试验.首先,对比R-STAE残差、ResNetV1、ResNetV2和不包含跳跃连接的模型精度,验证本文设计的残差结构的有效性.另外两组消融实验分别验证了添加按特征图连接的跳跃连接和堆叠BiConvLSTM的有效性.最后,模型实验对比包括最新的其他重构模型精度.本文模型RS-BCAE的检测效果优于或近似其他重构模型.
