基于VMD-BiLSTM-Attention 的抽水蓄能机组性能劣化趋势预测
2023-08-28李新新马森源刘铮光
方 娜,李新新,马森源,刘铮光
(1. 湖北工业大学 太阳能高效利用及储能运行控制湖北省重点实验室,湖北 武汉 430068;2. 湖北工业大学 新能源及电网装备安全监测湖北省工程研究中心,湖北 武汉 430068)
0 引 言
抽水蓄能机组是一种复杂系统,其运行受到水力、机械和电磁等多种因素的影响。伴随投运时间的增加和工况频繁启停转换的影响,结构疲劳和劣化的问题日益突出[1]。这些问题的累积,可能导致机组水力不均和效率降低,从而对机组的正常运行产生安全隐患[2]。因此,为保证机组在各种工况下都能正常运行,需对机组进行及时准确的趋势预测。
一般来说,现有的预测方法主要为基于物理模型和基于数据驱动两种[3,4]。随着监测系统的不断完善,越来越多的监测数据被用来挖掘研究机组的运行状态,基于数理分析的趋势预测成为了研究的热点[5-7]。机组的振摆信号中蕴含着丰富的状态信息,通过建模分析能有效的评估机组的劣化趋势。文献[8]构建了基于最小二乘曲面原理的健康状态模型,获得机组输入参数和输出参数之间的映射关系;文献[9]采用自回归滑动平均模型,对抽水态和发电态下的机组上导轴承和上机架振摆进行了预测,验证了该方法在机械振动趋势预测上的有效性。文献[10]提出了一种机组劣化趋势预测模型,该模型利用自编码器进行压缩并进行多尺度特征提取,充分考虑了工况参数和振摆之间的关系,尽可能保留有效信息,并关注劣化趋势序列的整体和局部波动。文献[11]针对水电机组信号非平稳非线性的特点,利用VMD,结合CNN 出色的局部特征提取能力和长短期记忆网络LSTM 对时序特征的良好表现,提出一种基于VMD-CNN-LSTM 的混合神经网络趋势预测方法,该方法在确保预测准确性的同时,可以缩短预测时间,提高预测效率。
