雅砻江梯级水电站运行数据管理优化模型
2023-08-26陈平何朝晖丁义邵朋昊张凯荣
陈平 何朝晖 丁义 邵朋昊 张凯荣
摘要:
为解决雅砻江梯级水电站日常运行数据管理中存在的数据元素杂乱、计算及存储不规范、维护效率低等问题,采用“数据处理-计算存储-管理维护”技术链条,提出了基于对象和类别划分的数据元素处理技术、基于特征值的数据计算及存储规范化技术和满足读写快速性、质量可靠性及来源唯一性的数据管理维护技术等关键技术,以水电站日常运行数据为传输流搭建关键技术之间的耦合方式,由此建立了雅砻江梯级水电站运行多元数据管理优化模型。将所建模型集成至雅砻江综合自动化系统二期工程,有效提升了雅砻江流域电站运行数据的管理及维护能力。应用结果表明:提出的多元数据管理优化模型,能有效解决流域梯级水电站运行数据管理及维护问题,并为流域梯级水电站智能运行提供有力的数据管理技术支撑。
关 键 词:
梯级水电站; 多元数据管理; 规范化技术; 雅砻江流域
中图法分类号: TV737
文献标志码: A
DOI:10.16232/j.cnki.1001-4179.2023.08.035
0 引 言
随着中国“碳达峰、碳中和”目标期限的逼近,各种可再生能源的开发和利用受到高度重视。我国水能资源储量世界第一,具有实现碳中和的天然优势[1]。水电站运行是水电工程建成后的重要工作内容,如何高质量运行水电站并提升运行调度智能化水平,是后工程时代中亟待思考的问题之一。当前,中国电网和水力发电企业都在积极探索实现水电站智能化运行的有效途径,其中一项是对水电站运行数据管理的研究。详实可靠的运行数据是水力发电企业生产管理中的一笔宝贵财富,可为开展经验总结分析、运行调度提质增效、电力生产精细化管理等提供数据基础。
目前关于水电站运行数据的研究集中于数据管理平台建设、数据格式标准化探索等。杜冬艳[2]从技术方面,提出了构建综合数据管理平台的总体方案、硬件拓扑结构、软件体系结构,解决了电力行业“信息孤岛”的问题;从企业管理角度,提出了要建立协调的数据管理组织机构和完善的数据管理绩效考核机制及人员培训机制,保证数据管理平台的高效运行。Lin[3]通过云计算提取数据特征并传送到数据特征集进行实时管理,然后利用特征集对数据实时管理流程进行优化。Wu等[4]基于GJB 6600标准设计交互式电力数据管理软件,实现数据规划、数据模块/数据实体/基础数据等人工数据管理功能,通过数据整编过程中的任务分配、校对、审批和定稿功能,实现数据版本管理和安全控制。