为准确预测抽水蓄能机组未来劣化趋势,本文深入分析机组现有的大量状态监测数据,探究监测数据与机组状态间的关联,提出一种基于VMD-BiLSTM-Attention 的趋势预测模型。首先,建立基于Bagging 算法的健康状态模型;其次,根据健康状态模型计算出机组劣化趋势序列;然后,利用VMD 算法对趋势序列进行有效分解,再借助深度神经网络良好的非线性特征提取能力,分别针对各模态分量建立BiLSTM-Attention 模型进行趋势预测;最后叠加重构各分量的预测结果即为机组最终的趋势预测结果。
1 基本原理
1.1 Bagging算法
Bagging 算法最初由Leo Breiman 于1994 年提出,是并行式集成学习的最著名代表,也是最早、最基本的集成技术之一。Bagging算法的思想是让该学习算法训练多轮,每轮训练都是从初始训练集中随机有放回的采样,得到T个训练数据集,形成若干个弱学习器,每个学习器相互之间是并行的关系,可以同时独立完成训练,最终将多个弱学习器结合,进行加权平均处理,得到最终的模型输出[12]。
相较于其他算法,Bagging的优点主要在于通过结合多个学习器,降低泛化误差,获得更好的泛化性能。同时,集成学习一般都是以弱学习器集成来得到一个强学习器,以便获得更好的性能,有效降低结果的方差,提升模型的预测准确率[13]。
1.2 变分模态分解算法
VMD 是2014 年提出的一种完全非递归、自适应的模态分解方法[14]。它通过求解优化频域变分问题,将强非线性和非平稳的复杂序列分解为不同频率且相对平稳的子序列[15],克服了LMD、EMD 等经典算法在信号出现阶跃性跳动时易出现的模态混叠和端点效应问题[16]。通过迭代变换寻求最优解,将非平稳信号分解为一系列标准正交模态函数,具体原理如下:
以各模态分量的估计带宽之和最小为目标,构造求解约束变分问题最优解。约束变分问题模型如下:
式中:δ(t)为狄拉克函数;y(t)为原始信号;ωk为各模态分量uk(t)的中心频率。
为求解约束变分的最优解,引入Lagrange算子λ(t)和二次罚因子α,将约束问题转化为非约束问题,并保证了约束的严格性。
式中:L(·)为增广拉格朗日函数;α用以保证信号重构的完整性;为二次惩罚项;λ(t)用以保证约束的严格性。
1.3 长短期记忆网络
LSTM 是一种具有特定构造的时间序列卷积神经网络,可以深度挖掘时间序列中复杂的时序变化规律,将短时和长时间的记忆融合,有效地解决了RNN仅具有短时、长时间的依赖性,并考虑到时间序列的时序性与非线性的关系,克服了在建模过程中常常遇到的梯度消失/爆炸的问题[17,18]。由于其特殊的结构设计,使得其在学习时间序列中的长期和短期相关信息方面具有良好的表现能力,在预测领域得到了广泛的应用[19]。其结构单元图如图1所示,计算过程如下:
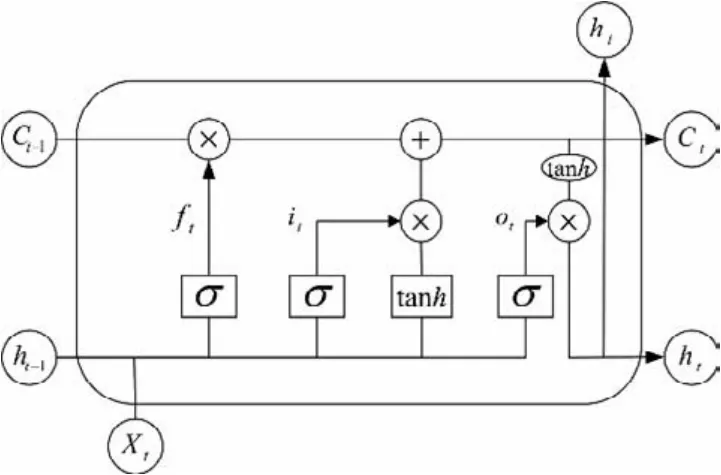
图1 LSTM结构单元示意图Fig.1 Schematic diagram of LSTM structural unit
式中:it、Wi为输入门的值及权重系数;ft、Wf为遗忘门的值及权重系数;ot、Wo为输出门的值及权重系数;σ和tanh 为sigmoid激活函数;xt为当前时刻输入;ht-1为前一时刻输出;ct为状态更新值;为候选向量;ht为最后的输出结果。
1.4 注意力机制
注意力机制(Attention Mechanism,AM)是机器学习中一种处理数据的方法,源于专家学者对人类视觉的研究而提出[20]。人在某些特殊时刻会集中精力于某些特殊领域,减少或忽略对其他领域的关注,以获取更多有用信息,抑制或摒弃其他的无用信息,其核心思想是通过巧妙合理的分配,忽略无用信息并放大有用信息[21]。Attention 机制的原理亦是如此,通过对特征向量赋予不同的权重,集中注意力来突出关键特征,从而得到更好的效果,其结构如图2 所示。其中,xt(t∈[1,n])表示BiLSTM 网络的输入,ht(t∈[1,n])对应于每一个输入通过BiLSTM得到的隐藏层输出,y为引入Attention 机制的BiLSTM 的输出值。
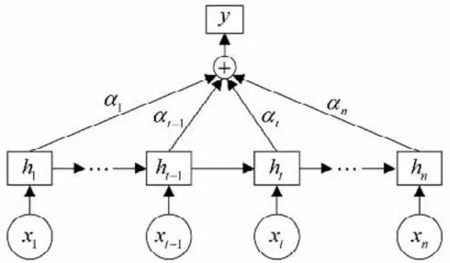
图2 Attention机制结构Fig.2 Attention mechanism structure