雷霆等[5]阐述了智能电网综合数据平台系统功能构架和逻辑层次的划分,探讨了标准规范体系、元数据管理和数据编码规范的数据规范化工作,从接口体系、交互界面、通用交换等方面综合分析了数据标准化接口,并介绍了标准化数据在数据质量综合辨识、可扩展数据综合搜索、集成式电网故障诊断等方面的应用。李小龙等[6]设计了包含数据规范化处理、成果文件输出、测量数据入库、数据动态建模分析与可视化等功能的新数据动态管理系统。张琳琳等[7]利用Hadoop的分布式文件系统HDFS和并行处理框架MapReduce的工作原理,搭建电网调度大数据应用平台系统,解决了不同业务系统之间的数据不能及时共享、访问、管理与分析挖掘等问题。
雅砻江是中国规划的十三大水电基地之一,是国家实施“西电东送”战略可靠优质的电源点,肩负地区供电及“西电东送”的重任。当前,雅砻江流域下游已建成并运行“两库五级”梯级水电站(锦屏一级、锦屏二级、官地、二滩和桐子林),为川渝及华中地区社会经济高质量发展提供了电力支撑。日常调度中,监控、水调自动化、水情自动测报等系统是“两库五级”梯级水电站安全稳定经济运行的技术保障,积累了大量的运行调度数据(如气象、水文、电能量等),如何高效管理这些数据并充分发挥其价值是调度人员面临的一个棘手问题。随着水电站规模的增加、时间的累积,运行调度数据将呈现快速增长态势,优化数据管理、整合数据资源、挖掘数据价值的应用需求将更为迫切,但目前涉及雅砻江梯级水电站运行数据管理的研究尚不多见。基于此,本文从数据梳理、计算存储规则、运行维护等方面构建雅砻江梯级水电站运行数据管理优化模型,为解决雅砻江流域电力生产数据高效管理问题提供理论支撑。
1 雅砻江梯级水电站运行数据管理现状
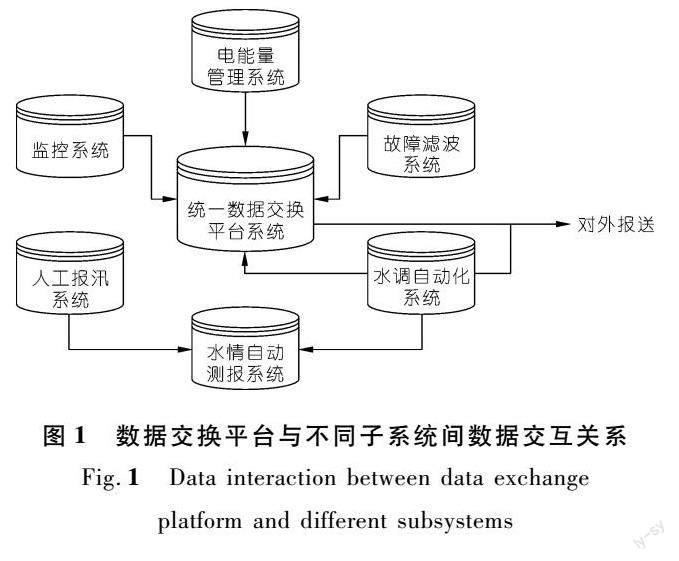
为满足电力生产运行需求,雅砻江流域水电开发有限公司集控中心(以下简称“集控中心”)建有多个生产业务系统,如计算机监控系统、电能量管理系统、故障滤波系统、水情自动测报系统、水调自动化系统和人工报汛系统等[8]。由于建设时期不同,各子系统从操作系统、开发语言、通信协议直到数据存储都不尽相同,不同子系统对水电生产数据的重复维护容易造成数据的不一致和不完整[8]。为此集控中心开发了统一数据交换平台系统(以下简称“数据交换平台”),具备接入数据的WEB展示及数据查询、报表服务、元数据存储管理等功能。
数据交换平台与不同子系统的数据交互关系如图1所示。数据交换平台实现了将各子系统的数据按照统一的模型建模,按照统一规范和统一编码进行存储和整合,并统一对外提供数据信息服务。多年运行实践表明,数据交换平台有效支撑了水电站运行数据的统一维护与管理工作,但也暴露出一些短板问题,不能很好地适应大规模、高精度、优效能的数据管理服务需求。