2 基于VMD-BiLSTM-Attention 的劣化趋势预测模型
文中提出的VMD-BiLSTM-Attention 劣化趋势预测模型的预测流程如图3 所示,主要包含3 个步骤:①建立基于Bagging的健康状态模型;②构建劣化趋势序列;③劣化趋势预测。
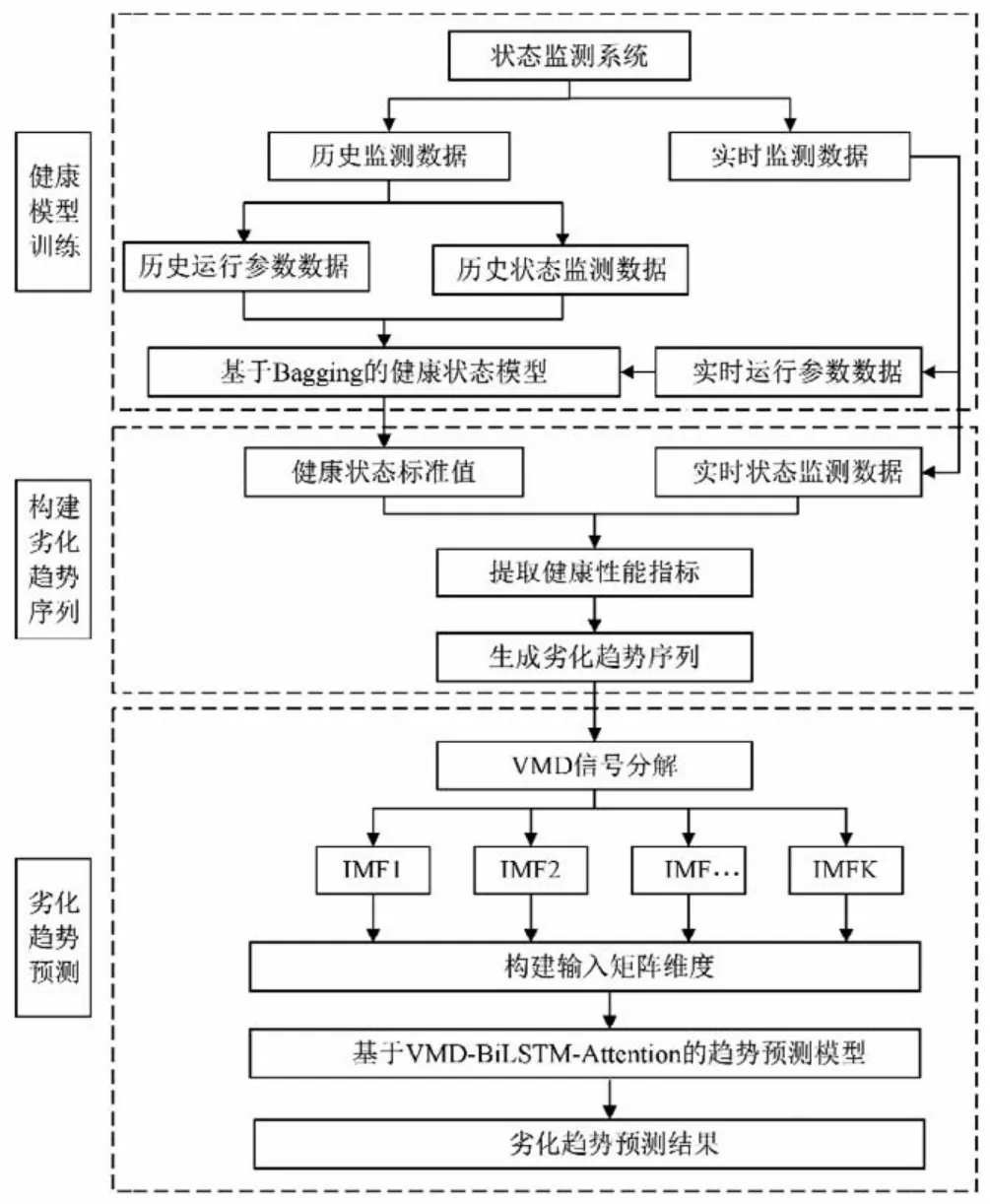
图3 劣化趋势预测流程图Fig.3 Deterioration trend prediction flow chart
2.1 基于Bagging的机组健康状态模型
通过对抽蓄机组历史监测资料中不同工况条件下的工作水头(H)、有功功率(P)、导叶开度(G)和转速(S)进行深入分析,建立起以Bagging 算法为基础的机组健康状态模型。实施流程如下:
(1)标准健康状态建模。选取与机组运行状态有较强关联性的敏感特性参数(H,P,G,S)等作为Bagging模型的输入,结合大量历史监测数据建立标准健康状态模型,然后将抽蓄机组历史状态监测数据(F)如摆度信号作为输出,获得运行参数(H,P,G,S)与状态监测数据间的映射关系:
式中:t为机组运行时间。
(2)构建机组健康性能指标。机组部件性能水平会随着服役年限的增加而逐渐降低,此时振摆的实测值V(t)往往会偏离同工况参数下健康值相互间的非线性映射关系。因此,为对机组的健康性能进行量化,本文将实时监测数据输入到机组投运初期的数据构建的健康状态模型中,以提取机组运行过程中健康性能指标序列。具体而言,将机组运行工况参数数据(H,P,G,S)作为健康模型输入,然后将该工况下计算得到的理论标准值F(t)作为构建模型健康性能指标的参考依据,并依据式(7)定义健康性能指标HPI:
式中:t为机组运行时间;性能指标取大于0部分。
2.2 VMD-BiLSTM-Attention 预测模型