(1) 数据元素杂乱,不利于数据高效应用,需要系统梳理。以水调自动化系统为例,由于首次建设时相关经验不足,系统里遗留了较多无数值以及没有意义或价值不大的数据元素,且数据元素的点号及命名设置不够规范,不利于快速查找和准确使用。因此,应进行数据元素的系统梳理,完善相应数据元素配置,建立数据元素管理台账,方便对其进行增减删改。
(2) 数据计算及存储质量不高,需进行规范化处理。现有数据资料系列,同一類数据存在单位不同、保留小数位不同、计算方法不尽相同的情况;同一数据元素不同统计特征值序列,直接被同一个数值填充;同一数据元素某些统计特征值序列没有意义,但仍被赋值,如日发电量平均值、日水量平均值;甚至同一数据元素同一个序列,时间上前后计算方法不同,一致性遭到破坏。这些问题都不利于水电站运行数据的分析应用。
(3) 数据修改维护管理复杂,需引进新技术提高管理能力。数据的扰动具有蝴蝶效应,如遥测基础数据的时效性和可靠性不足往往可造成其他众多相关计算数据的不确定;同时,不同单位部门对同一数据的需求是多变的,如电网对相关弃水损失电量的要求等。因此,数据的修改维护、计算方法调整是必要的,也是不可避免的。当前各系统相对独立,交互不强,为保证数据一致,需在多个系统里修改维护,效率较低。
2 多元数据管理优化模型
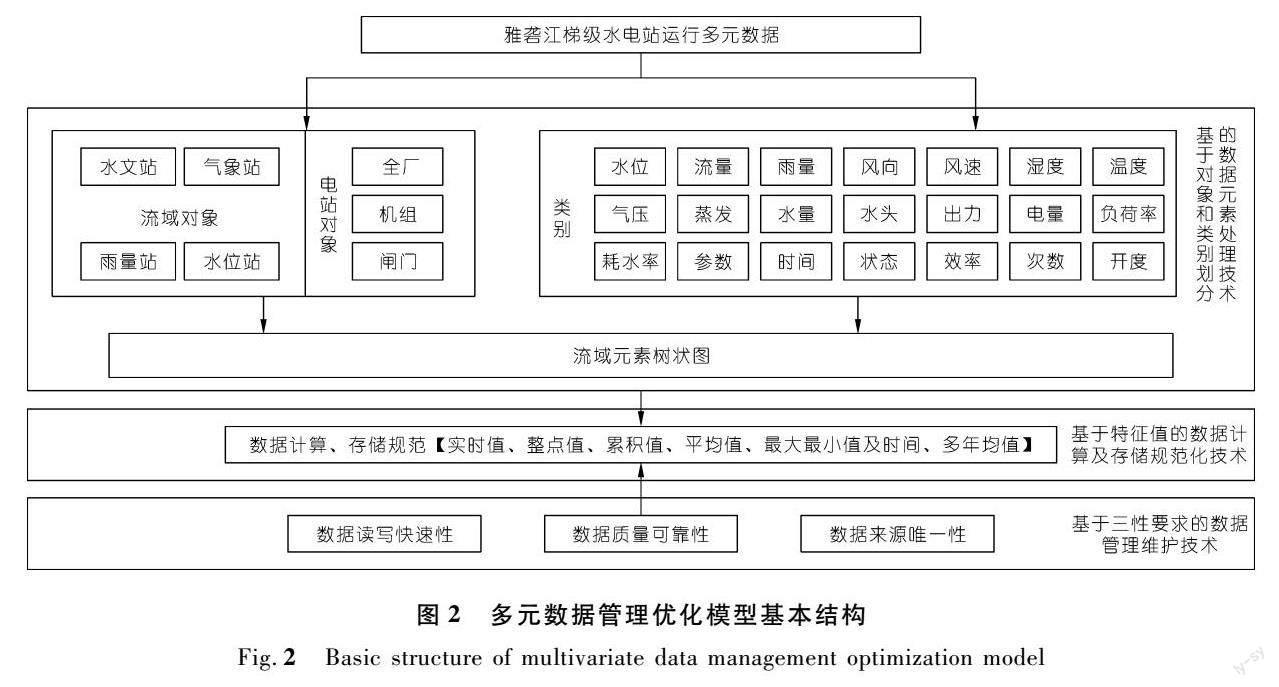
基于上述现状分析,建立多元数据管理优化模型,模型结构如图2所示。以雅砻江梯级水电站日常运行数据为输入,首先对具备多对象、类别特点的大量数据元素进行处理分析,再对处理后的各类别数据开展计算及存储的规范化研究,最后提出数据管理维护的3方面要求及实现途径。所建模型的核心内容包括3部分:基于对象和类别划分的数据元素处理技术、基于特征值的数据计算及存储规范化技术、基于三性要求的数据管理维护技术。
2.1 基于对象和类别划分的数据元素处理技术
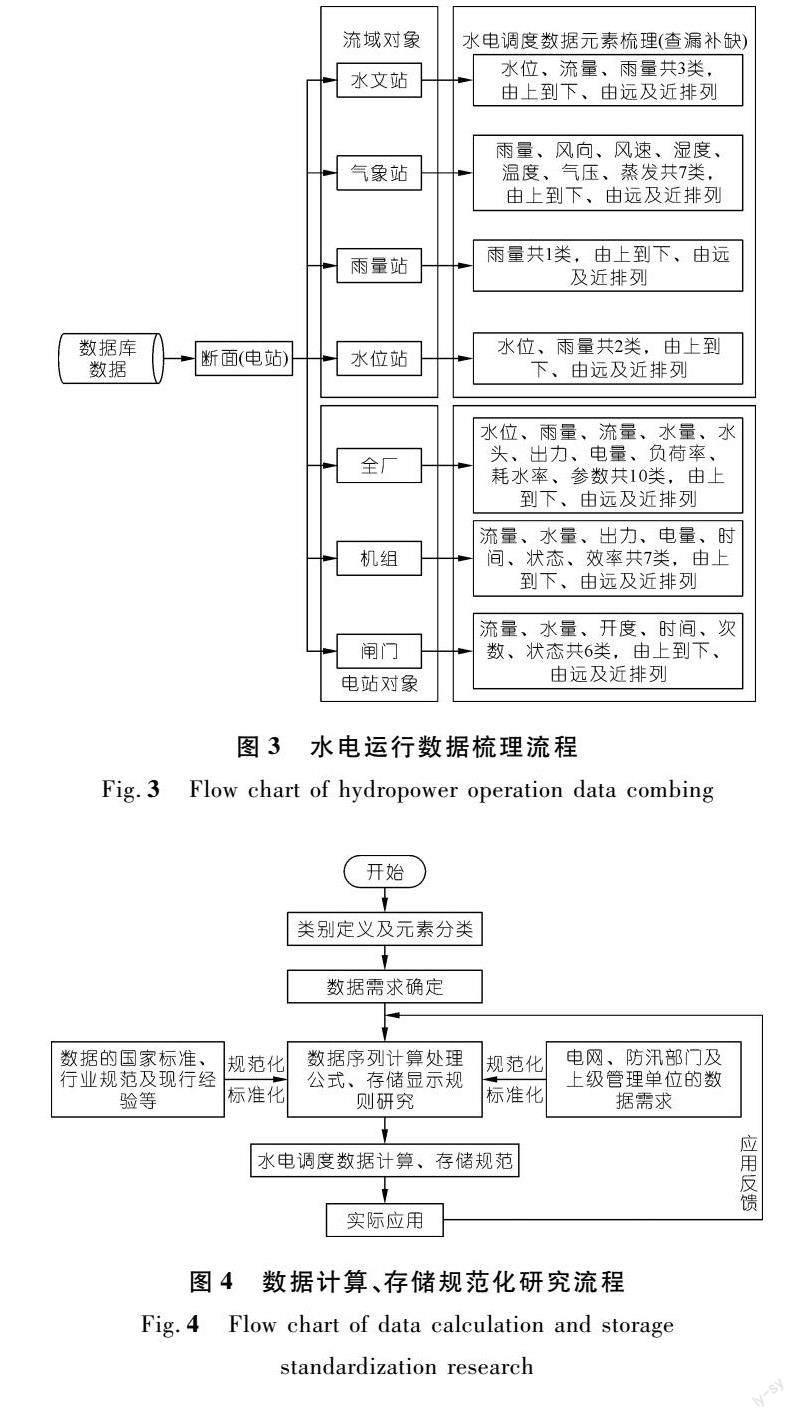
为解决数据元素杂乱问题,针对雅砻江梯级水电站实际运行特点,提出了基于对象和类别划分的数据元素处理技术,以快速对数据元素进行批量增减、精准查询和对比分析,提升对历史数据的利用水平。基于对象和类别划分的数据元素处理技术流程如图3所示。主要步骤包括:
步骤1:遵循分类清晰、类型全面的原则划分数据类别。将所有数据元素按所属对象分为流域对象和电站对象,流域对象包括水文站、气象站、雨量站、水位站4个子对象,电站对象包括全厂、机组和闸门3个子对象;系统所有数据元素按类别分为水位、流量、雨量、水量、出力、电量、水头、耗水率、负荷率、开度、状态、时间、次数、效率、风向、风速、湿度、温度、气压、蒸发、参数等21类。