由于提取的HPI 序列在时频域中不断地变化,具有较强的非线性和非平稳性,传统的预测方法在处理这些复杂信号时效果欠佳,为提高对复杂信号趋势预测的准确性,需考虑新的解决办法。本文综合VMD 在信号分解、BiLSTM 在时序预测和注意力机制在特征提取上各自的优势,提出基于VMD-BiLSTMAttention 的预测模型,能很好的泛化和预测高维非线性问题。将劣化趋势序列输入到预测模型中,得出机组未来健康的发展趋势,具体步骤如下:
首先,对原始序列进行VMD 分解,得到K个具有独立频率和带宽的模态分量,如图4所示。
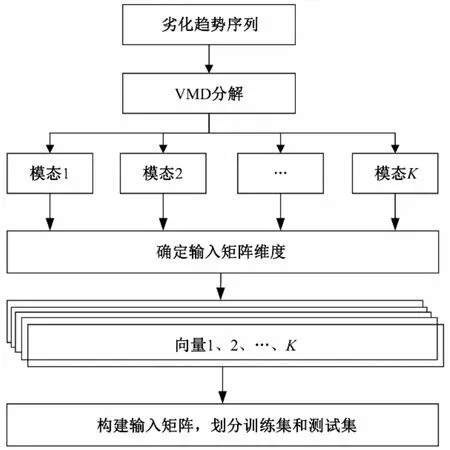
图4 变分模态分解Fig.4 Variational modal decomposition
其次,构建K个子分量的BiLSTM-AM 预测模型,结构如图5所示。
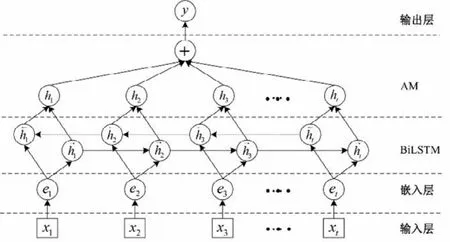
图5 BiLSTM-Attention模型结构Fig.5 BiLSTM-Attention model structure
按时间顺序将序列数据输入到BiLSTM 层。BiLSTM 会学习输入参数的特征,Attention层则对每个BiLSTM 层进行权重分配,以捕捉重要信息。最后,叠加重构各分量预测结果,即为机组最终的趋势预测结果。
本文选用Adam 优化算法更新网络参数,选用均方误差(Mean Square Error,MSE)作为损失函数,即:
式中:yi为真实值;为预测值;n为样本个数。
2.3 模型评价指标
为了综合评估模型的优劣并衡量预测结果的准确性,本研究采用了多个评价指标。主要选用的指标包括均方根误差(RMSE)、平均绝对误差(MAE)、平均绝对百分比误差(MAPE)和决定系数(R2)[23]。RMSE反映了预测值与实际值之间的偏差程度,MAE则衡量了预测值与实际值之间的平均差异,而MAPE则考虑了相对误差的影响。此外,R2可以帮助我们评估模型对数据的拟合程度,从而更好地理解预测结果的可靠性。具体公式如下:
式中:yi为趋势序列真实值为模型预测值;N为数据个数。
3 算例仿真分析
3.1 数据来源
机组设备的劣化趋势对其进行精准的趋势预测,制定科学合理的检修计划,节省非计划检修费用和安全稳定运行具有重大的现实意义和应用价值。本文选取某水电站2号机组数据进行仿真分析,以上导轴承X/Y向摆度来反映机组设备轴系稳定性的健康状况。根据电站运行报告,2019 年1 月15 日至2019年3 月15 日期间运行良好,以此阶段数据来训练和验证健康模型,推导出2019 年3 月16 日至2019 年9 月15 日的劣化趋势序列,训练并测试机组劣化趋势预测模型。
3.2 建立健康状态模型
为验证机组健康状态模型的有效性,选取机组正常运行时采集的数据并建立了Bagging 健康状态模型,该模型能够有效地映射机组运行参数(H,P,G,S)和振动之间的关系。选用机组2019 年1 月15 日至2019 年3 月15 日的数据样本建立健康模型并训练。为验证Bagging 模型的拟合能力,采用K邻近、线性回归和Bagging构建健康状态模型,并进行对比分析。
不同模型评价指标如表1 所示,其拟合结果如图6 所示。从表1 中可知,Bagging 模型输出值与真实值之间的RMSE分别为4.274、3.977,MAE分别为1.475、1.743,MAPE分别为18.937%、22.272%,决定系数R2为0.971、0.974。
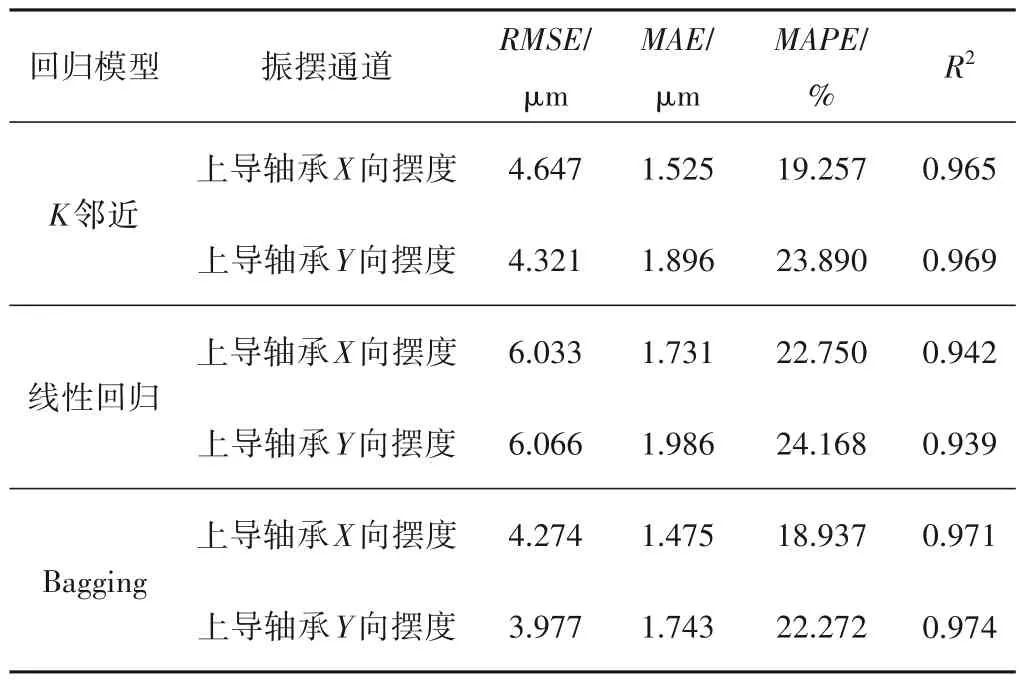
表1 各模型评价指标Tab.1 Each model evaluation index
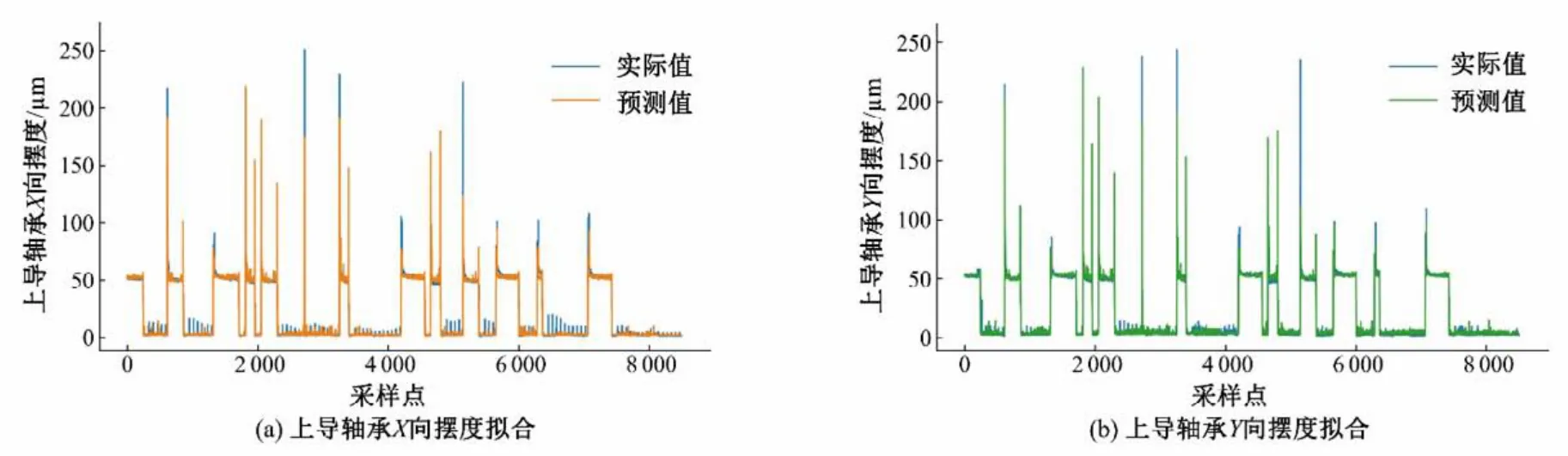
图6 基于Bagging算法的拟合结果Fig.6 Fitting results based on Bagging algorithm
由表1 和图6 可知,基于Bagging 的健康状态模型真实值与预测值基本吻合,表明Bagging 模型可从现有数据序列中挖掘机组运行参数与上导轴承摆度之间的关联。其拟合精度较高,表明基于Bagging 的健康模型能较好地刻画机组部件的运行特性。
3.3 劣化趋势序列生成