步骤2:构建流域树状结构,将元素从上游至下游,由远及近排列,去除原有多余无意义的元素,同时结合新电站投产及流域站网优化要求查漏补缺,完整地梳理出新系统应计算存储的所有数据元素。
2.2 基于特征值的数据计算及存储规范化技术
2.2.1 数据计算及存储规范化基本流程
水电站运行数据种类繁多,来源各异。每一类数据在存储时有统一的分表格式和配置,如水位类有实时数据表和时段统计表(小时表、日表、旬表、月表和年表),时段统计表里有整点值、平均值、最大值、最小值以及最大最小值时间等特征值序列。针对前述各电站同类数据计算方法不同、小数保留位数不一致、元素不同特征值序列被赋同一数值等计算及存储问题,研究提出基于特征值的数据计算及存储规范化技术,基本流程如图4所示。
主要步骤包括:
步骤1:厘清类别概念,对类别内元素进行归纳分类,确定每个类别/元素集的数据需求。
步骤2:结合水电调度数据的国家标准、行业规范和现行经验等,初步确定各类别/元素集的数据计算处理公式和存储显示规则。
步骤3:加强与电网机构、防汛部门和上级管理单位的沟通协调,研究确定满足数据上报要求的数据计算处理公式和存储显示规则。
步骤4:形成水电调度运行数据计算及存储规范,应用规范分析确定每个元素数据需求、计算处理公式和存储显示规则。
2.2.2 数据计算及存储规范化具体实例
本文以水位类别为例,从定义及分类、命名规范、计算规范、存储规范等4方面进行具体说明。
(1) 水位类别定義及分类。
水体在某一基准面以上的水面的高程。在系统中分为自动遥测水位、人工报汛水位和运行计划水位3类。
(2) 命名规范。
① 河道水文(位)站水位
按照“站名+遥测水位”规范命名,如:甘孜遥测水位。
② 枢纽水位站水位
按照“电站名+监测位置+水位传感器类别+遥测水位+编号(如有2套及以上设备时)”规范命名,如:锦屏一级坝上浮子遥测水位、锦屏一级尾水雷达遥测水位2。
③ 参与水务计算的枢纽水位
按照“电站名+监测位置水位”规范命名,“监测位置水位”包括坝(闸)上水位、坝(闸)下水位、尾水水位、进水口水位,如:锦屏二级闸下水位、锦屏二级尾水水位。
④ 河道水文(位)站报汛水位
按照“站名+报汛水位”规范命名,如:甘孜报汛水位。
⑤ 枢纽水位站报汛水位
按照“电站名+监测位置+报汛水位”规范命名,如:锦屏二级闸上报汛水位。
⑥ 运行计划水位
按照“电站名+目标时段+计划水位”规范命名,如:锦屏一级月末计划水位、二滩年末计划水位。
(3) 计算规范。
① 实时遥测水位。
H实时遥测=H水位计基值±h实时遥测数据(1)
式中:H实时遥测为实时遥测水位;H水位计基值为遥测站水位基值;h实时遥测数据为实时遥测数据,根据水位计类别,确定计算符号。
② 小时整点遥测水位。
取实时遥测水位中最接近整点时间(±5 min以内)的水位值,若无满足条件的水位值则触发报警。
H小时遥测t=match(t整点,H实时遥测)(2)
式中:H小时遥测t为t时刻小时整点遥测水位;t整点为t时刻。
③ 小时平均遥测水位。
根据小时时段内的实时遥测水位采用面积包围法计算得出。
H~小时遥测t=[(H0+H1)×t1+(H1+H2)×t2+…+(Hn-1+Hn)×tn]/[2×(t1+t2+…+tn)](3)
式中:H~小时遥测t为t-1至t时刻小时平均遥测水位;H0为t-1时刻小时整点遥测水位;H1、H2…Hn-1为t-1至t时刻内的实时遥测水位;Hn为t时刻小时整点遥测水位;t1、t2…tn为t-1至t时刻内实时遥测水位的时间间隔。
④ 小时极值遥测水位。
根据小时时段内的实时遥测水位统计得出。
⑤ 日平均遥测水位。
根据日内各小时平均遥测水位采用算术平均计算得出。
⑥ 日极值遥测水位。
根据日内小时极值遥测水位统计得出。
⑦ 旬(月、年)平均遥测水位。
根据旬(月、年)内各日平均遥测水位采用算术平均计算得出。
⑧ 旬(月、年)极值遥测水位。
根据旬(月、年)内日极值遥测水位统计得出。
⑨ 人工报汛水位。
包括实时报汛水位、旬平均报汛水位、月平均报汛水位及月极值报汛水位。人工根据规范观测处理后,将水位信息编码发送至中心站,由中心站解码后储存至相应数据元素特征值序列。
⑩ 运行计划水位。
发电计划编制完成后,运行计划水位自动储存至相应序列。
(4) 存储规范。
水位元素单位为m,按照四舍五入并保留2位小数存储。当计算依据元素发生变化时,系统自动提示,由人工判断是否进行联动计算。
按照上述流程,可形成梯级水电站各类水位数据计算和存储的统一标准。特别地,根据GB/T 50138-2010《水位观测标准》、SL/T 247-2020《水文资料整编规范》和公司管理需求,完善规范。应用规范确定各水位元素不同统计时段不同特征值序列的具体计算公式,提高数据质量,有利于数据后期维护。
2.3 数据管理维护技术
随着数据在时空范围上的延伸,水电站智能调度对多元海量数据的管理维护提出了更高要求。对于雅砻江梯级水电站,管理维护的需求主要体现在3个方面:即实现数据的快速读写、质量可靠以及来源唯一。
2.3.1 数据读写快速性