本研究选取了2019 年3 月16 日至2019 年9 月15 日的数据,以机组运行参数(H,P,G,S)作为健康模型的输入,在实际监测振动数据V(t)给定的情况下,计算出标准健康状态下的上导轴承振摆值F(t)。基于上述计算结果,依据式(7)计算上导轴承的劣化趋势序列,并得出其随服役年限的增加而逐渐出现劣化的结论。如图7 所示,机组设备的劣化趋势呈现出波动上升的趋势,这与实际生产情况相符,表明Bagging 模型可以生成可靠的劣化趋势序列。然而,该劣化趋势序列呈现非平稳和非线性的特征,且存在大量的局部波动,这为准确的预测带来了严峻挑战。
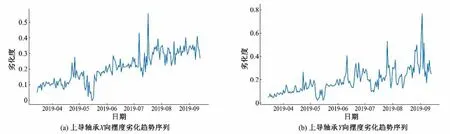
图7 上导轴承劣化趋势序列Fig.7 Upper guide bearing deterioration trend sequence
3.4 劣化趋势预测
为准确预测机组设备劣化趋势,根据所得劣化趋势序列,利用VMD-BiLSTM-Attention 预测模型对上导轴承劣化趋势进行预测。选用前80%的劣化序列用于模型训练,后20%用于测试,以检验所提模型的有效性。
采用VMD 将原始序列分解为4 个模态分量,如图8 所示。而后,将各模态分量置于对应的BiLSTM-Attention 模型中预测,叠加各分量的预测结果,获得上导轴承最终预测结果,如图9所示。
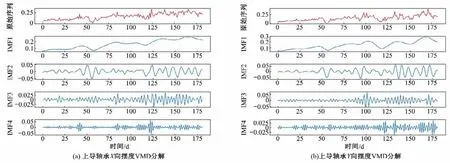
图8 VMD分解结果Fig.8 VMD decomposition results

图9 各模型的预测结果Fig.9 Prediction results of each model
为了验证所提模型的优越性,分别建立RNN、LSTM、BiLSTM、BiLSTM- Attention、VMD-LSTM、VMD-BiLSTM 和VMDBiLSTM-Attention 对劣化趋势进行预测并比较,结果如表2 所示。表2中给出了上导轴承X/Y向摆度的RMSE、MAE、MAPE和R2的预测结果,由表2 可知,文中所提模型的RMSE、MAE、MAPE和R2分别为0.005、0.008,0.004、0.007,1.881、3.291 和0.980、0.985,结果表明本文所提方法更为精准。