为了提升性能以及可存储量,针对工程特点、水电各专业特点等按照一定的规则进行数据库分表,并尽量控制每张表的记录条数在百万级别。
数据库分片指:通过某种特定的条件,将原一个数据库表中的数据分散存放在不同的多个数据表中,以分散单表容积、提升单表读写性能。同时为解决数据库表间数据快速查询和插入的问题,提出基于虚拟库技术的自动建表分流方法,其可对用户提交的各种数据库请求进行解析,精确为所有请求路由至不同的子表进行真实数据库访问,对访问的结果按照请求类型进行合并和排序反馈回水电业务端,用户则完全不需了解底层数据库的细节[9-10]。
虚拟数据库技术就是构建一个逻辑数据库,它利用标准的数据库通讯协议对外提供无差别的数据库访问服务(见图5)。所有的水电业务组件和模块的数据访问层统一访问逻辑库,由这个虚拟逻辑库去统一管理数据子表的访问和路由。
2.3.2 数据质量可靠性
数据全生命周期管理是近年来新兴的一项数据质量监管技术,它是指在分析系统数据特点及业务应用需求的基础上,采取一定的策略和方法对数据从采集、传输、处理、存储、报送等整个生命周期内的流动进行版本管理,来保障数据质量、提升业务应用的效率和水平[11-12](见图6)。此时,数据库将详细存储时间序列数据,包含数据的点号、依据时间、到达(产生)时标、来源标识、质量标识和版本等信息。
数据来源标识表明该数据的来源,即用不同整数来定义采集、通信、人工插补、数据库交换、系统自动计算、数据整编等类别;数据质量标识表明数据的可用性及可信度,也用整数来定义原始(待定)、可疑、异常、合理(信任)、高质量存档数据等类别。这些标识内涵及定義可根据系统应用需要而扩展。
2.3.3 数据来源唯一性
一体化平台系统是未来生产管理系统建设趋势,但是受困于不同业务安全分区和安全管理要求,系统仍存在数个独立、交互受限的数据库,同一数据序列可能同时储存到两个或多个子系统或数据库里。为保证数据唯一性,应修改维护数据源头,并自动向其他地方同步更新。为保证效率可采用拦截式跨区同步技术,雅砻江一体化平台跨区同步示意图见图7。
拦截式跨区同步技术原理为:在一体化平台中,对各业务数据总线设立统一代理拦截,所有客户端的服务请求都会通过代理拦截后再发送至各服务单元进行处理,服务结果再通过代理返回给客户端,代理对拦截到的数据进行同区和跨区同步通信[13-14]。基于一体化拦截的数据同步机制能更好地实现客户端存储和各区数据库存储数据一致的实时性,所有的拦截数据对象传输均以异步的方式进行,各拦截器不仅需要接收本方应用传输的存储更新请求,还需要执行其他拦截器提交的同步数据更新请求。
3 应用效果
当前雅砻江流域集控中心综合自动化系统二期工程已正式启动,目标为建设一个符合《智能水电厂技术导则》架构的、基于一体化平台的新一代综合自动化系统(见图8),实现全流域电站的经济运行和优化调度管理。本文所建模型是其中一体化平台的重要构成,已收集28个水文站、14个气象站、84个雨量站、20个水位站数据信息,并接入雅砻江“两库五级”梯级水电站多年运行数据(锦屏一级、锦屏二级、官地、二滩和桐子林)。已取得的主要效果如下。
(1) 精简了数据库元素。
梳理数据元素,筛查出无意义(含无数据及无用途)元素约1 250个,增补新投电站相关元素后,数据元素共计约1 720个。优化数据查询界面如图9所示,通过勾选对象,可以快速查找流域或电站相关元素;通过勾选类别,可以快速查找某一类元素;同时勾选对象和类别,可快速查找个人所需元素集;此外,用户可根据个人习惯设置并保存常用的元素分组。
(2) 提升了数据处理质量。
通过数据计算、存储规范化,在现有元素特征值序列(整点值、平均值、最大值、最小值、最大值时间和最小值时间)基础上增加累积值和多年均值,个性化确定各类别(元素)的特征值序列需求,如电站发电量有累积值、最大值、最大值时间、最小值、最小值时间和多年均值,而水位为整点值、平均值、最大值、最大值时间、最小值、最小值时间和多年均值。对系统元素的命名、计算和存储均进行了规范,详细确定了每列数据计算处理的公式步骤和输入输出形式,使得每个数据逻辑清晰,质量可靠。
(3) 優化了数据维护管理。
后台引入虚拟数据源-数据库表分片技术,在长时段历史或实时数据查询时可大幅提升数据查询分析的效率。数据全生命周期管理技术可记录数据生成、流转、消亡的过程,加强了对数据的管控,尤其可用于对系统异常数据的追踪分析。拦截式跨区同步技术,可快速对备份数据库和其他专用系统数据库等进行数据同步,提高了数据维护管理效率。
4 结 语
运行数据的高效整合与管理是实现水电站智能运行的重要基础。本文耦合3种技术构建了一种面向雅砻江梯级水电站运行的多元数据管理优化模型,提出的基于对象和类别划分的数据元素处理技术解决了数据元素杂乱问题,研究的基于特征值的数据计算及存储规范化技术改善了数据质量,数据管理维护技术提升了对数据修改维护的管理能力。所建模型已在雅砻江综合自动化系统二期工程进行了应用。随着两河口、杨房沟、卡拉等水电站的投产运行,持续提升模型在雅砻江流域时空尺度应用的适应性和延伸性是下一步需要解决的问题。
参考文献:
[1] 张博庭.新时期我国水电开发的新课题[J].水电与新能源,2022,36(1):1-5,12.