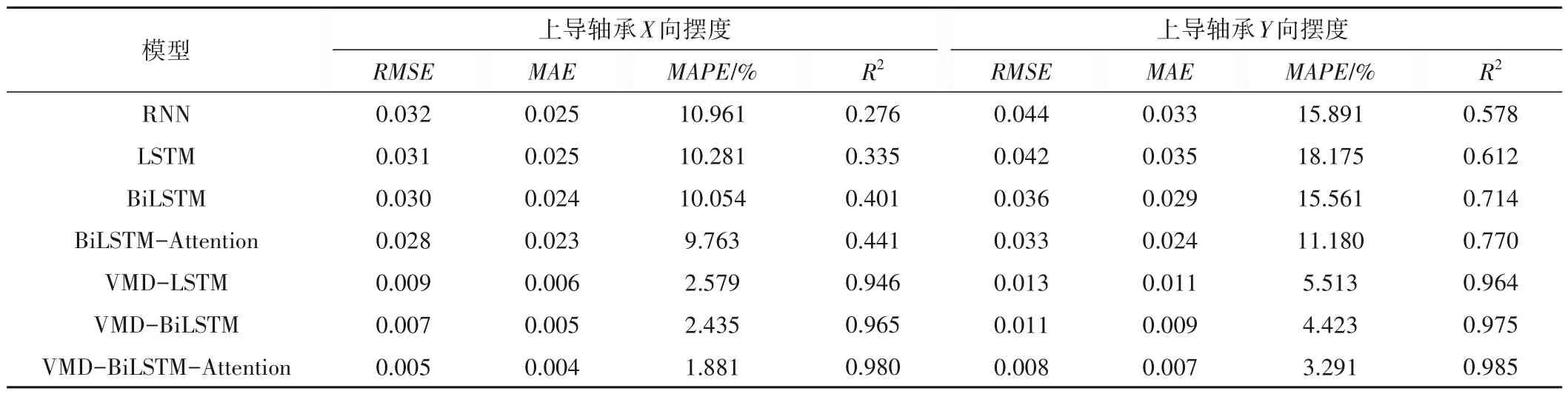
表2 各预测模型评价指标Tab.2 Each prediction model evaluation index
为对各模型预测效果有更直观的认识,采用误差分布箱线图来反映各模型预测性能上的差异,如图10 所示。由图10 可知,前4种未使用VMD 分解的模型预测的结果误差分布范围较广,且不在0 附近均匀分布,多存在异常值,表明这4 种模型的预测结果变化较大,预测结果的稳定性较差;后3 种使用了VMD分解的模型预测的结果误差分布范围较小且更加集中,误差中位数多接近于0,表明使用VMD 分解能够有利于处理复杂时间序列的预测问题。
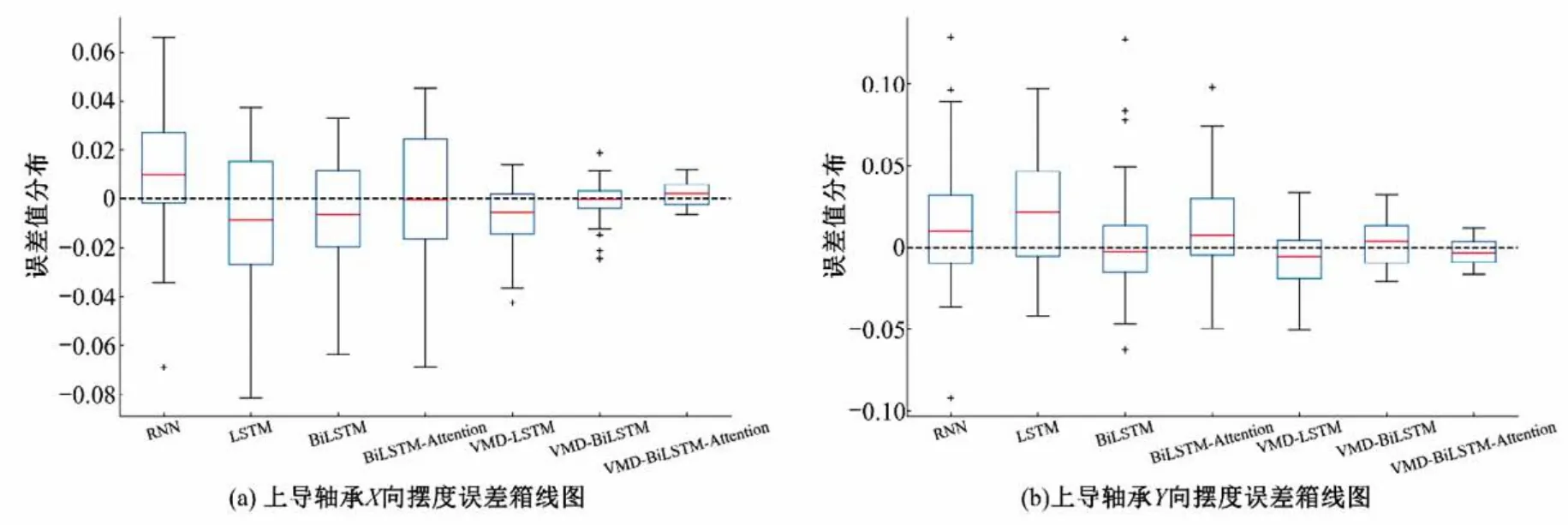
图10 各模型预测误差箱线图Fig.10 Boxplot of prediction error of each model
综上所述,通过对比分析各模型的预测误差分布,并结合本文提出的多维度评价指标进行全面分析,发现基于VMDBiLSTM-Attention 模型的预测精度高且表现稳定,较其他模型更为优秀,验证了本文模型在预测机组设备性能水平方面的卓越性。
4 结 论
本研究提出了一种基于VMD-BiLSTM-Attention 的机组劣化趋势预测模型,该模型能够很好地应对机组劣化趋势规律受运行条件影响具有随机和时变特点的挑战。通过仿真分析,得出以下结论:
(1)Bagging健康模型能很好地挖掘机组工况参数与振摆之间的映射关系,且拟合精度高,表明其可在较高置信水平下表征机组部件的运行特性。
(2)VMD 在非线性信号分解方面表现突出,将经VMD 分解后的劣化趋势序列作为BiLSTM 模型的输入,序列的时序性和非线性关系都能得到较好的分析。
(3)结合Attention 机制,突出关键特征,进一步提高了所提模型预测的精准度,表明模型可较好的实现机组性能劣化趋势的准确预测。