[2] 杜冬艳.电网调度综合数据平台管理研究[D].青岛:中国石油大学(华东),2013.
[3] LIN P.Research on optimization of distributed big data real-time management method[C]∥2018 3rd International Conference on Smart City and Systems Engineering(ICSCSE),2018:626-630.
[4] WU J,ZUO H,MENG L,et al.“IETM Data Management,” 2019 Chinese Automation Congress(CAC),2019:5158-5162,doi:10.1109/CAC48633.2019.8996837.
[5] 雷霆,黄太贵,李端超,等.智能电网调度数据标准化及应用[J].水电能源科学,2011,29(12):174-176,55.
[6] 李小龙,张天昊,程涛,等.水电站施工测量数据动态管理系统研究[J].人民长江,2017,48(16):63-66.
[7] 张琳琳,王顺江,郭星池,等.电力调度大数据应用平台系统技术研究[J].电力大数据,2021,24(1):48-54.
[8] 张竞,宁慧.雅砻江流域电力生产数据管理及应用现状分析[J].四川水力发电,2014,33(4):102-105,112.
[9] 谢振华.基于分布式的数据库分库与分表策略研究[J].电脑知识与技术,2020,16(14):60,62.
[10] 姬渭孟,于雪莲.基于数据库代理实现数据库分表、分库访问的方案研究[J].数字通信世界,2019(9):238.
[11] 屈莉莉,陈燕,王聪.基于成果导向的大数据专业建设及面向数据生命周期的课程体系设计[J].电脑知识与技术,2021,17(6):20-21,29.
[12] 贾韶辉,张新建,李妍,等.油气管道全生命周期数据管理及其在中俄东线的应用[J].油气储运,2020,39(7):756-762,820
[13] 陈意,向南,徐骏.基于代理拦截的智能化水电厂基础支撑服务冗余策略实现[J].水电厂自动化,2014,35(1):62-66.
[14] 杨宁,蔡杰,舒凯,等.智能水电厂一体化平台跨区数据同步策略[J].水电自动化与大坝监测,2013,37(4):1-3,12.
(编辑:黄文晋)
Abstract:
In order to solve the problems of chaotic data elements,irregular calculation and storage,and low maintenance efficiency in the daily operation data management of Yalong River cascade hydropower stations,a technical chain of “data processing-calculation and storage-management and maintenance” was adopted,some key technologies,such as data element processing based on object and class division,data calculation and storage standardization based on Eigenvalue,and data management and maintenance technology based on three requirements (read-write rapidity,quality reliability and source uniqueness) were put forward.The data management optimization model for Yalong River cascade hydropower station was established.The model has been integrated into the second phase of the Yalong River integrated automation system,which has been effectively enhancing the management and maintenance capability of the operation data of the hydropower stations in the river basin.The application result shows that the model can effectively solve the problems of operation data management and maintenance of cascaded hydropower stations,it can also provide powerful data management technical support for the intelligent operation of cascade hydropower stations.
Key words:
cascade hydropower stations;multivariate data management;standardization technology;Yalong River Basin
